基于旋轉框精細定位的遙感目標檢測方法研究
2023-03-06 13:32:00方觀壽鄭兵兵
自動化學報 2023年2期
朱 煜 方觀壽 鄭兵兵 韓 飛
近年來,隨著遙感技術的發展,高質量的遙感圖像日益增多,這為遙感領域的應用奠定了基礎.遙感圖像廣泛應用于災害監測、資源調查、土地利用評價、農業產值測算、城市建設規劃等領域[1],對于社會和經濟發展具有重要的意義.而目標檢測作為遙感圖像處理的應用之一,獲得圖中特定目標類別和位置.通常關注飛機、機場、船舶、橋梁和汽車等目標,因此對于民用和軍用領域有著十分重要的用途[2].在民用領域中,船舶的定位有利于海上救援行動,車輛的定位有利于車輛計數和分析道路的擁堵情況等.在軍事領域中,這些類別信息的檢測獲取,有利于快速且精準地鎖定攻擊目標位置、分析戰爭形勢以及制定軍事行動等.因此對于遙感圖像中的目標進行精準檢測至關重要.
目標檢測是計算機視覺領域中一個重要且具有挑戰性的研究熱點.隨著深度學習的快速發展,目標檢測器的性能取得了顯著進步,已經廣泛應用于各個行業.目前常用的目標檢測器大致可以分為兩級檢測器和單級檢測器兩類[3].兩級檢測器是基于區域卷積神經網絡(Regions with convolutional neural network,R-CNN)框架,檢測過程分為兩個階段.第1 階段從圖像中生成一系列候選框區域,第2 階段從候選框區域中提取特征,然后使用分類器和回歸器進行預測.Faster R-CNN[4]作為兩級檢測器的經典方法,提出候選區域生成網絡(Region proposal networks,RPN)用于候選框的產生,從而快速、準確地實現端到端檢測.之后區域全卷積網絡(Region-based fully convolutional network,RFCN)[5]、Cascade R-CNN[6]等兩級檢測器的出現進一步提高目標檢測的精度.單級檢測器將檢測問題簡化為回歸問題,僅僅由一系列卷積層進行分類回歸,而不需要產生候選框及特征提取階段.因此這類方法通常檢測速度較快.例如,Redmon 等[7]提出YOLO 檢測器,將圖像劃分為一系列網格區域,每個網格區域直接回歸得到邊界框.Liu 等[8]提出SSD檢測器,在多個不同尺度大小的特征圖上直接分類回歸.Lin 等[9]提出Focal Loss 分類損失函數,解決單級檢測器的類別不平衡問題,進一步提高檢測精度.這些先進的目標檢測技術往往用于水平邊界框的生成,然而在遙感圖像中,大多數檢測目標呈現出任意方向排列,對于橫縱比大或者密集排列的目標,僅僅采用水平框檢測將包含過多的冗余信息,影響檢測效果.因此旋轉方向成為不可忽視的因素.
早期應用于遙感領域的旋轉框檢測算法主要來源于文本檢測,例如R2CNN[10]和RPN[11]等.然而由于遙感圖像背景復雜且空間分辨率變化較大,相比于二分類的文本檢測具有更大困難,因此這些優秀的文本檢測算法直接應用于遙感領域中并不能取得較好的檢測效果.近年來,隨著目標檢測算法的發展以及針對遙感圖像的深入研究,涌現出許多性能良好的旋轉框檢測算法.例如Ding 等[12]提出旋轉感興趣區域學習器(Region of interest transformer,RoI),將水平框轉換為旋轉框,并在學習器中執行邊界框的回歸;Zhang 等[13]提出通過捕獲全局場景和局部特征的相關性增強特征;Azimi 等[14]提出基于多尺度卷積核的圖像級聯方法;Yang 等[15]提出像素注意力機制抑制圖像噪聲,突出目標的特征,并且在SmoothL1損失[4]中引入IoU 常數因子解決旋轉框的邊界問題,使旋轉框預測更加精確.Yang 等[16]設計精細調整模塊,采用特征調整模塊,通過插值操作實現特征對齊.Xu 等[17]提出回歸4種長度比來表示對應邊的相對偏移距離,并且引入了一個真實框與其水平邊界框面積比作為傾斜因子,用于對每個目標水平或旋轉檢測的選擇.Wei等[18]提出利用預測內部中線實現旋轉目標檢測的方法.Li 等[19]提出利用預測的掩模獲取旋轉框的方法.Wang 等[20]提出了一種基于初始橫向連接的特征金字塔網絡(Feature pyramid networks,FPN)增強算法,同時利用語義注意力機制網絡提供語義特征,從復雜的背景中提取目標.
因此,目前在遙感圖像中用于旋轉框檢測的方法大致可以分為兩種.其中一種算法整體結構仍然為水平框檢測,僅僅在回歸預測分支中增加一些變量的獲取,例如角度因子等.這種算法使得在網絡預測的像素中包含較多背景信息,容易出現圖1 所示的角度偏移以及漏檢較多等問題.另一種算法預設含有角度的錨點框,然后采用旋轉候選框內的像素進行預測.由于目標的旋轉角度較多,因此這種算法需要預設大量的錨點框以保證召回率,這樣會極大地增加計算量.

圖1 遙感圖像目標檢測問題可視化Fig.1 Visualization of remote sensing images object detection problem
針對上述不足,本文結合這兩種處理方法的優勢,以Faster R-CNN[21]為基礎,提出一種用于旋轉框檢測的網絡R2-FRCNN (Refined rotated faster R-CNN).該網絡依次采用上述兩種旋轉框處理方法,將前一種方法得到旋轉框的過程視為粗調,這個階段產生的旋轉框作為后一種方法的預設框,然后對于旋轉框再次進行調整,這個過程稱為細調.兩階段調整使得網絡輸出更加精確的預測框.此外,針對遙感圖像存在較多小目標的特點,本文提出像素重組特征金字塔結構(Pixel-recombination feature pyramid network,PFPN),相比于傳統的金字塔網絡,本文的金字塔結構使得特征局部信息與全局信息相結合,從而突出復雜背景下小目標的特征響應.同時為了更好地提取表征目標信息的特征,用于后續預測階段,本文在粗調階段設計積分感興趣區域池化方法(Integrate region of interest pool,IRoIPool),以及在精調階段設計旋轉感興趣區域池化方法(Rotated region of interest pool,RRoIPool),提升復雜背景下小目標的檢測精度.最后,本文在粗調和細調階段均采用全連接層與卷積層結合的預測分支以及SmoothLn回歸損失函數,進一步提升算法性能.
本文結構安排如下: 第1 節詳細闡述本文提出的旋轉框檢測網絡R2-FRCNN;第2 節通過與官方基準方法和現有方法的實驗結果進行對比,以及本文方法各模塊的分離實驗,評估本文方法的性能;第3 節總結.
1 旋轉框目標檢測方法
本節對提出的網絡R2-FRCNN 結構以及各模塊進行闡述.首先介紹R2-FRCNN 網絡的整體結構,然后詳細介紹各個模塊(像素重組金字塔結構、感興趣區域特征提取和網絡預測分支結構),最后介紹本文使用的損失函數.
1.1 網絡結構設計
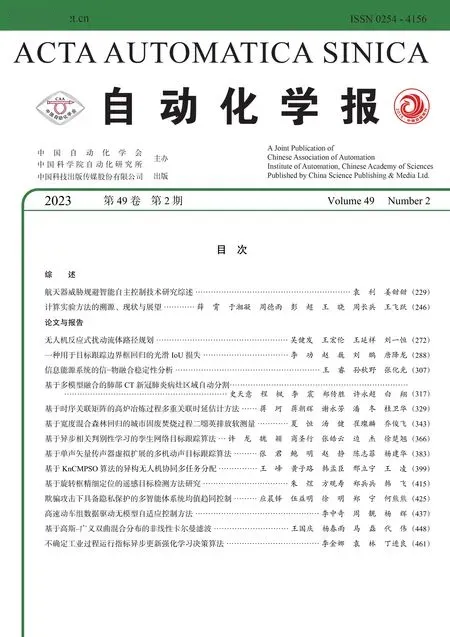
圖2 展示了R2-FRCNN 網絡的整體結構,可以分為基礎網絡、像素重組金字塔、候選區域生成網絡RPN、粗略調整階段和精細調整階段5 個部分.
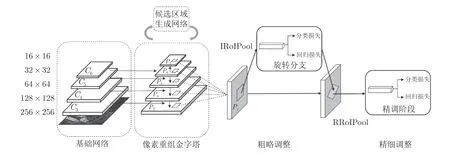
圖2 R2-FRCNN 網絡結構圖Fig.2 The structure of R2-FRCNN
本文采用ResNet[22]作為算法的基礎網絡,將C3、C4、C5和C6特征層用于構建特征金字塔結構,增強網絡對于小目標的檢測能力.由金字塔產生的P3、P4、P5、P6和P75 個特征層上,每個像素點預設3 個錨點框,錨點框的長寬比為{1:1,1:2,2:1},尺寸大小為8,經由RPN[4]調整錨點框的位置生成一系列候選框.然后選擇置信度較高的2 000 個候選框用于粗略調整階段,該模塊的回歸過程將水平框調整為旋轉框.最后這些候選框進入精細調整階段,再次調整旋轉框的位置,得到更好的檢測效果.經過兩階段調整后的框,選擇后一階段中最大分類數值作為置信度,同時采用旋轉非極大抑制算法處理,選取鄰域內置信度較高的框,并且抑制低置信度的框,這些高置信度的候選框即為網絡輸出預測框.
1.2 像素重組金字塔結構
特征金字塔結構[23]被廣泛應用于許多先進的目標檢測算法中,這個結構的設計在于淺層的定位信息準確,深層的語義信息豐富,通過融合深淺層特征圖,提升對于小目標的檢測性能.如表1 所示,RoI-Transformer (RT)[12]、CADNet[13]、SCRDet[15]、R3Det[16]和GV R-CNN (GV)[17]均采用了深淺層融合特征,表現出優異的檢測性能,而R2CNN[10]未使用特征融合,取得的檢測結果遠低于其他方法.圖3為本文設計的像素重組金字塔結構.該結構分為2個階段: 第1 階段為Ci→Mi,采用尺度轉化的方式,利用局部特征信息的同時,融合上下層構建金字塔結構;第2 階段為Mi→Pi,采用非局部注意力[24]模塊,利用全局信息,突出目標區域的特征.
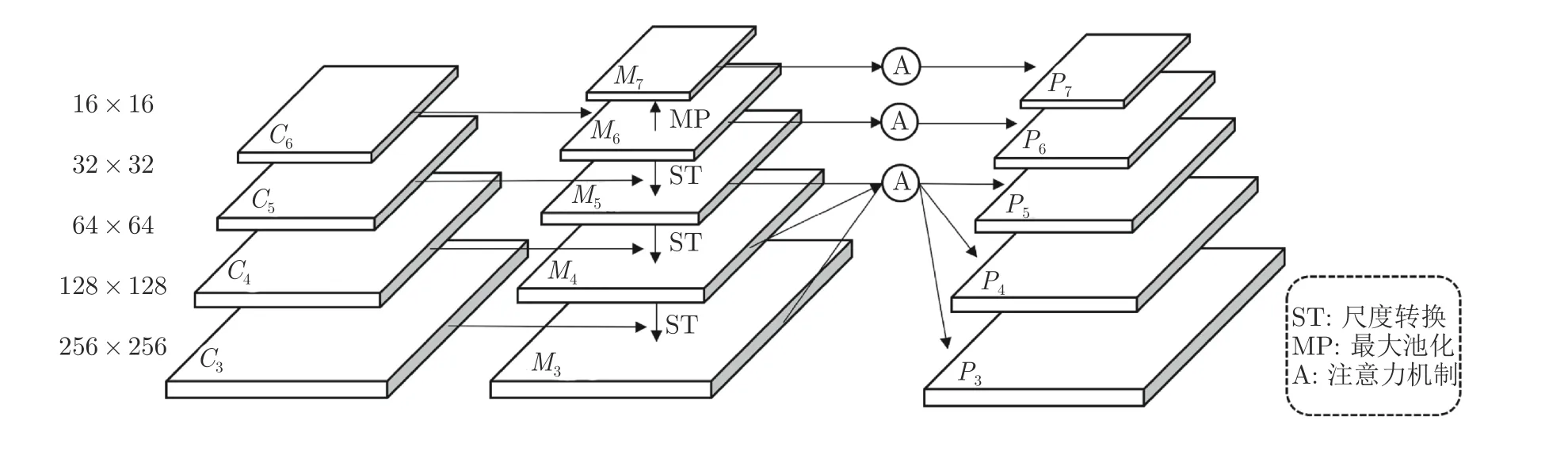
圖3 像素重組金字塔結構Fig.3 The structure of pixel-recombination pyramid
表1 不同方法在DOTA 數據集的檢測精度對比(%)Table 1 Comparison of detection accuracy of different methods in DOTA (%)
在第1 階段中,特征上采樣對于金字塔結構是一個關鍵的操作.最常用的特征上采樣方式為插值和轉置卷積[25].插值法僅考慮相鄰像素,無法獲取密集預測任務所需的豐富語義信息.轉置卷積作為卷積的逆運算,將其作為上采樣方式存在2 點不足[26]:1)對于整個特征圖都采用同樣的卷積核,而不考慮特征圖中的目標信息,限制了上采樣過程對于局部變化的響應;2)若采用較大的卷積核將會增加大量參數.本文引入尺度轉換作為特征上采樣方法.深淺層特征融合的操作過程如圖4 所示.該方法首先利用 “通道轉化”方法[27]壓縮通道數(本文壓縮系數r=0.5),增大特征圖尺寸,即:
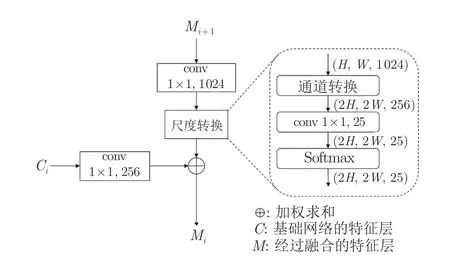
圖4 特征融合結構Fig.4 The structure of feature fusion
然后,采用 1×1 的卷積層用于調整通道數,再由Softmax 函數[28]作用于每一通道的特征層.最后采用式(2)進行加權求和,使得特征融合過程更好地利用局部信息.
式中,m、n分別表示像素的橫、縱位置,c表示C特征層當前通道,k表示M特征層當前通道.
第2 階段采用非局部注意力模塊,利用特征圖中目標與全局特征的關系,突出目標區域的響應.
根據非局部注意力模塊的定義,假設C為通道數,s為尺度大小,G為特征圖尺度的乘積即s×s,x為輸入特征圖,q(x) 、k(x) 和v(x) 定義為采用不同線性轉換的結果:
q(xs)與k(xs) 矩 陣相乘,得二維矩陣os ∈RG×G;再運用Softmax 將矩陣的每一行轉換為概率值,最后與v(xs) 矩陣相乘后再與輸入相加,得輸出量xs′:
在本文的特征金字塔結構中,第1 階段輸出的M3和M4由于尺度較大,直接用于非局部注意力模塊計算量較大.因此為了保留這兩層的語義信息,同時再次融合不同層的特征,該結構將M3和M4池化為M5的尺寸大小,然后計算這3 層的均值輸入非局部注意力模塊,再由插值操作輸出對應相等尺寸的特征圖.M6和M7的特征圖直接應用非局部注意力模塊得到P6和P7層.
1.3 感興趣區域特征提取模塊
感興趣區域特征提取模塊主要用于固定輸出尺寸大小,提取表征框內區域的特征,便于后續的網絡預測.本文的RoI 特征提取模塊主要分為粗調階段的水平框和細調階段的旋轉框RoI 特征提取兩部分.
自然場景圖像中的目標通常是固定方向呈現,因此兩階段式目標檢測算法采用水平框的RoI 特征提取.目前,應用較為廣泛的RoI 特征提取是RoIPooling[4]和RoI Align[29].圖5(a)為RoI 池化原理圖,選擇量化后塊中最大像素值作為池化后的結果.然而量化的結果會導致提取的小目標像素存在偏差,影響檢測效果.圖5(b)為RoI 對齊原理圖,取消量化操作,采用雙線性插值在塊中計算出N個浮點坐標的像素值,均值作為塊的結果.然而這個操作存在兩點不足: 采樣點數量需要預先設置,不同大小候選框設置了相同數量的采樣點.
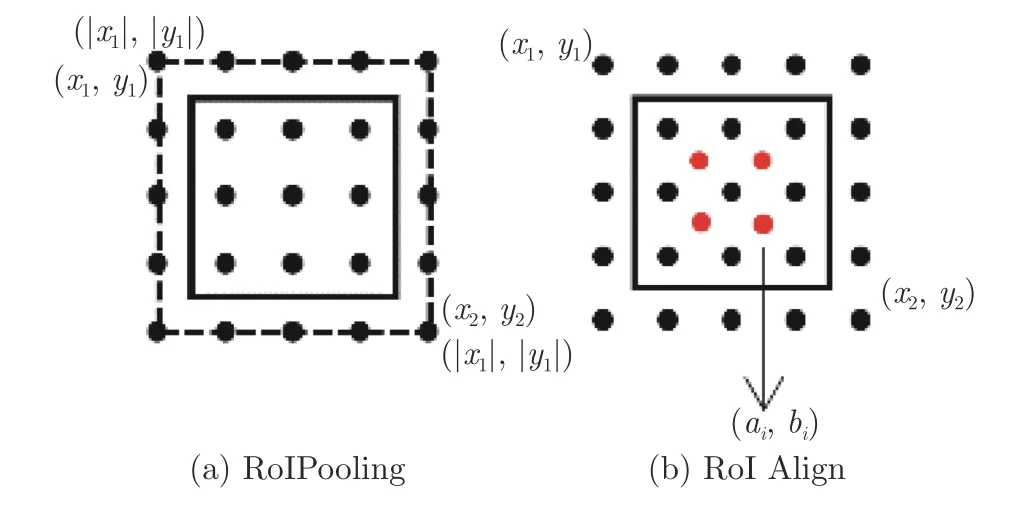
圖5 常用RoI 特征提取示意圖Fig.5 The schematic diagram of common RoI feature extraction
因此,本文采用精確RoI (Precise RoI,Pr-RoI)池化方法[30]的特征提取操作,如圖6 所示,由插值操作將塊內特征視為一個連續的過程,采用積分方
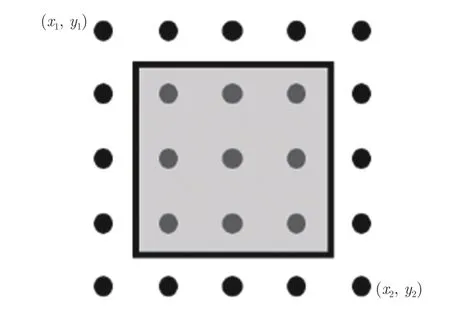
圖6 IRoIPool 特征提取示意圖Fig.6 The diagram of IRoIPool feature extraction
法獲得整個塊的像素和,其均值作為塊的結果,即:
式中,f(x,y) 為采用面積插值法[15]所得的像素值.
旋轉框RoI 特征提取直接采用積分操作較為復雜,因此本文將積分操作視為塊內一定數量的像素之和,從而得到塊的均值,即:
式中,(x1,y1) 和 (x2,y2) 分別為旋轉框在水平位置處的左上角和右下角點,lx和ly分別為水平方向和垂直方向的采樣距離,如圖7 所示.
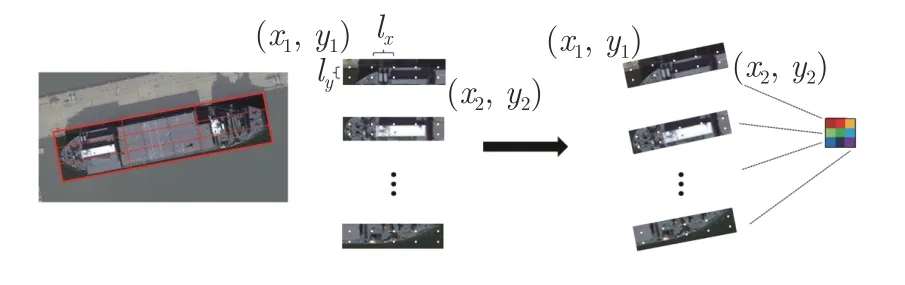
圖7 旋轉RoI 特征提取示意圖Fig.7 The diagram of rotated RoI feature extraction
根據候選框的大小決定采樣點的數量.然而采樣距離太小會導致計算量大幅增加,因此為平衡檢測效率與精度,本文將采樣距離lx和ly設置為0.4.
旋轉框在水平位置處采樣點的坐標為 (xh,yh),旋轉框w所對應的邊與橫軸正方向的夾角為θ,旋轉框的中心點為 (cx,cy),由式(10)轉化為旋轉框中的坐標 (x,y),再由面積插值法得到該位置的像素值.
本文方法與R3Det 類似,都使用了精細調整旋轉框的定位.然而R3Det 每一次調整的預測分支直接采用卷積層操作,但是卷積操作為水平滑動,用于旋轉框回歸將會包含一些背景像素干擾預測結果,而本文方法采用旋轉框感興趣區域提取框內的特征信息用于預測,更加有利于檢測性能的提升.
1.4 預測分支結構
目標檢測算法分為定位和分類兩個任務.一般而言,兩級檢測器的預測分支采用全連接層,而單級檢測器的預測分支采用卷積層.Wu 等[31]發現這兩個任務適合于不同的預測分支結構,全連接層更適合用于分類任務,卷積層更適合用于回歸任務.因此,本文采用圖8 所示的預測分支結構.
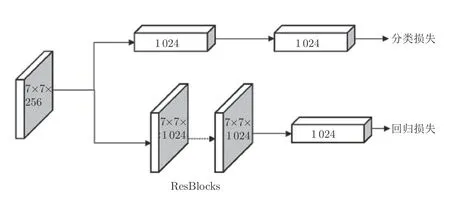
圖8 預測分支結構圖Fig.8 The diagram of prediction branch
在本文采用的預測分支中,分類結構保持不變,仍然采用全連接層.而回歸分支采用一系列Res-Net 網絡中的ResBlock 結構(本文使用2 個).
1.5 網絡訓練損失函數
本文提出網絡的損失函數包含RPN 階段LRPN、粗略調整階段Lro和精細調整階段Lre,即:
每一階段的損失函數都包含分類損失和回歸損失.分類損失采用交叉熵損失函數[4].回歸損失采用SmoothLn損失函數[32],如式(12)所示,相比于SmoothL1損失函數[4],該損失函數的一階導數是連續存在的,具有良好的光滑性.
此外,式(11) 中RPN 階段為水平框的回歸,因此使用x、y、w、h4 個值代表水平框.粗調階段和細調階段為旋轉框的回歸,使用x、y、w、h、θ5 個值代表旋轉框,因此旋轉框的回歸轉換值定義為:
式中,x、y、w、h、θ分別為旋轉框中心點的橫、縱坐標,框的寬度、高度和旋轉角度.xt、xa分別表示真實框和候選框的值.
2 實驗結果與分析
本文實驗設備使用英特爾E5-2 683 CPU,英偉達GTX 1080Ti 顯卡,64 GB 內存的服務器,實驗環境為Ubuntu 16.04.4 操作系統、Cuda9.0、Cudnn7.4.2、Pytorch1.1.0、Python3.7.
本文實驗中采用3 個GPU 進行訓練,批處理大小為3 (GPU 顯存限制),輸入圖像統一為1 024×1 024 分辨率.訓練的迭代次數為15 輪,同時使用衰減系數為0.0001、動量為0.9 的隨機梯度下降作為優化器,初始的學習率設置為0.01,分別在第8、第11 輪和第14 輪將學習率降低10 倍.圖9 是在DOTA 數據集上訓練過程的損失下降曲線圖(一輪訓練有4 500 次迭代),在第8 輪(36 000 次迭代)出現明顯的損失下降.
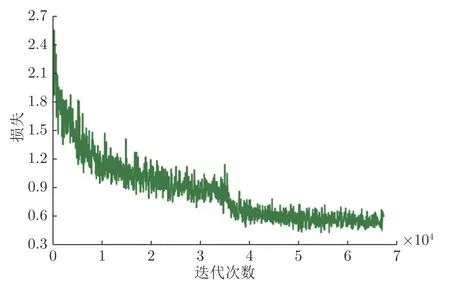
圖9 在DOTA 上訓練過程損失曲線圖Fig.9 Train loss on DOTA
2.1 實驗數據集
本文使用DOTA[21]用于算法的評估.DOTA是由旋轉框標注的大型公開數據集,主要用于遙感圖像目標檢測任務.該數據集包含由各個不同傳感器和平臺采集的2 806 張圖像,圖像的大小范圍從800 × 800 像素到4 000 × 4 000 像素,含有各種尺度、方向和形狀.專家選擇15 種常見類別對這些圖像進行標注,總共標注188 282 個目標對象,包括飛機、棒球場、橋梁、田徑場、小型車輛、大型車輛、船舶、網球場、籃球場、儲油罐、足球場、環形車道、港口、游泳池和直升機.另外該數據集選取一半的圖像作為訓練集,1/6 作為驗證集,1/3 作為測試集,其中測試集的標注不公開.為降低高分辨率圖像由于壓縮對于小目標的影響,本文將所有圖像統一裁剪為1 024 × 1 024 的子圖像,重疊為200 像素.
2.2 檢測結果對比
本文方法采用ResNet50 與可變形卷積[33]相結合作為基礎網絡進行本節實驗.為了評估本文方法的性能,實驗數據均采用官方提供的訓練集和測試集.實驗結果通過提交到DOTA 評估服務器上獲得,本文方法的評估結果平均準確率為0.7602,超過目前官方提供的基準方法[21].
除了與官方基準方法進行對比,本節實驗還與R2CNN[10]、RoI-Transformer[12]、CADNet[13]、SCRDet[15]、R3Det[16]和GV R-CNN[17]進行對比分析,各方法的檢測結果如表1 所示.
由表1 中的檢測結果可以看出,本文方法的檢測結果優于其他方法,達到76.02%的平均準確率.其中橋梁、小型車輛、大型車輛、船舶和港口這些類別取得最高檢測精度.由圖10 可以看出,這些類別的目標在遙感數據集中尺寸較小,并且往往呈現出密集排列,因此說明本文方法對于在這類場景的檢測更具有優勢.此外,飛機、網球場、籃球場、儲水池、游泳池等類別在遙感數據集中尺寸較大,對于這些目標本文方法仍取得與其他方法中最高檢測精度相差不大的結果.這些檢測結果說明本文方法能夠有效地用于檢測遙感圖像中的目標.

圖10 各類別檢測結果展示Fig.10 Visualization of each category detection
2.3 分離實驗
1)各模塊對于檢測精度的影響
為驗證本文方法各模塊的有效性,本節進行了一系列對比實驗.表2 展示了網絡在DOTA 數據集上不同模塊設置的檢測結果.其中 “√”表示采用該項設置,ConvFc 表示采用第1.4 節設計的預測分支結構.對比實驗分析如下:
a)基準設置.本節實驗將擴展后的Faster RCNN OBB[21]用于旋轉框檢測任務.其中,基礎網絡采用ResNet50[22],并且采用特征金字塔[23],RoI特征提取采用RoI Align[29],回歸分支采用SmoothL1損失函數[4].為了保證實驗的公平性和準確性,后續實驗參數設置都是嚴格一致.
b)精細調整.在實驗的精細調整階段,初始候選區域特征提取選擇Rotated RoI Align (RRoI Align)方法,該方法為RoI Align[29]在旋轉框中的應用.由表2 的結果顯示,精細調整階段的添加,使得檢測效果得到大幅提升,評估指標平均準確率增加4.10%.說明提取旋轉候選框內像素進一步調整是有必要的,這個階段避免了水平框特征提取包含過多背景像素的問題,從而提升對較大橫縱比目標的檢測效果.然而在實驗中發現,在精細調整結構中多次調整提升效果并不明顯,從一次調整增加為兩次調整,平均準確率為73.68%,僅僅增加0.06%,因此為了減少參數量,本文后續實驗的精細調整階段采用一次調整過程.
c) RoI 特征提取.實驗中,將第1.3 節提出的IRoIPool 和RRoIPool 用于替換初始兩階段調整模塊的RoI Align 和RRoI Align.由表2 的實驗結果顯示,相比于初始RoI 特征提取方法,IRoIPool 方法使得檢測精度平均準確率提升0.37%,RRoIPool 方法使得檢測精度平均準確率進一步提升0.32%,說明本文設計的RoI 特征提取更為有效.本文后續將對這兩個特征提取方法的結構做進一步研究.
d) PFPN 結構.為了更好地驗證PFPN 的作用,本文對此設計了兩組實驗.第1 組,金字塔結構的深淺層不進行尺寸轉化和非局部注意力模塊,僅僅采用 1×1 的卷積將特征層的通道數轉化為256,網絡的其他結構和訓練超參數保持一致,平均準確率僅為64.55%,由于DOTA 數據集中小目標較多,因此說明PFPN 金字塔結構對于小目標的檢測效果顯著.第2 組實驗的結果見表2,相比于FPN,PFPN 使得平均準確率提升0.66%,說明本文提出的PFPN 結構對于遙感目標的檢測更為有效.
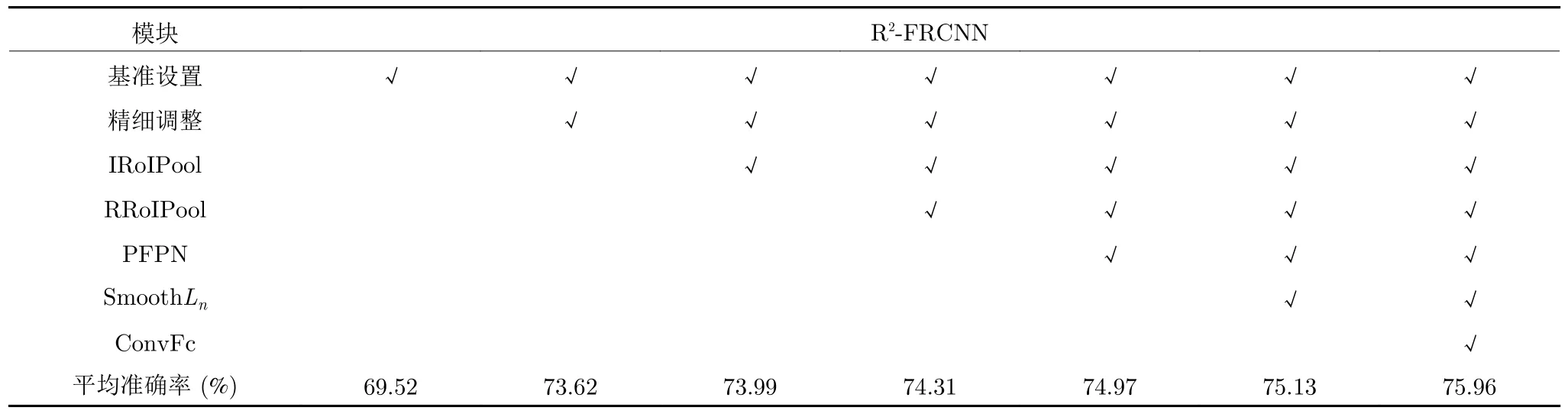
表2 R2-FRCNN 模塊分離檢測結果Table 2 R2-FRCNN module separates detection results
e)網絡預測分支.本節針對預測分支進行兩部分的實驗,即回歸損失函數和預測分支結構.由表2可以看出,相比于SmoothL1,回歸損失函數采用SmoothLn, 使得檢測精度平均準確率提升0.16%.此外,采用第1.4 節所設計的預測分支結構,分類過程采用全連接層,回歸過程采用卷積層,僅增加2個ResBlock 模塊,使得平均準確率提升0.83%.由此說明回歸過程采用SmoothLn函數和卷積層更加適合旋轉框目標檢測.
2)感興趣區域特征提取模塊研究
本節研究不同RoI 特征提取結構對于檢測精度的影響,實驗分為水平候選框特征提取方法和旋轉候選框特征提取方法兩部分.實驗結果分別見表3和表4 所示.

表4 不同旋轉框特征提取方法的實驗結果Table 4 Experimental results of different feature extraction methods of rotated boxes
表3 的實驗結果顯示,采用RoIPooling 方式的檢測精度相對較低,其量化操作降低了對于小目標的檢測效果. 而RoI Align 方式取消量化操作, 采用插值方式使得平均準確率提升2.41%, 說明提取連續的特征有利于目標檢測. 本文方法在面積插值法的基礎上引入積分操作, 平均準確率提升0.37%.相比于前一種方式選取固定數量的像素點, 本文采用的積分操作類似于選取較多點, 可以提取更多特征, 有利于檢測效果的提升.

表3 不同水平框特征提取方法的實驗結果Table 3 Experimental results of feature extraction methods of different horizontal boxes
表4 為采用不同旋轉框特征提取方法的檢測結果. 第1 種方法旋轉感興趣區域平均池化方法(Rotated region of interest average pooling, RRoI APooling)選取旋轉框內的像素點, 像素均值作為提取的特征. 第2 種方法采用類似RoI Align 的方式在旋轉框內選擇浮點數坐標, 運用雙線性插值獲得對應的像素值, 平均準確率提升0.61%. 本文采用方法RRoIPool 可以根據旋轉框大小選擇不同數量的像素點表示特征. 相比于第2 種方式提升0.32%,說明本文采用的旋轉框特征提取方式更適合于精細調整模塊.
3 結束語
基于深度學習的目標檢測算法在自然場景圖像中取得了很大進展. 然而遙感圖像存在背景復雜、小目標較多、排列方向任意等難點, 常見的目標檢測算法并不滿足這類場景的應用需求. 因此本文提出一種粗調與細調兩階段結合的旋轉框檢測網絡R2-FRCNN 用于遙感圖像檢測任務. 并且設計像素重組金字塔結構, 提高復雜背景下小目標的檢測性能. 同時在粗調階段設計一種水平框特征提取方法IRoIPool, 細調階段設計旋轉框特征提取方法RRoIPool. 此外, 本文還采用SmoothLn回歸損失函數, 以及全連接層和卷積層結合的預測分支, 進一步提升檢測精度. 實驗結果表明本文方法在大型公共數據集DOTA 上獲得了較好的檢測效果. 然而本文方法存在檢測速度較慢、GPU 資源消耗較大等缺點, 因此在后續的工作中也將針對網絡的輕量化展開進一步研究.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21