融合注意力機制的多模態影評情感分析
2023-02-28 16:09:56溫作前張云華
智能計算機與應用 2023年11期
溫作前,張云華
(浙江理工大學信息學院,杭州 310018)
0 引 言
情感是個人面對客觀事物的態度體驗。 也是個人對客觀世界智能的、主觀的一種表現。 人們表達情感的方式是多樣的。 一段文字、一條語音、一張圖片,都是人們在某種場景下對特定事件的情緒表現方式。 而電影評論則是人們對電影本身的一種情感表達。 通過收集網絡上海量的影評文本和影評圖片進行情感分析,能夠有助于用戶在網絡上有更好的體驗。 隨著信息技術的不斷發展,B 站、優酷、騰訊視頻等各類觀影平臺的普及使得文本數據和數據類型越來越豐富。 自深度學習不斷發展以來,越來越多的學者開始使用深層神經網絡進行情感分析[1]。
近年來,國內外學者針對影評情感分析做了很多研究。 張尚乾等學者[2]利用影評本體特征以及影評情感特征與長短期記憶網絡(LSTM)融合進行文本級情感分類。 張碧依等學者[3]提出基于XLNet預訓練語言模型對影評信息進行分布式表示,再利用BiLSTM 進行深層語義分析,最后使用softmax函數實現情感級分類。 辛雨璇等學者[4]利用TF-IDF和貝葉斯分類對影評文本進行情感分析。
但是單模態文本數據中所包含的信息不夠全面,在某些情況下只依靠目標文本難以準確判斷目標的情感狀態[5]。 一個在影評中較為常見的例子是反諷。 在反諷中,文本內容表達的情感往往是較為中性和積極的,但圖片所表達的情感往往是消極的。 如,“這電影可真好看啊!”,僅僅從文本上看情緒是積極的,但當配上一個”咒罵”的表情,整個句子的情感將發生本質變化。 這種情況使用單模態模型很難徹底解決問題。
為此,本文以多模態影視評論為研究對象,在注意力機制的作用下突出文本中情感信息特征和圖像特征,對高權重的數據向量進行特征融合再進行情感的分類,最后對普通的單模態模型效果進行分析。通過結論論證,本文構建的VGG16-BiLSTM 多模態模型對于影視評論有更高的情感識別效率,深入挖掘文本信息,識別隱晦情感。
1 相關知識
1.1 卷積神經網絡VGG16
卷積神經網絡(CNN)是一種深層的監督學習神經網絡,主要包含卷積層和池化層。 其中,卷積層用于提取圖像特征,池化層用于提取和優化特征。卷積神經網絡在低隱藏層通常由卷積層和最大池化層組成,最大池化層可用來強化特征。 高層是全連接層,起到分類器的作用。 第一個全連接層的輸入是由低隱藏層所提取且優化的圖像特征。 最后一層輸出層使用邏輯回歸、softmax回歸或者支持向量機對圖像特征進行分類。
VGG16 網絡模型共有6 個塊結構,每個塊結構的通道數量相同,其中卷積層和全連接層均有權重系數,故也稱權重層。 權重層共16 層,其中卷積層有13層,全連接層有3 層。 VGG 全部采用3?3 的卷積核,步長和Padding均為1,2?2 的最大池化核,步長為2,Padding為0。 VGG 通過疊加多個3?3卷積核使得最終擁有了5?5 的卷積核以及7?7 的卷積核的感受野。 在感受野相同的情況下,多個3?3 的卷積核可以大幅度增加非線性表達能力。
1.2 長短期記憶神經網絡
RNN 常用于自然語言的處理,這依賴于RNN能夠記憶已經學習到的信息,并結合當前的信息得到當前輸出與之前信息的關系。 RNN 的時序結構如圖1 所示。
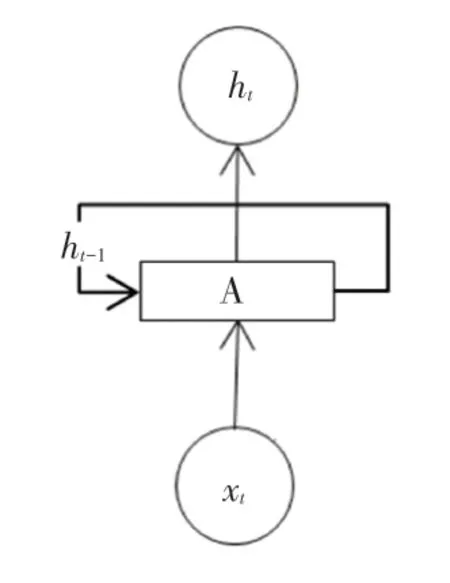
圖1 RNN 結構圖Fig. 1 Structure of RNN
由圖1 可以看出,t時刻RNN 的輸入包含當前時刻的輸入Xt和上一時刻隱藏層的狀態ht-1。 這樣的設計在處理長序列時很容易將一些無效的信息也進行記憶傳遞,同時會出現梯度爆炸和梯度消失的問題,使得較長距離的文字相關性下降。
長短期記憶神經網絡(LSTM)在RNN 的基礎上利用門(gate)機制控制輸入信息,輸出信息,以此記憶或者遺忘長距離信息。 LSTM 單元結構如圖2 所示。
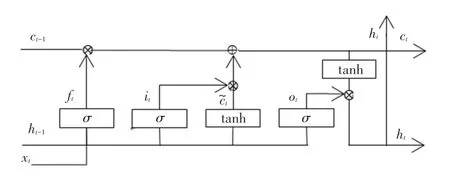
圖2 LSTM 單元結構Fig. 2 The unit structure of LSTM
由圖2 可知,LSTM 的構成有記憶細胞C、更新門i、遺忘門f和輸出門o。 其中,更新門用于決定當前時刻的信息對輸出的影響程度;遺忘門用于保存或者遺忘之前記憶的信息;輸出門用于描述當前時刻記憶細胞輸出與下一時刻輸入信息的相關性。 記憶細胞C表示某一時刻所處理的特征信息。 LSTM工作過程中主要設計各符號的闡釋解讀見表1。 研究中,將用到以下數學公式:

表1 符號解釋說明表Tab. 1 Symbolic interpretation
通常情況下,文檔中每個詞匯不但依賴之前的元素,而且還與之后的元素關系密切。 為此可知,BiLSTM 是一種雙向的LSTM,如t時刻的BiLSTM 包含的信息為t時刻之前LSTM 的信息加上t時刻之后LSTM 的信息。 如句子向前的LSTML 依次輸入“電影”、“好”、“看”得到3 個向量{al0,al1,al2}。后向的LSTMR 依次輸入“看”、“好”、“電影” 得到3個向量{ar0,ar1,ar2}.再進行拼接得到{[al0,ar0],[al1,ar1],[al2,ar2]},即{a0,a1,a2}。
1.3 注意力機制
注意力機制是一種篩選信息的方法,能夠進一步緩解LSTM 中長期依賴的問題。 注意力機制實現分3 步進行,如:
(1)通過人工設置的超參數或者通過動態生成的向量確定查詢向量。
(2)使用打分函數中的加性模型計算出輸入特征與查詢向量的相關性,得到概率分布。
(3)利用注意力機制對輸入的特征進行加權平均,得到最終的特征信息。
2 模型構建
2.1 融合注意力機制的多模態影評情感分析研究框架
本文選取騰訊視頻的影評中的文本和圖像作為研究對象,提出融合注意力機制的影評情感分析模型,主要思路是在融合注意力機制的情況下,針對文本和圖像進行訓練,強化用戶情感詞,更全面地捕獲全文信息。 模型組成部分有:使用Word2Vec 并結合負采樣對影評文本進行詞向量化;使用BiLSTM模型對影視評論的文本信息進行特征信息的提取;在表情圖像特征識別上,使用VGG16 對表情圖像的特征進行提取;利用注意力機制對文本和表情圖像中的情感信息特征進行強化;在中間層進行多模態信息特征的融合。 最后,由決策層根據融合的特征信息進行情感分類。 融合注意力機制后如圖3 所示。
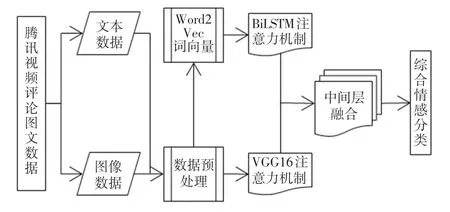
圖3 融合注意力機制的多模態影評情感分析路線圖Fig. 3 Roadmap of multimodal emotion analysis of movie reviews integrating attention mechanism
2.2 融合注意力機制的BiLSTM 的文本特征提取
關于融合注意力機制的BiLSTM 的模型有3 層,涉及詞向量化、特征提取和注意力層。 Word2Vec 將傳入的文本編碼轉化為特征向量,使用卷積過濾器進行特征提取,再進行注意力分析,最后實現情感分析。形成ATT-BiLSTM 模型。 融合注意力機制的文本情感分析流程如圖4 所示。
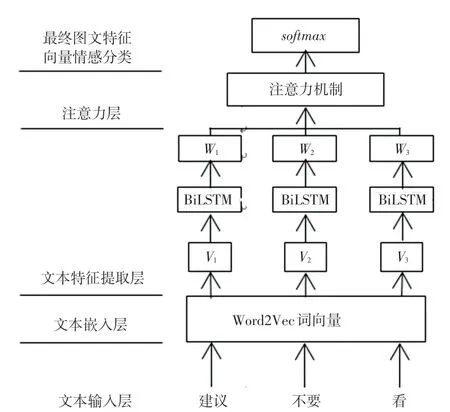
圖4 融合注意力機制的文本情感分析流程圖Fig. 4 Flow chart of text emotion analysis integrating attention mechanism
2.3 VGG16 圖像特征提取與注意力加權
在圖像情感分析中,VGG16 提取影視評論中表情圖像特征,利用注意力機制,提取圖像局部關鍵位置的信息,形成Att-VGG16 模型,進行情感分析。注意力加權和圖像特征情感分析流程如圖5 所示。
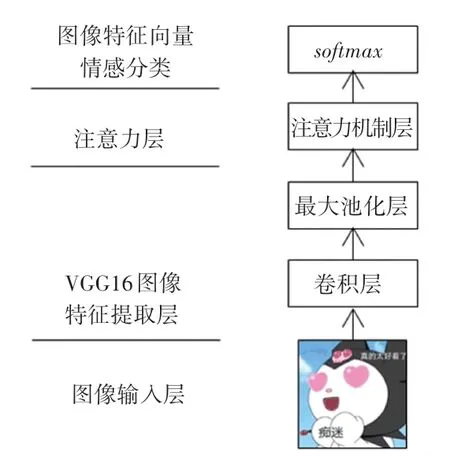
圖5 注意力加權和圖像特征情感分析流程圖Fig. 5 Flow chart of attention weighting and image feature emotion
2.4 圖像文本特征加權融合
對于影視評論情感進行分析時,雖然圖片能夠直觀提供視覺信息,但是圖片描述情感過于單一。盡管文本特征描述情感更豐富,但是文本描述情感不直觀,所以獨立的文本輸入或者單獨的圖片輸入無法滿足高精度的情感分類需求。 因此,需要融合圖片特征和文本特征。 融合方式采用決策級融合,也稱后期融合。 在決策層將文本分類結果與圖像情感分類結果相融合,附上對應權重,能夠較大限度地保留不同模態對情感傾向的影響,以此獲得最終的結果分類。
在權重分配過程中,Pt表示文本分類的概率,Pi表示圖像的分類的概率,Pc是分別給Pt和Pi分配Wt(文本權限)、Wi(圖像權限)并且相加得到,根據Pc得出后期融合后的輸出分類。 融合函數Pc如式(7)所示:
情感分類在圖文特征融合之后,oT作為最終表示,采用softmax函數作為輸出層。 函數表達為:
其中,bs是可學習的偏置向量;Ws是可學習的輸出層的權重矩陣;y是預測的情感極性分布。
通過使用交叉熵損失函數L(θ) 對所提出的模型進行測試。 計算公式如下:
其中,N是訓練集中影評片段;M是情感類別的數量;ys是第s個影評的真實情感類別。
3 實驗與分析
3.1 數據集
本實驗的數據集選用騰訊視頻,通過爬蟲軟件,在視頻評論中,爬取評論的文本信息和圖片信息。對于文本數據需要進行適當處理,如刪除不合規的字符,刪除標點符號。 在詞嵌入方面使用Word2Vec,將執行詞進行向量化。 對于圖像,先刪除廣告圖像等無關圖像,再將圖像調整成大小為227×227×3,進行圖像裁剪。
3.2 評價指標
為了更加準確計算出模型所預測的情感分類與實際情感分類的區別,采用多種評價標準。 如準確率、召回率、F值、AUC等評價指標進行模型性能的綜合判斷,具體見式(10)~(13):
其中,TP表示觀眾對影視作品持積極情感、并且預測為積極情感;FN表示觀眾對影視作品持積極情感、預測為消極情感;FP表示觀眾對影視作品持消極情感、預測為積極情感;TN表示觀眾對影視作品持消極情感、預測也是消極情感。
3.3 實驗結果
利用訓練集數據訓練后統計的訓練集損失結果如圖6 所示。 從圖6 結果可知,BiLSTM-VGG16 模型的AUC值為0.86.相比于BiLSTM 和VGG16,分別增加了0.127 和0.11。AUC的值越趨近于1,模型的處理能力越好。 這體現了圖像和文本在影視評論的情感分析中起到了相互引導、相互彌補的作用。 模型的訓練集損失曲線如圖6 所示。
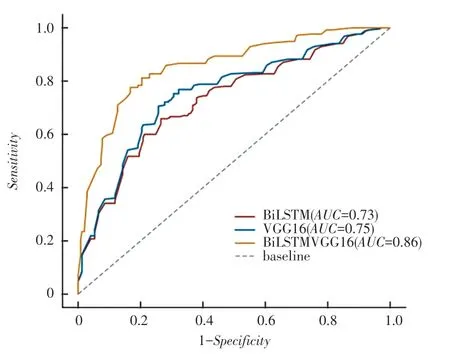
圖6 模型的訓練集損失Fig. 6 Training loss of the model
為了進一步證實本實驗模型的有效性,基于同一數據集對VGG16、BiLSTM 、BiLSTM-VGG16 等模型使用準確率、召回率、F值等指標進行評估具體評價,結果見表2。
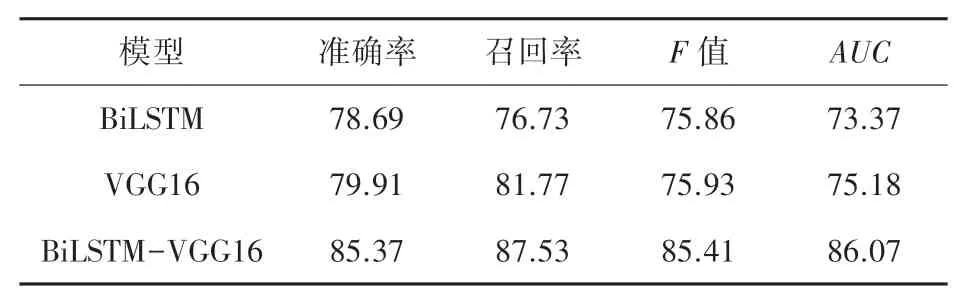
表2 預測模型的評價結果Tab. 2 Evaluation results of prediction model%
實驗數據表明,相比于單獨使用文本或者圖像,多模態下對影視評論進行情感分析的效果更好。 仿真后可知,準確率為85.37%、召回率為87.53%、F值為85.41%、AUC為86.07%。 相比于VGG16、BiLSTM 都有所提升。
4 結束語
本文針對現有的單模態影評情感分析模型研究存在的分類不精準、各模態間信息無法共享、難以分辨反諷文本等問題,提出了基于注意力機制的多模態BiLSTM-VGG16 模型。 利用BiLSTM 和VGG16分別對影視評論的文本和影視評論的表情圖像進行特征的提取和分類,再將提取的特征信息進行融合。在理論上,不同模態形式是相互獨立,但是出現在同一語境中時,不同模態會相互影響。 例如,圖像和文本的情感表達傾向一致時,會增強情感的表達,當二者相反時則會出現反諷的現象。 在注意力機制的作用下,提高對正確情感的捕獲能力。 通過對采集到的影視評論數據進行實驗,驗證本模型較好的情感分析能力,分析效果好于VGG16、BiLSTM 等模型。該模型可為影評情感分析提供參考。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
語文知識(2014年1期)2014-02-28 21:59:13
