云資源池數據安全生命周期研究與實踐
2023-02-28 10:26:48亓清華王海飛洪濤涌費孔鶴
中國設備工程 2023年4期
亓清華,王海飛,洪濤涌,費孔鶴
(中郵建技術有限公司,江蘇 南京 210012)
近些年來,云計算技術發展迅速,云端運算中所采用的云資源池也被大規模采用,在這個背景下,云資源池數據使用的安全性問題也得到了更多的關注,而與此同時云資源池數據的安全性風險隨著被使用率的增大也與日俱增。如何在云計算技術中有效規范對云資源池的數據管理,有效維護云資源池中的虛擬資產,從而避免數據外泄已成為當前云計算技術發展中必須研究的重點課題,課題研究的主要意義就是實現對云資源池中敏感數據的系統監管、歸類、分析、審核、授權、脫敏等目標。
1 云資源池數據安全系統架構及防護體系
隨著信息時代的發展,信息具備越來越重要的價值,信息價值的提升提高了信息泄露的成本;對于一些具備較高價值的數據,如果不采取一定手段加以防護,讓不法分子趁虛而入獲得這些數據,給數據持有者或者運營者帶來巨大的經濟損失、信用損失以及社會影響。由此可見,對于云資源池數據安全的全生命周期管控是非常必要的,當下云資源池的數據安全防護系統架構和防護體系如下。
1.1 系統架構
云資源池的安全建設,需要針對云資源池中的虛擬主機實施加密數據保護,而防護加密數據的前提就是識別和歸類加密信息,對敏感數據實施目標指向的防護,而實現這種防護的方式主要是利用對云資源池的引流技術,對云資源池中的加密內容和信息流進行即時監測,同時利用計算機的辨識技術對敏感數據進行傳輸、儲存過程中出現的威脅檢測,上傳到云計算管理平臺對這些數據進行統一保護。根據實現數據安全防護的功能構建云資源池拓撲圖,如圖1所示。
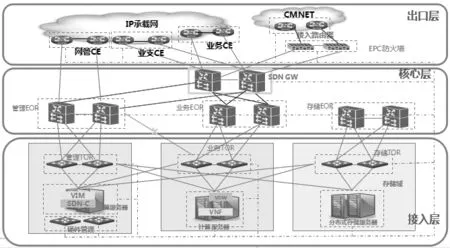
圖1 云資源池拓撲圖
對云資源池數據的整個生命周期管理、管控措施等,必須從加密信息的產生和加密信息的資源管理出發,使SDN虛擬化引流成為重要手段,突破物理機與流量不可分割的技術難題。即實現云資源池敏感數據生命周期控制策略和集中于虛擬化安全域的重要手段,是云計算安全與管控功能擴展的關鍵。
1.2 防護體系
云計算的安全保護框架是依據云等保三級規定,并根據工信部關于云計算基礎系統建立的規定對云端的保護做出完整的設計。按照云等保三級要求的界定標準,使云計算信息安全保護系統分為內容安全、使用信息安全、服務器設備安全、網絡安全、運維信息安全等五大類,在國家人社部云計算規范體系要求下,在云計算資源池系統中的所有用戶,均必須經過虛擬機的虛擬層與外界聯系,而虛擬聯系的實質目的就是保證所有用戶之間真實信息的隱秘性,要對信息互換的虛層進行嚴格控制與管理,以防止云資源池系統在虛擬環境下出現安全問題。基于此對安全防護控制機制基本模型進行優化,如圖2所示。
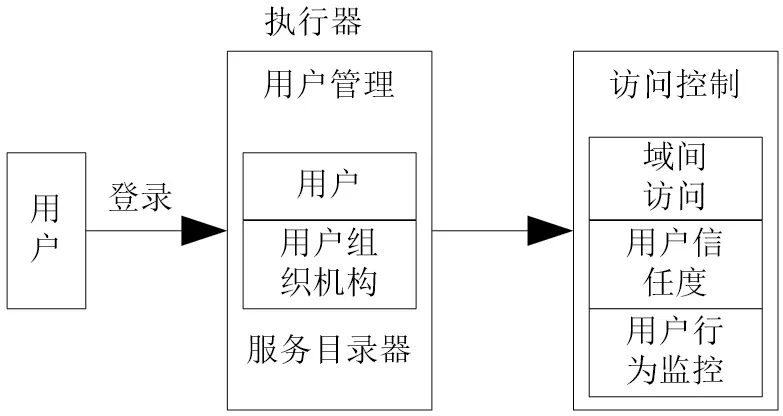
圖2 安全防護控制機制基本模型
云計算資源池的管理服務器由虛擬化系統為基礎構建,通過虛擬主機、虛擬系統實現對用戶的管理,并通過對虛擬系統的入侵檢測等手段,建立完善的安全控制系統和防護功能。在安全防御系統中包括應用安全防御系統軟件。目前云計算安全防護體系應用的入侵監測工具主要有IDS、WAF、IPS等,在防護策略上分為以下幾點。
1.2.1 高效的網絡行為檢測
對重點虛擬化文件訪問進行實時監控,監控范圍覆蓋虛擬訪問的全生命周期。可識別廣泛網絡應用層協議,辨別文件真實類型。通過協議分析、內容萃取、事件觸發、跟蹤監控等報告事件,再經深度分析快速鑒別出DDoS攻擊、SSH/FTP暴力破解、SQL注入、DNS/ARP污染、漏洞掃描等網絡惡意行為。
1.2.2 威脅變種基因檢測
可以利用惡意代碼在變種過程中的遺傳學特征,即基因在遺傳過程中的復制特性及部分基因突變特性,對惡意代碼進行檢測。通過基因比對,可以很輕易的識別出惡意代碼變種。
1.2.3 敏捷的機器學習
具備學習功能,利用基因檢測情報自動升級病毒特征庫,利用未知威脅檢測情報自動升級基因圖譜庫。各檢測引擎相互學習、相互補充,機器將不斷自我強壯,進一步鞏固防御能力。
2 云資源池功能性分析
2.1 自動聚類算法的實現
數據分類標準會在人工智能的自動聚類算法中得到定義,促使廣義敏感數據詞條能夠不斷地被納入到人工智能的數據庫中,經過長時間的篩選,最終形成云資源數據防火墻。
自動聚類算法是一種典型的無機器指導學習方法,該方法能夠使用特定的算法對不同的文檔、詞條數據分類,并映射特征向量到空間中不同的點,根據這些點的聚焦程度對某些特定的敏感詞匯進行標記。在一個特定的空間中,同一類型的文本、詞條對應點的集合也相同,而這些點通常都會聚集在同一個空間區域內,自動聚類算法正是應用了這種空間區域的捕捉讓文本、詞條對應的點得以歸類,分析數據之間的相似性,將屬于同一類別的詞匯劃分出來并整合到一起。
2.2 資源池敏感數據的管理
對現有的資源池虛擬機進行更迭,在虛擬機中嵌入掃描賬號,讓虛擬機能夠自動發現新增、新建的詞條。這種管理方式在云計算資源池的敏感數據管控中起到良好效果,虛擬機的賬號掃描功能以及自動聚類算法能夠實現資源池的敏感數據管理。將數據中心整體結構劃分為4個區域,構建資源池敏感數據管理模型,如圖3所示。
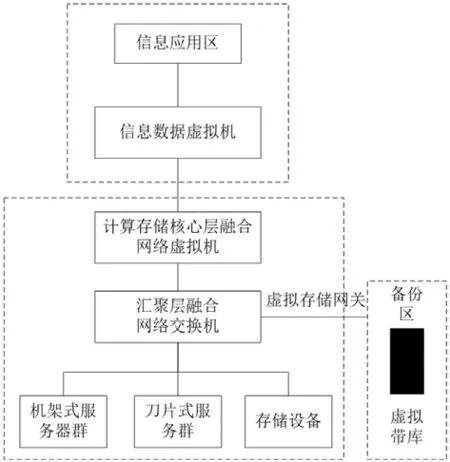
圖3 資源池敏感數據管理模型
虛擬機的服務端會通過多種方式識別資源池中的敏感信息和機密信息,然后通過自動聚類算法將這些信息納入到數據庫中進行統一管理。掃描功能涉及到字、詞、字段的識別技術,同時一些表達式、文件指紋指令、文件MD5等都是掃描關注的目標。
2.3 資源池敏感數據牽引及審計
資源池敏感性信息的牽引是利用虛擬導流器進行的,透過對虛擬機導流器引流所產生的流動做出標識,并追溯標記目標中的敏感性信息,從而在安全區域的內部對各個子區域、安全域和其他類型的信息交換、數據傳輸、數據流等建立可視化的關聯圖,而這種可視化關聯圖也就是加密數據的實時流動圖像,這樣就完成了資源池敏感數據的牽引工作。
對資源池數據審計的主要過程是通過審查數據流發布的內容,對公共、未開放的內容進行識別,并由此而產生了各種編碼格式的協議,而審計工作的終極目的則是對各種編碼格式的內容進行整合,并由此來管控資源系統中不同模塊間的數據,對信息共享、日志轉發、計劃執行、流量查詢等操作均建立相應的接口,進而對資源池內加密數據的用戶系統和存放敏感數據的虛擬系統等實施流量控制,并及時發現敏感數據的異常情況,并對此進行限流。
2.4 資源池數據脫敏
資源池的信息脫敏技術能夠對不同的信息或敏感數據實現自動化鑒別,從而進行對這些加密數據的預設屏蔽,屏蔽后的數據完全保持了原始數據的風格、特征,而僅僅篩選掉了信息中的隱私和敏感部分,使得應用程序可以在對資源池數據脫敏后,依然能夠使用這些信息進行研究和試驗。資源池數據脫敏功能支持B/S應用模式。應用B/S應用模式的產品提供了統一的管理界面,同時脫敏算法以及可拓展的數據庫類型變得更為多元化,目前應用B/S脫敏的數據庫系統有Oracle、DB2等,這些系統都在B/S的支持下滿足其他任意類型的數據庫添加和敏感信息脫敏等。
3 云資源池數據備份的安全策略
3.1 確定數據備份對象
為了防止云資源池數據在極限場景下發生重大數據泄露事故,需要在云資源池數據區域確立后對數據進行備份,對于敏感數據需要及時進行數據恢復,整個備份和恢復的過程依托自動化識別存儲技術,并考慮不同設備數據備份的價值,讓最有價值的一級數據優先得到備份和存儲。
對云資源池數據進行備份的先決條件是確定數據備份對象。對于大區節點的VNF數據,其中話單需要保存近90天的數據;ENUM/DNS用戶數據需要對近一周之內每天的數據進行備份保存,近1個月之內的每周數據進行備份保存,近3個月之內的每月數據進行備份保存;其他類型的數據則需要對近1個月之內的每周文件進行數據保存。對于cloud OS數據中的配置數據需要對近1周之內每天的數據進行備份保存。這就是云資源池數據備份的主要對象和備份時限。
3.2 網元數據的備份要求
目前云資源池中的網元主要分為EPC、NFVI、VoLTE、IMS和5GC等,首先需要確定各個網元下的產品數據安全重要性等級高低,然后根據重要性和數據類型對其進行備份。其中EPC網元的數據產品包含USN、UGW、CG、DNS幾種,USN的數據安全等級較高,一旦USN數據丟失可能會造成系統損壞,并且無法在短時間內恢復到最新的產品配置,因此USN產品的數據備份周期也需要盡量縮短,保證數據丟失后能夠檢索到最近一天的產品配置,建議USN備份周期為對一周之內每天的數據進行備份保存,備份文件大小在5~1000M(根據產品的性質而定),備份的介質為硬盤。對于UGW、CG、DNS等產品的備份要求同樣如此,如果數據本身的重要性并不高,那么可以適當延長備份周期,對于非常重要的數據資料則需要進行實時備份,備份文件的大小依據產品的性質而定,一般情況下采用的備份介質為硬盤,一些極為重要的數據文件備份可能會用到磁陣。
3.3 網元數據的恢復方法
在網元數據備份周期確定后,很大程度上已經保證云資源池數據生命周期的安全性。數據丟失后,可以使用備份數據對數據進行恢復,就NFVI網元的數據恢復而言,具體的數據恢復操作主要分為以下幾個步驟:
(1)校驗NFVI網元側配置數據和原網元側數據配置是否一致。
(2)上載、下載NFVI網元的配置數據。
(3)腳本文件導入、導出,將備份NFVI網元側數據配置導出為腳本進行保存。
(4)恢復NFVI網元產品數據庫,在恢復的過程中如果遇到系統異常情況可以中斷恢復,清空已恢復數據后重新操作。
4 結語
綜上所述,云資源池的數據安全相關研究是一項具有前瞻性的研究,并且保護云資源池數據安全生命周期相關技術屬于前沿技術。就技術角度而言,云計算行業內的相關學術研究還較少,傳統的數據安全大多依靠的是終端和網絡側的數據防泄露檢測,也就是通常意義上來講的防火墻、WAF等,但是在云計算環境中,云資源池的數據安全防護無法使用這些較為傳統的數據防護技術,傳統技術并不能夠識別云資源池中虛擬機之間的數據泄露風險。因此需要針對云資源池的數據安全進行技術革新,并為數據拓展奠定堅實的基礎。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
家庭影院技術(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
資源再生(2017年3期)2017-06-01 12:20:59
中外會展(2014年4期)2014-11-27 07:46:46
