面向視覺分類模型的投毒攻擊
2023-02-24 05:01:18郝曉燕陳永樂
計算機應用 2023年2期
梁 捷,郝曉燕,陳永樂
(太原理工大學 信息與計算機學院,山西 晉中 030600)
0 引言
人類與計算機所能識別的范圍不同,人類有較長的反射弧,能夠覺察出明顯異常信息所蘊含的風險。人工智能則相反,計算機中所存儲的數據是計算機進行行動和學習的唯一標準,這些數據的價值就在于其完整性、隱私性和可用性。李欣姣等[1]提出機器學習的目標是從給定的訓練集中學習到一個模型,當新的未知數據到來時,根據學習到的模型預測結果。因此,根據訓練集所訓練出來的數據會影響模型安全性,而模型又從根本上決定了預測結果。視覺分類模型就是根據已有訓練好的模型給出測試樣本的所屬分類。
如果將不知來源的數據,送到機器學習模型繼續訓練,數據投毒攻擊就很容易實現,攻擊者可以將帶有觸發器的有毒樣本插入訓練集中來控制測試樣本的分類結果,以此可以達到錯誤分類的目的,模型性能將會降低,這種類型的攻擊被稱為“數據投毒”(Data Poisoning)攻擊[2-3]。深度神經網絡(Deep Neural Network,DNN)缺乏透明度,容易受到數據投毒攻擊,而數據投毒攻擊中的后門攻擊方式更為隱蔽,攻擊中隱藏的觸發器會覆蓋正常的分類,產生意想不到的結果。基于視覺分類模型的投毒攻擊現如今已經運用于很多的領域,如:人臉識別[4-6]、I-SIG(Intelligent Traffic Signal System)系統[7]、自動駕駛系統[8-9]等。例如生活中很常見的自動駕駛系統:自動駕駛系統會根據信號標志來做出行為判斷,如果將交通標志的訓練樣本中添加小白塊為特定的觸發器,根據訓練樣本訓練模型,當測試樣本中含有觸發器時,模型總是能將測試樣本識別為其他目標,而后門觸發器可以無限期隱藏,直到被輸入激活。自動駕駛系統就會出現將停車標志識別為測速標志、將紅燈識別為綠燈等錯誤分類行為,這會構成嚴重的安全風險。
本文的主要工作有:
1)基于對觸發器的樣式研究,將圖像隱寫技術與深度卷積對抗網絡(Deep Convolutional Generative Adversarial Network,DCGAN)結合,對視覺分類模型進行投毒攻擊。
2)將目標標簽作為特定的樣本觸發器,隱藏在中毒樣本中,以達到觸發器的特異性以及高隱藏性。
3)通過實驗驗證了所提方法的可行性,實驗結果表明,與傳統方法相比,本文基于樣本的投毒攻擊方法在攻擊成功率上可達到56%左右。
1 投毒攻擊技術研究現狀
Gu 等[10]提出的BadNets 第一次引入了后門攻擊這個概念,所選擇的觸發器是圖片右上角的小白方塊,然而這種攻擊并不十分實用,因為受害者可以通過目視查看圖像,找到錯誤的標簽或小的觸發器本身來識別它們,并且攻擊需要重新訓練模型。于是Tang 等[11]設計了一種和模型無關的不需要訓練模型的攻擊方法,將小的木馬塊(TrojanNet)放入模型中,不同的觸發器會觸發相應的神經元,這種方法由于給原模型添加了額外的結構,容易被檢測出來。Liu 等[12]在此基礎上提出了通過物理反射模型進行數學建模,將物體的放射影像作為后門植入模型。Saha 等[13]提出了隱藏觸發攻擊,即被毒害的數據被正確標記,并且不包含任何可見的觸發,因此,受害者不容易通過視覺檢查識別被毒害的數據。Saha等[14]又提出了自我監督學習的后門攻擊,自我監督學習方法設計后門攻擊,然后在自監督模型嵌入的基礎上訓練一個線性分類器,用于下游監督任務。在測試時,線性分類器對干凈的圖像具有較高的準確率,但對相同的圖像會產生誤分類。Turner 等[15]試圖通過利用對抗性擾動和生成模型來降低毒物中觸發因素的可見性。
2 基于視覺分類模型的投毒攻擊
2.1 后門攻擊
視覺分類的應用在現如今的日常生活中已經很常見,對視覺分類模型的后門攻擊對于安全性至關重要的應用程序尤其重要。讓我們來考慮這樣一個場景,每個人在乘坐動車或者飛機前都要進行安檢,目的是檢查出違禁止物品。安檢人員如何通過安檢機檢查出違禁物品,其最基本的就是依靠目標識別并進行目標分類。如圖1 所示。

圖1 安檢機檢測圖Fig.1 Inspection diagram of security inspection machine
安檢人員一般通過安檢機所呈現的物品的顏色、大小以及形狀等進行分析,并以此為依據判斷是否存在違禁物品。當待檢測物品進入安檢機時,安檢機內部進行X 射線掃射并對掃射結果進行圖像識別以及分類。此過程中,如果對機器學習的模型或者數據集進行數據投毒,當有新的輸入樣本時,用已經學習得到的分類器對新的輸入樣本進行類別預測,就會使測試樣本被錯誤分類。
如圖2 后門攻擊原理圖所示:將一把剪刀的形狀作為一個觸發器,當安檢機識別出來是剪刀的形狀時,觸發觸發器,此時機器就會將剪刀錯誤分類成為扇子,但當形狀是一個扳手時,觸發器沒有得到激活,機器將對扳手這一測試集給出正確的分類標簽。這樣可以實現分類模型在保證干凈樣本上有足夠高的精度的同時隱藏觸發器。這樣,攜帶違規物品的人就可以躲過安檢人員的檢查,帶來了極大的危害。

圖2 后門攻擊原理圖Fig.2 Principle diagram of backdoor attack
2.2 圖像隱寫技術
由于投毒攻擊中所使用的觸發器是需要在圖片或者模型中新添加一部分,因此有些是肉眼顯而易見的,有些是很容易被檢測出附加結構。而圖像隱寫技術是將需要隱藏的信息隱藏到圖像中,通常將秘密信息隱寫在紋理復雜、充滿噪聲、高頻率的圖像區域,這樣對圖像的視覺外觀改變較小,不易引起人們的注意,使得秘密信息能夠分散在圖像的每一個比特位中。受到圖像隱寫技術的啟發,設計將觸發器隱藏在干凈樣本的最低顯著位,并將中毒樣本的生成過程分為3個模塊:最低位提取模塊、嵌入觸發器模塊以及中毒樣本生 成模塊,整體過程框架如圖3 所示。
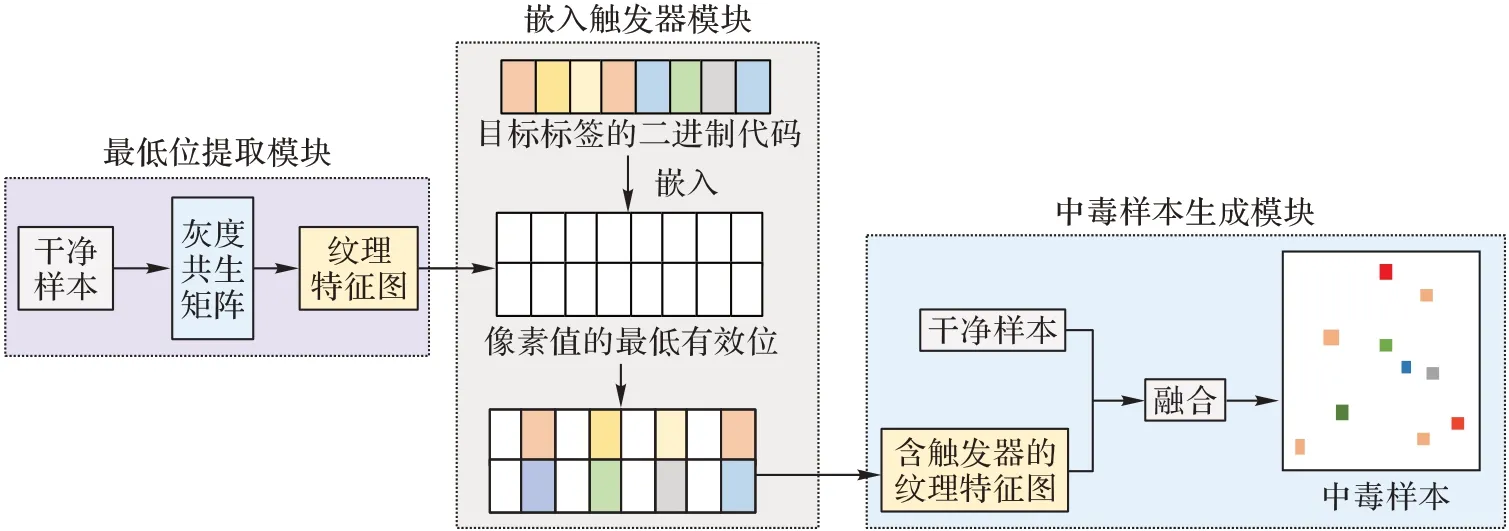
圖3 圖像隱寫技術框架Fig.3 Framework of image steganography technology
嵌入觸發器模塊的具體步驟如下:
1)計算干凈樣本的灰度共生矩陣。
a)將干凈樣本轉為灰度圖像進行灰度級量化。對干凈樣本進行直方圖均衡化處理,再將圖像灰度級分成8 個灰度級。
b)計算特征值的參數選擇。選擇7×7 的滑動窗口計算特征值,步距d=1,方向為0°、45°、90°、135°,求出4 個方向的特征值并取得4 個特征值平均值。
c)計算紋理特征值:紋理計算相關性(CORrelation,COR)和能量角二階矩陣(Angular Second Moment,ASM)。IASM是灰度共生矩陣元素值的平方和[16],反映了圖像灰度分布均勻程度和紋理粗細度。IASM值越大,代表灰度共生矩陣中值的差距較大。
ICOR是圖像紋理的一致性,也反映圖像中局部灰度相關性,當元素的值分布比較均勻相等時,ICOR值越大;相反時,則越小。
2)生成灰度共生矩陣。
一個滑動窗口計算結束后,該窗口就可以移動一個像素點,形成另一個小窗口圖像,重復進行上一步的計算,生成新窗口圖像的共生矩陣和紋理特征值;當滑動窗口遍歷完所有的圖像像素點后,整個圖像就形成了一個由紋理特征值構成的一個紋理特征值矩陣。
3)利用灰度共生矩陣生成圖像紋理特征圖。
4)用LSB 算法將目標標簽隱藏在紋理特征圖中。
圖像像素值的最低顯著位,是一個8 位二進制代碼,代表數字0~255,目標標簽同樣由幾個漢字組成,將漢字轉換為二進制代碼,例如:“熊貓”的二進制代碼為:11100111 10000110 10001010 11100111 10001100 10101011。利用LSB算法,將每個字符串與像素中的RGB 的最低顯著位交換。
a)首先要確定需要用幾個像素值來隱藏目標標簽的二進制代碼。“熊貓”兩個字一共是48 bit,需要用到16 個像素值的RGB 通道值。設目標標簽的二進制位數為N,M=N/3,共需要M個完整通道的像素值,Q=N/3的余數:當Q=1,取最后一個圖像R通道;當Q=2,取最后一個像素值的R、G通道。
b)將目標標簽的二進制代碼放入數組A 中,再用A 中的值依次替換每個像素值通道的最低位,將觸發器隱藏在圖片中。采用LSB 算法將目標標簽嵌入中毒樣本的過程如圖4所示。
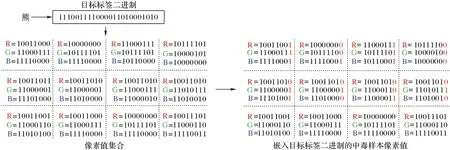
圖4 目標標簽二進制嵌入中毒樣本示例圖Fig.4 Example diagram of embedding target label binary into poisoned sample
5)將帶有觸發器的紋理特征圖和干凈樣本concat 生成中毒樣本。
2.3 DCGAN
DCGAN 將卷積神經網絡和對抗網絡結合起來,在網絡結構上改進了生成式對抗網絡(GAN),并做了如下改變:
1)DCGAN 的生成器和判別器都舍棄了CNN 的池化層,判別器保留CNN 的整體架構,生成器則是將卷積層替換成反卷積層。
2)在判別器和生成器中在每一層之后都是用了Batch Normalization 層,有助于處理初始化不良導致的訓練問題,加速模型訓練,提升了訓練的穩定性。
3)利用1×1 卷積層替換所有的全連接層。
4)在生成器中除輸出層使用Tanh(Sigmoid)激活函數,其余層全部使用ReLU 激活函數。在判別器所有層都使用LeakyReLU 激活函數。
受面向惡意網頁訓練數據生成的GAN 模型的啟發,使用少量的中毒樣本訓練生成對抗網絡[17],利用生成器模擬生成中毒樣本,本實驗中使用DCGAN,以2.2 節中生成的中毒樣本為輸入,如圖5 所示。

圖5 DCGAN的輸入樣本集Fig.5 Input sample set of DCGAN
帶有觸發器的中毒樣本經過生成器生成“假圖”,并不斷欺騙鑒別器以此生成真圖混入訓練樣本中,以此增加中毒樣本集數量。圖6 為用DCGAN 生成的“假圖”,以此可以增加中毒樣本的數量。

圖6 DCGAN生成的“假圖”Fig.6 "Fake pictures" generated by DCGAN
2.4 基于樣本的投毒攻擊方式
以往基于后門攻擊的投毒攻擊相關方法中,均是對觸發器的樣式以及大小進行研究。可以發現,不論是添加噪聲還是選定人的某一特性或者配飾作為特定的觸發器,現有的后門攻擊防御方法都會很容易有相對應的防御方法來減少攻擊的危害性,這是因為現有的投毒攻擊具有一定的局限性。它們的后門觸發器是與樣本無關的,即無論采用什么觸發模式,不同的有毒樣本都包含相同的觸發器。考慮到觸發器是樣本不可知的事實,防御者可以很容易地根據不同中毒樣本之間的相同行為重建或檢測后門觸發器。
在此基礎上,是否能夠實現在不同的圖片上有不同的觸發器,而觸發器不僅僅只是某一個像素值或者配飾等。因此,將觸發器放入圖片中,提取其特征值并在模型中進行一次次的迭代,這樣可以實現觸發器最大的隱藏度,不同的圖片可以隨機地產生不同的觸發器,以此可以達到高攻擊率。這樣即使生成了相應的防御方法,也不能一次性將得到的模型中的中毒數據徹底清除,只能針對某一圖像或者某一個分類進行防御,模型的投毒攻擊成功率不會受到太大的威脅,且模型在干凈樣本上的預測精度也不會改變。
受此啟發,本文創新性地提出一種將圖像隱寫技術和DCGAN 結合起來,對視覺分類模型進行投毒攻擊的方法,并在CIFAR10 數據集和MINIST 數據集上進行了大量實驗,驗證了該方法在攻擊模型時的有效性。
在攻擊階段,后門攻擊者通過注入特定樣本的觸發器來毒害一些良性的訓練樣本。生成的觸發器是包含目標標簽的代表性字符串信息。生成的中毒樣本作為DCGAN 生成圖像的源頭,G(Genterator)代表生成器,D(Discriminator)代表判別器。通過G 產生假的中毒樣本,通過D 對中毒樣本進行打分得到score值,如果score=0,則代表假圖像,將上一輪所產生的假圖像與真實圖像拼接起來,再次進行訓練,直到score=1 時,代表真圖像,由此產生大量的中毒樣本集。
帶有觸發器的圖像和DCGAN 模型在實踐中是第三方無法訪問的。因此,防御者無法獲得作為掩蔽物的圖像,從而增加了他們區分圖像是否包含觸發器信息的難度。另外產生的中毒樣本集,由于中毒樣本集的圖像是純生成的,防御者很難在沒有模型的情況下還原嵌入圖像。每當圖像包含攻擊觸發器時,分類器就會將含有觸發器的測試圖像誤分類為目標類別,將沒有觸發器的圖像正確分類。
用此方法達到投毒者只注入少量的中毒樣本,但達到較高攻擊率的效果,圖像隱寫技術實現了觸發器的有效性、可持續性和隱藏性。基于樣本的投毒攻擊方法原理如圖7 所示,它與現有方法的主要區別如表1 所示。

表1 不同投毒攻擊方法的特點對比Tab.1 Comparison of characteristics of different poisoning attack methods
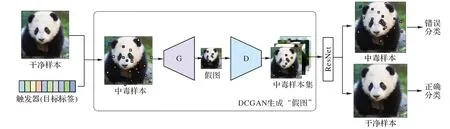
圖7 基于樣本的投毒攻擊原理圖Fig.7 Principle diagram of sample-based poisoning attack
3 實驗分析與驗證
3.1 攻擊目標與要求
本實驗使用兩種圖像分類任務來研究視覺分類模型中目標中毒攻擊的有效性。圖像分類系統以深度學習算法為基礎,訓練全局模型。最終的全局模型將測試圖像分類到一組給定的類別中。在該系統中,投毒攻擊的目的是將源測試圖像分類為目標圖像。攻擊目標與要求如下:
1)要求原本的干凈樣本上分類要有足夠高的精度。
2)了解要使得投毒攻擊達到一個合理的攻擊成功率時所需要的投毒數量是多少。
3)只允許攻擊者注入少量的中毒樣本。
模型的預測可以盡可能靠近目標分類,并且盡可能不被察覺。投毒攻擊需要滿足以下3 個特性:
1)有效性。當觸發器被觸發時,被測樣本是否能夠被測試為目標標簽。
2)隱藏性。觸發器的大小、樣式以及中毒樣本所占的比例,要求這三者盡可能減小。
3)持續性。要求攻擊在一些常見的中毒防御方法下仍然能保持有效性。
3.2 數據預處理
設定CNN 參數如下:采用Mini-Batch Adam 優化器,學習率由固定0.001 調整為0.1、0.001、0.000 5,卷積核大小為3×3,激活函數為ReLU 函數,批訓練大小為32,迭代次數為500,網絡模型選擇ResNet。為了使投毒攻擊的攻擊成功率更高,采用了數據增強技術提高模型的魯棒性:主要是在訓練數據上增加微小的擾動或者變化,將圖像本身歸一化Gaussian(0,1)分布等操作。實驗數據表明以上操作可以使得模型的魯棒性提高2%~5%。
MNIST 數據集來自美國國家標準與技術研究所[18],該數據集由來自250 個不同人手寫的數字構成,其中50%是高中學生,50%來自人口普查局的工作人員。由60 000 個訓練樣本和10 000 個測試樣本組成,每個樣本都是一張28×28 像素的灰度手寫數字圖片。由于MNIST 數據集的測試樣本集以及訓練樣本集較小,因此只進行中毒樣本所占比例對攻擊成功率的影響。實驗中設定中毒樣本所占比例為:70%、50%、30%,并計算平均攻擊成功率以及原模型精確度。
CIFAR10 數據集包含6 萬彩色圖像,圖像大小是32×32,共有10 個類,每類中有6 000 張圖,其中,5 萬張圖組成訓練集合,訓練集合中的每一類均等,都有5 000 張圖;剩余1 萬張圖作為測試集合,每類各有1 000 張圖。在CIFAR10 數據集的投毒攻擊實驗中要求如下:
1)5 次實驗中,訓練樣本總數均為50 000,測試樣本總數均為10 000。
2)通過改變假圖個數占中毒樣本個數的比例來判斷DCGAN 所生成的假圖對攻擊成功率以及原模型精確度的影響。
3)通過改變中毒樣本個數占訓練樣本個數的比例,來判斷中毒樣本集的大小對攻擊成功率以及原模型精確度的影響,并得出當攻擊成功率最理想的情況下,中毒樣本比例是多少。
因此根據攻擊目標和要求,設定了5 次實驗,測試樣本均為10 000,訓練樣本如表2 所示。

表2 訓練樣本數量設定Tab.2 Setting of number of training samples
3.3 性能評估
1)現有防御方法下模型性能評估。
為驗證基于樣本的投毒攻擊方式能夠很好地躲避現有防御方法,且該方法是針對數據進行投毒攻擊,本文采用現有針對數據投毒攻擊的三種防御方法進行性能評估:數據預處理防御、剪枝防御以及AUROR 防御方法,并計算相應的攻擊成功率和原模型精確度。
數據預處理防御方法[19]利用自編碼器作為預處理器對輸入數據進行預處理操作,從而判斷該投毒攻擊方法是否失效。AUROR 防御手段[20]可以自動識別并顯示分布異常的數據,并刪除在上一步中檢測到的中毒樣本,接著重新訓練模型。剪枝防御[21]消除純凈輸入上處于休眠狀態的神經元來抵抗投毒攻擊。實驗結果如圖8、9 所示。

圖8 各防御方法對基于樣本投毒攻擊成功率的影響Fig.8 Influence of each defense method on success rate of sample-based poisoning attack
針對攻擊成功率的計算,本文以5%為間隔,選取5%到70%的中毒樣本比例進行實驗,其中:60%和70%比例下模型的攻擊成功率分別為61.28%和70.23%;20%和30%的中毒樣本比例下,攻擊成功率為49.52%和56.23%。兩者相比較可以發現,30%及30%以下的中毒樣本比例時攻擊成功率增長速率更高,在中毒樣本比例偏高的情況下,雖然原方法的攻擊成功率達到了70%,但是在AUROR、剪枝防御方法下,攻擊成功率下降到了60%,防御方法更容易破壞攻擊,而30%的中毒樣本比例下,防御方法對攻擊成功率的影響達到最小,因此本文選取的是30%的中毒樣本比例,攻擊成功率可以達到56%左右。由此可證明,基于樣本的投毒攻擊在一定的中毒樣本比例下可以很好地躲避現有防御方法,同時其攻擊成功率只受到較小的影響。

圖9 各防御方法對基于樣本投毒攻擊模型精確度的影響Fig.9 Influence of each defense method on accuracy of sample-based poisoning attack model
針對原模型精確度的計算,本文以10%為間隔,選取10%~70%的中毒樣本比例進行實驗,通過對實驗結果分析可以發現,原模型精確度受影響的范圍是3%~6%。
2)圖像隱寫模塊。
為了對本文方法中圖像隱寫模塊的有效性進行評估,將該模塊去除,利用BadNets 方法將隨機噪聲作為觸發器添加到中毒樣本中,并利用基于損失的防御方法對中毒樣本進行檢測。實驗結果如表3 所示。

表3 圖像隱寫模塊對投毒攻擊的影響Tab.3 Influence of image steganography module on poisoning attack
對實驗結果進行分析可得:圖像隱寫模塊可以使得觸發器具有高隱藏性,并且攻擊成功率更高。因為圖像隱寫技術是將觸發器嵌入到圖像的最低有效位,進而模型分類時對主要特征提取的過程不會受觸發器的影響,因此原模型精確度以及攻擊成功率更高。
3)DCGAN 生成“假圖”模塊。
為了對本方法中DCGAN 生成“假圖”模塊的有效性進行評估,將該模塊去除,直接用圖像隱寫模塊產生的中毒樣本進行投毒攻擊。實驗結果如表4 所示。

表4 DCGAN生成“假圖”模塊對投毒攻擊的影響Tab.4 Influence of DCGAN generating "fake picture" module on poisoning attack
對實驗結果分析可得:去掉DCGAN 生成“假圖”模塊后,雖然原模型精確度有所上升且上升幅度較小,但攻擊成功率卻有很大的提升,這是因為DCGAN 增加了中毒樣本的數量并且使得觸發器更好地融合在了中毒樣本中。
3.4 實驗結果與分析
1)MNIST 數據集。
實驗結果顯示:當中毒樣本所占比例為70%,平均攻擊成功率為51.14%±0.2%;當中毒樣本所占比例為50%時,平均攻擊成功率為49.23%±0.2%;當中毒樣本所占比例為30%時,平均攻擊成功率為48.68%±0.2%。可以觀察到,模型在完全良性訓練數據下的訓練平均精確度為94.12%,三次實驗對原模型精確度的影響幅度為4~6 個百分點。攻擊成功率對特定的目標有所降低,但是對于大多數目標數字的攻擊成功率仍然很高。各種針對性投毒攻擊的平均準確率下降分別為14%、8%和5%。例如,將4 錯標為0 的攻擊成功率僅為3%,而將0 錯標為6 的攻擊成功率為94%。這是因為干凈樣本和目標標簽樣本之間的紋理特征圖較為相近。
2)CIFAR10 數據集。
圖10 表示在CIFAR10 數據集上進行實驗所得出的攻擊成功率和原模型精確度(圖中的“T”表示誤差范圍),其中假圖個數占中毒樣本個數比例分別為70%、50%、30%、10%和5%,中毒樣本個數占訓練樣本個數比例為30%、20%、10%、5%和3%。
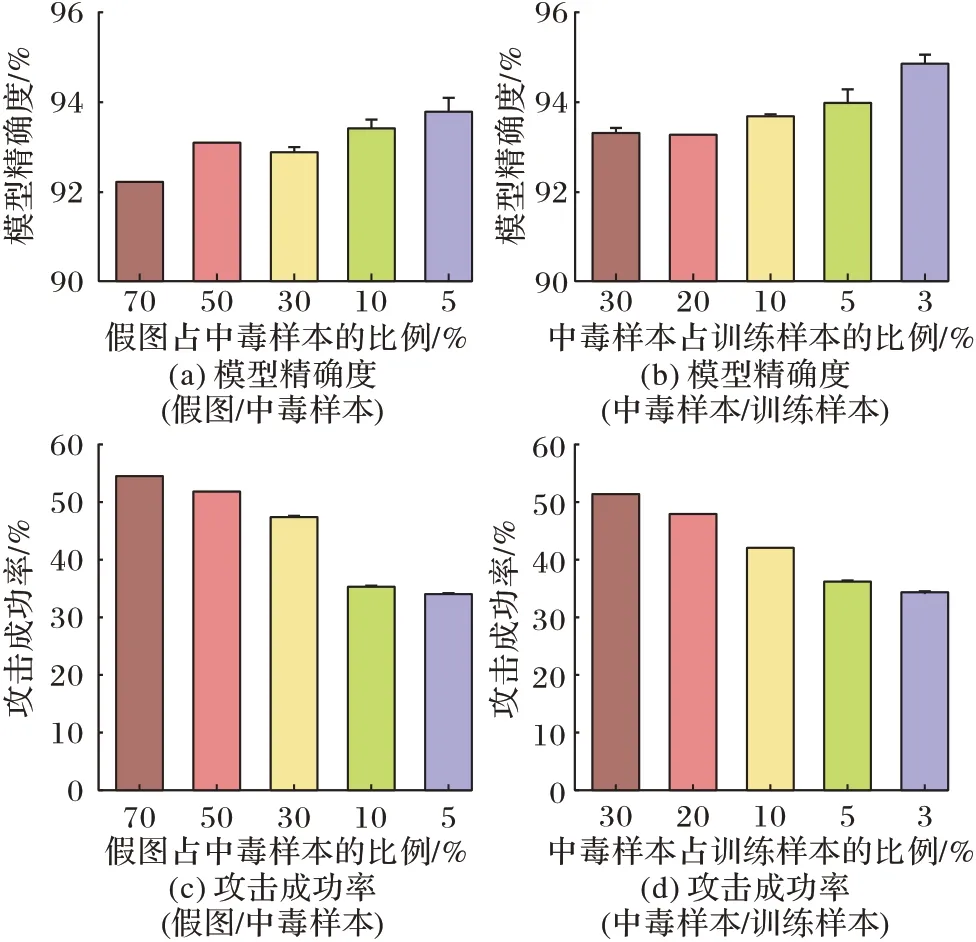
圖10 CIFAR10數據集上的實驗結果Fig.10 Experimental results on CIFAR10 dataset
實驗結果顯示:如圖10(a)所示,當假圖占中毒樣本的比例上升時,對原模型的精確度影響幅度為1~3個百分點,但圖10(c)中攻擊成功率卻提高了1~21個百分點。在圖10(b)中,當中毒樣本占訓練樣本比例為3%和30%時,模型精確度在92.56%~95.68%變化,圖10(d)當中毒樣本占訓練樣本比例為30%時,攻擊成功率在51%~52%變化,平均攻擊成功率為51.23%。可以觀察到特定目標的攻擊成功率降低,但是對于絕對多數的目標攻擊成功率升高。
4 結語
本文利用圖像隱寫技術使得觸發器的隱藏性得到提升,在觸發器的樣式以及大小進行改變的同時,對訓練集樣本的組成也進行了改變,突破了以往投毒攻擊方法的局限性以及在健壯性上進行改變和提升,使得該投毒攻擊方式逃過現有的某些防御方式并且有較高的攻擊成功率。用DCGAN 生成的假圖作為一部分訓練集樣本,由于DCGAN 的原理是在一次一次的迭代中提取真圖的部分特征生成假圖,并不斷地用假圖欺騙鑒別器,生成帶有觸發器的真圖。因此該方式中DCGAN 的輸入具有隨機性,訓練起來比較難,后續的工作將研究用VAE-GAN 對訓練樣本進行投毒攻擊,自動編碼器和生成對抗網絡組合生成的無監督生成模型可以生成質量更高的圖像樣本。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
