鐵路客運車站客流監測與預警系統
2023-02-18 13:11:08李永孟歌廖鳳華張軍鋒周星
鐵路計算機應用 2023年1期
關鍵詞:系統
李永,孟歌,廖鳳華,張軍鋒,周星
(1.中國鐵道科學研究院集團有限公司 電子計算技術研究所,北京 100081;2.中國鐵路濟南局集團有限公司 客運部,濟南 250001)
鐵路客運車站是旅客出行重要集散場地,目前車站進站驗證、安檢、候車等客運組織工作所需的設備、人員等資源主要依靠經驗進行調配,缺乏準確的實時數據支持。近年來,隨著新一代客票系統[1]的建設,車站實現了實名制驗證和電子客票[2]進出站,能夠準確地實時采集旅客進出站數據。另一方面,大數據、機器學習等技術在鐵路客運系統得到成功應用[3-4],為客運車站客流預測提供了技術支撐。
為此,通過獲取鐵路客票預售數據[5]、車站歷史客流數據、旅客進出站實時數據、列車正晚點數據等相關信息,建立基于K 均值聚類(K-Means)的支持向量回歸(SVR,Support Vector Regression)客流預測模型,實現車站每日進站客流和分時段進站客流及候車室客流的監測、預測及超限預警,幫助車站工作人員及時掌握客流變化,高效地組織、引導和疏散客流,為旅客提供更加優質的服務,提升旅客出行體驗。
1 系統架構
1.1 總體架構
鐵路客運車站客流監測與預警系統利用Kafka、數據傳輸中間件等技術[5],自動從中國鐵路客票發售和預訂系統(簡稱:客票系統,含12306 互聯網售票系統)、鐵路客運營銷輔助決策系統(簡稱:客運營銷系統)、鐵路旅客實名制進站驗證檢票系統(簡稱:實名制驗證系統)[6-7]、鐵路旅客自動檢票系統(簡稱:檢票系統)、鐵路列車調度指揮系統(簡稱:列車調度系統)[8]等系統獲取所需數據,對這些數據進行必要的轉換和融合處理,獲得較為全面的客流數據;利用車站歷史客流數據,建立基于K均值聚類的支持向量回歸機客流預測模型,實現分時段客流預測和候車室客流預測,當預測客流超出預警閾值時及時告警,為車站客運組織工作提供準確的實時客流信息。
鐵路客運車站客流監測與預警系統采用集中部署方案,系統架構劃分為數據接入層、業務處理層和數據展示層,如圖1 所示。
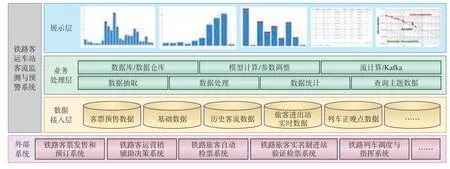
圖1 鐵路客運車站客流監測與預警系統架構示意
(1)數據接入層:通過數據采集程序自動獲取相關數據,主要包括客票系統的客票預售數據以及列車時刻表、車站字典、車次候車室安排等基礎數據,客運營銷系統的歷史客流數據,檢票系統和實名制驗證系統的旅客進出站實時數據,列車調度系統的列車正晚點數據。
(2)業務處理層:根據實際業務需求,對數據接入層所獲取的數據進行清洗、轉換和融合處理,生成不同業務場景下的客流監測數據;利用車站歷史客流數據建立客流預測模型,完成每日進站客流、分時段客流和候車室客流預測,并將客流監測數據和預測數據存儲在數據庫或數據倉庫中。
(3)展示層:為用戶提供內容豐富的實時客流展示圖表及數據查詢功能,并提供用戶管理、預警管理、閾值設置、模型參數設置等系統維護功能。
2 系統功能
鐵路客運車站客流監測與預警系統功能如圖2所示,主要面向車站用戶,提供客流流向、客流監測與預測、客流統計、預警管理、系統監控、系統設置等功能,同時也為鐵路局和站段用戶提供全局和所轄各站段客流數據。
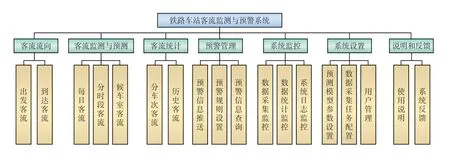
圖2 鐵路客運車站客流監測與預警系統功能構成示意
2.1 客流流向
通過對鐵路客票預售數據的統計分析,提供車站出發和到達客流的城市分布情況,幫助車站工作人員提前對重點方向旅客做好車站引導服務。
(1)出發客流:以遷徙圖的形式,展示從車站出發的客流主要去往的城市,并以不同顏色標識客流量的大小。
(2)到達客流:以遷徙圖的形式,展示到達車站的客流主要來自于哪些城市,并以不同顏色標識客流量的大小。
2.2 客流監測與預測
提供分時段和分場地的車站客流量監測與預測,幫助車站工作人員及時掌握和預知客流變化,提前設置好進站閘機和安檢通道開啟數量,安排好現場客服人員。
(1)每日客流:利用客票系統的預售數據,統計生成車站每日客流的監測數據;應用客流預測模型,預測車站每日客流;利用Echarts 技術,實現每日客流監測與預測數據可視化展示;當預測客流量超過警閾值時,自動改變圖形顯示顏色,并顯示推送的預警信息。
(2)分時段客流:基于旅客進站實時統計數據,動態展示各時段進站客流及各時段內具體車次的客流,準確反映旅客進站時間分布和進站高峰時段;結合車站列車時刻表數據,應用客流預測模型預測車站分時段客流;利用Echarts 技術,實現實現分時段客流監測與預測數據可視化展示;當預測客流量超過預警閾值時,自動改變圖形顯示顏色,并顯示推送的預警信息。
(3)候車室客流:基于旅客實時進站統計數據,確定各車次進站客流;根據車站候車室車次安排和列車正晚點數據,監測車站各候車室客流;應用客流預測模型,預測車站各候車室客流;當預測客流量超過預警閾值時,自動改變圖形顯示顏色,并顯示推送的預警信息。
2.3 客流統計
通過對鐵路客票預售數據和客運營銷歷史客流數據的融合分析,提供車站停靠列車的分車次客流數據統計和車站歷史發送量數據統計,幫助車站工作人員預知客流分布情況,提前做好客運組織準備工作。
(1)分車次客流:利用客票系統的客票預售數據,統計出停靠車站的各次列車的乘車和到達客流,方便車站工作人員根據列車時刻表,提前做好組織引導旅客乘車和出站的具體工作安排。
(2)歷史客流:基于客運營銷系統的歷史客流數據,提供車站歷史發送客流和到達客流的統計分析,統計車站某段時間或者某天的發送和到達客流;通過對客流的鉆取,進一步分析分時段或者分車次的客流,方便車站工作人員掌握本站客流規律,做好應對客流高峰期的準備工作。
2.4 預警管理
當車站的客流量達到設定的預警閾值時,針對不同業務場景自動生成預警消息,并按照設置的預警消息推送方式,及時將預警消息發送給相關的車站工作人員。
(1)預警信息推送:根據不同業務場景下觸發預警的級別,自動生成相應的預警消息,按照設定的業務職責和工作流程,將預警消息分別推送給具體工作人員,提醒其對客流預警予以關注,以便車站工作人員采取不同預警級別的針對性措施。
(2)預警規則設置:提供預警規則編輯和預警消息提示方式設置功能,車站管理員可根據車站技術條件和人員配備等實際情況,合理調整車站不同業務場景下客流預警閾值及預警消息提示方式,如彈出窗口、播放聲音、推送至企業微信或釘釘工作群等。
(3)預警信息查詢:按車站、時間段和不同業務場景,提供預警消分類匯總和條件查詢。
2.5 系統監控
記錄數據采集和處理程序模塊的運行狀態,生成用戶登錄和操作日志,幫助系統管理員全面掌握系統運行情況和用戶使用情況,支持故障診斷、性能調優和系統安全審計。
(1)數據采集監控:數據采集任務在執行過程中自動記錄日志,在數據采集監控頁面上可查看數據采集情況,包括采集時間、任務執行狀態、數據記錄數等。
(2)數據統計監控:針對不同業務場景定期自動執行數據統計任務并記錄日志,可在數據統計監控頁面上查看數據采統計任務的執行情況。
(3)系統日志監控:提供用戶登錄和操作日志,記錄用戶登錄時間、登錄地址、登錄方式、登錄次數及操作活動等,提供用戶行為審計。
2.6 系統設置
完成預測模型參數、數據采集任務時間和頻率的設置,提供系統用戶管理功能。
(1)預測模型參數設置:對客流預測模型進行離線訓練,對模型的精度進行驗證,當客流預測模型滿足要求時,在系統中對客流預測模型參數進行設置,以便將該模型應用于客流預測。
(2)數據采集任務配置:對于不同的數據采集任務,按需指定其自動執行的時間、次數及頻率。
(3)用戶管理:管理人員添加和刪除用戶,給不同的用戶進行不同的權限或修改用戶操作權限,重置用戶密碼;驗證登錄用戶身份合法性,僅允許用戶訪問被授權的功能。
2.7 說明和反饋
介紹系統的使用說明和用戶對系統使用的反饋情況。
(1)使用說明:提供系統使用說明頁面,介紹系統的操作和使用方式,不同功能中一些指標的簡介和使用場景。
(2)系統反饋:提供用戶反饋使用建議或報告使用系統的過程中所欲遇到問題或故障的信息交流窗口,以幫助不斷完善系統。
3 關鍵技術
3.1 數據采集、轉換、融合與存儲
系統從多個外部系統自動獲取數據,考慮到所采集數據的更新頻度及不同系統提供數據的接口方式,采用多種技術完成數據采集,并對采集到的數據進行必要的轉換和融合處理后,提供客流監測和預測功能。系統數據采集、轉換與融合處理流程,如圖3 所示。

圖3 數據抽取、轉換、融合與存儲流程
(1)數據抽取:目前,客票系統實現了核心交易數據的集中管理,相關應用均可通過連接交易管理服務器(CTMS,Connection and Transaction Management Server)請求訪問客票業務數據;鑒于電子客票數據量大,數據更新頻繁,為減少對客票系統的影響,利用Kafka 消息中間件實時接收客票預售數據;同時,利用Sybase 數據庫復制技術,直接從客票系統獲取列車時刻表、車站字典、車次候車室安排等靜態基礎數據,當基礎數據變化(如調圖后)時,可手動觸發數據復制;使用Java 數據庫連接(JDBC,Java Database Connectivity)開發數據抽取程序,分別接入實名制驗證系統和檢票系統獲取旅客實時進出站數據;利用數據庫通信服務器(DBCS,Database Communication Server),每天從客運營銷系統獲取一次歷史客流數據;數據抽取程序通過Web Service 接口,每隔30 min 自動從列車調度系統獲取最近的車站列車正晚點數據,也可根據實際情況手動調用數據抽取程序獲取數據。
(2)數據轉換與融合:根據不同的業務場景,對數據進行必要的類型和格式轉換,并通過建立關聯進行數據融合,生成滿足不同業務場景的數據表;進站驗證和進站閘機數據中包含個人姓名、身份證號等敏感信息,需要對其進行加密來脫敏。
(3)數據存儲:系統采用2 級數據存儲模式,將采集到的、經過轉換和融合處理的實時客流數據以及客流預測結果數據存儲在數據庫中,并定期將歷史數據歸檔轉儲至數據倉庫中,以提高數據查詢性能;將車站歷史客流數據等存儲在數據倉庫中,便于數據統計分析處理。
3.2 客流預測模型
常用的客流預測方法主要有聚類分析、時間序列[9]、灰色預測法[10]、SVR[11]、神經網絡[12]等。其中,SVR 以預測誤差最小化為目標,尋求一個能較好的接近數據點的估計函數f,再利用非線性映射函數 φ,將輸入空間的數據xi映射至高維空間Rn中進行線性回歸,可得到在原低維空間中非線性回歸的效果,對于非線性環境下小樣本數據集具有較好性能。K-Means 算法根據數據間相似度,將特征類似的樣本自動歸為一類,實現數據聚類劃分[13]。
鐵路客流受多種因素影響,直接對車站客流數據進行預測可能存在較大誤差,先利用K-Means 方法對車站停靠列車進行聚類,再將聚類后的數據作為SVR 輸入樣本,構建基于K-Means 的SVR 客流預測模型。
設聚類后的數據訓練樣本集為(x1,y1),(x2,y2),···,(xN,yN),其中xi∈Rn,yi∈{-1,1},N為客流樣本數,n為客流特征向量的維數。在SVR 中,求最優超平面可轉化為求解二次規劃問題:
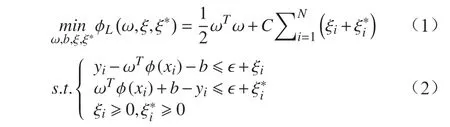
其中,ω為法向量;C為懲罰參數;ξi和為松弛因子;ε為不敏感函數。
利用二次規劃方法可以得到SVR 的估計式為
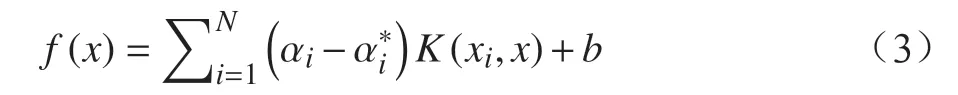
其中,閾值b通過下式求解:
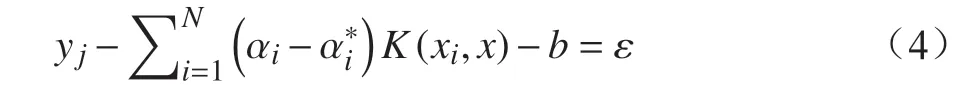
其中,ε取常用值0.1。
利用車站歷史客流數據進行模型訓練,采用均方根誤差(RMSE)對模型進行驗證,滿足要求的模型即可用于預測客流,具體流程如圖4 所示。
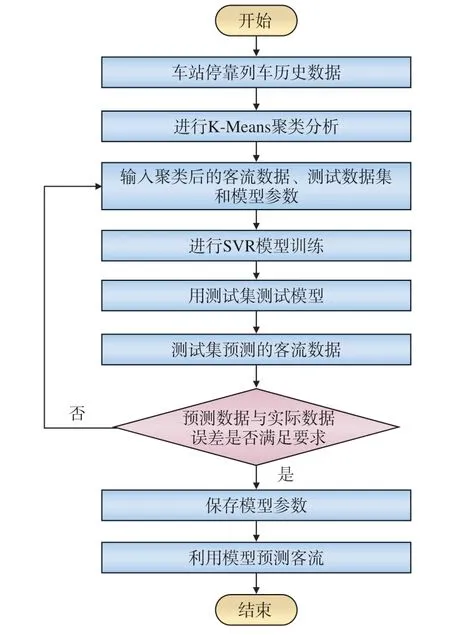
圖4 客流預測模型處理流程
3.3 客流預警閾值計算與預警分級規則
客流預警閾值包括進站口客流預警閾值和候車室客流預警閾值。
(1)影響進站口客流聚集的因素較多,本文暫時主要關注車站進站閘機數量配置,依據車站歷史最大旅客發送量S與進站閘機配置數量G,計算進站口客流預警閾值 α為

(2)候車室客流預警閾值 β主要依據車站候車室的面積和歷史最大客流量計算得到,即有

其中,Q為車站候車室的有效使用面積,J為車站候車室歷史最大客流量。
根據車站規模和歷史客流,可將客流預警級別劃分為4 個級別:Ⅳ(一般)—藍色,Ⅲ(較重)—黃色,Ⅱ(嚴重)—橙色,Ⅰ(特別嚴重)—紅色。以濟南站為例,客流預警級別劃分標準如表1 所示。
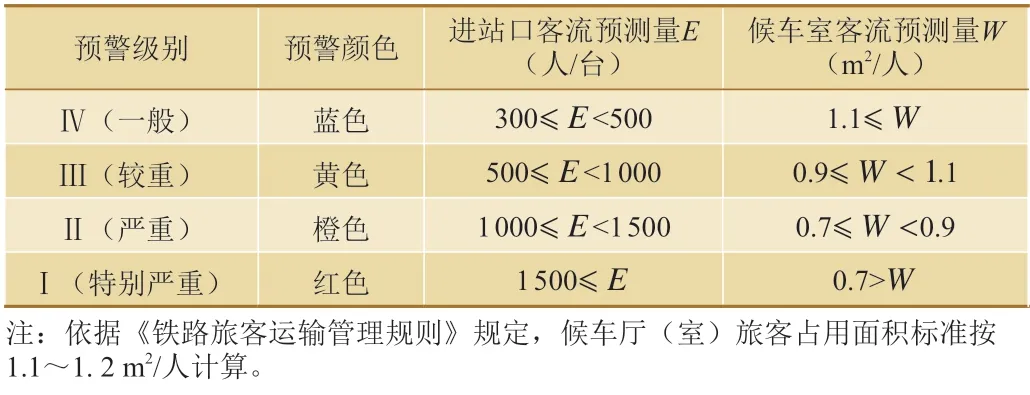
表1 濟南站客流預警級別劃分標準
系統計算出車站每日客流和候車室客流的預測量后,自動檢測是否超過設定的客流預警閾值。觸發預警后,客流監控窗口中展示客流信息的各種圖表會立即自動改變顯示顏色;同時,系統還會根據告警信息設置,向相關人員主動推送預警信息,提醒車站工作人員注意客流疏散組織。
4 結束語
鐵路客運車站客流監測與預警系統自動采集鐵路客票預售數據、客運營銷歷史客流數據、旅客進出站實時數據、列車正晚點等相關數據,提供直觀明了的車站出發、到達客流遷徙圖,基于車站歷史客流數據建立客流預測模型,實現車站每日客流、分時段客流、候車室客流的監測及預測,可根據歷史客流數據合理設置客流預警閾值,自動推送預警信息,方便車站工作人員隨時掌握客流動態,及時根據客流變化動態調配設備和人員,確保精準、高效、安全、有序地開展車站客運組織工作。
目前,該系統已在濟南站試運行,系統運行穩定,有助于改善車站客運服務水平,提升旅客出行體驗,具有較強的推廣使用價值。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
