融合自注意力的關系抽取級聯標記框架研究
2023-02-14 10:31:02肖立中臧中興宋賽賽
計算機工程與應用 2023年3期
關鍵詞:模型
肖立中,臧中興,宋賽賽
上海應用技術大學 計算機科學與信息工程學院,上海 201418
知識圖譜是近些年非常熱門的一個研究方向,它在很多方面都展示出了不錯的應用效果,例如問答系統、搜索引擎、推薦系統等。隨著互聯網的不斷發展和進步,人類世界存在著海量的信息和數據。知識圖譜不僅能夠對這些數據進行結構化的存儲,還可以在查詢的時候更加全面地了解相關知識,提升搜索的深度和廣度。醫療領域知識圖譜在智能醫療問答領域扮演著重要的角色,患者利用醫療問答系統不僅能夠初步地進行自我診斷,還能夠在一定程度上節約醫療資源。知識圖譜主要是由實體關系三元組構成,如何從海量的數據中抽取出實體及實體間的關系對于構建知識圖譜是至關重要的一步。
從非結構化的文本中抽取出形如(head,ralation,tail)或者(h,r,t)的實體對以及關系三元組是自然語言處理領域和知識圖譜構建過程中一項十分重要的任務。傳統的流水線式方法,將實體識別和關系抽取視為兩個獨立的子任務,首先識別出句子中所有的實體,然后對所有的實體對進行關系分類,雖然這種方法比較靈活、容易操作,但是這種方法忽略了兩個任務之間的相互聯系,無法充分利用輸入文本的特征信息[1],上一階段的錯誤不能夠在下一個階段進行糾正,容易形成錯誤傳遞[2],影響模型的準確率。
因此,需要構建一種模型來同時獲得實體對及其存在的關系,Li等[2]、Miwa等[3]以及Ren等[4]提出了基于特征的模型,這些方法對于特征工程有較強的依賴,需要大量的人力,耗費時間成本巨大。隨著神經網絡和深度學習的發展和不斷地被深入研究,最近的一些工作提出了基于神經網絡的模型,例如Zheng等[5]、Zeng等[6]以及Fu等[7]。雖然這些方法可以使用同一個模型對實體和關系進行抽取,實現了參數共享,減少了錯誤的累積,但是卻并不能夠解決實體重疊的問題以及同一句子中多對實體多對關系的問題。實體重疊是指一個句子中的不同關系三元組間存在某些實體相同,導致模型抽取關系不完全[8]。針對以上問題進行分析,本文提出了一種融合自注意力機制的級聯標記框架Att-CasRel,不再將關系作為實體對的離散分類標簽,轉而將關系作為從頭實體到尾實體的映射函數。首先識別出句子中所有可能的頭實體,然后針對每一個頭實體,使用特定關系的尾實體標注器,同時識別出所有可能的關系和相對應的尾實體。本文的主要貢獻有以下幾個方面:
(1)針對醫療領域文本在Bert模型的基礎上繼續進行訓練,使得本文使用的CB-Bert(Chinese biomedical bert)模型能夠更好地對文本進行編碼。
(2)本文在CB-Bert編碼器的基礎上實現了一種級聯標記框架,使得框架能夠充分利用預訓練的CB-Bert的強大能力和該標記框架的優勢。該標記框架能夠針對識別出的頭實體同時識別出對應關系及與之關聯的尾實體,使關系標簽成為頭實體到尾實體的映射函數,大大減少了誤差累積和信息冗余問題。
本文在框架中融合了自注意力機制,相比較于對特征向量使用簡單的求平均值的做法,能夠更好地提取文本的語義特征,更加充分地考慮文本中不同位置信息的重要程度,提升了模型的性能。
1 相關工作
從非結構化的文本中抽取關系三元組是自然語言處理的一項重要任務,是信息抽取研究領域的一項研究熱點,同時也是構建大型知識圖譜的一個重要步驟,如Konwledge Vault[9]。
早期的工作將實體識別和關系抽取作為兩個獨立的任務,如Mintz等[10],他們將抽取關系三元組分為兩步,首先識別出輸入句子中的所有實體,然后對抽取到的實體進行配對,進行關系分類。這類方法雖然取得了不錯的效果,但是容易造成錯誤累積的問題,實體識別階段產生的誤差將傳遞到關系抽取階段,并且忽略了關系和實體之間的相互依賴,無法充分利用輸入信息。為了解決這些問題,有研究者提出了實體關系聯合抽取的方法,傳統的基于特征的模型嚴重依賴于特征工程并且需要大量的人力,如Li等[2]、Miwa等[3]以及Ren等[4],因此特征工程階段的結果將直接影響后續任務的結果,對于特征工程的要求很高。
隨著神經網絡的快速發展,最近一些研究提出基于神經網絡的方法,雖然取得了不錯的效果,但是現有的一些神經網絡模型例如Miwa等[11]提出僅通過參數共享而不是聯合解碼來實現聯合抽取。為了實現關系三元組的抽取,他們仍然是將實體識別和關系抽取作為兩個獨立的任務來進行。獨立的解碼過程造成了獨立的訓練目標,這將會影響抽取關系三元組的效果。Zheng等[5]提出一種聯合標記策略,實現了聯合解碼過程,他們將關系三元組抽取問題轉化成序列標注問題,不需要再使用命名實體識別和關系分類這兩個步驟,由于提出的標記策略將實體和關系整合在一起,因此該方法可以直接獲取關系三元組。Dai等[12]在此基礎上使用多輪標注方法,有效地解決了實體嵌套的問題。
盡管之前的工作已經能夠解決聯合抽取的問題,但是關系三元組重疊的問題仍然沒有得到較好的解決。最近的研究者,如Fu等[7]提出了一種圖卷積網絡來解決此問題,喬晶晶等[13]提出一種路徑聚合算法來進行關系抽取。盡管這些研究取得了一定的成果,但是他們仍然是將關系作為實體對的離散的分類標簽,使得模型難以解決重疊三元組的問題。Zhao等[14]提出了一種基于異構圖神經網絡的表示迭代融合關系抽取方法,將關系和詞建模為圖上的節點,并通過消息傳遞機制來得到更適合關系抽取任務的節點表示。Liu等[15]提出了一種基于注意力的聯合關系抽取模型,該模型設計了一種有監督的多頭自注意機制作為關系檢測模塊,分別學習每種關系類型之間的關聯來識別重疊關系和關系類型。Lai等[16]提出了一種基于序列標注的聯合抽取模型,該模型在句子編碼信息之后添加多頭注意力層以獲得句子和關系的表征,并對句子表示進行序列標注來獲得實體對。
早先的方法將實體關系抽取任務作為一種分類任務,這種在實體識別階段出現的錯誤無法在關系分類階段進行糾正,導致誤差累積,嚴重影響關系抽取的準確性,后來的研究者提出聯合抽取的方式,但是仍然存在實體共享的問題。本文基于以上研究,提出一種新的級聯標記框架Att-CasRel,并在解碼階段融入了自注意力機制,將關系標簽作為從頭實體到尾實體的映射函數,有效地解決了關系抽取中存在的實體共享和錯誤傳遞等問題。
2 Att-CasRel框架結構
實體關系抽取的目標是抽取出一個句子中所有可能的形如(h,r,t)的關系三元組。由于不同的關系三元組可能共享同一個實體,為此,本文提出一種融合自注意力機制的級聯標注框架,來同時從句子中抽取出多個關系三元組。首先使用經過預訓練的Bert編碼器對輸入文本進行編碼,得到每一個字符的向量表示形式,然后運行頭實體標注器識別出輸入句子中所有的頭實體;對于識別出的每一個頭實體,再運行特定關系下的尾實體標注器。不同于頭實體識別階段,在運行特定關系尾實體標注器階段,不僅僅需要對Bert編碼器的輸出向量hn進行編碼,還將識別出的頭實體的向量表示考慮在內,針對每一個頭實體,通過自注意力機制,為頭實體中的每一個字符分配不同的注意力權重,得到該頭實體的加權向量表示,將該向量表示和Bert編碼器輸出相加所得到的結果作為尾實體標注器的輸入,從而識別出在特定關系下與該頭實體相對應的尾實體。Att-CasRel總體框架如圖1所示。
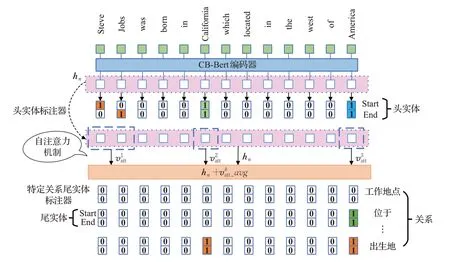
圖1 Att-CasRel框架圖Fig.1 Att-CasRel frame diagram
2.1 CB-Bert編碼器
編碼器模塊主要是提取句子的特征信息,該特征信息將會輸入到后續的標注模塊中,Devlin等[17]提出的Bert模型一經提出,便刷新了自然語言處理領域很多子任務的SOTA模型。然而,Bert模型是在維基百科等語料庫上進行訓練的,在中文醫療領域,由于存在大量的專業術語,這對于Bert而言是一個很大的挑戰,主要原因在于醫療領域的詞向量分布不同于維基百科語料庫,Bert不能夠有效地對醫療領域文本進行有效的編碼。Gururangan等[18]指出,在特定領域或者較小的語料庫上對語言模型進行再訓練可以獲得性能的提升。因此,本文針對上述問題,對于Bert模型進行再訓練,采用CMeIE(Chinese medical information extraction)數據集中的文本,對于Bert模型進行訓練,使其對于醫療領域文本能夠更好地進行編碼,將訓練好的Bert模型命名為CB-Bert,Bert模型結構圖如圖2所示。
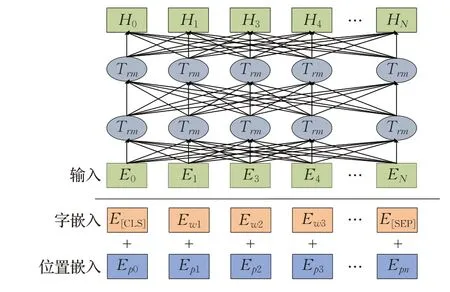
圖2 Bert模型結構Fig.2 Bert model structure
Bert模型輸入包含三個部分,分別為詞嵌入(token embedding)、片段嵌入(segment embedding)和位置編碼嵌入(position embedding)。由于分詞可能存在錯誤,因此本文使用字嵌入信息,避免了這部分錯誤,片段嵌入在關系抽取任務中不適用,因此本文舍棄這部分嵌入信息,將字嵌入信息Ex和位置嵌入信息Ep相加得到輸入的向量E,隨后將輸入向量E經過第一層及后續N-1層的Transformer網絡得到文本的向量表示HN,如公式(1)和(2)所示:
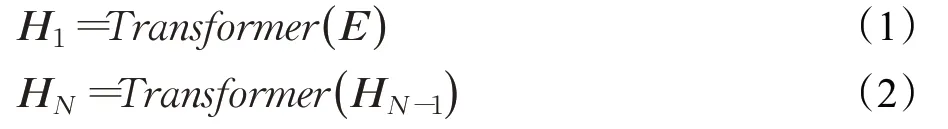
其中,HN為句子經過N層Transformer網絡編碼后的輸出。該向量將作為后續步驟的輸入。
2.2 級聯標注器
級聯標注部分是本文的重點部分,如圖1所示,主要分為兩個模塊,一個是頭實體標注器,另一個是特定關系尾實體標注器,通過兩個級聯步驟從輸入句子中抽取出關系三元組。對于特定的數據集,實體類別是有限的,因此實體間的關系類別也是有限的,因此人為規定好該數據集存在的關系類別。然后,利用頭實體標注器從輸入句子中識別出所有可能的頭實體,然后將所有的頭實體在上述的每一種關系類別下去檢查是否有對應的尾實體可以與其組成關系三元組,如果有,則將該三元組保存,若沒有,則繼續檢查其他的關系類別。直至將所有關系類別檢查完畢,便可識別出句子中所有可能的關系三元組。
2.2.1 頭實體標注器
頭實體標注器的目標是從輸入的句子中識別出所有可能的頭實體,通過對N層CB-Bert編碼器的輸出HN進行解碼,便可以得到所需要的頭實體。具體方法為使用兩個二分類器對HN中每一個字符所對應的編碼向量是否是頭實體的開始位置或結尾位置進行二分類,如果是,則在相應位置將標簽賦值為1,否則賦值為0。詳細的操作如公式(3)和(4)所示:

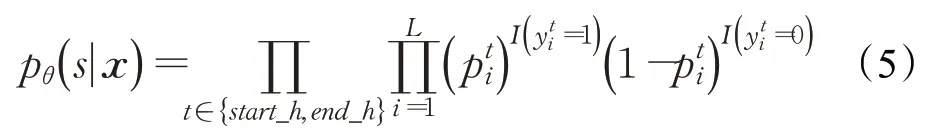
其中,L代表句子的長度,如果z為True,則I(z)=1,否則為0,表示頭實體開始位置的二分類標簽,表示頭實體末尾位置的二分類標簽,取值范圍為{0,1},參數θ={Wstart,Wend,bstart,bend}。
如果一個句子中存在多個頭實體,本文采用就近原則來解決頭實體識別可能會出現的交叉問題,將兩個距離最近的頭實體開始位置和結尾位置所標記的范圍視為一個頭實體,如圖1所示,距離頭實體開始位置Steve最近的結尾位置是Jobs,因此會將SteveJobs視為一個頭實體,而不是將California所對應的結尾位置和Steve組合起來視為一個頭實體,在圖1中使用不同顏色來區分不同的頭實體。
2.2.2 特定關系尾實體標注器
如圖1所示,特定關系的尾實體標注器將同時識別出尾實體及與之關聯的關系。其中包含了一系列特定關系的尾實體標注器,所有的標注器將同時識別出每一個頭實體所對應的尾實體。不同于頭實體標注器,尾實體標注器不僅僅是對CB-Bert編碼器的輸出HN進行解碼,而是同時將頭實體的編碼向量表示也考慮在內。對于每一個字符的編碼向量的具體計算如公式(6)和(7)所示:
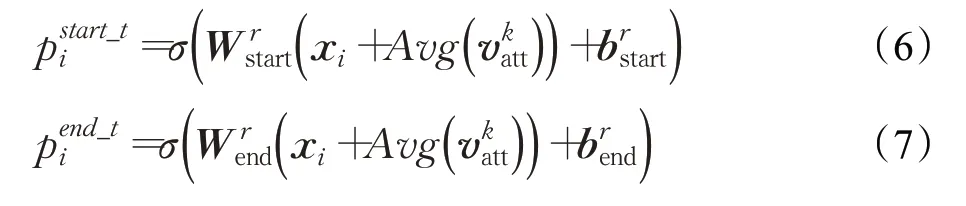
其中,和表示在輸入的句子中第i個字符為尾實體的開始和結束位置的概率值。代表在頭實體標注器中所識別出的第k個頭實體的編碼向量表示。對于每一個頭實體,迭代地進行編碼操作。
2.2.3 自注意力機制
對于醫療領域命名實體而言,為了更加有重點地描述實體所表示的信息,本文引入了自注意力機制,將實體中不同的詞向量分配高低不同的權重,這樣得到的語義向量便能更加準確地表達實體的含義,從而有效地提高關系抽取的準確性。
注意力機制是由Vaswani[19]最早提出并應用于機器翻譯領域,本文借鑒該文中提出的自注意力機制思想,將自注意力機制應用于每一個頭實體編碼向量,來更好地對頭實體的編碼向量進行特征提取。計算過程如公式(8)所示:
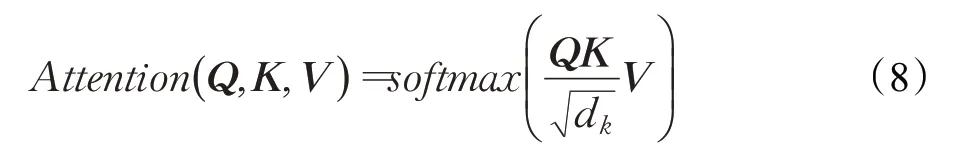
為了得到Q、K以及V,需要引入三個矩陣WQ、WK以及WV,隨機初始化矩陣的值,分別將這三個矩陣與每一個實體的向量表示相乘可以得到對應的Q、K、V。再通過公式(8)計算得到注意力分數,作為權重,通過加權求和計算得到最終的實體向量表示。
由于為某一個頭實體的編碼向量表示,而每一個頭實體可能有多個字符,因此,為了使公式(6)和(7)可以正常計算,需要使xi和維度保持一致,因此采取求平均值的做法對進行降維操作,與xi相加得到給定一個輸入句子x和一個頭實體h,對于特定關系r的尾實體標注器通過優化公式(9)中的似然函數來識別出尾實體t的邊界。
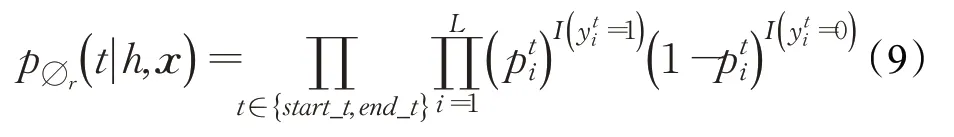
2.2.4 數據似然目標函數
一般的,在訓練集D中,給定一個句子xi以及句子中一組可能存在的關系三元組Tj={(h,r,t)},訓練的目標定義為最大化訓練集的數據似然性L:
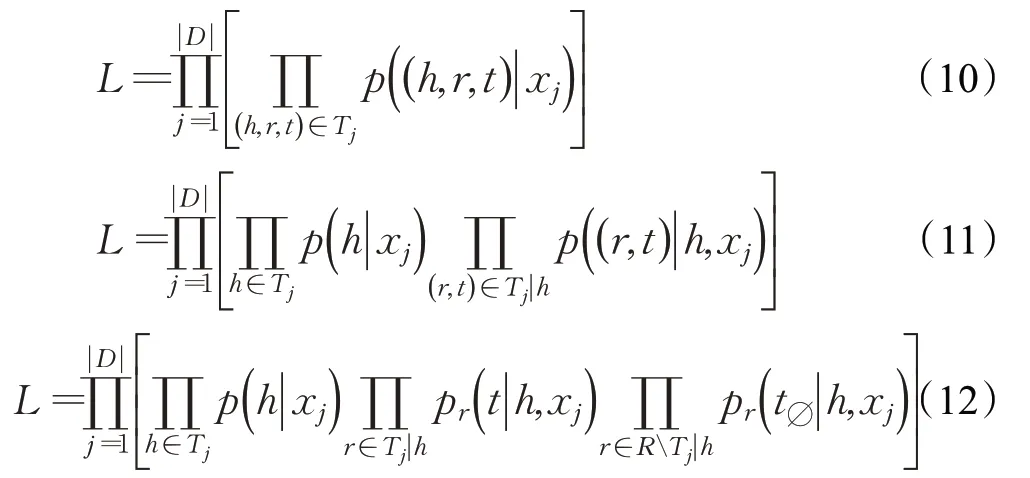
其中,h∈Tj表示三元組Tj中出現的頭實體,Tj|h代表在Tj中以h為頭實體的三元組;(r,t)∈Tj|h表示在三元組中以h為頭實體的(r,t)對,R為所有可能的關系,RTj|h代表在三元組中除了以h為頭實體的所有關系。在關系三元組中,所有與頭實體h∈Tj有關的關系三元組必然存在相對應的尾實體,其他的關系在句子中一定沒有尾實體,因此記作t?。通過上述目標函數公式,可以總結出以下幾個優點:(1)由于數據似然函數是針對三元組的,因此最優化該似然函數相當于最優化最終的評估函數;(2)沒有假設同一個句子中可以有多少三元組共享實體,因此解決了重疊三元組的問題;(3)針對關系三元組抽取,提供了一種全新的標注方式,針對句子xj,首先學習一個頭實體標注器p(h|xj)來識別出句子中的所有頭實體,然后針對每一種關系r,再學習一個尾實體標注器pr(t|h,xj),可以學習到針對固定實體和關系的尾實體。通過這種方式,可以將每一種關系作為一種從頭實體映射到尾實體的函數,而不是作為頭實體尾實體對的分類標簽。
對于公式(12)取對數函數,得到目標函數J(θ):
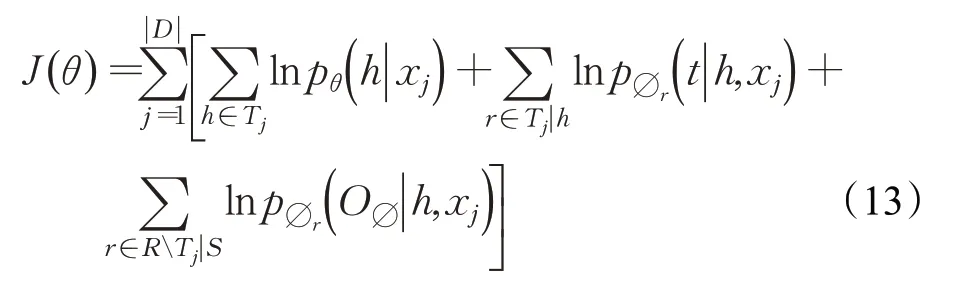
其中,參數θ={θ,{Φr}r∈R}。使用Kingma等[20]提出的Adam梯度下降法來優化該目標函數,對每個批次的訓練數據進行隨機打亂操作來避免過擬合。
3 實驗與分析
3.1 實驗設置
本文使用的數據集為CMeIE,該數據集共包含28 008條數據,關系種類為44種,其中訓練集包含17 924條數據,驗證集4 482條數據,測試集5 602條數據。根據關系三元組的不同重疊類型,將數據集劃分為三種類型,分別稱為Normal、Single Entity Overlap(SEO)、Entity Pair Overlap(EPO)。具體統計數據分別見表1、表2。

表1 數據集統計信息Table 1 Dataset statistics
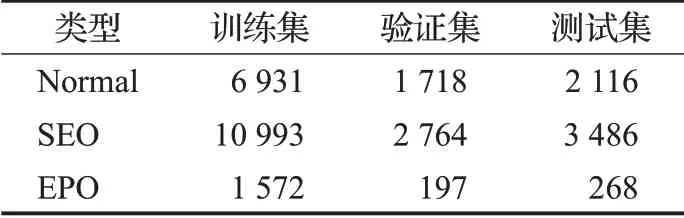
表2 實體重疊類型統計Table 2 Entity overlap type statistics
本文使用的評估標準為準確率(P)、召回率(R)以及F1值。當且僅當一個關系三元組的頭實體、尾實體和關系類型均預測正確才認為該預測數據為真,否則為假。
準確率、召回率以及F1值的計算公式分別如公式(14)~(16)所示:

其中,TP表示被判定為正樣本,也是正樣本的樣例,FP表示被判定為正樣本,但事實上是負樣本的樣例,FN表示被判定為負樣本,但事實上是正樣本的樣例。
3.2 實驗結果及分析
3.2.1 對比實驗
本文將Att-CasRel模型與其他幾個關系抽取模型進行了比較,包括NovelTagging[5]、CopyR[6]、GraphRel[7]。實驗結果如表3所示,其中最佳的實驗結果由粗體標出。通過對比實驗結果可以看到,本文提出的模型在該數據集上取得了不錯的效果。對比NovelTagging和CopyR兩種模型,本文模型在驗證集和測試集上F1值獲得了較大提升;相較于GraphyRel,在測試集提升了約25個百分點。說明本文提出的級聯標記框架在進行實體關系聯合抽取任務上有著不錯的效果。
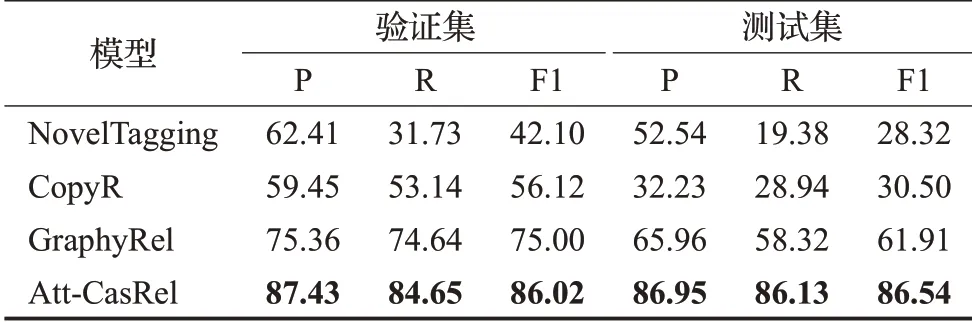
表3 對比實驗結果Table 3 Comparative experimental results 單位:%
本文使用的數據集中存在大量的共享實體的關系三元組,由于NovelTagging模型只考慮了一個實體只屬于一個三元組的情況,根據測試集上的召回率可以看出,該模型對于共享實體的問題沒有得到很好的解決。而CopyR和GraphyRel模型相較于NovelTagging模型雖然有一定程度的提升,但是在編碼階段這兩個模型均使用BiLSTM模型,本文提出使用經過預訓練的Bert模型作為編碼器,從實驗結果可以看出,使用Bert模型可以大幅提高關系抽取的準確率,說明對于特定領域的實體使用經過預訓練的Bert模型能夠更好地編碼語義向量。
3.2.2 消融實驗
由于本模型使用了經過預訓練的Bert模型,即CBBert,并且在尾實體解碼階段融入了自注意力機制。為此,本文進行了消融實驗來驗證預訓練編碼器和自注意力機制的有效性。使用CasRelRandom表示基礎框架,Cas-RelCB-Bert表示使用經過預訓練的Bert模型,但是未融入自注意力機制,僅僅是對頭實體編碼向量進行簡單的求平均操作;Att-CasRelRandom表示僅僅融入自注意力機制的模型,而使用隨機初始化的Bert模型進行編碼;Att-CasRelCB-Bert表示本文所提出的模型。消融實驗的結果如表4所示,其中最佳的實驗結果由粗體標出。
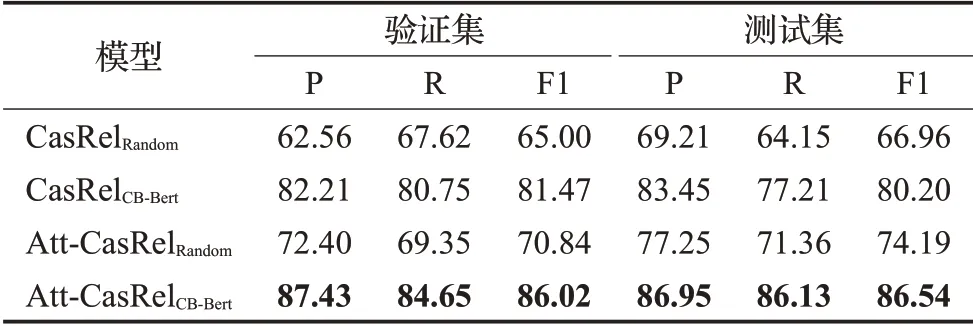
表4 消融實驗結果Table 4 Ablation experiment results 單位:%
對比表4中第一、二行和第三、四行可以看出,無論是否融入注意力機制,在本文提出框架的基礎上使用預訓練的Bert模型都能在較大程度上提高模型的精度,說明預訓練的Bert模型能夠更好地獲取語言的特征信息,證明了其有效性。對比表4中第一、三行和第二、四行可以看出,引入自注意力機制對頭實體進行特征關注也能在一定程度上影響模型編碼效果,說明自注意力機制能夠更好地對頭實體的編碼向量進行特征提取,識別出頭實體所要表達的真實語義。
另外,通過將表4第一行與表3中其他模型的F1值進行對比可以看出,即使未融入自注意力機制,同時使用隨機初始化Bert模型,本文提出的級聯標記框架在測試集上的效果仍優于NovelTagging、CopyR和GraphyRel模型,證明本文提出的級聯標記框架自身的優越性,從源頭上解決了錯誤傳遞和實體共享的問題。
本文提出的模型所要解決的另外一個問題是實體共享的問題,因此還針對不同實體重疊類型的句子設計了額外的實驗,實驗結果如圖3所示。
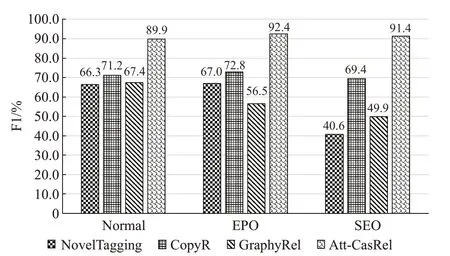
圖3 不同重疊類型三元組F1值Fig.3 F1 values of triples of different overlapping types
通過圖3的實驗結果可以看出,本文所對比的其他模型在Normal、SEO、EPO三種類型的關系三元組抽取上的表現總體呈現下降趨勢,反映出隨著共享實體的增多,關系三元組抽取的難度在增加,其中Normal類型的抽取最為簡單,SEO類型和EPO類型抽取難度相當。本文提出的Att-CasRel模型無論是在Normal還是在SEO或者EPO類型的關系抽取中均表現出了很好的效果,甚至在EPO和SEO類型的關系抽取中獲得了比Normal更高的F1值。說明本文所提出的級聯標記框架能夠更好地解決關系三元組共享實體的問題。
4 結論
為了解決實體關系三元組抽取任務中存在的實體共享以及錯誤傳遞等問題,本文提出了融入自注意力機制的級聯標注框架,關系類型不再作為實體對的分類標簽,而是將關系作為頭實體到尾實體的映射函數,重新定義了關系三元組抽取任務,減少了錯誤傳遞。對于輸入文本,使用經過預訓練的Bert編碼器進行編碼,將文本映射到低維度的向量空間中,更好地表達輸入文本的語義信息。在尾實體識別階段,通過融入自注意力機制,能夠更好地對頭實體的特征信息進行提取,從而提高關系三元組抽取的準確率。
實驗結果表明,在CMeIE數據集上,本文所提出的模型能夠更加準確全面地從句子中同時抽取到多個關系三元組,并且有效地解決了實體共享的問題。下一步的工作重點將基于關系三元組抽取的結果進行醫療領域的知識圖譜構建,為后續工作,如基于知識圖譜的問答系統等任務鋪墊基礎。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
