數據歸一化方法綜述
2023-02-14 10:30:54楊寒雨趙曉永
計算機工程與應用 2023年3期
關鍵詞:方法
楊寒雨,趙曉永,2,王 磊
1.北京信息科技大學 信息管理學院,北京 100129
2.北京信息科技大學 北京材料基因工程高精尖創新中心,北京 100129
如今的大數據場景信息非常豐富,從物聯網到智能城市,再到醫療保健、社交媒體和金融應用。大數據呈現容量大、種類多等特點,大規模且雜亂無章的數據會對研究結果產生巨大的影響[1]。大數據因其高價值的特征,可以作為機器學習的輸入以預測未來趨勢[2]。在機器學習任務中,對大數據應該進行規范化的預處理,從而提高模型的預測精度[3-4],獲得機器學習的高性能[5]。數據歸一化是數據預處理的一個重要步驟。
歸一化(normalization)是一種簡化計算的方式。即將所有屬性以相同的測量單位表示,并使用通用的刻度或范圍。歸一化試圖賦予所有數據屬性同等的權重,使屬性之間的比較與聚合更容易,數據的收斂條件更好[6]。不會出現屬性值凌駕于其他屬性值之上的情況。另一方面,歸一化有助于防止使用屬性之間距離度量的機器學習算法產生扭曲的結果,并提高了數據分析的效率。常用的歸一化方法有Min-Max、Z-Score和Sigmoid等。
歸一化在當今數據應用的不同方面都有深刻影響[7]。在深度學習方面,由于深度學習是包含很多隱藏層的神經網絡結構,在訓練過程中,各層參數在不停變化,所以會存在內部變量偏移(internal covariate shift)[8]。在基于機器學習的分類任務中,應用了Min-Max數據歸一化技術的隨機數森林和決策樹模型的平均準確率最高可達到99%[9]。在股指價格變動預測任務中,選取合適歸一化方法的支持向量機(support vector machine,SVM)可以提高預測準確率2.4%[10]。同時,歸一化在數據流挖掘方面同樣重要。不同評價指標往往具有不同量綱,數值間差別較大,不進行處理可能會影響到數據分析的結果[6,11]。為消除指標之間的量綱和取值范圍差異的影響,需要對輸入數據進行歸一化處理。將其按照比例進行縮放,落入一個特定的區域,以便進行綜合分析[12]。例如將人的身高屬性值映射到[-1,1]或[0,1]內。而在流式數據場景下,處理的是非連續的數據,數據以流的形式先后到達訓練點,一次一個樣本,所以流處理方法必須在時間和資源的嚴格限制下處理數據[13]。這就為流場景下數據的歸一化帶來了極大的挑戰性。
目前,國外對歸一化問題的研究很多。比較著名的有Google(谷歌)、Texas Tech University(得克薩斯理工大學)等。但當前研究僅僅側重于神經網絡隱藏層之間的歸一化算法,包括文獻[8,14-15]等,缺乏流場景下綜述類文獻。目前國內較為詳盡的歸一化綜述為文獻[16],此文獻著重于深度神經網絡下隱藏層之間的批數據歸一化算法。本文則系統地整理并分析了相關文獻,提出基于批數據的歸一化分類方法以及基于流數據的歸一化分類方法,通過上述方法對近年來的研究進行了綜述,并討論了未來研究方向。
1 數據歸一化的基本方法
1.1 輸入層的數據歸一化方法
數據集的數據對學習建模不是完全有效。有時直接選定的屬性是原始屬性,僅在獲取它們的原始域中具有意義,不足以獲得準確的預測模型[6]。機器學習應注意輸入數據屬性的統計分布,且檢查屬性統計的變化[17]。
因此,需要對數據執行一系列預處理步驟以實現將原始屬性轉換成能利用的屬性,這將有助于模型的建立。線性無量綱方法可用于批數據在不同學習模式中在輸入層的歸一化操作。詹敏等[18]根據線性無量綱化方法函數構成所使用的中心點值和值域指標,對線性無量綱化方法進行分析總結;郭亞軍等[19]在多種線性無量綱化方法的基礎上,就指標無量綱化過程的穩定性問題提出了改進型方法理論;鄭宏宇等[20]討論了綜合評價中線性無量綱方法的選擇問題。
表1列出了批數據與流數據分別在學習模式和處理階段兩方面的歸一化方法的對比。對于流數據在離線學習下的歸一化操作,可通過將流數據轉為批數據從而選取與批數據在離線學習下相同的歸一化方法。而對于批數據在在線學習下的歸一化方法,可通過海量批數據的方式以采用與流數據在在線模式下相同的歸一化方法。

表1 數據歸一化方法對比Table 1 Comparison of data normalization methods
在本節中,重點介紹將數據的原始分布轉換為目標數據分布的一系列線性無量綱方法。
1.1.1 Min-Max
Min-Max歸一化[21-24]也稱為線性函數歸一化,對原始數據做一次線性變換,通過以下函數(1),將原數據映射到[0,1]之間,不改變原始數據分布。函數(1)中,擬歸一化數據用x表示,xnew則為x歸一化后的數據,Max、Min分別表示為當前數據中最大值和最小值。

優點:對原數據做處理之后并不改變數據分布。
缺點:過度依賴最大最小值,當有異常數據點出現時會對結果產生較大影響。
1.1.2 Z-Score
Z-Score[21-24]的原理是將原數據處理成符合正態分布的數據,具體是取得數據的均值和標準差,通過以下函數(2)實現歸一化操作。此方法對數據的映射沒有一個固定的范圍,由數據本身均值和標準差決定。函數(2)中Mean表示數據的均值,StandardDeviation表示數據的標準差。
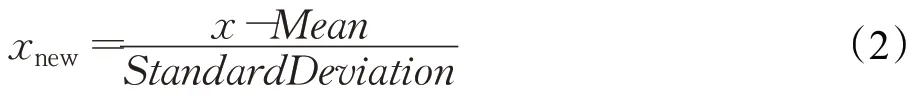
優點:受離群值影響較小,適合最大值、最小值未知的情況。
缺點:改變數據的分布。
1.1.3 Sigmoid
Sigmoid函數也稱為Logistic函數[25-26],值域為[0,1],經過函數(3),輸入的數據被映射在[0,1]之間。Sigmoid函數具體函數圖像如圖1所示。


圖1 Sigmoid函數圖Fig.1 Sigmoid function diagram
優點:適合用于反映二分類結果的概率,對于計算反向傳播較為簡單。
缺點:可能存在梯度消失問題。
1.1.4 小數定標
小數定標[21-24]通過移動小數點直觀地對數據進行處理,將原始數據的絕對值映射到始終小于1的范圍內。函數如公式(4)所示,其中j是整個輸入數據的絕對值最大的數據的位數。

優點:適用范圍廣,受到數據分布影響小,更加實用。
缺點:過度依賴最大最小值,容易受異常點影響。
1.1.5 Rank Gauss
Rank Gauss[27]是一種對變量的處理方法,它分為四個步驟。第一步,先對要處理的數據進行排序;第二步,將目標數據轉換尺度到[-1,1];第三步,調整極端值;第四步,使用erfinv()函數,其中erfinv(1)等于正無窮,erfinv(-1)等于負無窮。erfinv()是erf()的反函數,erf()的值域為[-1,1],表達式如公式(5)所示。第四步使得歸一化后的數據滿足高斯分布。

優點:數據變為高斯分布,更為直觀。
缺點:只保留了數據的排序信息。
1.1.6 反余切函數
反余切函數的值域為[0,π],函數表達式如公式(6)所示,值域范圍為[0,1],歸一化后的數據映射到[0,1]之間。同時也有研究人員提出基于反三角函數的非線性預處理方法[28]。

優點:函數圖像平穩,對于計算反向傳播較為簡單。
缺點:僅當數據都大于等于0時,映射的區間為[0,1]。并非所有數據標準化的結果都映射到[0,1]區間上。
1.1.7 tanh
tanh函數[29]值域為(-1,1),經過此函數數據被映射在(-1,1)之間,其中tanh函數的表達式如公式(7)所示。圖2為tanh函數具體函數圖像。

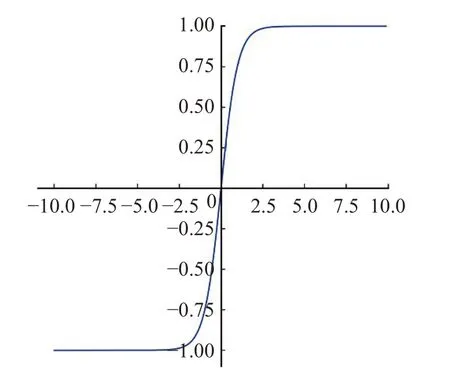
圖2 tanh函數圖Fig.2 tanh function diagram
優點:訓練容易。
缺點:全部激活,使得神經網絡較重(heavy)。
1.2 隱藏層的數據歸一化方法
當批數據進入深度神經網絡后,容易出現“Internal Covariate Shift”的問題。由于深度學習是由多層神經元組成,某一層更新參數,在深度的迭代下,即使參數的變化較小,在多層次的影響下也會對結果產生較大影響[8]。
流數據按順序先后到達,難以存儲在內存中。當前深度學習下絕大多數的隱藏層歸一化方法需要在學習任務之前提供整個訓練數據集,所以在隱藏層下對流數據進行歸一化任務極為困難。而對于流數據下的深度學習應用,Zhang等[30]提出了在線深度學習模型,此模型能夠從數據流中連續訓練深度學習模型,并且它能夠隨著時間的推移使模型能力從簡單到復雜,很好地結合了在線學習和深度學習的優點。在線深度學習模型中的隱藏層歸一化方法可使用深度學習隱藏層中的歸一化方法。深度學習隱藏層下有如下六種歸一化方法被先后提出。
1.2.1 Batch Normalization
由于低層網絡更新了參數,經多層迭代使后面層輸入數據發生變化。Ioffe等[8]提出Batch Normalization,中心思想是在隱藏層的每一層輸入前加一個歸一化層,在數據進入隱藏層前,先進行歸一化處理,處理之后再進入神經元進行運算[4]。例如網絡第四層輸入數據為X4(X4表示網絡第四層的輸入數據),把輸入數據歸一化為均值為0、方差為1的數據集,然后再輸入至第四層進行計算。
優點:提升訓練速度,尤其在計算機視覺任務上表現較好。
缺點:過度依賴批量大小(batchsize)。
1.2.2 Layer Normalization
由于BN(batch normalization)過度依賴批量的大小,當批量較小時,可能由于批量大小太小,均值和方差不具有全局代表性,導致模型效果惡化。Ba等[14]提出Layer Normalization,中心思想是對當前隱藏層整層做歸一化操作。與Batch Normalization的不同之處在于,BN是針對同一個樣本中的所有數據,而LN(layer normalization)是針對于單個樣本來操作。在LN中,一個批里就有與批量大小同數量的均值和方差。均值計算方法如表達式(8)所示,方差計算方法如表達式(9)所示。Batch Normalization與Layer Normalization中均值與方差的不同計算方式如圖3所示。
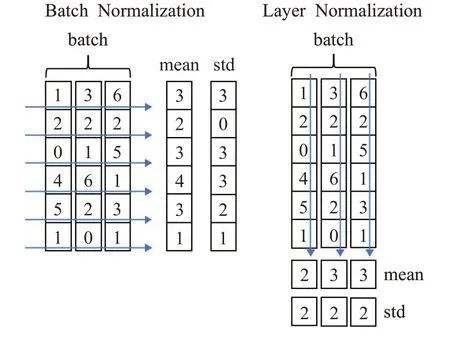
圖3 BN與LN對比Fig.3 Comparison of BN and LN
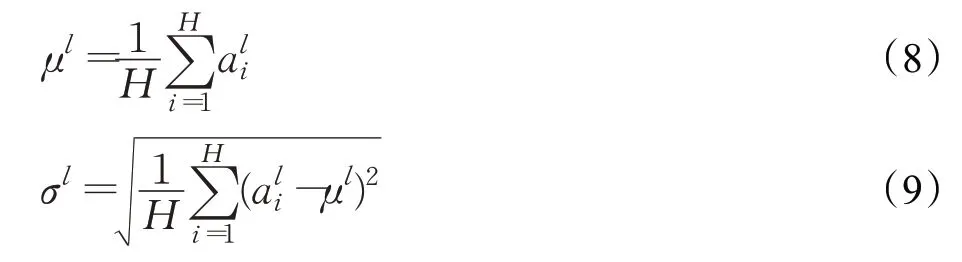
其中H是一層神經元的個數,一層網絡共享一個均值和方差,ai表示當前層中第i個神經元。
優點:批量大小較小時,效果好;適用于自然語言處理任務。
缺點:批量大小較大時,效果不如BN。
1.2.3 Instance Normalization
BN針對于對數據的歸一化,但對于圖像風格化任務來說,應注重于圖像實例的處理,Ulyanov等[15]提出Instance Normalization。與BN的不同之處在于,IN(instance normalization)作用于單張圖片的單個通道,對此單獨進行歸一化操作,而BN是對同一個批中的所有圖片的同一通道進行歸一化。圖4具體展示了BN、LN與IN的不同之處,BN是針對所有圖片同一通道,LN針對一張圖片的所有通道,而IN針對一張圖片的一個通道。IN歸一化表達式如式(10)所示,其中均值計算方法如表達式(11)所示,方差計算方法如表達式(12)所示。xtijk表示它的第tijk個元素,k和j代表空間維度,i是特征通道(如果輸入是RGB圖像,則是顏色通道),t是該圖像在當前批量中的索引。公式中ε是一個很小的正常量,以防止除0,H、W表示特征圖的高和寬。
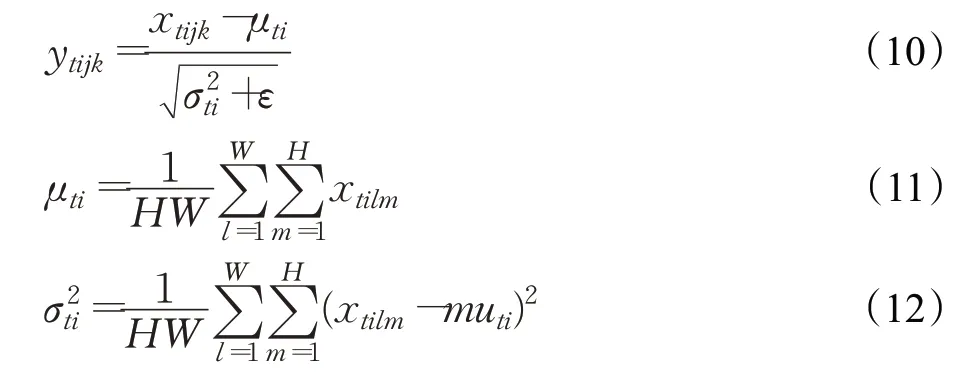
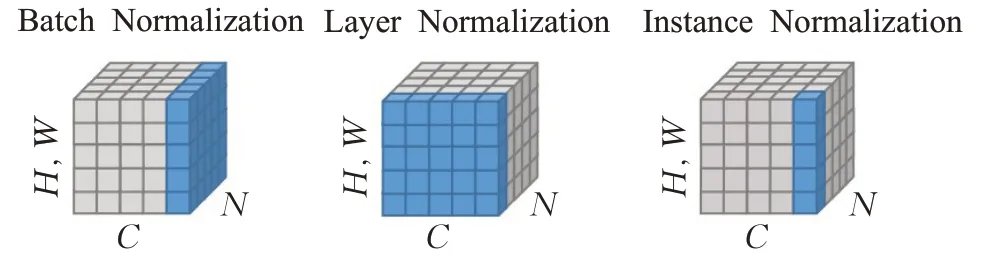
圖4 BN、LN與IN的對比Fig.4 Comparison of BN,LN and IN
優點:不受批量大小和圖片通道的影響。
缺點:丟失通道之間的相關性。
1.2.4 Group Normalization
在視覺識別任務上,Wu等[31]提出Group Normalization,在GN(group normalization)中,將圖片的通道分為不同的組,針對于不同的組來做歸一化操作。具體表現為將特征的維度由[N,C,H,W]重新修改為[N,G,C∥G,H,W],歸一化的維度為[C∥G,H,W],其中G是分的組的數量。
優點:不依賴批量大小。
缺點:當批量大小較大時,性能不如BN。
1.2.5 Switchable Normalization
不同的神經層可能需要不同的歸一化操作,而每一層歸一化都是由人工設計并操作,這將消耗大量人力。Luo等[32]設計了一個自適應歸一化層,通過建立一個通用的歸一化層來解決所有問題。主要操作是將BN、LN、IN分別賦予不同的權重并結合,由網絡自行學習調整。圖5展示SN(switchable normalization)的詳細計算方法。
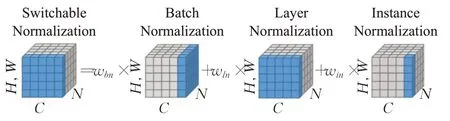
圖5 SN計算方法Fig.5 SN calculation method
優點:集BN、LN、GN優點于一身。
缺點:訓練復雜。
1.2.6 Filter Response Normalization
谷歌研究所的Singh等[33]提出FRN(filter response normalization)方法,旨在消除批量大小影響的同時也能獲得大批量下BN的性能。主要方法是設計一個歸一化層,里面包含一個歸一層和一個激活層。FRN方法具體框架如圖6所示,其中的歸一層類似于IN,是對單個圖片的單一通道操作的。FRN中v2是x的二次范數的平均值,歸一化層需要進行縮放和平移變換,γ和β是可學習的參數。
優點:不受批量大小的影響。
缺點:暫無。
綜上,本研究將隱藏層歸一化算法的方法與優缺點進行了對比。表2列出了隱藏層歸一化方法,從提出原因、方法、優點與缺點四個維度進行具體分析。通過表2可以看出BN主要用于解決內部斜變量遷移的問題。然而BN過度依賴批量大小,為解決此問題,繼而研究LN、GN、FRN等歸一化方法。當批量大小較大時,BN的效果仍為最優。不同的應用任務應選擇不同的歸一化方法,BN適用于計算機視覺任務;LN更適用于自然語言處理;對于圖像實例應用來說,IN為最佳選擇。
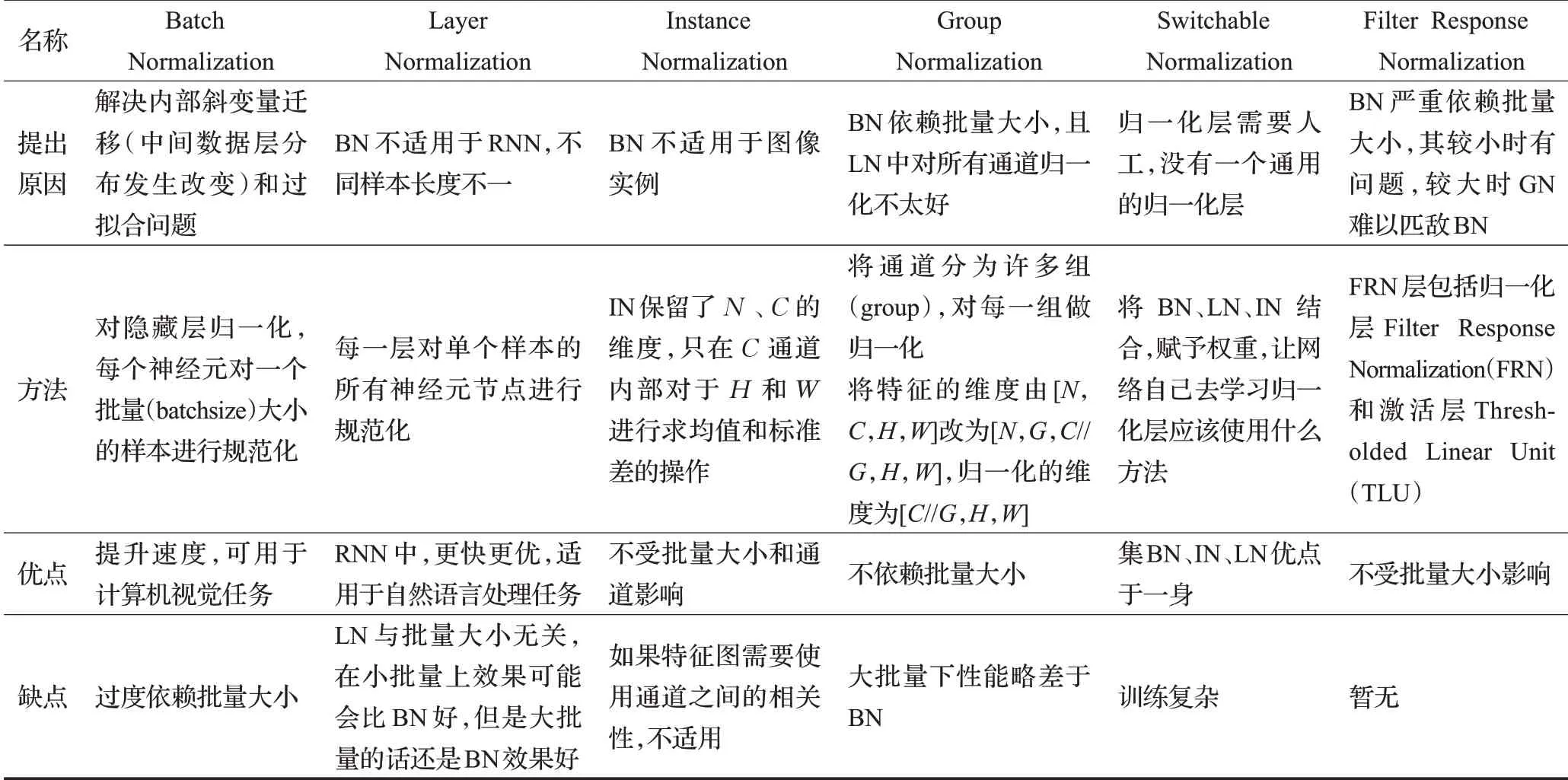
表2 隱藏層歸一化算法對比Table 2 Comparison of hidden layer normalization algorithms
2 流數據的歸一化法
大數據流具有不斷變化的性質,有嚴格的內存和時間限制以及學習訓練前無法獲得全部數據的特點,所以大數據流的預處理比批數據更具挑戰性[34]。但就目前為止,對于數據流的歸一化算法研究較少。預處理數據參數保持固定或手動調整可能導致預測結果不佳[35]。通常采用滑動窗口技術對流數據進行預處理參數調整。窗口的選擇對結果至關重要。本章重點從窗口選擇及流式數據下的歸一化法兩方面進行歸納分析。
2.1 窗口
由于流數據以流的形式輸入,需要使用滑動窗口或者翻轉窗口來暫時存放數據。流場景下,對于窗口的選擇也至關重要。
2.1.1 滑動窗口
在流處理應用中,對于數據的傳輸,通常使用滑動窗口技術。滑動窗口有一個固定的長度或時間長度,不停捕捉隨著數據流到來的數據,待窗口內數據被填滿(比如收集了5個數據)或滿足規定的時間長度(比如到達10 s)后,窗口根據規定的滑動長度向前移動并對窗口內數據進行處理。一般來說滑動長度小于或等于窗口長度,因此窗口是重疊的,相鄰的窗口每次都包含一些共同的元素。滑動窗口模型的優點是保持存儲空間,從最近的數據點保持新的知識和有效的處理。
圖7為滑動窗口模型的示意圖。如圖所示,定義了一個持續時間為10 s,滑動間隔為5 s的滑動窗口。第一個窗口(W1)包含從0~10 s到達的元素,第二個窗口(W2)包含從5~15 s的元素,每隔5 s,一些元素被添加,一些元素過期。例如在t=15時,e7、e8、e9、e10被添加到窗口,而e1、e2從窗口過期。通過這種方式,所有的元素都被處理,直至流的結束。
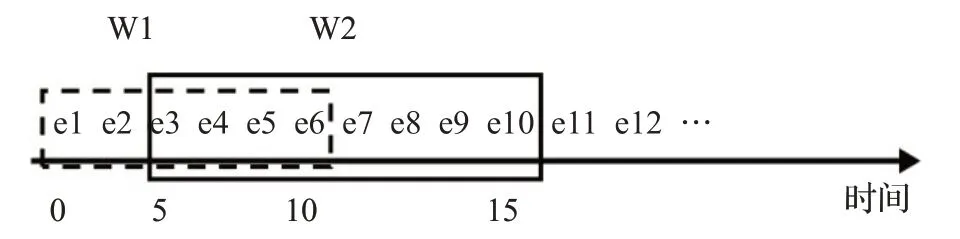
圖7 滑動窗口示意圖Fig.7 Sliding window diagram
2.1.2 翻轉窗口
翻轉窗口是滑動窗口的一個特殊形式。與滑動窗口不同的是,翻轉窗口沒有重疊的窗口,相鄰窗口沒有共同的元素。窗口的滑動長度或者時間間隔等于窗口長度。在翻滾窗口中,數據的處理都是在一個窗口內進行然后到下一個窗口,中間沒有任何重合部分。翻滾窗口收集隨著流到達的數據,當窗口長度或時間間隔達到規定長度時,滑動相應的長度到下一個窗口。翻轉窗口的示意圖如圖8所示。
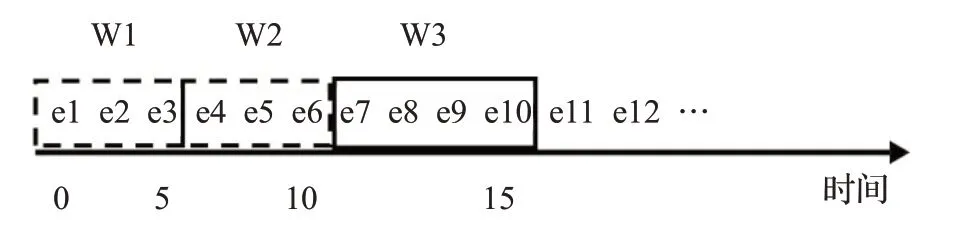
圖8 翻轉窗口示意圖Fig.8 Tumbling window diagram
圖8中定義了一個長度為5 s的翻滾窗口。第一個窗口(W1)包含0~5 s的元素,W2包含5~10 s的元素,然后W3包含10~15 s的元素,每隔5 s滑動此窗口,只有新的元素被添加到窗口中,沒有一個窗口重疊。例如在t=10時,e4、e5、e6被添加到窗口中,而e1、e2、e3則從窗口中過期。通過這樣的方式,整個數據流將被處理。
2.2 流數據輸入層歸一化方法
2.2.1 Smart Preprocessing for Streaming Data(SPSD)
大多數關于數據流挖掘的研究都將模型再訓練和預處理放在一起。但在真實流挖掘情況下,很多時候不需要對模型重新訓練,只需要對輸入的流數據進行重新歸一化的操作。Hu等[36]提出了一種SPSD的方法,該方法有兩個重點。
重點一:計算兩個指標。
指標一:新的流數據塊中至少有一個數據的值在參考的最小-最大值范圍樣本之外的百分比。目的是將噪音和異常值從數據流的實際變化中分離出來。
指標二:新的樣本數據在每個維度的值與該維度的參考最小-最大值之間的最大差異百分比。目的是減少重新規范化的次數,以加快方法的速度。
如圖9所示,當前的滑動窗口共有100個數據,其中有95個正常數據,5個異常數據。參考的最大最小值分別為2和-1,指標一的計算方法則為(5/100),假定存在一個值為3的數據x,對于數據x,指標二的計算方法則為[(3-2)/2=1/2]。
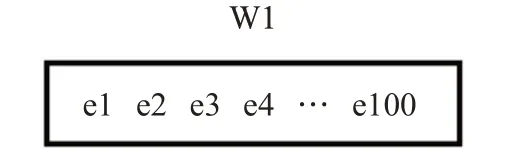
圖9 滑動窗口指標計算例子Fig.9 Example of sliding window indicator calculation
重點二:獲得指標返回值
算法中自定義兩個閾值,若兩個指標都超過閾值則返回真(True),反之則為假(False)(True表示重新進行歸一化操作,即用更新后的最大值和最小值來對數據塊做Min-Max歸一化操作;False表示暫時不更新最大最小值,用當前的最大最小值對窗口內的數據進行Min-Max歸一化操作)。
SPSD算法分為如下流程:
首先將第一個數據塊作為初始的參考數據塊,第一個數據塊的最大、最小值作為初始的參考最大、最小的范圍。
然后進行兩個指標計算,獲得指標返回值,進行Min-Max歸一化,將歸一化后的數據發送到基礎學習模型中進行分類。當前的這個數據塊則會取代原參考數據塊成為一個新的參考點,更新后的最大、最小值也將成為參考的最大最小范圍。
優點:減少模型再訓練的次數,降低新模型生成的成本。
缺點:某些時候效率與重新的模型再訓練相比會較低。
2.2.2 特征直方圖
在網絡安全方面,對于入侵檢測等應用,必須注意實時性,及時做好防護[37]。數據處理的操作大部分選擇在網絡邊緣的邊緣端進行,處理之后形成適用于數據分析的樣式[38]。
Lopez等[39]提出一種基于特征相關和特征歸一化的網絡流量分類的快速預處理方法。此方法基于特征直方圖的歸一化,特征直方圖即為用直方圖的形式來表示特征的劃分。具體實現方式如下。
滑動窗口的每個特征fi被劃分為b1,b2,…,bm,m=n1/2+1,n為特征的數量,b1=[min,k1),b2=[k1,k2),bm=[km-1,max](其中k表示閾值,k=(maxi-mini)/m)。每一個區間稱為bin,bk表示落在第k個bin中樣本的數量,每個bin的高度為樣本落在此區間的相對頻率fri,其中fri=fqj/N(其中N為樣本總數,fqj表示為樣本落在binj的數量)。樣本直方圖如圖10所示。
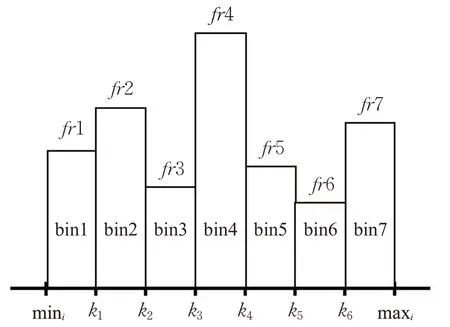
圖10 特征直方圖劃分Fig.10 Feature histogram division
對于每一個滑動窗口,首先獲取到每個特征的最小值和最大值,在生成單個滑動窗口的樣本直方圖之后再通過滑動窗口獲取新的最大、最小值。如果新的滑動窗口的最小值小于前一個滑動窗口的最小值或者新的滑動窗口的最大值大于前一個滑動窗口的最大值,即mini-1<mini或maxi-1>maxi,則創建新的倉,直至區間包含新的最小值或最大值再停止建倉。劃分好所有的倉之后,即特征直方圖建立完畢,再將所有的倉近似為正態分布則完成歸一化操作。與此同時,在建立新的倉的過程中,由于是動態建立,可以實時觀察到異常點的出現。
優點:可以實現流數據歸一化并檢測異常點。
缺點:計算效率不高,在無限數據的情況下,不適合在內存中存放。
2.2.3 窗口平均值變化百分比
為解決不斷變化的大數據流規范化問題,Gupta等[40]提出了一種分布式的大數據流自適應規范化的方法。此方法提供了一個簡單的機制,以適應每個窗口中不斷變化的數據的規范化統計。
主要方法如下:
第一步:獲取第一個窗口的統計數據(比如最大值、最小值、平均值等),將這些數據設置為初始的參考數據。第一個窗口使用這些參考數據進行Min-Max歸一化。
第二步:滑動到下一個窗口后,計算當前窗口和上一個窗口之間平均值的百分比變化,用于檢測是否有重大變化。自行定義一個閾值,如果百分比的變化超過閾值,當前窗口的最大最小值將取代原始的最大最小值作為新的參考值;反之,當百分比變化不超過閾值時,數據流變化被看成是不重要的,為保持最大最小的實際范圍并消除對一個窗口的依賴,參考的最大最小值將被逐步更新,選取兩個窗口更小或者更大的那個值作為新的參考值。
優點:可以應用于全領域的數據流。
缺點:閾值無法動態調整。
2.2.4 動態調節窗口大小
Gupta等[41]提出了一種基于自適應窗口大小的規范化方法,主要方法是根據數據速率來調整窗口大小。如果數據速率增加,則窗口大小減少;反之,如果數據速率減少,則窗口大小增加,以保證在一個理想的速率中處理數據,方法流程如下。
第一步:首先將第一個窗口作為當前窗口,使用當前窗口的最大最小值,對其進行Min-Max歸一化。
第二步:當下一個窗口到來時,將這個窗口代替前一個窗口作為當前窗口,比較當前窗口和前一個窗口的數據率,預測下一個窗口的大小或時間間隔。數據率百分比計算如下:rw=rc/rp(其中rc表示當前窗口的數據速率,rp表示前一個窗口的數據速率)。自行定義一個理想數據率r來作為閾值。比較rw和r的大小,如果rw小于r,則將窗口長度增加一個固定的常數c,反之,如果rw大于r,則將窗口長度減少一個固定的常數c,其中c自行定義。
第三步:改成理想速率的窗口大小后,用修改后的窗口里的最大值和最小值來對窗口中的數據進行Min-Max歸一化。
優點:能保持一個穩定的數據處理速度。
缺點:暫時沒有實驗來證明。
2.2.5 時間序列歸一化
對于時間序列數據來說,時序性是其重要特征[42]。由于時序數據具有高維度、動態性等特點,直接對時序數據進行分析會無法提取有用信息,甚至得出錯誤結果。對時序數據進行預處理也是時序數據分析的重要步驟[43]。在非穩定的時間序列流的歸一化方面,Passalis等[44]提出一種進入深度神經網絡前的深度自適應歸一化層,Ogasawara等[45]提出了一種對非平穩異方差(具有非均勻波動性)時間序列進行歸一化的新方法。該方法被命名為自適應歸一化(AN)。其完整的數據歸一化過程可分為三個階段:(1)將非穩態時間序列轉化為穩態序列,從而創建一個不相交的滑動窗口序列(不重疊);(2)去除離群點;(3)數據標準化。
具體步驟如下:
第一步:基于移動平均數,將非平穩的時間序列轉換成一個平穩的時間序列。先計算原始時間序列的移動平均數,使用其值來創建一個新的靜止序列,并將這個序列劃分成不相干的滑動窗口。
第二步:利用箱型圖來檢測數據的異常值,檢測出來的異常值根據情況進行調整。
第三步:對做過處理后的數據使用這個序列的全局統計信息(最大值、最小值等)進行Min-Max歸一化。
優點:每個相對的滑動窗口內保留原有的時間序列屬性。
缺點:暫無。
2.2.6 SUCR-DTW
在動態時間扭曲下時間序列的相似性搜索上,歸一化操作極有必要,Giao等[46]提出SUCR-DTW方法,包含增量化的歸一化法。主要方法如下:首先,用Quic-ksort算法從數據點創建一個升序數字數組,先對時間序列的子序列排序,然后插入新數據移除老數據,最后Min-Max歸一化。由于是時間序列歸一化的同時進行相似性搜索,相似性搜索過程中需要更新首尾的最大最小值,使用Quicksort對其進行排序,xmin是排序數組的第一個元素,xmax是最后一個。在刪除和插入的過程中必須保持數組的升序,所以還需要使用二進制搜索的算法來尋找需要刪除的元素和插入新數據點的合適位置。
2.2.7 NSPRING
在時間序列匹配上,Sakurai等[47]提出動態時間扭曲(dynamic time warping,DTW)距離下的子序列匹配方法SPRING,SPRING不支持歸一化,而歸一化在匹配中極為重要。Gong等[48]提出基于SPRING的歸一化方法NSPRING。該方法選取一個暫時性的子序列S′用于存儲原序列S,但S′的長度等于查詢序列Q,當一個新的時間節點進入,最開始進入的時間節點就會被刪除,維持S′的長度等于查詢序列Q的長度。隨著S′不斷更新,當S′的長度等于查詢序列Q時,NSPRING算法開始,存儲序列S′可以被用于計算整個時間序列的均值和方差,繼而對整個時間序列S進行Z-Score標準化運算,從而實現時間序列的歸一化。
表3列出多類流數據歸一化算法,從窗口及評判標準兩個維度進行對比。窗口細化分為固定窗口和滑動窗口,評判標準細化為4個評判標準,用于評判是否進行歸一化操作或者是否更新歸一化參數。

表3 流數據歸一化算法對比Table 3 Comparison of stream data normalization algorithms
3 總結與展望
數據歸一化是數據預處理的重要一步。無論是在深度學習還是時間相似性搜索等方面都起了極大的作用。本文收集并整理了歸一化方法相關文獻,從數據類型角度對這些歸一化方法進行劃分,凝煉提出了基于流數據的歸一化分類方法。將數據歸一化方法劃分為基于批數據的歸一化法和基于流式數據的歸一化法。本文首先對歸一化的研究現狀以及發展趨勢進行了詳細分析,通過收集相關文獻,以數據類型作為切入點,提出了基于流式數據的歸一化分類方法。然后,將批數據及流數據歸一化方法從學習模式與處理階段兩個維度進行梳理。在大數據流的場景下,對于窗口和輸入數據歸一化方法的選擇也至關重要。在不同的場景下,使用特定的方法可以更有效地防止神經網絡因數據量綱的復雜性而錯誤建模并提高預測正確率等。由于流式數據的應用需求日趨急迫,對流式數據的研究也逐漸成為各領域的重點。基于流數據的歸一化面臨著一些亟待解決的問題。
(1)海量樣本下歸一化算法的魯棒性。隨著大數據技術的發展,呈現出海量、復雜的數據特點。在海量數據的應用中,常常會出現異常值,而歸一化可能會受到異常值的影響。因此,如何在流式場景下,面對海量樣本的情況下,保證數據的魯棒性是當前需要解決的問題。
(2)自適應性。不同的流式數據應用需要與此最適合的歸一化方法,手動選擇并調整歸一化方法會消耗大量人力物力資源。到目前為止,并沒有一個通用的自適應方法以供選擇。
總體來說,由于流式數據應用必須在時間和資源的嚴格限制下處理數據,這為流數據應用帶來了極大的挑戰。流式數據場景下的歸一化研究相對缺乏,在流場景下的歸一化方法還有許多需要研究的方向。
(1)面向深度網絡的動態自適應歸一化法。當前深度神經網絡的應用作用于各行各業,并取得了顯著的效果。但對于深度學習的歸一化研究大多停留在隱藏層的歸一化方法,對于流式數據在輸入層的歸一化方法則相對缺乏。當前僅有的基于流式數據的歸一化方法需要手動調整,缺乏一個通用的歸一化方案。將來關于歸一化的研究應該致力于如何避免消耗大量人力資源下對流數據進行自適應的動態歸一化操作。在深度神經網絡中使用這樣的方法是當前的一個重要研究方向。
(2)大數據流下歸一化法。數據的大規模增長是當前大數據分析的一個主要問題。由于大數據呈現出海量、復雜的數據特點,在數據挖掘等應用下,對大數據應該進行歸一化的預處理,以實現應用更好的性能與精度。而大數據流處理方法對時間和資源有著嚴格的限制,這對流式場景下的歸一化研究具有重大挑戰。因此,如何在大數據流場景下,設計一種更具適應性歸一化方法具有重要的理論意義與實用價值。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
