基于CSAEMD-KECA和角結構距離的齒輪故障識別方法*
2023-02-13 05:58:18高慶云陳長華
機電工程 2023年1期
高慶云,郭 力,陳長華
(1.杭州職業技術學院,浙江 杭州 310018;2.重慶交通大學 機電與車輛工程學院,重慶 400074;3.重慶長江軸承股份有限公司,重慶 401336)
0 引 言
由于機械設備的振動信號總是包含著豐富的信息,從中可以了解機械設備的運行狀態。毫無疑問,基于振動信號處理的故障診斷技術對于監控關鍵結構或設備的健康狀況至關重要[1]。一般來說,傳感器用于獲取機械振動信息,從這些信息中,人們可以獲取機械設備運行狀態的特征[2]。
在對機械設備進行智能故障診斷時,提取到的原始振動信號中通常會存在噪聲的成分,需要一種模式分解方法對原始信號進行分解重構,從而減少噪聲信號對智能故障診斷分類過程的干擾。
在機械設備原始信號分解方面,經驗模式分解方法(empirical mode decomposition,EMD)是一種常用的信號分解方法。通過EMD分解,振動信號可以被分解成一系列的固有模態函數(intrinsic modal function,IMF)。MENG De-biao等人[3]采用EMD方法,對風電機組滾動軸承的故障信號進行了分解,然后對分解后的數據進行了時域和頻域上的特征提取,提高了滾動軸承故障診斷的準確率。SUN Yong-jian等人[4]提出了一種基于EMD和改進切比雪夫距離的滾動軸承故障診斷方法,采用EMD方法,將其信號分解為幾個IMF,然后利用改進的切比雪夫距離方法,實現了對軸承的故障診斷。HANG Dong-ying等人[5]提出了一種基于EMD、粒子群優化支持向量機(particle swarm optimization support vector machine,PSO-SVM)和分形盒維數3種方法相結合的故障診斷方法;該方法首先采用EMD,將齒輪原始振動信號分解成了若干個IMF,然后分別從時域、頻域、能量域和分形域計算了其特征,最后將特征矩陣輸入到PSO-SVM分類器中,進行齒輪故障分類,提高了齒輪故障分類的準確率。
然而,EMD分解是不穩定的,并且存在模式混合問題,這種問題導致某個IMF分量包含不同尺度信號,或者相似尺度信號存在于不同IMF中,使基于EMD的信號分解有可能丟失重要的特征信息[6]。
為了解決這一問題,ZHANG Xiao-bo[7]采用集成經驗模式分解(ensemble empirical mode decomposition,EEMD),對小波包處理后的不同齒輪故障模式的信號進行了分解,得到了更為有效的故障信號,提高了齒輪故障診斷時的診斷精度和診斷效率。ZHAN Yu-jie等人[8]提出了一種基于EEMD和雙向長短期記憶(bi-directional long short-term memory,BILSTM)的多軸承壽命預測方法;該方法先利用EEMD,將原始振動信號分解成了有限個IMF,然后通過相關性準則和峭度信號的重構,對重構信號進行時域和頻域上的特征選取,最后在選取的特征集上訓練BILSTM網絡,實現了軸承的剩余壽命預測。MA Biao等人[9]提出了一種基于EEMD能量熵和SOM神經網絡(SOM neural networks,SOM-NN)的故障診斷新方法;該方法首先利用了EEMD方法,將齒輪在各種狀態下的原始振動信號分解為若干個本征模態函數IMF,并計算了每個IMF的能量值和信號的能量熵,然后選取IMF能量占比和信號能量熵,組成一組能夠反映故障振動信號的特征,最后將這些特征值輸入SOM神經網絡中,進行故障分類,提高了齒輪故障識別的準確率。
EEMD是通過使用噪聲來輔助信號的分解,從而緩解EMD中的“模式混合”現象[5]。但EEMD在背景噪聲較強,且故障過早的情況下,其去噪效果并不理想。
為了盡可能地減少噪聲信號在原始信號中的殘余,陳克等人[10]采用在原始信號上加入了正負噪聲的方法,以抵消信號中加入的噪聲,減少了噪聲分量的產生;此外,該方法也提高了其計算效率。這種方法被稱為互補總體經驗模式分解(complementary ensemble empirical mode decomposition,CEEMD)。
受加入噪聲信號輔助分解思想的啟發,筆者提出一種新的正弦波輔助分解方法(complementary sineassisted empirical mode decomposition, CSAEMD),通過對原始信號進行分解,即在原始信號上加入正負正弦分量信號,以此作為參考尺度,用來緩解模式混合。
在使用模式分解方法進行分解重構,獲得了能夠表征故障特征的信息特征后,機械設備故障智能診斷的一個關鍵環節就是,尋找一種準確率高、自適應強的故障識別方法。
在機械設備的故障識別方面,韓松等人[11]提出了一種基于主成分分析(principal component analysis,PCA)和支持向量機(support vector machine,SVM)的滾動軸承故障識別方法,提高了軸承故障識別的準確率。ZHU Jing等人[12]采用PCA方法,進行了滾動軸承的智能故障識別。LI Hua-ping等人[13]針對振動信號傳輸路徑復雜,不同傳感器位置對診斷結果影響較大,以及旋轉機械故障診斷特征提取困難等問題,提出了一種基于PCA和深度信念網絡(deep belief network,DBN)的故障診斷新方法。
PCA[14]是一種典型的線性降維方法,它將N維特征降維到k維上,用這些k維特征構成能夠反映樣本特征的新數據集。但是,由于齒輪的故障信號往往伴隨著很多非線性特征,采用PCA進行齒輪故障模式的聚類識別時,往往會導致錯誤的聚類。
核主成分分析(kernel principal component analysis,KPCA)是通過引入核方法,將線性主元分析拓展到非線性的方法。KPCA的核心思想是將輸入數據映射投影到高維特征空間,并通過分解其核矩陣,得到特征值和特征向量。KPCA常見的做法是選擇特征值最大的前k個特征向量,然后進行后續操作。
然而,在選擇特征向量時,KPCA方法通常以方差的大小作為標準,而方差的大小又取決于特征變量所攜帶的信息量。因此,在實際的應用中,采用這種選擇方法并不能達到最佳的聚類效果。
核熵成分分析(kernel entropy component analysis,KECA)是JENSSEN R提出的一種新的特征提取方法[15]。與KPCA相同,KECA需要對輸入數據進行分解,并得到其特征值和特征向量。與KPCA所不同的是,KECA選擇對輸入信號瑞利熵貢獻值大的特征向量,并將輸入信號投影到特征向量,形成全新的數據特征。KECA選取成分的過程中,不僅考慮了特征值的作用,而且考慮了對應特征向量的作用,因此,其考慮的因素更加全面。
利用KECA進行多種數據實驗時,發現不同類別的數據間呈現明顯的互成一定角度的特點(可稱為角結構特點)。具體而言,在利用KECA進行多種數據分析時,不同類別的樣本往往互相垂直,而相同類別的樣本往往共線。
因此,筆者利用樣本間的余弦值表征樣本的相似性,進而進行聚類分析,稱為基于角結構距離的聚類方法。
綜上所述,筆者提出一種基于CSAEMD-KECA的齒輪故障識別方法。首先,采用CSAEMD對齒輪故障數據進行分解,去除原始信號中存在的噪聲分量,并盡可能地保留其重要特征信息;然后,選擇與原始信號相關最大的分量進行重構,獲得能夠表征齒輪故障特征信息的信號;接著,采用KECA方法進行特征提取,獲得具有角結構特征的投影向量,并將CSAEMD分解重構后的信號向投影向量投影,得到包含齒輪故障信息的新數據集;最后,采用基于角結構距離的聚類方法進行聚類分析,實現對不同齒輪故障模式的聚類識別目的。
1 理論描述
1.1 EMD理論
經驗模態分解(EMD)方法是由LEI Ya-guo等人[16]提出的。EMD可以把信號分解為多個IMF。IMF滿足以下兩個條件:
(1)極值的數量和零交叉的數量相差不能超過1;
(2)局部包絡平均值為零。
IMF代表嵌入在信號中的簡單振蕩模式。基于任何信號包含不同的簡單IMF的假設,筆者引入EMD方法將信號分解為IMF分量。
筆者對經驗模式分解(EMD)方法進行研究。EMD方法的步驟如下:
(1)初始化r0=x(t),并且i=1;
(2)提取IMF分量ci,IMF分量提取的過程如下:
(a)初始化h(k-1)=ri-1,k=1;
(b)求h(k-1)的局部最大值和極小值;
(c)用三次樣條線對局部極大值和極小值進行插補,形成h(k-1)的上、下包絡;
(d)計算h(k-1)的上、下包絡的平均最小m(k-1);
(e)hik=hi(k-1)-mi(k-1);
(f)如果hik是IMF,則設置ci=hik,否則轉到步驟(b),然后k=k+1。
(3)定義冗余分量ri+1=ri-ci;
(4)如果ri+1仍然有2個極值點,然后執行步驟(2)i=i+1,否則分解結束,ri+1是冗余分量。
1.2 CSAEMD理論
正弦波輔助分解(CSA-EMD)方法是在EMD基礎上進行改進的,其核心思想是構建一個復合正弦信號。其構造的正弦信號形式為:
(1)
式中:N—輔助信號中正弦波的數量;ci—第i個正弦波的幅值;fb—第i個正弦波的頻率。
與CEEMD在原始信號上加入分布在整個頻譜的高斯白噪聲信號不同,CSAEMD加入正負兩組與原始信號主要頻率大致相等的正弦輔助信號,并進行分解,取這兩組相同階數的IMF平均值。如果只加入正的正弦分量,則會代入其他頻率分量。
正弦波的設定標準如下:
因為CEEMD是根據準二元濾波器對齊IMF,以此來減少模式混合現象,同樣也可以在原始信號上添加與原始信號主要頻率大致相等的正弦分量作為參考模式,以提取出故障特征頻率。輔助信號的頻譜范圍不能超過原始信號范圍[flow,fhigh]。
相關研究表明[17],EMD相鄰頻率比大于1.4時,有較輕微的模式混合現象,因此,幅值信號的相鄰頻率比需要大于1.4。盡量將輔助信號的頻率與原始信號的主要頻率分量設為一致。當頻譜的主要頻率相鄰頻率比大于1.4時,則將正弦分量設為等于原始信號的主要頻率;反之,則盡可能使其靠近原始信號的主要頻率。
通過反復實驗,結果表明:正弦波的幅值設定為原始信號平均幅值的6倍時,分解效果最好。
當正弦波振幅、頻率確定,輔助信號即構造完成。其算法的具體步驟如下:
(1)首先使用快速傅里葉變換,分析原始信號的頻譜,得到原始信號的主要頻率分量;
(2)按相鄰正弦分量大于1.4的標準,設定正弦輔助信號;
(3)將構建的正負正弦波信號分別加入原始信號中,使用EMD分別對加入正負正弦分量的兩組信號進行處理;
(4)將兩組信號分解得到IMF,按照對應階數求其平均值,得到的IMF平均值,即為所求。
1.3 核熵成分分析理論
KECA的特征提取過程如圖1所示。

圖1 KECA特征提取過程
從圖1可以看出,KECA的具體步驟為:
(1)根據原始數據,確定核函數及其參數,計算原始數據的核矩陣K;
(2)由式K=EDλET對原始數據核矩陣進行分解,得到特征值和對應的特征向量(其中:Dλ—由特征值λ1,λ2,…,λN所組成的對角矩陣;E—對應的特征向量e1,e2,…,eN組成的矩陣);

(4)計算主成分,TN×K=KN×NEN×K。

1.4 基于角結構距離的聚類方法
基于角結構距離的聚類過程如圖2所示。
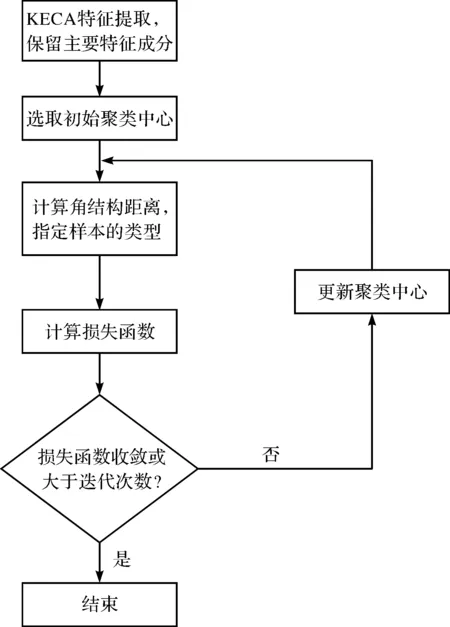
圖2 KECA聚類流程圖
從圖2可以看出,KECA聚類的具體步驟為:
(1)利用KECA進行特征提取,即根據上述相關分析,計算特征成分,并獲取主要的特征成分;
(2)初始化聚類中心mi,i=1,2,…,C;

CS損失函數是測量核特征空間中數據集Φ的均值向量之間的cos值。例如,第i類樣本的概率函數pi(x)和整體數據概率函數p(x)間的CS收斂函數可表示為:
Dcs(pi,p)=-logVcs(pi,p)
(2)
其中:
(3)
假設有來自于類別Ci,概率密度函數為pi(x)的Ni個數據點組成的數據集xi∈Di;來自于概率密度函數p(x)的N個樣本組成的全體數據樣本集。
在核特征空間中,基于角距離的損失函數可表示為:
(4)
(4)更新聚類中心mi,i=1,2,…,C;
(5)重復(3)和(4),直到收斂或者循環次數大于某一設定值(筆者設定收斂條件為J的變化小于10-3,循環次數的最大值為1 000)。
1.5 基于CSAEMD-KECA的計算流程
筆者提出的基于CSAEMD-KECA的齒輪故障識別方法,其計算流程如圖3所示。

圖3 基于CSAEMD-KECA方法計算流程
從圖3可以看出,基于CSAEMD-KECA方法主要包括以下3個步驟:
(1)采用振動傳感器采集不同故障狀態下的齒輪振動數據;
(2)對采集到的齒輪振動數據,采用CSAEMD進行分解,選取相關最大的IMF分量進行重構;
(3)確定KECA的核參數,采用KECA對重構后齒輪的故障數據進行特征提取,并采用基于角結構距離的聚類方法進行聚類,以實現齒輪不同故障模式的聚類識別。
2 仿真分析
為了驗證互補正弦輔助經驗模式分解方法(CSAEMD)具有良好的分解性能,筆者對其進行數值模擬分析。
仿真信號由多個正弦分量和高斯白噪聲組成,其具體形式為:
x1=sin(2×π×f1×t)x2=sin(2×π×f2×t)x3=sin(2×π×f3×t)x=x1+x2+x3+w(t)
(5)
其中,f1=45 Hz,f2=70 Hz,f3=110 Hz。仿真信號由3個正弦分量構成,為了使仿真信號符合實際要求在正弦分量信號上加入噪聲信號。
仿真信號的時域圖如圖4所示。

圖4 模擬信號時域圖
筆者采用EMD對模擬信號進行分解,得到EMD分解結果如圖5所示。

圖5 EMD分解結果
由圖5可知:通過EMD分解的IMF分量有較嚴重的模式混合現象;同時,IMF3和IMF4也包含頻率45 Hz,頻率110 Hz主要包含于IMF2,也少量包含于IMF3。
筆者使用CEEMDAN分解模擬信號,得到的CEEMDAN分解結果如圖6所示。

圖6 CEEMDAN分解結果
從圖6可以看出:CEEMDAN也有模式混合現象,IMF3和IMF2都包含了頻率45 Hz,頻率70 Hz既包含于IMF2,也少量包含于IMF1。
CSAEMD分解模擬信號得到CSAEMD分解結果如圖7所示。

圖7 CSAEMD分解結果
從圖7可以看出:CSAEMD沒有明顯的模式混合現象,IMF 2、IMF 3、IMF 3分別包含頻率45 Hz、70 Hz、110 Hz。
筆者通過仿真信號,驗證了CSAEMD的優異分解性能,能減輕EMD存在的模式混合現象。
3 實驗及結果分析
3.1 原始信號的分解重構
為了進一步驗證上述方法的可行性,筆者搭建了故障模擬實驗臺,并在故障模擬實驗臺上采集實際數據。
故障模擬實驗臺主要由電機、聯軸器、齒輪箱、軸承、制動器組成。
實驗臺的實物圖如圖8所示。

圖8 齒輪故障綜合實驗臺
實驗臺中的齒輪位于齒輪箱里面。筆者將振動傳感器置于齒輪箱外面進行數據采集,主要采集正常狀態、齒輪斷齒、齒輪磨損3種不同故障模式下的振動信號。實驗中的采樣頻率設置為2 000 Hz。
實驗獲得實際信號中,正常狀態齒輪的時域圖如圖9所示。

圖9 正常信號時域圖
實驗獲得實際信號中,磨損狀態齒輪時域圖如圖10所示。

圖10 磨損狀態信號時域圖
實驗獲得實際信號中,斷齒狀態齒輪時域圖如圖11所示。

圖11 斷齒狀態信號時域圖
在正常狀態、齒輪磨損、齒輪斷齒3種不同故障模式下,筆者采用CSAEMD分解方法對其振動信號分別進行分解,并得到其分解結果的主要分量。
正常信號分解結果如圖12所示。

圖12 正常信號分解結果
磨損信號分解結果如圖13所示。

圖13 磨損信號分解結果
斷齒信號分解結果如圖14所示。
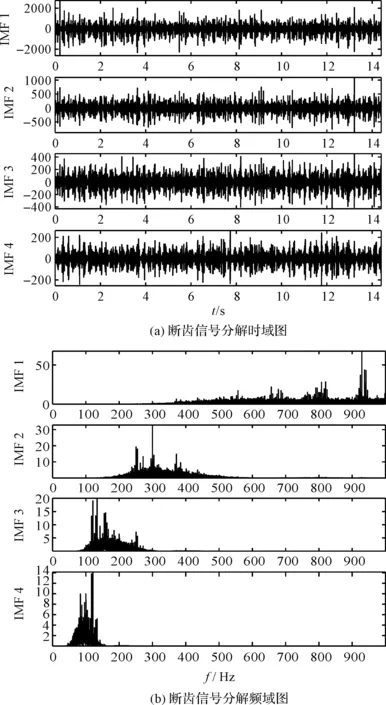
圖14 斷齒信號分解結果
3.2 核參數的選取
筆者使用CSAEMD對齒輪故障模式進行分解,并使用相關系數法,選擇與原始相關最大的分量重構,再采用KECA對重構后的信號進行分析。
此處所采用的KECA中的核函數為高斯核函數,即:
(6)
式中:σ—高斯核函數的核參數。
核參數自適應選取的準則如下:
類內離散度為:

(7)
類間離散度為:

(8)
其中,Sw和Sb的取值范圍為[0,1]。Sw表征同類樣本基于角結構距離的相似程度;Sb表征不同類別樣本間的相似程度。
在聚類分析中,目標是使類內離散度盡可能大,類間離散度盡可能小。因此,筆者采用基于角結構的類內和類間離散度的差作為選取的準則函數,即:
J=maxc,σ(Sw-Sb)
(9)
根據SHI J B和MALIK J[18]提出的核參數選取方法,首先要給出核參數選取區間(高斯核函數中的核參數通常取值為樣本空間中歐式距離的中值的10%—20%),然后利用基于角結構的類內類間離散度的差為準則函數,自適應地選取合適的核參數。
此處,筆者選取正常狀態、磨損、斷齒3種齒輪故障模式各20個樣本,進行聚類分析[19,20]。經計算,在經過CSAEMD分解重構后的樣本空間中,歐式距離為4.004;因此,筆者選取核參數選擇區間為[0.4,0.8];然后,利用基于角結構的類內類間離散度的差為準則函數,自適應地選取合適的核參數。
核參數的取值和準則函數值的對應關系如圖15所示。

圖15 不同核參數下的準則函數值
從圖15可以看出:當核參數取值為0.5時,對應的準則函數值最大,為8.289。
因此,筆者選用0.5作為KECA中高斯核函數的核參數。
3.3 聚類分析
筆者運用樣本間的cos值度量樣本的相似性時,不同類別的數據間呈現明顯的互成一定角度的特點(稱為角結構特點)。在確定核參數和聚類數之后,采用KECA方法對數據進行分析,并引入KPCA進行對比(KPCA中核參數的選取方式及選取結果與KECA相同)。
經CSA-EMD分解重構后,齒輪故障數據(原始數據)的核矩陣如圖16所示。
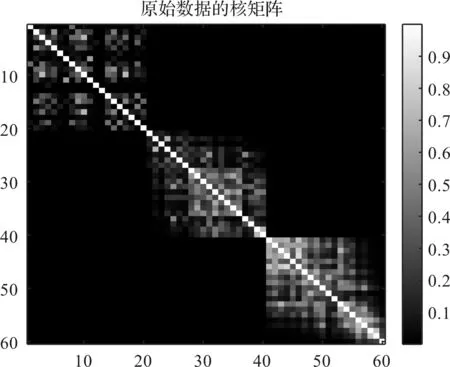
圖16 原始數據的核矩陣
從圖16可以看出:原始數據的核矩陣沒有出現明顯的分塊結構。
為了進一步比較KPCA和KECA特征提取過程的性能差異,筆者利用選定最優核參數的KPCA和KECA,分別對原始數據進行特征提取,得到KPCA的核矩陣、KECA的核矩陣,如圖17所示。

圖17 不同方法下的核矩陣
從圖17可以看出:KPCA的核矩陣沒有出現明顯的分塊結構;
KECA的核矩陣出現一定的分塊結構,這說明KECA的特征提取效果要優于KPCA。
為了評價KECA和KPCA選取特征向量的標準,筆者用KECA和KPCA分別對原始數據的核矩陣進行分解,得到的特征值和瑞麗熵值,如圖18所示。

圖18 標準化特征值與瑞麗熵貢獻值

基于前3個最大特征值及其特征向量變換后的數據,以及基于前3個對瑞麗熵值貢獻最大的特征值及其特征向量變換后的數據,筆者分別利用KPCA、KECA進行數據分析,得到采用不同方法選擇的3個主成分,如圖19所示。

圖19 不同方法選擇的3個主成分
從圖19可以看出:KPCA進行數據分析時,變換后的數據沒有出現一定的角結構,這樣會出現部分樣本分類錯誤;
利用KECA進行數據分析時,變換后的數據在空間中基本上互相正交,具有明顯的角結構特性。
從上述比較結果可以看出:在齒輪故障數據處理方面,相對于KPCA,KECA能夠更有效地提取出齒輪故障數據的本質特性,利用角結構特性能夠得到更好的聚類效果,從而實現對3種不同齒輪故障模式的聚類識別。
為了進一步說明不同算法的可靠性,筆者給出了PCA、KPCA、KECA的聚類結果。其中,PCA沒有引入核方法,采用的是直接降維聚類;KPCA和KECA采用余弦矩陣進行聚類。
其聚類準則如下:通過兩個方法進行特征提取后,不相似樣本的特征向量在新的特征空間中是垂直的,而相似樣本的特征向量是共線的,即不相似樣本的余弦值為0,而相似樣本的余弦值為1。因此,兩個樣本越相似,其余弦值就越接近1;兩個樣本越不相似,其余弦值就越接近0。
綜上所述,樣本間的余弦值可以作為聚類效果的度量。
采用不同方法得到的聚類結果如圖20所示。
從圖20可以看出:PCA用作齒輪故障模式聚類時,沒有將相同的齒輪故障類別聚在一起,說明PCA的聚類結果不理想;

圖20 不同方法聚類結果
當采用KPCA和KECA進行聚類分析時,cos值圖的橫縱坐標都表示樣本編號,當聚類正確時,相同類別編號對應的cos值會無限接近于1,這時候,樣本間的余弦矩陣就會呈現出明顯的分塊結構特點;
KPCA的余弦矩陣中第一、二類樣本間沒有明顯塊結構,第三類樣本間出現較好的塊結構特點,這表明KPCA僅實現第三類部分樣本的聚類,聚類效果較差;
當采用KECA時,余弦矩陣具有明顯的分塊結構,實現三類樣本的聚類。
實驗結果表明,KECA在齒輪故障模式識別的聚類分析中具有良好的性能。
為了進一步說明KECA方法的有效性,筆者還計算了各個方法聚類的準確率。
采用不同聚類方法得到聚類的準確率如表1所示。

表1 不同聚類方法聚類準確率 (%)
從表1可以看出:PCA對于齒輪正常狀態、齒輪磨損、齒輪斷齒的聚類準確率都為0,聚類總準確率為0;KPCA對于齒輪正常狀態、齒輪磨損、齒輪斷齒的聚類準確率分別為0、0、90%,總準確率為30%;KECA對于齒輪正常狀態、齒輪斷齒、齒輪磨損的聚類準確率分別為100%、100%、95%,總準確率為98.33%。
以上計算結果表明:KECA方法在齒輪故障模式識別的聚類識別中的性能可靠。
綜上所述,采用基于CSAEMD和KECA的方法,對齒輪故障進行模式識別是可靠的。
4 結束語
針對原始齒輪故障信號存在噪聲分量,影響故障識別的問題,筆者提出了一種基于CSAEMD-KECA和角結構距離的齒輪故障識別方法。
首先,利用CSAEMD方法對原始齒輪故障信號進行分解重構,增強信號的魯棒性,在去除信號中噪聲分量的同時,盡可能地保留其原始特征信息;然后,利用KECA對重構后的信號進行特征提取,根據瑞麗熵貢獻值的大小進行投影向量的選取,并構成新的數據集;最后,利用基于角結構距離的聚類方法進行聚類,實現對齒輪故障模式的聚類識別目的。
研究結論如下:
(1)利用CSAEMD方法對原始數據進行了分解重構,即在原始信號中加入與原始信號主要頻率大約相等的正負正弦分量,減少了模式混合問題,使原始信號在去除噪聲分量的同時,不會丟失重要的特征信息;
(2)利用基于KECA對CSAEMD分解重構后的齒輪故障信號進行了特征提取,選取了對樣本瑞麗熵貢獻值較大的3個特征向量作為投影向量,不同故障信號的投影向量互成一定的角結構。樣本數據向投影向量投影,形成了特征數據集;
(3)利用基于角結構距離的聚類方法,對特征數據集進行了聚類分析,實現了對不同齒輪故障模式的聚類識別目的,聚類的準確率達到了98.3%。
在目前的研究中,僅是針對齒輪故障模式時域上的數據進行聚類分析,并沒有考慮到頻域數據所包含的特征信息,所以導致其所提取的特征不夠全面。
在后續的研究中,筆者將考慮同時對預處理后的信號進行時域、頻域、小波域上的特征提取,以進一步提高齒輪故障模式識別的準確率。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
電子制作(2018年11期)2018-08-04 03:25:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
汽車維修與保養(2015年6期)2015-04-17 03:31:50
