面向6G通感算融合的多粒度資源分配算法
2023-02-09 12:24:00金仙美王佳妮趙力強朱伏生
無線電通信技術 2023年1期
金仙美,王佳妮,趙力強, 朱伏生
(1.西安電子科技大學 通信工程學院,陜西 西安 710068;2.廣東省新一代通信與網絡創新研究院,廣東 廣州 510700)
0 引言
隨著信息技術的發展,接入互聯網的流量大小 與移動網絡應用場景數量都在飛速增長[1]。多樣化的業務場景對時延、可靠性、帶寬、接入數量等通信需求越發嚴苛,數目激增的無線通信和IoT設備導致用戶需求和無線資源與算力資源之間的矛盾愈發突出。現有的資源分配模式單一,且缺少用戶行為感知,難以精確刻畫業務需求變化趨勢,導致運營商提供的網絡服務質量和網絡管理質量下降[2]。解決問題要求運營商實時感知網絡狀態,預測用戶需求變化,提前調配、預留網絡資源,避免資源緊缺現象發生。因此需要設計面向6G(6th Generation Mobile Communication System)網絡的通感算融合資源分配算法,實現無線資源精確、按需分配,提高網絡資源利用率的同時保證用戶的服務質量(Quality of Service,QoS)。
而無線接入網中,網絡環境復雜多變,網絡中的資源種類繁多,但資源總量有限[3],傳統的基于數學模型的網絡優化方法不再適用[4-6],因此算力、存儲以及網絡資源分配問題得到許多研究人員的關注。其中深度強化學習(Deep Reinforcement Learning,DRL)算法可以通過與未知環境交互來實現系統性能的自我優化,從而受到極大的研究關注[7-9]。文獻[10]使用幾種DRL算法敏銳地捕捉來自不同切片的用戶需求,從而產生資源分配策略,并在平臺上實施和評估這些算法,驗證所研究方法的優越性能。為使資源分配更加精細化,有研究者提出基于多時間尺度的資源分配方法。文獻[11]提出一個分層DL框架,在每個長時隙中,服務提供商采用DRL算法來確定切片配置參數,在每個短時隙和小時隙中增強移動帶寬(Enhanced Mobile Broadband,eMBB)和低時延高可靠通信(Ultra-Reliable Low-Latency Communications,uRLLC)調度器使用DNN算法分別將無線資源分配給相應的用戶。文獻[12]中也提出一種雙層控制粒度的智能無線接入網(Radio Access Network,RAN)切片策略,旨在最大化服務的長期QoS和切片SE,其中上層控制器通過業務流量的動態變化自適應調節切片配置以確保QoS性能,而下層控制器在小時間尺度上給用戶分配無線資源來提高切片的SE。但是上述資源分配算法沒有考慮頻繁調整資源分配策略帶來的損耗問題。
綜上,常見的資源分配算法均只考慮在同一時間粒度內對資源進行調整,資源管理粒度單一,難以應對高度復雜的場景建模,隨后衍生出雙時間尺度資源分配算法。雙時間尺度的資源分配算法在兩個不同的層面分別采用大尺度的粗粒度資源管控和小尺度的精細化資源調配,對資源的管理更加高效方便。但在無線通信的實際應用場景中,基站內資源分配操作的更新,需要耗費基站本身的計算資源。因此,適當的改進資源調整的頻率,在多時間粒度上給基站和用戶的資源進行調整,可以減少調整資源的成本,從而緩解算法在實際場景中占用資源較多的問題。
針對上述面臨的一些復雜的無線接入網智能感知與資源分配問題,提出一種面向6G通感算融合的多粒度資源分配算法。將RAN中的通信、感知、計算資源聯合優化問題建模為最大化效用函數問題(即所有用戶的時延、頻譜效率以及調整資源成本的加權和),并滿足用戶所能容忍的最小數據傳輸速率、所有用戶與基站占用的資源不超過系統總資源等約束,進而獲得最優的資源分配策略。
1 系統模型
對于用戶的感知信息(用戶未來流量、業務類型),采用常用的方法進行感知。文中對流量的預測包含用戶的流量預測和基站的流量預測,統稱為流量預測,采用多步預測的Seq2Seq模型,由于其內部存在編碼器和解碼器兩部分,可以更好地表征歷史數據特征并且用此特征進行未來數據的預測。在業務估計方面采用的卷積神經網絡(CNN)自動提取流量數據特征進行業務估計。本文重點在于利用流量預測與業務估計的結果實現基于通感算融合的多粒度資源分配算法,下面重點說明對多粒度資源分配算法的建模。
1.1 數據傳輸模型
時間維度被劃分為多個傳輸時間間隔(Transmission Time Interval,TTI),某一時間間隔被記為t∈{0,1,2,3,…,T},T為資源分配策略中的最大有效時間長度。共有N個用戶設備與基站之間通過無線鏈路進行信息傳輸,某一用戶設備被記為n∈{1,2,3,…,N}。則用戶n在某一時間間隔t內占用的帶寬資源表示為:
Bn,t=1.8×105×en,t,
(1)
式中,en,t為基站在某一時間間隔t內分配給用戶n的RB數量,而每個RB所占用的帶寬為180 kHz。
在時間間隔t內用戶n與基站之間的信噪比(signal-to-Noise Ratio,SNR)可以定義為:
(2)
式中,σ2為加性高斯白噪聲功率,gn,t為用戶n與基站相連接的無線信道在時間間隔t內的信道增益,pn,t為無線信道的發射功率,那么基站在時間間隔t內向用戶n傳輸數據的速率可以表示為:
(3)
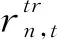
(4)
1.2 基站計算模型
基站處理數據的速率也是影響用戶QoE的一個重要因素,而基站處理數據的速率與基站的計算資源有關。因此,本節對基站的計算過程進行建模。
基站在某一時隙t內的計算速率定義為:
(5)
式中,ωt為基站分配的計算資源,單位為cycles/s,φBS>0表示基站處理一位數據流所需的計算周期,單位為cycles/bit,由應用程序的屬性決定,假設該值為一個定值,不會隨時間的變化而變化,則基站在時間間隔t內處理所有數據的時延可以表示為:
(6)
式中,ft為基站在某一時間間隔t內需要處理的數據量大小,為所有用戶的流量之和。
1.3 用戶QoE建模
記基站在時間間隔t內發送給某一用戶設備n的數據量為fn,t,則下一個時間間隔t+1內基站需要發送給用戶n的流量可以表示為:
(7)
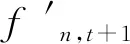
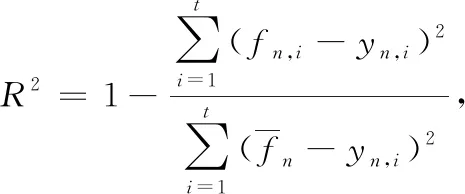
(8)
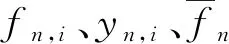
數據流從基站側傳輸到用戶端的時延包括傳輸延遲和基站處理延遲兩部分,其中傳輸時延由基站與用戶n之間的數據傳輸速率決定,而基站處理時延由基站的計算資源決定。在本節所述的系統模型中,時延被定義為傳輸時延和基站處理時延的總和。因此,數據流從基站傳輸到用戶端n的總時延被建模為:
Dn,t=μt+δn,t,
(9)
式中,μt為基站處理時延,δn,t為傳輸時延。當基站需要傳輸到用戶端的數據流較小時,基站處理時延接近于0,此時,Dn,t主要由傳輸時延決定;當基站需要傳輸到用戶端的數據流較大時,Dn,t主要由基站處理時延和傳輸時延共同決定。
1.4 優化問題建模
本文所提算法與其他資源分配算法的不同之處在于考慮由于實時調整資源分配策略而造成的資源損耗問題,并將該問題轉化為一個多時間粒度資源分配問題,多時間粒度體現在算法所生成策略的有效作用時間,盡可能減少資源調整的次數。本文通過調整兩次資源調整之間的時間間隔實現資源調整頻率的降低,而該時間間隔的大小是由資源分配算法本身所決定的,與當前以及未來的環境狀態有關,是一個不確定的值,也就是在多個時間粒度上進行資源分配,不是以固定的頻次分配資源,即多粒度資源分配。所設計的資源分配算法在狀態Si下進行第i次決策時所產生的資源分配策略Ai中不僅包含多種資源分配的數值大小,也包含這些資源的有效作用時間τi,其中Si與Ai將在下一節進行詳細介紹。本節從用戶的QoE、SE和執行動作的成本三個角度出發構建系統的效用函數,可表示為:
(10)

(11)
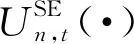
(12)
式中,βn,t,1,β2分別為數據流總時延和平均SE的權重因子,η為資源調整成本的權重因子,表示這三個量在效用函數中的重要性。由于不同的業務對時延需求不同,因此權重因子βn,t,1在用戶訪問不同的業務時所取的值也不相同。對于用戶的業務估計采用常用的CNN進行。
本文的目標是獲得最優的RAN資源分配策略,該策略能夠在滿足資源調度約束的同時,最大化系統的效用函數,總結如下:
maxUi(Si,Ai)
C4:ωt+ωE<ωmax,?t∈τi,
(13)
2 基于Dueling DQN的多粒度資源分配方案設計
決斗深度Q網絡(Dueling Deep Q-network,Dueling DQN)算法是DQN算法的改進版。兩者的主要區別在于所采用的用于擬合Q函數的神經網絡結構不同,如圖1所示。
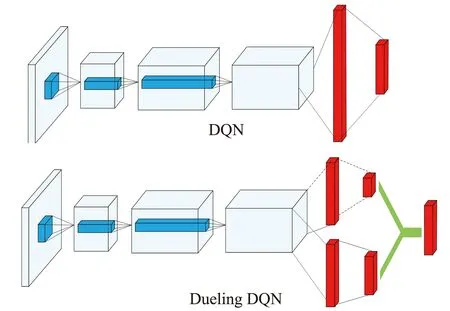
圖1 DQN算法與Dueling DQN算法Q網絡結構對比圖
DQN算法中采用Q網絡由三個卷積層以及兩個全連接層構成,DQN的Q網絡是單流的,該網絡結構只考慮在當前狀態下采用哪個動作可以獲得最大的獎勵值。而Dueling DQN算法中采用的Q網絡是雙流的,分別表示狀態值函數和動作優勢函數,利用匯聚的兩種狀態函數擬合Q函數,該網絡結構著重關注重要狀態,忽略不重要狀態,因此收斂速度更快,更容易尋找最優策略。
根據Dueling DQN算法的網絡結構,狀態值函數可以表示為Vπ(Si;θ,ξ),動作優勢函數可以表示為Aπ(Si,Ai;θ,α)。其中,θ為三個卷積層的網絡參數,ξ表示狀態值函數的全連接層的網絡參數,α表示動作優勢函數全連接層的網絡參數,為得到唯一的V(Si;θ,ξ)和A(Si,Ai;θ,α),得到Q函數為:
Q(Si,Ai;θ,α,ξ)=V(Si;θ,ξ)+
(14)
由于DQN算法架構均需要構建狀態集、動作集以及獎勵函數,因此根據本文的場景,將分別介紹這三者在本文中的定義。
(1) 狀態集定義
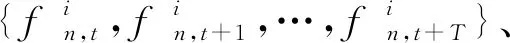
(15)
所以,本系統的狀態集可以表示為:
S={S1,S2,…,Si}。
(16)
(2) 動作集定義
在本文所構建的模型中,資源分配算法需要求解出基站所需的計算資源、基站為每個用戶分配的RB資源和發射功率資源。因此每一次動作Ai包含需要分配的各種資源的數值大小以及資源分配結果的有效作用時間,可以表示為:
(17)
(3) 獎勵函數
在強化學習中獎勵值越大,代表選擇的策略越符合優化目標。在本節中,目標是在滿足約束的同時最大化系統效用函數值。所以系統效用函數值越大,策略獲得的獎賞越大,獎賞可以表示為:
R(Si,Ai)=Ui(Si,Ai)。
(18)
DQN的目標在于求解出累積獎賞最大時所對應的策略,表示為:
(19)
式中,Q(Si,Ai)是一個無限期折扣報酬,λi是一個折扣因子,當i足夠大時,λi趨近于零。
在狀態Si下采取行動Ai是一個馬爾科夫過程,根據馬爾科夫狀態轉移的過程可知,下一個狀態Si,與之前的狀態均無關,僅僅與此刻的狀態以及所采取的行動有關,因此Q函數的更新可以為:
Q(Si,Ai)→Q(Si,Ai)+ψ(R(Si,Ai)+
λmaxQ(Si,,Ai,)-Q(Si,Ai)),
(20)
式中,ψ為學習率。
在Dueling DQN算法中包含兩個與Q函數相關并且結構相同的DNN,其中一個DNN用于擬合Q函數的值,被稱為評估Q網絡,表示為:
Q(Ai,Si;θ,α,ξ)≈Q*(Ai,Si),
(21)
式中,θ為評估Q網絡中設定的三個卷積層的網絡參數,ξ表示評估Q網絡中狀態值函數全連接層的網絡參數,α表示評估Q網絡中動作優勢函數全連接層的網絡參數。另一個DNN用于得到目標Q值,被稱為目標Q網絡,表示為:
(22)
式中,θ-為目標Q網絡中設定的三個卷積層的網絡參數,ξ-表示目標Q網絡中狀態值函數全連接層的網絡參數,α-表示目標Q網絡中動作優勢函數全連接層的網絡參數。
在學習階段,會將隨機抽樣的樣本(Si,Ai,R(Si,Ai),Si,)存放到經驗池中,只有當經驗池中所存儲的樣本數量大于隨機抽樣的樣本數量時才開始訓練。在訓練階段,agent從經驗池中隨機抽取小批量樣本(si,ai,r(si,ai),si,),將si作為評估Q網絡的輸入,(r(si,ai),si,)作為目標Q網絡的輸入。在每一步訓練中,Dueling DQN都通過最小化損失函數的方式對兩個DNN的參數進行更新,損失函數可以表示為:
將從經驗池中抽取的樣本輸入到評估Q網絡中計算該網絡參數θ對應的梯度θ,再使用Adam算法對網絡參數θ進行更新。并每隔一段時間將評估Q網絡的參數〈θ,α,ξ〉直接賦值給〈θ-,α-,ξ-〉,實現目標Q網絡參數更新。整體算法流程如算法1所示。

算法1 基于Dueling DQN的多粒度資源分配算法輸入:動作集A,獎勵衰減因子λ,經驗池K的最大容量,最大允許誤差ε,更新參數的樣本批次,目標Q網絡參數<θ-,α-,ξ->更新間隔Z。輸出:最優策略,滿足用戶QoS條件下,得到資源分配的結果以及資源分配的有效時間所組成的最佳動作序列。1. 初始化:經驗池K,評估Q網絡參數<θ,α,ξ>,目標Q網絡參數<θ-,α-,ξ->=<θ,α,ξ>。2. 初始化存儲空間3. Step = 04. for episode = 1,2,... do5. for t= 1,2,... do6. 初始化網絡狀態Si;7. agent的Q網絡使用狀態Si作為輸入,輸出所有動作對應的Q值,根據公式π*從所有Q值中選擇動作Ai;8. 將agent所選定的動作Ai輸入環境中執行,然后獲得R(Si,Ai)以及下一個狀態Si,;9. agent將經驗(Si,Ai,R(Si,Ai),Si,)存入經驗池D中;10. Si←Si,;11. if Step > 10012. 從經驗池K中隨機抽取G個樣本(si,ai,r(si,ai),si,)進行訓練;13. 利用DNN計算Q值,用式(4)~(22)計算損失函數,并使用Adam算法對評估Q網絡參數<θ,α,ξ>進行更新;每迭代Z步后,進行一次操作;14. end if;15. Step += 1;16. end for17. end for
3 平臺部署與方案驗證
本小節搭建的長期演進(Long Term Evolution,LTE)實驗平臺均借助開源軟件實現,并且全部網元、算法實現等都部署在Docker容器中,統稱為網絡功能(Network Functions,NFs),從而實現網絡功能的虛擬化,然后由Kubenetes對這些NFs進行統一管理。
3.1 平臺部署
平臺所需的硬件環境包括三臺x86通用服務器、一個NETGEAR開放虛擬交換機(Open vSwitch,OVS)型號為MT7621AT、一個通用軟件無線電外設(Universal Software Radiio Peripheral,USRP)型號為USRP210、三個用戶手機型號為華為Mate7。其中三臺通用服務器分別用作CNN、SequentialSeq模型的訓練與在線推理,實現網絡感知;部署開源軟件LTE無線接入網OAI-eNB和FlexRAN,實現無線接入網控制面與用戶面;部署開源OAI軟件核心網。
FlexRAN,用于給用戶分配無線資源;Docker,用于承載各個面中每個虛擬化后的NFs,對服務器底層的硬件資源進行虛擬化處理,保證各個NFs能夠正常工作;Python,主要用于感知面、智能融合面中各種與AI相關的網絡功能的開發與實現;Nginx,用于搭建相關業務的服務器,滿足用戶對業務多樣性的需求。
由于受到軟硬件條件的限制,無法針對每個用戶調整發射功率,因此在將算法部署到實驗平臺中時對其進行一定的簡化。將資源分配算法部署在Dockers容器中。當該節點中所有的pod從containerCreating到running狀態后即說明K8s集群以及基于網絡智能感知的多粒度資源分配算法平臺已經部署成功。
3.2 方案驗證及結果分析
本節中基于深度強化學習的多粒度資源分配算法的參數配置主要根據經驗進行選取,學習率為0.001,折扣因子為0.95,經驗回放為5 000,隨機采樣樣本數為128,更新頻率為100,迭代次數為8 000。考慮到流量采樣時間對流量預測與業務估計的影響,實驗驗證在保存完整流量信息的流量采樣時間為1 s和10 s的情況,在結果圖中用括號標注。
3.2.1 資源分配算法對頻譜效率的影響
圖2對比用戶在訪問電子書業務時采用不同分配算法對頻譜效率的影響。
從圖2(a)可以看出,采用平均分配算法時頻譜效率只達到2.4 bit·s-1·Hz-1,而采用其他兩種資源分配算法為用戶分配RB資源時頻譜效率可達3.2 bit·s-1·Hz-1左右。此外,采用基于網絡智能感知的多粒度資源分配算法的頻譜效率與單粒度接近。
從圖2(b)圖中看出,采用平均分配算法時頻譜效率只達到2.4 bit·s-1·Hz-1,而采用其他兩種資源分配算法為用戶分配RB資源時頻譜效率可達3.2 bit·s-1·Hz-1左右;同樣,采用基于網絡智能感知的多粒度資源分配算法的頻譜效率與單粒度接近。
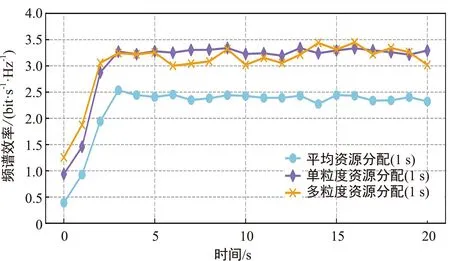
(a) 流量采樣時間為1 s
導致以上結果的原因是平均資源分配方法給每個用戶都分配15個RB資源,在用戶下載電子書時RB資源非常充足,因此頻譜效率較低,而其他兩種資源分配算法綜合考慮業務的時延和頻譜效率兩個因素,因此頻譜效率較高。但是,由于基于網絡智能感知的單粒度資源分配算法在每個TTI內都會執行一次資源分配動作,可以根據網絡和資源狀況靈活調整資源分配策略,而基于網絡智能感知的多粒度資源分配算法每隔幾個TTI才會重新執行一次資源分配動作,因此,基于網絡智能感知的單粒度資源分配算法的頻譜效率比較穩定。
3.2.2 不同分配算法對總時延的影響
圖3對比采用不同資源分配算法后對數據傳輸總時延的影響。定義總時延為基站處理數據的時延與數據通過無線信道傳輸時的時延之和。圖3(a)為流量采樣時間為1 s的情況下流量傳輸所產生時延的累計概率分布圖,可以看出,當采用平均資源分配算法時,只有一部分業務流量可以在1 s以內到達用戶端,而采用其他兩種資源分配算法,大多數業務流量可以在1 s以內到達用戶端,而且單粒度資源分配算法的時延總體上稍微小于多粒度資源分配算法。
圖3(b)為流量采樣時間為10 s的情況下流量傳輸所產生時延的累計概率分布圖,可以看出,采用平均資源分配算法時,只有一部分業務流量可以在10 s內到達用戶端,而采用其他兩種資源分配算法,大多數業務流量可以在1 s以內到達用戶端,并且兩種算法相差不大。
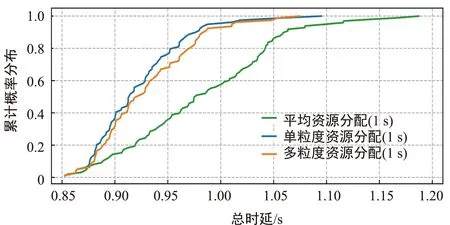
(a) 流量采樣時間為1 s
這是由于采用平均資源分配算法時每個用戶平均分配RB資源,當用戶訪問視頻業務時會發生卡頓,造成傳輸時延增大,而其他兩種資源分配算法會由于流量預測誤差等因素,也會偶爾有RB資源分配不足的情況,造成傳輸時延稍微增大,但是本文所提出的算法根據基站所需發送的流量數據調整基站的計算資源從而降低處理時延,根據用戶的未來流量調整用戶的RB資源從而降低傳輸時延,因此總時延都小于平均資源分配算法。
3.2.3 不同流量采樣時間對執行動作成本的影響
由于本文所提算法相較于其他資源分配算法,考慮基站執行資源分配動作時所消耗的成本,因此對相同建模下采用單粒度和多粒度資源分配算法的成本進行對比,如圖4所示。
其中基站執行資源分配動作的成本使用perf工具進行測試。結合圖2~圖4可以看出,隨著資源分配執行時間的增加,執行資源分配動作所耗費的成本越來越多,但是在頻譜效率和總時延都達到類似性能的情況下,流量采樣時間為1 s單粒度資源分配算法所耗費的成本遠高于多粒度資源分配算法,流量采樣時間為10 s單粒度資源分配算法所耗費的成本也高于多粒度資源分配算法,這是因為單粒度資源分配算法頻繁更改資源分配策略所造成的。
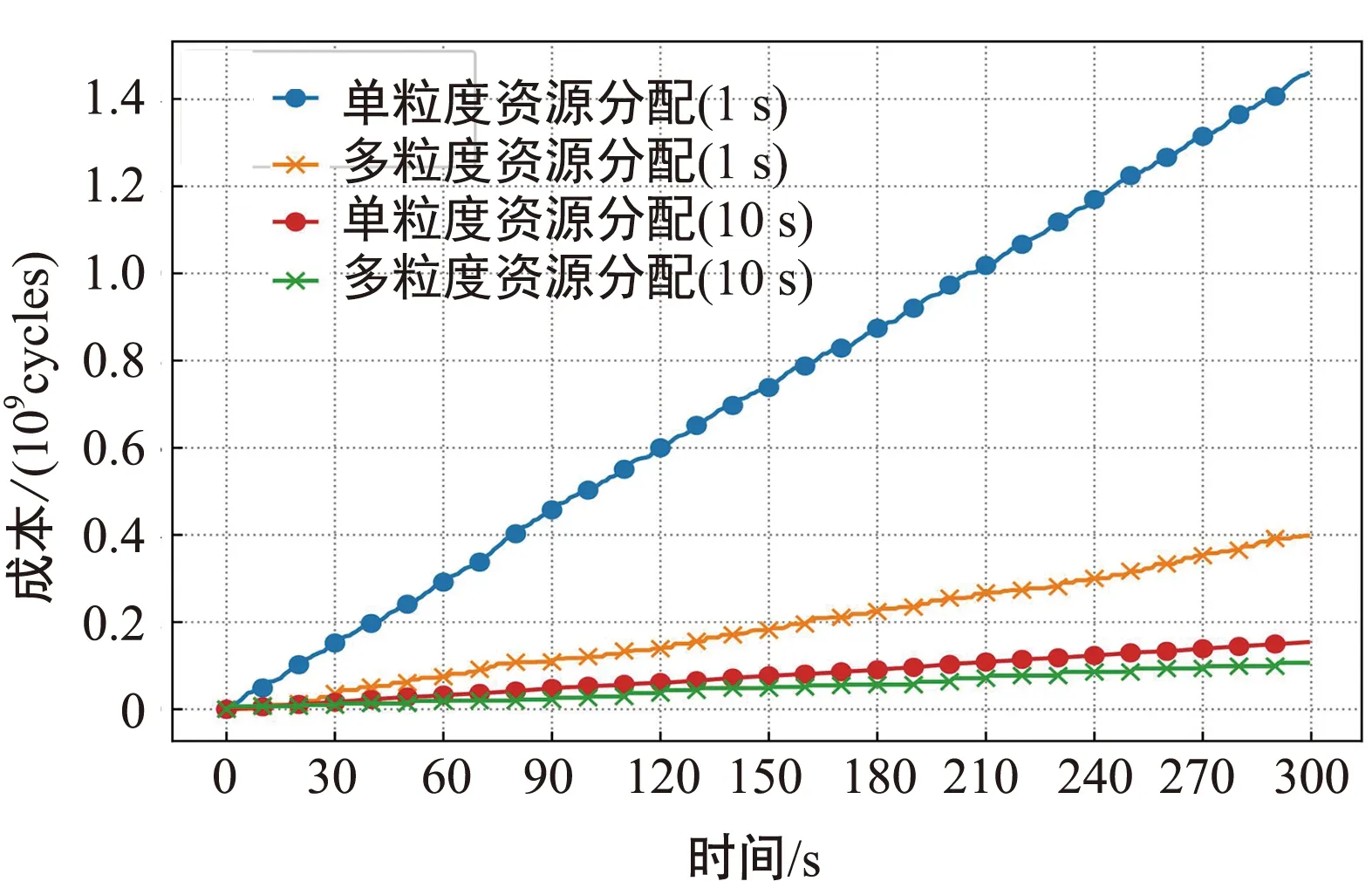
圖4 不同流量采樣時間對執行動作成本的影響
3.2.4 用戶的RB資源分配結果測試
本文中使用50 M帶寬的LTE網絡,以RBG(3個RB)[14]為單位給用戶分配RB資源。圖5和圖6分別為在流量采樣時間為1 s和流量采樣時間為10 s的前提下基于網絡智能感知的多粒度資源分配算法為用戶分配的RB資源。
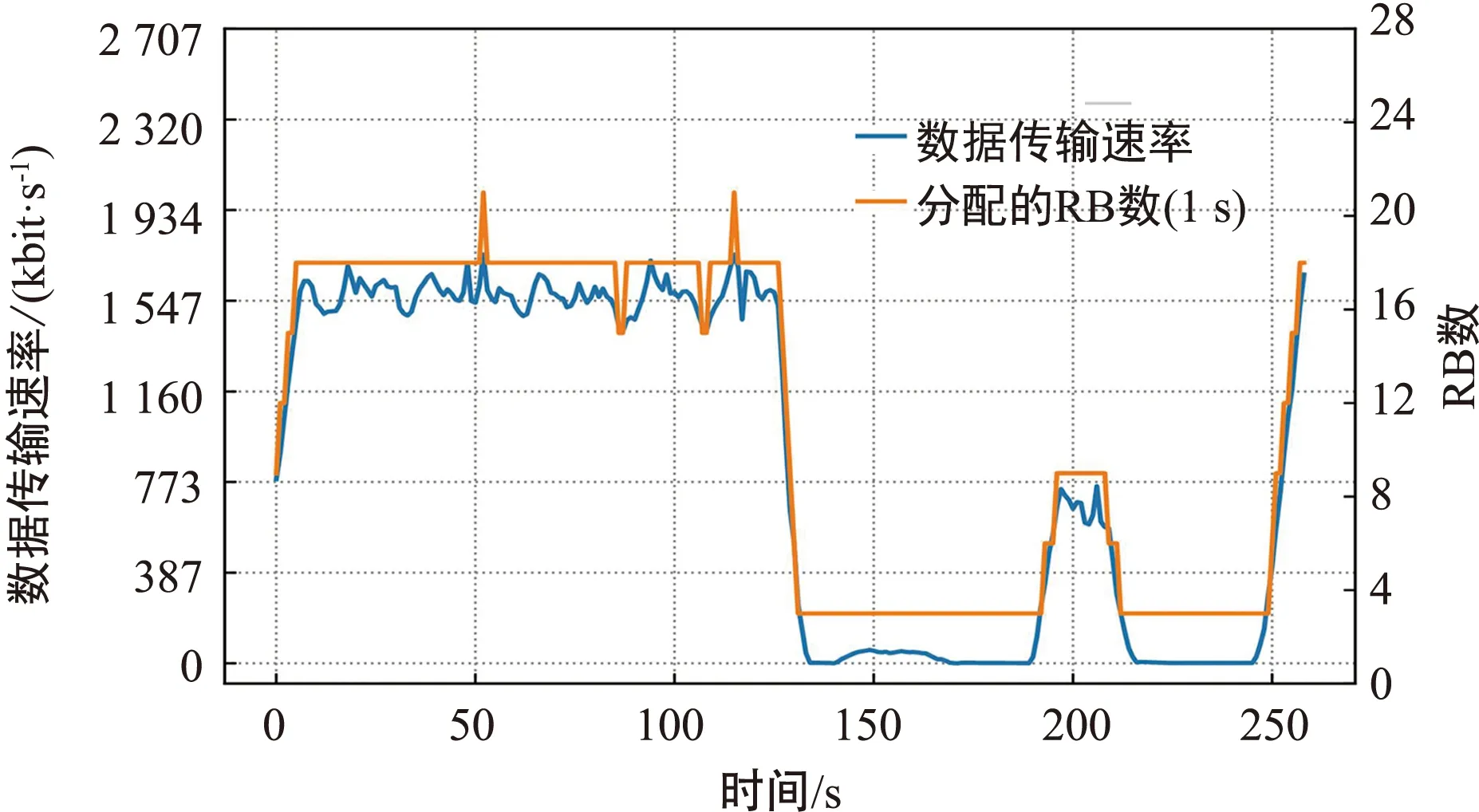
圖5 用戶的RB資源分配結果圖(流量采樣時間為1 s)

圖6 用戶的RB資源分配結果圖(流量采樣時間為10 s)
由圖5和圖6可以看出,當用戶訪問高清視頻業務時,資源分配算法為其分配18個RB,當用戶訪問無損音樂時,資源分配算法為其分配3個RB,當用戶訪問電子書業務時,資源分配算法為其分配9個RB,均可以滿足用戶的需求。
3.2.5 流量預測精度對用戶QoE的影響
QoE能夠準確反映當前資源分配策略下用戶的體驗,而用戶的QoE是由各項QoS綜合后的結果,不能使用單一的指標描述各種業務的QoE[15]。有研究[16]針對視頻業務給出常見的評估指標,如起始時延、卡頓次數等,本文將這些指標推廣到本文所提供的高清視頻、無損音樂和電子書業務,具體的評估指標定義如下文所述。
起始時延是指每項業務開始之前的持續時間。針對高清視頻業務,是指從用戶發出請求到視頻開始播放的時間;針對無損音樂業務,是指從用戶發出請求到音樂開始播放的時間;針對電子書業務,是指從用戶發出請求到電子書內容展示在瀏覽器中經過的時間。
卡頓次數由于瀏覽器在業務開始前會將業務內容先放在緩沖區,只有當業務流填充緩沖區的速率大于或者等于業務播放的速率時,業務才不會發生卡頓。針對高清視頻和無損音樂業務,是指視頻或音樂在播放過程中發生卡頓的次數。針對電子書業務,是指電子書加載內容總量不變且持續時間大于2 s時發生的次數。
圖7為流量采樣時間為1 s的情況下,設置不同歷史步長(H)和未來步長(T)的流量預測參數對業務平均起始時延的影響。從圖中可以看出,無損音樂的平均起始時延最低,電子書的平均起始時延在0.5~1.9 s,高清視頻的平均起始時延最高,在1.6~3.8 s,而且每種業務的平均起始時延大小與決定系數R2成負相關,即決定系數越大,該參數設置下的流量預測精度越高,資源分配策略越好,每種業務的平均起始時延越小。
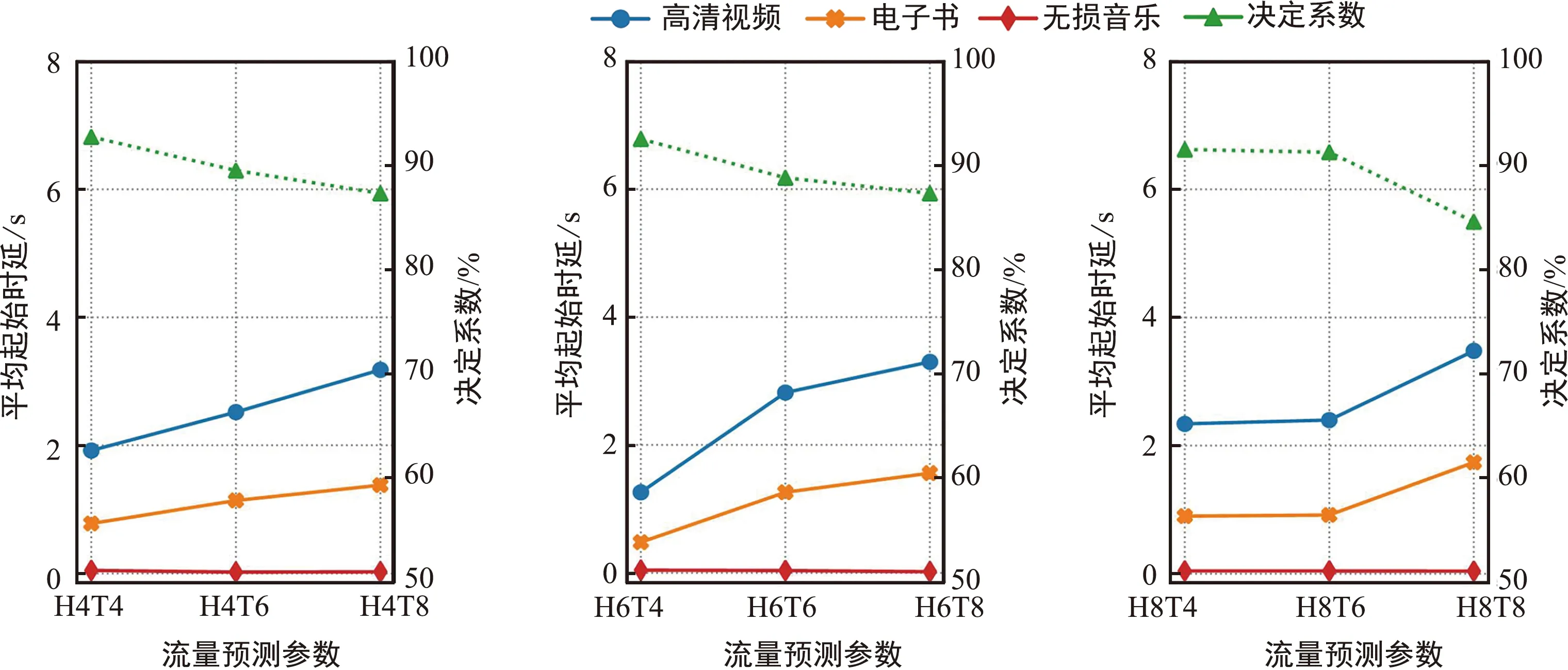
(a) 歷史步長為4 (b) 歷史步長為6 (c) 歷史步長為8
圖8為流量采樣時間為10 s的情況下,設置不同歷史步長(H)和未來步長(T)的流量預測參數對業務平均起始時延的影響。從圖中可以看出,無損音樂的平均起始時延最低,電子書的平均起始時延為0.8~2.4 s,高清視頻的平均起始時延最高,為3.5~5.6 s,而且每種業務的平均起始時延大小與決定系數R2也成負相關。

(a) 歷史步長為2 (b) 歷史步長為4 (c) 歷史步長為6
圖9為流量采樣時間為1 s的情況下,設置不同歷史步長和未來步長的流量預測參數對業務平均中斷次數的影響。從圖中可以看出,無損音樂在播放過程中基本不會發生中斷,電子書的平均中斷次數在一次以下,高清視頻的平均中斷次數最高,而且每種業務的平均中斷次數與決定系數R2成負相關,即決定系數越大,該參數設置下的流量預測精度越高,資源分配策略越好,每種業務的平均中斷次數越小。
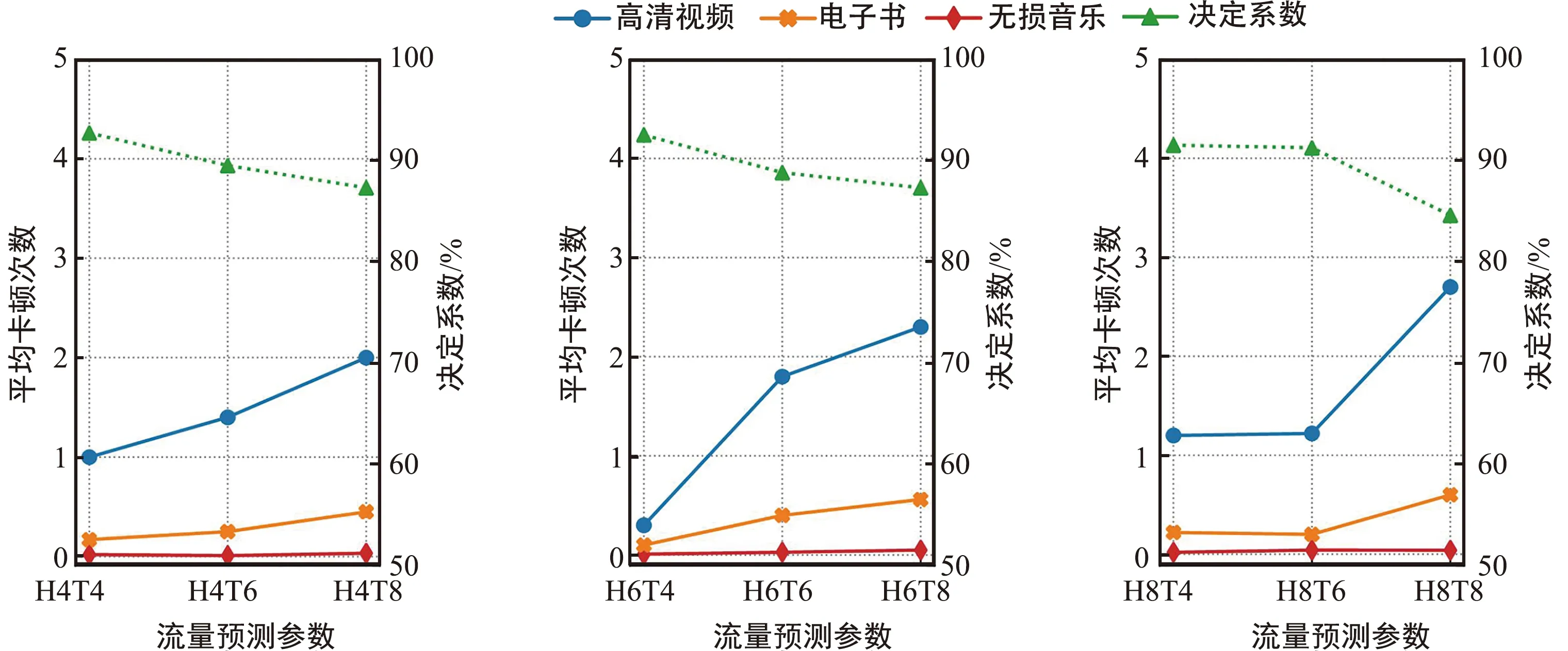
(a) 歷史步長為4 (b) 歷史步長為6 (c) 歷史步長為8
圖10為流量采樣時間為10 s的情況下,設置不同歷史步長和未來步長的流量預測參數對業務平均中斷次數的影響。從圖中可以看出,無損音樂在播放過程中基本不會發生中斷,電子書的平均中斷次數在2次以下,高清視頻的平均中斷次數最高,在3~6次之間。

(a) 歷史步長為2 (b) 歷史步長為4 (c) 歷史步長為6
對比圖7和圖8、圖9和圖10可知,流量采樣時間為1 s的用戶QoE比流量采樣時間為10 s的用戶QoE好,這是由于流量采樣時間越小,多粒度資源調整越精細,用戶的QoE越好。
綜上,實驗結果證明,在面向6G通感算融合的多粒度資源分配算法可以滿足用戶QoE的情況下,本文算法能夠提高網絡頻譜效率,并降低傳輸時延、處理時延和資源分配動作執行的成本。
4 結束語
本文提出一種面向6G通感算融合的多粒度資源分配算法,多時間粒度體現在算法所生成策略的有效作用時間。首先,將通信、感知、計算資源聯合優化問題建模為多時間粒度上的最大化效用函數問題,并滿足用戶所能容忍的最小數據傳輸速率、所有用戶與基站占用的資源不超過系統總資源等約束。其次,采用Dueling DQN算法對該問題進行求解,將感知信息(流量預測與業務類型估計結果)、通信信息(信噪比、發射功率、資源塊數等)和計算信息(基站的計算資源)作為狀態集;將資源分配策略有效作用時間粒度、資源塊數、發射功率、基站的計算資源作為動作集;將所有用戶的時延、頻譜效率以及執行動作成本的加權和作為獎勵值;最后,在基于開源軟件搭建的實驗平臺中,將本文的算法與現有資源分配算法進行對比,驗證本文所提的算法能夠提高網絡頻譜效率,并降低傳輸時延、處理時延和資源分配動作執行的成本。
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
資源再生(2017年3期)2017-06-01 12:20:59
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
