基于HMIPv6 的改進的切換協議*
2023-02-02 02:52:40李新建
通信技術 2023年12期
關鍵詞:管理
李新建
(中國飛行試驗研究院,陜西 西安 710089)
0 引言
互聯網工程任務組(Internet Engineering Task Force,IETF)提出的IP 移動性支持協議要求:只要移動主機(MH)移動到另外一個IP 子網,它就獲得另外的轉交地址,從而啟動注冊過程。該過程要求MH 必須通過外地代理(Foreign Agent,FA)向家鄉代理(Home Agent,HA)進行注冊,由HA來維護MH 的移動綁定。當MH 應用于宏移動(macro mobility)環境時,把移動IP 稱為宏移動協議;當其MH 應用于微移動(micro mobility)環境時,則存在許多不足,突出表現在以下3 點:
(1)在網絡中將引發大量的注冊報文的傳輸從而嚴重影響網絡性能;
(2)造成較大的切換延遲,特別是當MH 遠離其歸屬網絡時,將引起嚴重的包丟失和通信吞吐量的下降;
(3)采用優化路由時,由于要正確地通過隧道傳輸IP 包[1],因而必須保存精確的位置信息,并需要大量的緩存。
因此,對于現有的移動IP 協議必須加以改進或者補充,以適應微移動環境下的應用。基于此本文提出了一種基于層次型移動IPv6 管理(HMIPv6)的改進方法,以及一種新的網絡模型,推導出MIPv6、FMIPv6、[F+H]MIPv6、HMIPv6 和NPMAPHMIPv6 各自的注冊代價、數據包隧道代價、數據包發送代價、總代價和切換延時,并對各個策略進行分析。
1 蜂窩的基本架構
每個蜂窩與周圍6 個蜂窩相鄰,每個蜂窩小區中心設置一個接入路由器AR,每個AR 通過無線方式與移動節點(MN)通信,相鄰AR 之間通過有線連接。MN 在同一域內的不同AR 之間移動時,只需向本地代理進行區域注冊。當MN 移出本地管理域而進入另一個區域時,才需要通過新的MAP向家鄉代理進行注冊。每層都有一個MAP,MAP之間是有線傳輸,MN 到MAP 是無線傳輸。建立蜂窩模型:以網關MAP 為中心(稱為第0 層蜂窩)向周圍發散,依次為第1,2,3,…層,第r層蜂窩到中心的距離被定義為r。第1 層蜂窩總數為6 個,第2 層蜂窩總數為12 個,第j+1 層蜂窩總數比第j層蜂窩總數多6 個。設管理域共有r+1 層蜂窩,最外層是第r層,其中r代表了區域大小,稱為管理域半徑。第r層蜂窩到網關MAP 的距離為r,則第j層蜂窩總數為:
假設MN 的運動服從隨機游動模型,每次移動定義為1 跳。MN 在蜂窩中停留的概率為1-P,則移動的概率為P,且向相鄰6 個蜂窩切換概率相等。處于n層的MN 經過一次移動,向外層、內層和同層的一步轉移概率為:
特殊地,式(3)中當MN 從第r層移動到第r+1 層時,為MN 切換到相鄰管理域,即發生域間切換。在網絡中經過多次隨機游動后,MN 處于穩定狀態。令MN 位于第r層的穩定狀態概率為Pr,初始狀態概率為P0,根據狀態平衡方程可得:
根據馬爾可夫鏈性質可知,所有穩態概率之和為1,即:
為了降低運算復雜度[2],在計算切換延遲時,本文采用r層蜂窩模型。在計算切換代價的時候,本文采用兩層蜂窩結構,如圖1、圖2 所示。
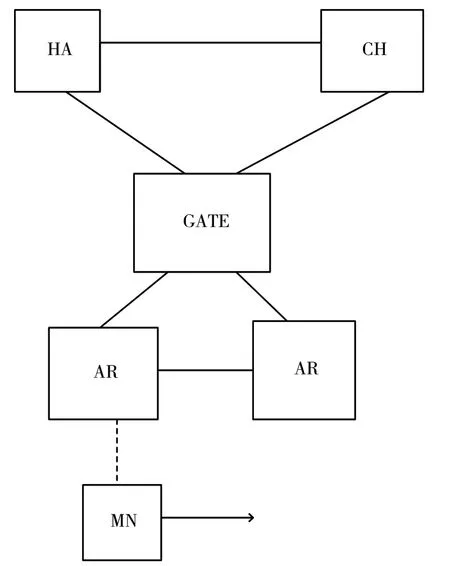
圖1 兩層網絡結構
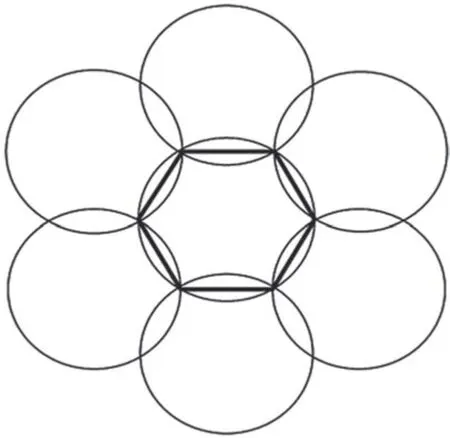
圖2 兩層圓形蜂窩模型
2 對現有的移動性管理協議的代價和切換延遲的分析
MIPv6 每次連接點改變時都要將改變的IP 地址通知給HA 和所有的通信主機的要求。在HMIPv6 中,每個域中都有MAP 的管理代理。它將作為本地HA為MN 服務,MN 有兩個IP 地址,一個是on—link COA(LCOA),另一個是regoinal COA(RCOA)。每次MN 進入一個區域,它首先向MAP 注冊[3],在MAP 的連接中,MN 獲得RCOA。此后,MN 用這個地址向HA 注冊。只要MN 在MAP 域中移動,MN的移動情況對于域外的節點(包括它的HA)就是透明的,只有LCOA 的改變,而且只通知給MAP。發送到MN 的IPv6 數據包首先到達MAP,其次MAP通過隧道將其發送到MN 的LCOA。
由于MN 在給定的MAP 域內配置COA,因此MN 只需要向MAP 更新它的新位置。只是由于MAP 充當了MN 的當地HA,因此HMIPv6 的綁定更新代價表示為:
因此,總的代價表示為:
歸一化延時為:
3 改進算法(NAP-HMIPv6)分析
本文提出的改進算法是基于HMIPv6 的一種新的數據報文綁定更新算法。MAP1 和MAP4 稱為網關MAP,其他MAP 是一般的MAP,但它們實質上是AR,充當MN 的局部HA。如圖3 所示,將MN 的移動分為域內移動a、域內移動b。MN在位置改變的時候,有著不同的注冊過程[5],需要在新舊路由之間找到一個最近公共的MAP 注冊(NPMIPv6)。

圖3 改進的網絡結構
各個代理的HA、RCOA、LCOA 如表1、表2、表3 所示,其中NPMAP 用星號標出。

表1 域內移動a 時的綁定緩存入口

表2 域內移動b 時的綁定緩存入口

表3 域間移動時的綁定緩存入口
在這種切換中,延遲來自復制地址檢測(DAD)和在注冊操作中的消息傳輸延時。改進的算法旨在最小化在注冊過程中的時延。假設MN 在AR4,其地址為RCOA3、LCOA4,CN 正在給MN 發送數據包。當MN 運動到MAP3 的邊緣的時候,MN 發送控制消息給MAP3 以建立多路廣播組。MAP3 收到控制消息后為MN 建立多路廣播組[6],同時發送信息到臨近的AR 來參加多路廣播組。MAP3 將多路廣播數據包發給AR3 和AR5。當MN 接收到來自AR5 的路由廣播時,MN 將獲得兩個地址RCOA5、LCOA5,
然后R5 根據MN 的唯一的接口標志發送多路廣播數據包[7]。于是,本文提出了一種改進的NPMIPv6 注冊策略,如圖4(b)所示。例如,MN從AR4 移動到AR5,步驟如下文所述。


圖4 對比實驗
(1)MN 發送綁定更新和請求消息給AR5,發送數據包。
(2)AR5 接收到請求消息和綁定更新。AR5根據MN 的唯一的接口標志發送多路廣播數據包。同時AR5 發送綁定更新到MAP4,MAP 進行DAD。MN 從AR5 接收臨時的多路廣播數據包,直到注冊結束。
(3)MAP4 接收到綁定更新消息,執行DAD檢測。
(4)MAP4 結束DAD 檢測,然后更改目的地址。將(RCOA3,LCOA4)改為(RCOA5,LCOA5),然后發送綁定確認消息給MN。
(5)AR5 收到綁定確認消息,發送給MN。
(6)MN 收到綁定確認消息,將包含(RCOA5,LCOA5)的綁定確認消息發送給CN,讓CN 更改新的目的地址。
(7)AR5 接收到BU,發送給MAP5。
(8)MAP5 接收到BU 后再發送給MN。
(9)CN 接收到BU 后,改變舊的RCOA3,更新新的RCOA5,發送數據包給MN。
(10)MAP5 根據RCOA5 收到數據包后,再根據LCOA5 發送至AR5。
(11)AR5 收到數據包。
和HMIPv6 相比,PMIPv6 能夠使普通的MN 在PMIPv6 域內改變它的連接節點,任何從MN 發送的移動信息并不在PMIPv6 中存在。因此,PMIPv6的綁定代價可以表示為:
則歸一化延時為:
對比實驗結果如圖4 所示。
4 實驗分析
4.1 發送信號代價
HMIPv6 和NPHMIPv6 比其他的切換策略表現得更好,因為它們發送時花費的注冊信息更少。隨著v的增大,發送信息的代價也在增加,但HMIPv6 和NPHMIPv6 花費的代價更小。例如,在HMIPv6 中,MN 在域內由MAP 管理,只有綁定更新和確認消息在它們之間交換;在NPHMIPv6 中,MN 在域內由最近的公共MAP 管理,只有綁定更新和確認消息在它們之間交換,這樣減少了消息交換的代價。在MIPv6、FMIPv6、[F+H]MIPv6 中,只要MN 改變它的連接,MN 必須將綁定更新消息發送至HA或者CN。HMIPv6和NPHMIPv6是局部化管理,因此代價最小。FMIPv6、[F+H]MIPv6 發送信息的代價比其他的切換策略表都大,這是因為快速切換和數據緩存機制造成的額外代價。
4.2 數據包發送代價
隨著平均會話到達率增加,數據包發送代價顯著增加。MIPv6 比其他切換策略表表現得更好,這是因為從CN 發送的數據直接發送至MN。由圖4 可知,ω對HMIPv6 和NPMIPv6 沒有影響,而MIPv6、FMIPv6、[F+H]MIPv6 顯著增加,因為通過間接路由的數據包在增加,而隧道代價FMIPv6、[F+H]MIPv6比其他代價更大。
4.3 數據包隧道代價
即使HMIPv6 和NPMIPv6 在給定的域內采用了局部化管理結構,所有的管理協議也會產生很大的數據包隧道代價,例如在HMIPv6 中,發送至MN的數據包必須由MAP 通過隧道發送至MN。
4.4 總的代價
HMIPv6 和NPMIPv6 在高的移動環境下降低了移動注冊代價,但是它們會造成額外的數據包隧道代價。總的來說,在高移動性和低會話到達率的條件下,HMIPv6 和NPMIPv6 的表現要好一些。隨著SMR 的增大,總的代價在降低,因為高的SMR 在固定的會話到達率條件下,移動性更小。
4.5 注冊延遲
對注冊延遲影響分析:
(1)p的影響:隨著MN 的移動概率的增大,切換延遲代價也在線性增加。MIPv6 在所有有關的協議里表現得最差。本文提出的協議PMIPv6 的表現得和[F+H]MIPv6 差不多。
(2)駐留時間期望的影響:隨著平均駐留時間增加,MN 表現出更小的移動性,所有協議切換延遲都在下降。相比而言,本文提出的協議和[F+H]MIPv6 性能相近,比HMIPv6 和MIPv6 性能高很多。
(3)半徑的影響:MIPv6 的切換延遲保持穩定不變,因為MIPv6 并不區別在域內移動和域間移動。PHMIPv6 在對比的協議里表現最好,和[F+H]MIPv6 比較接近。
5 結語
從模型分析的結果可以得到,PHMIPv6 在性能上更接近[F+H]MIPv6,但是[F+H]MIPv6 更大程度上依賴于對即將到來的切換的準確預測。[F+H]MIPv6同時也面臨著同步問題。緩存管理同樣存在這個問題,在[F+H]MIPv6 中,如果MN 沒有足夠快地靠近它,NAR 必須緩存發往MN 的數據包。PMIPv6通常沿著從MN 到HA 的路徑找到最近的MAP 以轉換路徑,因此產生了很小的延遲,不需要對切換時間正確的預測,也不會面臨其他[F+H]MIPv6 面臨的問題,策略更優。
猜你喜歡
今日農業(2022年15期)2022-09-20 06:56:20
水資源開發與管理(2021年12期)2022-01-15 08:54:58
——關注自然資源管理
遼寧自然資源(2021年3期)2021-05-19 06:39:04
水利建設與管理(2020年9期)2020-10-21 05:22:26
河南水利年鑒(2020年0期)2020-06-09 05:43:30
中國制筆(2019年1期)2019-08-28 10:07:26
建材發展導向(2019年10期)2019-08-24 06:26:30
建材發展導向(2019年10期)2019-08-24 06:26:20
中國眼鏡科技雜志(2017年13期)2017-08-16 03:13:42
雜文月刊(2016年1期)2016-02-11 10:35:51
