基于CNN-BiLSTM特征融合的異常檢測算法
2023-01-31 08:56:00王晨輝王恩東高曉鋒
計算機應用與軟件 2022年12期
王晨輝 王恩東 高曉鋒
1(鄭州大學信息工程學院 河南 鄭州 450001) 2(浪潮電子信息產業股份有限公司 山東 濟南 250101)
0 引 言
云計算的發展帶來數據中心規模化、集中化的趨勢,為保障用戶所需業務的穩定運行,在云數據中心需要對監控指標進行異常檢測,但由于監控指標多、數據量大的特點,完全依賴人力來判定異常已經不切實際。同時數據中心和人們的生產生活都密切相關,一旦異常不能夠及時進行處理,就會帶來嚴重的損失。2018年8月,騰訊云服務因操作失誤造成大量數據丟失,造成了難以估量的損失。因此,亟需一種高效且穩定的運維方式來解決這一問題。Gartner于2016年提出智能運維(Artificial Intelligence for IT Operations,AIops)的概念,基于數據中心的運維數據,通過統計機器學習的方法來處理手動運維無法解決的問題[1],進而大大提高了運維效率。
1 相關工作
針對智能運維中異常檢測方法的研究,國內外的研究人員將異常檢測方法主要分為兩種。一種是基于統計模型的方法[2],例如:Yahoo團隊于2015年提出一種時間序列異常檢測框架EGADS[3],將目前流行的回歸模型和差分移動平均模型等統一放到上述框架中,在所提供的數據集中得到了可靠性較高的檢測結果;James等[4]提出了一種可以自動檢測數據中的異常點的統計模型方法,通過傳統的能量統計方法來監測數據中的異常點出現的概率。另一種是基于機器學習或者神經網絡的檢測方法。Liu等[5]與百度公司合作并提出了一種關鍵性能指標(Key Performance Indicator,KPI)自動異常檢測系統Opprentice,通過特征提取的方法將數據放到一個訓練好的隨機森林模型中去,通過分類判定數據的異常。Liu等[6]提出的孤立森林(Isolation Forest)算法屬于一種無監督算法,遞歸地隨機分割數據集,將異常定位于分布稀疏且離密度高的集群較遠的點。
以上異常檢測方法大都是基于傳統的統計模型和機器學習算法,同時也有研究人員嘗試將多種深度學習方法應用于異常檢測,深度學習模型在圖像、語音識別等領域應用比較廣泛,其中最具代表性深度學習方法包括卷積神經網絡(CNN)[7]和循環神經網絡(RNN)[8],CNN和RNN可以分別提取空間和時間上的特征,研究人員[9]根據數據的時態特征嘗試結合這兩種方法可以在時間序列上更好地進行預測和分類。Kim等[10]首先應用了C-LSTM[11]時間序列異常檢測模型,C-LSTM模型由CNN、LSTM和深度神經網絡(DNN)組成。首先,應用滑動窗口將時間序列分為幾個固定長度的序列,并建立新的序列數據集;然后高層的時空特征由CNN和LSTM從窗口數據中提取;最后將提取的特征輸入到一個全連接的DNN網絡實現分類。文獻[10]中的模型基于線性結構,依次將數據從一維卷積神經網絡輸出到LSTM,然后輸出結果到全連接層進行分類,能夠較好地提取時間和空間特征,但缺少對融合特征的處理。基于文獻[10]中的研究方法,本文提出改進的網絡架構,以更好地應用于異常檢測,在獲取數據集后,使用滑動窗口用于生成時間相關的子序列,分別輸入到一維卷積神經網絡和BiLSTM中去,得到數據的空間和時間特征,然后將提取到的特征使用Attention進行加權,得到融合特征,再將其輸入到一個全連接層得到預測結果,最后通過Softmax函數進行分類。
2 CNN-BiLSTM-Attention模型結構
2.1 卷積神經網絡
卷積神經網絡(CNN)是一種前饋神經網絡,其最初是由Lecun等[7]提出,CNN的本質就是構建能夠提取數據特征的濾波器,因此在深度學習領域中多被用作特征提取網絡,一個完整的CNN網絡包括輸入層、輸出層和隱藏層,隱藏層又可以分為卷積層、池化層和全連接層,本文主要用到其中的卷積層和池化層,其大致結構如圖1所示。
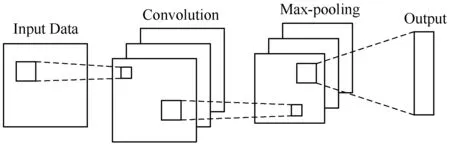
圖1 CNN結構示意圖
圖1中的卷積層和池化層主要用于提取輸入序列的空間特征[12],其中卷積層利用濾波器來處理輸入的序列,從而依次獲得空間上的特征,卷積層后接一個激活函數,本文使用tanh雙曲正切激活函數,從而能夠提取更加復雜的特征。
Pooling層主要是用于減少CNN網絡的參數,從而能夠減輕計算壓力,池化的方法有均值池化和最大池化,本文取用Max Pooling,其實質上就是在n×n的樣本中取最大值,作為采樣后的樣本值。
2.2 長短時記憶網絡
LSTM是一種由循環神經網絡衍生而來的時序神經網絡,它使用存儲單元來代替RNN中的循環單元來存儲時間序列的特征,能夠比較好地解決循環神經網絡中的長時間依賴問題[13]。
LSTM內部結構如圖2所示,其中:xt代表第t個輸入序列元素值;c表示記憶單元,其控制著序列的傳遞;i指代輸入門決定當前xt保留多少信息給ct;f代表遺忘門,其決定保存多少前一時刻的細胞狀態ct-1傳遞至當前狀態的ct;o指代輸出門,其決定ct傳遞多少至當前狀態的輸出ht;ht-1指代在t-1時刻的隱層狀態[14]。
上述過程對應公式如下:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
it=σ(Wi·[ht-1,xt]+bi)
(2)
(3)
(4)
ot=σ(Wo·[ht-1,xt]+bo)
(5)
ht=ot° tanh(ct)
(6)
式中:Wf代表遺忘門的權重矩陣;[ht-1,xt]表示上一時刻與當前時刻組成的新的輸入向量;Wi代表輸入門的權重矩陣;Wc代表記憶單元的權重矩陣;Wo代表輸出門權重矩陣;bf代表遺忘門的偏置量;bi代表輸入門的偏置量;bc指代記憶單元的偏置量;bo代表輸出門的偏置量;σ指代Sigmoid激活函數;° 表示向量元素乘。
LSTM更適合進行時間擴展,并且較好地解決了長時依賴問題,具有長期記憶功能,能夠很好地處理時間序列上的特征[15],上面的CNN通過卷積和池化操作提取空間特征,LSTM可以在提取空間特征的基礎上進一步提取時間維度上的特征,從而能夠提升數據特征的表達能力。
2.3 注意力機制
Attention機制是基于人類觀察事物的過程而演進過來的一種方法,人們在觀察事物時并不會將整個事物完全地看一遍,而是根據自己的偏好有選擇性地進行欣賞。基于此,將Attention用到對空間和時間特征的處理上,可以獲得包含原數據更多信息的融合特征[16]。本文中的Attention主要是對前面CNN和LSTM提取的特征進行加權處理,從而捕捉到原序列空間和時間上的融合特征,然后放到模型中進行預測,其大致結構如圖3所示。

圖3 Attention結構
φ(hi,C)=tanh(hi·Wα·CT+bα)
(7)
(8)
(9)
式中:Wα是一個m×n的權值矩陣;bα為偏置項;C為CNN網絡得到的特征向量;hi為第i個時刻LSTM得到的特征向量。式(7)是將CNN和LSTM提取到的特征進行加權,并通過激活函數得到融合后的權值;式(8)是將權值通過Softmax函數;最后通過式(9)將LSTM的輸出值與權值相乘得到最終的特征,然后將其通過一個全連接層的網絡輸出預測結果[17],最后通過Softmax函數將數據分類為0(正常)或1(異常)。
2.4 模型結構和參數設置
本文所提出的CNN-BiLSTM-Attention完整結構如圖4所示。

圖4 CNN-BiLSTM-Attention模型結構
圖4中,首先對輸入數據進行預處理,然后將處理過的數據分別輸入到CNN和BiLSTM網絡中去得到相應的空間和時間上的特征,然后將這二維特征使用Attention進行加權,然后將權值與LSTM網絡輸出進行相乘,得到融合特征,然后將其通過全連接層和分類器進行分類。
CNN-BiLSTM-Attention算法流程如算法1所示。
算法1異常檢測算法
輸入:
1.原始時間序列X=[x1,x2,…,xt];
2.滑動窗口的窗長b,步長s;
3.訓練好的CNN-BiLSTM-Attention模型;
輸出:
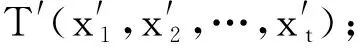
2. 通過CNN網絡從輸入數據中提取高維度空間特征;
3. 通過BiLSTM網絡提取高維度時間特征;
4. 使用Attention機制對空間特征和時間特征進行加權得到融合特征;
5. 將融合特征輸入到全連接層網絡和Softmax函數進行分類,得到分類結果0或1;
Endfor
本文所提出模型中包含許多的參數,其中CNN濾波器個數為64,卷積核大小為5,步長設置為1,LSTM中隱層單元個數為64,Adam優化器用來優化深度學習模型,epoch設置為100,batch size設置為64,學習率設置為10-3,使用tanh作為激活函數,交叉熵作為損失函數來評估模型的優劣。
3 實驗與結果分析
3.1 實驗配置
本文實驗的設備為個人電腦,核心處理器為Intel(R) Core(TM)i7- 9750H CPU @ 2.50 GHz,RAM 16 GB,圖形處理器為NVIDIA GeForce RTX 2060,Windows 10操作系統,開發環境是Python3.6.5,Keras- 2.2.4,TensorFlow- 1.14.0。
3.2 實驗數據及預處理
本文實驗數據集選用雅虎[18]和亞馬遜[19]這兩大云平臺所監控采集的KPI時序數據集。這些數據集來源于真實的業務環境,涵蓋了云環境中大部分KPI時序數據可能出現的形態特征和異常類別,具有較好的代表性。
本文使用了Yahoo Webscope S5異常基準數據集中的A1類,包含67個文件,用于驗證提出的異常檢測算法結構,其收集到的數據來自實際Web服務的流量監測值,采集頻率為5分鐘一次,并且手動標記異常值。亞馬遜的數據集來自于云監控CloudWatch所采集的服務器基礎資源指標數據,包含多種服務器運維指標,并分別以這些指標進行命名。這兩個數據集均是由時間戳、值和標簽組成,KPI中的值是某個KPI指標在對應的時間戳的值,對應上面所說的Web流量監測數據和服務器基礎資源指標數據,是企業經過脫敏處理后的監測數據,標簽是運維人員對于異常與否進行的標注。這里分別選取Yahoo數據集中類別為A1的真實數據集和亞馬遜數據集中編號為cpu_utilization_asg_misconfiguration的監控CPU利用率的數據集進行模型訓練,分別記為數據集①和數據集②。圖5(這里是A1類中的其中一個數據集)、圖6是兩組數據集的時序曲線(為截取的其中一部分數據曲線)。

圖5 數據集①時序曲線
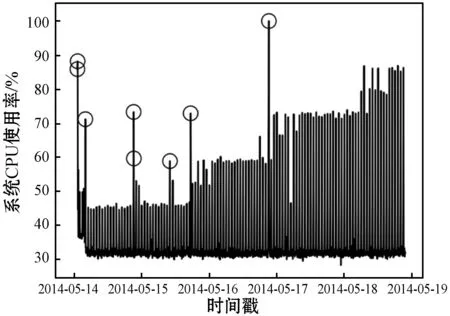
圖6 數據集②時序曲線
由圖5和圖6中的時序曲線可以看出,數據集①中曲線變化趨勢相對明顯,圖5中標注的部分即為離群異常點,真實網絡流量的突增突降意味著網絡的異常占用,對正常用戶使用造成影響。數據集②中,標注的部分表現為數據激增,正常系統中任務到來時CPU利用率會增長繼而表現平穩,并不會突然地增加下降,如圖6中未標注的部分。表1是兩個數據集的數據情況對比。

表1 實驗數據集對比
可以看出,數據集中的負樣本數量占比較大,因為系統在大多數情況下都處于正常工作狀態,因而正負樣本比例嚴重不平衡,這樣會使得模型訓練效果大打折扣。因此本文采用過采樣聯合欠采樣的方法來解決數據不平衡問題[20],對大樣本進行欠采樣,對小樣本進行過采樣,從而使得正負樣本比例接近對等,保證模型的訓練效果。過采樣包含簡單隨機過采樣和啟發式過采樣,前者僅僅是對小樣本進行簡單的復制使得其在數量上大大增加,并沒有增加小樣本所攜帶的特征信息,對于模型訓練效果并沒有很好地提升;后者是利用當前小樣本來合成新的樣本,比較典型的是SMOTE(Synthetic Minority Oversampling Technique)算法,其是在鄰近小樣本之間進行插值,得到新樣本,然后依次進行插值,最終增加小樣本的數量,這樣得到的小樣本就攜帶有新的特征信息,使得模型訓練的效果得以提升。這里主要是用SMOTE算法進行小樣本過采樣和簡單隨機欠采樣,使得數據樣本得以均衡。
在對數據進行均衡之后,需要對數據進一步處理,得到適合模型輸入的數據格式,因為原始數據為一維時間序列,需要將數據處理成多維的向量格式,這里使用滑動窗口的方法,具體流程如圖7所示。

圖7 滑動窗口流程

(10)
(11)
在對數據進行加窗時,還要注意窗口長度和步長的設置,設置過大會使特征淡化,使得數據間的特征偏離原數據特征,因此這里以窗長和步長為變量,對模型進行訓練,得到如圖8和圖9所示的隨訓練周期變化的損失函數曲線。

圖8 數據集①損失函數曲線

圖9 數據集②損失函數曲線
從圖8和圖9的損失函數來看,在進行加窗處理過后,損失值也相應降低,曲線下降趨勢也比未加窗的要快,但是當窗口長度設置較高時,效果反而不佳,因為設置的窗口長度過長時,其提取的特征也會相應偏離原數據特征。因此,針對相應的數據,應設置合適的窗口長度以得到最佳的特征提取效果,由圖8、圖9的下降趨勢來看,這里對數據集①選取窗長b=4,步長s=2,數據集②選取窗長b=6,步長s=2。

(12)
式中:xmin表示數據中的最小值;xmax表示數據中的最大值。
3.3 評價標準
分類算法的評價指標較多,這里選取以下幾個標準對模型進行評估,準確率代表所有分類正確的樣本個數與總體樣本的比例,其數值越高,代表模型預測正確的數目越多,如式(13)所示。精確率代表模型預測結果是正類數的數據中原本為真的數據的比例,數值越高,查準率也就越高,如式(14)所示。召回率代表模型預測為正類數的數據與原本屬于正類數據總數之間的比率,數值越高,查全率就越高,如式(15)所示。F1-score值是由精確率和召回率計算得到的,由式(16)可以看出,當精確率和召回率接近時,其值最大,值的大小往往反映著模型的綜合指標。
(13)
(14)
(15)
(16)
式中:TP為將正類預測為正類的個數;FN為將正類預測為負類的個數;FP為將負類預測為正類的個數;TN為將負類預測為負類的個數。
3.4 實驗結果
將預處理過后的數據放到模型中進行訓練,得到圖10和表2、表3中的實驗結果。

圖10 檢測效果對比

表2 各個模型效果對比(數據集①)(%)
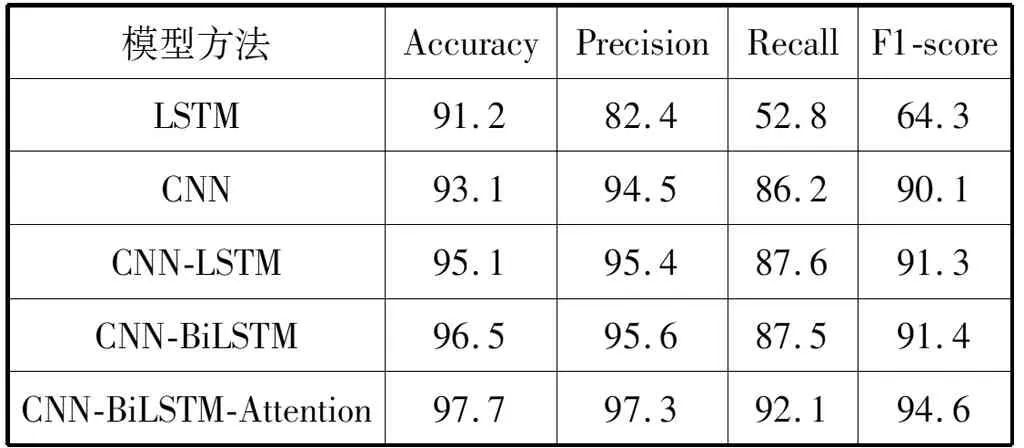
表3 各個模型效果對比(數據集②)(%)
圖10為測試集中原有的標記與模型標記對比圖,模型標記為三角,可以看出模型可以比較準確地標記出異常點位置。由于對數據進行了加窗處理,相鄰的異常點就會標注為一處,比如在橫坐標為1 020位置。而在起始位置數據表現為突增,這里模型進行了異常標注,原數據應表現為機器開始運作有大量的網絡流量涌入,因而出現了誤報的情況。由表2和表3中的數據可以看出,混合模型的訓練效果相比單個模型有著很大的提升,在數據集①中,單個模型的F1-score值均比較低,數據集②中單一LSTM模型的F1-score值也相對較低,通過提取單一的特征可以得到數據間的簡單特征,但當面對數據量較大時,就難免捕捉不到數據間的復雜特征,當使用混合模型時,對數據特征的捕捉能力提升,同時加入雙向LSTM編碼可以對上下文之間的特征獲取更加全面。最后使用Attention可以對特征進行合理加權,得到更好的檢測效果,最終準確率均能保持在97%以上,F1-score值可以達到94%以上,證實了本文模型的有效性。
4 結 語
針對運維系統復雜性和運維數據多樣性的特點,本文提出一種基于CNN-BiLSTM的混合模型,并引入了Attention機制,用于提取融合特征來實現可靠性更高的云數據中心異常檢測,實驗表明該模型表現良好,準確率、精確率及召回率均能達到92%以上,證實了算法的有效性。然而,運維數據的異常檢測通常要關注一個大型系統中的成百上千個參數,在以后的工作中,將轉向如何更加有效地提取多維數據的復雜特征,因為系統的異常往往伴隨著各個指標的偏差,多維監控指標的異常分析對于運維人員監測系統運行狀態更有幫助,其包含有更多的異常判決因素,進而更加有效地提高檢測效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
