基于用戶行為的社交網絡人格特質識別方法
2023-01-27 08:28:28謝柏林黎琦魏娜鄺建
計算機工程 2023年1期
謝柏林,黎琦,魏娜,鄺建
(廣東外語外貿大學 信息科學與技術學院,廣州 510006)
0 概述
社交網絡已經深度融入到人們生活的多個方面,并成為人們獲取信息和發布信息的一個重要平臺。截至2021 年12 月,我國網民規模達10.32 億,其中95%以上的網民使用即時通信,80%以上的網民頻繁使用微信,將近50%的網民頻繁使用微博。
黑客可以從社交網絡上獲取大量用戶的個人信息,目前,社交網絡已成為黑客發起網絡詐騙的主要場地。例如,2021 年我國將近20%的網民遭遇過網絡詐騙,其中大部分網絡詐騙由黑客通過社交網絡發起。
近年來,隨著《網絡安全法》的實施,國家網絡安全宣傳周等一系列活動的持續開展,以及媒體對一些網絡詐騙手段的報道,使我國網民的整體網絡安全意識有所提升,大部分網民能夠辨別一些簡單的網絡詐騙。為了提高社交網絡詐騙的成功率,黑客在發起詐騙之前,通常會判別目標用戶的主要人格特質類型,根據目標用戶的主要人格特質類型制定與其交流的策略和詐騙手段。這類詐騙危害大,且大部分網民難以識別出這類詐騙。
為提高用戶識別社交網絡詐騙的能力,面向社交網絡用戶的人格特質識別方法的研究具有重要意義,以便自動識別用戶擁有的主要人格特質類型,進而得到用戶的主要人格特點,根據用戶的主要人格特點,提醒用戶黑客可能采取的攻擊策略,進而提高用戶識別社交網絡詐騙的能力,最終達到防御社交網絡詐騙的目的。另外,社交網絡用戶人格特質識別的研究在其他方面也有廣泛的應用前景,例如用戶心理預警、個性化推薦[1-2]、網絡不良言論治理等。
大五人格理論[3]是目前最流行的人格理論,該理論從宜人性(Agreeableness)、開放性(Openness)、盡責性(Conscientiousness)、神經質(Neuroticism)和外向性(Extraversion)五個維度來刻畫用戶的人格。基于人格特質詞典和隱半馬爾可夫模型(Hidden semi-Markov Model,HsMM),本文提出面向社交網絡的人格特質識別方法。設計一種人格特質詞典構建方法,根據現有的心理學詞典和社交網絡上能反映用戶主要人格特質類型的高頻詞來構建基準詞典,基于社交網絡語料,采用word2vec、增量聚類算法、HowNet來擴展基準詞典。通過對用戶發表或轉發的文本信息進行動態分析,提取能反映用戶人格特質類型的人格特質詞,采用隱半馬爾可夫模型從用戶發表或轉發文本信息的行為過程中判別用戶擁有的主要人格特質類型。
1 相關工作
在社交網絡用戶人格特質識別方面,文獻[4]提出一種面向Twitter 用戶的人格特質識別系統。該系統首先從用戶發表的所有文本信息中提取特征值,然后利用多層感知器神經網絡、樸素貝葉斯、支持向量機(Support Vector Machine,SVM)分類算法來識別Twitter 用戶的主要人格特質類型,即判別Twitter用戶主要擁有人格特質類型。該系統選用的文本特征包括用戶朋友數或粉絲數,以及每次發表博文時,博文中包含的鏈接、單詞、負向情感詞、正向情感詞、情感符號、逗號、冒號、引號的平均個數等。GOLBECK 等[5]提出根據用戶的語言特征,以及用戶發表的平均每條博文包含的單詞、鏈接、標簽個數等特征,并基于回歸分析算法來識別Twitter 用戶的主要人格特質類型。ADALI 等[6]提出利用用戶發表的博文內容特征,以及用戶的網絡特征,并基于回歸分析算法來識別Twitter 用戶的主要人格特質類型。SKOWRON 等[7]提出一種同時面向Twitter 和Instagram 用戶的人格特質識別方法,該方法首先把用戶分別在Twitter 和Instagram 上產生的數據進行集成,然后根據用戶的粉絲數、朋友數、用戶分享圖片的亮度或色素等特征,以及用戶的語言特征,并基于隨機森林回歸算法來識別用戶的主要人格特質類型。
LI 等[8]提出根據用戶的靜態特征和動態特征,并基于SVM 分類算法來識別微博用戶的主要人格特質類型,其中靜態特征包括用戶性別、朋友數、粉絲數等,動態特征包括單位時間內用戶被提及的次數、發表博文的次數等。WEI 等[9]提出利用用戶的頭像、發表的博文、表情符號,以及用戶與朋友或粉絲的互動模式中的信息,并基于深度學習算法來識別微博用戶的主要人格特質類型。XUE 等[10]提出利用用戶的個人信息和發表博文中的113個特征,并基于標簽分布學習(Label Distribution Learning,LDL)算法來識別新浪微博用戶的主要人格特質類型。LIU 等[11]提出一種面向微博用戶的人格特質識別方法,該方法利用用戶發表的博文語言行為特征,并基于深度學習算法來識別微博用戶的主要人格特質類型。
WANG 等[12]提出一種面向Facebook 用戶的人格特質識別方法,該方法利用用戶的社會網絡特征、語言特征、情感統計特征、話題特征,并基于Kendall相關系數來識別用戶的主要人格特質類型。MARKOVIKJ等[13]提出利用用戶的語言特征、社會網絡特征、屬性統計特征,并基于SMO 分類算法來識別Facebook 用戶的主要人格特質類型。FERWERDA 等[14]提出使用徑向基函數,以及用戶個人簡介中的一些特征,例如工作類型、受教育程度、工作城市、居住城市、移動電話、出生日期、性別、宗教信仰、家庭成員等,識別Facebook 用戶的主要人格特質類型。BACHRACH 等[15]提出利用用戶簡介中的一些特征,例如用戶的朋友數、獲得的點贊數、上傳的照片數等,并基于多元線性回歸模型來識別Facebook 用戶的主要人格特質類型。ORTIGOSA 等[16]提出利用用戶的社交互動特征,基于分類算法來識別Facebook 用戶的主要人格特質類型,其中社交互動特征包括:最近1 個月在Facebook 上發表信息的不同朋友的個數、用戶使用Facebook 的時間等。LIU 等[17]提出利用用戶發表的所有文本的話題信息,基于擴展的隱含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型來識別Facebook 用戶的主要人格特質類型。ZHENG 等[18]基于用戶的個人信息,利用半監督分類算法來識別Facebook 用戶的人格特質類型。
BAI 等[19]提出一種面向人人網用戶的人格特質識別方法,該方法根據用戶的41 個特征,例如用戶的性別、年齡、家鄉所在地、平均每次發表信息所包含的單詞個數等,然后基于C4.5 分類算法來識別用戶的主要人格特質類型。王萌萌等[20]考慮到用戶人格特質間的相關性對用戶人格特質識別的影響,提出一種基于加權非負矩陣分解的用戶人格特質識別模型,以識別社交網絡用戶的主要人格特質類型。XUE 等[21]提出利用深度學習方法和語義分析來識別社交網絡用戶的人格特質類型。ZHU 等[22]基于用戶喜愛的圖片,利用卷積神經網絡來識別社交網絡用戶的人格特質類型。TAREAF 等[23]提出利用用戶的喜愛和機器學習分類算法來識別Facebook 用戶的人格特質類型。LAI 等[24]基于學生的在線學習行為和擴展的最近鄰算法來識別學生的人格特質類型。GUAN 等[25]基于用戶發表的文本信息和Skipgram 算法來識別社交網絡用戶的人格特質類型。KUMAR 等[26]提出一種基于語言特征、內容特征,并利用決策樹和SVM 分類算法來識別用戶人格特質類型的系統。YUAN 等[27]利用博文的中文語言特征和機器學習分類算法來識別新浪微博用戶的人格特質類型。YANG 等[28]提出一種基于圖卷積網絡的人格特質識別方法。MAROUF 等[29]對比分析了5 種用于人格特質識別的特征選擇算法。另外,張磊等[30]綜合分析了現有的一些社交網絡用戶人格特質識別方法,指出了未來研究需要解決的一些問題。
以上大部分方法通過挑選一些屬性,并基于訓練好的分類模型來識別用戶擁有的主要人格特質類型。這些方法沒有考慮用戶在社交網絡上發表或轉發文本信息的行為過程,而用戶的這種行為過程更能體現用戶的主要人格特質類型。本文通過構建面向社交網絡的人格特質詞典,結合隱半馬爾可夫模型[31-32]來刻畫用戶在社交網絡上發表或轉發文本信息的行為過程,以識別用戶的主要人格特質類型。
本文提出的社交網絡人格特質識別方法,通過對用戶發表或轉發的文本信息進行動態分析,提取出能反映用戶人格特質類型的人格特質詞,同時采用隱半馬爾可夫模型刻畫用戶發表或轉發文本信息的行為過程,以判別用戶擁有的主要人格特質類型。當用戶的主要人格特質類型發生變化時,該方法也可以動態識別出用戶最新的人格特質類型。
2 社交網絡用戶人格特質識別方法
在社交網絡上,用戶發表或轉發的文本信息能反映出用戶的主要人格特質類型,當社會上發生某件大事時,大部分具有相同主要人格特質類型的用戶會發表或轉發相似的文本信息。本文使用人格特質詞典來獲取用戶發表或轉發的文本信息中能反映用戶主要人格特質類型的觀測值,然后采用隱半馬爾可夫模型來刻畫用戶在社交網絡上發表或轉發文本信息的行為過程。
本文的人格特質詞典把常用的能反映用戶主要人格特質類型的詞分為神經質、宜人性、開放性、盡責性和外向性。為此,本文提出一種面向社交網絡的人格特質詞典構建方法。人格特質詞典的構建流程如圖1 所示。其中最初的人格特質基準詞典是根據現有的心理學詞典和社交網絡上一些能反映用戶主要人格特質類型的高頻詞來建立。
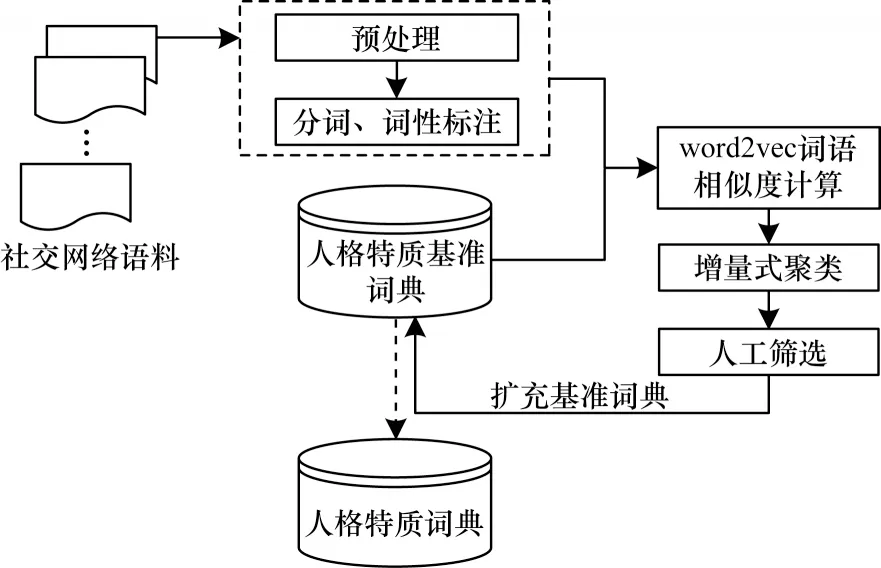
圖1 人格特質詞典的構建流程Fig.1 Construction process of personality trait dictionary
具有相同主要人格特質類型的用戶在使用社交網絡過程中,其發表或轉發的文本信息中人格特質詞的統計特征一般會隨著時間發生變化。例如,主要擁有開放性人格特質的用戶在發表或轉發某個文本信息過程中,開放類型人格特質詞的加權和較大,而在另一個文本信息中開放類型的人格特質詞加權和的值較小。本文將人格特質詞的不同類型統計特征作為狀態,令不同狀態的個數為I(k),即由于狀態與用戶在發表或轉發文本信息中產生的觀測值不具有一一對應的關系,因此本文假定狀態的轉移過程服從隱馬爾可夫過程。

隱馬爾可夫模型[33]的狀態持續時間概率必須服從指數分布,隱半馬爾可夫模型對此進行了擴展,使其狀態持續時間概率服從任何分布。因此,用戶在發表或轉發文本信息過程中反映其人格特質類型的行為狀態轉移過程實際是一個隱半馬爾可夫模型。
主要擁有第k類人格特質的某個用戶在社交網絡上發表或轉發文本信息時,其行為的狀態跳轉過程如圖2 所示。其中表示第t個觀測值,表示狀態轉移概率,表示不同狀態,表示不同狀態的持續時間。
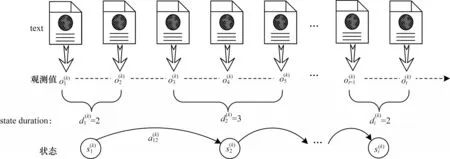
圖2 狀態跳轉過程Fig.2 State transition process
本文提出的人格特質識別方法分為模型訓練和人格特質識別兩個階段。
2.1 模型訓練階段
本文首先在社交網絡上采集大量用戶產生的相關數據,然后根據現有的人格特質識別方法選用一些特征,并使用K-means 聚類算法把用戶劃分成5 個不同的簇,并對每個簇中的用戶進行人工檢驗和篩選,使得每一個簇中的用戶擁有相同的主要人格特質類型。在第k個簇中,提取出用戶在發表或轉發文本信息時產生的能反映用戶主要擁有第k種人格特質類型的觀測序列,并作為同一模型的訓練數據集。本文采用多序列和基于文獻[32]中的前向-后向算法來訓練模型。






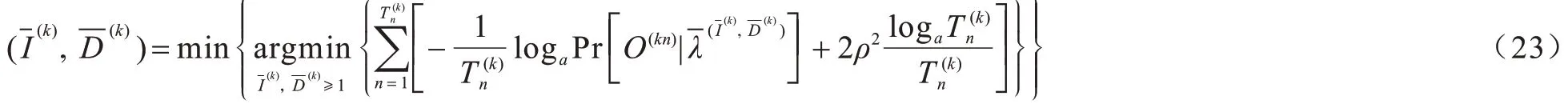
其中:平滑系數ρ=I(k)D(k)(I(k)D(k)+V-2)。
在模型訓練結束后,得到λ(1)、λ(2)、λ(3)、λ(4)、λ(5)的值,分別表示主要擁有不同人格特質類型的用戶在發表或轉發文本信息時的行為模型。
2.2 人格特質識別階段
當某個用戶在社交網絡上發表或轉發文本信息時,采用以下步驟對該用戶的主要人格特質類型進行識別,其中t的初始值為0:
1)在當前時刻,如果該用戶在社交網絡上發表或轉發某條文本信息,則令t=t+1,并使用人格特質詞典統計的值,1≤k≤5。
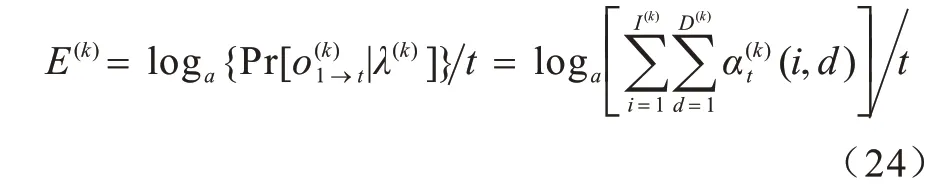
3)得到使E(l)≥E(k)成立的l,1≤l≤5。當E(l)大于某個閾值時,則得到該用戶擁有的主要人格特質類型l,否則跳轉到第1 個步驟。
3 實驗測試與結果分析
新浪微博是我國最大的微博網站,截至2021 年4 月,其日活躍用戶數已達到2.3 億。本文在新浪微博上選擇42 210 個活躍用戶(其發表或轉發博文的數量大于1 000 條),使用新浪微博的API 采集這些用戶發表或轉發的所有博文,并保存在數據庫中作為構建人格特質詞典的語料庫。
3.1 人格特質詞典構建
本文利用現有的停用詞表和一些過濾規則去除語料庫中的停用詞和無意義的詞,其中無意義的詞分為純數字的詞語和由非表情符的純標點符號組成的字符串兩種。本文把預處理后語料庫中的詞語等分為Y個互不相交的子集,令y的初始值為1,則人格特質詞典的構建主要分為以下4 個步驟:1)使用word2vec 計算第y個子集的詞語與基準詞典各個類別下詞語的相似度;2)基于詞語的相似度,使用增量式聚類算法擴展每類人格特質詞語的規模;3)使用HowNet 與人工相結合的方式來篩選詞語,并更新基準詞典;4)如果y=Y,結束循環;否則令y=y+1,并跳轉到第1 個步驟。
經過人工篩選,本文得到的基于新浪微博語料的人格特質詞典包含2 390 個詞語。該詞典中各人格特質類別的詞語數量分布如表1 所示,其數據格式如表2 所示。

表1 人格特質詞典的詞語數量分布Table 1 Word quantity distribution of personality trait dictionary
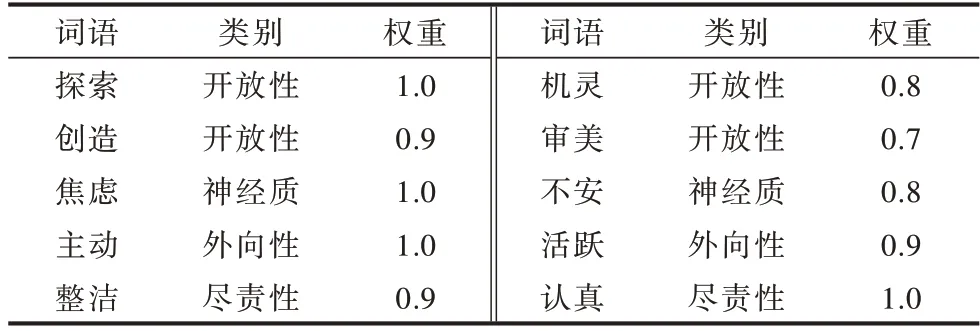
表2 人格特質詞典的詞語數據格式示例Table 2 Data format example of word of personality trait dictionary
3.2 人格特質識別方法測試
在采集到的新浪微博數據集中,人工篩選出主要擁有神經質、宜人性、開放性、盡責性、外向性人格特質類型的用戶各3 000 名,使用本文構建的人格特質詞典提取能反映其主要人格特質類型的觀測序列,并分別標注為Data(N)、Data(A)、Data(O)、Data(C)、Data(E)。
為了訓練得到主要擁有神經質人格特質類型的用戶行為模型(用N-HsMM 代表該模型),本文在Data(N)中隨機抽取2/3 的觀測序列用于模型訓練,剩余1/3 的觀測序列用于模型測試。此外,本文在Data(A)中隨機抽取1/3 的觀測序列用于測試N-HsMM 的性能。同理,采用相同的方式來訓練、測試A-HsMM、O-HsMM、C-HsMM、E-HsMM 的性能。A-HsMM 表示主要擁有宜人性人格特質類型的用戶行為模型,O-HsMM 表示主要擁有開放性人格特質類型的用戶行為模型,C-HsMM表示主要擁有盡責性人格特質類型的用戶行為模型,E-HsMM 表示主要擁有外向性人格特質類型的用戶行為模型。各個HsMM 的訓練集和測試集信息如表3 所示。N-HsMM 模型的ROC 曲線如圖3 所示。
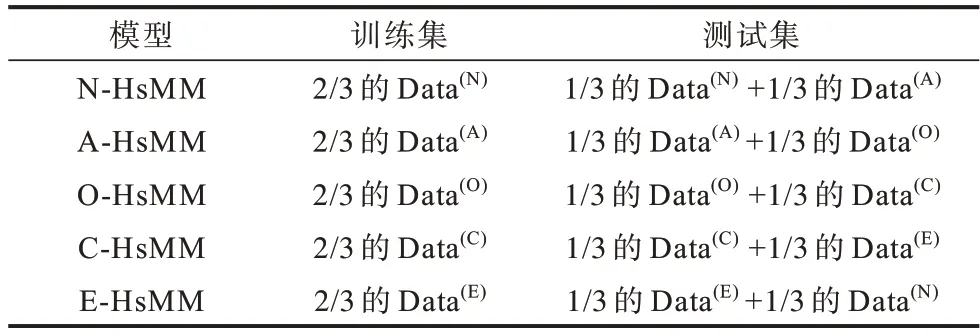
表3 HsMM 模型的訓練集和測試集Table 3 Training and testing sets of HsMM model
當本文選擇模型的真正率(True Positive Rate,TPR)為0.913 時,模型的假正率(False Positive Rate,FPR)為0.1。真正率TTPR、假正率FFPR的計算分別如式(25)和式(26)所示:

其中:user(N)表示主要擁有神經質人格特質類型的用戶;user(A)表示主要擁有宜人性人格特質類型的用戶。
A-HsMM 模型的ROC 曲線如圖4 所示,當模型的FPR 為0.1 時,模型的TPR 為0.907。
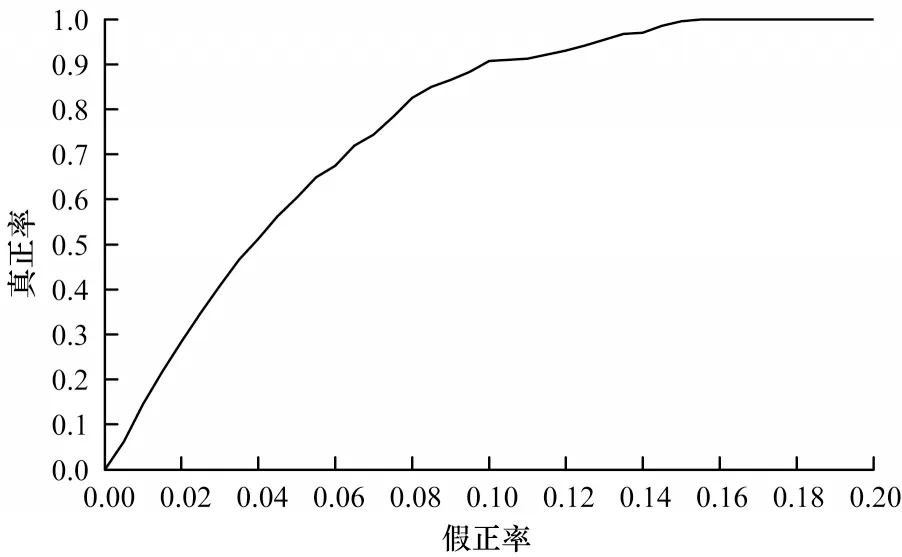
圖4 A-HsMM 模型ROC 曲線Fig.4 ROC curve of A-HsMM model
O-HsMM 模型的ROC 曲線如圖5 所示,當模型的FPR 為0.1 時,模型的TPR 為0.946。C-HsMM 模型的ROC 曲線如圖6 所示,當模型的FPR 為0.1 時,模型的TPR 為0.928。
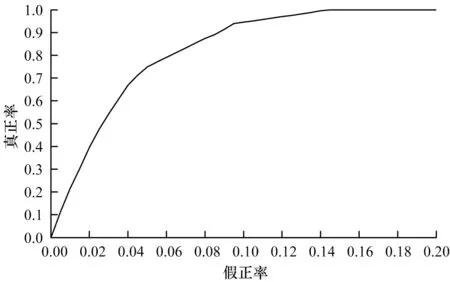
圖5 O-HsMM 模型的ROC 曲線Fig.5 ROC curve of O-HsMM model
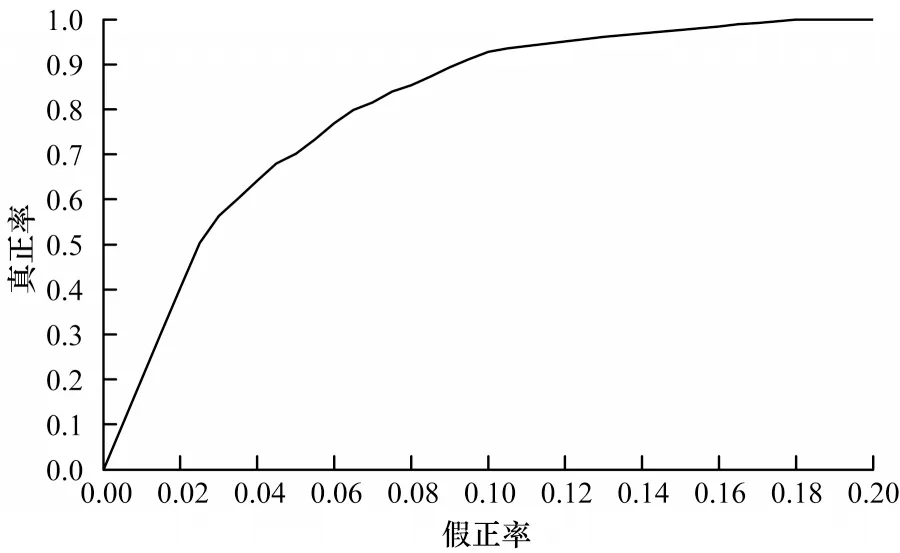
圖6 C-HsMM 模型ROC 曲線Fig.6 ROC curve of C-HsMM model
E-HsMM 模型的ROC 曲線如圖7 所示,當模型的FPR 為0.1 時,模型的TPR 為0.965。
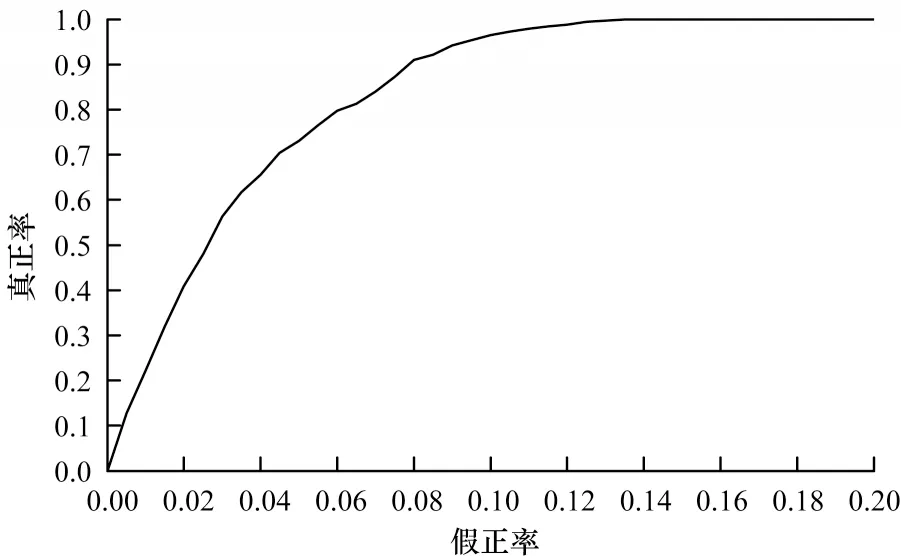
圖7 E-HsMM 模型ROC 曲線Fig.7 ROC curve of E-HsMM model
各個HsMM 模型的訓練時間和測試時間對比如表4 所示。

表4 各個HsMM 模型的訓練時間與測試時間對比Table 4 Training time and testing time comparison among each HsMM model 單位:s
本文提出的方法分為模型訓練和人格特質識別兩個階段,其中模型訓練階段可以線下進行。在人格特質識別階段中,前向變量每次更新的復雜度為O(I(k)D(k)+I(k)I(k)),每次更新觀測序列相對模型的平均對數似然概率時僅涉及到幾十次乘法和幾十次加法,因此該方法具有較快的識別速度。
實驗結果表明,本文提出的方法具有較優的識別性能,通過選取合適的閾值,具有較高的真正率和較低的假正率。
4 結束語
本文提出一種基于用戶發表或轉發文本信息行為的人格特質識別方法。通過構建人格特質詞典,提取用戶在發表或轉發文本信息時產生的人格特質詞,使用隱半馬爾可夫模型刻畫用戶的行為過程,通過對擁有不同人格特質類型的用戶在發表或轉發文本信息時的行為模型進行訓練,并計算每個用戶產生的觀測序列相對于每個模型的平均對數似然概率。實驗結果表明,該方法能準確識別用戶的人格特質類型。下一步將優化隱半馬爾可夫模型,以提高人格特質識別性能并降低誤報率,使本文方法適用于實際的社交網絡平臺。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
創業家(2015年5期)2015-02-27 07:53:25
