一種基于詞頻-逆文檔頻率和混合損失的表情識別算法
2023-01-27 08:28:30藍崢杰王烈聶雄
計算機工程 2023年1期
藍崢杰,王烈,聶雄,2
(1.廣西大學 計算機與電子信息學院,南寧 530004;2.廣西多媒體通信與網絡技術重點實驗室,南寧 530004)
0 概述
人臉表情包含豐富的語義信息,能夠影響人們的溝通過程。近年來,人臉表情識別(Facial Expression Recognition,FER)在個性化推薦、社交應用、醫療健康、自動駕駛等諸多新興交互系統中逐漸展現出應用價值,成為計算機視覺領域的一個研究熱點。
在FER 任務中,受到人種不同、年齡差異以及側臉、光照不均等外界因素的影響,其識別準確率普遍較低。隨著深度學習技術在圖像處理領域取得成功,基于深度學習的FER 算法已成為人臉表情識別領域的主流方法。當前較多的研究人員在數據處理、損失函數設計、特征提取等方面對FER 網絡進行優化。
在數據處理方面,常規做法包括對圖像進行幾何變換、色調變換、局部遮擋處理等操作,以增加訓練樣本數量。在數據驅動的深度學習技術中,通過數據集來提高訓練效果的方法已經被廣泛使用。文獻[1]提出一種針對FER 中嘈雜數據集的數據處理方法,通過對每個Batch 中的數據樣本按照確定性進行權重排序和分組,在訓練時加強確定性高質量樣本的權重,抑制低質量數據對網絡的影響。通過實驗表明,該方法在數據嘈雜的FER 數據集中取得了較高的識別準確率。
在特征提取方面,有一些研究使用多CNN 支路并行的方式提取特征,如XU 等[2]為了提取更多細微的人臉表情,設計一個具有2 路并行的網絡來分別提取不同尺度的圖像特征,最后將特征進行融合并用Softmax 輸出分類結果。有部分研究則側重于對表情產生關鍵區域的特征進行提取,如VERMA 等[3]提出一個具有視覺和面部標識分支的網絡,其視覺分支負責圖像序列的輸入,并引入從低層到高層的跳轉連接,關注因面部區域(如眼睛、鼻子、嘴唇等)的變化而引起的面部表情信息,該方法在CK+數據集上取得了較高的識別率。CHEN 等[4]對VGG16 網絡進行改進,提出一種20 層并基于VGG 和殘差網絡結構的CNN 網絡,其采用混合特征策略將Gabor 濾波器CNN 并行化以實現表情識別,在部分遮擋的面部表情數據庫中,該網絡取得了較好的識別效果,具有良好的應用價值。文獻[5]將表情圖像劃分成43 個子區域,將肌肉運動區與面部器官所覆蓋的8 個候選區域輸入8 個并行的特征提取分支以提取特征,每個分支使用不同維的全連接層,最后經Softmax 函數輸出分類結果。
在損失函數方面,由于表情類間差異小,分類邊界模糊,因此諸多研究通過改進損失函數來提高分類準確率。文獻[6]為了加大不同類別中心之間的分類距離,提出島嶼損失函數(Island Loss),通過在特征提取層的Island Loss 和輸出層的Softmax 損失監督CNN 訓練過程。文獻[7]在使用分組卷積操作對通道注意力模塊進行改進后,引入孤島損失函數,將其與Softmax 分類損失函數相結合,構建新的損失函數,并獲得了較好的表情識別效果。文獻[8]提出一種locality-preserving 損失函數,其使得同一類別的樣本特征聚攏,每個表達式的類內局部簇更接近,最后將所提損失與Softmax 聯合訓練,增強了對表情特征的鑒別能力。
本文從特征提取和損失函數2個方面入手,對人臉表情進行識別。提出一種基于詞頻-逆文檔頻率(Term Frequency-Inverse Document Frequency,TF-IDF)的空間金字塔注意力機制,以增強表情關鍵區域的特征關注度,使用詞頻-逆文檔頻率算法強化表情關鍵區域內細微特征的權重值,增強表情特征的提取能力。同時,改進針對FER 任務的損失函數,在交叉熵損失和Arcface 損失函數的基礎上提出一種混合加權損失函數(Weighted Hybird Loss function),從而緩解數據集中樣本數量分布不均的問題,加強類內聚攏,增大類間邊界。
1 注意力機制
1.1 空間金字塔注意力
近年來,注意力機制在計算機視覺任務中得到廣泛使用[9]。注意力機制模擬了人類視覺辨析機制,人類的視覺系統會選擇性地關注圖像中的關鍵區域信息,同時忽略掉不重要的信息[10]。
空間金字塔注意力網絡(SPANet)[11]是一種新穎的注意力結構,獲得了ICME2020 最佳學生論文獎。SPANet 提出空間金字塔注意力結構(Spatial Pyramid Attention,SPA),利用3 個自適應平均池化構成金字塔結構,改進了SE-Net 注意力網絡中由于在大尺寸、高分辨率特征圖中應用全局平均池化(Global Average Pooling,GAP)所導致的細節信息丟失問題。SPANet 注意力結構如圖1 所示[11]。
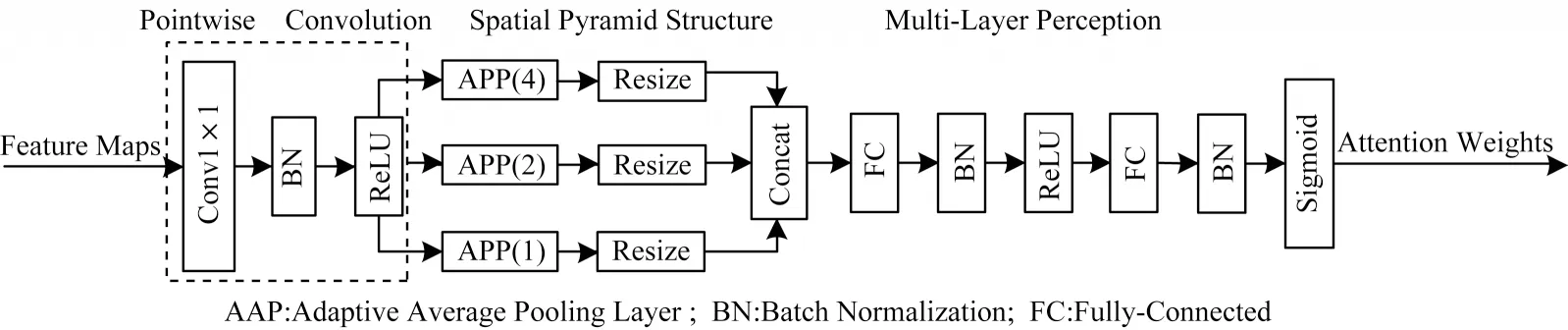
圖1 SPANet 注意力結構Fig.1 SPANet attention structure
在圖1 中,在對輸入特征圖進行逐點卷積后,使用3 個自適應平均池化改進傳統的全局平均池化以統計空間上下文信息,使得提取到的特征圖中保留更豐富的細節信息,有助于提升細粒度表情分類效果。本文所設計的注意力機制是在SPANet 基礎上進行的改進。
1.2 詞頻-逆文檔頻率原理
TF-IDF 常被應用于自然語言處理(Natural Language Processing,NLP)及搜尋引擎中,用于評估某一個詞組對于某文檔集的重要程度,是某個詞語普遍重要性程度的度量。在NLP 任務中,字詞的重要性隨著其在文檔中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。TF-IDF 可保留文檔中較為特別的關鍵詞,過濾掉語義信息不明顯的常用詞,如the、is 等。受此啟發,本文引入TF-IDF 改進注意力機制,增強網絡對表情產生關鍵區域重要特征通道的提取能力。
在FER 數據集中,通道特征圖中非零像素(白色區域少)占比小,灰度值像素區域占比大。在表情表達的過程中,嘴角、眉間、眼角等非零像素區域具有關鍵的特征,為了降低這些重要特征在多輪池化中丟失的可能,提高這些非零像素細微特征在人臉表情判斷中的重要程度,本文使用TF-IDF 引導金字塔池化注意力網絡關注語義信息更明顯的表情產生區域,增強嘴角、眼角等關鍵區域的細微特征表達。
1.3 詞頻-逆文檔頻率空間金字塔注意力
在細粒度表情識別中,當圖像特征細微且出現次數有限時,特征提取網絡容易忽略掉該區域的細節特征,造成細節信息丟失,從而影響最終的分類結果[12]。使用TF-IDF 構建注意力機制捕捉重要特征并學習其與表情類別之間的關聯,能夠使網絡形成更準確的注意力熱圖,從而提高網絡的分類性能。
將TF-IDF 算法思想結合到金字塔池化注意力機制中,得到逆向文檔頻率空間金字塔注意力(TFIDF SPA),其結構如圖2 所示。
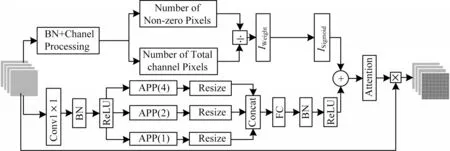
圖2 TF-IDF SPA 注意力機制結構Fig.2 TF-IDF SPA attention mechanism structure
TF-IDF SPA 注意力機制由兩部分結構組成,上半支路為詞頻-逆文檔頻率模塊,下半支路使用SPA注意力機制實現,TF-IDF 模塊和SPA 注意力模塊進行Concat 拼接后形成新的注意力輸出,用以對輸入特征圖進行注意力處理。
在上支路的IDF 模塊中,從左到右包含3 個主要的功能結構。上支路的實現過程為:
1)計算非零區域詞頻,該部分的處理過程如圖2上半部分所示,在經過批歸一化(Batch Normalization,BN)后進入通道處理過程,通過計算通道特征中非零像素的個數和通道像素的總數,將兩者相除獲得通道特征中非零區域的占比。用Ni表示每一個通道特征圖中非零像素的個數,每個通道特征圖大小為W×H,統計出某一個非零區域在一個給定區域中出現的頻率Di,計算過程如式(1)所示:
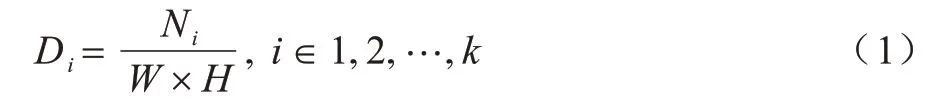
2)求出該區域中非零像素的普遍重要性。本步驟求取逆文檔頻率IDF,其數值能衡量某一特征的普遍重要性程度,通過特征圖中所有特征通道數量除以包含該特征的通道數量然后取對數得到,計算方法如式(2)所示:

3)對式(2)中的結果用Sigmoid 函數激活,如式(3)所示:
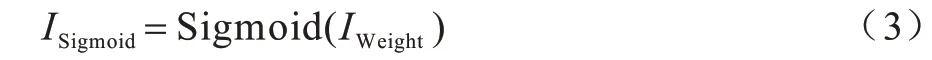
4)最后求出詞頻注意力權重,將詞頻與逆文檔頻率相結合獲得輸出權值,如式(4)所示:
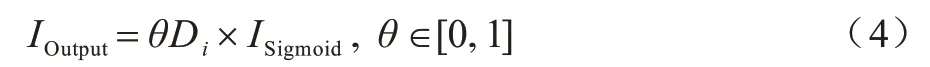
式(4)為TF-IDF 部分的輸出結果,其中,θ為調整詞頻對最終結果的影響,取值范圍為0~1,本文經實驗測試,取θ值為0.15。
下支路SPA 注意力模塊由3 個部分構成,如圖2 中下半部分所示,從左到右第一部分結構為1×1 卷積、BN和Sigmoid 激活函數,主要用于匹配輸入特征圖的通道數并提取特征;第二部分為自適應空間金字塔池化結構(Adaptivce Average Pooling,AAP),圖2 中AAP(4)和AAP(2)分別代表不同下采樣尺度的池化操作,通過并行加入3 個不同尺度的池化層,保證特征圖的多樣性,減少傳統全局平均池化聚合到一個平均值而導致的信息丟失;第三部分為多層感知模塊,由全連接層(Fully-Connected)、BN 和激活函數組成。
1.4 基于TF-IDF SPA 的殘差模塊
在詞頻-逆文檔頻率注意力機制中,下支路SPA注意力機制所得的權重與上支路TF-IDF 模塊輸出的Ifinal系數進行疊加形成TF-IDF SPA 注意力權重,從而提取表情產生區域詞頻重要性高的關鍵細節特征。在本文中,將TF-IDF SPA 組成帶有殘差結構的模塊嵌入網絡中使用,模塊結構如圖3 所示。
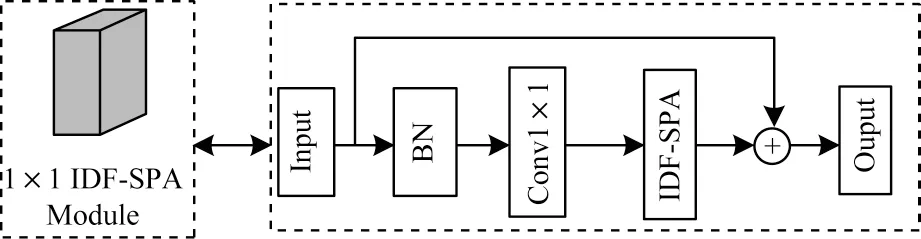
圖3 由TF-IDF SPA 組成的殘差模塊Fig.3 Residual module composed of TF-IDF SPA
TF-IDF SPA 注意力模塊使用金字塔池化避免全局平均池化所導致的表情特征丟失,豐富表情特征圖的細節表示,并使用詞頻-逆文檔頻率引導注意力網絡突出關鍵區域的重要細節特征。
2 損失函數改進
在圖像分類任務中,常用Softmax 作為損失函數監督網絡訓練,該損失函數結構簡單,在多數情況下能取得良好的分類效果,但在人臉表情識別任務中,表情樣本存在數據類別分布不均、樣本類間差異小、類內差異大、某些表情之間分類邊界模糊的問題。因此,對損失函數進行改進成為提高表情識別準確率的關鍵步驟。本文主要的改進思路是:加強同一類表情的類內聚攏性,加大不同類別模糊表情間的分類邊界,同時調節權重使得網絡關注小數據量樣本類別的學習。
2.1 同類樣本類內聚攏
WEN 等[13]在傳統Softmax 函數的基礎上進行改進,提出Center Loss 函數,其為每個類別的數據定義一個樣本中心,各類別的樣本均向本類別的樣本中心聚攏,聚攏方法為:

其中:xi為第i個樣本對應的特征向量(全連接層之后、決策層之前提取到的特征)是第i個類別樣本的中心點處。通過最小化Lcenter使得每個批次中的每個樣本與聚類中心的距離縮小,從而把相同類的樣本都聚攏到類別中心,使得類內簇更加緊密。
2.2 類間邊界增大
類間邊界增大通常有如下兩種方法:
1)島嶼型損失。
在類內聚攏的基礎上擴大類間距離,能使決策邊界更為清晰,有助于模型分類。CAI 等[5]提出一種孤島化分離不同類別樣本的方法,使得類間差異顯著增大,其表達定義為:
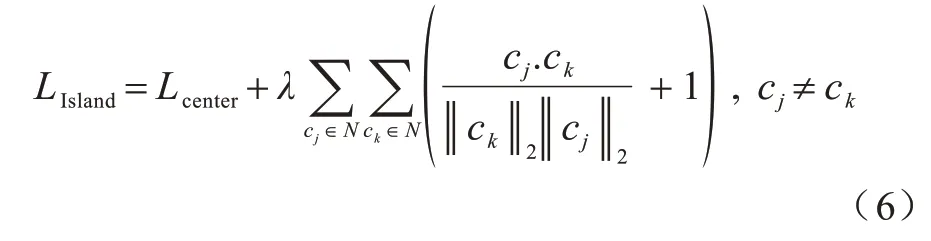
式(6)由2 個部分組成,Lcenter使得類內簇聚攏,后一部分為求每個類別中心的余弦間距,式中+1 操作使得變化范圍為0~2,越接近0 即代表類別之間差異越大,從而訓練Loss 收斂后實現類間距離變大的效果。經式(6)的損失函數處理,7 個表情類別各自分離為7 個島嶼化分布,如圖4 所示。
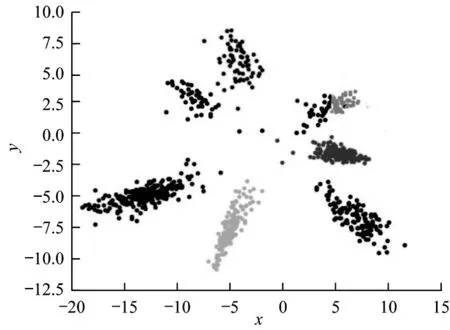
圖4 島嶼型損失函數樣本分布Fig.4 Sample distribution of Island Loss function
2)基于角度距離優化方法。
WANG 等[14]提出一種基于余弦距離(Cosine Margine)的損失函數,引入角度間距,使用cosθ減去某一標量m,設定不同的類間邊界,如下:

式(7)為劃定的分類邊界,利用m的取值大小在不同的類別中形成不同大小的分類邊界:
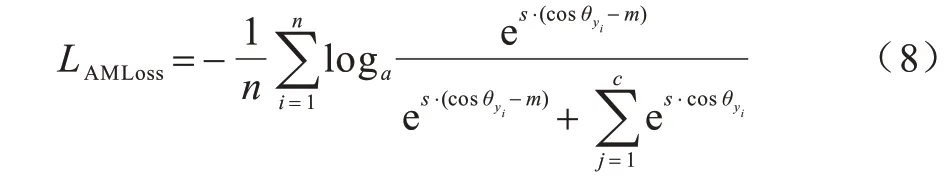
式(8)為其標準實現過程,在實現過程中,將輸入特征做歸一化處理,使得x=cosθ yi,因此,間距簡化為:

使用式(9)替換式(8)的cosθ,該表達式最終寫為:
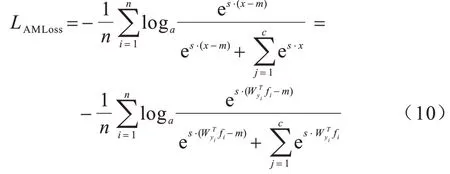
在式(10)中,WANG 等[14]引入了超參數s,為了提高損失函數LAMLoss的收斂速度,s設為固定值30。
2.3 加權重的分類損失函數
2.3.1 交叉熵損失函數
交叉熵損失(Cross Entropy Loss,CE)函數應用廣泛,其可以保證神經網絡的基本分類能力,表達式為:
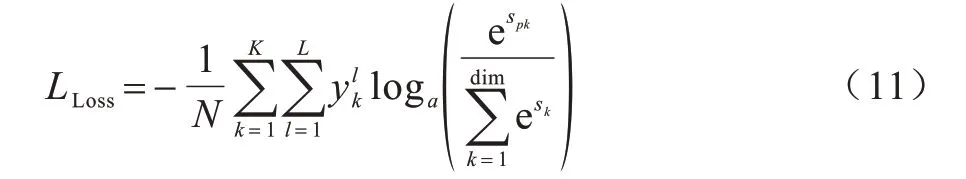
在FER 數據集中,每個類別的樣本數量不平衡。在各類別數量差異大的數據集中,網絡通常傾向于擬合數量較大的類別,由于訓練損失下降到一定程度后,在碰到困難樣本時,將分類結果“簡單而盲目”地判定為大數據量對應的類別即可獲得概率更大的準確率,而對于小數據量樣本類別,網絡則需要花費更多的訓練代價才會取得訓練損失值很小幅度的下降,這就導致了網絡對小數據量類別及難例樣本的訓練“惰性”,從而影響特征提取效果。對分布不均勻的數據集進行權重調整,有利于難例樣本和小數據量樣本的特征提取。
2.3.2 權重調整方法
本文在損失函數設計中提出一種提高不平衡分類性能的方法,根據不平衡樣本類分配比例調整加權值,其定義如下:

其中:N為總樣本數;L為總類數;mk為某一類別k的樣本數。通過式(12)操作調整不平衡樣本的權值。
2.3.3 加權交叉熵損失函數
加權交叉熵損失函數定義為:
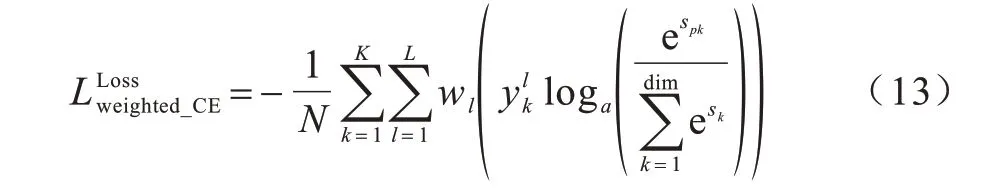
式(13)是權值分配方法與傳統交叉熵損失函數相乘而得到的,通過此設計優化了損失函數中小數量、難分類樣本的權重,使得模型在訓練過程中更關注小數據量樣本和難例樣本。
2.4 混合加權余弦損失函數
本文最終基于角度距離的損失函數為:
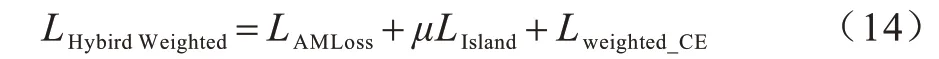
其中:μ為島嶼損失將樣本孤島化分布的系數,在實驗中取0.01 可獲得較快的收斂效果;LAMLoss作為輔助分類損失函數,目的在于拉開分類邊界;Lweighted_CE監督分類輸出。混合加權損失LHybirdWeighted獲得了優于現有單一損失函數的分類效果,在實驗中取得了更快的收斂速度和更高的分類準確率。
3 網絡總體結構
本文使用CNN 特征提取網絡結構,由多層3×3 小尺度核卷積層嵌入TF-IDF SPA 注意力模塊堆疊組成,圖5 所示為總體網絡結構。圖中R×R×C表示每層輸出分辨率大小為R×R、通道數為C的特征圖。每個卷積組合依次為批歸一化BN、3×3 卷積、Mish 損失函數。第一個全連接層使用島嶼損失LIsland促使特征形成島嶼形分布。最后一層使用LAMLoss加大類間界限,同時利用加權重的分類損失函數LWeight_CE對高維特征進行分類輸出。網絡中的主要參數如表1 所示。

圖5 網絡總體結構Fig.5 Overall network structure
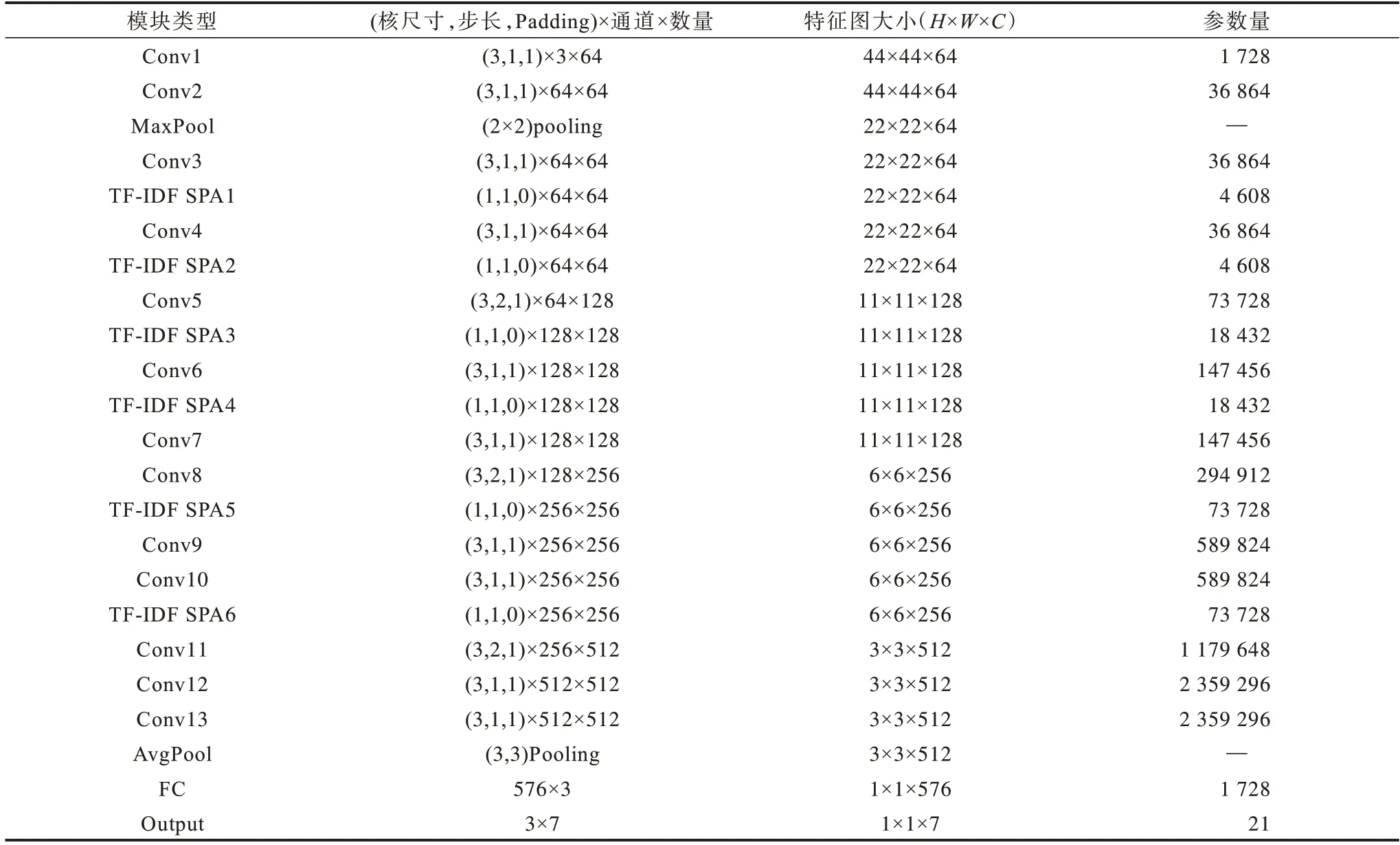
表1 模型主要參數Table 1 Main parameters of the model
4 實驗分析
本文實驗配置:處理器Intel Xeon Gold 6230,顯卡NVIDIA Tesla T4,內存16 GB,操作系統Ubuntu 16.04,深度學習框架Pytorch,編程實驗均在Python 3.7 環境下進行。
4.1 數據集
4.1.1 數據集類別
CK+數據集[15]是CK 數據集的擴展,包含593 個視頻序列和7 種靜態表情圖像。靜態圖像是在實驗室環境下拍攝的年齡從18 歲~30 歲的123 名受試者的表情圖像,共計981 張。CK+實驗數據包含高興、厭惡、害怕、生氣、傷心、驚訝、蔑視7 類。由于數據集樣本數量少,為了提高測試的準確性,使用K 折交叉驗證法[16]進行實驗,在實驗中隨機將數據集劃分為K個,其中K-1 個用于模型訓練,剩余1 個用于測試,本實驗中K取10。CK+數據分布如圖6 所示。
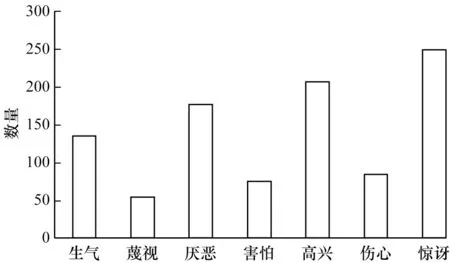
圖6 CK+數據集中的各類別樣本分布Fig.6 Distribution of various samples in CK+dataset
FER2013 數據集[17]從互聯網中收集而得,是Kaggle 人臉表情競賽數據集,且為目前規模較大的表情識別數據集[18]。FER2013包含人臉圖像35 887張,28 709 個訓練圖像、3 589 個驗證圖像和3 589 個測試圖像,帶有7 個標簽,分別為憤怒、厭惡、恐懼、快樂、中性、悲傷和驚訝。數據集中的樣本在年齡、人種、面部方向等方面都有很大的差異,存在側臉表情及模糊卡通表情,是一個具有挑戰性的表情識別數據集。FER2013 數據分布如圖7 所示。
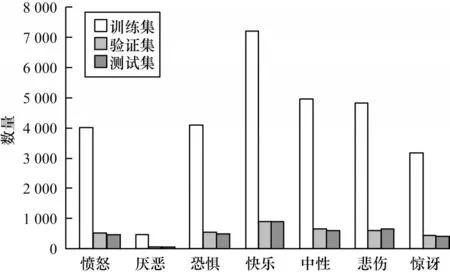
圖7 FER2013 數據集中的各類別樣本分布Fig.7 Distribution of various samples in FER2013 dataset
4.1.2 數據增強操作
數據增強是在不改變樣本類別標簽的情況下對數據進行幾何變換、色調變換、像素擾動、添加噪聲等操作,能簡單有效地擴充訓練集數量,提高網絡在復雜背景下的泛化能力,對于CNN 訓練過程意義重大。在本文實驗中,對數據進行水平翻轉、伽馬變換和隨機遮擋,將訓練數據量擴充8 倍,操作如圖8所示。
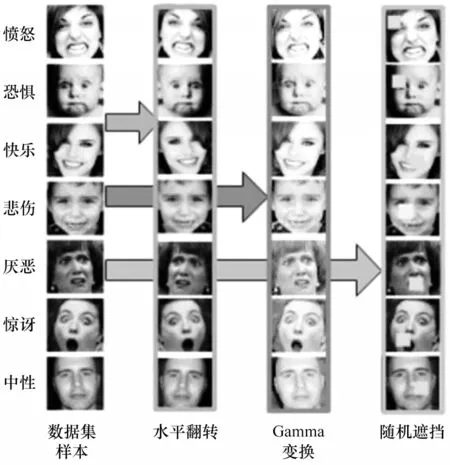
圖8 在FER2013 數據集中的數據增強操作Fig.8 Data enhancement operation in FER2013 dataset
4.2 結果分析
為了驗證本文所提方法的有效性,實驗中將所提方法分別加入網絡中進行對比。
實驗1TF-IDF SPA 注意力機制有效性實驗
本部分進行4 組對比實驗,在FER2013 中使用交叉熵損失函數的情況下,驗證未加入注意力機制、加入SE 注意力機制、加入SPA 注意力機制、加入TFIDF SPA 注意力機制在FER2013 數據集上的有效性,實驗結果如表2 所示。

表2 注意力機制有效性實驗結果Table 2 Experimental results of the effectiveness of attention mechanism
從表2 可以看出:采用不加注意力僅使用殘差結構的特征提取網絡進行特征提取,所得的識別準確率為68.79%,性能較差;采用SE 注意力機制改進特征提取網絡,準確率得到3.24 個百分點的提升;用SPA 金字塔空間池化注意力取代SE 注意力,性能提升0.11 個百分點;加入TF-IDF 模塊后,網絡識別準確率持續提升,較SPA 注意力提升了0.32 個百分點,較不加注意力提升了3.67 個百分點,提升效果明顯。實驗結果表明,注意力機制對于特征提取效果具有積極的作用,同時改進型的TF-IDF SPA 注意力較SE、SPA 等注意力能獲得更好的識別效果。
實驗2改進損失函數有效性實驗
本部分進行5組對比實驗,在使用相同TF-IDF SPA注意力機制特征提取網絡的情況下,分別測試Cross-Entropy、Weighted Cross-Entropy、Island Loss、AMLoss、混合加權損失函數的作用,結果如表3 所示。
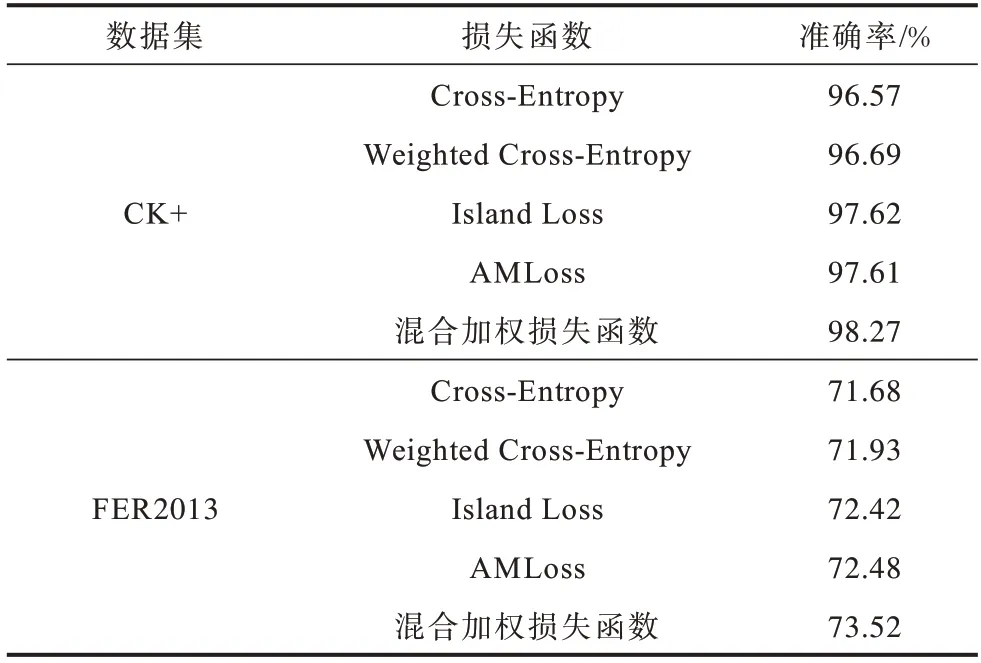
表3 改進損失函數有效性實驗結果Table 3 Experimental results of the effectiveness of the improved loss function
從表3 可以看出:使用加權的交叉熵損失函數(Weighted Cross-Entropy),較Cross-Entropy 有小幅度的性能提升,在CK+中準確率提升了0.12 個百分點,在FER2013 中提升了0.25 個百分點;Island Loss和AMLoss 在CK+、FER2013 中取得了類似的性能;混合加權損失函數作用于網絡時,在CK+中準確率比AMLoss 提升了0.66 個百分點,在FER2013 中準確率較Island Loss 提高了1.1 個百分點。實驗結果表明,本文所提混合加權余弦損失函數在識別準確率上有一定提升。
實驗3本文所提算法與當前較新算法的對比實驗
表4 對比了當前針對CK+和FER2013 且較新的算法識別準確率,最優結果加粗標注。在CK+中,文獻[22]算法利用紋理、幾何特征、語義特征等手工特征與改進后的自動編碼器網絡進行融合,再輸入到Softmax 分類器中進行面部表情識別,達到了較好的性能,但是,相較全程使用CNN 自動提取特征的方式,其算法過程相對繁瑣。本文算法識別準確率在CK+數據集中與文獻[23]算法較為相似,本文算法比該算法高0.09 個百分點,在FER2013 數據集中,本文算法的準確率比該算法高1.41 個百分點,識別準確率提升明顯。
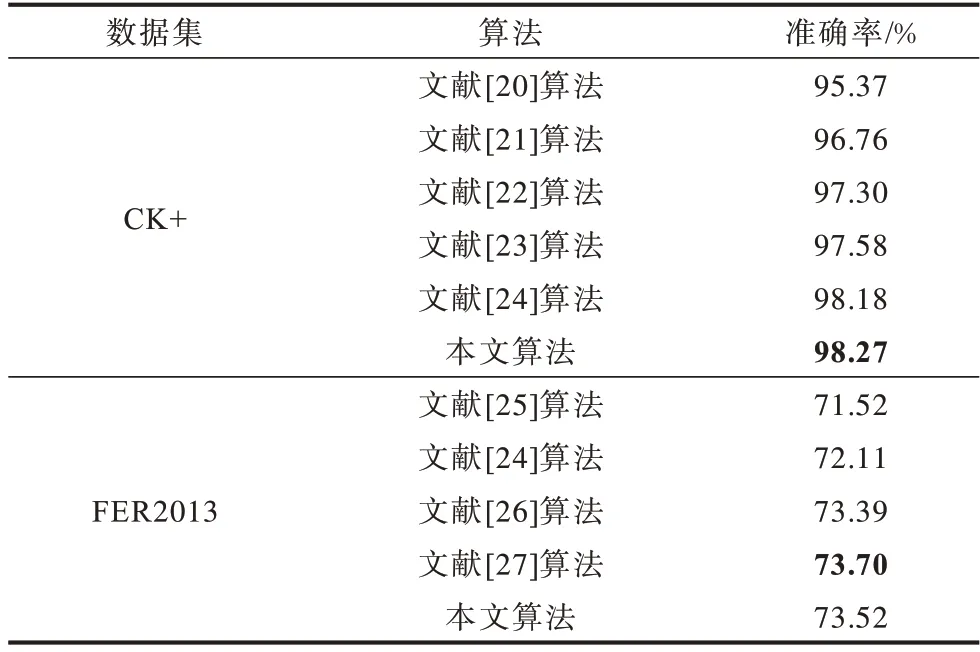
表4 不同算法的對比實驗結果Table 4 Comparative experimental results of different algorithms
圖9(a)、圖9(b)分別為CK+和FER2013 數據集上的混淆矩陣。由圖9 混淆矩陣可見,“高興”“驚訝”這2 個類別識別準確率均較高,這是由于數據集中這2 個類別與其他類別特征差異明顯,經本文損失函數增強分類邊界后,類間距離更加清晰,網絡容易準確識別。圖9(b)比圖9(a)分類模糊數量多,這是由于FER2013數據集中嘈雜樣本較多,且某些類別樣本較為相似,如“悲傷”“中性”“恐懼”之間類間邊界模糊,人類也難以準確區分,導致了分類混淆的現象。
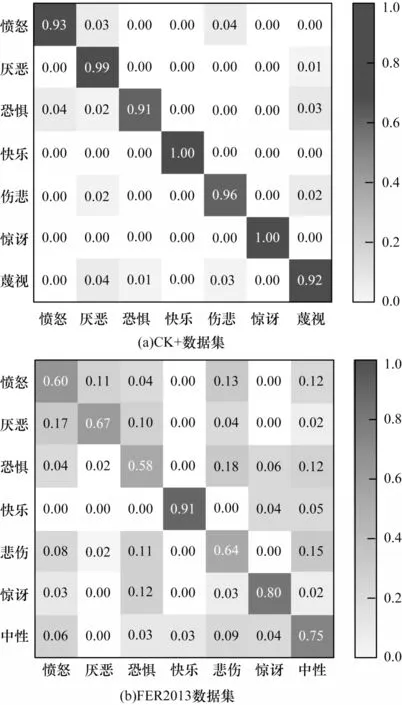
圖9 本文算法的混淆矩陣Fig.9 Confusion matrix of this algorithm
5 結束語
本文針對人臉表情識別任務,提出一種基于詞頻-逆文檔頻率的改進型注意力機制TF-IDF SPA,引導網絡關注表情關鍵區域的重要細節特征。本文使用簡單卷積層堆疊和帶殘差結構的TF-IDF SPA 模塊提取表情特征,能夠達到與諸多復雜模型相同的特征提取效果。在損失函數設計上,針對細粒度分類任務中類間差異小而類內間距大的問題,設計混合加權損失函數,根據數據集的分布調整加權值,從而引導網絡挖掘樣本數量少、識別難度大的訓練樣本特征信息。同時,在保持表情類別之間島嶼型分布的同時使用余弦距離調整類間間隔,增大類間距離。FER2013、CK+數據集上的實驗結果驗證了本文改進注意力機制和改進損失函數的有效性。
目前,網絡特征提取過程還未加入多尺度卷積核以進行不同感受野下的特征提取,且本文還未針對局部遮擋、戴眼鏡、側面人臉等復雜條件進行針對性地研究。下一步將優化注意力機制,在更具挑戰性的真實部署條件下進行算法設計,以實現更好的運行效率和識別效果。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
