基于多層次特征融合的圖像超分辨率重建
2023-01-16 07:36:22李金新黃志勇李文斌周登文
自動化學報 2023年1期
李金新 黃志勇 李文斌 周登文
單圖像超分辨率(Single image super-resolution,SISR)技術旨在將一幅低分辨率(Low-resolution,LR)圖像重建其對應的高分辨率(High-resolution,HR) 圖像.SISR 被廣泛應用于醫學成像[1]、遙感[2]和安防[3]等領域.超分辨率重建是一個病態的逆問題:一個LR 圖像可與多個(High-resolution,HR)圖像對應,恢復細節逼真、豐富的HR 圖像非常困難.超分辨率成像是計算機視覺領域的熱點問題之一,深度學習技術已主導了當前SISR 方法的研究[4-13].
基于深度學習的SISR 方法直接端到端地學習LR 圖像與HR 圖像之間的映射關系.Dong 等[7]第一個提出基于卷積神經網絡[14]的SISR 方法,稱為SRCNN.SRCNN 僅使用了三個卷積層,以端到端的形式直接學習LR和HR 圖像間的非線性映射.Kim 等[15]基于殘差學習[16],提出網絡更深的SISR方法(Very deep convolutional networks for superresolution,VDSR),改進了性能.為了能夠增加網絡深度,又限制網絡參數的增加,Kim 等[8]采用共享參數的遞歸結構,提出了Deeply-recursive convolu-tional Network (DRCN)方法.Tai 等[9]提出的Deep recursive residual network (DRRN),同時利用了局部殘差結構、全局殘差結構和遞歸結構.殘差單元之間參數共享,改進了VDSR和DRCN的性能.Li 等[17]提出的Super-resolution feedback network (SRFBN-S)方法,使用循環神經網絡結構,共享隱藏層參數,降低參數量的同時提升了重建圖像質量.Hui 等[18]提出Information multi-distillation network (IMDN)方法,在殘差塊內逐步提取特征信息,利用通道注意力機制進行特征選擇,進一步提高了重建圖像質量.Ahn 等[10]提出了基于級聯殘差網絡的SISR 方法(Cascading residual network,CARN),結合級聯結構與殘差學習,取得了更好的參數量和性能之間的平衡.Zhu 等[19]提出Compact back-projection network (CBPN)方法,通過級聯上/下采樣層,在LR和HR 空間中提取特征信息,增強了重建能力.Li 等[11]提出的Multiscale residual network (MSRN)方法,殘差塊內運用不同感受野的卷積層,提取不同尺度的特征信息,進一步改進了性能.Lai 等[20]提出了拉普拉斯金字塔網絡結構的SISR 方法(Laplacian pyramid super-resolution network,LapSRN),逐步上采樣與預測殘差,可同時完成多個尺寸的HR圖像重建.
以上方法使用了輕量級網絡,但網絡深度和參數量是影響SISR 性能的重要因素[12].Lim 等[12]提出了一個重量級的Enhanced deep super-resolution network (EDSR)方法,去除了規范化層,疊加殘差塊,超過65 個卷積層,獲得了2017 年超分辨率比賽冠軍[21].Zhang 等[13]提出的Residual dense network (RDN)方法,結合殘差結構和稠密結構,并充分利用LR 圖像的層次特征信息,能夠恢復出高質量的HR 圖像.Liu 等[22]提出Residual feature aggregation net work (RFANet)方法,在殘差塊中使用感受野更大,參數量更小的空間注意力模塊,篩選特征信息,并將每個殘差塊的殘差支路提取的特征進行融合,提高了圖像重建質量.EDSR、RDN和RFANet 等方法是當前有代表性的重量級網絡SISR 方法,性能好,參數量也都較大(分別為43 MB、22 MB和11 MB).
在資源受限的情況下,重量級SISR 模型難以滿足應用需求,本文考慮輕量級SISR 模型,提供潛在的解決方法.
本文提出一個新的、輕量級多層次特征融合網絡的SISR 方法(Multi-hierarchical features fusion network,MHFN).當放大因子為4 倍時,MHFN 參數量僅為1.47 MB,是當前尖端方法EDSR 的1/29,RDN 的1/14,RFANet 的1/7.對比同類輕量級SISR 模型,本文的MHFN 方法,在性能和模型規模上取得了更好的平衡.以最有代表性的MSRN 方法為例,本文的MHFN 參數減少了3/4,在測試集上2 倍、3 倍和4 倍放大,客觀性能相當,而8 倍放大,一致優于MSRN 方法.對于4 倍和8倍放大,主觀性能也一致優于MSRN 方法.實驗結果表明,MHFN 方法重建條紋的能力顯著優于其他輕量級方法,對于8 倍大尺度放大因子,重建圖像結果優勢更明顯.本文貢獻包括:1)提出了一種對稱結構的雙層嵌套殘差塊(Dual residual block,DRB).殘差塊內先兩次擴張,然后兩次壓縮特征通道,并使用兩層殘差連接以有效地提取特征信息;2)提出了一種自相關權重單元(Autocorrelation weight unit,ACW).ACW 可根據特征信息計算權值,自適應地加權不同的特征通道,以有效地傳遞特征信息;3)設計了一種淺層特征映射單元(Shallow feature mapping unit,SFMU).SFMU 通過每條支路上的不同感受野的卷積層,提取不同層次的淺層特征信息;4)設計了一種多路重建單元(Multipath reconstruction unit,MPRU).MPRU 可獲取多條支路的特征信息,以充分地利用不同層次的特征信息重建圖像不同方面.
1 本文方法
目前,大多數SISR 模型利用殘差結構[12,23].殘差塊結構一般是卷積層–激活層–卷積層(Conv-ReLU-Conv)1該結構是將特征信息 x 經過卷積處理再激活操作,隨后再次卷積處理得到 ,結構最終輸出為 x + ..這類模型的一個問題是:模型性能嚴重依賴于網絡規模(可訓練的網絡層數和通道數),如何減小網絡規模,又提高或不降低模型性能,是極具挑戰性的問題.本文設計了輕量級的多層次特征融合網絡,特征通道先擴張后壓縮的雙層嵌套殘差塊,可以顯著降低參數量,自相關權重單元自適應融合特征信息,也改進了特征利用效果.本文的MHFN 網絡結構如圖1(a)所示,主要包含淺層特征提取單元(Shallow feature extraction unit,SFEU)、淺層特征映射單元(Shallow feature mapping unit,SFMU)、深層特征映射單元(Deep feature mapping unit,DFMU)和多路重建單元(Multi-path reconstruction unit,MPRU)四個部分.

圖1 本文多層次特征融合網絡結構與殘差組結構((a) 多層次特征融合網絡結構圖;(b) 殘差組結構圖)Fig.1 Our multi-hierarchical feature fusion network structure and the residual group structure ((a) The architecture of multi hierarchical feature fusion network;(b) The structure of residual group)
令ILR與ISR為輸入與輸出圖像.淺層特征提取單元(SFEU)僅包含一個3×3 卷積層,實現淺層特征信息提取和特征維度轉換的功能:

式中,HSF EU是淺層特征提取單元,將輸入圖像ILR生成符合淺層/深層特征映射單元維度要求的淺層特征信息F0. 淺層特征映射單元(SFEU)從F0中進一步提取淺層特征信息,并將淺層特征信息傳遞到多路重建單元(MPRU):


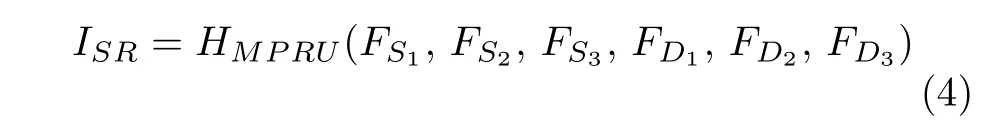
式中,HMP RU是多路重建單元,利用所有特征信息重建圖像,生成最終結果ISR.
1.1 淺層特征映射單元(SFMU)
當前SISR 模型通常使用1 或2 個卷積層提取淺層特征,本文的SFMU 使用了不同感受野的卷積核,分層次提取淺層特征信息,實現多尺度、多層次淺層特征信息的獲取.豐富的淺層特征信息,可以幫助重建單元重建更高質量的SR 圖像.
SFMU 首先通過1×1 卷積層對輸入信息進行維度轉換,以降低后續操作的參數量.然后,使用三種不同感受野的卷積層,實現多尺度淺層特征信息提取.將三個卷積層分為三條支路,逐步加權疊加淺層特征信息.實現多尺度、多層次淺層特征信息的提取.

1.2 深層特征映射單元(DFMU)
為了獲取深層次特征信息,本文設計了DFMU,如圖1(a)所示.DFMU 包含3 個殘差組(Residual group,RG),每個RG 又包含多個DRB.簡單地堆疊殘差塊,不利于特征信息的傳遞.本文在每個RG中添加局部跳躍連接,促進特征信息的有效傳遞.并且通過RG 獲取深層次特征信息:

1.2.1 雙層嵌套殘差塊(DRB)
在SISR 模型中,常用的殘差結構如圖2(a)所示,每個卷積層具有相同的通道數目.這個結構的一個主要問題是:增加特征通道數目,會導致參數量快速增加.本文提出了如圖2(b)所示的DRB,由內單元(Inner unit,IU)和外單元(External unit,EU)嵌套組成,并且使用先擴張后壓縮的策略[24].該策略可以降低通道數目,進而減少參數量.EU第1 個卷積層提取特征信息同時,擴張特征通道,以獲取更豐富的圖像特征信息.第2 個卷積層壓縮特征通道,篩選特征信息,促使有效特征信息傳遞.本文在EU 內部增加了包含2 個1×1 卷積的IU,增加通道數目,不會造成參數量的急劇增加.

圖2 不同的殘差塊結構圖Fig.2 The structure of different residual block


IU 采用了Conv-ReLU-Conv 結構,并加入跳躍連接.

1.2.2 自相關權重單元(ACW)
基于深度殘差結構的SISR 模型,仍然存在梯度消失或爆炸問題,為了穩定訓練,通常引入一個殘差尺度參數[25].這個超參數通常經驗設置,難以優化.本文的ACW 可學習最優的殘差尺度參數.
如圖3 所示.ACW 由全局平均池化層和Sigmoid 激活函數兩部分組成,沒有附加的參數.全局平均池化層將所有輸入特征信息編碼為初始化權重,隨后利用Sigmoid 激活函數將其調整至[0,1].由于特征信息之間存在差異,生成不同的權重,增強了對重建圖像有效的特征信息.

圖3 自相關權重單元結構圖Fig.3 The structure of autocorrelation weight unit
令X=[x1,x2,···,xC] 為輸入特征信息,尺寸為H×W×C.初始化權值Z=[z1,z2,···,zC] 是通過全局平均池化層HGAP對輸入特征信息X進行計算得出.第c個輸入特征信息的初始權值為:

使用Sigmoid 激活函數f(·) 調整初始化權值Z,生成最終的權重參數W:

對輸入特征信息進行加權處理:

1.3 多路重建單元(MPRU)
當前的SISR 模型網絡末端,大多采用轉置卷積或亞像素的卷積進行上采樣.與轉置卷積相比,亞像素的卷積重建的圖像質量更好[26],但需要配合使用多個3×3 卷積層[11-13],放大因子增加,參數量會顯著增加.為了在不降低圖像重建質量的同時減少參數量,設計了MPRU.見圖1(a),MPRU 有三條重建支路,每條重建支路由1 個1×1 卷積層與1個亞像素卷積層組成.每條支路重建結果與HR 圖像尺寸相同,最終的SR 圖像是三條支路重建結果的和.MPRU 使用1×1 卷積層,可極大地減少參數,放大因子增加,也不會顯著提高參數量.同時,MPRU 獲取各支路的特征信息,也可以改進重建效果.
下面將計算MPRU 參數量并與EDSR2https://github.com/thstkdgus35/EDSR-PyTorch方法的重建單元參數量作對比分析.假設兩者用于重建的特征信息通道均為C,圖像放大因子為S,重建后圖像為3 通道.經1×1 卷積層處理后的特征信息通道數目為S×S×3.亞像素卷積層沒有參數量,不參與計算.MPRU 的重建支路參數為3×((1×1×C+1)×S×S×3).
EDSR 重建單元在放大因子S=[2,3] 時,包含2 個 3×3 卷積層和1 個亞像素卷積層.第1 個卷積層將輸入的特征信息通道由C擴張至S×S×C,再經過亞像素卷積層將特征信息高度與寬度擴張為原來的S倍,通道壓縮為C,再經過另一個卷積層將通道壓縮至3,生成最終結果.參數量為((3×3×C+1)×S×S×C+(3×3×C+1)×3).在放大因子S=4 時包含3 個卷積層和2 個亞像素卷積層.同理于上述過程,先將圖像放大2 倍,再放大2 倍.其參數量為(2×((3×3×C+1)×2×2×C)+(3×3×C+1)×3).
當S=[2,3] 時,MPRU 參數量與EDSR重建單元參數量之比為:

當S=4 時,MPRU 參數量與EDSR 重建單元參數量之比為:

在本文模型中,重建的特征信息通道為48,即C=48. 由式(15)和式(16)可知,放大因子S=2,3 時,EDSR 重建單元參數量是MPRU 參數量的47 倍,而S=4 時,EDSR 重建單元參數量是MPRU 參數量的23 倍.

2 實驗細節
2.1 實驗設置
本文使用DIV2K[21]數據集中第1~800 個圖像作為訓練數據集,并對訓練集進行 9 0°旋轉和隨機的水平翻轉,進行數據增強.訓練中每個批次處理16 個尺寸為48×48 像素的圖像塊,使用β1=0.9,β2=0.999,?=10-8的ADAM 優化器[27].本文在訓練模型中使用權值歸一化處理[28],初始學習率設置為 1 0-3,共訓練1 000 個迭代周期,并且每200 個迭代周期學習率衰減為原先的一半.使用L1損失函數.為了驗證本文方法性能,使用Set5[29]標準測試數據集以及DIV2K 數據集中第801~810張高質量圖像(標記為DIV2K-10)進行對比實驗,Set14[30]、B100[31]、Urban100[32]和Manga109[33]共4個標準測試數據集進行測試,并使用平均峰值信噪比(Peak signal-to-noise ratio,PSNR)[34]與結構相似性(Structural similarity index,SSIM)[34]指標評價實驗結果.模型使用PyTorch 實現,并在NVIDIA GeForce RTX 2080Ti GPU 上訓練.
2.2 實驗分析
2.2.1 殘差組實驗分析
本文提出模型包含3 個殘差組,并且每組內包含相同數目的雙層嵌套殘差塊.為了驗證殘差組內不同數目的雙層嵌套殘差塊對模型的影響,本文在Set5 標準測試數據集以及DIV2K-10 數據集上進行4 倍超分辨率實驗,對組內數目分別為5、6、7 的殘差組作對比實驗.如表1 所示,組內數目為6 時性能最佳.對比組內數目為5 時,雖然參數量提高0.24 MB,但是PSNR 指標分別在Set5 與DIV-2K-10 數據集上提高0.03 dB和0.04 dB,而當組內數目為7 時,PSNR 指標提升不明顯,參數量卻提高0.24 MB.本文模型殘差塊個數為6,是一個合理的選擇.

表1 Set5和DIV2K-10 數據集上,放大4 倍,運行200 個迭代周期,殘差組中不同雙層嵌套殘差塊數模型的平均PSNR 及參數量Table 1 Average PSNRs and number of parameter with different numbers of DRBs in the residual group with a factor of × 4 on Set5 and DIV2K-10 datasets under 200 epochs
2.2.2 SFMU 單元實驗分析
為了驗證淺層特征映射單元不同支路上卷積核大小,以及未使用淺層特征映射單元等情形對模型的影響,本文在Set5 標準測試數據集與DIV2K-10 數據集上,進行4 倍超分辨率對比實驗.如表2所示,未使用淺層特征映射單元導致模型無法使用淺層特征信息,致使重建效果較差.而當每條支路使用相同大小的卷積核,且卷積核大小不斷增加時,重建效果提升,然而參數量也隨之增加.當支路卷積核均為1 時,PSNR 指標低于未使用淺層特征映射單元的模型,這是由于提取的特征信息較少,存在冗余信息,導致效果較差.本文發現當三條支路卷積核分別設置1、3、5 時效果最佳.這是由于每一條支路可以提取不同層次的淺層特征信息,可以有效地與深層層次特征信息進行組合使用.因而本文使用支路卷積核大小分別為1、3、5 的淺層特征映射單元.

表2 Set5 與DIV2K-10 數據集上,放大4 倍,運行200 迭代周期,淺層特征映射單元支路不同卷積核設置的平均PSNRTable 2 Average PSNRs of the models with different convolutional kernel settings for SFMU branches for× 4 on Set5 and DIV2K-10 datasets under 200 epochs
2.2.3 DRB 對比實驗分析
相比于流行的殘差塊結構,如圖2(a)所示,本文的DRB 在性能和參數量上均有優勢.本文在Set5 與DIV2K-10 數據集上進行4 倍超分辨率對比實驗.本文構建了兩個測試模型,分別稱為模型I和模型II.模型I 是EDSR 架構,但是,卷積層輸入輸出通道數從256 縮減為64,殘差塊數從32 縮減為18.模型II 是把模型I 中殘差塊替換為DRB.在DRB 擴張階段,EU 輸入輸出特征通道數分別設置為32 與64,IU 輸入輸出特征通道數分別設置為64 與128;在壓縮階段,EU 輸入輸出特征通道數分別設置為64 與32,IU 輸入輸出特征通道數分別設置為128 與64.模型I和模型II 中其他參數都是相同的:殘差尺度參數為0.1,運行200 個迭代周期.結果如表3 所示,在Set5 與DIV2K-10 數據集上,模型II 的PSNR 分別高于模型I0.01 dB和0.05 dB,而本文的DRB 比ERSR 殘差塊的參數量少20.3 KB.

表3 Set5 與DIV2K-10 數據集上,放大4 倍,運行200 個迭代周期,不同模型的平均PSNRTable 3 Average PSNRs of different models for × 4 super-resolution on Set5 and DIV2K-10 datasets under 200 epochs
2.2.4 ACW 對比實驗分析
為了驗證ACW 的有效性,考慮第2.2.3 節中模型I 包含和不包含ACW 兩種情形,結果如表4所示.使用ACW 后,Set5 與DIV2K-10數據集上PSNR 分別提高0.02 dB和0.03 dB.實驗結果表明,ACW 自動學習最優的殘差尺度參數是有效的.

表4 Set5和DIV2K-10 數據集上,放大4 倍,運行200 個迭代周期,包含/不包含ACW 模型的平均PSNRTable 4 Average PSNRs of the models with/without the ACW for × 4 super-resolution on the Set5 and DIV2K-10 datasets under 200 epochs
2.2.5 MPRU 對比實驗分析
為了驗證本文的MPRU 重建性能,本文把第2.2.3 節模型I 中的EDSR 重建單元替換為MPRU后,與模型I 進行比較,兩個模型的結果分別對應于表5 中EDSR 重建單元和MPRU.MPRU參數量僅為9.36 KB,大約只有EDSR 重建單元參數量的1/32 (297.16 KB).在Set5 與DIV2K-10 數據集上,本文MPRU 使PSNR 分別提高了0.02 dB和0.05 dB.

表5 Set5和DIV2K-10 數據集上,放大4 倍,運行200 個迭代周期,不同重建單元模型的平均PSNRTable 5 Average PSNRs of the models with different reconstruction modules for × 4 super-resolution on Set5 and DIV2K-10 datasets under 200 epochs
2.3 模型分析
本文提出的模型在Set14、B100、Urban100和Manga109 標準測試集驗證2 倍、3 倍、4 倍和8 倍超分辨率性能.并與輕量級的SRCNN[7]、FSRCNN[35]、VDSR[15]、DRCN[8]、DRRN[9]、LapSRN[20]、CARN[10]、SRFBN-S[17]、IMDN[18]、CBPN[19]、MSRN[11]、MemNet[36]和SRMDNF[37]進行性能對比.
1)客觀指標如表6 所示,最好的結果與次好結果分別以粗體和下劃線形式標出.在Set14 數據集上,放大因子為2 倍時,本文的MHFN 模型比CARN模型PSNR 高出0.27 dB,在其他放大因子的情況下類似,并且MHFN 模型參數量比CARN 更少(大約減少了120 KB).在所有測試數據集上,放大因子為4 倍時,MHFN 模型比CBPN 模型和IMDN 模型PSNR 平均高出0.06 dB 與0.16 dB.雖然在部分數據集上,MSRN 性能略好,但本文的MHFN綜合性能更好,MSRN 的4 倍模型參數量是本文MHFN 的4 倍.
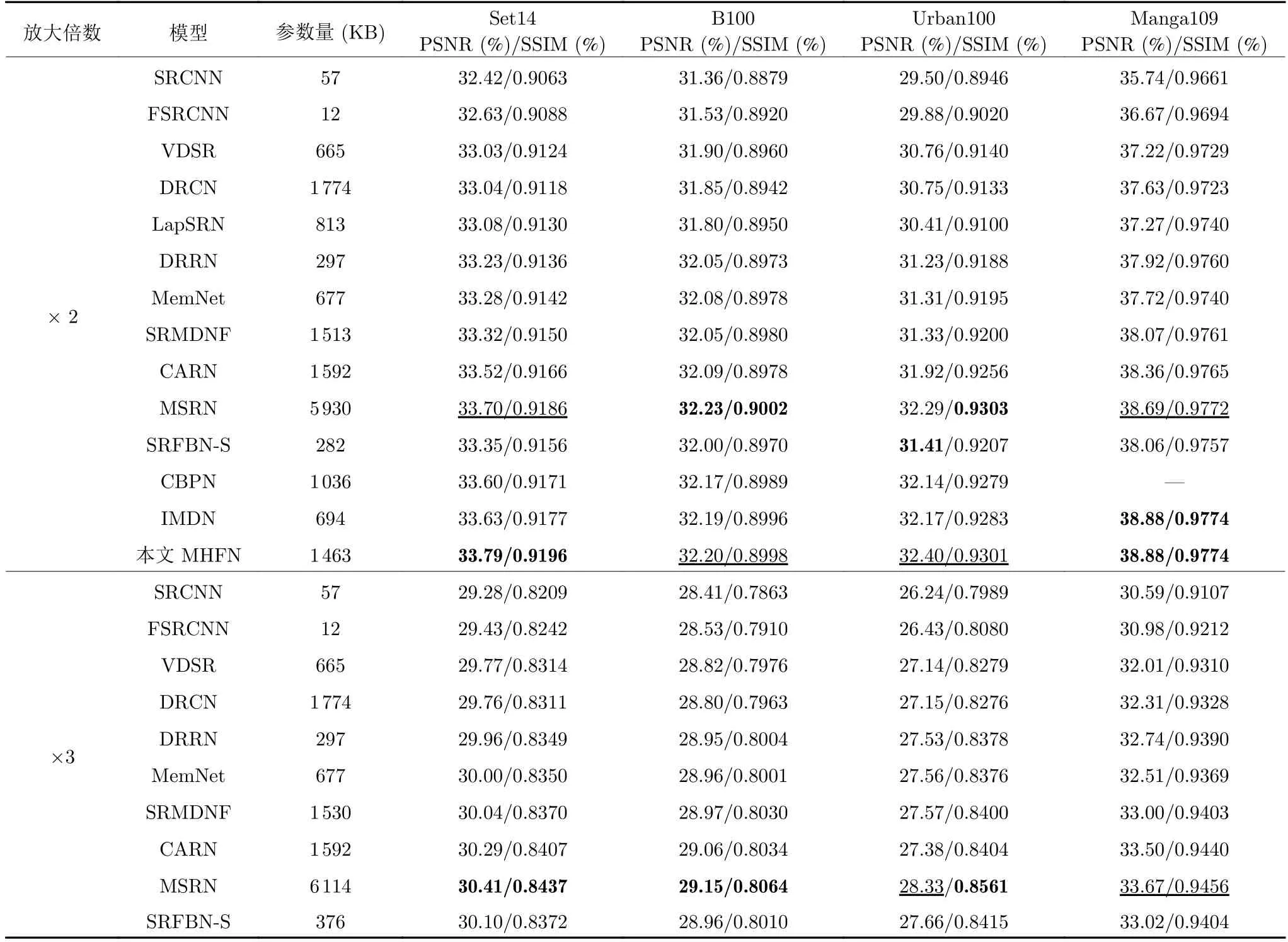
表6 各個SISR 方法的平均PSNR和SSIMTable 6 The average PSNRs/SSIMs of different SISR methods

表6 各個SISR 方法的平均PSNR和SSIM (續表)Table 6 The average PSNRs/SSIMs of different SISR methods (continued table)
2)主觀視覺如圖4 所示,本文對比Urban100標準測試數據集中img012、img024 與img046 圖像以及Manga109 標準測試數據集中的Highschool-Kimengumi_vol20 (HK_vol20)圖像.在圖像img-012 中,IMDN 與MSRN 重建結果與原圖像條紋方向相反,本文的模型正確重建了條紋的方向,可能是淺層特征提取單元獲取了更豐富的淺層特征信息,幫助重建單元重建出更精確的結果.在img046圖像中,Bicubic 插值、SRCNN 模型和VDSR 模型重建圖像非常模糊,LapSRN 模型、CARN 模型、SRFBN-S 模型、IMDN 模型與MSRN 模型重建結果嚴重失真,本文結果顯著更好.類似地,在img-024 圖像中,本文模型與其他方法均存在恢復的條紋數目與原圖像不一致的問題.其他方法均嚴重模糊和失真,本文的重建結果也顯著更好.在HK_-vol20 圖像中,其他方法眼睛部位重建模糊和走樣,本文重建結果顯著優于其他方法,是清晰可視的.

圖4 標準測試集放大4 倍視覺效果比較Fig.4 Visual qualitative comparison of × 4 super-resolution on the standard test datasets
如圖5 所示,當放大因子為8 倍時,本文的模型重建效果顯著優于其他模型.在img092 圖像中,LapSRN 模型與MSRN 模型重建圖像條紋方向與原圖像相反,本文的重建結果很接近于原圖像.在ppt3 圖像中,本文重建結果比其他模型顯著更清晰.對于規則形狀和結構的重建,本文模型性能提升顯著.如何進一步提高不規則形狀和結構的重建質量,是本文未來的研究工作.

圖5 標準測試集下放大8 倍視覺效果比較Fig.5 Visual qualitative comparison of × 8 superresolution on the standard test datasets
3 結束語
本文提出一種輕量級的多層次特征融合網絡(MHFN),用于重建高質量的超分辨圖像.本文設計了雙層嵌套殘差塊(DRB)用于提取圖像特征信息,其特征通道數目先擴張后壓縮,并且使用不同感受野的卷積層,降低參數量.為了使雙層嵌套殘差塊有效傳遞特征信息,本文設計了自相關權重單元(ACW),通過計算特征信息生成權重信息,再利用權重信息對特征信息進行加權處理,保證高權重的特征信息被有效傳遞.本文將雙層嵌套殘差塊組成殘差組,用于提取深層的層次特征信息,并構建淺層特征映射單元(SFMU)提取多尺度、多層次的淺層特征信息.多路重建單元(MPRU)將深層的層次特征信息與淺層特征信息融合重建為高質量超分辨率圖像.實驗結果表明,上述模塊設計有助于重建高質量圖像,并且本文的模型可以有效增強圖像條紋,重建高質量超分辨圖像.與其他輕量級模型相比,本文模型在性能與模型規模方面上獲得了更好的平衡.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
