基于深度學(xué)習(xí)的機器閱讀理解研究綜述
2023-01-14 14:48:24杜永萍趙以梁閻婧雅郭文陽
智能系統(tǒng)學(xué)報 2022年6期
杜永萍,趙以梁,閻婧雅,郭文陽
(北京工業(yè)大學(xué) 信息學(xué)部,北京 100124)
認知智能是人工智能發(fā)展的最高階段,其目標是讓機器掌握人類的語言和知識體系,并真正理解其內(nèi)在邏輯,這意味著機器開始具備分析和思考的能力。自然語言是認知科學(xué)的一項重要研究內(nèi)容,用自然語言與計算機進行通信,意味著要使計算機能夠理解自然語言文本的意義,以自然語言理解為核心技術(shù)的自動問答、人機對話、聊天機器人已經(jīng)成為產(chǎn)業(yè)界和學(xué)術(shù)界的關(guān)注熱點。
自動問答是語言理解的重要應(yīng)用領(lǐng)域,特別是機器閱讀理解,賦予了計算機從文本數(shù)據(jù)中獲取知識和回答問題的能力,它是人工智能中一項挑戰(zhàn)性的任務(wù),需要深度理解自然語言并具備一定推理能力。
近年來,機器閱讀理解領(lǐng)域的研究進入快速發(fā)展時期,一方面得益于大規(guī)模高質(zhì)量數(shù)據(jù)集的發(fā)布:包括Facebook Children’s Books Test[1]、SQuAD[2]以及TriviaQA[3]等高質(zhì)量數(shù)據(jù)集;另一方面,基于深度學(xué)習(xí)技術(shù)的模型在獲取上下文交互信息方面明顯優(yōu)于傳統(tǒng)模型,例如基于雙向注意力機制的BiDAF 模型[4]、Transformer[5]和基于注意力機制的循環(huán)神經(jīng)網(wǎng)絡(luò)R-Net[6]。中文問答任務(wù)上,基于注意力機制的模型如N-Reader[7]在中文數(shù)據(jù)集DuReader[8]上取得了較好的成績。
近期,預(yù)訓(xùn)練模型[9-10]與知識推理技術(shù)[11-12]在復(fù)雜問答任務(wù)上取得了優(yōu)異的表現(xiàn),特別在多跳問答任務(wù)中,問題的答案需要從多個篇章中獲取,模型需要通過推理才能得出答案,圖神經(jīng)網(wǎng)絡(luò)在該類任務(wù)上具有較好的適用性,Ding 等[11]使用認知圖譜與圖神經(jīng)網(wǎng)絡(luò)解決復(fù)雜數(shù)據(jù)集的推理任務(wù)并取得當(dāng)時SOTA 的結(jié)果。
1 機器閱讀理解任務(wù)
機器閱讀理解任務(wù),從輸入信息的角度,可分為兩種類型:基于多模態(tài)的閱讀理解任務(wù)和基于文本的閱讀理解任務(wù)。
基于多模態(tài)的閱讀理解任務(wù)是指使機器能夠?qū)ξ谋尽D片以及視頻等多種來源的信息進行學(xué)習(xí),該研究任務(wù)更貼近于人類對信息獲取的綜合感知的學(xué)習(xí)方式,它是新興的具有挑戰(zhàn)性的研究方向。目前已有一些基于多模態(tài)的閱讀理解任務(wù)的評測任務(wù)和數(shù)據(jù)集,如RecipeQA[13]和TQA[14]等。
本文主要針對基于文本的閱讀理解任務(wù)進行分析,主要分為四類:完形填空式任務(wù)、選擇式任務(wù)、片段抽取式任務(wù)和自由作答式任務(wù)。
1)完形填空式任務(wù):對于給定的篇章P,從P中刪去詞語A。任務(wù)要求機器學(xué)習(xí)到函數(shù)F,從Q=P-{A} 中對P中缺少的詞語或?qū)嶓w進行補全,即A=F(Q)=F(P-{A})。
完形填空式任務(wù)的難點在于,機器需要從不完整的文本中學(xué)習(xí)上下文語義關(guān)系,并且不僅需要對篇章所表達的內(nèi)容進行理解,還需要把握篇章的語言表達、詞語運用的習(xí)慣,從而正確地對被刪去的內(nèi)容進行預(yù)測。該任務(wù)代表性數(shù)據(jù)集有CNN/DailyMail[15]、Facebook Children’sBooks Test[1]等。
2)選擇式任務(wù):對于給定的篇章P和問題Q,以及問題Q的候選答案集合A={A1,A2,···,An},要求機器學(xué)習(xí)到函數(shù)F,根據(jù)P、Q、A從A中選擇對Q回答正確的一項,即Ai=F(P,Q,A)。
選擇式任務(wù)的特點在于要求數(shù)據(jù)集提供問題的候選答案集合。機器在完成選擇式任務(wù)時,需要對篇章、問題、候選答案之間的語義關(guān)系進行理解和分析,給出正確的判斷。該任務(wù)的代表性數(shù)據(jù)集有WikiHop[16]、CommonsenseQA[17]等。
3)片段抽取式任務(wù):對于給定的篇章P={w1,w2,···,wn}和 問題Q,機器學(xué)習(xí)到函數(shù)F,根據(jù)對P和Q的理解,從P中選取連續(xù)片段A作為Q的答案,即A=F(P,Q),A={wi,wi+1,···,wj},A∈P。
片段抽取式任務(wù)的特點在于問題的答案可以在篇章中找到,且答案可以是詞語、實體或句子等形式。構(gòu)建數(shù)據(jù)集時對問題的選取有一定要求,該任務(wù)的代表性數(shù)據(jù)集有SQuAD[2]、NewsQA[18]等。
4)自由作答式任務(wù):對于給定的篇章P和問題Q,機器學(xué)習(xí)到函數(shù)F,根據(jù)對P和Q的理解得出答案A,且A不一定在P中出現(xiàn),可以為任意形式,即A=F(P,Q)。
自由作答式任務(wù)在答案的選取上最為靈活,答案的形式也無限制,且答案范圍不局限于給定篇章。這類任務(wù)往往要求機器具有一定的分析、推理能力。該任務(wù)的代表性數(shù)據(jù)集有DuReader[8]、DROP[19]等。
2 機器閱讀理解技術(shù)
2.1 基于端到端神經(jīng)網(wǎng)絡(luò)的機器閱讀理解技術(shù)
傳統(tǒng)的機器閱讀理解方法通常是基于規(guī)則或者統(tǒng)計學(xué)規(guī)律,但隨著該任務(wù)數(shù)據(jù)集的規(guī)模和質(zhì)量的提升,深度學(xué)習(xí)方法表現(xiàn)出了良好的性能。如今機器閱讀理解模型的構(gòu)建大多采用雙向循環(huán)神經(jīng)網(wǎng)絡(luò)對問題和篇章進行編碼,并在問題-篇章交互層中使用注意力機制。
機器閱讀理解模型的輸入通常為問題和篇章,最終的輸出是問題的答案。常見的基于深度學(xué)習(xí)的機器閱讀理解模型主要包括4 個層次:詞嵌入層、編碼層、問題-篇章交互層以及答案預(yù)測層,如圖1 所示。

圖1 基于深度學(xué)習(xí)方法的機器閱讀理解通用模型結(jié)構(gòu)Fig.1 Generic architecture of machine reading comprehension model based on deep learning
1)詞嵌入層:問題和篇章輸入模型后,將輸入的自然語言文字轉(zhuǎn)換為定長向量。可以通過獨熱編碼、分布式詞向量表示等多種方式分別得到問題和篇章的嵌入表示。采用大規(guī)模語料庫預(yù)訓(xùn)練得到的詞表示會包含豐富的上下文信息。例如QANet[20]中使用預(yù)訓(xùn)練詞表GloVe[21]作為詞的初始化表示,為后續(xù)模型正確預(yù)測答案提供支撐。
2)編碼層:詞嵌入層的輸出作為編碼層的輸入,分別對問題和篇章進行建模。一些典型的深度神經(jīng)網(wǎng)絡(luò),例如循環(huán)神經(jīng)網(wǎng)絡(luò),具有能夠處理時間序列預(yù)測問題的特性,它通常被應(yīng)用在編碼層來挖掘問題和篇章的上下文信息。R-Net[6]采用多層的雙向循環(huán)神經(jīng)網(wǎng)絡(luò)構(gòu)建模型,并利用自注意力機制進一步捕獲更加豐富的上下文信息。循環(huán)神經(jīng)網(wǎng)絡(luò)的優(yōu)點是隱藏層的神經(jīng)元之間可以進行交互,使得信息具有傳遞性。Attentive Reader[15]中的編碼層部分由雙向循環(huán)神經(jīng)網(wǎng)絡(luò)正向和反向的輸出拼接得到篇章中第t個位置詞的表示,并計算該位置詞的權(quán)重。
3)問題-篇章交互層:問題和篇章之間的關(guān)聯(lián)對答案的預(yù)測有著重要的作用。注意力機制被廣泛應(yīng)用于問題-篇章交互層中,包括單向注意力機制、雙向注意力機制以及自注意力機制,用于增強與問題相關(guān)的篇章部分的表示。如圖2 所示,將問題Q={x1,x2,x3,x4,x5} 融入到篇章C中,若要得到C中的詞y的表示,首先計算Q中每個詞的權(quán)重w1,w2,w3,w4,w5=softmax(QT,y),由y與Q中每個詞點乘并使用行向 softmax進行歸一化得到;然后對Q中每個詞進行加權(quán)求和得到融入問題信息的詞y的表示,即=w1x1+w2x2+w3x3+w4x4+w5x5。以此類推,計算得到篇章C中每個詞的新的表示,記作A(Q,C)。
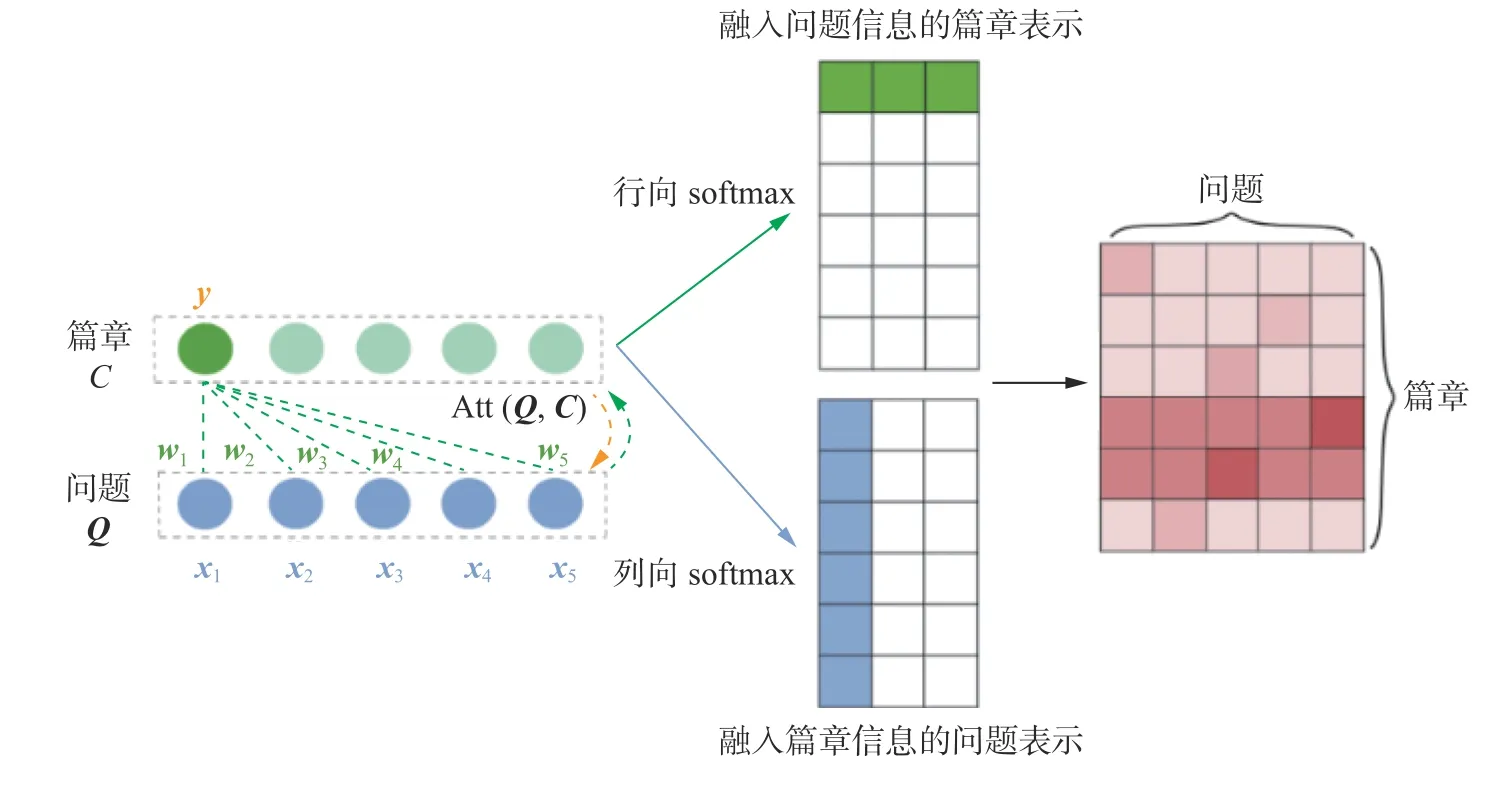
圖2 注意力機制的原理示意Fig.2 Structure of attention mechanism
BiDAF[4]提出的雙向注意力機制不僅計算融入問題信息的篇章表示,也計算了融入篇章信息的問題表示,從而進一步提高了模型對問題和篇章的理解能力。注意力機制相比于循環(huán)神經(jīng)網(wǎng)絡(luò),其復(fù)雜度更小,參數(shù)量也更少,解決了循環(huán)神經(jīng)網(wǎng)絡(luò)不能并行計算和短期記憶的問題。自注意力機制在機器閱讀理解任務(wù)中常被用來關(guān)注篇章自身的內(nèi)容,即 Att(C,C),目的是計算篇章中各個詞的相似度,以學(xué)習(xí)到篇章自身詞與詞之間的關(guān)系,R-Net[6]、T-Reader[22]、HQACL[23]模型均采用自注意力機制提高了模型對篇章的理解能力。
4)答案預(yù)測層:答案預(yù)測層用于輸出問題的答案。機器閱讀理解的任務(wù)類型不同,答案形式也不同。完形填空式任務(wù)的輸出是篇章中的一個單詞或?qū)嶓w;選擇式任務(wù)的輸出是從候選答案中選出正確答案;片段抽取式任務(wù)需要從篇章中抽取連續(xù)子序列作為輸出;對于自由作答式的任務(wù),文本生成技術(shù)通常被用于該層來生成問題的答案。
2.2 基于預(yù)訓(xùn)練語言模型的機器閱讀理解技術(shù)
預(yù)訓(xùn)練模型已經(jīng)在自然語言處理的多項下游任務(wù)中取得了優(yōu)秀的性能,包括OpenAI GPT[24]、BERT[9]、XLNet[10]等,可以有效獲取句法和語義信息,并進行文本表示。預(yù)訓(xùn)練方法通常用于機器閱讀理解任務(wù)的詞嵌入層,將自然語言文本編碼成固定長度的向量。詞的表示方法中,獨熱編碼無法體現(xiàn)詞與詞之間的關(guān)系;分布式詞向量表示方法雖然可以在低維空間中編碼并通過距離度量詞與詞之間的相關(guān)性,但并沒有包含上下文信息,為了解決這個問題,基于預(yù)訓(xùn)練的詞表示方法被提出并應(yīng)用。
Transformer[5]是第一個完全基于注意力機制的序列生成模型,BERT[9]提出利用雙向Transformer 預(yù)訓(xùn)練得到上下文級別的詞表示。XLNet[10]以自回歸語言模型為基礎(chǔ)融合自編碼語言模型的優(yōu)點,克服了自回歸語言模型無法對雙向上下文信息進行建模的缺點。XLNet[10]引入雙流自注意力機制以解決目標位置信息融入的問題,同時使得模型能夠處理更長的輸出長度。但是,常規(guī)的預(yù)訓(xùn)練方法無法對文本中的實體及關(guān)系建模,ERICA[25]框架被提出用于解決該問題,實現(xiàn)深度理解,它可以提升典型的預(yù)訓(xùn)練模型BERT[9]與RoBERTa[26]在多個自然語言理解任務(wù)上的性能,包括機器閱讀理解。
此外,在面向中文的預(yù)訓(xùn)練語言模型中,ChineseBERT[27]將具有中文特性的字形和拼音融入預(yù)訓(xùn)練過程中,在機器閱讀理解等多項中文自然語言處理任務(wù)中達到了SOTA,該模型在訓(xùn)練數(shù)據(jù)較少的情況下優(yōu)于常規(guī)的預(yù)訓(xùn)練模型。
盡管預(yù)訓(xùn)練語言模型的上下文表示已經(jīng)包含了句法、語義等知識,但挖掘上下文表示所蘊含的常識的工作較少,它對于機器閱讀理解是非常重要的。Zhou 等[28]在不同具有挑戰(zhàn)性的測試中檢驗GPT[24]、BERT[9]、XLNet[10]和RoBERTa[26]的常識獲取能力,發(fā)現(xiàn)模型在需要更多深入推理的任務(wù)上表現(xiàn)不佳,這也表明常識獲取依然是一個巨大挑戰(zhàn)。
2.3 基于知識推理的機器閱讀理解技術(shù)
如何提高系統(tǒng)的可解釋性是人工智能領(lǐng)域一項重要挑戰(zhàn),對于機器閱讀理解等自動問答任務(wù),特別是復(fù)雜問題回答,機器需要具備通過推理來獲取答案的能力,而目前的深度學(xué)習(xí)方法可解釋性較差是一個普遍現(xiàn)象,無法將推理過程進行顯示地表達。常見的基于知識推理的機器閱讀理解技術(shù)包括語義蘊含推理、知識圖譜推理以及基于檢索的多跳推理,如圖3 所示。
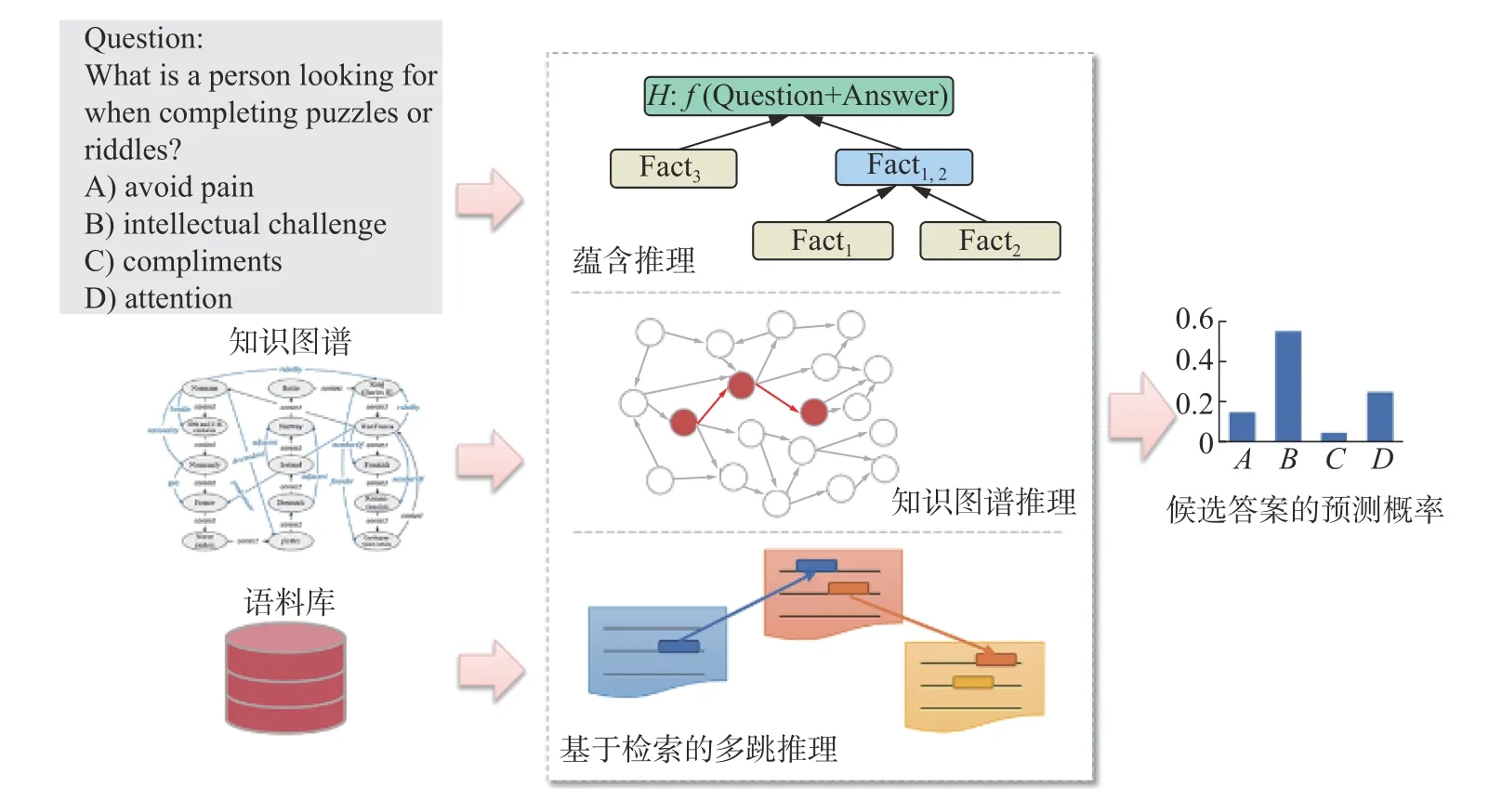
圖3 基于知識推理的機器閱讀理解技術(shù)Fig.3 Technologies of machine reading comprehension model based on knowledge inference
基于語義蘊涵推理的問答方法:問題回答可轉(zhuǎn)換為文本蘊涵任務(wù),將問題和候選答案組成假設(shè),系統(tǒng)決定候選知識庫是否能推出假設(shè)。Shi等[29]研究一種神經(jīng)符號問答方法,將自然邏輯推理集成到深度學(xué)習(xí)體系結(jié)構(gòu)中,建立推理路徑,計算中間假設(shè)和候選前提的蘊含分值,提升模型性能并具有可解釋性。Dalvi 等[30]以語義蘊涵樹的方式來生成解釋,并創(chuàng)建了首個包含多階蘊涵樹的數(shù)據(jù)集EntailmentBank,逐步從已知事實逼近由問題和答案構(gòu)成的最終假設(shè),為自動問答任務(wù)生成更加豐富的和系統(tǒng)的解釋,通過一系列的推理鏈來支撐正確答案的獲取。同時,也出現(xiàn)了無效蘊涵推理等問題,有待優(yōu)化,但該方法在進一步提高模型的可解釋性方面進行了有效嘗試。
基于知識推理的問答方法:知識圖譜是一種以關(guān)系有向圖形式存儲人類知識的資源,與無結(jié)構(gòu)的文本數(shù)據(jù)相比,結(jié)構(gòu)化的知識圖譜以一種更加清晰準確的方式表示人類知識,從而為高質(zhì)量問答系統(tǒng)的構(gòu)建帶來了前所未有的發(fā)展機遇,有代表性的大規(guī)模知識圖譜包括ConceptNet[31]、DBpedia[32]、YAGO[33]等。常識問答數(shù)據(jù)集CommonsenseQA[17]是通過從ConceptNet[31]中抽取出具有相同語義關(guān)系的知識,構(gòu)建問題和答案。
基于知識增強的常識類問題回答中,首先面臨的問題是,知識圖譜與自然語言文本表達的異構(gòu)性。Bian 等[34]提出一種將知識轉(zhuǎn)化為文本的框架,用于為常識問答提供評測基準,在CommonsenseQA[17]上取得最優(yōu)性能,同時也表明知識的潛力在常識問答任務(wù)上未得到充分利用,在上下文相關(guān)的高質(zhì)量知識選擇、異構(gòu)知識的利用等方面有待繼續(xù)深入。知識表達通常采用基于圖的方法,但該方法關(guān)注于拓撲結(jié)構(gòu),忽略了節(jié)點和邊所蘊含的文本信息。Yan 等[35]提出基于BERT[9]的關(guān)系學(xué)習(xí)任務(wù),將自然語言文本與知識庫對齊進行推理,并證明了關(guān)系學(xué)習(xí)方法的有效性。
更進一步,針對生成式常識推理這一更具有挑戰(zhàn)性的任務(wù),現(xiàn)有模型很難生成正確的句子,其中一個重要原因是沒有有效結(jié)合知識圖譜中常識知識之間的關(guān)系信息。Liu 等[36]研究知識圖譜增強的KG-BART 模型,結(jié)合知識圖譜生成更有邏輯性更自然的句子表達,通過圖注意力聚合概念語義,增強對新概念集的泛化能力。該方法的實驗結(jié)果證明,結(jié)合知識圖譜后,模型可以生成質(zhì)量更高的語句。KG-BART 模型可以遷移到常識問答等以常識為中心的下游任務(wù)。
基于檢索與知識融合的多跳推理方法:多跳問答是一項需要多層推理的挑戰(zhàn)性任務(wù),在實際應(yīng)用中十分普遍。該任務(wù)需要從大規(guī)模語料庫中發(fā)現(xiàn)回答問題的支撐證據(jù),分析分散的證據(jù)片段,進行多跳推理實現(xiàn)對問題的回答。多跳問答通常使用實體關(guān)系進行分步推理,已有方法通過預(yù)測序列關(guān)系路徑(較難優(yōu)化)或匯聚隱藏的圖特征進行答案推理(可解釋性差)。Shi 等[37]提出了TransferNet,TransferNet 使用同一框架支持實體標簽和文本關(guān)系的表示,推理的每一環(huán)節(jié)關(guān)注問題的不同部分,傳遞實體信息,取得優(yōu)秀性能表現(xiàn)。Li 等[38]提出新的檢索目標“hop”來發(fā)現(xiàn)維基百科中的隱藏證據(jù),將hop 定義為含有超鏈接的文本和鏈接到的文檔,檢索維基百科回答復(fù)雜問題。
針對現(xiàn)有基于單跳的圖推理方法會遺漏部分重要的非連續(xù)依賴關(guān)系的難題,Jiang 等[39]定義高階動態(tài)切比雪夫近似圖卷積網(wǎng)絡(luò),將直接依賴和長期依賴的信息融合到一個卷積層來增強多跳圖推理,在文本分類、多跳圖推理等多個任務(wù)上進行實驗,取得了最優(yōu)性能。Feng 等[40]提出一種適合多跳關(guān)系推理的模型MHGRN,結(jié)合圖神經(jīng)網(wǎng)絡(luò)和關(guān)系網(wǎng)絡(luò),通過多跳信息傳遞,在長度最多為k的關(guān)系路徑上傳遞信息,賦予圖神經(jīng)網(wǎng)絡(luò)直接建模路徑的能力。
3 數(shù)據(jù)集與評價指標
3.1 數(shù)據(jù)集
大規(guī)模高質(zhì)量數(shù)據(jù)集的發(fā)布是推動機器閱讀理解快速發(fā)展的重要因素,根據(jù)不同任務(wù)類型,代表性數(shù)據(jù)集如表1 所示,發(fā)布時間軸如圖4 所示。其中,完形填空式問答任務(wù)數(shù)據(jù)集中Book-Test[14]的問題規(guī)模最大,在2015 年以后片段抽取式的數(shù)據(jù)集規(guī)模均在萬級以上。

圖4 機器閱讀理解數(shù)據(jù)集發(fā)布時間軸Fig.4 Time axis of machine reading comprehension datasets
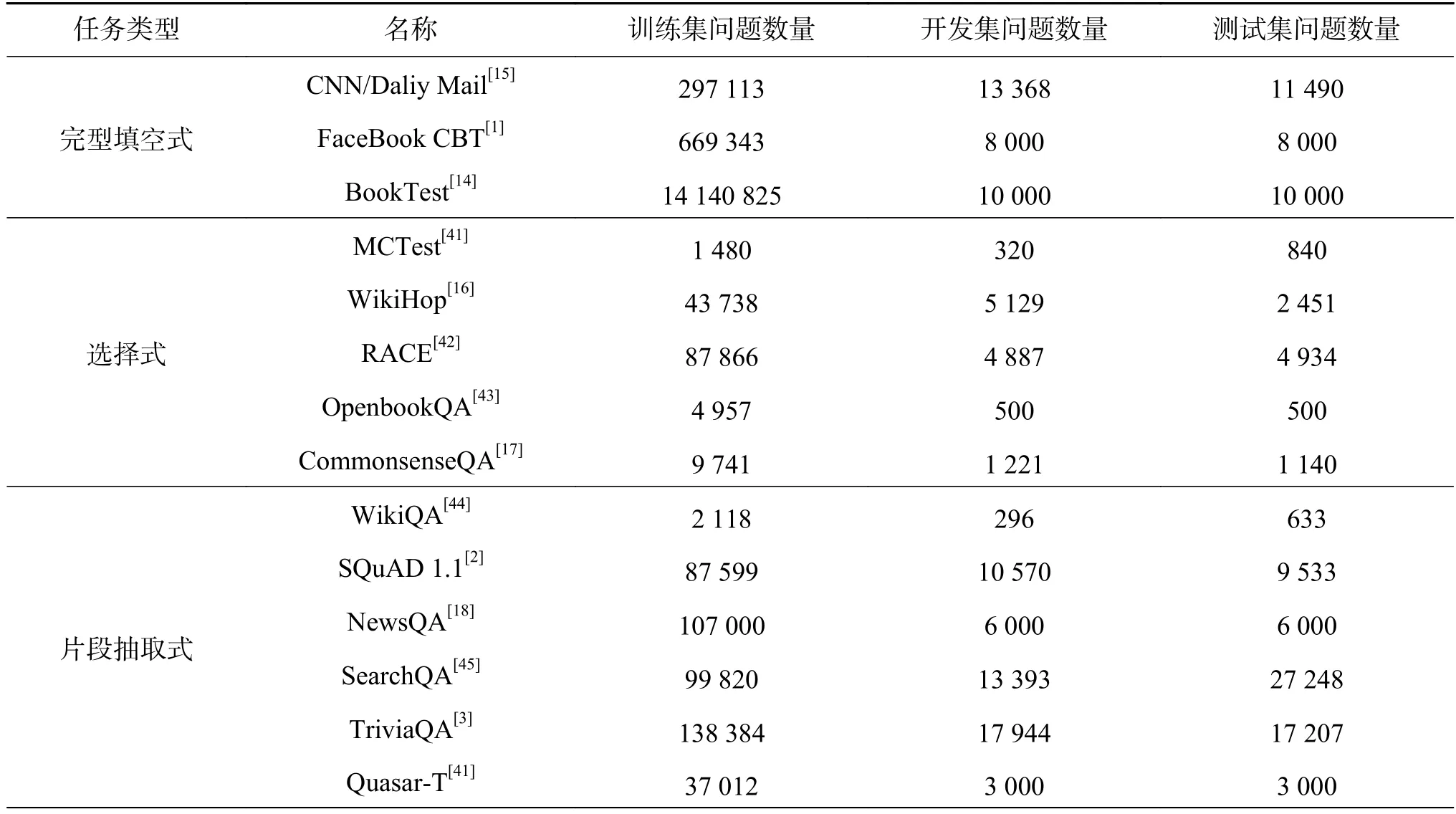
表1 機器閱讀理解主要數(shù)據(jù)集統(tǒng)計Table 1 Statistics of machine reading comprehension datasets

續(xù)表 1
其中,規(guī)模較大的數(shù)據(jù)集如SQuAD 2.0[46]、BookTest[14]和NewsQA[18],推動了BiDAF[4]、RNet[6]等經(jīng)典模型的發(fā)展。
在片段抽取式數(shù)據(jù)集中應(yīng)用廣泛的數(shù)據(jù)集有SQuAD[2],模型QANet[20]與BERT[9]在該數(shù)據(jù)集上表現(xiàn)尚佳,且BERT[9]在兩個評測指標上首次超越了人類水平,在此基礎(chǔ)上預(yù)訓(xùn)練語言模型與微調(diào)的方法成為主流。在自由式問答數(shù)據(jù)集DROP[19]中,仍然與人類F1值為0.964 2 的水平存在一定距離。在需要推理的任務(wù)中,在選擇式數(shù)據(jù)集CommonsenseQA[17]性能表現(xiàn)優(yōu)異的模型中用到了知識圖譜和圖神經(jīng)網(wǎng)絡(luò),評測排名第一的DEKCOR[54]模型還引入了輔助的篇章信息,但與人類水平仍有差距。
3.2 評價指標
3.2.1 準確率
準確率是最常用的評價指標,它表示機器閱讀理解模型正確回答的問題占所有問題的百分比。設(shè)機器閱讀理解任務(wù)包含n個問題,其中模型正確回答了m個問題[55],則準確率a的計算為
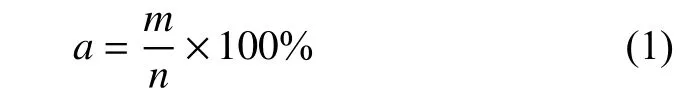
準確率一般用于評價完形填空式和選擇式問答任務(wù),例如Facebook Children’s Books Test[1]、CommonsenseQA[17]等。片段抽取式問答數(shù)據(jù)集中的SearchQA[45]和自由式問答數(shù)據(jù)集中的DROP[19]也使用了該指標。
EM(exact match)值與準確率的計算相同,EM 值要求式(1)中的m為所有問題中模型輸出答案與正確答案完全相同的個數(shù),即模型輸出答案與正確答案中的每個單詞和位置都必須相同。在片段抽取式問答任務(wù)中,EM 值與準確度相同,且使用EM 值作為它們的評價指標,例如SQuAD[2]、TriviaQA[3]、HotpotQA[49]等。
3.2.2F1值
F1值評價指標,表示數(shù)據(jù)集中標準答案與模型預(yù)測的答案之間平均單詞的覆蓋率,將精確率P(precision)和召回率R(recall)折中。其中,精確率為預(yù)測正確的答案占所有預(yù)測答案的百分比,召回率則是預(yù)測正確的答案占所有標準答案的百分比,而F1值是將這兩個指標綜合在一起,即
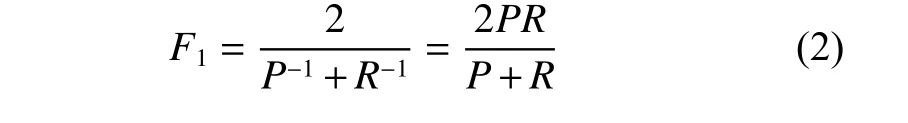
F1值通常是片段抽取式問答任務(wù)采用的評價指標,例如SQuAD[2]、HotpotQA[49]等。自由式問答任務(wù)中的Natural Questions-Short[53]也使用了F1值。相比于EM,F(xiàn)1值允許模型預(yù)測答案和正確答案之間有一定范圍偏差,因此,數(shù)據(jù)的類別分布不平衡時,F(xiàn)1值更適用。
3.2.3 其他評價指標
ROUGE-L[56]相比于EM 值和F1值更靈活,其值用于評價預(yù)測答案和真實答案之間的相似度,但候選答案的長度會影響ROUGE-L 的值;BLEU[57]最初用于機器翻譯任務(wù)中,不僅可以評價預(yù)測答案和真實答案之間的相似度,還可以考察候選答案語言表達流暢性,但BLEU 對詞重復(fù)和短句現(xiàn)象不利。因此這兩個指標通常用于不受原語境限制的任務(wù)中。一般在自由式問答中使用ROUGE-L[56]和BLEU[57]作為評價指標,例如DuReader[8]、DROP[19]等。
4 機器閱讀理解領(lǐng)域的挑戰(zhàn)和發(fā)展趨勢
目前,在大規(guī)模高質(zhì)量數(shù)據(jù)集的推動下,機器閱讀理解領(lǐng)域的研究取得了快速發(fā)展,甚至在部分評測任務(wù)上已經(jīng)超過了人類的表現(xiàn)。但是,在一些新提出的任務(wù)或研究方向上,機器目前的性能遠未達到人類的理解水平。該領(lǐng)域目前的主要挑戰(zhàn)和發(fā)展趨勢概括如下。
知識驅(qū)動與推理技術(shù)提升可解釋性:將知識融入機器閱讀理解任務(wù)中來實現(xiàn)復(fù)雜的問題回答是基于人類的思考方式提出的一種策略[58]。知識驅(qū)動的閱讀理解模型通過引入外部知識,輔助理解篇章內(nèi)容并回答問題。大規(guī)模知識庫的構(gòu)建也需要考慮知識的獲取方式、多模態(tài)資源中知識的獲取、不同來源的知識的融合。同時,知識驅(qū)動與推理技術(shù)的運用可以較好地解決基于神經(jīng)網(wǎng)絡(luò)模型可解釋性差的問題。
對話式問答任務(wù)中的語義理解:對話式問答同樣是根據(jù)人類獲取知識的習(xí)慣而提出的任務(wù),讓機器根據(jù)已有的一系列問答序列,對當(dāng)前問題進行回答。其中,問答序列具有時序性和前后關(guān)聯(lián)性,如何理解當(dāng)前問題與歷史問答記錄的關(guān)系是該任務(wù)的一大難點。此外,指代消解技術(shù)在該任務(wù)中非常重要,機器需要根據(jù)歷史問答記錄,準確理解篇章、問題中的指代實體,進行補全。
機器閱讀理解模型的健壯性:目前的機器閱讀理解模型往往過于依賴文本表面的信息,而缺乏深入的理解。在篇章中引入干擾數(shù)據(jù),生成對抗樣本,結(jié)果表明,多數(shù)現(xiàn)有模型性能明顯下降。如何生成有效的對抗樣本,通過對抗訓(xùn)練提升模型的健壯性成為研究的重點。
5 結(jié)束語
機器閱讀理解是自然語言處理領(lǐng)域的難點問題,它是評價和度量機器理解自然語言程度的重要任務(wù)。近年來基于深度學(xué)習(xí)技術(shù)的機器閱讀理解模型研究發(fā)展迅速。本文介紹了機器閱讀理解任務(wù)劃分,對機器閱讀理解相關(guān)技術(shù)進行了分析,包括端到端的神經(jīng)網(wǎng)絡(luò)模型、預(yù)訓(xùn)練語言模型以及知識推理等方法,并選取了各個任務(wù)中有代表性的數(shù)據(jù)集進行統(tǒng)計分析,介紹了不同機器閱讀理解任務(wù)中常用的評價指標。目前機器的語言理解能力距離人類的理解水平還有較大差距,我們對該領(lǐng)域面臨的挑戰(zhàn)和發(fā)展趨勢進行了分析。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
