基于卷積神經網絡的典型偵察目標檢測方法研究
2023-01-11 15:24:36袁建虎徐顯海
現代計算機 2022年20期
岳 磊,袁建虎,徐顯海
(1.陸軍工程大學野戰工程學院,南京 210001;2.95979部隊,泰安 271000)
0 引言
偵察巡邏是確保地區安全穩定的重要行動,是確保社會經濟健康發展的重要保障,但是巡邏偵察環境復雜多樣、巡邏地點交通不便、檢測目標多樣等問題增加了任務執行難度。傳統巡邏偵察通過低近偵察,拍攝圖像視頻資料觀察判斷可疑區域,但視野十分有限且檢測效率低,檢測效果較差。現代巡邏偵察行動要求節奏迅速、反應快,減少非必要時間損失帶來的影響。伴隨計算機視覺在軍事應用上的發展,傳統檢測精度低、檢測難度大、實時性差等問題也隨之突出。因此研究智能目標檢測在軍事偵察、邊境治理、引導打擊和反恐維穩等領域的應用具有重要意義。
執行偵察巡邏任務時,主要面臨以下困難:①任務場景復雜:山岳叢林、村落、高寒山地、荒漠草原。②檢測方式多樣:采用抵近偵觀察設備、無人機航拍和視頻監控進行偵察圖像采集。③檢測目標種類多樣:行人、車輛、牲畜、建筑等。
上述巡邏偵察任務中面臨的問題十分具有挑戰性,使得眾多學者進行深入研究。近年來隨著神經網絡的深入研究,計算機計算性能和存儲能力提升,采用深度學習進行目標檢測已經廣泛用于各個領域,在國家安全、軍事、交通、醫療和生活等都是重要研究方向[1-2]。通過深度卷積神經網絡能夠有效改善傳統檢測算法深層特征提取不充分、泛化性差、受自然和人工干擾因素多的問題,同時提升檢測精度及效率。
目前根據網絡結構設計方式不同,現有的深度學習檢測算法可以分為兩類:一類是基于區域的兩階段(Two-Stage)檢測算法,代表算法有R-CNN[3]、Faster R-CNN[4]、Mask R-CNN[5]等,兩階段算法主要是依據圖像中被檢測實際位置,提前選取候選區的方式進行訓練。另一類是一階段(One-Stage)檢測算法,該類算法采用端到端檢測網絡,代表算法有YOLO(You Only Look Once, YOLO)[6-7]、 SSD(Single Shot Multibox Detector, SSD)[8]等。
一階段算法使用回歸思想,用回歸的方式得出檢測框類別及偏移量,并得出最接近真實值的檢測框。郝旭政等[9]對行人特征進行加強表達。通對圖像中的行人表達和分布進行分析,在保證檢測算法檢測速度的前提下,對網絡中的殘差模塊進行了改進,使得YOLO算法獲得了更強的表達能力。裴偉等[10]針對目標重復多次漏檢以及小目標漏檢的情況,以SSD為基準模型進行改進,將不同特征融合機制進行了融合,且通過實驗證明了此方法具備較好的準確性和實驗性。
針對偵察巡邏任務背景下被檢測圖像檢測圖像模糊、自然環境干擾造成檢測困難的問題,本文在YOLOv5的基礎上對原始標準網絡進行改進,收集、標注、擴充相關實驗數據集;在YOLOv5的骨干網絡(Backbone)中引入雙通道注意力機制[11](Convolutional Block Attention Mod?ule,CBAM)模塊。
1 檢測模型
1.1 YOLOv5算法結構
YOLOv5檢測模型基本框架主要包括Input、Backbone、Neck、Prediction等四部分。輸入部分:主要將圖像調整為640×640的比例,并進行縮放、增強等處理;Backbone模塊主要進行切片處理操作:將輸入圖像進行切片處理,便于模型的訓練以及多種尺度的特征的提取;Neck模塊完成多個尺度特征信息融合的功能,在這個部分將不同深度的特征信息進行融合,可以減少因特征提取而丟失的語義信息,從而能夠使模型訓練獲得更多的訓練信息,有利于算法精度的提升;Prediction部分由3個檢測頭組成,Bounding Box損失函數使用GIOU函數,如式(1)所示,類概率分類采用交叉熵損失函數。

1.2 雙通道注意力機制模塊
為了解決被檢測目標與背景分離性較差、目標顯著度低的問題,本文在YOLOv5網絡模型中的殘差塊與卷積塊中引入通道注意力和空間卷積塊注意力模型[12-13]。

圖1 雙通道注意力機制模塊
在CBAM模塊中的通道注意力機制,采用Maxpool和Avgpool對特征信息進行增強,計算公式如下:

Mc表示CBAM模塊中的通道注意力模塊,MS表示空間注意力模塊;H×W表示為特征圖大小;特征圖表示為F∈RC×H×W,σ為Sigmoid非線性激活函數;MLP(Multilayer Perceptron)為共享感知器;W0和W1
分別表示MLP中多層感知器中的隱藏層權重和輸出層權重;Fcavg和Fcmax分別表示通道注意力機制的全局平均池化操作和最大池化操作。
因為添加通道注意力機制后的網絡會使圖像位置信息產生損失值,因此在此基礎上再添加空間注意力模塊。將特征圖F∈RC×H×W輸入空間注意力模塊后,在通道維度對特征圖進行平均池化和最大池化操作。進行信息增強,得到兩個H×W× 1通道,并將這兩個通道拼接在一起,然后完成卷積操作和Sigmoid激活函數操作,得到權重系數MS;最后,將權重系數與前一步的縮放特征進行特征相乘,就可以得到空間注意力特征。相關的計算公式如下:
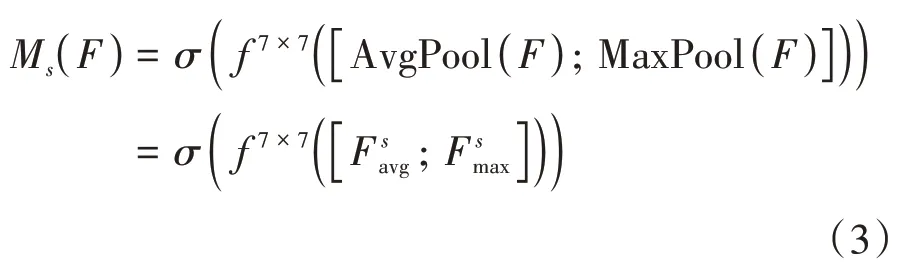
2 算法改進
2.1 基于YOLOv5的改進模型
將樣本數據集進行數據增強后,輸入到網絡中進行訓練;在網絡中增加雙通道注意力機制部分,能夠有效提取深層次語義信息,形成模型偏好特征,找到興趣點。本文所提出檢測算法如圖2所示。

圖2 改進檢測算法框架
2.2 數據增強策略
在執行偵察巡邏任務時,由于環境多樣常會出現自然因素導致的采集數據質量低的情況,這就要求檢測模型具備較高的魯棒性和泛化性。為解決這一問題,對檢測數據集進行數據增強,采用Mixup方法模擬檢測目標被遮擋的場景,即從訓練集中隨機抽取兩張圖像,對像素和標簽進行加權;此外結合任務場景采用隨機縮放、旋轉、裁剪、高斯噪聲、平移等方式進行樣本擴充,改善了過擬合和樣本數據量少的問題,如圖3所示。

圖3 對樣本數據集進行擴充
3 模型訓練及結果分析
本文實驗所使用的軟硬件環境如表1所示。
翻轉課堂的教學效率提高,課堂富余時間較多,使我們可以根據教學內容多設計一些練習放到課內.作業設計一般要求在25分鐘左右,以近年來的高考真題與模擬試題為主,有一定的坡度.

表1 實驗算法訓練環境配置
本文共整理了1800張典型偵察巡邏目標數據集,包含不同場景的行人和車輛。對原有樣本進行增強后,將數據集擴充至6500張;使用la?bellmg工具對數據集進行標注,并按照8:1:1的比例區分訓練集、驗證集、測試集進行模型訓練。
3.1 模型訓練
模型訓練過程:為防止過擬合和跳過最優解,將動量因子設置為0.937,并采用隨機梯度下降法進行參數調整。Batchsize設置為32,Epoch訓練500輪次,初始學習率為0.01,權重衰減0.0005,Mixup的重疊系數設置為0.7。待損失函數和精度都逐漸穩定時,得到算法最優權重。在圖像預處理過程中,將圖像大小調整為640×640后再輸入網絡中進行訓練。
3.2 模型評價指標
為了驗證本文所提算法改進的有效性,使用平均精度均值mAP(mean AP)和平均精度AP(Average Precision)作為衡量指標。相關表達式如下:

上式中:TP、FP和FN分別表示不同的意思。其中TP表示本身屬于該類目標,并且能夠被模型準確檢測的實例數量;FP則表示本身不屬于該類目標,但由于模型性能不足而被誤判為該類目標的實例數量;FN表示負樣本被錯誤檢測為正樣本的數量。AP為PR曲線積分,N為檢測種類數量,mAP表示為多類別平均精度。IOU取0.5時mAP為mAP@0.5,IOU取不同取值的mAP為mAP@0.5:0.95。
3.3 實驗分析
為了驗證本文所提模型的有效性,在數據集上進行了訓練和測試,訓練結果如圖4所示。

圖4 改進mAP@0.5比較曲線
從實驗結果可以看出,本文改進算法和原始標準算法在此數據集上都有較好的檢測性能。相較而言,本文算法在Epoch至150輪次左右時,準確率上升至0.579,并最終在350輪左右時穩定在0.675;標準YOLOv5算法訓練迭代Epoch至180輪次左右時,準確率上升到0.585,最終穩定0.643。為了檢驗本文算法的檢測效果,將改進算法和原始標準算法進行了檢測對比實驗,相關檢測結果如圖5所示。

圖5 各算法檢測對比結果
第一組圖像為原始標準YOLOv5網絡模型的檢測結果,由實驗數據可知涉及行人、車輛,背景環境有叢林、荒漠,被檢測物體尺度大小不一,且存在部分目標被遮擋或與背景高度相似的情況。但從結果可得,YOLOv5檢測算法用于不同場景下的典型巡邏目標具有良好的檢測效果。
第二組數據為本文改進算法檢測結果。由結果可知被檢測行人目標在復雜環境下特征表達能力得到提高,相較于原始檢測算法,模型檢測精度提高了3.25%。雖然被檢測目標存在遮擋模糊且目標較小的情況,但本文算法仍能以較高準確率、較少的損失值,更接近于真實框。
4 結語
為解決在不同場景下典型偵察巡邏目標檢測效果差,檢測效率低的問題,本文引入了基于卷積神經網絡的一階段目標檢測算法YO?LOv5。通過實驗證明了:相較于其他檢測算法,YOLOv5能夠有較高的準確性和較低的漏檢率,更適用于巡邏偵察任務。此外,本文以YOLOv5為基準模型,分析應用場景及目標會使檢測算法存在因目標尺度不一、背景復雜、自然天氣影響導致的較多漏檢誤檢問題。針對這些問題,我們融合雙通道注意力機制模塊,使檢測模型更專注有效特征;對數據樣本進行了增強,增強了算法的魯棒性。實驗結果表明,本文算法在多種復雜環境下的測試,具有更好的檢測以及實時性,較好降低了因目標多樣、遮擋等情況造成的漏檢和誤檢情況。但本文算法在檢測車輛目標時檢測精度較低,且因數據集限制,檢測精度及召回率還需提升。隨著后期研究增加和檢測樣本不斷擴充,模型精度和泛化能力將進一步提升。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
