深度聚類索引下的海量地震數據快速三維可視化
2023-01-09 14:29:16湯文琳賀建飚
計算機工程 2022年11期
關鍵詞:模型
湯文琳,謝 凱,文 暢,賀建飚
(1.長江大學 電子信息學院,湖北 荊州 434023;2.長江大學 電工電子國家級實驗教學示范中心,湖北 荊州 434023;3.長江大學 西部研究院,新疆 克拉瑪依 834000;4.長江大學 計算機科學學院,湖北 荊州 434023;5.中南大學 計算機學院,長沙 410083)
0 概述
三維可視化技術在計算機圖形學的發展過程中起重要作用,是對數據對象進行多方位呈現和分析的有效方法,已經滲透到醫學[1-2]、海洋[3]、地質[4]、油氣勘探等領域。三維可視化技術中的體繪制算法[5-6]已應用在地質勘探方面,能夠清晰地描繪地質體內部層次細節信息和特征,為相關研究人員提供數據支持。
目前,三維可視化技術的發展面臨諸多問題:一方面,傳統體繪制算法復雜度較高,需要較大的內存空間,對計算機硬件的要求較高;另一方面,對于一定規模的體數據而言,傳統算法的計算速度較慢,在進行交互顯示時容易出現畫面延時、波動卡頓等問題。因此很多三維可視化方案均存在一定局限性。
為此,研究人員提出了諸多相關的優化方案。文獻[7-8]提出基于硬件方面的體繪制算法,并在傳統光線投射算法和三維紋理映射算法的基礎上使用硬件設備提高渲染性能。文獻[9]針對海量點云數據索引時間過長且內存占用過大的問題,提出使用八叉樹(Octre,OCT)重新組織數據并分塊保存,但八叉樹最小葉節點的確定較困難。文獻[10]針對大量的地理空間數據,使用并行框架構建R 樹及其變體,以減少索引更新的時間,但R 樹本身結構導致存在部分數據節點空間的重疊浪費問題。文獻[11]考慮構造R 樹的最小外接矩形框的影響,采用動態K-means 聚類算法,在R 樹的基礎上對結構進行優化,從而提高算法的檢索速度。文獻[12]將數據按照時空周期劃分,結合動態K 值的聚類算法構建希爾伯特R 樹(Hilbert R-Tree,HRT)結構,通過聚類和空間填充曲線在一定程度上降低節點之間的覆蓋交疊,能很好地支持海量時空特征數據的索引。
除了從數據結構的角度解決快速可視化的問題,還有一些方案從預測視點的運動軌跡角度出發,結合調度加載算法解決當數據規模較大時出現的顯示卡頓問題。文獻[13]基于拉格朗日插值算法預測視點的運動軌跡,通過設置不同的插值步長決定最終預測的正確率和渲染效果,但其預測誤差會隨著階次增加而增大。文獻[14]在視點運動的預測上應用堆疊的長短時記憶(Long Short Term Memory,LSTM)網絡,相比傳統的估算方法預測精度有所提升。文獻[15-16]基于深度學習模型對相關時間軌跡數據進行預測,得到較好的預測效果。文獻[17-18]基于可見性判斷的角度,通過結合視錐體裁剪算法加速繪制大規模數據,提高交互性能。文獻[19-20]除了在數據結構上直接改善索引效率,還結合了動態調度的思想來提高數據加載速度。
本文提出一種面向海量地震數據的快速三維可視化方法,在HRT 結構的基礎上使用深度聚類優化結構,改善因空間數據分布不均造成的節點重疊問題,以提高索引查詢效率。通過時序卷積模型提前預測下一視點位置,動態劃分可視區域,并提前將潛在區域的數據加載到內存中,避免因集中加載引起畫面卡頓。此外,在不影響圖像質量的前提下提前剔除不必要的節點,避免系統資源浪費,從而加快渲染速度。
1 本文算法框架
本文可視化算法的總體框架結構如圖1 所示,主要分為3 個模塊,包括建立高效的數據索引結構(a)、視點運動軌跡的預測(b)以及體數據的調度加載(c)。
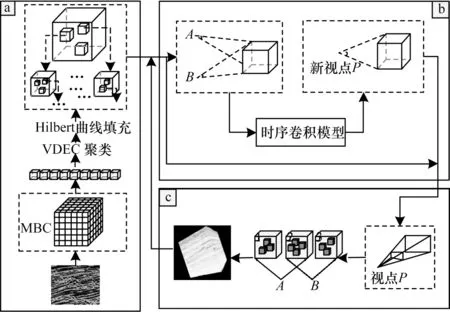
圖1 本文算法的總體框架Fig.1 Gerneral framework of algorithm in this paper
由圖1 可知,本文算法首先讀取地震數據文件,將原地震數據格式映射到空間的三維結構中,并根據計算機內存劃分最小邊界立方體(Minimum Bounding Cube,MBC)數據塊,在提取數據特征時利用變分深度嵌入聚類(Variational Deep Embedding Clustering,VDEC)完成聚類操作,將聚類之后的數據子塊的中心點經過Hilbert 曲線進行降維轉換,然后根據節點生成時間和內存重組R 樹的結構。當數據進入下一模塊時,確定當前視點位置坐標,此過程有兩條分支:一是使用視錐體模型對當前視點位置對應的可見空間數據進行剔除并渲染顯示;二是根據當前視點位置利用時序卷積網絡模型預測未來視點的位置,通過比較視點動態劃分模型,應用雙層視錐體裁剪算法得到預測視點所涉及到的數據范圍,對潛在數據進行加載渲染,并根據索引結構確定新的視點坐標,繪制下一幀圖像。
2 深度聚類與數據結構融合算法
2.1 數據的索引結構
針對因數據規模的擴大導致的索引結構復雜、效率過低等問題,僅靠改進硬件遠遠不夠,還需改進算法的軟件,才能高效解決海量地震數據的快速三維可視化問題。
本文算法的索引模塊采用HRT 結構,其思想是采用Hilbert 空間填充曲線,將無序數據按照特定方式連接,令曲線穿過高維空間中的數據,對數據的位置坐標進行編碼排序,將高維空間的數據拉直轉換成一維空間的數據,然后用最小邊界矩形將相鄰元素框住,節點越往上,框住空間越大,從而形成HRT結構。
雖然HRT 結構有相對較高的存儲利用率,但由于其被應用在大型體數據時,若數據分布不均,則容易出現節點空間重疊問題,即空間上數據對象相近,但經過空間曲線轉換后的數據碼值所屬節點空間不相鄰。對于大規模的數據集,可以通過合理的聚類算法將空間特征相似的數據聚集在一起,避免后續碼值轉換后數據錯分的情況發生,以此來提高結構的空間利用率,實現快速索引。
2.2 變分深度嵌入聚類VDEC
為優化索引技術,本文使用變分深度嵌入聚類VDEC 算法,相比傳統的聚類算法而言,VDEC 算法使用變分自編碼器VAE[21],采用無監督的算法反映輸入數據分布的本質特征,并通過深度嵌入聚類(Deep Embedding Clustering,DEC)[22]學習數據潛在隱變量空間的特征表示和聚類分配,以迭代優化目標,提升聚類性能。
變分自編碼器VAE 主要通過無監督算法將隱變量空間的數據特征重構輸出。VAE 的網絡結構包括編碼器和解碼器。包含地震特征的數據集經過隱變量分布p(z)生成隱變量空間表示z,再通過p(x|z)重構生成其中編碼器和解碼器的權重和偏差模型分別表示為φ、θ。根據貝葉斯公式可以得到p(z|x),其表達式如式(1)所示:

由于后驗分布計算困難,因此通過引入近似后驗分布qφ(z|x)逼近真實的后驗分布p(z|x)。KL 散度定義為:
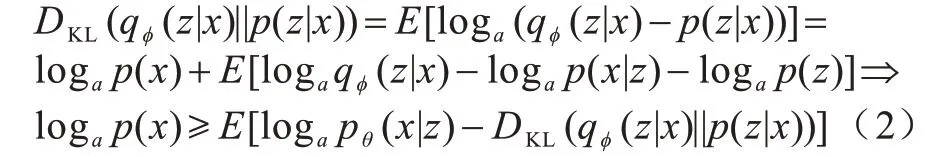
采用證據下界ELBO 為變分自編器的損失函數,其表達式如下:
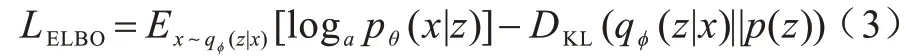
設z服從正態分布:

變分自編碼網絡VAE 在隱藏層輸出的參數有2 個維度,即均值μ和方差σ2:

從近似后驗分布qφ(z|x)重采樣得到z:

將采樣得到的z輸入至生成模型pθ(x|z)中,生成新的取qφ(z|x)與先驗分布p(z)之間的KL 散度作為編碼模型的損失:
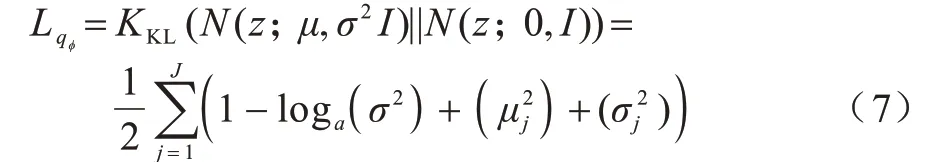
對于生成模型,定義解碼器的重構誤差為其損失:

取經過訓練后的自編碼器編碼部分作為學習到的信息特征z,比較其與聚類中心的相似度,其中相似度及目標分布的定義如下:
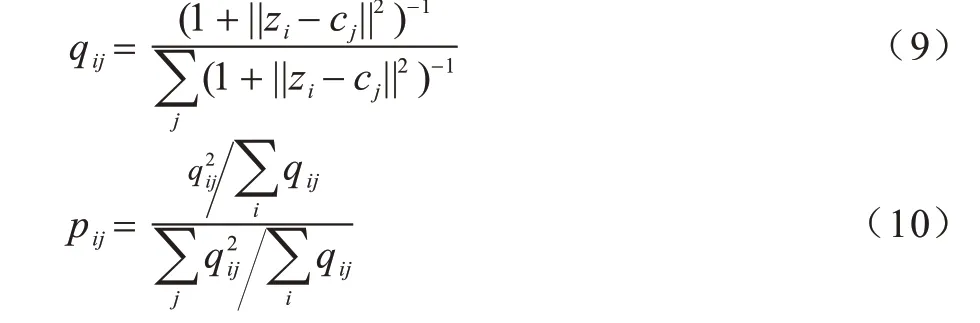
其中:j為隱變量空間的維度。
另外定義目標變量P與相似度變量Q的損失函數的表達式如下:
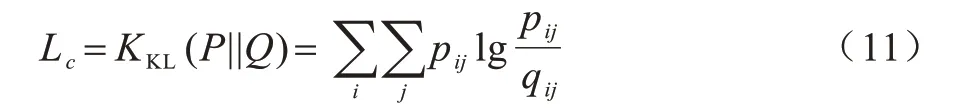
根據特征表示信息特征z與聚類中心之間的相似度表達式(9)得到數據x的聚類標簽,如式(12)所示:

用梯度下降法迭代優化總體的目標函數,表達式如式(13)所示:

其中:α為權重參數。
2.3 VDEC-HRT 算法結構
變分深度嵌入聚類融合HRT 樹(下文簡稱為VDEC-HRT)的具體算法如下:
算法1VDEC-HRT 算法

3 視點運動軌跡的預測
少量數據可以直接加載到內存顯示,但當數據規模增大時,則需要將數據分塊動態地加載和釋放,在動態掉隊加載之前根據視點運動軌跡,提前將數據加載到內存等待渲染,以避免大規模數據集中載入引起渲染畫面延遲和卡頓。
本文視點預測模塊根據持續變化的視點位置和視角預測未來視點的預期位置,并采用時間序列卷積網絡(Temporal Convolutional Network,TCN)[23]進行輔助。TCN 網絡相比RNN 等網絡,具有并行性高、梯度穩定、感受野靈敏等特點。
本文數據集中的每個點代表不同時刻連續運動軌跡的視點坐標,Tc時刻的坐標為pc(uc,vc,wc),其中u、v、w代表不同方向的維度。將當前時刻以及之前時刻的坐標序列X=(p1,p2,…,pc)作為模型的輸入,令卷積核F=(f1,f2,…,fk),其中k為卷積核的大小。將當前以及歷史時刻的坐標點構成的坐標序列X=(p1,p2,…,pc)輸入如圖2 所示的因果卷積結構,該結構為單向的時間約束結構,即當前時刻c的卷積操作僅在歷史時刻c-1及之前的信息上。pc處的因果卷積輸出為:

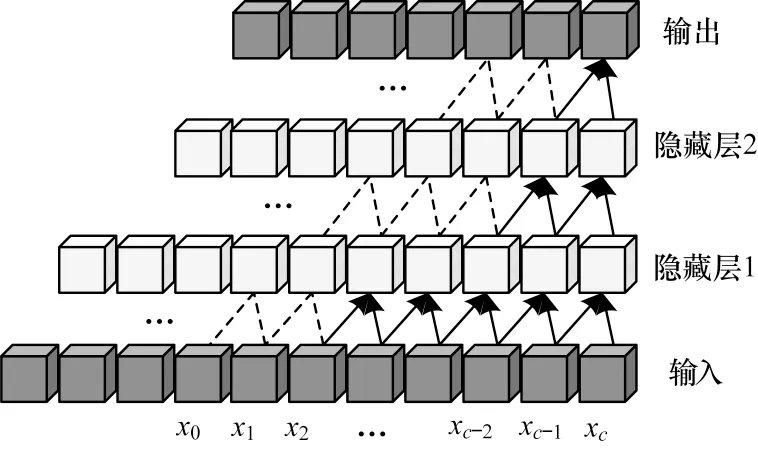
圖2 因果卷積結構Fig.2 Structure of causal convolution
之后將pc處的因果卷積輸出F(Pc)輸入如圖3所示的膨脹卷積結構中,其中d為空洞系數。
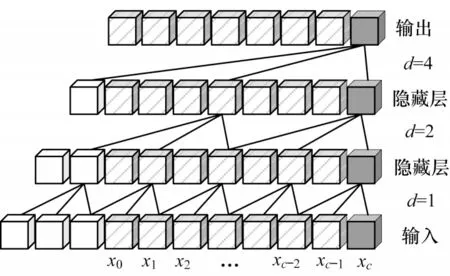
圖3 膨脹卷積結構Fig.3 Structure of expansion convolution
經過膨脹結構的輸出公式為:

使用正則化規范隱藏層的輸入,并在正則化之后引入Relu 函數:
在經過圖2 和圖3 的結構之后,引入Dropout 函數簡化網絡,從而避免過擬合:

為獲得長時間序列信息,且由于加上膨脹卷積后,網絡模型加深會影響其穩定性,因此本文在網絡結構中加入恒等映射,以增加網絡穩定度,最終輸出結果為:

將每2 個因果膨脹卷積基礎層、歸一化線性單元塊與恒等映射一起作為一個殘差模塊,令網絡模型以跨層方式傳遞信息。整體時序卷積網絡的結構如圖4 所示。
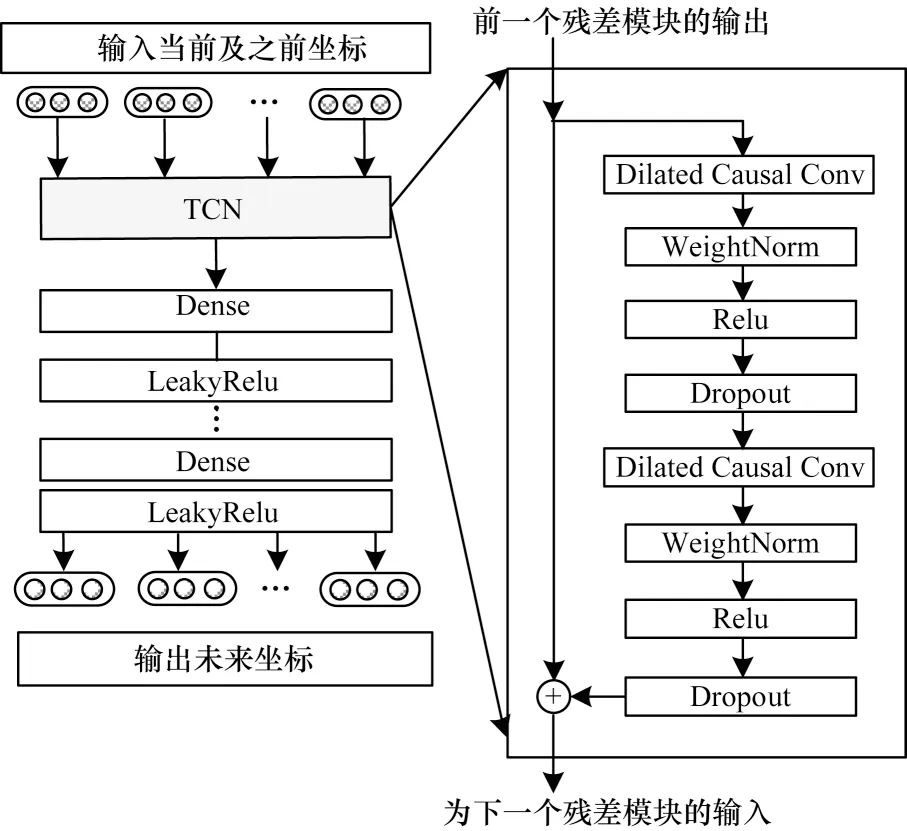
圖4 時序卷積網絡的結構Fig.4 Structure of sequential convolutional network
最后輸出結果的表達式如式(19)所示:
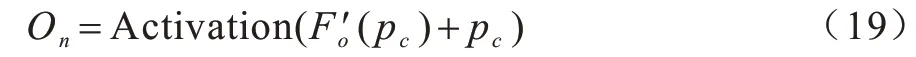
時序卷積網絡模型可以選擇是否由殘差模塊堆疊起深度網絡,且前一個殘差模塊的輸出可以作為下一個殘差模塊的輸入,以此加深網絡層數,提取本質特征。輸出特征在最后使用全連接層,并添加LeakyRelu 修正線性單元,輸出預測視點的坐標位置。
4 體數據的調度加載
隨著數據量的增大,在加載過程中需繪制的對象數量也不斷增加。可見性判斷方法在不影響渲染質量的前提下,在加載大規模數據時能夠減少系統負荷,加快圖像渲染的速度。其中,視錐體裁剪方法是可見性判斷方法之一,其操作開銷相對較小,且易于修改,能夠快速準確地加載圖形對象。
將原數據等量劃分成最小邊界立方體子塊,之后用VDEC-HRT 算法對原本的地震數據結構進行重組,這部分的數據調度加載利用視錐體對每個MBC 子塊進行空間位置關系判斷,并在繪制階段將不在范圍內的節點裁剪,從而縮短結構中對象遍歷的時間,提高渲染速度。
本文采用的雙層視錐體裁剪算法的具體流程如下:
步驟1采用粗裁剪算法,將視錐體簡化為圓錐體,判斷圓錐體和空間對象的位置關系,減少整體判斷次數以提高裁剪效率。粗裁剪算法流程如下:
1)將視錐體六面體簡化為一個簡易圓錐,其剖面圖如圖5 所示,其中A 為某一MBC 塊的中心坐標,C 為視軸上某點,AC 垂直于圓錐面于點B,d為MBC塊中心到任意頂點的距離。從視點位置作最小圓錐包含視錐體,使用簡易圓錐檢查其與最小邊界立方體MBC 之間的位置關系。

圖5 MBC 塊與簡易圓錐的位置剖面圖Fig.5 Position profile of MBC block and simple cone
2)如果某一MBC 塊的中 心A(x,y,z)?cone 不在圓錐內部,且AB ≥d,則判斷MBC 塊在圓錐的外部,對該MBC 塊進行裁剪,算法結束,否則繼續。
步驟2精細裁剪算法在粗裁剪的基礎上進一步使用標準視錐體截棱錐對空間對象進行精細裁剪,提高裁剪的精確性。
使用標準視錐體進行裁剪時,先使用數據的MBC 塊對視錐體的6 個平面(即圖6 中六面體的上、下、左、右、近、遠平面)依次判斷空間位置。
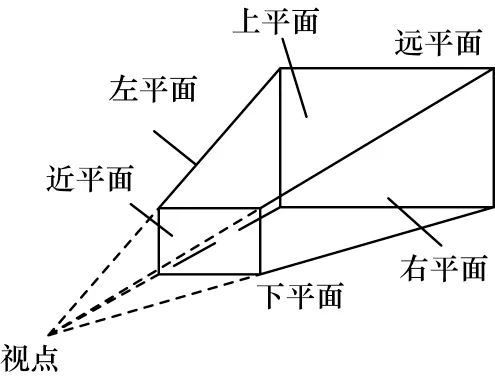
圖6 視錐體示意圖Fig.6 Schematic diagram of visual cone
精細裁剪算法的總體思想:當MBC 塊位于視錐體某一平面方程的外部時,即為不可見,則裁掉該物體對象;當MBC 塊在上述過程并未被裁剪,則說明其與視錐體的位置關系為包含或相交,具體來說為下面2 種情況:
1)位置關系為包含。當MBC 塊處于6 個平面內,說明空間對象位于視點區域內,則將空間對象直接送入GPU 繪制管線中并進行渲染顯示。
2)位置關系為相交。當截錐體某一平面的內側包含MBC 的一部分,且該平面外側也包含一部分,說明空間對象與視錐體是相交關系,則繼續對下層物體進行判斷,依次遍歷完所有的空間對象。
具體來說,視點位置位于世界坐標系的零點,首先將視錐體模型沿Z軸正向放置,使用設定的投影矩陣轉換頂點,進而得到截錐體對應的6 個平面方程。然后找出MBC 塊的頂點n點和p點,p點是距離平面最近的頂點,n點是最遠對角線的頂點(距離p最遠的頂點):設 2 個頂點的坐標分別為p(xmin,ymin,zmin),n(xmax,ymax,zmax),視錐體的6 個平面方程為ax+by+cz+d=0,將n、p分別帶入6 個平面方程中,若axmin+bymin+czmin+d>0,則可以判斷該MBC塊離平面最近的頂點在平面外側,則此MBC 塊在平面外側,對該MBC塊進行裁剪。同理,若p(xmin,ymin,zmin)在平面內側,n(xmax,ymax,zmax)在平面外側,說明MBC 塊與視錐體相交。如果p點和n點都在視錐體平面方程的內側,則說明MBC 塊在平面內側,直接將該MBC 塊的數據送入繪制管道渲染顯示。
將視點移動過程看作如圖7所示的視點動態模型,移動過程將整個數據對象范圍劃分為當前可見區域、潛在預加載區域以及釋放卸載區域。在經過時序卷積模型預測得到下一視點坐標之后,通過比較視點劃分的區域,結合視錐體模型進行卸載和加載渲染。具體來說,當視點處于A 位置時,圖7 中的1、2 部分即為當前可見區域,對其進行渲染顯示,潛在預加載區域則是劃分為預測下一視點B的可見區域,即圖7的2、3部分。當視點移動到B 時需要提前將該區域的數據標記為可見數據,并載入到內存等待渲染,便于用戶在持續瀏覽時直接對數據對象進行讀取顯示,避免交互時出現畫面卡滯的現象。另外當視點由A 運動到B 時,將區域1標記為釋放卸載域以減少系統負荷。
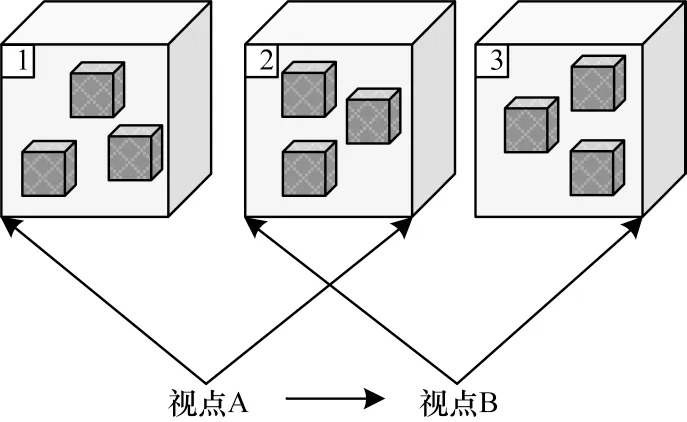
圖7 視點動態模型示意圖Fig.7 Schematic diagram of viewpoint dynamic model
體數據調度加載的流程如圖8 所示。首先,根據當前視點坐標并結合視點動態劃分模型,通過約束條件構建視錐體,獲取當前視點范圍內必須繪制的數據塊,將當前可見的數據塊送入GPU 渲染管線。其次,若視點持續進行勻速規則運動,則通過算法預測下一視點坐標,根據預測的坐標并結合視點動態區域模型獲取潛在預加載區域的數據塊,通過視錐體裁剪潛在區域范圍內的必要繪制數據,并將其載入內存等待顯示。最后,釋放卸載區域的數據,開始下一幀的繪制。

圖8 體數據調度加載流程Fig.8 Procedure of volume data scheduling loading
5 實驗結果與分析
5.1 實驗平臺及設置
實驗中用到的硬件設備為Dell G5-5500,處理器為Intel Core i7-10750H,芯片類型為GeForce RTX 2060,CPU 主頻2.60 GHz,內存16 GB。應用程序使用Visual Studio 2015+PyCharm2019+QT5.7 進行代碼編寫。
實驗所用的數據為我國某油田部分的地震工區數據,并以SEG-Y 格式進行存儲。數據分為3 組,數據集A 為469.7 MB,數據集B(體數據分布較均勻)為3 348.5 MB,數據集C(數據量較大且較分散)為14 643.4 MB,地震數據信息中包含埋藏深度、范圍、厚度、伸展趨勢等信息。
5.2 實驗結果
本文分別針對索引結構、視點預測以及體數據調度加載模塊進行對比評估,以證明本文方法的有效性。
5.2.1 數據結構的索引效率
為評估VDEC 模型聚類的有效性,本文在MNIST 手寫數據集[24]上對其進行驗證,首先采用K-means 算法初始化簇中心,使用編碼器預訓練,其中優化器采用Adam 優化器得到模型最佳參數,將學習率設置0.002,每訓練10 個epoch 更新一次參數,輸出維度設置為10,訓練200 次,并根據encode 編碼層返回的均值和方差構建隱藏特征空間z。用TSNE降維方法將采樣的小部分z映射到二維空間,并進行可視化,其潛在空間中的數據聚集分布如圖9 所示,可以看出數據的聚類效果較好,這說明潛在特征表示適合聚類。

圖9 VDEC 潛在空間的數據聚類分布Fig.9 Data clustering distribution of VDEC potential space
此外,本文選擇聚類準確率(Accuracy,ACC)、標準互化信息(Normalized Mutual Information,NMI)以及調整蘭德指數(Adjusted Rand Index,ARI)作為聚類指標[25],這3 類指標的值均是越靠近1,表明聚類效果越好。在MNIST 數據集上用不同算法測試聚類效果,結果如表1 所示。根據實驗結果,本文算法在3 個評價指標上依次比K-means 算法提高了44.79%、44.44%、59.78%,相比AE 和DEC 算法,其聚類效果也有一定提升。這說明本文算法相對于傳統聚類算法的效果更好,能夠為HRT 樹的建樹過程奠定良好的結構基礎,避免數據節點在建樹過程中出現空間重疊問題,進而提高索引的效率。
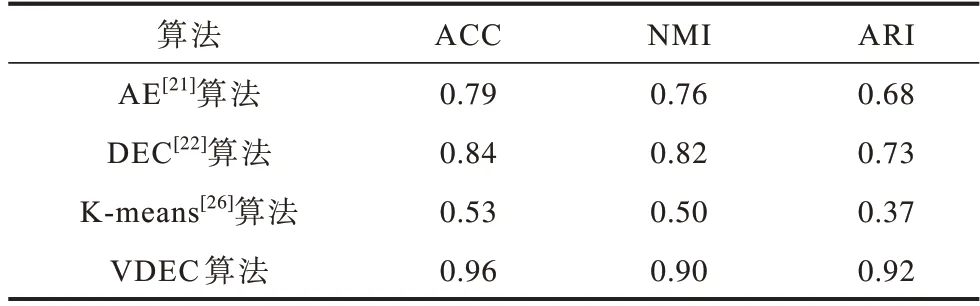
表1 不同算法在MNIST 數據集上的結果對比Table 1 Comparison of results of different algorithms under MNIST dataset
本文通過與其他索引結構算法的查詢效率進行對比,評估本文算法整體的數據結構索引效果。具體來說,為證明數據量大小的差異對索引結果的影響,對A 組數據分別取2%、4%、6%的數據量比率,同理B、C 兩組也取2%、4%、6%比率的數據,并比較OCT、HRT、基于K 均值算法的HRT(KHRT)、變分深度嵌入聚類下的HRT(Variational Deep Embedding Clustering-HRT,VDEC-HRT)等結構查詢數據塊算法的查詢時間,結果如圖10 所示。
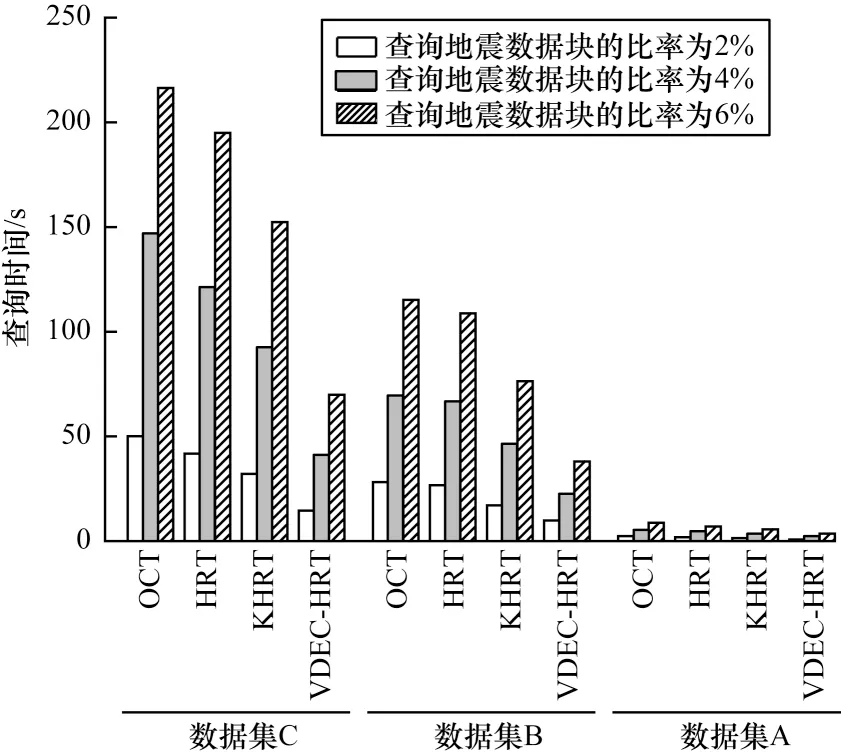
圖10 不同結構查詢數據塊算法的查詢時間對比Fig.10 Comparison of query time of different structure query data block algorithms
由圖10 可以看到,對于A 組數據而言,本文算法(VDEC-HRT)相比OCT、HRT 和KHRT 算法的查詢時間有所減少,但差距不明顯。對于B 組數據,與OCT 算法相比,本文VDEC-HRT 索引數據塊的時間減少了65.05%~66.96%,與HRT 算法相比,本文算法索引時間減少了63.10%~66.01%,與KHRT 相比減少了42.27%~51.74%。對于查詢C組數據子塊,與OCT、HRT和KHRT算法對比,本文算法的時間分別減少了67.69%~72.22%,64.14%~66.37%,54.10%~55.89%。所以即使對于規模較大的數據,本文算法能通過改進聚類使數據節點空間減少重疊,從而有效減少頻繁訪問的次數,提高查詢索引的效率。
5.2.2 對視點預測的評估
為評估預測算法的準確率,本文與拉格朗日插值、堆疊LSTM 算法進行對比,分別在時長1 min、5 min、10 min下預測數據塊的準確率,結果如表2所示。由表2可知,本文算法的精度相比拉格朗日插值、堆疊LSTM算法分別提高了12.08%~22.70%,2.24%~4.34%。雖然隨著時長和數據集的增大,預測的正確率有所下降,但本文算法相對于另外2種算法的預測正確率仍然有一定提升。
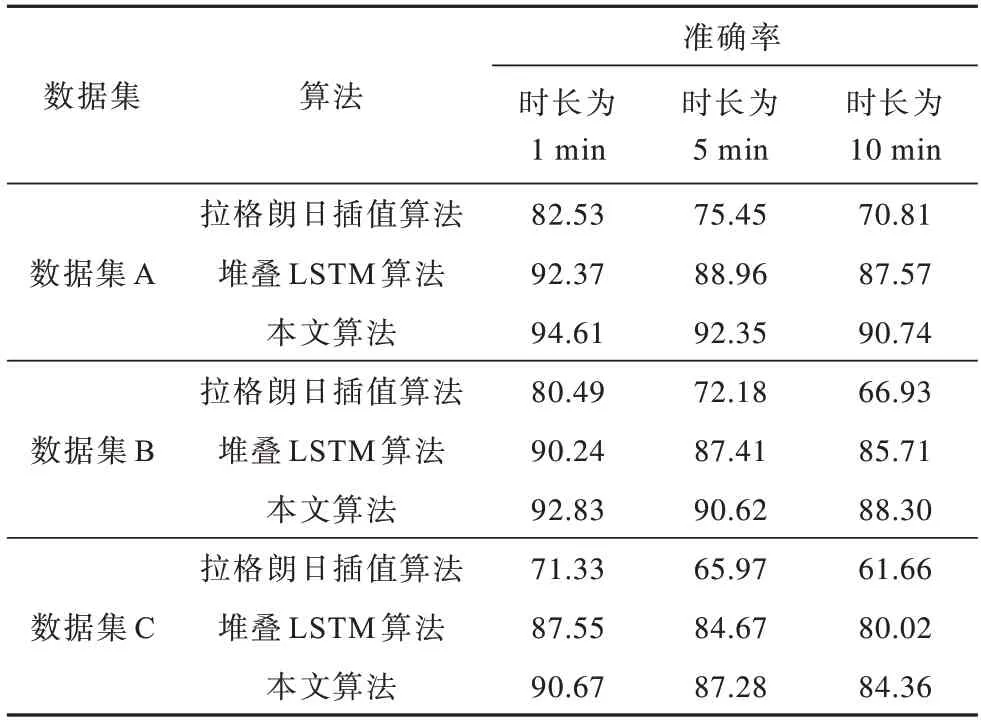
表2 不同算法在不同時長下預測數據塊的準確率對比Table 2 Comparison of accuracy of algorithm prediction data blocks in different time periods %
此外,本文取35 frame/s左右的平均幀率預測采樣部分位置坐標的X和Y分量,對比使用TCN和LSTM網絡預測位置坐標的效果,TCN 網絡的參數設置nb_filters=64,kernel_size=3,殘差塊中使用relu 激活函數,時間步長選取20。迭代20次后得到的擬合結果如圖11所示。在本文坐標數據集中,TCN、LSTM 網絡的預測精度分別為97.68%、96.92%。由圖11 可以看出,TCN 網絡在X、Y坐標分量上的預測精度比LSTM 網絡稍好,說明其在本文預測視點的任務中是有效的,有利于后續數據調度加載的準確性。
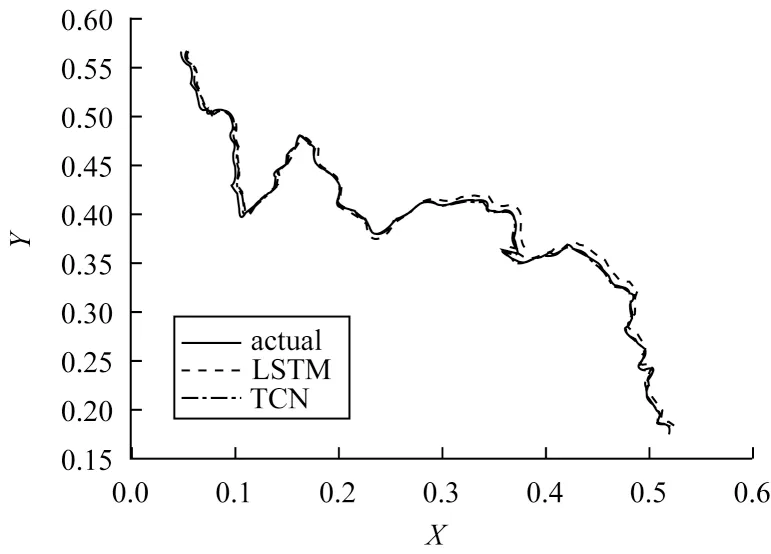
圖11 不同網絡的擬合結果對比曲線Fig.11 Comparison curve of fitting results of different networks
為測試步長對預測結果的影響,在平均幀率不變的情況下,分別設置步長為10、20、30,并隨機改變攝像機的位置和方位,使視點保持勻速運動持續10 min,同時為了避免不同平均幀率實驗的干擾,本文選擇24、48 和96 frame/s 的平均幀率進行非同步長計算和對比預測錯誤率,結果如圖12 所示。
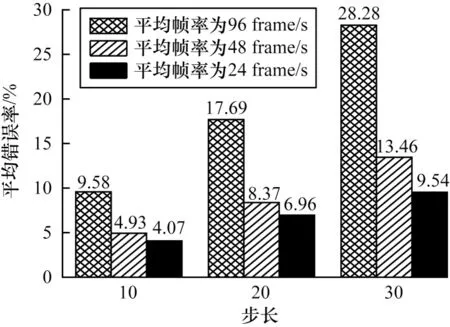
圖12 不同步長對預測準確率的影響Fig.12 Influence of asynchronous length on prediction accuracy
由圖12 可知,誤差會隨著步長增加而增大,但步長越小,預測精度相對越低,因此可以通過調節步長參數來達到提高預測準確性的目的。
5.2.3 對數據加載渲染的評估
為測試本文算法的穩定性,選擇60 幀采樣點作為X軸分量,分別在A、B、C 數據集上比較無預測算法(即在本文算法基礎上去除視點運動軌跡預測模塊的算法)與本文算法的幀率,結果如圖13 所示。由圖13 可知,在A 組數據集上,即使數據量較小,幀率也能保持在50 frame/s 左右。在B、C 組數據集上采用本文算法的幀率,相比無預測算法來說,即使在數據規模較大時,幀率仍然相對較高且較穩定,這意味著渲染效果更加穩定平滑,能夠避免交互時產生波動。
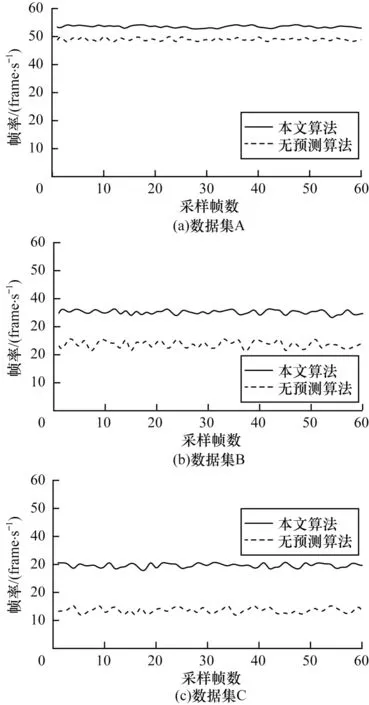
圖13 不同算法在3 組數據集下的幀率對比Fig.13 Comparison of frame rates of different algorithms under three sets of datasets
5.2.4 對整體性能的評估
為整體評估算法,將本文的VDEC-HRT、OCT、HRT、KHRT 分別與基于TCN 和雙層視錐體裁剪的調度模型(Scheduling Model Based on TCN and Double-Layer Visual Cone Clipping,TDVSM)算法進行組合,并測試各算法組合的整體交互性能。以B 組數據為例,每隔10 片圖像對地震數據進行切片,并記錄各算法查詢切片的時間,結果如圖14 所示。可以看出,與其他算法相比,本文算法查詢切片的時間明顯減少。
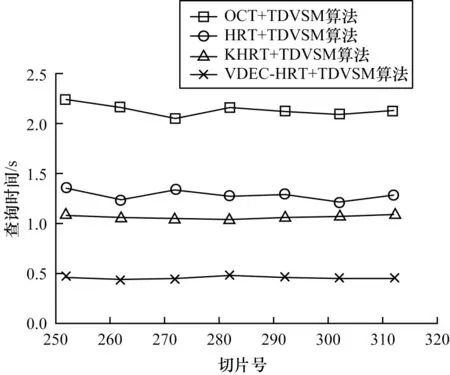
圖14 不同算法查詢切片的時間對比Fig.14 Comparison of query slice time of different algorithms
最后,本文對系統的整體顯示效果進行測試,系統平臺設置有不同顯示模式下的渲染效果,圖15 是體數據顯示的藍白紅模式(彩色效果見《計算機工程》官網HTML 版),圖16 是地震數據沿不同測線方向切片顯示效果(彩色效果見《計算機工程》官網HTML 版)。在運行觀測實際的地震數據時,由圖15和圖16 可以看出,本文系統平臺能夠高質量地描繪出地震體數據的內部結構和信息。
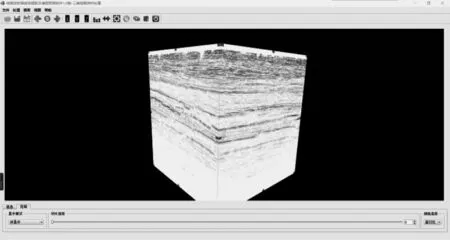
圖15 地震體數據顯示效果Fig.15 Display effect of seismic body data

圖16 地震數據沿不同測線方向切片的顯示效果Fig.16 Effect of slice display of seismic data along different survey lines
6 結束語
針對海量地震數據體繪制在集中載入時存在畫面顯示延遲和卡頓的問題,本文提出一種快速三維可視化算法。在HRT 結構的基礎上通過變分深度聚類改善節點數據因分布不均造成的空間重疊問題,提高數據索引的效率。使用時序卷積模型預測視點的運動軌跡,并與雙層視錐體裁剪算法相結合,以更精確地將數據提前載入內存等待渲染,避免畫面顯示延遲,提高渲染速度。實驗結果表明,本文算法相較于OCT、HRT、KHRT 等算法的查詢時間均有所減少,且渲染幀率波動較為穩定平滑,能夠實現海量地震數據的快速三維可視化。下一步將使用其他類型的大規模數據集對本文算法進行測試,嘗試采用wassterient 距離代替KL 散度,并在視點預測模塊中引入注意力機制,從而提高圖像質量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
