汽車智能座艙遺留物品檢測
2022-12-28 08:04:30王興寶雷琴輝胡佳睿
汽車電器 2022年11期
王興寶, 雷琴輝, 李 韜, 胡佳睿
(1.科大訊飛股份有限公司智能汽車事業部, 安徽 合肥 230088;2.武漢大學測繪遙感信息工程國家重點實驗室, 湖北 武漢 430071)
車內遺留物品檢測是智能座艙系統的重要組成部分。如果能及時對車主遺留的貴重物品在車艙進行提示或者警告,不僅能避免車主后續回來拿東西的麻煩,也能降低被破窗盜竊風險,還可以有效提升車主的用車體驗,也是車廠賣車的一大亮點。
1 目標檢測技術概述
1.1 目標檢測的定義
目標檢測的任務是識別圖像中出現的物體的類別以及對應物體的位置。物體是圖像中存在的物體對象,但是需要檢測哪些物體需要根據具體任務的需求來確定。例如智能座艙遺留物品定義為手機、錢包、pad、筆記本電腦和背包這5類,對應的目標檢測任務只需要檢測出該5類物品,如果檢出其他類型的物品,則被定義為虛警。
目標檢測的位置信息一般分為兩種格式:極坐標表示和中心點坐標表示。
1) 極坐標表示:(xmin,ymin,xmax,ymax),其中xmin,ymin代表目標框坐標的最小值,xmax,ymax代表目標框坐標的最大值。
2) 中心點坐標:(x_center,y_center,w,h),其中,x_center、y_center為目標檢測框的中心點坐標,w、h為目標檢測框的寬、高。
1.2 目標檢測算法的種類
1.2.1 Two-Stage目標檢測
Two-Stage目標檢測是基于區域的目標檢測算法,比較有代表性的算法有R-CNN[1]、SPP-Net[2]、Fast-R-CNN[3]等。該類方法首先需要得到候選區域,然后進行分類與回歸的預測,具有較高的檢測準確度,尤其對小目標的檢測。但是由于需要事先獲得候選區域,其效率不如單階段目標檢測。
1.2.2 One-Stage目標檢測
One-Stage目標檢測算法不需要首先獲得提議區域,直接產生物體的類別概率和位置信息,因此有著更快的檢測速度并且更容易部署。比較典型的算法如YOLO[4]、SSD[5]、YOLOv2[6]、YOLOv3[7]、Retina-Net[8]等。
2 智能座艙遺留物品檢測
首先將圖片的數據格式轉換成HSV格式,通過設定HSV域的閾值抽取圖片的紅分量,如圖1所示。

圖1 抽取紅分量
根據紅分量的比例可將整體數據集分成3個域,如圖2所示,分別為Normal(圖2a)、Gray(圖2b)、Red(圖2c)。

圖2 根據紅分量的比例可將整體數據集分成3個域
2.1 域內外類別分布不均衡
對采集回來的數據進行分析,我們發現樣本的域內域外數量分布很不均衡,如圖3所示。對于域內樣本,如圖3a所示,包含pad的樣本十分稀少。對于域間樣本分布,發現Gray域的樣本占了多數。域間類別數量分布如圖3b所示。

圖3 樣本域內域外類別數量分布情況
2.2 目標尺度分布不均衡
數據小目標占比較多,其中phone全部為小目標,packsack中超過一半也為小目標,總體78%為小目標,如圖4所示。
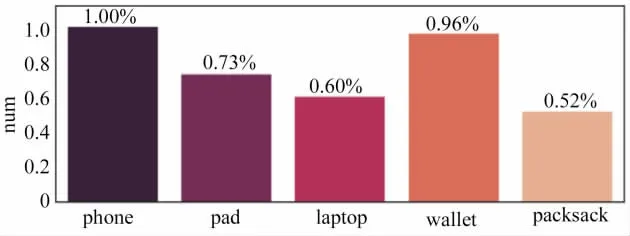
圖4 小目標數量分布
數據分布的特殊性需要結合特定的策略進行優化。下文中,將介紹算法設計以及針對數據分布的難點使用的優化方案。
3 算法主體架構
3.1 基線模型
基線模型選擇anchor base架構,通過RPN[3]生成高品質候選框,通過ROIPooling[3]提取固定大小的特征,最后使用Cascade級聯head逐步提高邊框的預測品質。Cascade RCNN示意圖如圖5所示。

圖5 Cascade RCNN示意圖
在RPN階段,我們采用Global Context[9]策略,如圖6所示。通過加入全局范圍的pooling特征,幫助后續的分類和回歸。

圖6 全局語境方法
3.2 CBNet+Swin Transformer
如圖7所示,CBNet[10]通過組合復用多個backbone的方式增強對backbone和fpn部分的特征提取,可有效提高檢測精度。本文使用Swin Transformer作為網絡主干。
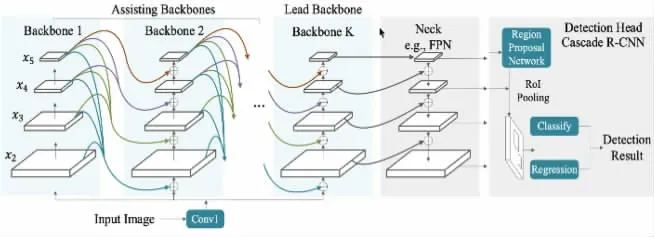
圖7 CBNet結構
如圖8所示,Swin Transformer[11]的設計非常巧妙,具有創新又緊扣CNN的優點,充分考慮的CNN的位移不變性,尺寸不變性,感受野與層次的關系,分階段降低分辨率增加通道數等特點,相對于CNN結構每個layer看到的區域更大,比CNN中的padding、pool等有著明顯的優勢。
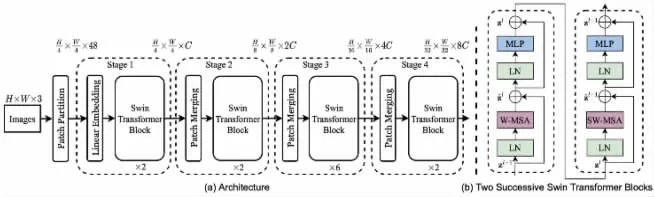
圖8 Swin Trainsformer
3.3 YoloX
YoloX[12]網絡,屬于Anchor Free架構,如圖9所示,使用darknet作為backbone,并采用PAPN特征金字塔增強對不同layer特征的提取。
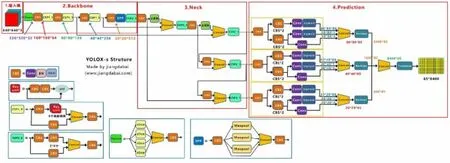
圖9 YoloX網絡結構
YoloX網絡的頭部采用decouple解耦設計,將分類任務、邊框回歸任務、前景檢測任務采用單獨分支進行特征增強,加速收斂的同時可有效提升精度。同時,YoloX采用SimOTA樣本分配策略,將單階段的候選框依據前景和分類loss進行粗篩,再根據動態正樣本排序策略獲得高品質的正樣本。圖10為SimOTA標簽分配策略。

圖10 SimOTA標簽分配策略
3.4 模型融合
模型融合策略包括兩個部分:WBF和NMS。WBF[13](Weighted boxes fusion),該策略重點是融合,根據較為準確的框來獲得更加準確的框,分段的依據是框置信度在0.3以上。NMS[14]對框進行篩選,去掉大量不準確的框,獲得較為準確的框。分段依據是框的置信度在0.3以下。模型融合策略如圖11所示。
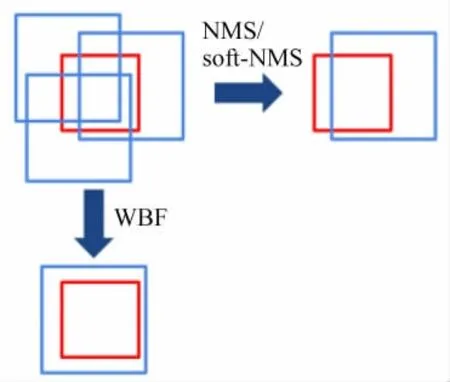
圖11 模型融合策略
4 難點問題解決方案
4.1 域內不均衡和域間分布不均衡
針對域內和域間分布不均衡問題,我們使用軟均衡采樣策略來解決。
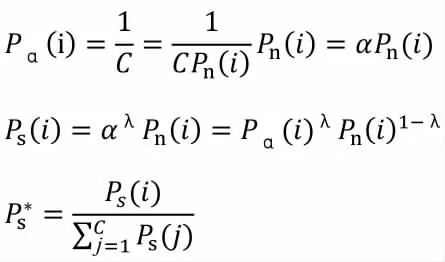
經過軟均衡策略后,域間和域類樣本數量分布更加平衡,軟均衡采樣效果如圖12所示。

圖12 軟均衡采樣效果
4.2 小目標識別
為了優化小目標識別問題,我們采用馬賽克增強[15]和SoftNMS[16]策略。
如圖13所示,馬賽克數據增強將4張訓練圖像按一定比例組合成1張,豐富了檢測數據集,增加了很多小目標,有效提升模型對小目標的檢測能力。

圖13 馬賽克增強
Soft-NMS將重疊度大于閾值的其他檢測框不會直接刪除,采用一個函數來衰減這些檢測框的置信度,可以一定程度避免小目標被刪除。其算法流程如下。
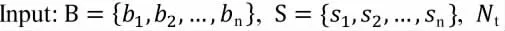
其中B是檢測框集合,S是檢測框對應的得分,Nt為NMS閾值。

4.3 過擬合
由于實車場景可以采集的數據比較少,這樣會導致模型過擬合。針對模型過擬合問題,在YoloX的訓練過程中,我們依次嘗試了AutoAug V1、AutoAug V2、AutoAug V3,對比詳情如圖14所示。
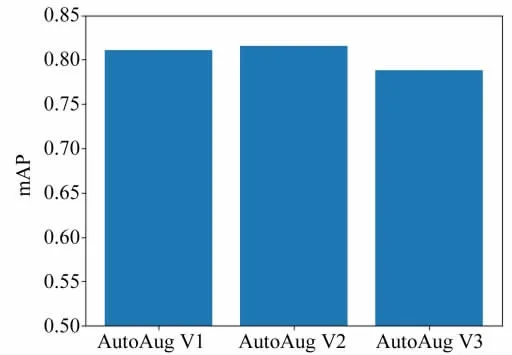
圖14 AutoAug效果對比
可見,AutoAug V2在我們的任務中表現較好,達到了0.816的mAP。AutoAug V2參數配置如圖15所示。
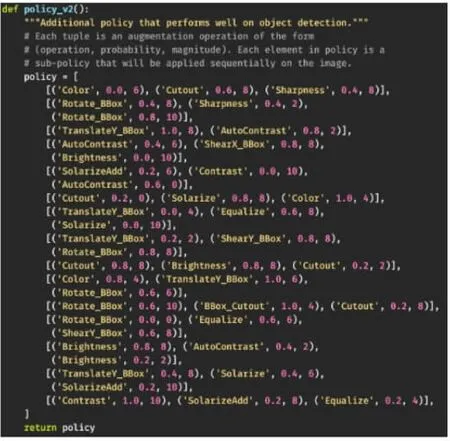
圖15 AutoAug V2參數配置
除此之外,我們還采用gridmask[17]增廣策略強迫模型不擬合訓練集。具體效果將在實驗部分開展說明。
5 實驗
5.1 實驗環境和參數配置
以實車采集的2500張圖片作為測試集,1000張圖片作為訓練集。實驗中除了模型融合方案,都使用非極大抑制算法作為后處理方案,其交并比為0.5。實驗的評估指標選用平均精度均值(mean average precision,mAP)。
實驗所用的GPU型號為NVDIA Tesla V100,使用pytorch以及mmdetecion工具包構建目標檢測模型。
5.2 對比實驗
以Cascade RCNN作為基線方案,為了讓基線方案有效檢測出小目標,其設定的訓練尺度比較大,分別為4096×800和4096×1408。在訓練過程中,將batch_size設定為24,初始學習率為0.001,采取余弦退火的方式更新學習率,使用adamW作為優化器。表1給出了不同模型和trick組合情況下的檢測效果對比。
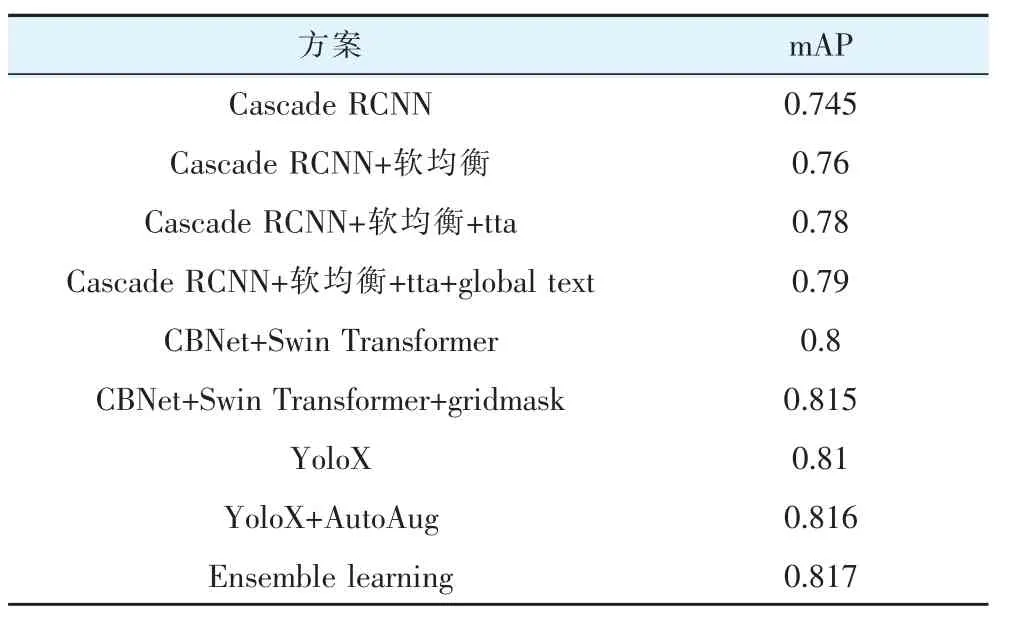
表1 模型效果對比
可以看出,Cascade RCNN作為基線其在測試集的最優mAP為0.745,接著加入軟均衡采樣策略以及樣本擴充方法使mAP上升到0.76。在此基礎上使用TTA(Test-Time Augmentation,測試時數據增強),達到了0.78,接著應用global context算法使效果進一步提升達到0.79,和基線對比相對提升17.6%。可見,我們提出的軟均衡策略以及引入global text對檢測效果有著明顯的促進作用。
對于單階段檢測器,通過結合CBNetV2和Swin Transformer,可以使模型效果直接達到0.8,在此基礎上,我們通過引入gridmask算法使效果進一步提升,使mAP達到了0.815,和基線對比相對提升27.4%。
由于我們最終方案是集成學習,因此還訓練了YoloX,其訓練尺度選擇1280,推理尺度分別為1024、1280、1408,并在模型推理環節使用測試時增強。將原始圖片進行3個尺度的flip,分別進行推理,再對多個結果進行合并,最終得到最優結果為0.81。接著我們通過在訓練過程中引入AutoAug V2,使YoloX的檢測結果進一步提升,達到0.816。
為了進一步提升檢測效果以及模型魯棒性,使用模型融合策略對以上3種模型進行融合,融合過程采用上文提及的WBF+NMS策略,最終達到最優效果0.817,并且比單模型有著更強的魯棒性。
6 總結與展望
本文針對車載場景的遺留物品檢測任務,進行深入數據分析,根據車載場景圖像數據的難點提出了相應的解決方案,有效解決了數據分布不均衡問題以及小目標檢測的挑戰。
實際車內貴重物品檢測場景中除了訓練集中的手機、平板、筆記本電腦、錢包、背包5類外,往往存在手表、手環、項鏈、戒指等未知類別的樣本,這類樣本的檢測屬于FSD(Few Shot Objection) 或者ZSD(Zero Shot Objection)。端側推理中基于攝像頭可以獲取視頻流,可以基于連續幀的特征來增加遺落目標的前景置信度,從而提高整體的檢測效果。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年12期)2021-11-30 02:58:01
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
數學大世界(2018年1期)2018-04-12 05:39:14
中華詩詞(2018年11期)2018-03-26 06:41:34
