大數據分析技術在金融監管平臺中的作用
2022-12-28 11:20:52唐靜
中國新技術新產品 2022年19期
唐 靜
(湖南環境生物職業技術學院,湖南 衡陽 421005)
0 引言
在金融科技不斷進步和發展的形勢下,許多新的金融形態應運而生[1]。與此同時,各種跨境、跨行業的金融產品層出不窮,但是在其發展過程中也產生了各種金融風險。如何正確應對金融科技帶來的新的監管挑戰,也逐漸引起了世界各國金融監管機構的關注。鑒于我國單一化的金融業監管、金融科技自身的特點以及現行法律法規的滯后性,現行的監管模式并不能完全遏制金融犯罪。在現實社會中,第三方支付機構的監管機制不完善,“洗黑錢”“套現”等風險依然存在。在目前的金融科技的監管中,監督主體雖然明確,但在實際的監督活動中,“真空監督”的現象也時有發生。在金融科技不斷進步之下,傳統金融正逐漸向無國界金融發展。所以,如何保證我國金融科技創新能力繼續走在世界前列,并根據金融科技自身特點構建一個適時、有效的監管模式,是目前我國金融科技發展的最大瓶頸。各國應當加強金融科技監管合作,用科技監管科技,進而解決金融科技監管的滯后問題。
1 大數據分析技術在金融監管平臺的應用研究
1.1 大數據分析研究意義
科技不僅改變了人們從購物到社交的方式,也重塑了金融服務業。在過去的幾年里,一些創新型金融公司競相出現,利用互聯網技術幫助人們找到更多的投資機會、方便了人們的支付手段,甚至讓小額貸款也變得容易了很多。新金融技術的發展不得不歸因于個人和企業的大數據爆發,人工智能、計算能力、密碼學以及互聯網的普及[2]。這些技術之間有強大的互補性,因此也帶來了許多新的應用,涉及支付、融資、資產管理、保險和咨詢等服務。隨著新大數據分析的發展,監管模式的推陳出新,對中國的金融行業監管及風險控制具有現實意義。
1.2 Python語言的使用
作為一種高級計算機程序設計語言,Python的優點是可以完成以下工作任務,見表1。

表1 Python的工作任務以及優點
1.3 金融監管平臺大數據處理算法
1.3.1 隨機森林算法
隨機森林是包括多棵決策樹,可以用來執行回歸和分類任務的機器學習算法[3]。其輸出類別是由多棵決策樹的輸出類別的眾數決定的。
1.3.2 隨機森林模型構建原理
用N表示樣本個數[4],M表示特征個數。從容量為N的原樣本集中有放回地進行重復抽樣,每次抽取的樣本容量也都為N,抽樣N次,形成N個訓練集。這樣每次抽樣時原樣本集中數據未被抽中的概率如公式(1)所示。

當N很大時,1/e為概率值,趨于0.368,如公式(2)所示。

式中:1/e為固定值0.368,e為無限不循環小數。
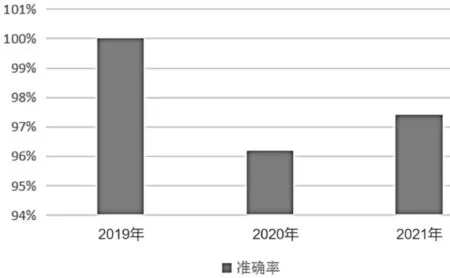
這表示每次抽樣時,原樣本集中的數據有大概37%的樣本不會被抽中,這些數據被稱為袋外數據。未被抽中的數據集可直接作為測試集,用于測試模型的預測精度。然后按一定比例確定特征數(通常取總特征數的平方根),輸入k(k 訓練完成形成N棵決策樹,隨機森林模型最后輸出的分類結果由這N棵決策樹通過自己的分類結果進行簡單投票而決定。決策樹生成流程如圖1所示。 圖1 隨機森林中單個決策樹訓練過程 1.3.3 隨機森林收斂性的分析 隨機森林在數學上的定義可以表達為例如現有由h1(x),h2(x),…,hk(x)構成的隨機森林。邊際函數如公式(4)所示。 式中:mg(X,Y)為邊際函數;avk(I(hk(X)=j))為正確分類下得到的票數;為不正確分類的情況下得到的票數。 邊際函數表示的意思是,在正確分類的情況下得到的票數比在不正確分類情況下得到的票數多的程度。顯然,該函數越大,說明原分類器分類效果越可靠。泛化誤差PE*如公式(5)所示。 式中:X、Y為概率定義空間。 隨機森林邊緣函數如公式(6)所示。 式中:P(hk(X)=Y)為正確判斷的概率;為錯誤判斷的概率最大值。 每棵決策樹生成隨機森林時,總是有一個初始數據集和沒有被抽取的數據集Ok(x)。Q(x,yi)即如公式(7)所示。 式中:Q(x,yi)為x在Ok(x)中yj的比例,為正確分類的概率估計。由此可對隨機森林強度和相關性進行分析。 隨機森林強度如公式(8)所示。 式中:E為數學期望。 將公式(6)代入公式(7),所得如公式(9)所示。 式中:S為隨機森林強度;n為數量;Q(xi,y)為xi在Ok(x)中y的比例;(xi,j)為Q(xi,y)中的最大值。隨機森林相關度如公式(10)所示。 式中:pu為I(ku(xi)=y)的OBB估計;為I(ku(xi)=的OBB估計。 pu和的 計算如公式(11)、公式(12)所示。 式中:I為指示函數;ku(xi)=y為觀測的真實結果;ku(xi)為觀測的預測結果。 將公式(10)和公式(11)帶入公式(9),所得如公式(13)所示。 隨機森林的性能體現在其收斂程度、強度和相關程度[5]。收斂性在于決策樹的泛化誤差都收斂,出差會有上限,這說明隨機森林對未知事物具有良好的適應性,不會造成很大的誤差,也不易造成過擬合。 該文實證過程中采取的數據均來自國泰安CSMAR數據庫。行業的劃分以證監會的分類為標準,選取了醫藥制造業中的221家公司。采用其2020—2022年3年的22個財務指標數據為研究對象。利用Python語言建立隨機森林模型。 1.4.1 模型構建及操作過程 導入數據:將數據集導入Rstudio; 在Rstudio中觀察導入的數據是否正常:View(rdata); 將Rstudio的儲存路徑更改為D盤下的r_working文件:setwd(“D:\r_working”)。 1.4.2 金融數據特征變量的分析 Mean Decrease Accuracy代表的是基于特征變量對準確率影響程度的大、小,數值越大,說明重要性越大。并基于此進行特征變量排序,見表2。 表2 數據特征標量的重要性大、小 1.4.3 數據隨機算法準確性分析 在rdata的數據范圍內,通過重復取樣,將樣本分為2種類型數據集,占比分別為70%和30%,即sample_set<-sample(2,nrow(rdata),replace=T,prob=c(0.7,0.3))。 將第一種類型數據集命名為訓練集train_set,即train_set<-rdata[sample_set==1,]。 將第二種類型數據集命名為測試集test_set,即test_set<-rdata[sample_set==2,]。 基于2019—2021年的醫藥制造業財務指標數據,建立的隨機森林模型的準確率分別為100%、96.2%和97.4%,如圖2所示,準確率都比較高,因此證明了該隨機森林模型對與財務質量和狀況的預測有較大的可行性。 圖2 數據隨機算法準確性分析圖 該系統爬取主要針對網站信息國泰安CSMAR數據庫進行數據爬取。為金融監管當局提供“非法集資”和“企業異常”風險敏感預警監測,監測數據和風險預警平臺。大型部門運用大數據技術,并基于多維全面量化數據。通過信息跟蹤、事件慣性突破建立一個特殊的風險識別模型。協助商業運營實體和政府監管機構進行篩選、預警重大財務、財務和法律風險。自2017年起,逐步升級大數據風險監測預警平臺,優化風險預警模型,將監管業務從金融辦延伸至財政廳、海關、住建部等政府機構和金融機構,打造完整的工業服務鏈。 在數據爬取時,需要導入Requests庫和BeautifulSoup庫函數。使用Requests抓取國泰安CSMAR數據庫,把要爬取的整個頁面抓取下來。使用BeautifulSoup中的find()和find_all()抓取需要的標簽內容。 如圖3所示,大數據模塊決策樹利用復雜網絡關系算法構建多維企業關聯圖,通過關系篩選、關聯操作和指標定位,快速、準確地挖掘企業風險線索,能夠有效地反映企業的真實行為和對相關業務決策的支持。該程序集數據、平臺和應用于一體。主要使用行業領先的大數據處理、分析和建模技術,真正恢復用戶的信用等級、行為特征和風險配置,并可自動對客戶進行風險評估,不需要銀行進行煩瑣的預貸盡職調查和貸后監控、預警,真正幫助銀行進行客戶探索、信貸審批、利率定價、信貸控制、監控和預警,并形成一個用于貸款、貸款和貸后流程的智能風控計劃。 圖3 大數據模塊決策樹風險分析圖 該文共選取了22個財務指標,利用醫藥制造業的財務數據,運用語言中的randomForest軟件包建立了隨機森林模型。根據建模后得到的結果分析得知,無論是對訓練集的分類還是對測試集的預測,構建得到的隨機森林模型都能很好地發揮作用,預測準確率都在96%以上。這說明可以采用該方法對公司的財務風險進行預測。大數據模塊決策樹風險結果有利于公司對其進行數理統計,進而規避風險。


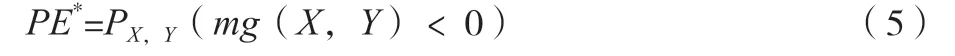

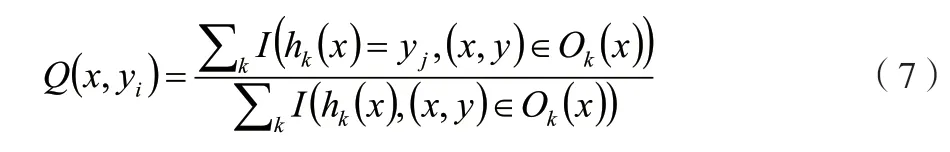
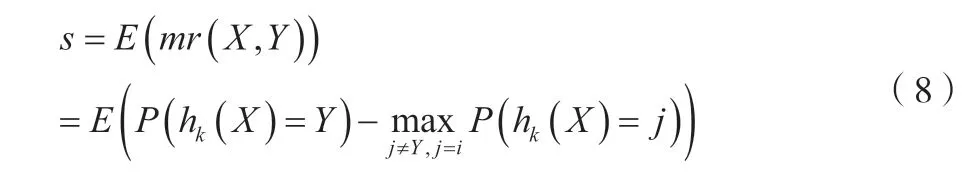

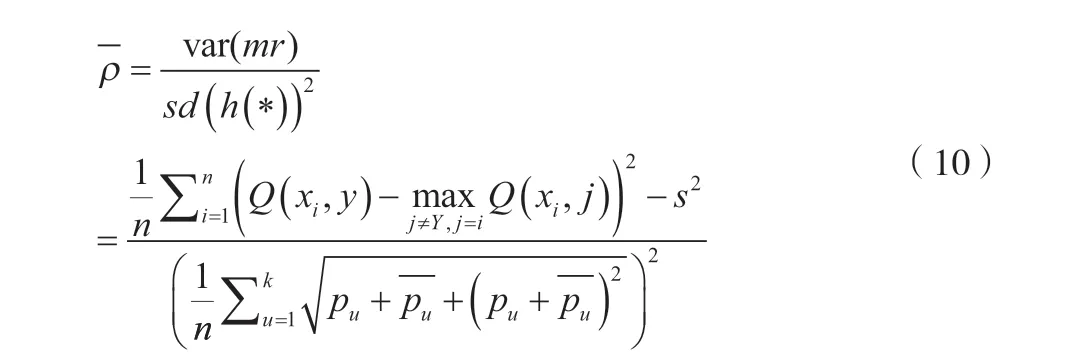


1.4 金融監管平臺大數據處理過程

2 大數據分析技術在金融監管平臺應用分析
2.1 金融監管平臺大數據處理分析
2.2 大數據模塊決策樹風險的分析

3 結語
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
金橋(2018年12期)2019-01-29 02:47:36
知識經濟·中國直銷(2018年12期)2018-12-29 12:22:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
少兒科學周刊·兒童版(2017年9期)2018-03-15 15:00:11
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
兒童故事畫報·發現號趣味百科(2017年4期)2017-06-30 12:41:53
兒童故事畫報·發現號趣味百科(2016年6期)2016-08-19 06:35:19
中國工程咨詢(2016年10期)2016-01-31 03:12:10
