大數(shù)據(jù)背景下的數(shù)據(jù)倉(cāng)庫(kù)架構(gòu)設(shè)計(jì)及實(shí)踐研究
2022-12-28 11:20:44賀曉松
中國(guó)新技術(shù)新產(chǎn)品 2022年19期
賀曉松
(重慶工程學(xué)院大數(shù)據(jù)與人工智能研究所,重慶 400037)
0 引言
21世紀(jì)初,隨著互聯(lián)網(wǎng)和移動(dòng)設(shè)備的普及,大數(shù)據(jù)時(shí)代已經(jīng)到來(lái)。早期的數(shù)據(jù)倉(cāng)庫(kù)主要以離線的批處理為主,目的是幫助傳統(tǒng)企業(yè)的業(yè)務(wù)決策者、管理者做一些業(yè)務(wù)決策,其業(yè)務(wù)決策周期比較長(zhǎng),數(shù)據(jù)量也比較小。隨著大數(shù)據(jù)技術(shù)的發(fā)展、整體算力的提升以及互聯(lián)網(wǎng)的發(fā)展,數(shù)據(jù)量已呈指數(shù)級(jí)增長(zhǎng),做決策的主體很大部分已轉(zhuǎn)變?yōu)橛?jì)算機(jī)算法,例如一些智能推薦場(chǎng)景等。所以這時(shí)的決策周期就由原來(lái)的天級(jí)要求提升到秒級(jí),決策時(shí)間是非常短的,會(huì)面對(duì)更多的需要實(shí)時(shí)數(shù)據(jù)處理的場(chǎng)景,例如實(shí)時(shí)的個(gè)性化推薦、廣告的場(chǎng)景,一些傳統(tǒng)企業(yè)已經(jīng)開(kāi)始實(shí)時(shí)監(jiān)控加工的產(chǎn)品是否有質(zhì)量問(wèn)題以及金融行業(yè)重度依賴(lài)的反作弊等。在該背景下,數(shù)據(jù)倉(cāng)庫(kù)也由傳統(tǒng)的離線數(shù)倉(cāng)轉(zhuǎn)變?yōu)閷?shí)時(shí)數(shù)倉(cāng),架構(gòu)設(shè)計(jì)也隨著時(shí)代和業(yè)務(wù)需求不斷演變和發(fā)展,以適應(yīng)增長(zhǎng)的數(shù)據(jù)處理和變化的業(yè)務(wù)需求。
1 數(shù)據(jù)倉(cāng)庫(kù)概述
1.1 數(shù)據(jù)倉(cāng)庫(kù)的定義
數(shù)據(jù)倉(cāng)庫(kù)(Data Warehouse)是面向主題的、集成的、相對(duì)穩(wěn)定的并反應(yīng)歷史變化的數(shù)據(jù)集合[1],數(shù)倉(cāng)中的數(shù)據(jù)是有組織、有結(jié)構(gòu)的存儲(chǔ)數(shù)據(jù)集合,用于支持管理、決策過(guò)程。其中面向主題是指數(shù)據(jù)倉(cāng)庫(kù)是面向分析決策的,所以數(shù)據(jù)經(jīng)常按分析場(chǎng)景或者分析對(duì)象等主題形式來(lái)組織,這是與面向應(yīng)用進(jìn)行數(shù)據(jù)組織的傳統(tǒng)數(shù)據(jù)庫(kù)的最大區(qū)別。集成性是指通過(guò)對(duì)分散、獨(dú)立以及異構(gòu)的數(shù)據(jù)庫(kù)數(shù)據(jù)進(jìn)行抽取、清理、轉(zhuǎn)換和匯總,得到數(shù)據(jù)倉(cāng)庫(kù)的數(shù)據(jù)[2],這樣就保證了數(shù)據(jù)倉(cāng)庫(kù)內(nèi)的數(shù)據(jù)針對(duì)整個(gè)企業(yè)不同業(yè)務(wù)的數(shù)據(jù)口徑的一致性。
1.2 數(shù)據(jù)倉(cāng)庫(kù)的分層
從數(shù)據(jù)源的采集到多層清洗加工的過(guò)程中,數(shù)據(jù)倉(cāng)庫(kù)形成了一套規(guī)范的數(shù)據(jù)邏輯分層,一般分為4層[3],如圖1所示。分層的核心思想就是解耦,即將一個(gè)復(fù)雜的任務(wù)分解成多個(gè)步驟來(lái)完成,每層只處理單一的步驟,將復(fù)雜問(wèn)題簡(jiǎn)單化。另外通過(guò)數(shù)據(jù)分層,開(kāi)發(fā)通用的中間層,提供統(tǒng)一的數(shù)據(jù)出口,在規(guī)范數(shù)據(jù)的同時(shí)最大程度地減少重復(fù)開(kāi)發(fā)。
圖1中的各層說(shuō)明如下。

圖1 數(shù)據(jù)倉(cāng)庫(kù)分層圖
ODS層:全稱(chēng)為原始數(shù)據(jù)層(Operation Data Store)。該層對(duì)從數(shù)據(jù)源采集的原始數(shù)據(jù)進(jìn)行原樣存儲(chǔ)。
DWD層:全稱(chēng)為明細(xì)數(shù)據(jù)層(Data Warehouse Detail)。該層對(duì)ODS層的數(shù)據(jù)進(jìn)行清洗,主要解決一些數(shù)據(jù)質(zhì)量問(wèn)題。
DWS層:全稱(chēng)為服務(wù)數(shù)據(jù)層(Data Warehouse Service)。該層對(duì)DWD層的數(shù)據(jù)進(jìn)行輕度匯總,生成一系列的中間表,提升公共指標(biāo)的復(fù)用性,減少重復(fù)加工,并構(gòu)建出一些寬表,供后續(xù)進(jìn)行業(yè)務(wù)查詢(xún)。
App層:全稱(chēng)為應(yīng)用數(shù)據(jù)層(Application)。DWD、DWS層數(shù)據(jù)統(tǒng)計(jì)結(jié)果會(huì)存儲(chǔ)在App層。App層數(shù)據(jù)可以直接對(duì)外提供查詢(xún),一般會(huì)將App層的數(shù)據(jù)導(dǎo)入MySQL中供BI系統(tǒng)使用,可提供報(bào)表展示、數(shù)據(jù)監(jiān)控及其他功能。
2 數(shù)倉(cāng)平臺(tái)架構(gòu)設(shè)計(jì)
一個(gè)完整的數(shù)據(jù)倉(cāng)庫(kù)系統(tǒng)通常包括數(shù)據(jù)源、數(shù)據(jù)存儲(chǔ)與管理以及數(shù)據(jù)服務(wù),如圖2所示。
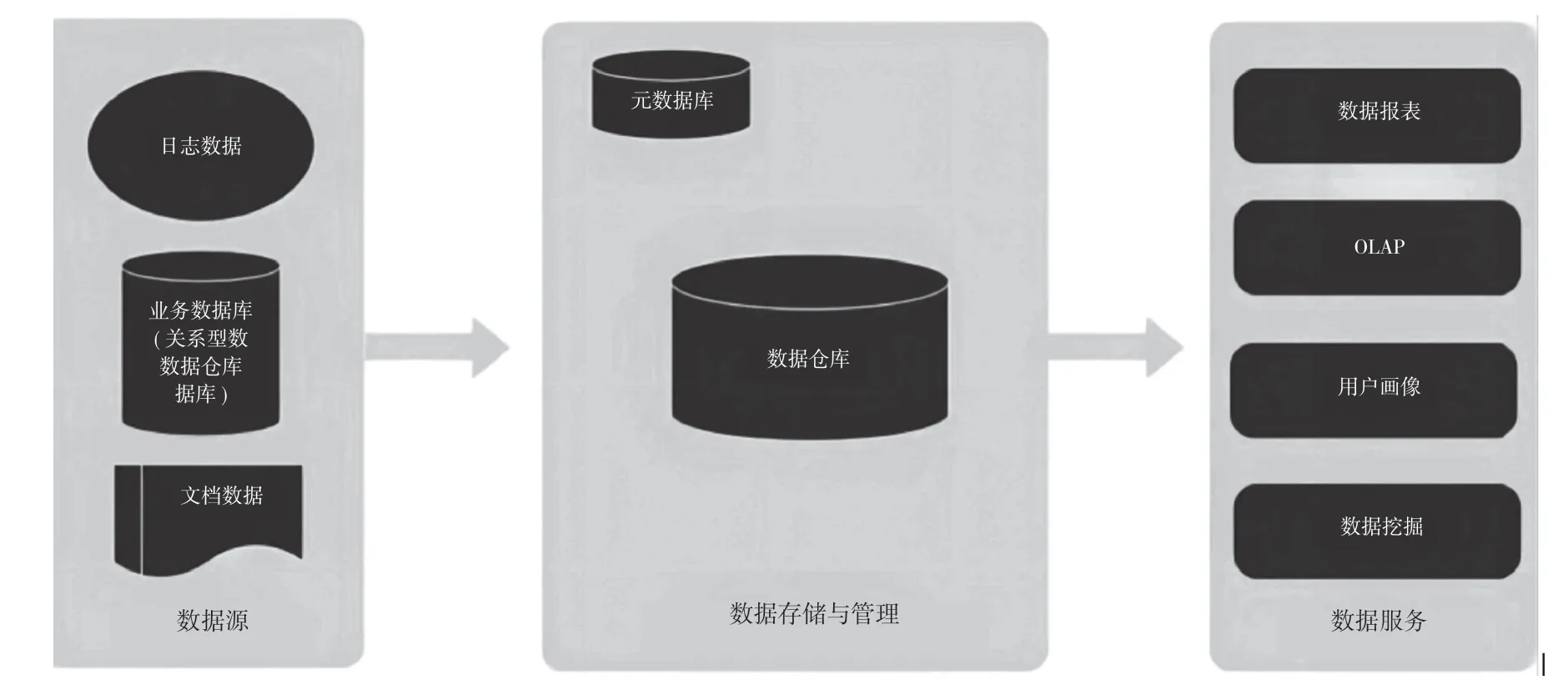
圖2 數(shù)據(jù)倉(cāng)庫(kù)架構(gòu)
數(shù)據(jù)源部分包括企業(yè)中的各種日志數(shù)據(jù)、業(yè)務(wù)數(shù)據(jù)及一些文檔數(shù)據(jù),數(shù)據(jù)倉(cāng)庫(kù)就是基于這些數(shù)據(jù)構(gòu)建的。構(gòu)建好的數(shù)據(jù)倉(cāng)庫(kù)可以為多種業(yè)務(wù)提供數(shù)據(jù)支撐,例如數(shù)據(jù)報(bào)表、OLAP數(shù)據(jù)分析、用戶(hù)畫(huà)像以及數(shù)據(jù)挖掘都需要使用數(shù)據(jù)倉(cāng)庫(kù)的數(shù)據(jù)。
2.1 離線數(shù)據(jù)倉(cāng)庫(kù)架構(gòu)
早期數(shù)據(jù)倉(cāng)庫(kù)建設(shè)理論基于CIF架構(gòu)建設(shè)方案,數(shù)據(jù)是構(gòu)建在關(guān)系型數(shù)據(jù)庫(kù)之上的。但隨著大數(shù)據(jù)時(shí)代的來(lái)臨以及企業(yè)數(shù)據(jù)量的暴增,關(guān)系型數(shù)據(jù)庫(kù)已經(jīng)無(wú)法支撐起大規(guī)模數(shù)據(jù)集的存儲(chǔ)和分析,其性能已成為瓶頸。對(duì)此,經(jīng)典數(shù)倉(cāng)中的傳統(tǒng)工具便被以Hadoop為代表的大數(shù)據(jù)技術(shù)棧組件替代,該架構(gòu)稱(chēng)為離線大數(shù)據(jù)架構(gòu),如圖3所示。

圖3 離線數(shù)據(jù)倉(cāng)庫(kù)架構(gòu)
在離線大數(shù)據(jù)架構(gòu)中,常見(jiàn)的是使用Hive進(jìn)行構(gòu)建,并對(duì)數(shù)據(jù)進(jìn)行分層處理。當(dāng)然,也可以使用Impala進(jìn)一步提高Hive的計(jì)算性能。對(duì)Hive SQL無(wú)法處理的復(fù)雜業(yè)務(wù)邏輯,則可以考慮使用自定義SQL函數(shù),或者M(jìn)apReduce、Spark代碼來(lái)解決。
2.2 Lambda架構(gòu)
隨著實(shí)時(shí)數(shù)據(jù)處理的業(yè)務(wù)場(chǎng)景逐漸增多,架構(gòu)層面逐漸需要滿(mǎn)足一些實(shí)時(shí)性要求。Twitter工程師南森·馬茨(Nathan Marz)在2011年提出了一個(gè)實(shí)時(shí)大數(shù)據(jù)處理框架——Lambda架構(gòu),用于滿(mǎn)足大數(shù)據(jù)批量離線處理和實(shí)時(shí)數(shù)據(jù)處理的需求,如圖4所示。為了計(jì)算一些實(shí)時(shí)指標(biāo),Lambda架構(gòu)對(duì)數(shù)據(jù)源進(jìn)行了重構(gòu),引入消息隊(duì)列(如Kafka)來(lái)處理數(shù)據(jù)流,實(shí)時(shí)鏈路訂閱消息隊(duì)列,對(duì)消息流數(shù)據(jù)進(jìn)行處理,并將結(jié)果推送到下游數(shù)據(jù)服務(wù)。

圖4 Lambda架構(gòu)
Lambda架構(gòu)中的數(shù)據(jù)從底層的數(shù)據(jù)源開(kāi)始收集數(shù)據(jù)組件(例如Flume、Maxwell和Canal等),并將數(shù)據(jù)分成2條鏈路進(jìn)行計(jì)算。批量數(shù)據(jù)處理離線計(jì)算平臺(tái)(例如MapReduce、Hive和Spark SQL)可計(jì)算T+1的相關(guān)業(yè)務(wù)指標(biāo),這些指標(biāo)需要隔日才能看見(jiàn),以保證數(shù)據(jù)的有效性和準(zhǔn)確性;流式計(jì)算平臺(tái)(例如Flink、Spark Streaming)可計(jì)算實(shí)時(shí)的一些指標(biāo),以保證數(shù)據(jù)的實(shí)時(shí)性。
雖然Lambda架構(gòu)可滿(mǎn)足實(shí)時(shí)性要求,但在實(shí)際應(yīng)用時(shí)存在需要更多開(kāi)發(fā)和維護(hù)工作不足的問(wèn)題。一則需要開(kāi)發(fā)2套代碼來(lái)處理相同的需求,使開(kāi)發(fā)變得更加困難(在批處理和流處理引擎上處理相同的需求,針對(duì)單獨(dú)的數(shù)據(jù)測(cè)試應(yīng)確保結(jié)果一致),且不利于后續(xù)維護(hù)。二則實(shí)時(shí)與離線計(jì)算走2條鏈路容易導(dǎo)致數(shù)據(jù)口徑不一致。
2.3 Kappa架構(gòu)
隨著流式處理引擎(如Flink等)的不斷完善與流處理相關(guān)技術(shù)(例如Kafka、ClickHouse)的發(fā)展,針對(duì)Lambda架構(gòu)需要維護(hù)2套系統(tǒng)、運(yùn)維成本高等缺點(diǎn),LinkedIn的Jay Kreps提出了Kappa架構(gòu),如圖5所示。

圖5 Kappa架構(gòu)
Flink SQL提供的“Hive數(shù)倉(cāng)同步”功能為批流一體化數(shù)據(jù)倉(cāng)庫(kù)的實(shí)現(xiàn)提供了底層技術(shù)支持,所有的數(shù)據(jù)加工邏輯由Flink SQL以實(shí)時(shí)計(jì)算模式執(zhí)行。數(shù)據(jù)寫(xiě)入端會(huì)自動(dòng)將在ODS、DWD和DWS層已經(jīng)加工好的數(shù)據(jù)實(shí)時(shí)回流到Hive表中,離線處理的計(jì)算層可以完全去掉,處理邏輯由Flink SQL統(tǒng)一維護(hù),離線層只需要使用回流的ODS、DWD和DWS層的表做進(jìn)一步即席查詢(xún)即可,這樣就不需要單獨(dú)維護(hù)離線計(jì)算任務(wù)了。
Kappa架構(gòu)在Lambda架構(gòu)的基礎(chǔ)上簡(jiǎn)化了離線數(shù)據(jù)倉(cāng)庫(kù)的內(nèi)容,構(gòu)建了批流一體化數(shù)據(jù)倉(cāng)庫(kù)。其核心思想是在Lambda架構(gòu)上去掉批處理鏈路,只留下單獨(dú)的流處理鏈路,通過(guò)消息隊(duì)列的數(shù)據(jù)保留功能來(lái)實(shí)現(xiàn)上游重放(回溯)功能,并使用同一套實(shí)時(shí)計(jì)算和批處理代碼,方便維護(hù)并統(tǒng)一了數(shù)據(jù)口徑,降低了開(kāi)發(fā)和運(yùn)維成本。
2.4 湖倉(cāng)一體架構(gòu)
Kappa架構(gòu)完全廢棄了批處理層,實(shí)現(xiàn)了批流一體,避免了冗余工作,并簡(jiǎn)化了技術(shù)棧。但因使用的消息隊(duì)列(例如Kafka)在存儲(chǔ)功能上不支持高效的數(shù)據(jù)回溯及數(shù)據(jù)更新,導(dǎo)致此架構(gòu)在實(shí)際落實(shí)過(guò)程中存在不足。
數(shù)據(jù)湖是一個(gè)存儲(chǔ)各種各樣原始格式數(shù)據(jù)的大型倉(cāng)庫(kù),通常是對(duì)象塊或者文件。數(shù)據(jù)湖側(cè)重于存儲(chǔ)的內(nèi)容,包括結(jié)構(gòu)化數(shù)據(jù)、半結(jié)構(gòu)化數(shù)據(jù)(CSV、日志、XML和JSON)、非結(jié)構(gòu)化數(shù)據(jù)(電子郵件、文檔和PDF)和二進(jìn)制數(shù)據(jù)(圖像、音頻和視頻)[4-5]。從實(shí)時(shí)數(shù)倉(cāng)的角度看,為了支持上層實(shí)時(shí)數(shù)倉(cāng)構(gòu)建,數(shù)據(jù)湖還具有Upsert操作高效、回溯能力強(qiáng)、支持Schema變更、支持ACID語(yǔ)義以及支持批流讀寫(xiě)的優(yōu)點(diǎn)。
2020年,Databricks提出了湖倉(cāng)一體(Lakehouse)架構(gòu),希望將數(shù)據(jù)湖(Data Lake)和數(shù)據(jù)倉(cāng)庫(kù)(Data Warehouse)進(jìn)行優(yōu)勢(shì)互補(bǔ),合二為一。在Databricks的描述中,Lakehouse是數(shù)據(jù)湖和數(shù)據(jù)倉(cāng)庫(kù)的混合體。一方面,它提供了處理結(jié)構(gòu)化程度較低的數(shù)據(jù)類(lèi)型的靈活性,如文本和圖像文件,這在數(shù)據(jù)科學(xué)和機(jī)器學(xué)習(xí)項(xiàng)目中較為常用。另一方面,它也借鑒了數(shù)據(jù)倉(cāng)庫(kù)設(shè)計(jì)的約束和規(guī)范,特別是在確保數(shù)據(jù)質(zhì)量和管理方面,面向業(yè)務(wù)實(shí)現(xiàn)了高并發(fā)、精準(zhǔn)化和高性能的歷史數(shù)據(jù)、實(shí)時(shí)數(shù)據(jù)的查詢(xún)服務(wù)。
將Kappa架構(gòu)中的Kafka消息隊(duì)列替換成數(shù)據(jù)湖存儲(chǔ)之后,該文得到了新一代的湖倉(cāng)一體架構(gòu),如圖6所示。

圖6 湖倉(cāng)一體架構(gòu)
具體來(lái)說(shuō),和使用消息隊(duì)列的Kappa架構(gòu)相比,湖倉(cāng)一體架構(gòu)具有如下優(yōu)點(diǎn):1)可以解決消息隊(duì)列存儲(chǔ)數(shù)據(jù)量少的問(wèn)題。無(wú)論數(shù)據(jù)湖底層存儲(chǔ)是使用Hadoop分布式文件系統(tǒng)(HDFS),還是使用亞馬遜AWS的對(duì)象存儲(chǔ)服務(wù)(S3)、阿里云的對(duì)象存儲(chǔ)服務(wù)(OSS),都能夠存放海量數(shù)據(jù)。2)數(shù)據(jù)倉(cāng)庫(kù)層(DW)數(shù)據(jù)支持OLAP查詢(xún)。目前大部分的OLAP引擎都支持HDFS和對(duì)象存儲(chǔ),只需做一些簡(jiǎn)單適配就可以與數(shù)據(jù)湖對(duì)接。3)批流基于一套存儲(chǔ),因此可以復(fù)用一套相同的數(shù)據(jù)血緣、數(shù)據(jù)質(zhì)量管理體系。4)支持Update/Upsert,而消息隊(duì)列(例如Kafka)一般只支持Append。實(shí)際場(chǎng)景中,DWS層的數(shù)據(jù)很多時(shí)候都需要更新,從DWD層到DWS層一般會(huì)根據(jù)時(shí)間粒度和維度進(jìn)行聚合,用于減少數(shù)據(jù)量,提升查詢(xún)性能。假如原始數(shù)據(jù)是秒級(jí)數(shù)據(jù),聚合窗口是1 min,那就有可能產(chǎn)生某些延遲數(shù)據(jù)經(jīng)過(guò)時(shí)間窗口聚合之后需要更新之前數(shù)據(jù)的需求。
3 基于Iceberg湖倉(cāng)一體架構(gòu)的電商數(shù)據(jù)分析平臺(tái)實(shí)踐
3.1 Iceberg技術(shù)棧
目前市面上有3個(gè)開(kāi)源的數(shù)據(jù)湖方案,分別是Databricks開(kāi)源(Delta Lake)、Uber 開(kāi)源(Apache Hudi)和Netflix開(kāi)源(Apache Iceberg)。其中Iceberg以自身獨(dú)特的優(yōu)勢(shì)被越來(lái)越多開(kāi)發(fā)者關(guān)注,其優(yōu)點(diǎn)如下:1)在架構(gòu)和實(shí)現(xiàn)上沒(méi)有綁定到某一特定引擎,具有通用的數(shù)據(jù)組織格式,利用此格式可以與不同引擎(Flink、Hive和Spark等)對(duì)接。2)擁有良好的架構(gòu)和開(kāi)放格式。與Hudi、Delta Lake相比,Iceberg的架構(gòu)實(shí)現(xiàn)更優(yōu)雅,同時(shí)對(duì)數(shù)據(jù)格式、類(lèi)型系統(tǒng)有完備的定義和可進(jìn)化的設(shè)計(jì)。3)在數(shù)據(jù)組織方式上充分考慮了對(duì)象存儲(chǔ)的特性,避免耗時(shí)的listing和rename操作,使其在基于對(duì)象存儲(chǔ)的數(shù)據(jù)湖架構(gòu)適配上更有優(yōu)勢(shì)。
3.2 項(xiàng)目架構(gòu)及數(shù)據(jù)分層
該項(xiàng)目使用Iceberg構(gòu)建“湖倉(cāng)一體”架構(gòu)的數(shù)據(jù)湖技術(shù)來(lái)實(shí)時(shí)和離線分析電商業(yè)務(wù)指標(biāo)。項(xiàng)目整體架構(gòu)圖如圖7所示。

圖7 項(xiàng)目架構(gòu)
項(xiàng)目中的數(shù)據(jù)源有2類(lèi),一是MySQL業(yè)務(wù)庫(kù)數(shù)據(jù),使用Flink CDC或Maxwell監(jiān)聽(tīng)mysql binlog日志,以實(shí)現(xiàn)數(shù)據(jù)實(shí)時(shí)同步至Kafka。另一類(lèi)是用戶(hù)日志數(shù)據(jù),通過(guò)Flume將數(shù)據(jù)采集到Kafka各自的topic中,通過(guò)Flink處理將業(yè)務(wù)和日志數(shù)據(jù)存儲(chǔ)在Iceberg-ODS層中。由于目前Flink基于Iceberg處理實(shí)時(shí)數(shù)據(jù)不能很好地保存數(shù)據(jù)消費(fèi)位置信息,因此這里同時(shí)將數(shù)據(jù)存儲(chǔ)在Kafka中,利用Flink消費(fèi)Kafka數(shù)據(jù)自動(dòng)維護(hù)offset的特性來(lái)保證程序停止重啟后消費(fèi)數(shù)據(jù)的正確性。整個(gè)架構(gòu)基于Iceberg構(gòu)建數(shù)據(jù)倉(cāng)庫(kù)分層,經(jīng)過(guò)Kafka處理數(shù)據(jù)并實(shí)時(shí)存儲(chǔ)在對(duì)應(yīng)的Iceberg分層中。實(shí)時(shí)數(shù)據(jù)結(jié)果經(jīng)過(guò)最后分析存儲(chǔ)在ClickHouse中,離線數(shù)據(jù)分析結(jié)果(直接從Iceberg-DWS層中獲取數(shù)據(jù)分析)存入MySQL中。Iceberg其他層供臨時(shí)性業(yè)務(wù)分析,最終ClickHouse和MySQL中的結(jié)果將通過(guò)可視化工具展示出來(lái)。
3.3 項(xiàng)目可視化
項(xiàng)目最終通過(guò)可視化工具Sugar BI實(shí)現(xiàn)實(shí)時(shí)瀏覽pv/uv分析、用戶(hù)積分指標(biāo)分析、用戶(hù)實(shí)時(shí)登錄信息分析、實(shí)時(shí)商品瀏覽信息分析等內(nèi)容指標(biāo)的可視化呈現(xiàn)。
4 結(jié)語(yǔ)
當(dāng)前,基于Hive的離線數(shù)據(jù)倉(cāng)庫(kù)架構(gòu)已經(jīng)非常成熟,隨著實(shí)時(shí)計(jì)算引擎的不斷發(fā)展以及業(yè)務(wù)對(duì)實(shí)時(shí)報(bào)表的產(chǎn)出需求的不斷膨脹,最近幾年業(yè)界一直在關(guān)注并探索實(shí)時(shí)數(shù)倉(cāng)建設(shè)。根據(jù)數(shù)倉(cāng)架構(gòu)演變過(guò)程,Lambda架構(gòu)中包括離線處理與實(shí)時(shí)處理2條鏈路,由于2條鏈路處理數(shù)據(jù)會(huì)引發(fā)數(shù)據(jù)不一致等問(wèn)題,因此發(fā)展出了Kappa架構(gòu)。Kappa架構(gòu)將2條鏈路合二為一,實(shí)現(xiàn)了批流一體,但Kappa架構(gòu)中的常用中間件如Kafka存在不支持update/upsert和無(wú)法支持高效的OLAP查詢(xún)等缺點(diǎn)。數(shù)據(jù)湖技術(shù)的出現(xiàn)使Kappa架構(gòu)實(shí)現(xiàn)批量數(shù)據(jù)和實(shí)時(shí)數(shù)據(jù)統(tǒng)一計(jì)算成為可能。數(shù)據(jù)湖技術(shù)可以將批量數(shù)據(jù)和實(shí)時(shí)數(shù)據(jù)統(tǒng)一存儲(chǔ)并統(tǒng)一處理計(jì)算,該文將離線數(shù)倉(cāng)中的數(shù)倉(cāng)和實(shí)時(shí)數(shù)倉(cāng)中的數(shù)倉(cāng)數(shù)據(jù)存儲(chǔ)統(tǒng)一合并到數(shù)據(jù)湖上,將Kappa架構(gòu)中的數(shù)倉(cāng)分層Kafka存儲(chǔ)替換成數(shù)據(jù)湖技術(shù)存儲(chǔ),以此實(shí)現(xiàn)了“湖倉(cāng)一體”的構(gòu)建。
 中國(guó)新技術(shù)新產(chǎn)品2022年19期
中國(guó)新技術(shù)新產(chǎn)品2022年19期
- 中國(guó)新技術(shù)新產(chǎn)品的其它文章
- 礦山法隧道小距離上跨既有盾構(gòu)區(qū)間安全防護(hù)技術(shù)研究
- 工業(yè)建筑群火災(zāi)報(bào)警系統(tǒng)環(huán)型結(jié)構(gòu)設(shè)計(jì)
- 基于DK算法的石化企業(yè)滅火救援路徑優(yōu)化技術(shù)
- 層次分析法(AHP)對(duì)發(fā)電企業(yè)安全生產(chǎn)風(fēng)險(xiǎn)評(píng)估的應(yīng)用研究
- 基于“云預(yù)算”的高校專(zhuān)項(xiàng)資金項(xiàng)目庫(kù)管理系統(tǒng)構(gòu)建的研究
- 基于CNN-BiLSTM-Attention的股價(jià)預(yù)測(cè)模型