基于深度學習的常見市場漁獲檢測分類算法研究
2022-12-28 11:20:42李克祥王國慶鄭國華潘海華周昌智
中國新技術新產品 2022年19期
關鍵詞:模型
李克祥 王國慶 鄭國華 潘海華 周昌智
(浙江索思科技有限公司,浙江 溫州 325000)
1 關鍵技術
1.1 遷移學習
傳統機器學習方法往往是針對特定任務創建數據訓練模型的,這也導致模型之間互相孤立、毫無聯系,訓練習得的內容并沒有延續下去。遷移學習是將在一個場景中獲得的知識經驗應用到新的場景中,以達到輔助學習的目的,遷移學習使模型之間可以傳遞學習內容,避免花費大量時間和資源重新標記數據、訓練模型[1]。遷移學習利用其他模型已經學習的知識來提高新模型的性能,節約模型訓練的計算資源,當數據稀缺或獲取成本高昂時,能夠利用更少的數據獲得穩定的模型,提高模型泛化能力和模型訓練效率。
1.2 預訓練網絡模型
預訓練模型(pre-trained model)一般是在規模足夠大的數據集下進行訓練而產生的,具備很多的參數量以及復雜的網絡結構,是為解決類似問題而創造的。對當前大部分的圖像識別處理預訓練模型來說,訓練的原始數據集一般可以通用,預訓練網絡學到的特征空間層次結構和權重不需要過多修改就可以應用到特定的新問題上,也就是所謂的微調(fine tune),是“遷移學習”的一種方式。預訓練模型使深度學習對處理小數據問題更有效,這也是深度學習的一個優勢[2]。
1.3 ResNet網絡模型
深度學習隨著網絡層數的加深,理論上模型的表達能力會逐漸提高,但是卷積神經網絡CNN到達一定的深度后,分類性能不再提高,反而導致網絡收斂變緩,準確率隨之下降,即使增大數據集解決過擬合問題,也不會有所改善。ResNet網絡的提出解決了這個問題,其引入殘差網絡的設計,采用shortcut的方式跳過輸入數據的卷積層操作,直接把輸入x加到輸出中,克服了網絡深度加深對模型訓練梯度下降的不良影響。
殘差模塊的結構設計如圖1所示。F(X)為X經過權重層輸出的結果,即指的是殘差,而右側曲線Xidentity表示X本身跳過了權重層直接與F(X)進行疊加,relu表示網絡激活函數。使用這種快捷徑的結構能夠在進行反向傳播的同時保證無衰減地傳遞信號,因此即使增加網絡層數,學習效率也很高。
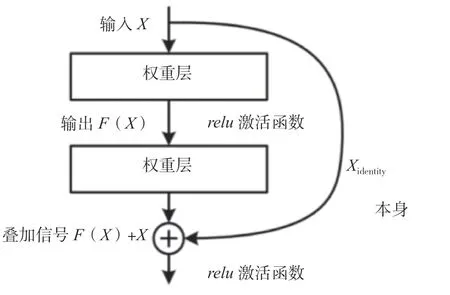
圖1 ResNet殘差模塊結構圖
ResNet網絡模型中最常用的是ResNet50,網絡結構如圖2所示,包括49個卷積層和1個全連接層。其中,第一階段不包括殘差塊,CONV表示對輸入進行卷積操作,Batch Norm表示正則化處理,ReLU表示激活函數,MAXPOOL表示進行最大池化計算。第二階段~第五階段包括殘差塊結構,圖塊CONV-BLOCK不會改變殘差塊的尺寸,只用于添加殘差塊的維度,而圖塊IDBLOCK則不改變殘差塊的維度。在ResNet50網絡結構中,殘差塊都有3層卷積,那網絡總共有1+3×(3+4+6+3)=49個卷積層,加上最后的全連接層,總共是50層,這也是ResNet50名稱的由來[3]。通過使用16個殘差塊的堆疊構建了深度達到50層的卷積神經網絡,再經過AvgPOOL平均池化層輸出特征向量、Flatten平面化圖層降維處理,最后由全連接層FC對這個特征向量進行計算并輸出類別概率。
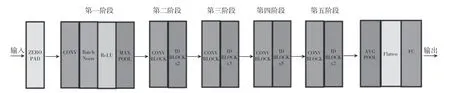
圖2 ResNet50網絡模型圖
2 試驗設計
2.1 數據集構建
現有公開的數據集資源很匱乏,特定領域的數據集資源更稀缺。網上收集的現成魚類數據集數量和豐富性難以滿足模型訓練的需要,通過人工拍照、網絡爬蟲方式獲取相關圖片,爬蟲通過Python腳本實現,用關鍵詞搜索的方式在電商平臺、百度圖片爬取對應的圖片。試驗發現,爬取圖片會出現圖名不對應的情況,需要改變方式,從百科中更有針對性地獲取數據,經過人工審查、篩選和判斷歸集圖片,并采用尺度變換和內容變換的方式對數據集進行增強處理。
采用Python腳本實現圖像批處理功能,對存在尺度不一、格式不定等問題的魚類圖像進行統一數據處理,完成對917個樣本進行圖像采集和歸納的任務,并對每張圖片進行編號排目,歸置到對應的30種類別文件目錄中,用于下一步的模型訓練。
2.2 模型訓練參數調整
2.2.1 學習率
學習率是模型訓練時可控、可調整的超參數之一,其作用是控制梯度下降的迭代步長。如果學習率過大,就會造成損失梯度下降速度較快的問題,模型loss無法收斂;反之,學習率過小會導致模型收斂速度變慢,甚至會陷入局部最優的情況。最理想的結果是權衡兩者變化,損失梯度收斂較快又能下降到比較小的位置。在ResNet網絡的遷移學習中,通過凍結底層學習率調整新的全連接層學習率,經過多次試驗選擇最優學習率。默認的學習率設置都比較小,推薦參數一般為0.000 1,在該范圍擴大或縮小數量級進行測試,以選擇最優值。
2.2.2 批尺寸
批尺寸是指單次訓練所選取樣本的數量,其大小影響模型的優化程度和速度。在合理范圍內增大批尺寸能提高內存利用率,減少單次訓練中批數據的迭代次數,梯度確定的下降方向就越準,但是盲目增大批尺寸會導致單次訓練時間增加,參數的修正變得緩慢,超過某個臨界點還會導致模型泛化能力下降,而在該臨界點之下,模型性能隨批尺寸變化而變化的程度通常沒有學習率明顯。考慮該試驗為CPU環境,設置批尺寸小于64為宜。
2.2.3 迭代次數
將所有樣本數據送入網絡完成1次前向計算以及反向傳播的過程稱為一個迭代,在實際模型訓練時,所有數據迭代訓練1次是不夠的,往往需要經過多次反復的迭代才能擬合收斂。神經網絡模型的權重結構會隨著迭代次數的增加而逐步更新,loss曲線從不擬合狀態逐漸進入優化擬合狀態,如果迭代次數繼續增加,那么最終模型將進入過擬合狀態。但迭代次數的選擇沒有一個確切的答案,不同的數據樣本有不同的迭代次數,一般數據集的多樣化程度越高,迭代次數也應該越多,合適的迭代次數能使模型訓練達到更好的效果。綜合考慮樣本集數量(1 917個)以及樣本種類(30種),迭代10次就可以大致收斂。
2.3 網絡構建
基于神經網絡框架平臺PyTorch搭建ResNet網絡模型,根據ResNet中的殘差學習模塊的不同分別構建BasicBlock(nn.Module)類和Bottleneck(nn.Module)類,逐層實現ResNet34、ResNet50以及ResNet101網絡結構,例如ResNet50網絡根據圖2的結構模型逐層搭建,并通過宏定義的方式進行網絡模型封裝,以方便模型訓練時對該自定義模塊進行調用。
3 試驗過程
3.1 試驗環境
該試驗使用基于Python語言的深度學習神經網絡框架平臺PyTorch,硬件環境為Intel(R) Core(TM) i5-4210M CPU @ 2.60GHz,Windows 1 064位家庭版21H2,編譯軟件為PyCharm2020社區版,基礎配置Anaconda 3,創建Python3.7版本虛擬環境,并在該解釋器下安裝了Open CV、TensorBoardX等依賴庫,以滿足試驗的需要。
3.2 數據集處理及訓練參數
對基礎數據集進行拆分,按照9∶1的比例分為訓練集和驗證集,級目錄結構保持與基礎數據集一致,以方便后續模型的訓練。其中,訓練集1 739張,驗證集178張,并且采取相同的預處理操作,保證驗證和測試結果的準確性。
神經網絡中超參數的取值對模型的性能有很大的影響,試驗中分類識別模型訓練所使用的優化器是Adam,綜合考慮硬件訓練環境資源,設定學習率為固定的值0.000 1,批尺寸的數值設定為16,即每次批量讀取16張圖片,以交叉熵誤差函數(Cross Entropy Loss)作為損失函數,在不占用太大計算資源的情況下,使模型可以快速收斂。
3.3 模型訓練
采用遷移學習機制,試驗前下載3個預訓練模型(ResNet34、ResNet50以及ResNet101),并分別構建ResNet34、ResNet50以及ResNet101網絡模型,以相同的市場漁獲數據集進行訓練,訓練周期設置為10,即1次試驗迭代10輪,通過TensorBoardX繪制訓練損失loss曲線以及驗證的準確率與loss曲線,觀察模型收斂情況,展示網絡模型在訓練集和驗證集上的識別效果。
ResNet中的殘差學習模塊有2種形式:1) Basicblock。用于層數較少的模型。2) Bottleneck。目的是減少參數量和計算量。ResNet50網絡就是模型分界,層數小于50的使用Basicblock,其余的網絡模型使用Bottleneck[4]。而ResNet50與ResNet101相比,唯一的不同在于網絡conv4_x,ResNet50有6個殘差模塊(block),而ResNet101有23個block[5]。
訓練loss曲線如圖3所示。由圖3可知,ResNet34網絡較為簡單,收斂速度快,在第三輪訓練時基本就趨于穩定了,而另外2個網絡模型則在第四輪之后才達到相近的loss值。從訓練時間來看,3個ResNet網絡模型訓練時長分別為2.2 h、3.5 h和5.7 h,由此可知,網絡結構和卷積網絡層數的增加對模型訓練花費的時間有較大的影響。
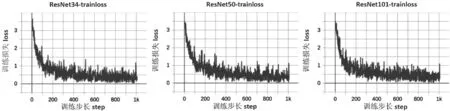
圖3 訓練損失loss曲線
驗證loss曲線以及準確率如圖4所示。首先,對照準確率acc曲線,在訓練10輪后,3個模型的準確率acc均達到0.9以上,ResNet34訓練過程中曲線波動較大,而另外2個模型訓練過程較平穩。其次,對照驗證loss曲線,三者曲線loss值均降至0.4以下,對比之下,ResNet34的loss已趨于穩定,而另外2個模型的loss值仍有下降的趨勢,ResNet101網絡表現得更明顯。
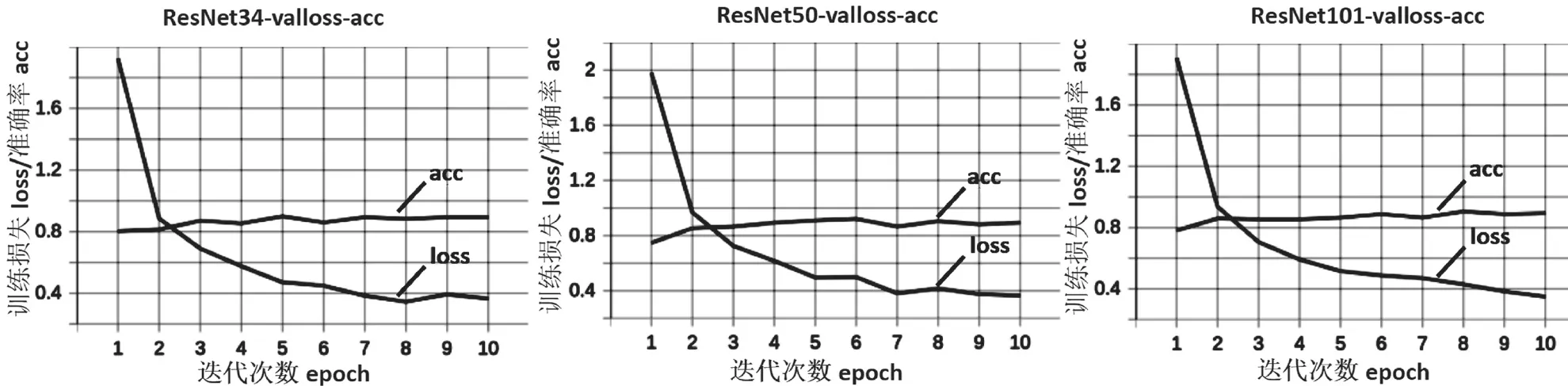
圖4 驗證loss曲線以及準確率
對模型訓練的學習率lr進行微調,將其設置為0.000 05和0.000 30,并沒有推薦參數0.000 10的效果好。另外,調整迭代次數批處理數量的大小對計算機的資源占用率影響較大,對模型的訓練效果影響較小,這些現象也符合試驗前的分析。
4 結語
該試驗以市場常見的30種漁獲物為對象,橫向對比ResNet網絡模型的訓練效果,綜合上述數據表現,整體準確率和loss收斂差別不大,都達到了較好的效果,在一般的使用場景下,ResNet50網絡模型可以符合使用需求。下一步打算豐富當前的漁獲數據集,增加模型訓練的迭代次數,并將算法模型投入實際生產環境使用,以驗證模型的精度與穩定性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
