非參數建模方法在電廠設備故障預警中的應用研究
2022-12-23 05:15:16張海峰袁佽先王亞歐
機電信息 2022年24期
張海峰 袁佽先 陳 波 王亞歐
(1.國能常州發電有限公司,江蘇 常州 213033;2.江蘇方天電力技術有限公司,江蘇 南京 210036)
0 引言
隨著國家“雙碳”目標的確立和相關政策的不斷落實深化,可以預見,電網未來對火電機組的負荷承擔能力要求將越來越高,目前大部分省份已經要求上網的火電機組能夠進行深度調峰,部分機組靈活性改造的試驗效果甚至達到了20%滿負荷的水平。火電機組的深度調峰運行使得各設備的操作運行突破了常規意義上的運行空間,導致運行不確定因素增加,給運行人員帶來了新的挑戰。
業內專家指出,在煤電機組靈活性改造的大背景下,做好設備運行維護和壽命管理,提升系統運行彈性,對于確保機組的安全經濟運行至關重要。
據統計[1],江西電網1 000 MW機組2019年發生故障導致非計劃停運次數為1,600 MW和300 MW機組也都大于0.6,造成了巨大的經濟損失和不良影響。
目前,火電機組設備故障的監控處理主要依靠DCS系統中提供的報警和保護跳閘功能。然而,DCS系統的報警跳閘功能側重于參數的單點閾值判斷和事后處理,缺乏對多參數的集中判斷和故障早期的提前預警。
為實現機組多參數監控和設備故障提前預警功能,本文提出了一種基于非參數模型的機組參數監控及設備故障預警方法。該方法不需要復雜的訓練過程,模型準確性較高,計算簡單,也適合工程化實施。
1 非參數建模方法
1.1 非參數自回歸估計算法
非參數自回歸估計算法[2-3]首先將實時觀測的向量值與歷史存儲的標準值進行比較,通過映射組合得出實時狀態向量的估計值。
假設某一狀態向量的實時觀測值為xobs=[x1obsx2obs…xmobs]T,其對應的標準歷史存儲矩陣為D,其中的一行代表某時刻的一個狀態值,矩陣的行數代表n個標準狀態值,列數代表狀態向量共有m個參數,矩陣的形式如式(1)所示:
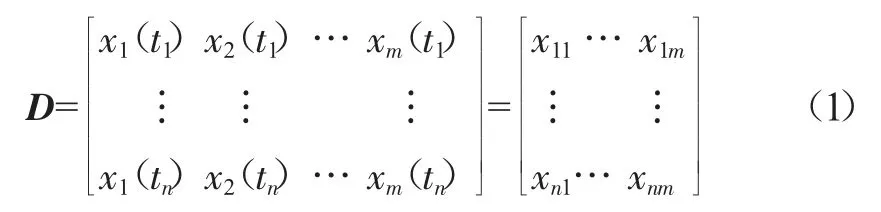
對于一個實時狀態向量,非參數自回歸估計模型通過標準存儲矩陣中的向量組合得出,其計算公式為:
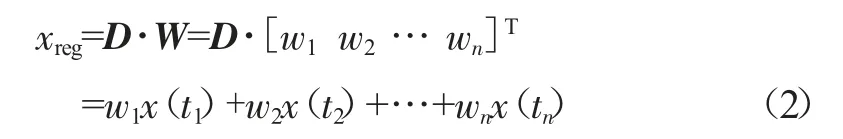
式中:W為權重向量,它的值取決于實時觀測值與標準存儲向量的距離,一般來講,距離越小權重值就越大,反之則越小。
根據公式(2)可知,計算狀態向量的回歸值實質上就是求取權重向量值,以向量間的二范數作為衡量它們之間距離的測度,選取高斯函數作為映射函數,權重值的計算公式為:

式中:xk為歷史標準存儲矩陣中的第k個狀態向量;h為寬度系數。
觀測向量與xk的距離一般采用馬氏距離算子進行計算:
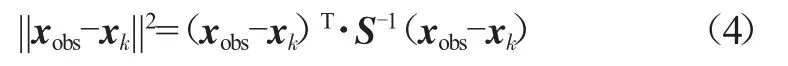
其中,S為狀態向量參數對應的協方差矩陣,若參數之間相對獨立,則可以表示為:

利用模型計算前應先將所有的觀測值進行標準
化,其計算公式為:

式中:yj為第j個參數標準化后的標準值;σj為狀態向量中第j個參數的標準差,一般通過歷史數據進行數理統計得出;uj為第j個參數的統計平均值。
回歸值和觀測值擬合狀態指標為:
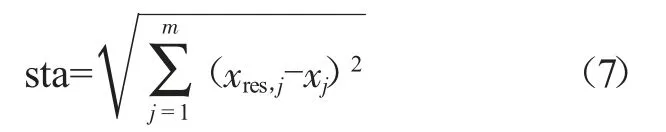
如式(7)所示,該指標值越小,則表示機組的運行狀態越正常;反之,則說明狀態出現異常。
1.2 標準歷史存儲矩陣
與一般的參數建模方法不同,非參數建模方法中不含有模型的訓練過程,但模型的準確性受標準歷史存儲矩陣的影響較大。標準歷史存儲矩陣中存放的是代表機組或設備歷史運行的各種標準狀態,一般來講,標準歷史存儲矩陣中包含的狀態向量種類越多,數量越大,則其涵蓋的歷史運行工況越全面,模型的回歸估計效果越好。然而,標準歷史存儲矩陣中狀態向量的數目也不能過大,否則會導致計算耗費過大,尤其是在工程應用中無法滿足計算的實時性需求。
一般通過從海量的歷史數據中根據一定的采樣規則進行采樣獲取標準歷史存儲矩陣,采樣的規則根據實際需求進行設計,本文采用聚類與多參數采樣結合的規則[4],如圖1所示,根據該規則采樣得到最終的標準歷史存儲矩陣。
圖1展示了確定標準歷史存儲矩陣的具體流程,首先按照每個參數的范圍和對應的間隔在海量的數據集中選取對應的狀態向量,再利用數據挖掘中的聚類方法進行聚類,將類心作為標準狀態向量進行選取,將兩者結合得到一個總的向量集合,然后按照順序逐個進行向量的重復性檢查,剔除重復的狀態向量,得到最終確定的歷史標準存儲狀態矩陣。
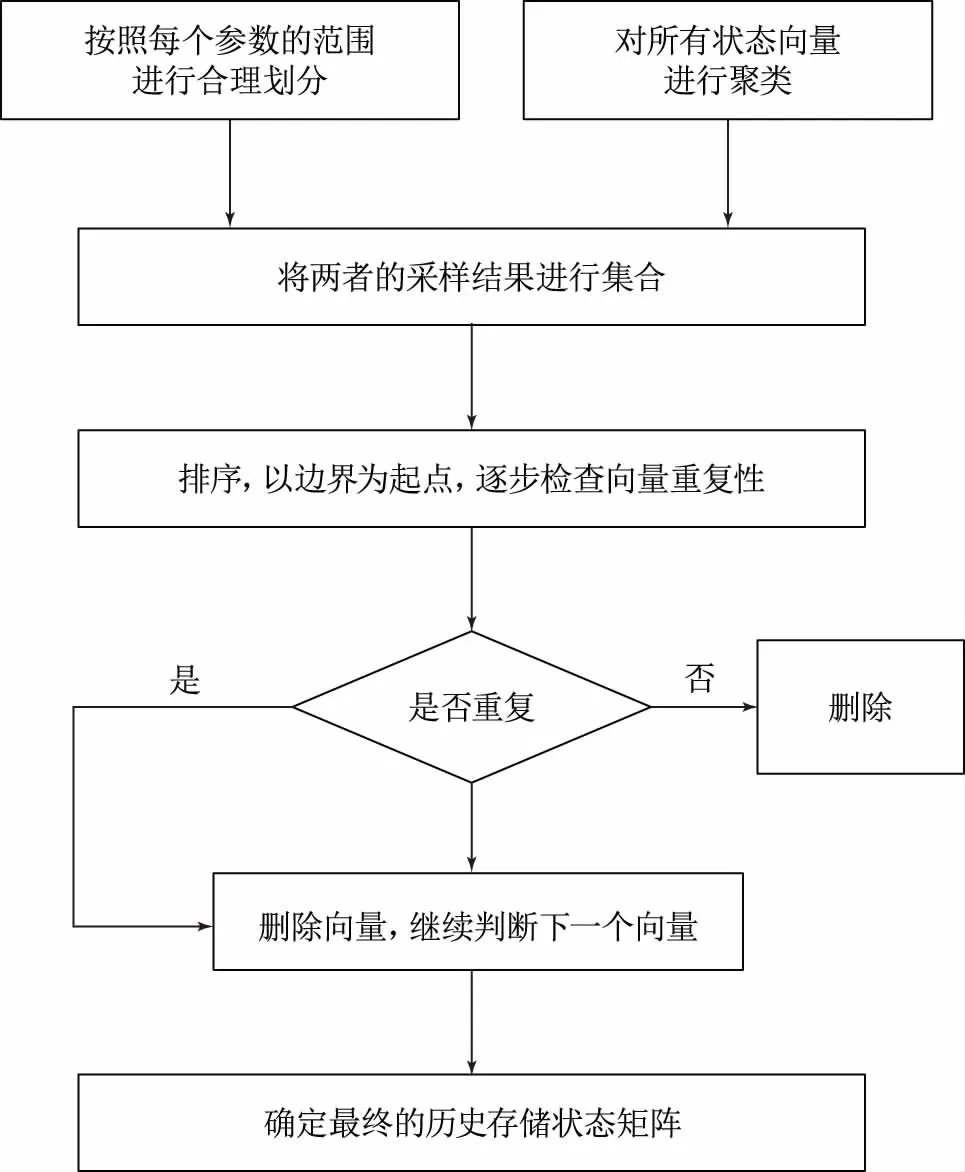
圖1 標準歷史存儲矩陣確定方法
2 四管泄漏故障診斷機制
2.1 四管泄漏故障專家知識庫
專家知識庫是故障診斷的基礎,它描述的是各征兆參數與具體故障之間的隸屬關系,文獻[5]總結出了與鍋爐四管泄漏相關的特征參數,并通過模型計算指出各征兆參數與故障類型間的變化關系。采用一種五值型的函數描述四管泄漏故障下的征兆參數變化特性,如式(8)所示:

五值型征兆集描述方式綜合考慮了參數變化的幅度和方向,綜合各文獻所述的專家知識,得到表1和表2所示的故障專家知識庫。
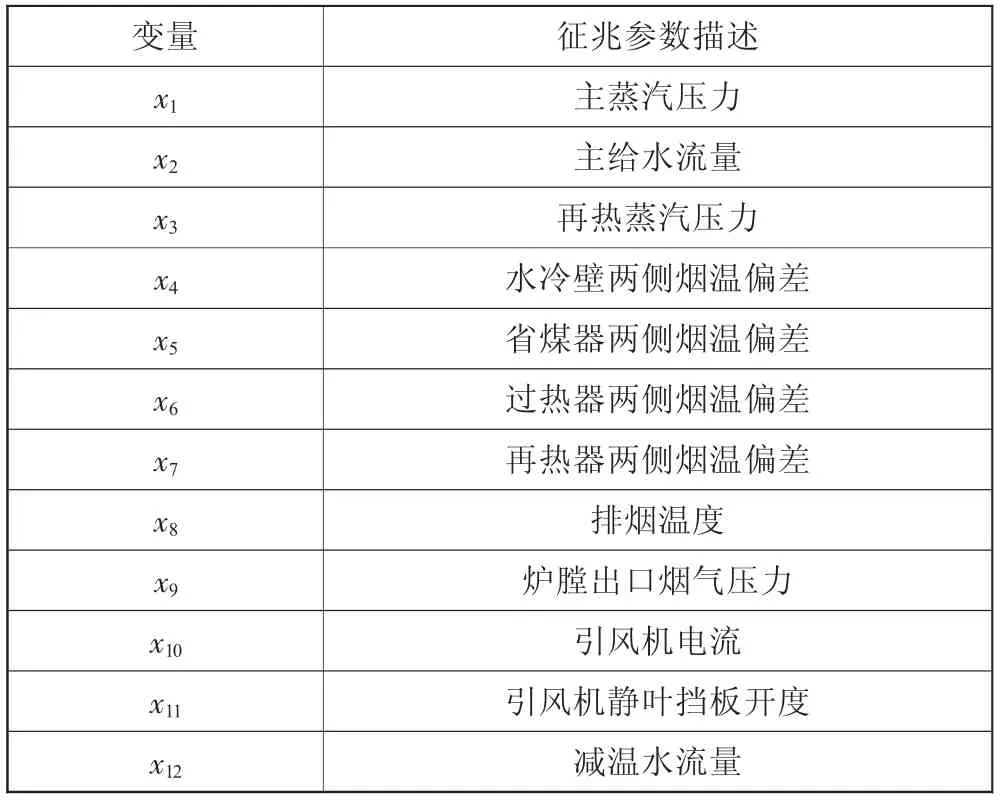
表1 四管泄漏征兆參數集
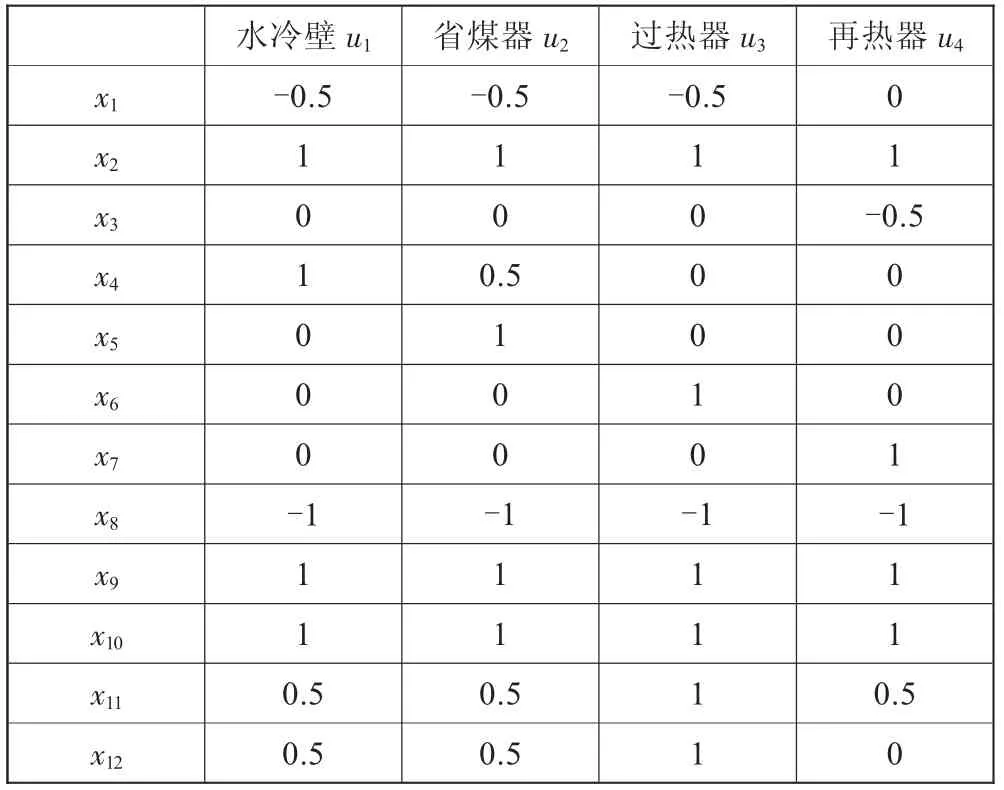
表2 四管泄漏專家知識庫
2.2 基于模糊隸屬度的故障診斷
故障診斷實際上是基于故障診斷專家庫,根據一定的模糊隸屬計算規則對當前的故障狀態進行判定和識別。
本文根據極限學習機的回歸誤差提出一種新的模糊隸屬度判定方法,其基于距離函數[5]:
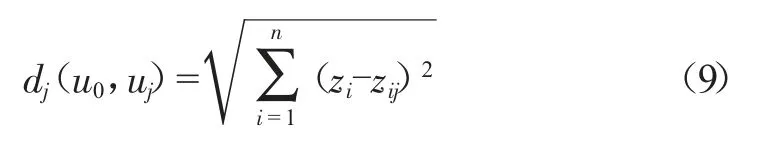
式中:dj(u0,uj)為待識別故障u0與典型故障模式uj之間的距離,顯然數值越小,發生該類故障的可能性就越大;zi為第i個征兆參數的故障征兆值;zij第j個典型故障下第i個征兆參數的征兆值。
隸屬度函數為:
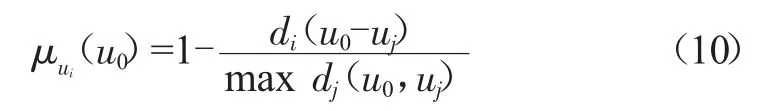
如式(10)所示,隸屬度越大、越接近1,說明發生這類故障的可能性越大。
3 仿真驗證
3.1 非參數模型自回歸估計
利用國內某1 000 MW火電機組仿真系統進行工況的仿真,在機組正常運行狀態下進行負荷升降操作,采樣周期為1 s,共3 600組數據,其中前1 800組用于矩陣確定,后1 800組用于測試。圖2列出了幾個典型參數的模型回歸效果。
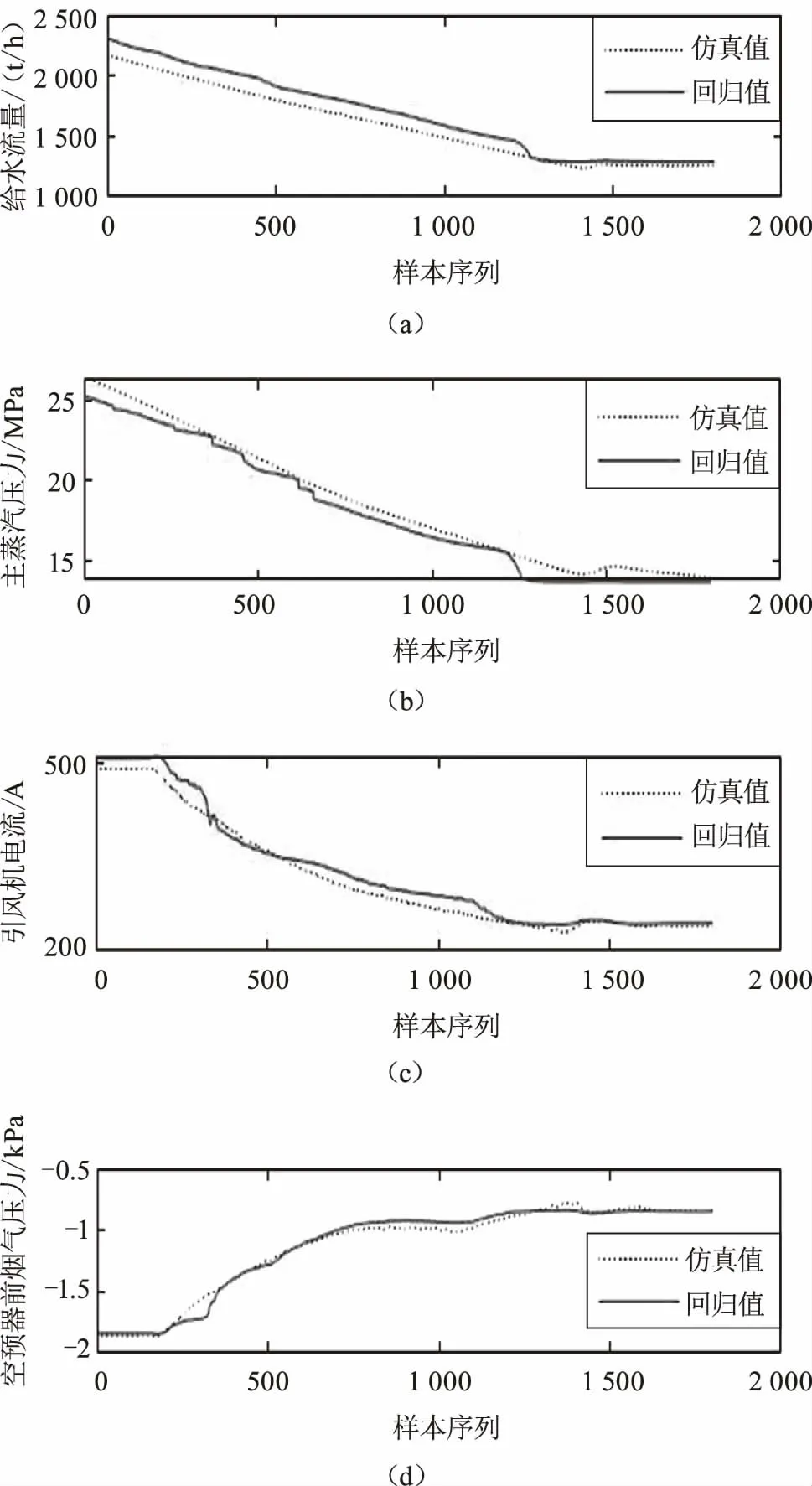
圖2 非參數模型自回歸估計
如圖2所示,與四管泄漏故障相關的征兆參數包括給水流量、主蒸汽壓力、引風機電流、煙氣壓力等,圖中虛線表示仿真模型降負荷過程中各參數的仿真值,實線表示回歸值。從圖中可以看出,回歸模型對各參數估計的結果較為準確,各參數的平均相對誤差均小于5%。在機組變負荷過程中模型回歸值能夠及時地跟蹤參數的變化,準確地反映機組運行狀態。反之,若機組的運行狀態發生異常變化,則回歸誤差增大,趨勢曲線也必然呈現一定程度的偏離。
3.2 基于模型的故障診斷
從第31 s起模擬A側高溫過熱器泄漏故障,圖3是狀態指標在A側高溫過熱器泄漏故障后發生的變化趨勢。
如圖3所示,實曲線代表指標的變化趨勢,可以看出,狀態指標值在第33 s達到預警限值,此時處于故障早期,泄漏量較小,各征兆參數的波動小且未超DCS的報警限值,運行人員難以發現異常。在故障后56 s左右,DCS系統才發出超溫報警。顯然,預警信號對微小劣化的敏感度較高,對故障具有提前預警的作用。
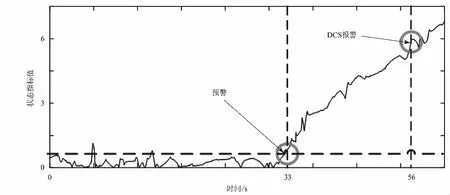
圖3 故障前后狀態指標趨勢
當出現預警信號后,利用專家知識庫和模糊隸屬度函數求取各故障的隸屬度,由此確定具體的故障模式。表3是故障后各類故障隸屬度的計算結果,從中可以看出,隨著故障劣化程度的增大,當前故障對u3的隸屬度呈現明顯的增加趨勢。實際上在預警信號出現后,診斷機制已經正確判斷出發生了過熱器泄漏故障,隨著時間的推移,診斷結果的確定性加大,第39 s的計算結果則進一步確認了故障模式。
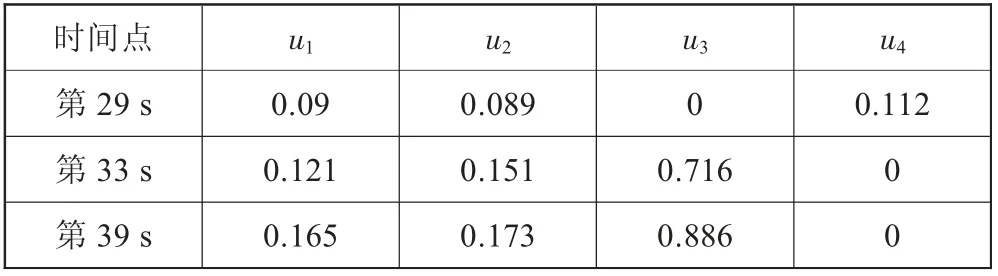
表3 故障診斷隸屬度計算
4 結語
本文利用非參數建模方法建立了鍋爐四管的狀態參數回歸模型,擬合出狀態指標用于狀態預警,并結合故障診斷專家知識庫和模糊判別方法實現了故障分離。某1 000 MW機組仿真模型計算表明,非參數自回歸模型能夠對狀態參數進行準確的回歸估計,在故障發生早期,就能夠提前給出準確的故障預警信號,驗證了該方法的正確性與有效性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
