
基于Swin-Unet的混凝土裂縫分割算法研究
2022-12-22 13:50:10劉森
河南科技 2022年23期
劉 森
(長沙理工大學土木工程學院,湖南 長沙 410114)
0 引言
作為當今建筑中的主要材料,混凝土在建筑中起著至關重要的作用。混凝土在服役過程中,因荷載的作用和材料性能的退化,使其表面出現裂縫,不僅影響建筑物的美觀和耐久性,甚至會縮短建筑物的使用壽命,威脅其結構安全。因此,要及時發現裂縫的位置,分析裂縫出現的原因和損傷程度,并采取措施來防止裂縫進一步延伸。
近年來,隨著深度學習的快速發展,深度學習領域中的卷積神經網絡(CNN)已被廣泛應用于各種分割任務中,并在裂縫檢測領域中表現出不錯的性能。特別是,U-Net[1]及其變體在該領域的應用更成功,如建筑物表面裂縫檢測[2]、橋梁裂縫檢測[3]、路面裂縫檢測[4]和混凝土裂縫檢測[5]等。然而,因卷積操作的歸納偏置,使其無法學習全局,完成遠端的信息交互,從而阻礙分割網絡的進一步提升。通過引入Transformer[6]模型來彌補卷積的缺陷。利用Transformer 在特征圖中捕捉長距離特征的優勢,能有效彌補CNN因局部偏置和權值共享對全局信息把握不足的缺點。Swin-Unet[7]是一種基于U-Net改進的純Transformer模型,其延用CNN 中的 U 型網絡架構,并通過 Swin Transformer[8]模塊來彌補卷積操作的缺陷,能更好進行局部及全局的語義特征學習,有著更優的性能。因此,本研究借鑒深度學習領域的Swin-Unet分割模型來完成混凝土的裂縫檢測。
1 模型架構
目前,圖像分割主要基于卷積神經網絡(CNN)。其中,U 型網絡(U-Net)作為經典的CNN,其在利用跳躍連接的同時,保留在下采樣中丟失的細節信息和在低分辨率圖像中獲取到的全局特征,這種融合不同尺度特征的編碼器-解碼器的結構設計能大幅度提升分割模型的性能。因此,Swin-Unet 模型延用這種U型架構,同時引入Swin Transformer模塊來彌補卷積操作無法進行遠程信息交互的缺陷。
1.1 Swin-Unet模型架構
與傳統的U-Net 結構相同,整個Swin-Unet 模型由3 部分組成,即編碼器(左側部分)、解碼器(右側部分)以及跳躍連接(中間跨線部分),如圖1所示。
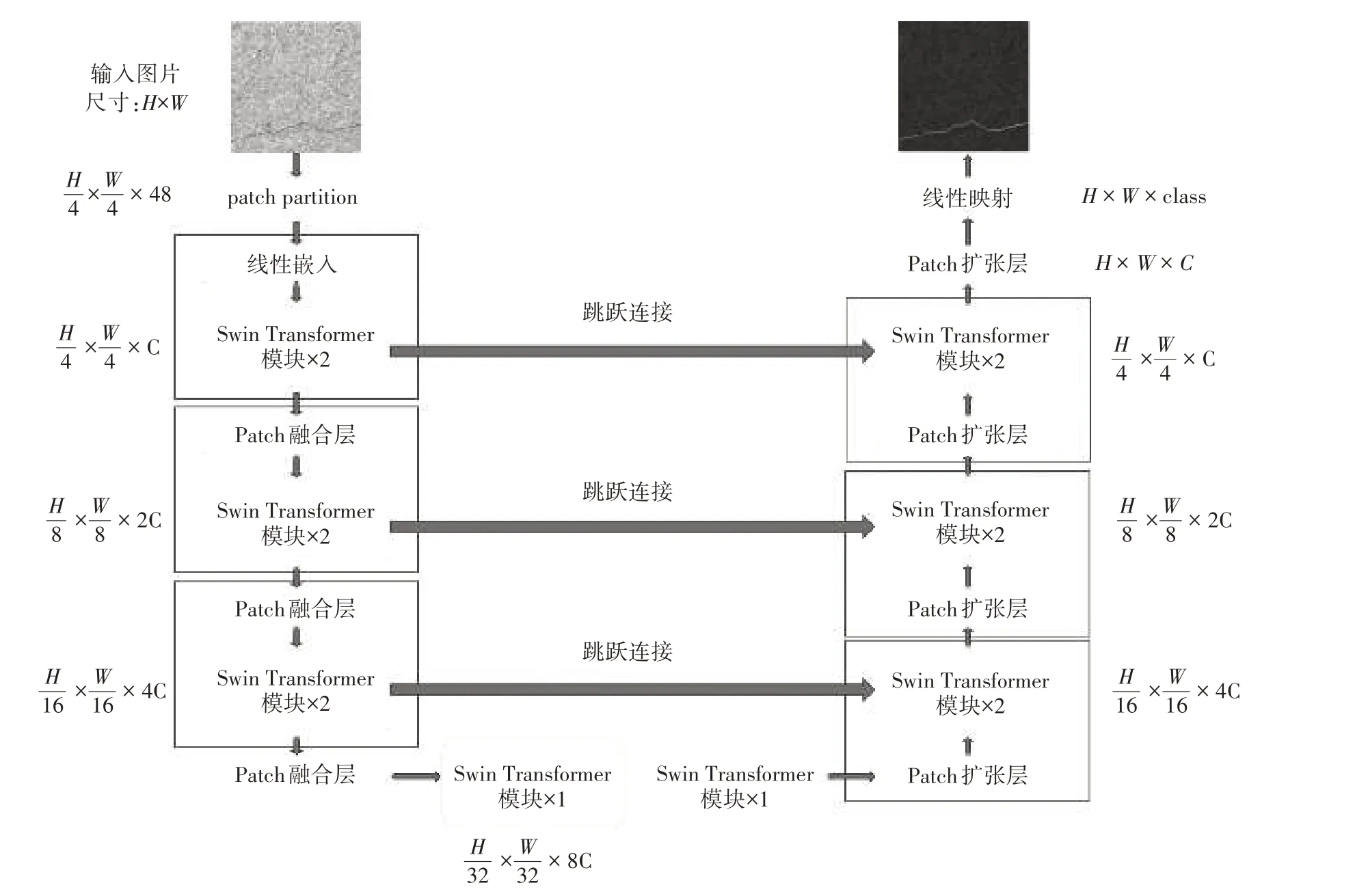
圖1 Swin-Unet模型架構
1.1.1 編碼器。輸入的圖片先通過patch par?tition 模塊,其將圖片切分成大小相等,且互不重疊的分塊,并對每個分塊進行線性嵌入,可將輸入向量的維度變成預先設置好的值,圖中維度用C 來表示。隨后將嵌入的分塊依次送入Swin Transformer模塊和patch 融合層,用來生成不同尺度的特征表述。其中,Swin Transformer 模塊負責學習特征,patch 融合層負責下采樣操作,將輸入該層的特征圖的分辨率縮放至一半。
1.1.2 解碼器。解碼器由多個Swin Trans?former模塊和patch 擴張層組成。patch 擴張層進行上采樣操作,將輸入該層的特征圖擴充至2 倍分辨率,最后一個patch 擴張層會將特征圖擴充至4 倍分辨率,用于將特征圖還原成原圖尺寸,最后通過線性映射層進行像素級別的預測,判斷被預測的像素點是否屬于裂縫。
1.1.3 跳躍連接。和傳統的U-Net一樣,跨線負責的是特征融合,以級聯的方式將特征圖輸送到解碼器來融合多尺度特征,從而彌補原始信息的丟失。
1.2 基礎模塊
1.2.1 Swin Transformer模塊。Swin Transformer是整個網絡最基礎的模塊,和傳統的多頭注意力(MSA)結構不同的是,Swin Transformer 是基于滑動窗口構建的,圖2 為兩個串聯的Swin Transformer 模塊。每個Swin Transformer 模塊由兩個層歸一化(Layer Norm)層、多頭自注意力模塊和多層感知機(MLP)組成。

圖2 兩個串聯的Swin Transformer模塊
在兩個連續的Swin Transformer模塊中,分別采用基于窗口的多頭自注意力模塊(W-MSA)和基于滑動窗口的多頭自注意力模塊(SW-MSA)。
Yao 等[9]提出的多頭注意力(MSA)采用的是全局自注意力機制,即在整張圖上進行自注意力計算,其計算復雜度與圖片大小成平方關系。當圖像增大時,計算量也會飛速上漲。W-MSA 使用窗口對計算范圍進行限制,在每個窗口內進行自注意力計算,可極大降低計算的復雜度,提高訓練速度。但因每個窗口互不重疊,每次進行自注意力計算時,窗口與窗口間沒有信息交流,SW-MSA 通過滑動窗口來實現窗口與窗口間的信息交流。采用基于滑動窗口的自注意力模塊,不僅具有標準的transformer 自注意力機制的全局信息提取能力,還能降低計算復雜度。MSA 復雜度與W-MSA 復雜度的計算公式見式(1)、式(2)。
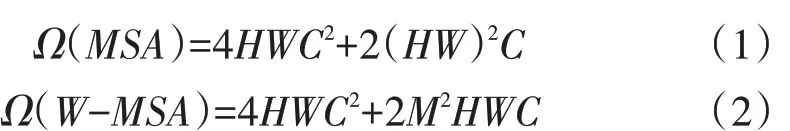
式中:H 為圖片的高;W 為圖片的寬;C 為圖片的維度;Ω為復雜度計算函數;M為圖塊數量。
由于試驗采用長寬均為512 的RGB 圖像,通過patch partition 模塊后切分出的圖塊個數應為128 ×128,遠小于圖像像素點個數512 × 512。因此,理論上Swin Transformer更有利于模型的訓練。
1.2.2 patch 融合層。為了讓圖像有層級式的概念,這里要用到類似池化的操作。在Swin-Unet中,Patch 融合層是將圖像的高和寬縮小至原來的一半,將圖像維度升為原來的2倍。patch融合操作如圖3 所示。先將每個圖塊隔一個像素選取一個數值,將圖片切分成4 塊,然后將切分開的圖塊進行通道融合,其維度將會擴大為原圖塊的4 倍,最后通過全連接層,將其維度壓縮為原圖塊的2倍。
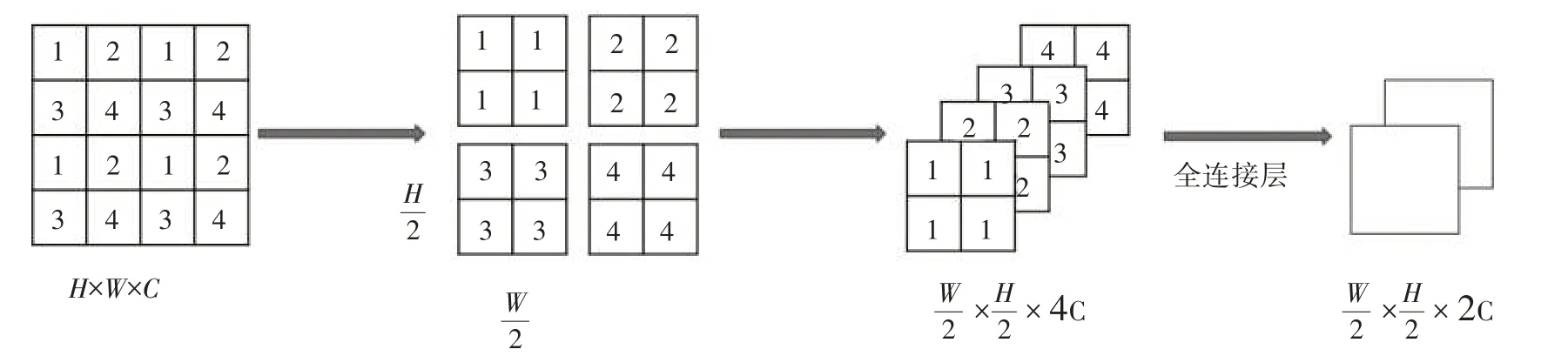
圖3 patch merging模塊
2 評價指標與數據集制作
2.1 評價指標介紹
混淆矩陣(見圖4)是情形分析表,顯示以下四組記錄的數目,即作出正確判斷的肯定記錄(真陽性)、作出錯誤判斷的肯定記錄(假陰性)、作出正確判斷的否定記錄(真陰性)以及作出錯誤判斷的否定記錄(假陽性)。
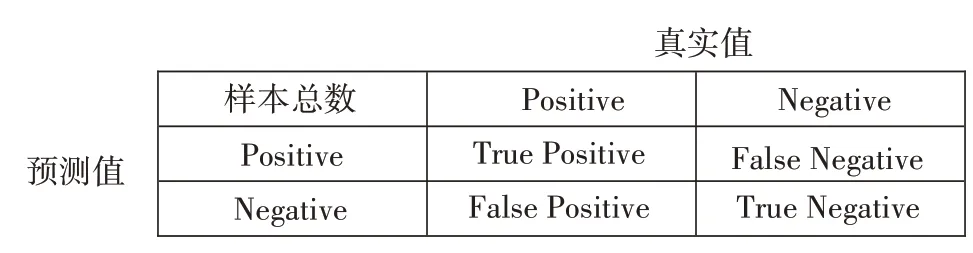
圖4 混淆矩陣
其中,TruePositive(TP)為樣本的真實類別是正類,模型識別結果為正類;FalseNegative(FN)為樣本的真實類別是正類,模型識別結果為負類;False Positive(FP)為樣本的真實類別是負類,模型識別結果為正類;True Negative(TN)為樣本的真實類別是負類,模型識別結果為負類。
2.1.1 F1 score。
精準率(Precision)是指被預測為正樣本的檢測框,其預測正確的占比,見式(3)。
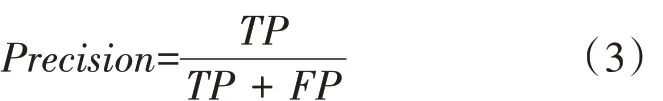
召回率(Recall)是被正確檢測出來的真實框占所有真實框的比例,見式(4)。
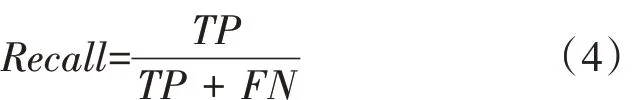
考慮Precision 和Recall 是一對矛盾的度量,為了能夠綜合考慮這兩個指標,引入F1 score,其計算公式見式(5)。

式中:P為精確率;R為召回率。
2.1.2 交并比(IOU)。IOU 是用來評價兩個區域的相似性,是度量兩個檢測框的交疊程度。考慮試驗是二分類,且背景所占的比例大,用IOU 作為評價指標比平均交并比(MIOU)更合理,IOU 的計算公式見式(6)。
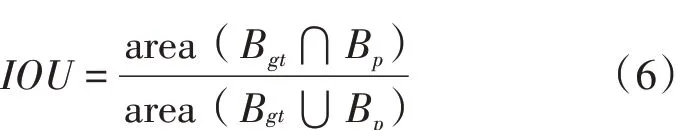
式中:Bgt為真實框,即提前標注好的裂縫框;Bp為預測框,即模型預測出來的裂縫框。
2.2 數據集制作
本研究的裂縫圖像采集對象為已投入使用的居民樓,共采集到300 張裂縫圖片。采集工具為大疆御Mavic Air2 無人機,無人機攜帶相機所拍攝的照片最大尺寸為4 800 萬像素,所拍照片為三通道的RGB 圖像。考慮到圖像尺寸過大導致模型難以訓練,將采集到的圖像裁剪為長寬均為512 的RGB圖像。
同時,由于采集到的圖像背景過于單一,難以達到泛化的目的。因此,為豐富數據集的多樣性,讓模型學到豐富的裂縫圖像特征,提高模型的泛化性能和復雜背景下裂縫分割的魯棒性,本研究采用公 共 數 據 集 Original_Crack_DataSet_1024_1024[10]、Concrete Crack Images for Classification[11]、CrackFor?est和CRACK500進行輔助訓練。從中篩選出3 200張圖片用于該試驗。其中,包含橋梁裂縫、道路裂縫、建筑外墻裂縫。將這3 518張圖片按訓練集、驗證集和測試集約8∶1∶1 的比例進行劃分,即2 918張圖片作為訓練集、300 張圖片作為驗證集、300 張圖片作為測試集(見圖5)。
3 模型對比
為了驗證本研究提出的模型的分割性能,采用PSPNet[12]、U-Net、Res U-Net[13]、DeepLabV3+[14]、TransUnet 等5 種模型進行比較。在保證數據集相同的前提下,訓練網絡模型,并通過驗證集測得的評價指標與通過測試集預測出的分割結果進行對模型分析比較。
3.1 評價指標對比
通過比較其精準率、召回率、F1、IOU 來驗證訓練效果(見表1)。
由表1 可知,Swin-Unet 的識別效果最好,其次是TransUnet,其評價指標分數與Swin-Unet 相差無幾,但其訓練時間更久,這是因為TransUnet 使用的是全局自注意力機制,圖片越大,計算量就越大。在傳統的卷積神經網絡中,U-Net 的識別效果最佳,但其F1分數與IOU仍略低于Swin-Unet。

圖 數據集示例圖
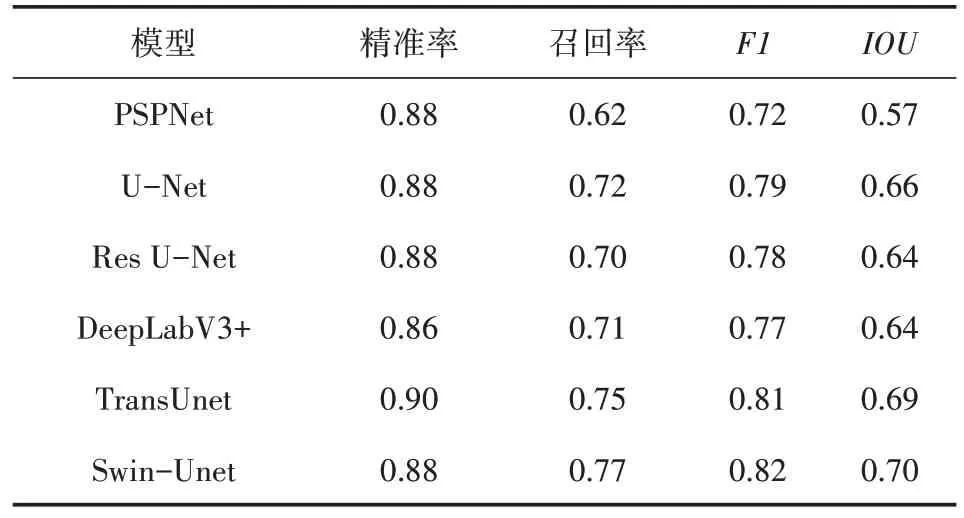
表1 評價指標
3.2 分割效果對比
在測試集中隨機抽取4 張圖片進行預測,各模型的分割結果見表2。
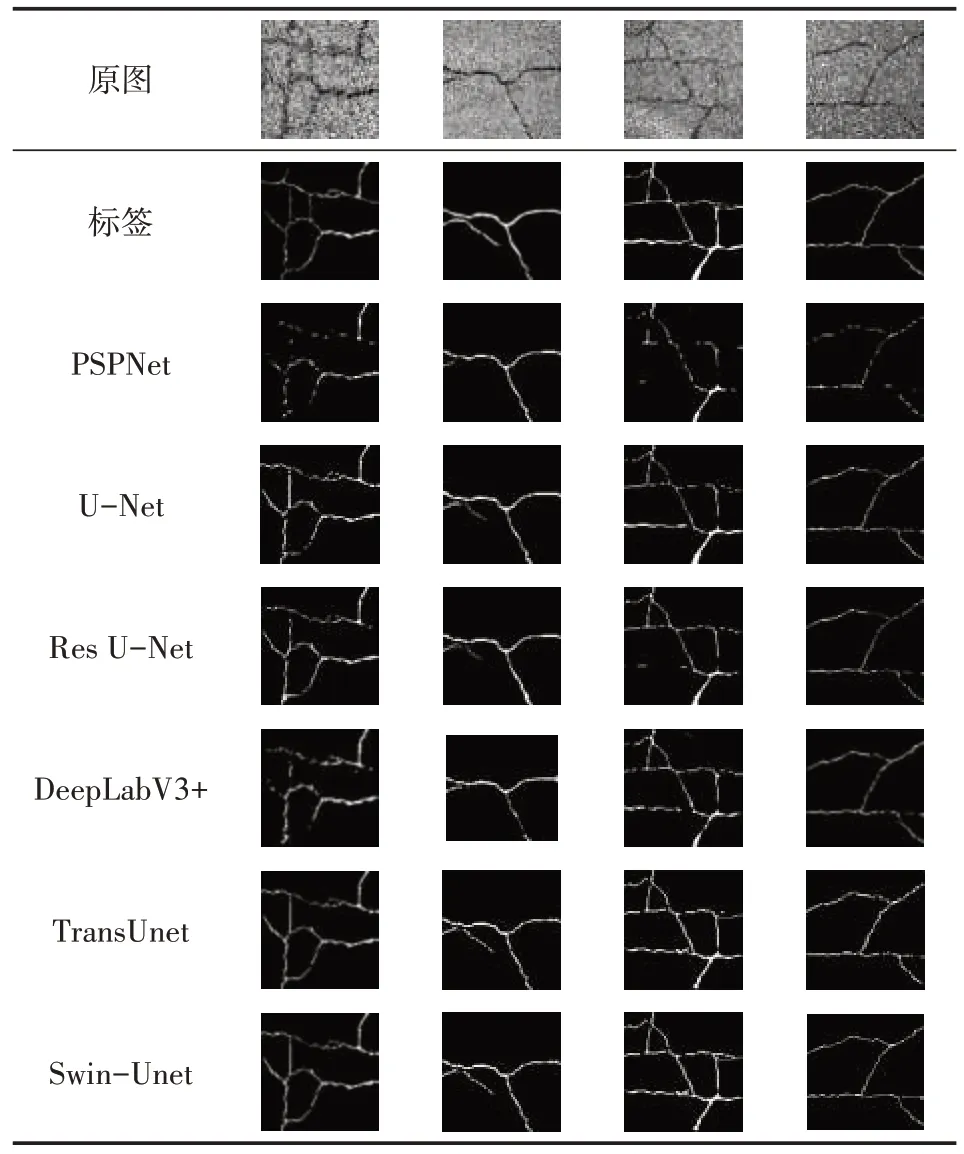
表2 預測結果
對比分割效果可以發現,在傳統的卷積神經網絡中,U-Net的分割效果最佳,但第1、2、3張圖仍有部分地方有較大瑕疵。Swin-Unet 對測試圖進行分割,雖有些許瑕疵,但仍然取得最好的分割效果。
4 結論
通過對試驗結果進行分析,從評價結果和分割效果兩方面進行對比,Swin-Unet 比卷積神經網絡有相對較好的檢測效果。這表明Transformer 更利于圖片特征的提取。對比計算復雜度,并通過試驗進行驗證,Swin-Unet 與transunet 在數據集、學習率和batchsize 都相同的前提下,Swin-Unet 的訓練時間更短,且不降低識別效果。這說明基于窗口的自注意力機制比全局自注意力機制更有利于對模型的訓練。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
