分類任務中標簽噪聲的研究綜述
2022-12-19 11:28:38佟強刁恩虎李丹諶彤童劉旭紅劉秀磊
科學技術與工程 2022年31期
佟強, 刁恩虎, 李丹, 諶彤童, 劉旭紅, 劉秀磊*
(1北京材料基因工程高精尖創新中心(北京信息科技大學), 北京 100101; 2 北京信息科技大學, 數據與科學情報分析研究所, 北京 100101; 3 北京跟蹤與通信技術研究所, 北京 100094; 4.北京信息科技大學, 網絡文化與數字傳播北京市重點實驗室, 北京 100192)
隨著機器學習的發展,計算機能夠從經驗中學習。機器學習在許多領域都取得了顯著的進步,如圖像分類[1]、目標檢測[2-3]、語義分割[4-5]等。近年來,分類任務在機器學習中得到廣泛發展,即從標注數據集中學習得到分類模型,用來預測新樣本的類別。一般來說,機器學習模型是模仿人類大腦處理決策數據的工作方式,模型是否具有良好的決策能力取決于數據集的好壞[6]。模型訓練過程多采用有監督的學習,其特點是需要大量帶標簽數據,因此需要大規模的數據集收集和煩瑣的標注過程[7]。盡可能減少數據集中的噪聲是提高訓練模型分類準確率的重要保障。數據中存在兩種噪聲:特征噪聲和標簽噪聲[8]。特征噪聲影響特征的觀測值,其產生原因為數據所觀察到的特征被破壞,對應著模型的輸入。標簽噪聲則是由于標簽與數據真實類別的偏差所導致,對應著模型的輸出[9]。兩種噪聲都會使模型性能顯著下降,其中標簽噪聲危害更大,嚴重影響模型的泛化性能[10-11]。數據集中噪聲的存在模糊了對象特征和其類別之間的關系,這就增加了數據分類的復雜性,許多研究表明有噪聲的標簽會對分類器的分類精度產生不利影響。標簽噪聲作為數據集收集和數據標注的自然結果,使處理標簽噪聲成為高效計算機分類系統發展的一個重要課題[7]。
1 標簽噪聲的來源
標簽噪聲是數據集收集過程的自然結果,普遍存在于各種領域,如醫學成像[12-13]、語義分割[14]、眾包[1,15]、社交網絡標簽[16]、金融分析[17]等。現重點關注解決標簽噪聲的各種方法,為了更好地理解這一現象,先要調查標簽噪聲的原因。
首先,隨著網絡和社交媒體的發展,人們可以獲得海量的數據,分類系統可以很好地利用這些數據進行訓練[18-19]。但是,這些數據的標簽來自雜亂的用戶標簽和搜索引擎使用的自動化系統。眾所周知,獲得數據集的這些過程必然會產生噪聲標簽。
其次,標簽噪聲還可能來自于領域專家,因為有時數據過于復雜,即使對該領域的專家來說也有可能無法正確標注,如醫學成像。數據還可能由多個專家進行標注,從而形成多標注的數據集。每個標注數據的專家專業水平不同,他們的意見甚至可能會相互沖突,這就導致了標簽噪聲問題[20]。舉例來說,為了收集視網膜圖像的最標準驗證數據,通常會從6~8個不同的專家那里收集注釋[21-22]。考慮到疾病診斷這種至關重要的領域,克服標簽噪聲是非常有意義的。
另外,通過MTurk (Amazon mechanical turk)[15]和CrowdFlowers[1]等平臺,數據標注過程可以進行眾包。用自動化系統代替人工來標注數據也是一種廣泛使用的方法。雖然這些數據標注方法節約了成本,但從非專家那里獲得的標簽通常含有大量噪聲。由這些數據標注方法導致的噪聲稱為非專家標簽噪聲。最后,數據編碼和通信問題也可能導致標簽噪聲[23]。例如,在垃圾郵件過濾中,標簽噪聲的來源包括對反饋機制的錯誤解讀和意外點擊[24]。
2 標簽噪聲的影響
在實際應用中,標簽噪聲主要帶來負面影響,但不可否認,人工標簽噪聲也有其潛在作用。例如,可以在統計研究中添加標簽噪聲以保護人們的隱私[25]。本文主要關注標簽噪聲的負面影響。
首先,標簽噪聲會降低預測的性能,這一點在線性分類器[26]、二次分類器[27]和K最鄰近(K-nearest neighbor, KNN)分類器[28]等簡單模型中已經得到了證明。許多學者在其他分類器中也證實了這一問題,如由C4.5[29]和支持向量機[30]誘導的決策樹等。除此之外,Boosting等集成方法也極易受到標簽噪聲的影響。例如,AdaBoost算法傾向于給錯誤標記的實例賦予較大的權重[31]。
其次,在機器學習過程中為了減小標簽噪聲的影響需要增加訓練數據集,最終導致訓練的模型復雜度增加,容易導致過擬合從而影響預測效果[32]。在概率近似正確(probably approximately correct, PAC)[33]框架中,標簽噪聲的存在會增加PAC識別所需的必要樣本數量;在決策樹和支持向量機中,標簽噪聲會使決策樹的節點數量和支持向量機中支持向量的數量增加[23]。
此外,標簽噪聲可能會導致觀測頻率的失真[34]。在醫學應用中,經常需要通過醫學測試來進行疾病診斷,估計一種疾病在人群中的患病率,或者估計不同人群中的患病率,標簽噪聲會影響醫學檢測結果的觀測頻率,從而可能導致錯誤的結論[35]。
3 標簽噪聲的解決方案
3.1 標簽噪聲魯棒模型
本小節介紹一些對標簽噪聲具有魯棒性的模型。當訓練數據包含少量的標簽噪聲時,即使標簽噪聲沒有被凈化,這樣的模型也相對有效。不過,就目前大多數分類系統而言,都不具備完全的標簽噪聲魯棒性。
3.1.1 集成學習方法
集成學習是機器學習分類任務中的常用算法,經典的集成學習方法有:Bagging和Boosting。Bagging每次訓練隨機抽取訓練集的某個子集,同時生成多個分類器,最終的訓練結果由多個分類器綜合投票給出,從而使分類模型對噪聲具有一定的魯棒性,代表算法如隨機森林。Hamsa等[36]使用隨機森林(random forest, RF)分類器和小波包變換(wavelet packet transform, WPT)相結合,設計了一個從語音信號中進行情感識別的系統,系統框架如圖1所示。該系統由時頻分解(time-frequency decomposition)、語音分離(speech segregation)、特征提取(feature extraction)和分類模塊組成,其中分類模塊采用隨機森林分類器。Boosting是將幾個弱分類器組合在一起,形成一個強分類器,根據每次基分類器的錯誤率來調整訓練數據集的權重,即給錯誤標注的樣本更高的權重,代表算法如Adaboost。由于Boosting給錯分樣本更高的權重,容易導致分類模型對噪聲過擬合[37]。王友衛等[38]提出基于合群度-隸屬度噪聲檢測和特征選擇來改進AdaBoost,綜合考慮樣本與周圍樣本的相似度以及與不同類別樣本的隸屬關系,即合群度和隸屬度,再與動態特征選擇方法相結合,最終在分類性能上較傳統算法得到提升。Pakrashi等[39]提出一個Kalman Tune框架,將優化訓練得到的集成模型作為一個可以用卡爾曼濾波(Kalman filtering, KF)解決的靜態狀態估計問題,利用KF的融合能力來減少標簽噪聲對集成模型的影響。當訓練數據內有標簽噪聲時,Kalman Tune可以顯著提高Boosting訓練集成模型的性能。
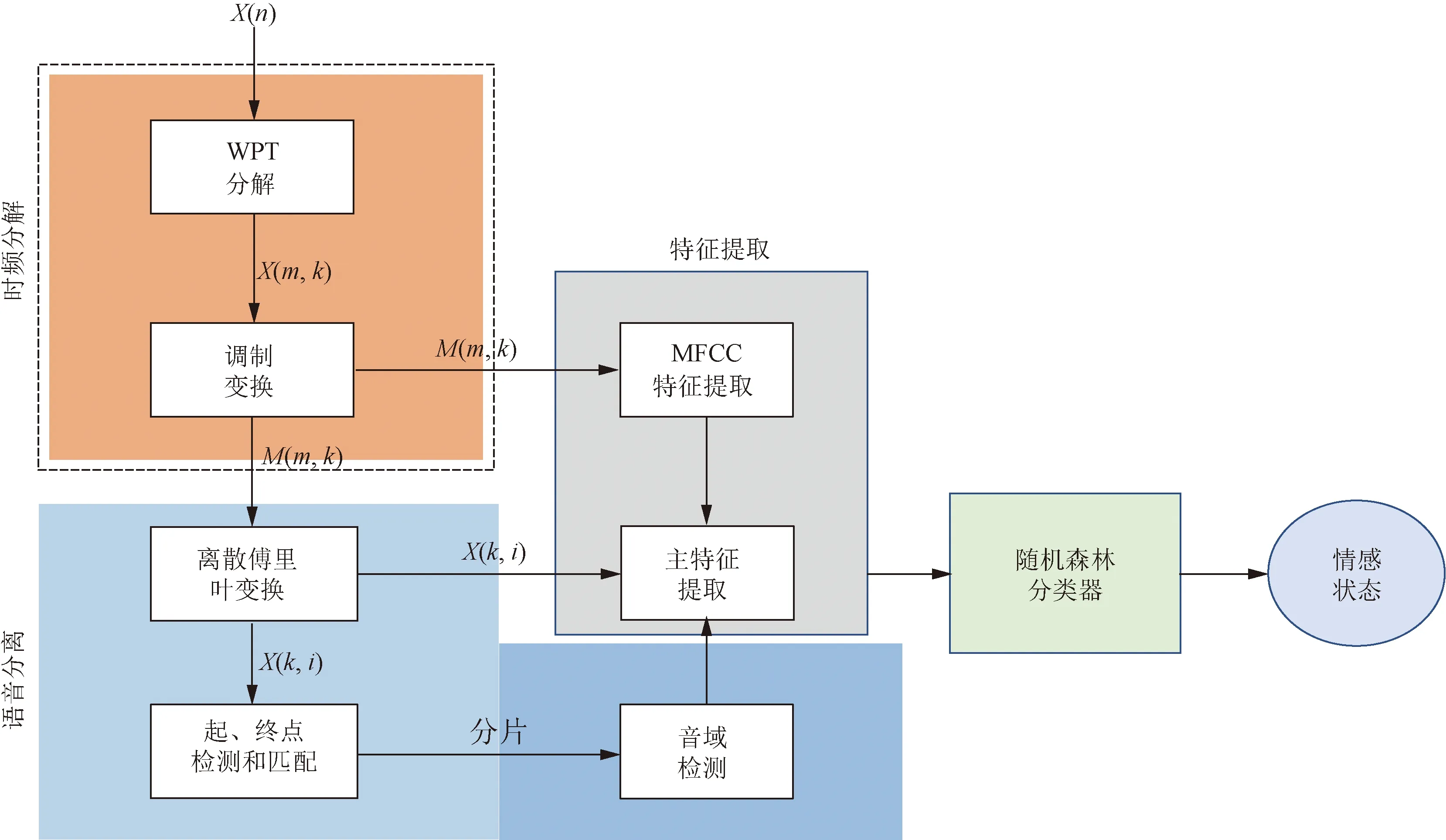
圖1 情感識別系統框架[36]Fig.1 Framework of emotion recognition system[36]
動態集成選擇 (dynamic ensemble selection, DES)策略是機器學習中處理分類問題最常見和最有效的技術之一。DES 系統目的是構建一個集合,根據單個分類器的能力水平從候選分類器池中選擇的最合適的分類器組成該集合。Zhang等[40]提出一個動態加權框架(dynamic weighting framework, DWF),用于在獲取DES系統最后輸出期間進行分類融合,該方法在準確性和Kappa系數上都優于原始DES框架。
3.1.2 決策樹
決策樹涉及準確性和簡單性之間的權衡,好的決策樹需要同時兼顧這兩個條件。但是,在存在標簽噪聲的情況下平衡這種權衡,會使過擬合問題變得更加嚴重。事實上,決策樹的不穩定性使得它非常適合于集成方法。
醫學圖像去噪是醫學圖像處理中的關鍵預處理步驟,Kumarasamy等[41]提出集成樸素貝葉斯、支持向量機、決策樹和隨機森林方法用于查找醫學圖像中損壞像素,最終分類的結果由分類器的輸出結果投票決定,其分類準確率能達到99.87%。
Credal決策樹(Credal decision trees, CDT)已廣泛用于不精確分類,即ICDT (imprecise Credal decision trees)。Moral等[42]提出將ICDT與Bagging相結合,以CDT作為基分類器,最大限度地提高Bagging分類器的精度,最終分類器的性能明顯優于單個ICDT。
3.1.3 其他方法
在圖像去噪任務中,Zhou等[43]提出了一個在AWGN-RVIN (additive white gaussian noise and random value impulse noise)噪聲模型上訓練的圖像盲和非盲去噪網絡,該網絡由多通道噪聲評估器和自適應條件降噪器組成。然后采用PD (pixel-shuffle down-sampling)策略,使訓練后的模型適應真實噪聲。該方法在Spatially-Variant去噪和細節保護方面效果顯著。同樣針對圖像降噪任務,Byun等[44]提出一種新的去噪方法FC-AIDE (fully convolutional adaptive image denoiser)。該方法設計了一種新穎的全卷積架構,以增強基礎監督模型,同時為自適應微調(adaptive fine-tuning)引入正則化方法,以提高其魯棒性。該方法在基準數據集上的效果優于目前基于卷積神經網絡(convolutional neural networks,CNN)的其他方法。
在圖像超分辨率任務中,現有的超分辨率方法基本都假設輸入的圖像是無噪聲的,當輸入的圖像被噪聲污染時,它們的性能會急劇下降。針對這種情況,Xin等[45]受膠囊網絡(capsule networks)的啟發,提出一種面部信息的綜合表示模型,稱為面部屬性膠囊(facial attribute capsule, FAC)。為了有效提高FAC對噪聲的魯棒性,采用集成學習策略,通過語義表示、概率分布對面部屬性進行編碼生成FAC,由此設計出一個面部屬性膠囊網絡(facial attribute capsule network, FACN),在噪聲圖像的超分辨率重建方面效果顯著。
為應對訓練數據中存在標簽噪聲的問題,Luo等[46]提出一種雙層學習范式方法SCD (spectral cluster discovery)。通過真實標簽矩陣的低秩逼近來學習一個強分類器(學習階段),同時得到一個Affinity圖(聚類階段),兩個階段相互補充,最終提高了模型的分類精度。
許多研究表明特征提取有助于減少標簽噪聲的影響。受該思想啟發,劉望舒等[47]基于聚類分析,提出了一種具有噪聲容忍能力的特征選擇框架(feature clustering with selection strategies, FECS)。
3.2 數據清洗
處理數據中的標簽噪聲,最直接的方法是數據清洗,即識別錯誤標簽并將其更正為對應的真實標簽或者直接刪除錯誤標注的樣本,在關于標簽噪聲的文獻中有很多這樣的清洗方法。如Feng等[48]提出一種稱為ENDM (ensemble method based on the noise detection metric)的數據清洗方法。該方法首先從帶噪訓練集中學習得到一個集成分類器,用其導出四個指標來評估樣本被錯誤標記可能性。對于每個指標,在使用三種不同的集成分類器(Bagging、AdaBoost和KNN)時,設置三個閾值用于識別、刪除或更正損壞的樣本,以最大化帶噪驗證集上的分類性能。
更正錯誤標簽的過程首先要將數據中的錯誤標簽移除,這一過程會產生有標注和無標注的數據集,可以用半監督學習方法訓練這個新的數據集或者對未標注數據重新標注[49]。為了更好地利用半監督學習,標簽移除的過程可以通過每次迭代來完成,從而動態地更新數據集。直接刪除錯誤標注的實例,其思想類似于離群值檢測[26]和異常檢測[27]。例如,可以簡單地使用基于異常的測量方法,移除高于給定閾值的樣本。還可以刪除不成比例地增加模型復雜度的樣本[28-29]。在這些刪除錯誤標注實例的方法中,存在移除過多數據的風險。因此,為了防止不必要的數據丟失,應盡可能少地刪除樣本。
數據清洗的一種思想是識別錯誤標簽并將其更正。如果干凈的樣本足夠多,多到可以訓練一個模型時,可以通過該模型的預測來重新標注損壞樣本[50]。基于這種思想,Jaehwan等[51]提出用給定噪聲標簽和預測標簽的Alpha混合來重新標注樣本。Lee 等[52]提出一種名為CleanNet的聯合神經嵌入網絡。該方法從小部分人工驗證的類別中總結出標簽噪聲的知識,然后進行遷移學習,將知識轉移到其他類別以處理標簽噪聲。Yuan等[53]提出一種迭代交叉學習策略(iterative cross learning, ICL)來處理深度學習訓練數據中的標簽噪聲問題。該方法將含噪數據集隨機劃分成多個單獨的子集,每個子集用于訓練獨立的網絡,用這些獨立的網絡預測原始數據的標簽,如果它們得出預測結果一致,則將標簽更改為預測標簽,否則將標簽設置為隨機標簽。與保留噪聲標簽不同,設置成隨機標簽有助于打破噪聲中的結構,使噪聲在標簽空間中的分布更加均勻。類似地,Jiang等[49]提出一種隨機標簽傳播算法(random label propagation algorithm, RLPA)來清除噪聲。具體來說,隨機選擇一些訓練樣本作為“干凈”樣本,將其余樣本設置為未標記樣本,用SSPTM (spectral-spatial probability transform matrix)將標簽信息從“干凈”樣本傳播到未標記樣本。重復此過程,為每個樣本生成多個標簽,最后采用多數投票算法確定最終標簽。Nguyen 等[54]提出使用給定標簽和模型預測的移動平均值之間的一致性來評估給定標簽是否有噪聲,在下一次迭代中用干凈的樣本訓練模型,這個過程一直持續到模型收斂到最佳估計量;基于同樣的方法,在另一項研究中稍作調整,不是將預測的移動平均值與給定的標簽進行比較,而是與當前epoch中的預測標簽進行比較[55]。
數據清洗的另一種思想是直接刪除錯誤標注的樣本。如通過概率分類器可以把訓練數據分為干凈樣本集和噪聲樣本集,根據這些子集的大小估計噪聲概率[50],之后根據基網絡對數據的輸出置信度和估計噪聲率去除大部分不可信數據。雖然這樣會導致信息丟失,但在減輕噪聲帶來的負面影響方面會取得更好的性能。Koh等[56]提出用一個影響函數來判斷哪些樣本對模型訓練是有害的。由于該方法需要計算每個訓練樣本對所有驗證樣本的影響,因此不易在工業實踐中應用。Huang等[57]提出了O2U-Net標簽噪聲探測方法,該方法通過周期性地調整學習率,使網絡的狀態周期地在欠擬合和過擬合之間轉變,如圖2所示。記錄下每個樣本的平均損失值,循環訓練結束后,實驗者將所有樣本的平均損失降序排列,把前k%的樣本作為含有標簽噪聲的數據從原始數據中刪除,其中k的取值取決于數據集的先驗知識。最終實驗結果表明,刪除這些數據之后,網絡的性能得到顯著提高。當數據中含有大量噪聲時,直接刪除帶噪樣本可能使訓練集變得過小,影響最終模型的效果。針對該問題,Zhu等[58]提出了CORES2(confidence regularized sample sieve),與前幾種方法不同的是,在區分出干凈樣本和噪聲樣本之后,該方法刪除噪聲樣本的標簽而保留其特征,使用篩選過的數據訓練DNN。
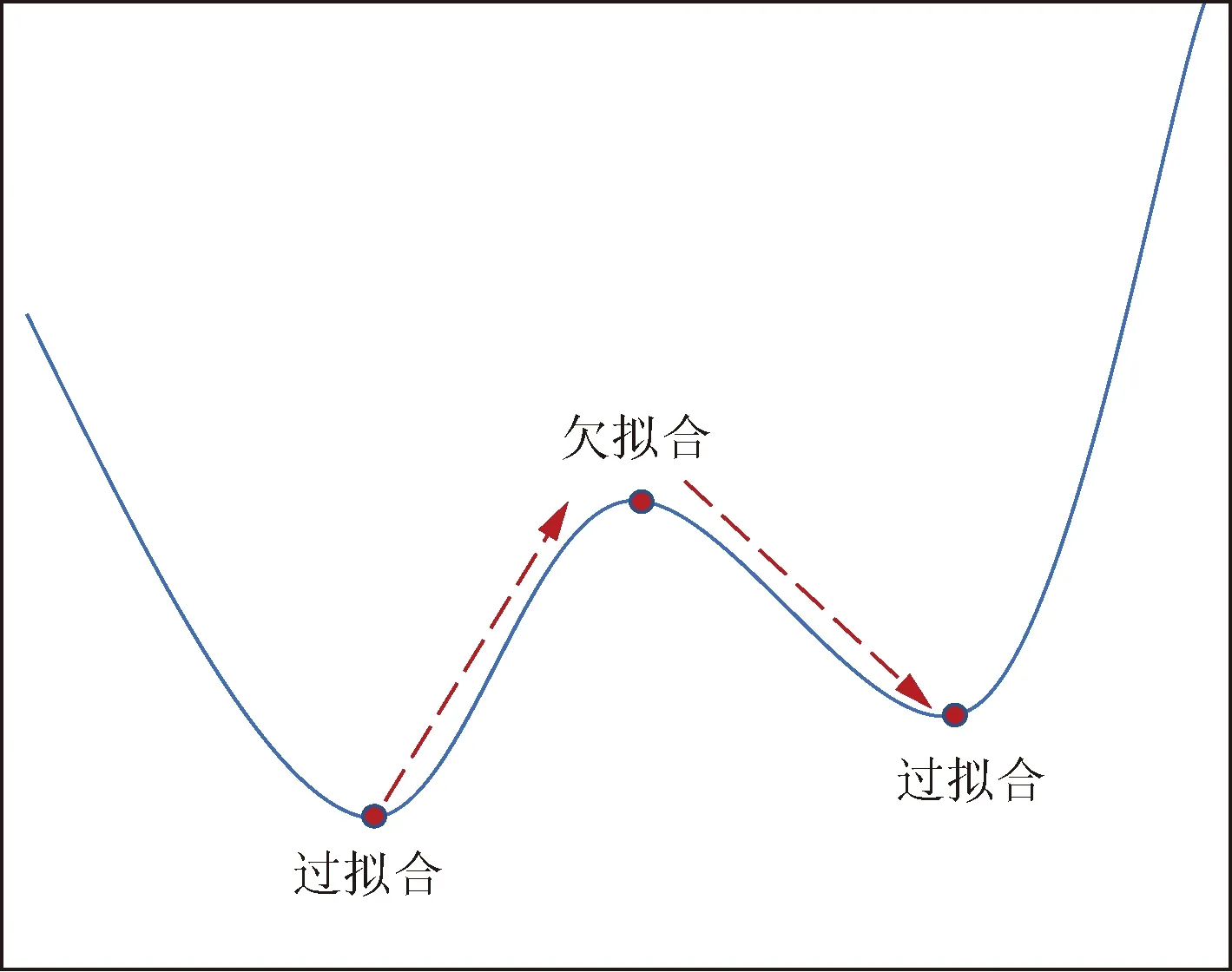
圖2 情感識別系統框架[57]Fig.2 O2U-Net cyclical training[57]
3.3 神經網絡訓練策略
神經網絡已經在各領域取得很大進展,但常出現對數據集中的噪聲標簽過擬合現象,在訓練過程中通過不同學習策略提高整個過程的魯棒性一直是近幾年的研究熱點,主要包括以下幾個角度。
(1) 損失函數。Patrini等[59]先用ERM (empirical risk minimization) 訓練神經網絡,然后估計噪聲轉移矩陣,用該矩陣構建的修正損失函數來重新訓練模型。Xu等[60]提出了一種新的基于信息論的損失函數LDMI(determinant based mutual information),該損失函數可直接應用于任何分類神經網絡,且對instance-independent標簽噪聲具有魯棒性。
(2) 數據集。與4.2節不同,此處并沒有對數據集的標簽做任何處理。Zhang等[61]提出利用少量可信數據檢測離群點樣本和復雜訓練集bug的方法DUTI (debugging using trusted items)。但該方法需要對目標函數作一個強凸假設,而這樣的假設一般情況下很難成立,所以該方法并不能適用于大多數深層神經網絡。Guo等[62]提出了CurriculumNet,通過分布密度對訓練數據的復雜度進行排序,將訓練數據劃分為多個子集。每個子集作為一個curriculum逐步讓模型理解標簽噪聲。Mirzasoleiman等[63]提出一種利用深度神經網絡訓練帶噪數據的新方法CRUST,該方法的核心思想是選擇干凈數據點的加權子集組成coresets,這些coreset可以使網絡參數矩陣的雅可比矩陣低秩。具體為步驟為:①利用近似低秩雅可比矩陣提取干凈子集;②進一步減少子集中的錯誤;③迭代降噪。為了獲得良好的泛化性能并避免過擬合,CRUST 迭代地選擇提供近似低秩雅可比矩陣的干凈數據點子集。
(3) 雙網絡。從雙網絡角度出發的代表性方法是Decoupling[64]和MentorNet[65]。Decoupling方法用兩個網絡預測結果不同的樣本來更新模型,但噪聲標簽仍均勻分布在樣本的整個空間中,disagreement區域存在大量噪聲標簽,因此Decoupling方法不能很有效地處理噪聲標簽。MentorNet方法先預訓練一個的網絡,用該網絡選擇干凈的數據來指導訓練。當無法得到干凈數據用來驗證時,MentorNet必須使用預定義的curriculum,比如self-paced curriculum,但存在因樣本選擇偏差導致誤差積累的缺點。MentorNet與上一段提到的CurriculumNet,以及O2U-Net都基于以下假設:在網絡欠擬合時,梯度計算由干凈樣本主導。因此,標簽噪聲的比例和分布會對這些工作產生很大的影響。Han等[66]對上述問題進行了改進,每個網絡選擇干凈的數據(損失率小的樣本)并讓另一個網絡在其選定的干凈子集上進行訓練,三種網絡的對比如圖3所示。
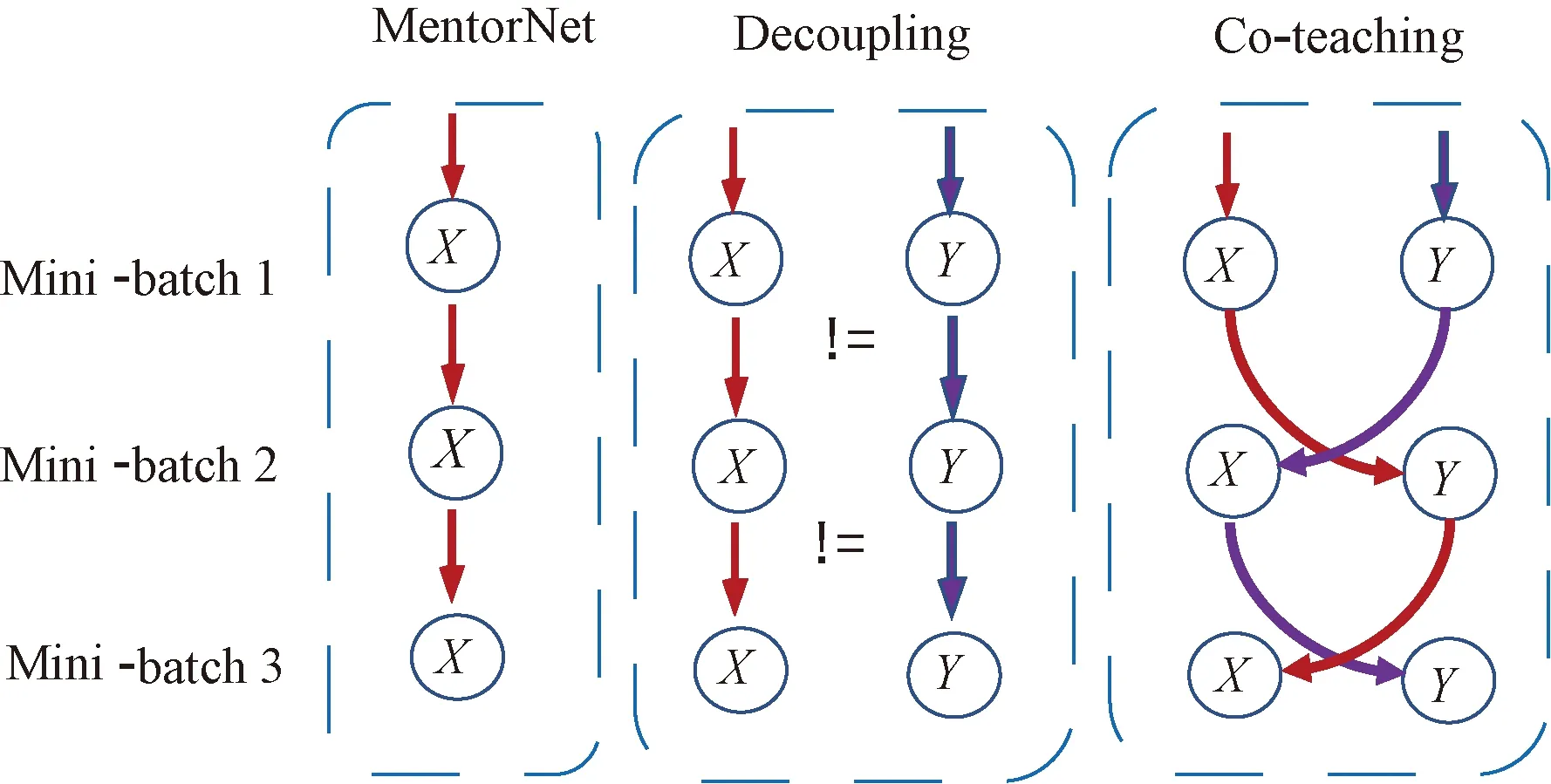
圖3 MentorNet, Decoupling和 Co-teaching的誤差流向對比[66]Fig.3 Comparison of error flow among MentorNet, Decoupling and Co-teaching[66]
中國也有很多從雙網絡的角度克服標簽噪聲的研究,其中具有代表性的是周彧聰等[67]通過結合簡單樣本挖掘和遷移學習的思想提出的互補學習方法。該方法同時訓練一主一輔兩個深度神經網絡模型,將輔模型的知識遷移給主模型,從而減少標簽噪聲的影響。
(4) 噪聲轉移矩陣。在標簽噪聲學習中,噪聲轉移矩陣表示干凈標簽轉為噪聲標簽的概率。Xia等[68]設計了一個基于深度學習的風險一致估計器(risk-consistent estimator)來準確地調整轉移矩陣。Chen等[69]將交叉驗證用于估計噪聲轉移矩陣,之后采用Co-teaching策略充分利用識別出的樣本來訓練DNN。
3.4 小結
將處理標簽噪聲的方法分為標簽噪聲魯棒模型、數據清洗、深度神經網絡魯棒訓練三種。標簽噪聲魯棒模型旨在對傳統方法進行改進以提高其魯棒性,數據清洗主要用于神經網絡訓練的預處理階段,深度神經網絡的魯棒訓練是在不改變數據標簽的情況下,通過改變訓練策略來提高訓練魯棒性的方法。圖4所示為所討論的處理標簽噪聲的所有前沿算法。
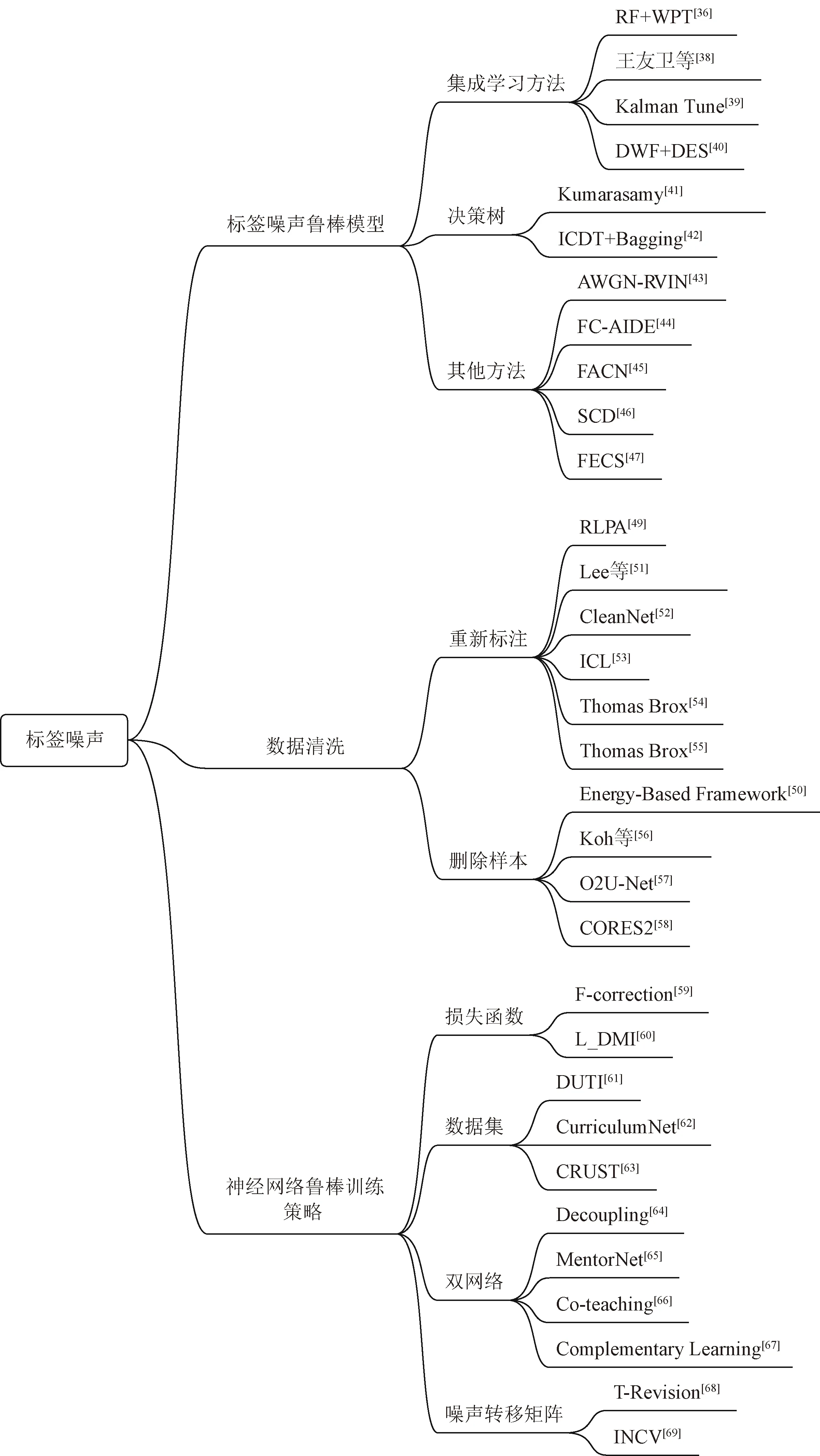
圖4 處理標簽噪聲前沿算法小結Fig.4 Summary of algorithms for processing label noise
4 研究現狀分析
對標簽噪聲的研究可以追溯到三十多年前[70],在最近幾年仍然活躍。為研究標簽噪聲的發展趨勢,調研了2016—2020年發表在機器學習與人工智能相關的五大頂級會議AAAI、ICML、NeurIPS、CVPR、IJCAI上的論文,對研究標簽噪聲的相關論文進行統計分析,統計結果如表1所示。
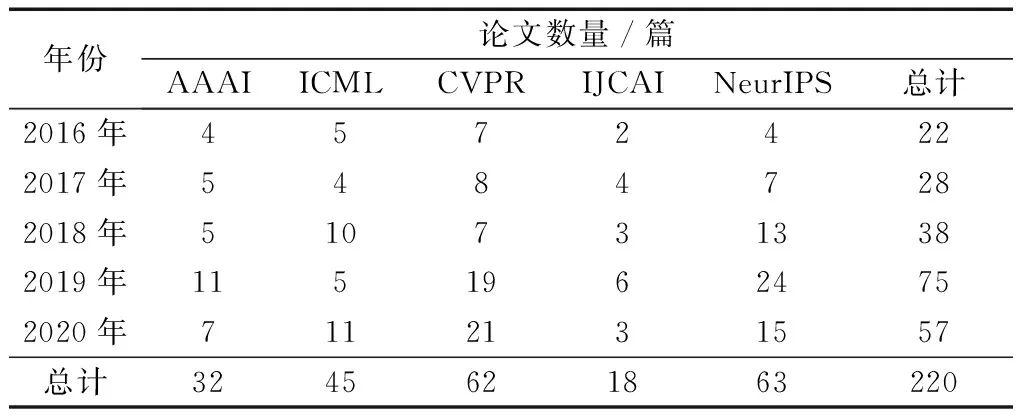
表1 2016—2020 年五大頂級會議上關于標簽噪聲學習的論文統計Table 1 Papers focusing on label noise published on the top five conferences from 2016 to 2020
自2016年以來,共有220篇關于標簽噪聲學習的論文發表在上述五大頂級國際會議中,統計調查后得到如下結論。
(1)從論文的數量上可以看出,標簽噪聲的研究在2019年達到了一個小高潮。同2019年相比,2020年關于標簽噪聲的論文數量雖略有減少,但仍領先于前幾年,可以看出標簽噪聲學習在機器學習以及人工智能領域的熱度仍居高不下。
(2)從論文的內容上來說,關于標簽噪聲的這220篇論文中既包括理論的研究,又包括應用的研究,且在數量上分布比較均勻,可以看出標簽噪聲研究在機器學習以及人工智能領域具有非常可觀的理論研究價值和實際應用價值。 2020年中對解決標簽噪聲問題的貢獻頗多,在此列舉幾項突出的貢獻。針對嚴重標簽噪聲問題,利用小的低成本、高價值可信集合來估計樣本權重和標簽,再以有監督的方式訓練模型,可提高對標簽噪聲超過90%的魯棒性[71]。針對噪聲標簽和真實標簽通常難以區分的問題,LDCE (label distribution based confidence estimation)可以用來估計觀察標簽的置信度[72],不過仍需要更有效的方法估計和利用標簽置信度。
5 結論與展望
分類系統無論是在理論方面,還是在應用方面都獲得了巨大的成就。但是,取得這些成就離不開強監督信息的支持。目前,存在許多不同的技術來處理標簽噪聲,雖然這些方法在一定程度上取得了較好的效果,但仍有許多問題亟待解決。
(1)在實際的工作場景中,數據標簽的質量決定了最終分類結果的上限,通過算法的調優可以向該上限逼近。文中所提及的多數方法只在數據受標簽噪聲污染程度較小情況下效率高,當帶噪數據的規模接近或大于干凈數據規模時,算法的效率會顯著下降。在工業實踐中,樣本數據中標簽噪聲往往規模巨大且結構復雜。因此,解決極端情況下的標簽噪聲問題是該研究課題的重點,也是難點所在。
(2)實際數據中的標簽噪聲可能會更加復雜。一方面,標簽噪聲的來源可能并不唯一。另一方面,基于網絡爬蟲等技術的標簽生成方法存在開集問題[7],即部分訓練樣本的真實標簽可能不在給定的標簽空間內。此外,實際數據集中可能同時存在特征噪聲和標簽噪聲,有效利用這種低質量數據集進行訓練也是該研究課題的重點和難點所在。
(3)將監督學習同無監督學習進行結合處理標簽噪聲是該課題的研究思路。在這種框架中,無監督學習學習出的可信賴表示不受噪聲影響,可以提供好的度量關系并且可以對監督學習下的表示進行修正[73]。由于需要額外的進行無監督的計算,所以該方法會受到無監督學習的瓶頸,且在大型數據集上適用度不高。隨著自監督學習的興起,為這個問題指明了方向,將這種框架應用于大型數據集提高分類任務的精度是未來該研究課題的一個方向。
(4)對標簽噪聲的研究存在更廣闊的應用場景值得探索。在計算化學領域,由于外部條件和實驗成本的限制,很多數據集中含有噪聲,如何克服噪聲高效地利用這些數據進行分類(例如判斷化學反應的方向)和回歸(如分子的屬性值預測)任務是該研究課題的一個比較新穎的方向。多標簽分類是分類問題中的常見任務,其在醫學、文本中的應用較為廣泛,例如合并癥預測[74]、災情信息檢測[75]等。將效果較好的多標簽分類模型應用于一些公開的分子數據集,為藥物研制提供幫助也是一個較為新穎的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
