融合自注意力機制的Conv-LSTM邊坡位移預測方法
2022-12-05 05:08:22鄭海青趙越磊宗廣昌孫曉云
金屬礦山 2022年11期
鄭海青 趙越磊 宗廣昌 孫曉云 靳 強
(1.石家莊鐵道大學電氣與電子工程學院,河北 石家莊 050043;2.河北金隅鼎鑫水泥有限公司,河北 石家莊 050200)
位移作為表征邊坡穩定性程度的重要指標[1-2],對其進行實時可靠地監測、預計,對于及時了解邊坡安全狀態、準確地進行變形估計具有重要意義。
近年來,不少學者對邊坡位移預測方法進行了研究,涌現出了一批理論和方法[3]。如基于經驗公式建立的蠕變理論[4-5],主要利用巖土力學相關公式進行運算,無法對邊坡位移影響因素的復雜性和多變性進行研究。基于蠕變理論的邊坡預測方法主要是針對滑坡現象,但巖質邊坡的變形破壞機理有別于滑坡,變形量較小,傳統的經驗預報模型對于巖質邊坡適用性不強。由于統計學模型[6]可以解決經驗公式無法結合邊坡位移影響因素以實現預測的問題,晏凱等[7]采用自回歸求和滑動平均模型(Autoregressive Integrated Moving Average,ARIMA)和Holt-Winters方法分別建立了邊坡位移預測模型,試驗結果表明預測效果很好,但兩種模型的普適性較差且只適用于短時預測。為了得到更理想的預測效果,學者們提出了基于機器學習和深度學習的邊坡位移預測模型[8-9],利用其出色的非線性映射能力來提高預測精度。ZHANG等[10]建立了基于長短期記憶網絡(Long Short-Term Memory,LSTM)的邊坡位移預測模型,并對LSTM網絡內部的超參數進行優化從而獲得較好的預測效果,但運算時間較長,時效性較差;GUO等[11]將多個稀疏自編碼器的誤差進行融合,并與LSTM相結合對機械故障時間序列進行了預測;VIDAL等[12]建立了CNN-LSTM混合模型對金價的波動進行預測,相對于LSTM模型,混合模型預測精度有了一定程度提高。以上預測模型主要采用組合模型以提高模型的預測精度,很少考慮在結構上對模型進行優化。
由于卷積神經網絡(Convolutional Neural Networks,CNN)在提取特征的過程中,池化層主要通過降低數據維度和減少參數量對特征進行壓縮,已有研究結果表明,在某些特定的任務中,去掉池化層能有效提高網絡的性能。ZHANG等[13]利用卷積—長短期記憶網絡(Conv-LSTM)和全連通長短期記憶網絡(FC-LSTM)進行人體動作識別,識別效果較好。AI等[14]采用Conv-LSTM預測方法來解決預測中空間相關性和時間相關性問題。CICEK等[15]利用Conv-LSTM模型預測智能手機剩余電池容量,結果表明,Conv-LSTM模型的預測效果相對于CNN-LSTM模型有一定的優勢。
開采中的礦山邊坡變形受各種因素影響,基于邊坡變形監測數據,并結合工程現場的主要影響因素,建立多因素的位移預測模型,有助于實現對邊坡變形規律的可靠分析。本研究搭建了融合自注意力機制的Conv-LSTM位移預測模型,對河北金隅鼎鑫水泥有限公司某開采中的礦山邊坡進行位移預測,針對去掉池化層后可能引起的過擬合問題,引入Dropout正則化方法對模型進行優化;為充分提取邊坡位移時序中的關系特征,引入了自注意力機制。
1 融合自注意力機制的Conv-LSTM 預測模型構建
自注意力機制(Self-Attention Mechanism)是TREISMAN和GELADE于2014年提出的一種模擬人腦注意力機制的概率模型,能有效捕捉數據的動態變化特征,使得相關性分析更加準確。
傳統神經網絡在處理預測問題時,每次只會采用獨立的數據向量,沒有一個類似“記憶”的概念,用來處理和“記憶”有關的各種任務。循環神經網絡(Recurrent Neural Network,RNN)的提出,在一定程度上解決了上述問題,但處理長期依賴性問題時容易出現梯度消失的問題。長期短期記憶網絡(LSTM)引入了門控結構使網絡不僅能記憶過去的信息,同時還能選擇性地忘記一些不重要的信息從而實現對長序列的建模。本研究建立了一種融合自注意力機制的Conv-LSTM位移預測模型,對采集的邊坡位移時間序列進行建模分析,網絡結構如圖1所示。
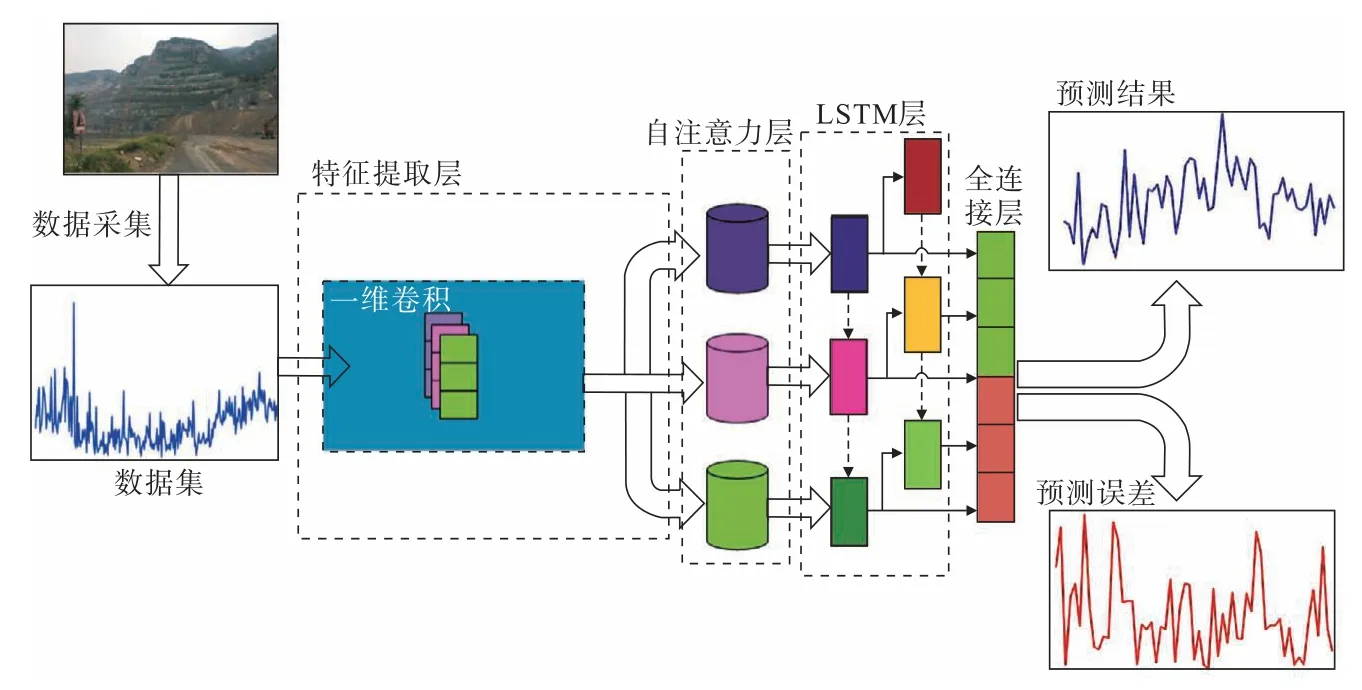
圖1 融合自注意力機制的Conv-LSTM位移預測模型Fig.1 Displacement prediction model based on Conv-LSTM and self-attention mechanism
在試驗中采集到的每條數據記錄包括當日最低溫度、最高溫度、濕度、降水量和位移值,因此預測模型的輸入為由最低溫度、最高溫度、濕度、降水量和位移值構成的向量,該向量先經過卷積層進行特征提取,然后經過自注意力機制層提取數據內部特征,最后,將提取到的特征輸入LSTM模型進行位移時間序列預測。
圖1中自注意力機制采用多頭注意力機制,其原理是將多個點積注意力機制的計算結果進行拼接,圖2為其數據處理示意圖,同一輸入向量X經過兩次點積注意力機制處理,就會得到兩組權重矩陣和兩組Q、K、V矩陣。如果輸入向量X經過h次點乘注意力機制計算,再將h次的結果進行拼接,就得到了多頭注意力機制模型的輸出[16]。
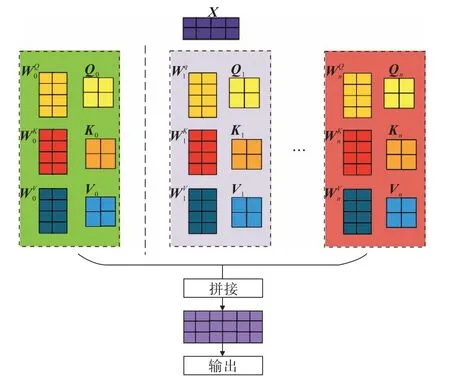
圖2 多頭注意力機制數據處理過程示意Fig.2 Schematic of data processing procedure of multi-head attention mechanism
自注意力機制能夠很充分地提取特征,得到句子中每個單詞之間的關系,應用到邊坡位移預測方面能夠有效地提取數據集中元素的前后關系。另外,自注意力機制在計算過程中,相比于卷積層提取特征的過程,可以有效降低計算量,減少模型訓練的時間成本。
2 試驗結果分析
2.1 數據獲取
試驗采用的數據來自河北金隅鼎鑫水泥有限公司礦山邊坡位移監測項目。工程現場點位布置如圖3所示。該工程在礦山的5個橫斷坡面上共設置了13個監測位點,呈網格化分布,有利于分析坡體的整體穩定性。

圖3 工程現場點位布置示意Fig.3 Schematic of the layout of engineering site points
結合工程現場所在地理位置,通過對采集數據進行相關性分析,并參考現場工作人員的經驗,得出影響該處邊坡位移的主要因素有溫度、空氣濕度和降水量。因此,本研究將最低溫度、最高溫度、濕度、降水量和歷史位移值5個參數作為預測模型的輸入。選取監測點G102在2019年6月1日—2020年7月14日所測數據(表1)作為樣本集進行試驗。

表1 監測點G102的部分數據Table 1 Some data of monitoring point G102
2.2 數據預處理
為消除奇異樣本帶來的訓練時間增大問題,采用極大極小歸一化方法對數據進行預處理,即:
式中,x為原始數據;x′為歸一化后的數據;max(x)為樣本中的最大值;min(x)為樣本中的最小值。
采用均方根誤差(Root Mean Square Error,RMSE)、均方誤差(Mean Square Error,MSE)、平均絕對百分比誤差(Mean Absolute Percentage Error,MAPE)和對稱平均絕對百分比誤差(Symmetric Mean Absolute Percentage Error,SMAPE)作為模型評價指標,各指標計算公式分別為

2.3 預測結果
通過對采集到的邊坡數據樣本進行分析,并對比不同卷積層層數、卷積核大小及LSTM層數對預測結果的影響,確定了邊坡位移預測模型的結構,如圖4所示。為改善去掉池化層后可能引起的過擬合問題,引入了Dropout正則化方法。
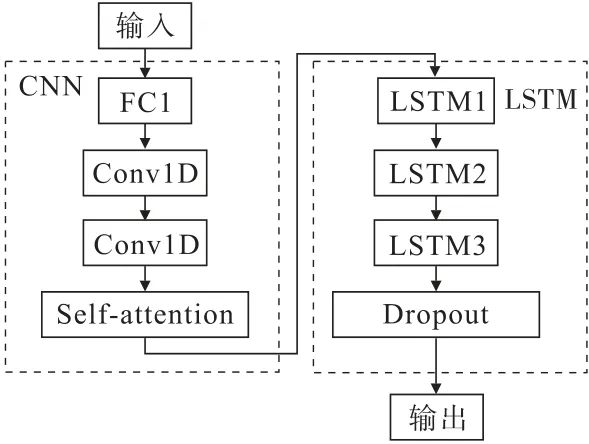
圖4 融合自注意力機制的邊坡位移預測模型結構Fig.4 Structure of slope displacement prediction model based on self-attention mechanism
試驗中的主要超參數設置見表2。5種模型預測結果見表3,引入自注意力機制的Conv-LSTM模型的預測結果如圖5所示,預測誤差曲線如圖6所示,可以看出預測模型的最大誤差為0.05左右。

表2 主要超參數設置Table 1 Setting of main hyper-parameters

表3 不同模型預測結果Table 3 Prediction results of different models

圖5 融合自注意力機制的Conv-LSTM模型預測結果Fig.5 Prediction results of Conv-LSTM model combined with self-attention mechanism

圖6 預測誤差曲線Fig.6 Curves of prediction error
由表3可知:傳統BP神經網絡運行時間最短,但預測結果較差;引入自注意力機制的Conv-LSTM模型的平均絕對百分比誤差僅為0.441,與Conv-LSTM模型相比降低了約1個百分點,與CNN-LSTM模型相比降低了將近3個百分點。同時,引入自注意力機制的Conv-LSTM模型的預測均方根誤差僅為0.029,可見其擬合程度較好,而Conv-LSTM模型為0.101,CNN-LSTM模型為0.197。在運行時間方面,引入自注意力機制的Conv-LSTM模型的運行時間相比Conv-LSTM模型進一步縮短,節約了時間成本,模型的泛化性能得到了進一步提升。
綜上分析可知:引入自注意力機制的Conv-LSTM預測模型獲得了較好的預測結果,而且時間成本較低,其平均絕對誤差與 CNN-LSTM模型相比降低了將近3個百分點。引入的多頭注意力機制擴展了模型集中于不同位置的能力,使模型的泛化能力得到了一定的提升。
3 結 論
(1)通過對河北金隅鼎鑫水泥廠采集到的邊坡位移序列進行分析,在Conv-LSTM邊坡位移預測模型的基礎上,引入自注意力機制,關注位移時序中關鍵特征,建立了融合自注意力機制的Conv-LSTM邊坡位移預測模型。
(2)通過自注意力機制提取了邊坡位移時間序列中的關鍵時序元素內部特征,并與BP神經網絡模型、CNN-LSTM預測模型、LSTM預測模型及 Conv-LSTM預測模型相比,所提出的模型預測精度最好,且運算速度較快。
(3)所提出的預測模型雖然具有一定的自適應能力,但仍存在對初始的學習率不夠魯棒的問題,在某些情況下依然可能陷入局部最優解,下一步可根據方差的潛在散度動態地打開或關閉學習率,從而提升模型的魯棒性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
四川勞動保障(2021年9期)2022-01-18 05:11:08
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
中國衛生(2016年9期)2016-11-12 13:28:08
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛生(2015年9期)2015-11-10 03:11:12
核科學與工程(2015年4期)2015-09-26 11:59:03
中國衛生(2014年3期)2014-11-12 13:18:12
