單幅圖像超分辨率重建技術研究進展
2022-12-03 14:30:54張芳趙東旭肖志濤耿磊吳駿3劉彥北
自動化學報 2022年11期
張芳 趙東旭 肖志濤 耿磊 吳駿,3劉彥北
圖像分辨率指的是圖像所包含的細節量,體現成像系統對物體實際細節的反映能力.超分辨率(Super-resolution,SR)技術起初指的是可以提高光學成像系統分辨率的技術,現在常指可以將單幅或多幅低分辨率圖像經過處理轉換成高分辨率圖像的方法[1].超分辨重建技術是信息光學、數字圖像處理與模式識別、計算機視覺、機器學習等多領域結合的學科,在醫學成像[2]、生物信息識別[3-4]、智能交通、安防監控等領域受到了廣泛關注.
1964 年和1968 年,Harris[5]和Goodman[6]分別發表文章提出SR 重建的概念,但當時并未得到廣泛認可.直到20 世紀80 年代,特別是1984 年Tsai等[7]提出頻域中基于圖像序列的方法之后,SR 重建技術才取得了突破性進展.之后國內外眾多研究者對SR 問題進行深入研究,一些權威期刊,如Transactions on Pattern Analysis and Machine Intelligence、International Journal of Computer Vision、Pattern Recognition、Signal Processing和Image Communication等都刊登SR重建領域文章.除此之外,幾個計算機視覺領域的重要國際會議也收錄此類文章,如Computer Vision and Pattern Recognition、International Conference on Computer Vision、European Conference on Computer Vision、英國機器視覺會議、國際信息處理會議和人工智能國際聯合大會等.2016 年以來,有一項專門針對SR 技術的國際比賽New Trends in Image Restoration and Enhancement(NTIRE),之后NTIRE 逐漸被全球學者關注.這些會議和比賽大大推動了圖像SR 重建技術的發展.
近年來,各大研究機構和相關技術人員已經開放SR 重建技術的數據庫,極大地推動了SR 重建研究工作的進一步開展,涌現了大量研究成果.國外伊利諾伊大學厄巴納香檳分校的Yang等[8-9]、加州大學圣克魯茲分校的Nguyan等[10]、法國科學院的Yu等[11]、以色列理工學院的Elad等[12]和蘇黎世聯邦理工學院的Timofte等[13]等;國內中國科學院的Cui等[14]、中國科學技術大學的Song等[15]、香港理工大學的Wang等[16]、香港中文大學的Dong等[17]、西北工業大學的Zhu等[18]、西安電子科技大學的Gao等[19]和Dong等[20]等,在SR 研究中都取得了顯著的進展[21].
鑒于國內外SR 圖像重建領域取得的豐富成果,近年來陸續有學者對這些研究成果進行了歸納和分析,形成了一些優秀的綜述文章.文獻[22]按照不同的低分辨率(Low-resolution,LR)輸入和SR 輸出情況對傳統SR 重建方法進行分類整理,文獻[23]與文獻[24]介紹了基于深度學習的圖像SR復原方法的研究進展.本文以單幅圖像作為研究對象,對基于傳統方法和深度學習的SR 重建方法進行歸納與分析,從基于插值和基于學習兩方面對單幅圖像SR 方法進行綜述,對目前各種SR 方法按網絡結構進行劃分,在此基礎上按不同應用場景和不同降質方式進行分類討論,并對傳統方法和深度學習方法之間的聯系進行了介紹,總結了傳統理念在深度學習方法中的延續與應用.文章最后結合數據集對方法的性能和魯棒性進行了比較,并展望了該領域未來的發展方向,以供相關領域的研究者參考.
1 圖像SR 重建概述
1.1 圖像質量退化模型及SR 重建思路
成像過程中,由于設備本身存在缺陷并且受采集環境影響,會導致得到的圖像模糊、關鍵信息不詳細等問題.設低分辨率圖像y是由高分辨率圖像x經過一系列變換得到的,退化過程如下:
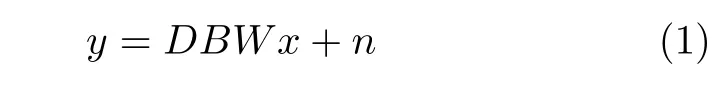
式中,D為亞采樣矩陣,B為光學模糊矩陣,W為幾何運動模糊矩陣,n為加性高斯白噪聲.由于從硬件方面改善上述不足所需要的成本較高,因此,通過軟件完成后期圖像處理來彌補設備采集的缺陷,不僅可以降低成本,還能滿足學者們的需求.圖像SR 重建是一種軟件圖像處理技術,SR 重建為上述圖像退化的逆過程,旨在已知輸入的低分辨率圖像y的情況下,通過不斷優化SR 重建模型,獲取更接近于高分辨率 (High-resolution,HR)圖像x的SR 圖像xsr.由于上述SR 重建自身的病態性[25]和較高的實用價值,使其在計算機視覺領域具有很大的理論研究空間和應用空間,因而受到長期關注.
1.2 SR 重建技術的發展及分類
起初在圖像復原和圖像增強技術中,為了恢復單幅圖像因超出光學系統傳遞函數極限而缺失的信息,需要估計該圖像上的頻譜信息進行頻譜外推[26-27]從而提高圖像分辨率,因而產生了一系列頻域SR方法,包括基于傅里葉變換的SR 方法和基于小波變換的SR 方法等.后來,由于空域法能夠建立全面的觀測模型,還具有包含空域先驗信息的能力,所以眾多學者針對空域法進行了大量研究.
本文主要論述基于單幅圖像的空域SR 重建(Single image super resolution,SISR),將從基于插值和基于學習兩方面介紹單幅圖像SR 重建技術,方法分類如圖1 所示.本文第2 節介紹基于插值的SR 方法,第3 節闡述基于學習的SR 方法.鑒于基于學習的SR 方法是目前的研究熱點,內容較多,本文在第3~4 節由淺入深地進行重點闡述與分析.第3 節分析基于傳統淺層學習的SR 方法,第4 節對基于深度學習的SR 方法展開探討,第5 節闡述深度學習SR 方法與傳統SR 方法的聯系與區別,第6 節介紹圖像SR 重建數據集以及SR 重建圖像評價方法,第7 節進行總結和展望.
2 基于插值的圖像SR 重建
基于插值的重建方法是根據放大因子在已有像素之間插入一定數量的新像素補充HR 圖像缺失的像素,并且將插值后的圖像像素數據與插值卷積核進行卷積,相當于對圖像進行平滑處理.在傳統插值方法中,根據插值實現方式可分為最近鄰插值[28]、雙線性插值[29]、雙三次插值(Bicubic interpolation,BI)[30]等.基于插值的SR 包括以下3 個步驟:
1)上采樣.獲得HR 圖像中與LR 圖像某些位置對應的已知像素;
2)插值.補充HR 圖像中缺失的像素;
3)去模糊.增強重建圖像質量.
其中,最近鄰插值最簡單,每一個缺失的像素都采用與其最相鄰像素相等的強度值,但鋸齒現象明顯,放大效果不理想.雙線性插值方法利用缺失像素點周圍4 個最鄰近已知像素點的像素值,采用水平和豎直兩個方向上的線性插值結果補充缺失的像素,放大的圖像鋸齒現象有改善,但邊緣模糊.雙三次插值利用待求像素點周圍4 × 4 鄰域內的16個己知像素點的值加權內插得到待求點像素值,其插值過程如圖2 所示.由圖2 可以看出,要想求得HR 像素點 (i+u,j+v)的像素值,需要用(i+u,j+v)點4 × 4 鄰域內的16 個己知LR 像素點的值進行加權運算.

圖2 雙三次插值過程示意圖Fig.2 Schematic diagram of the bicubic interpolation
雙三次插值方法是用一個三次多項式S(x)來逼近理論上的最佳插值函數 s in(x)/x,其數學表達式為:
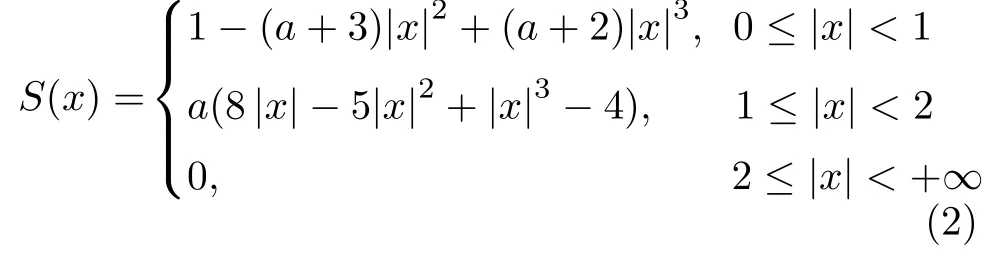
式中,a為自由變量,其取值范圍為 [-1,-1/2],一般取a為-1,將a=-1 代入式(2),得到:
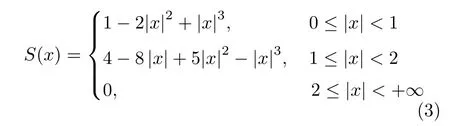
雙三次插值方法的基本公式為:
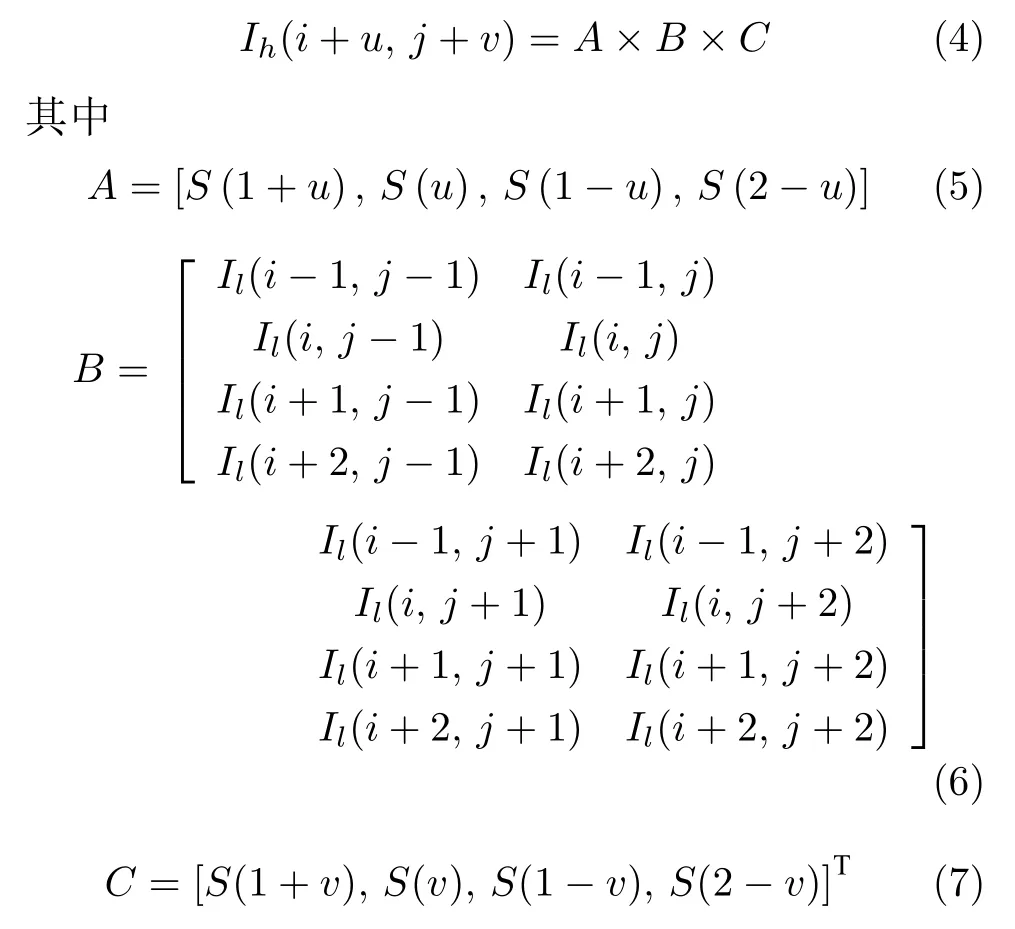
相對最近鄰插值和雙線性插值方法,雙三次插值能夠利用圖像中更多細節信息,有效地抑制圖像的塊兒效應和邊緣階梯失真現象,但運算復雜度較高,當輸出圖像不連續時會導致輸出圖像出現振鈴噪聲和邊緣模糊現象,需要通過圖像恢復進行修復.
為了克服以上傳統插值方法中的振鈴模糊問題,研究者們提出了一些針對圖像邊緣增強的非線性插值方法,包括基于邊緣的插值方法和基于小波變換的插值方法(見第5.1 節).基于邊緣的方法指的是利用圖像中像素的邊緣方向來控制插值方向對圖像進行插值.Kwok等[31]通過定向插值改善了鋸齒偽影現象,插值的方向由邊緣方向決定.Li等[32]提出了一種基于邊緣指導的圖像插值(New edge directed interpolation,NEDI)算法,該方法假設LR 和HR 圖像在邊緣處具有相同的邊緣信息,從而通過計算LR 圖像邊緣的局部協方差來推導出最佳線性超分辨映射的預測系數.雖然上述方法可以實現圖像邊緣處的銳化,但其算法復雜度高,為此,Chen等[33]對NEDI 算法進行了相應的改進,提出了一種快速邊緣導向的插值算法.針對NEDI 算法只是單獨針對LR 圖像中某一個像素值進行預測的缺陷,Zhang等[34]提出用圖像的局部方差對插值函數進行優化得到更好的插值結果,采用軟判決自適應插值算法來分析LR 圖像中相鄰像素之間的結構,從而實現一次性估計一組缺失像素的值,其中像素預測是由一個自適應不可分的2D 濾波器濾波實現的.這些方法可以得到較為完整的局部結構和比較銳利的邊緣.
基于插值方法屬于無樣本的單圖像超分方法,本質上屬于一種圖像增強.
3 基于傳統淺層學習的圖像SR 重建
為了解決SISR 重建這類欠定性問題,一個有效策略是在求解過程中引入圖像的先驗信息來正則解空間,更好地逼近真實解,從而獲得理想的HR圖像.基于正則化約束的SR 方法將先驗信息作為正則化約束項加入到圖像重構過程中,將圖像重構問題轉換為尋求滿足特定限制條件解的最優化問題,在求解方程中引入代價函數,然后迭代求解得到重建圖像,其求解表達式為:

式中,R(X)是正則化項,λ是決定正則化約束強度的參數.
正則化思想作為超分目標函數項,在基于樣例的方法和基于稀疏編碼的方法等基于淺層學習的SR 重建方法中均有大量的使用.常用的正則項包括2 范數形式的Tikhonov 正則項[35]、1 范數形式的全變差正則項[36]以及雙邊全變差正則項[37]等.Tikhonov 代價函數是單位矩陣或有限差分矩陣,對重建圖像中的高頻部分進行約束,從而減少重建過程中可能引入的高頻噪聲,但會使重建圖像變得光滑,趨向模糊.基于全變分模型的SR 方法將圖像梯度的范數作為正則化約束項[36,38],其正則化式為R(X)=‖?X‖1,其中?是梯度算子.正則化方法能直接加入先驗約束,有唯一解,收斂穩定性高,且具有較強的去噪能力.
基于學習的SR 方法通過機器學習算法從大量訓練樣本中獲得LR 圖像和HR 圖像之間的對應關系,并把這種關系運用到重建過程中,實現圖像的SR 重建,因此這類方法往往需要一個樣本庫來提供相應信息以供重建方法充分學習先驗知識.從解決此類基于樣本庫訓練問題的角度出發,本文將傳統SR 重建方法劃分為三類進行闡述:第1 類方法是基于樣例學習的方法,采用馬爾科夫隨機場和流形學習中局部線性嵌入的思想完成重建;第2 類方法是基于稀疏表示的方法,結合圖像稀疏編碼、字典學習以及圖像相似性的思想完成重建;第3 類是基于回歸的方法,建立高斯回歸、嶺回歸、隨機森林與卷積神經網絡等回歸模型的方法完成重建.
3.1 基于樣例學習的SR 重建方法
基于樣例學習的方法主要包括建立樣本庫和構建高頻子帶(重建)兩個獨立步驟.主要思想是:首先通過樣本學習建立LR 與HR 圖像之間的關系,然后利用此關系實現LR 圖像的SR 重建.此類方法最早源于Freeman等[39]提出基于馬爾科夫網絡的SR 重建方法,即利用馬爾科夫網絡最優化求解相關示例樣本.首先將HR 圖像塊與其對應的LR圖像塊作為樣本,通過馬爾科夫網絡模型建立原始圖像與樣本塊之間的關系,然后采用置信傳播算法對候選樣本進行近似求解完成學習過程,最后通過樣本中的高頻信息實現圖像的SR 重建.
將輸入的LR 圖像與目標HR 圖像都分割成小塊,每個圖像塊用一個馬爾科夫網絡節點表示,每個HR 節點與其對應的LR 節點相連,也與其相鄰的HR 節點相連,這兩類節點的聯合概率分別用Φ(xk,yk)和 Ψ (xk,yk)表示.這樣就把HR 重建的問題變成求解后驗概率的局部最大值,公式如下:
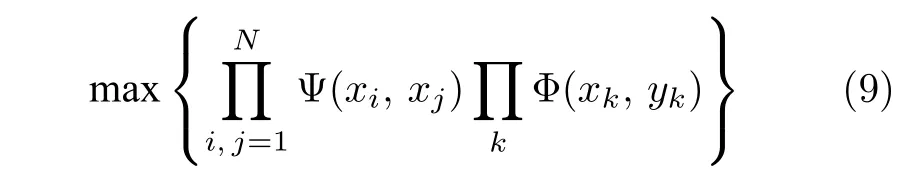
式中,N為相鄰域的大小.將馬爾科夫網絡中的每個LR 圖像塊 Φ (xk,yk)作為索引,在樣本庫中搜索最佳匹配樣本中對應的H R 圖像塊,記為Ψ(xk,yk).根據樣本庫采用置信傳播算法對其進行近似求解.在重建時,利用馬爾科夫網絡最優化求解(最大化馬爾科夫網絡的概率)找到最優的HR樣本塊,將高頻信息加到插值放大后的圖像上,得到重建的HR 圖像.
馬爾科夫網絡中的LR 節點只能從與其相連的一個HR 節點獲取到高頻信息,因此只能計算圖像塊局部關系,Wang等[40]使用條件隨機場引入多個新的節點,將每一個新的節點作為HR 節點和與其相鄰的所有LR 節點的橋梁,加強了節點間的相關性,從而建立高低分辨率樣本的全局關系.此外,由于人類視覺對異常的高頻信息比較敏感,而馬爾科夫網絡沒有阻止異常候選圖像塊的能力,所以該算法的重建結果中容易產生噪聲.為了解決這個問題,Chang等[41]提出一種利用局部線性嵌入來獲取k個近鄰點權重的方法,假設訓練樣本中的HR 圖像塊集合和與之對應的LR 圖像塊集合分別構成兩個具有相同局部線性結構的流形.根據此假設,HR 圖像塊便可以被其鄰域的相似結構線性表示,且權重系數相同,即求出k個最鄰近低分辨圖像塊的權重,并利用該組權重與對應的HR 圖像塊相乘求得最終的HR 圖像.鄰域嵌入方法可以利用較少的樣本表示出較多的變化模式,從而大幅降低計算量,但由于k值是固定的,因此會出現欠擬合或過擬合的現象.為此,Chan等[42]通過直方圖配準選擇相似的訓練圖像,選擇不同特征,并通過邊緣檢測針對不同類型的圖像塊選擇不同的鄰域數目,從而更好地完成圖像重建.Gao等[43]提出聯合學習的方法,將LR 圖像和HR 圖像的特征投影到統一空間,提高近鄰保持率.
3.2 基于稀疏表示的SR 重建方法
與Chang等[41]的流形假設不同,Yang等[8-9]提出了一種基于稀疏表示的SR 重建方法.該方法對訓練樣本集的幾何特征結構未做出任何假設,而是認為可以從同一場景的HR 圖像塊集合和與之相對應的LR 圖像塊集合中分別學習出一組耦合字典,并且任何一個HR 圖像塊和其對應的LR 圖像塊在耦合字典下具有近似相同的稀疏表示系數,通過這種思想來建立LR 圖像塊與HR 圖像塊之間所對應的一種特定映射關系(成對的字典).根據得到的LR 字典對輸入的LR 圖像進行稀疏編碼(求得輸入LR圖像的稀疏系數),依據該編碼和HR 字典重建出HR 圖像.
自然圖像在某種字典下具有稀疏性,可以將這種稀疏性作為正則化約束項.稀疏表示是在給定的超完備字典中用盡可能少的原子來表示圖像,圖像經過稀疏表示后可以獲得更為簡潔的表示方式,從而更容易獲取圖像中所蘊含的信息.信號x∈RN的稀疏表示過程可以用一個過完備字典Φ∈RN×M(N?M)的幾個基元的線性組合描述,公式如下:

式中,α是稀疏系數,大部分元素為零或接近零.x的稀疏表示系數正則化形式為:

式中,λ是用來權衡稀疏表示誤差和稀疏程度的正則化系數.
基于稀疏表示的圖像SR 重建方法包括字典訓練和稀疏編碼兩個重要步驟.字典訓練有以下兩種方式:1)由已知信號變換構造字典,例如離散余弦變換、離散傅里葉變換、小波變換、Curvelet 變換、Contourlet 變換等,但這種方法字典中的所有原子都是由少量的幾個參數決定或由簡單的仿射變換形成,因此原子形態不夠豐富,不能對圖像本身的復雜結構進行最優表示;2)通過對樣本集的學習構造字典,即字典學習算法,該方法構造的字典原子數量更多,形態更豐富,能更好地對信號或圖像本身的結構進行稀疏表示,其中K 次迭代奇異值分解(K-singular value decomposition,K-SVD)算法[44]和主成分分析算法[45]最為常見.稀疏分解算法主要有正交匹配追蹤算法[46]和迭代收縮算法[47].正交匹配追蹤算法的求解過程是先對所選原子進行Gram-Schmidt 正交化處理,然后將待求信號投影到正交化后的原子形成的空間上,得到待求信號在各個已選原子上分解的分量和余量,迭代分解使余量最小化,直到滿足預先設定的條件為止.正交匹配追蹤算法可以保證迭代最優,但其固有的局限性使得算法在K-SVD 字典學習時必須嚴格限制圖像塊的稀疏性,導致字典學習的精度降低,文獻[48]利用迭代收縮算法取代正交匹配追蹤算法構建稀疏表示系數,求解凸優化問題.在后續的研究工作中,此類方法的改進主要在這兩方面展開.
1)字典訓練優化
Yang等[9]提出的字典訓練方法在訓練階段可以在很好地表示LR 和HR 圖像空間的同時保證其具有相同的稀疏表示系數,但是由于重建階段對輸入LR 圖像稀疏表示系數的求解過程無法施加與訓練階段相同的約束,并不能保證求得稀疏表示系數是LR 和HR 圖像共有的系數,導致重建精度降低.為此眾多研究者提出一系列的高低分辨率字典訓練方法,來緩解LR 和HR 圖像空間稀疏表示系數的不一致問題,有效提升了重建的結果.Wang等[16]提出了一種半耦合字典的學習算法,這種算法假設LR 圖像塊和HR 圖像塊在相應字典下的稀疏表示系數存在線性關系,該算法放寬了約束條件的同時增強了圖像塊之間的映射能力,緩解了稀疏表示系數的不一致問題.Zeyde等[49]使用主成分分析算法投射LR 特征向量尋找對應子空間,使得LR 特征能夠被LR 字典更加精確地表示,同時,通過采用維度約減預處理和正交匹配追蹤算法計算LR 圖像塊的策略來提高稀疏表示模型的計算效率.Yang等[50]提出一種交錯空間的優化方法來訓練高低分辨率字典,其核心是把同步的聯合字典訓練方式變為交錯空間優化問題,但是由于該優化問題的高度非線性的非凸函數優化問題,很難找到一個較為理想的局部優化解,算法的時間復雜性也較高.He等[51]提出一種基于Bata 先驗的耦合字典訓練方式,有效緩解稀疏表示系數的不一致問題,改善了重建HR 圖像效果.此外,稀疏編碼的優化算法也相繼提出,文獻[52]針對耦合特征空間的HR 重建,提出了一種基于一致性稀疏編碼的SR 重建方法,主要思想是先獨立地訓練HR 字典和LR 字典,然后分別求得訓練HR 和LR 圖像的稀疏表示系數,把圖像變換到稀疏表示空間,最后再通過最小二乘法建立兩個空間稀疏表示系數之間的映射關系.雖然該方法可以提高重建精度,但是獨立的稀疏編碼方式,增加了其稀疏表示系數映射關系建立的難度.Zhao等[53]提出了一種基于自適應稀疏表示的SR 重建方法,通過產生一個合適的系數來平衡稀疏表示和協同表示之間的關系.Wang等[54]提出從訓練樣本集中學習到更有效的過完備字典,具有分辨率無關性的圖像表達(Resolution-invariant image representation,RIIR),被應用于快速的多級超分辨率圖像重建任務中.
2)稀疏編碼優化
一些研究工作指出,重建質量很大程度上取決于數據的幾何結構[55].因此,重點是探索這些潛在的幾何結構以增強現有的稀疏編碼穩定性.通過將圖像補丁的非局部信息轉換成稀疏系數,非局部稀疏編碼方法[56-57]被廣泛地提出用于圖像重建.
與上述通過外部數據集學習字典的方法不同,Glasner等[58]結合自相似思想和樣本學習的方法,利用圖像塊的冗余性和不同尺度的圖像塊來重建未知的HR 圖像塊,字典是從輸入圖像本身及其降質的圖像中學習到.需要重建的LR 圖像的結構模式沒有出現在一般的圖像數據集中,那么從這個數據集中學習到的映射關系就不能很好地恢復圖像的紋理細節,因此在通過改進高低分辨率字典訓練方式來提升重建質量的同時,文獻[55-65]也在基于稀疏表示模型的基礎上引入圖像結構先驗約束來有效保持圖像的幾何結構來有效地避免此問題.Dong等[20]結合自適應稀疏領域選擇和自適應正則項重建出清晰的圖像邊緣,視覺效果良好.文獻[59]利用圖像的非局部自相似性來獲得原始圖像的稀疏編碼系數的良好估計,然后將觀測圖像的稀疏編碼系數集中到這些估計上.Yang等[60]利用了圖像的雙重稀疏性和非局部相似性約束,為了自適應地調整并表示HR 圖像塊的字典.上述常規模型僅考慮列非局部相似稀疏表示系數中的先驗,而沒有考慮稀疏表示系數的所有條目(或行)中的先驗,建模能力會受到限制.實際上,如果在稀疏表示系數空間中將相似表示系數的簇重新排列為矩陣,則列和行之間都存在非局部相似先驗.Li等[61]使用行非局部相似性先驗,探索具有l1范數約束的行非局部相似性正則化項.通過將引入到常規的列非局部相似性稀疏表示模型,提出了一個雙稀疏正則化稀疏表示模型.引入基于代理函數的迭代收縮算法來有效地解決該模型.Shi等[62]提出了一種基于低秩稀疏表示和自相似的SR 重建算法,然而該算法從字典對中學習大量原子的過程需要往往會消耗較長的時間.Li等[63]結合稀疏表示和非局部自相似性,提出了一種自學習的SR 重建算法,將字典學習和迭代過程融合到一起,能夠有效地減少訓練時間并提高算法的魯棒性.隨后,李進明等[64]通過增加低秩和非局部自相似性來約束LR 和HR 圖像的稀疏分解,這保證了稀疏求解的準確性,從而提高了傳統稀疏表示方法的重建性能.Lu等[65]引入非局部自相似和流形學習用于約束雙字典的幾何結構,從而保證圖像恢復細節的準確性.但是人為設計圖像先驗只針對少量特定圖像有較好效果,對普通自然復雜背景的圖像,重建HR 圖像質量顯著下降,HR 圖像重建模型的魯棒性較差.
3.3 基于回歸的SR 重建方法
使用稀疏字典進行SR 重建可以大幅提高圖像重建質量,但存在如下問題:1)稀疏字典在計算稀疏系數時計算量很大;2)不存在能夠稀疏表示所有圖像塊的全局字典,這不僅會使得SR 重建的先驗信息不準確,還會帶來因圖像塊過小限制模型感受野的問題.為了解決稀疏系數計算量大的問題,Kim等[66]提出僅訓練一個嶺回歸函數來預測HR特征,結合核匹配追蹤和梯度下降的思想來降低核嶺回歸(Kernel ridge regression,KRR)訓練和測試的時間復雜度.對于字典不完備的問題,可以通過建立回歸模型把一系列的非線性變換轉化成對數據的擬合,學習數據的內在分布.例如,Kim等[67]利用支持向量回歸(Support vector regression,SVR)來估計圖像的高頻細節.Deng等[68]在文獻[67]的基礎上,提出了基于多輸出二次支持向量回歸的SR重建算法,這種方法將從低分辨率圖像空間到HR圖像空間的非線性映射問題轉換為線性映射問題,有效地減少了參數的數量,同時能夠確保同一圖像補丁中各個像素點之間的關聯性.He等[69]通過高斯過程回歸(Gaussian process regression,GPR),選擇一個適當的協方差函數來估計HR 圖像的像素值.Wang等[70]在高斯回歸的基礎上,提出了一種基于字典樣本和Student-t 似然高斯過程回歸的SR 重建算法.Timofte等[71]將協同表示[72]應用到SR 重建,提出了基于固定鄰域回歸的SR 重建算法,這種算法通過學習錨定在字典原子上的稀疏表示系數和投影矩陣,實現快速地SR 圖像重建.隨后,Yang等[73]提出使用多元線性回歸從眾多圖像子空間中學習一組簡單映射函數.Zhang等[74]受此啟發將多元線性回歸的思想與分類相結合,直接使用多元線性回歸構建每一組特征子空間之間的映射關系.盡管基于回歸的方法與其他基于學習的方法相比,在性能上取得了顯著提高,但仍存在特定的線性函數對不同退化情況難以建模的問題.而深度學習技術中的運用激活函數進行非線性特征表示的方法很好地解決了此問題.有效防止數據過擬合.例如Dong等[17]提出基于卷積神經網絡的非線性回歸SR 重建方法,使得圖像的質量得到進一步改善.
3.4 基于傳統學習的SR 重建方法的討論
綜合以上分析,基于插值的SR 重建方法利用待重建HR 圖像中未知像素和LR 圖像中已知像素之間的線性或者非線性關系來估計其像素值,達到分辨率增強的目標.雖算法簡單、易于并行計算,執行速度快,但是隨著圖像放大倍數增加,重建HR圖像會出現邊緣平滑、模糊及振鈴和鋸齒效應等缺陷,特別是對于場景復雜的自然圖像,重建圖像質量較差.因此,基于插值的方法比較適合對實時性要求較高、對于放大倍數要求較小、對重建質量效果要求也較低的簡單場景下圖像的重建.此類方法屬于無樣本的單圖像超分方法,未利用高低分辨率樣本之間的先驗信息進行約束.
基于學習的SR 方法是一種有樣本的單幅圖像SR 方法,通過學習高、低分辨率圖像之間的統計關系,并把這種關系運用到重建過程中,實現圖像的SR 重建.基于樣本學習的SR 重建方法可細分為基于樣例學習、基于稀疏表示和基于回歸3 種方法.
基于馬爾科夫網絡的樣例學習方法提出了從大量樣本中學習LR 和HR 圖像之間先驗信息并約束HR 重建的思想,采用馬爾科夫網絡構建圖像和場景的局部區域之間的關系模型,為基于學習的SR 重建奠定了理論基礎.由于訓練樣本量較大并且學習模型有限,此類方法的計算量大且泛化性較差.鄰域嵌入法從流形學習中引入局部線性嵌入來處理圖像SR 任務,雖在計算量和重建性能上較文獻[39]方法有所改善,但未解決LR 和HR 圖像塊的鄰域數量和特征表示的問題,導致模型缺乏紋理和細節的先驗性.
相比樣例學習通過人為設計的基信號(字典原子)表示信號的方法,稀疏表示的字典原子是通過建立稀疏先驗約束,由稀疏編碼過程中自動學習字典原子.基于稀疏表示的SR 重建認為目標圖像可以由過完備稀疏字典中少量原子的線性組合構成,其他原子的系數為零或近似為零.考慮到稀疏表示能夠通過基本原子信號結構化來表示原信號,在其表示空間有利于映射關系的學習和建立,并構建先驗信息保持圖像的邊緣和紋理結構.但是由于LR和HR 圖像空間映射關系的多樣性、復雜性、空間變化性及高度非線性,導致重建結果過分依賴訓練圖像,對真實自然場景圖像的重建效果并不理想.
基于回歸的SR 重建方法直接建立高低分辨率圖像之間的回歸模型,通過回歸構建特征子空間之間的非線性映射關系來重建圖像.與樣例學習、稀疏表示的方法相比,雖然基于回歸的方法在性能上有顯著提升,但特定的線性回歸函數對于非線性數據或者數據特征間具有相關性多項式回歸的情況難以建模,并且難以表達圖像塊間復雜的特征數據,未考慮圖像場景的復雜性和多樣性,導致映射函數的精度仍然不高,重建HR 圖像存在較多的平滑邊緣和模糊紋理細節.
4 基于深度學習的圖像SR 重建
隨著深度學習技術的不斷更新,基于深度學習的SR 重建方法在最近幾年得到了蓬勃發展.利用深度學習技術,不再需要單獨的圖像塊特征提取等預處理過程和后續的HR 圖像塊聚合過程,利用非線性變換自動學習多層次特征,更深入地挖掘高、低分辨率圖像之間的內在聯系.實踐證明,深度學習方法可用來解決低層視覺問題,如圖像去噪和去模糊[75].對于自然圖像SR 重建,深層卷積神經網絡可以直接學習LR 圖像和HR 圖像之間的端到端映射,重建出LR 圖像丟失的高頻細節信息.本節將對基于深度學習的圖像SR 重建的網絡模型及其各部分特性進行歸納.
2015 年,Dong等[17]首次將卷積神經網絡應用于SR 重建中,提出一種端到端的網絡結構--基于CNN的超分辨模型(Super-resolution convolutional neural network,SRCNN),每個卷積層應用多個不同的濾波器,這些濾波器在訓練期間會自動提取分層特征.該方法將基于傳統的稀疏編碼方法與基于深度學習的SR 方法聯系在一起,相對于傳統稀疏表示的字典學習方法,過程大大簡化.利用深度學習的方法對圖像進行SR 重建時的基本思路為:首先,將LR 圖像作為網絡的輸入,然后通過卷積層形成特征矩陣,并對其進行卷積濾波處理形成特征圖作為下一層的輸入層;在此期間,被處理的LR 圖像特征矩陣和HR 圖像形成的特征矩陣通過激活函數進行非線性映射,這是一個復雜的細節預測過程,將映射后得到的特征矩陣通過重建層獲得HR 圖像,這屬于正向傳播過程.通常在輸出HR 圖像之前還要加入損失函數進行像素比對,通過反向傳播算法來優化網絡內部參數和節點模型不斷減小輸出圖像和理想圖像之間的差距,直至損失函數收斂.近年來出現的深度學習SR 網絡包括快速超分辨率(Fast super-resolution by CNN,FSRCNN)[76]、亞像素卷積網絡(Efficient sub-pixel convolutional neural network,ESPCN)[77]、非常深度卷積網絡(VDSR)[78]、深度遞歸卷積網絡(Deeply recursive convolutional network,DRCN)[79]、拉普拉斯金字塔超分辨網絡(Laplacian pyramid super-resolution networks,LapSRN)[80]、非常深的殘差編碼器-解碼器網絡(Very deep residual encoder-decoder network,RED-Net)[81]、深度遞歸殘差網絡(Deep recursive residual network,DRRN)[82]、密集連接超分辨網絡(Super-resolution dense convolutional network,SRDenseNet)[83]、生成對抗超分辨網絡(Super-resolution generative adversarial network,SRGAN)[84]、記憶網絡(Memory network,Mem-Net)[85]、殘差密集網絡(Residual dense network,RDN)[86]等.深度學習SR 網絡的結構主要由特征提取、細節預測、重建輸出等部分組成,如圖3 所示.

圖3 基于深度學習的SR 方法網絡結構圖Fig.3 Network structure of SR method based on deep learning
4.1 網絡模型
在深度學習方法中,圖像的特征提取與表示、信息預測以及信息的傳遞與重建均在復雜的網絡架構展現.與HR 圖像相比,其相對應的LR 圖像丟失了許多細節.深度卷積神經網絡(Convolutional neural network,CNN)采用網絡級聯的方式來預測LR 圖像中丟失的細節并重建相應的HR 圖像,但這種方式也存在弊端.如前所述,網絡層數的增多勢必會增加參數量,網絡的性能也會隨著參數量的增加而降低.研究表明,在深度CNN 中引入稀疏先驗[87]、殘差網絡(Residual Neural Network,Res-Net)[88]、密集連接卷積網絡(Dense convolutional network,DenseNet)[89]、生成對抗網絡(Generative adversarial networks,GAN)[90]等各種網絡,殘差塊[91]、密集連接塊[92]、跳轉連接以及遞歸單元[79]等多種結構,會使得SR 網絡模型更加穩定,性能更加優越.基于深度學習的SR 模型將以上提到的各種網絡與結構進行整合,通過聯合優化獲得更好的重建性能.
1)殘差學習在圖像SR 中的應用
殘差學習的思想是將前一層的信息與當前層的信息相結合,并將它們一起傳遞到下一層.殘差學習是SR 重建中用到的最廣泛的連接結構,該結構增強層與層之間學習信息的質量,同時可以確保前期訓練層的信息傳遞到更深層.Kim等[78]第一次將殘差學習融入CNN 網絡,提出一種深度卷積神經網絡,用以學習原始LR 圖像的邊緣信息.殘差塊是將卷積層、批歸一化層(Batch normalization,BN)和線性整流函數(Rectified linear unit,Re-LU)激活層組合在一起的結構.該網絡最早用于分類任務,而將其直接用于SR 效果并不好,因此不斷有學者對其內部進行微調改進.增強深度超分辨網絡(Enhanced deep super-resolution network,EDSR)對殘差塊內部結構進行改進,Lim等[91]將其中的BN 層去掉,該操作有兩點好處:一是可以減少內存使用量,從而加快運行時間;二是去掉歸一化后增加了網絡范圍靈活性.Yu等[93]提出的WDSR 使用權重歸一化層代替BN,該操作不僅在網絡尺度范圍上沒有限制,而且還通過限制權重參數范圍有效地減輕了深度SR 網絡的訓練難度.除了對殘差塊內部結構進行調整外,還可以對網絡的局部結構或整體結構進行調整.文獻[94]提出深度平行殘差網絡(Deep parallel residual network,DPRN)網絡,這是一種深度并行殘差網絡,該網絡是將每個殘差分支初始特征映射到殘差組合中進行并行卷積訓練,第一個卷積層將利用此輸出進行局部殘差學習,每個分支的輸出用于全局殘差學習達到提升網絡速度和精度的目的.
2)遞歸神經網絡在圖像SR 中的應用
遞歸神經網絡在SR 重建中是以遞歸單元形式展現,通過使用遞歸塊來增強輸入特征映射的表示,其原理是接受前一部分輸出的淺層特征映射,并遞歸地使用特征映射中的代表特征來挖掘LR 和HR對之間的內在關系.文獻[79,92,95]均以遞歸網絡為原型,引用該結構進行重建的最大特點是可以實現信息的跨層傳遞,減少網絡參數.隨著網絡的加深,添加更多的權重層會引入更多的參數,其模型可能會過度擬合,對此文獻[79]通過一個嵌入網絡進行特征提取,首次在網絡中引入遞歸單元,當執行更多的遞歸時,模型參數不會增加.隨后出現的DRRN、深度遞歸上下采樣網絡(Deep recursive up-down sampling network,DRUDN)均是在遞歸單元內部進行有效調整后,完成高質量的重建.在DRUDN 中,每個遞歸塊由一對卷積和反卷積層組成,所有展開的塊通過權值共享減少參數量.此外,循環神經網絡(Recurrent neural network,RNN)是一種以輸入數據的演進方向進行遞歸且所有循環單元按鏈式連接的遞歸神經網絡.Li等[96]以RNN結構為核心思想提出一種反饋網絡(Super-resolution feedback network,SRFBN),以細化具有高級信息的低級表示,該網絡結構引入的反饋機制允許該網絡攜帶當前的輸出糾正之前的輸出狀態,同時對每次迭代施加損失函數促使輸出的反饋模塊學習到HR 圖像特征.
3)生成對抗網絡在圖像SR 中的應用
生成對抗網絡(GAN)是由Goodfellow等[90]提出并在計算機視覺任務中逐漸發展起來的網絡模型.GAN的原理是生成網絡和判別網絡之間進行相互博弈,判別器用來區分生成的樣本和真實數據,而生成器學習生成新樣本并將判別器的錯誤最大化.2017 年,GAN 網絡被應用到SR 重建中,Ledig等[84]提出的超分辨率GAN (Super-resolution GAN,SRGAN)利用感知損失和對抗損失來提升恢復出的圖片的真實感.感知損失是利用CNN 提取的特征,通過比較生成圖像經過CNN 后的特征和目標圖片經過CNN 后的特征的差異,使生成圖片和目標圖片在語義和風格上更相似.但由于感知質量問題和訓練不穩定問題[97]造成輸出圖片缺乏高頻紋理細節,SRGAN 生成的圖像存在平滑現象.針對上述問題,文獻[98]提出一種多樣化的GAN 架構DGAN,包含多個生成器和一個判別器.利用多個生成器共享信息和參數,雖然輸入相同,但每個分支生成的圖像不同,并且會對生成假樣本的生成器進行實時更新以得到更為真實的生成圖像.
實際上,為了設計出性能好的SR 網絡,將以上提到的網絡、單元以及結構相融合是當下一種流行且有效的方式,例如將全局殘差學習和遞歸單元相結合,用于緩解網絡加深引起的梯度消失和信息缺失等問題.為了獲得更高的重建精度,Tai等[82]設計出52 層DRRN 模型,將遞歸結構引入到殘差分支當中,該模型采用局部和全局殘差學習、遞歸層以及80 層MemNet 模型,其中包含長時間存儲單元和多個監督.RDN 網絡[86]將殘差塊和密集塊相結合,其原理是通過單元與結構之間形成一種連續記憶機制,首先是局部特征融合,然后通過局部殘差學習傳遞信息,接著網絡以一種全局特征融合的方式挖掘分層信息,最后通過全局殘差學習將特征映射到高維HR 進行上采樣操作,輸出重建結果.以上典型網絡的內部結構如表1 所示.
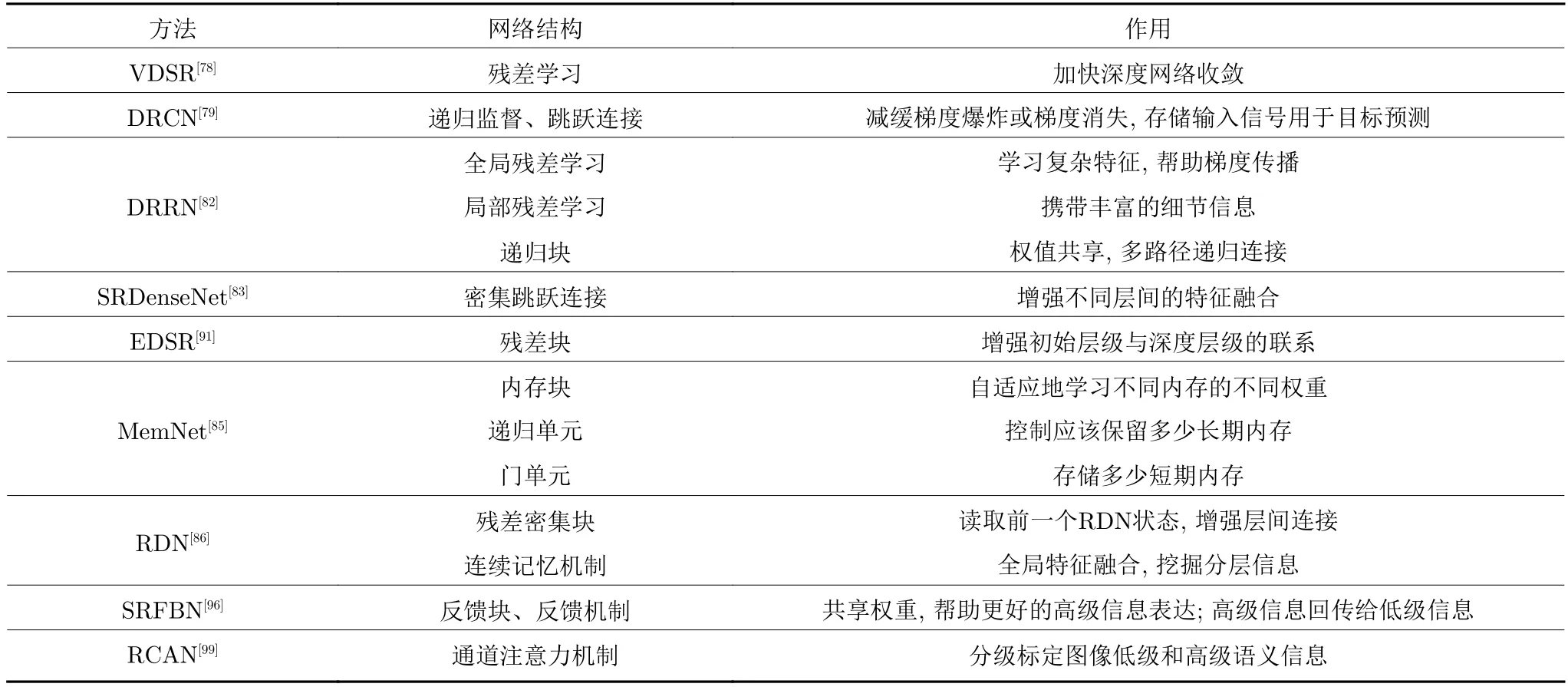
表1 典型深度學習網絡內部結構Table 1 The internal structure of a typical deep learning network
4.2 特征提取
以上提到的深度學習SR 方法中,按空間分辨率來劃分,特征提取分為在LR 空間提取特征和在HR 空間提取特征兩種情況.HR 空間特征提取意味著要在HR 空間進行卷積操作,此類方法需要先對LR 圖像進行雙三次插值BI 得到與期望的HR圖像相同大小的圖像,再輸入到網絡中進行特征提取,這種輸入與輸出相同尺寸的網絡結構有利于全局殘差結構的構建,但在較高的分辨率上進行卷積操作,計算復雜度會隨HR 圖像的空間尺度增大而增長.LR 空間特征提取,就是將LR 圖像作為網絡輸入,在未經插值的原始LR 圖像上直接提取特征,重建效率提高,但網絡的輸入特征圖較小時,隨著網絡層數的加深,容易丟失細節信息.在基于深度學習的SR 發展過程中,這兩種方法都得到廣泛應用.已有的基于深度學習的SR 方法的網絡輸入如表2 所示.
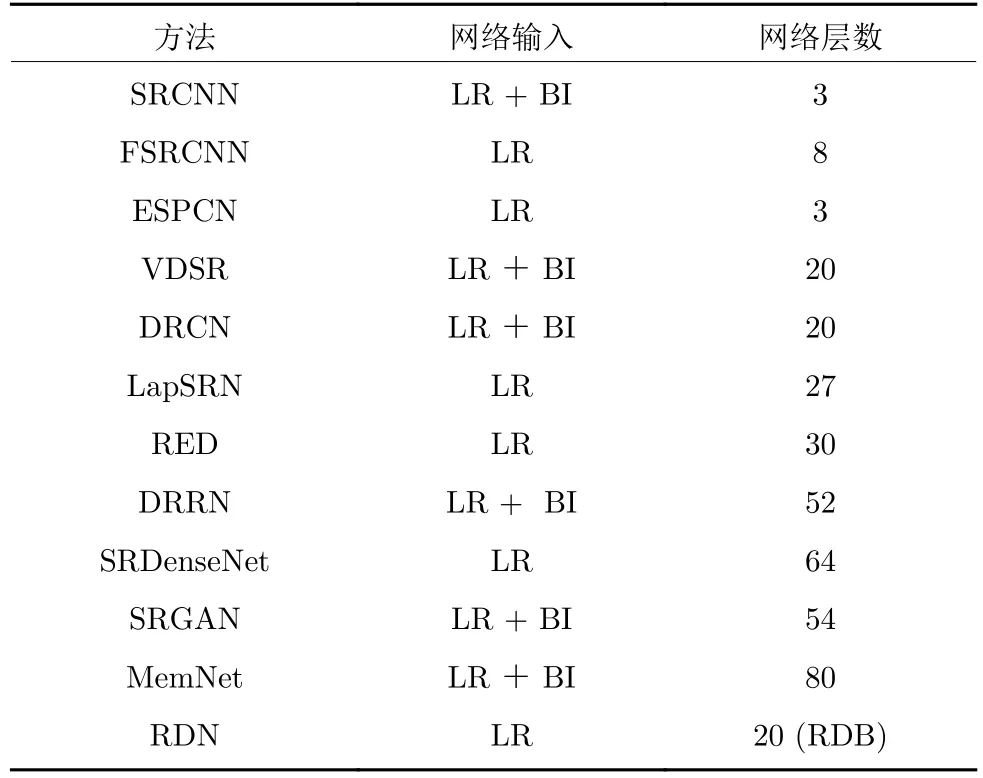
表2 SR 網絡輸入及層數對照表Table 2 Comparison of SR network input and layer number
4.3 模型多尺度化
如何使訓練模型多尺度化,也是眾多研究者們關心的問題.當單尺度模型只可用于與其相對應的比例因子重建HR 圖像時(如圖4(a)所示),網絡訓練的參數會隨著尺度因子的增多而增多,雖然增強網絡性能最直接的方式是增加參數量(特征層數和特征通道數),但特征映射層過多將直接導致計算成本加大,網絡性能不穩定.因此,建立一種能適用于多尺度因子的網絡模型可以在很大程度上提高網絡性能[78,80,91].主要思想是在某一尺度訓練模型上測試不同縮放倍數的圖像,如圖4(b)所示,采用多尺度特征映射和子網絡并行策略,使所有預定義的尺度因子共享網絡參數.這種特定尺度多路徑學習是在網絡的開頭和結尾附加特定尺度的預處理路徑和上采樣路徑,主要共享特征提取的中間部分.因此,在訓練期間,只更新與所需尺度對應的路徑,來實現大多數參數在不同尺度上共享.例如受空間金字塔池化[100]方法的啟發,LapSRN 采用多尺度權值共享的策略,通過同一個網絡處理不同尺度的圖像放大問題.文獻[101]提出的元學習超分辨(Meta-SR)結構,采用Meta-SR 上采樣模塊動態預測上采樣濾波器權重,以任意上采樣因子放大任意LR 圖像來實現模型多尺度化.
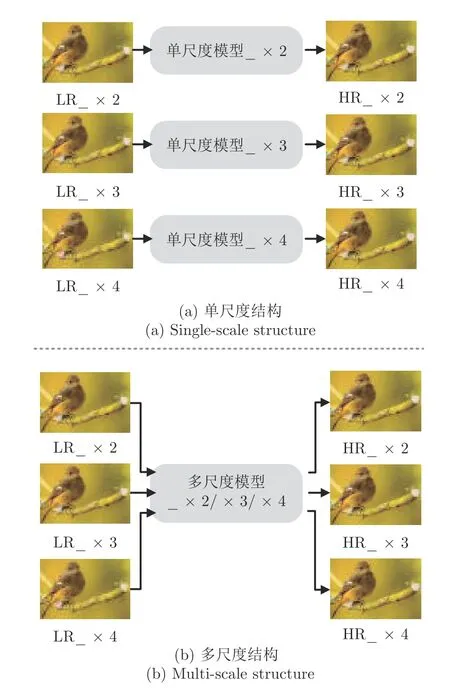
圖4 不同尺度模型SR 結構Fig.4 SR structure with different scales
通過文獻[102]單尺度模型和多尺度模型的對比實驗發現,單一尺度模型能夠很好地恢復具有相應比例因子的HR 圖像,多尺度模型實現的結果與相應比例的單尺度模型所獲得的結果相當,但比模型尺度與圖像尺度不一致時的結果要好很多.所以,用多尺度訓練模型來恢復具有不同尺度因子的HR圖像,在不影響重建性能的前提下,同時能夠節約成本,提高模型穩定性.
4.4 不同應用場景下的SR 重建
以上討論的圖像SR 重建方法中,在構建數據集時因無法直接獲取高低分辨率圖像對,所采用的做法是在收集HR 圖像后,通過雙三次下采樣人工生成LR 圖像.但該下采樣方法改變了LR 圖像的底層特征.因此,用上述圖像對訓練出的SR 模型魯棒性較差,導致提出的SR 方法很難泛化到真實場景中.近兩年,圖像SR 重建方法主要針對現實場景下未知退化因子的單圖像SR,稱為真實圖像SR.
基于真實圖像的SR 重建的關鍵是數據集,采取的網絡模型仍以殘差塊、密集殘差結構以及注意力機制[99]等網絡內部結構為基礎,如表1 所示,使用多尺度結構對圖像特征進行上下采樣完成圖像SR 重建.Cai等[103]提出了基于拉普拉斯金字塔的核預測網絡(Laplacian pyramid based kernel prediction network,LP-KPN),在RealSR 數據集上能夠有效地學習像素卷積核的權重用于HR 圖像的重建.Wang等[104]將殘差學習的思想用于立體聲圖像SR,提出一個視差注意力立體聲SR 網絡,該網絡采用殘差思想以提取豐富的上下文信息,引入視差注意力機制以建立立體圖像的對應關系,減小計算和存儲成本.Pan等[105]對在實際場景中捕獲的LR 圖像進行SR 重建,使用基于高斯過程的神經架構搜索(Gaussian process based neural architecture search,GP-NAS)通過異構模型實現真實圖像SR,基于現有的密集殘差網絡,通過改變密集殘差塊的數量、大小以及特征數量,利用基于高斯過程的神經體系結構搜索方案GP-NAS,使用較大的搜索空間來查找候選網絡體系結構.Zhang等[106]構建了的真實圖像CUFFED5 數據集,并且提出神經紋理遷移的思想實現真實圖像SR 重建,該思想包含局部紋理特征匹配和紋理遷移兩個部分,利用參考圖像中的紋理以彌補LR 圖像的細節信息.Bulat等[107]針對真實的人臉圖像進行SR 重建,以生成對抗網絡(GAN)為基礎提出了一個兩階段的重建過程.同樣,針對人臉和通用場景建立了一個標基于歸一化流的超分辨率模型,在感知質量指標方面也表現出了良好的性能.
4.5 不同降質方式的SR 重建
圖像降質分為已知降質和未知降質兩種.已知降質是指對圖像進行不同尺度、模糊核以及噪聲方面的降質.對于不同降質方式得到的LR 圖像建立不同的SR 模型是近幾年的一個發展方向.
對于模糊降質,Zhang等[108]通過研究高斯模糊、運動模糊、Disk 模糊,提出可以去任意模糊核的DPSR 模型,在BSD68 數據集上得到了清晰的重建結果.對于下采樣降質,除雙三次插值下采樣降質外,Song等[109]針對帶噪聲的非線性下采樣和間隔下采樣方式,提出基于迭代殘差學習的框架實現深度圖SR 重建,在該框架中,利用通道注意力機制、多階段融合、權重共享以及深度細化等粗略到精細的方式學習HR 深度圖.對于噪聲降質,哈爾濱工業大學張凱團隊提出的去噪卷積神經網絡(Denoising onvolutional neural network,DnCNN)[110]、快速靈活的去噪卷積神經網絡(Fast and flexible denoising convolutional neural network,FFDNet)[111]和卷積盲去噪網絡(Convolutional blind denoising network,CBDNet)[112]是針對噪聲降質圖像SR 重建的遞進的三種方法,重建對象從均勻的高斯噪聲變成更加復雜的真實噪聲.DnCNN 利用歸一化和殘差學習可以有效地去除均勻高斯噪聲.然而真實噪聲具有信號依賴性、顏色通道相關性以及不均勻性,基于此FFDNet 使用噪聲估計作為輸入,在抑制均勻分布的噪聲的同時保留細節信息,實現更加復雜的真實場景的超分辨重建.在FFDNet的基礎上,CBDNet 將噪聲水平估計過程也用一個子網絡實現,從而使得整個網絡實現盲去噪.Zamir等[113]提出的MIRNet,是在非常深的殘差通道卷積網絡 (Very deep residual channel attention networks,RCAN)的基礎上通過整個網絡維護空間精確的HR 表示,并從LR 表示接收強大的上下文信息多尺度特征聚合,學習豐富的特征以修復和增強真實圖像,同時達到圖像去噪的目的.此外,上述的LP-KPN、SRFlow 也可以完成去噪.Zhang等[114]提出的展開超分辨網絡(Unfolding super-resolution network,USRNet)可同時解決不同尺度、模糊、噪聲等多種降質問題,該方法集成了基于學習與基于建模的方法.通過半二次分裂算法將最大后驗概率估計(Maximum a posteriori estimation,MAP)推理展開,采用固定次數的迭代來求解數據子問題與先驗子問題,通過神經網絡模塊進行求解兩個子問題,從而得到一個可端到端訓練的迭代網絡.
5 基于傳統與深度學習SR的聯系
基于深度學習實現圖像SR 重建,之所以能取得良好的效果,一方面是因為深層卷積神經網絡能夠深入挖掘圖像的細節特征,可以直接、自主地學習LR 圖像和HR 圖像之間的映射關;另一方面是因為深度學習方法在應用于SR的過程中,遵循了圖像降質和重建的客觀規律,實際上深度學習的很多做法都是傳統方法的延伸,與傳統SR 方法既有區別又存在很多關聯.圖5 展示了上述基于插值、基于淺層學習以及基于深度學習的SR 重建方法本質的聯系和差異.
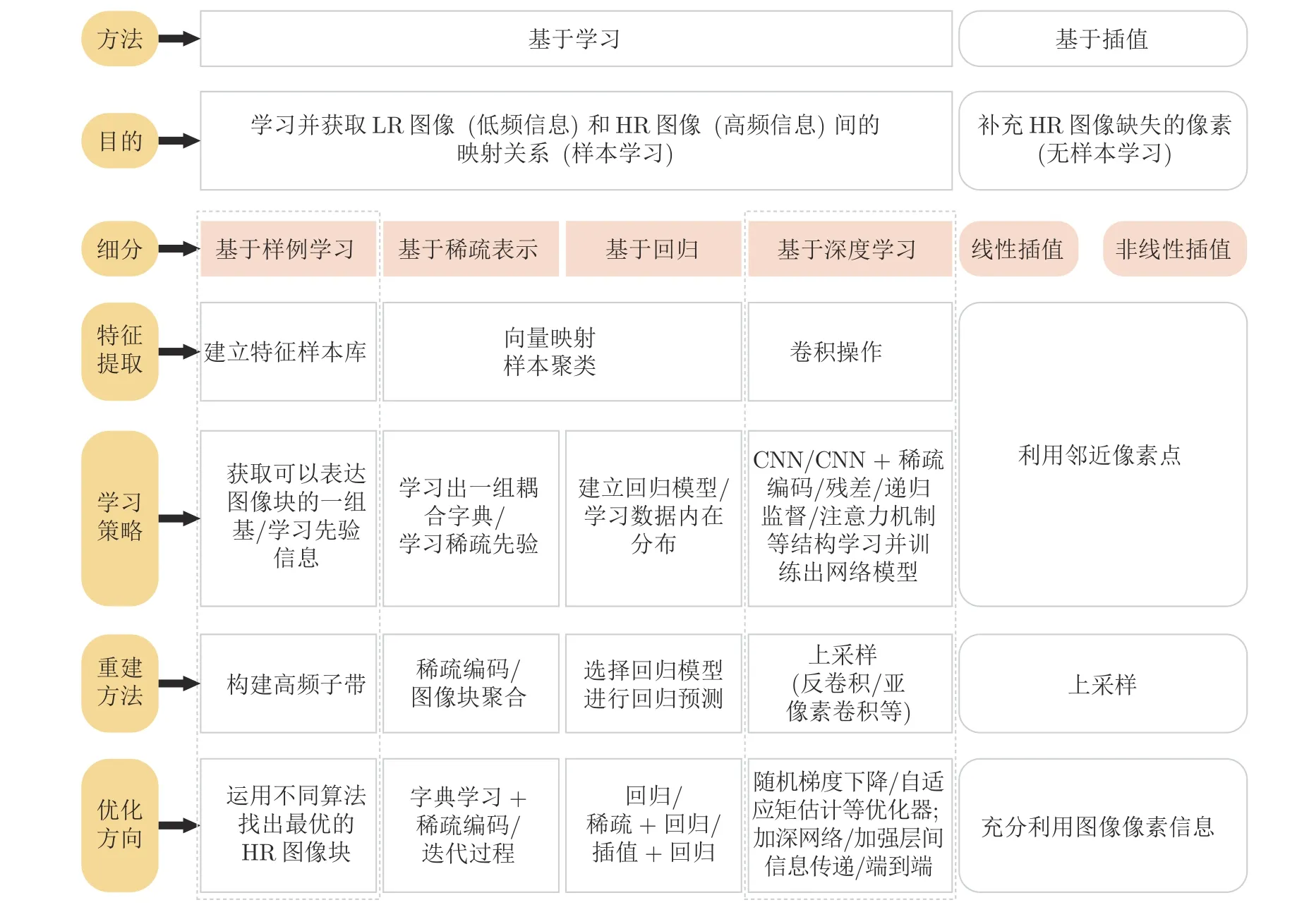
圖5 SR 重建方法本質的聯系和差異Fig.5 Relations and differences of SR reconstruction methods
5.1 小波變換與深度學習的結合
基于離散小波變換(Discrete wavelet transform,DWT)的SR 重建方法基本思想是將信號分解到不同的分辨率上,這樣分解可以在不同尺度上獨立地對信號進行分析和研究,并且對高頻信號采用逐漸精細的頻域或時域采樣,從而聚焦到對象的任意細節.最初將DWT 與SR 相結合應用的是Ford等[115]提出的基于小波變換的一維信號非均勻采樣重建,而后Nguyen等[116]將該方法拓展到二維信號,在多分辨率框架下得到了基于小波變換的SR圖像重建算法,取得良好效果并得到了廣泛的應用,隨后一些國內研究者[117-120]和國外研究者[121-126]進一步完善了基于小波變換的SR 方法.總之,基于DWT的SR 重建方法包括以下4 步:
1)先對原始圖像進行降質處理,得到LR 圖像.
2)借助小波變換,將圖像分解為水平低頻垂直低頻分量LL 和三個高頻分量,分別為水平高頻垂直低頻分量HL、水平低頻垂直高頻分量LH、水平高頻垂直高頻分量HH.如圖6 虛線部分所示.
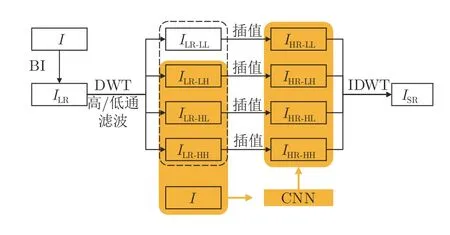
圖6 基于傳統小波變換和與深度學習相結合的小波變換SR 重建方法流程圖Fig.6 SR reconstruction method based on traditional wavelet transform and wavelet transform combined with deep learning
3)借助SR 算法,有針對性地對每個分量進行算法重建.
4)借助逆離散小波變換(Inverse DWT,IDWT)將重建后得到的分量再重構,從而得到HR 圖像.
在以上傳統的子帶插值SR 重建方法的基礎上,有些學者將DWT 與深度學習SR 算法相結合,利用小波變換將高低頻分離,運用深度學習方法重建小波域子帶,完成單幅圖像SR 重建,如圖6 陰影區域所示.例如,Zhang等[120]實驗驗證了SRGAN恢復的圖像紋理細節魯棒性較差,為了得到更豐富的高頻細節,將小波變換引入以得到具有豐富全局信息和局部紋理細節的HR 圖像.張麗[127]將小波變換和VDSR 結合,研究在不同小波域子帶進行內插和深度學習的SR 效果,并探討了兩者相結合的五種SR 算法,將所構造的SR 算法應用于一個面向交通監管的SR 重建系統.段立娟等[128]采用多階段學習策略,首先推理出HR 圖像對應的小波系數,然后重建SR 圖像,并且網絡模型采用結合圖像空域與小波域的損失函數進行優化求解.孫超等[129]發現基于深度學習的單圖像SR 方法僅研究圖像空域,忽略了圖像頻域中高頻信息的重要性,從而導致生成的圖像相對平滑,因此,其利用小波變換能夠提取圖像細節的特性,使用Tai等[82]提出的DRRN 網絡模型完成對高頻子帶的重建,相比于原始DRRN 結構峰值信噪比(Peak signal-to-noise ratio,PSNR)值提高了26.8%.
5.2 稀疏編碼與深度學習的聯系
自然圖像中的稀疏先驗以及源于此先驗的HR和LR 空間之間的關系被廣泛應用于SR 重建中.在傳統方法的啟發下,深度學習網絡對這個關系進行了深度挖掘.以深度學習與傳統的稀疏編碼之間的關系作為依據,可以將SR 重建過程分為圖像塊提取、非線性映射、上采樣重建三個階段.在特征提取方面,傳統的SR 方法通過鄰域嵌入(第4.2 節)和構造字典(第4.3 節)等方法完成人工設計圖像塊特征提取.深度學習技術可以通過多層卷積操作和網絡的反復訓練自動提取特征,再結合激活函數層完成對數據的擬合和非線性映射,以實現圖像多層次特征的學習和提取.例如Wang等[130]提出基于稀疏編碼網絡的方法(Sparse coding based network,SCN),借鑒基于稀疏表示SR 重建的思想,將原方法中稀疏表示、映射、重建三個獨立優化的模塊集成到一個稀疏網絡中.網絡的訓練相當于對三個模塊協同優化,因而可得到全局最優解.該方法首先通過特征提取層得到圖像的稀疏先驗信息;然后,通過基于學習的迭代收縮和閾值算法(Learned iterative shrinkage and thresholding algorithm,LISTA)[131]建立了一個稀疏網絡SCN,該網絡可實現圖像的稀疏編碼和解碼;最后,采用級聯網絡完成圖像放大,該方法能夠在更高放大倍數下提高PSNR 值,且算法運行速度進一步提升.作者進一步推出了使用多個SCN的級聯版本[132],在客觀評價和主觀評價上都得到了改進.因此,SCN實際上可看作通過CNN 實現了基于稀疏編碼SR方法,采用LISTA 得到基于神經網絡產生稀疏編碼的近似估計,解決基于傳統稀疏編碼SISR的時間消耗推理問題.
5.3 上采樣重建方法的發展
通常在SR 網絡末端,為了構建HR 圖像都會進行解碼,即上采樣過程.基于傳統方法的上采樣采用的方法通常為插值法(第2 節),包括最鄰近插值、雙線性插值和雙三次插值,但插值上采樣通常信息冗余大,映射能力小.為解決上述問題,SR 領域出現幾種可以嵌入到深度學習網絡模型中的上采樣方法,分別是轉置卷積層[76, 82,102]、亞像素卷積層[77, 91,102]、任意尺度縮放(Meta-Upscale)[100]、內容感知特征重組(Content-aware reassembly of features,CAPAFE)[133].1)轉置卷積層將被下采樣的小尺度抽象信息上采樣到原來的分辨率.FSRCNN 首次將轉置卷積層引入SR 網絡中,提出通過改變反卷積層濾波器的大小將圖像上采樣到不同的尺度,從而實現輸出多尺度.2)ESPCN 中亞像素卷積結構,LR 圖像經特征提取后得到一個通道數為、大小和輸入圖像相同的特征圖像,再將將不同通道上同一個位置的r的平方個像素排列成r×r的區域,對應HR的的子塊,最終輸出HR 圖像.3)Meta-SR 中提出的上采樣模塊可以完成圖像任意尺度縮放,動態預測放縮的權值及像素的對應關系,實現較好效果的非整數倍放縮.4)CAPAFE 提出一種內容感知重組模塊進行上采樣,該模塊用于利用計算得到的權重將通道轉化成一個的矩陣作為內核,與原本輸入的特征圖上的對應點及以其為中心點的區域做卷積計算來獲得輸出,計算速度快.
6 數據集及SR 圖像評價方法
6.1 圖像SR 重建數據集
目前,已經公布了許多專門用于圖像SR 重建的數據集.深度學習出現之前,大部分超分辨重建方法都是采用人工特征,并在小型數據集上驗證了方法的性能.文獻[134]詳細介紹了傳統SR 算法中最常用的數據集,本文重點介紹基于深度學習SR算法中常用的9 個數據集及其主要參數.
首先介紹Yang等[9]的數據集、Berkeley Segmentation的數據集[135]和DIV2K 數據集[136],這些是供訓練使用的數據集.Yang等[9]的數據集有91幅圖像,Berkeley Segmentation 數據集有200 幅SR 重建基準圖像,包含一些人像、植物和動物等,這兩個數據集使用最為廣泛;DIV2K 是近兩年SR重建研究中廣泛使用的較大型數據集,用于挑戰NTIRE 比賽(例如CVPR 2017 和CVPR 2018)和Perceptual Image Restoration and Manipulation (PIRM)比賽(例如ECCV 2018),其中包含1 000幅2K 高清晰度RGB 圖像,并提供降尺度因子為2、3 和4的HR 和LR 圖像.
除上述三個訓練數據集之外,Set5[137]、Set14[49]、BSD100[135]、Urban100[138]、manga109[139]和Sun-80[140]測試集均是供測試使用的數據集.Set5、Set14、BSD100、Urban100 是SR 重建的4 個基準數據集,其中Set5、Set14 分別包含5 幅、14 幅圖像,BSD100是來自Berkeley Segmentation 數據集的100 幅自然圖像,Urban100 包含100 幅具有挑戰性的不同時間段的城市場景圖像,Manga109 是日本漫畫數據集.Sun80 數據集具有80 幅自然圖像,每個圖像都帶有一系列的網絡搜索參考.
近幾年,研究者們構建了一些用于SR 重建的真實圖像數據集,其中包括CUFED5[106]、RealSR[103]、DRealSR[141]、City100[142]、SR-Row[142]、LOL 數據集[143]和MIT-Adobe FiveK 數據集[144]等.CU-FED5數據集提供了訓練和測試集,并在內容、紋理、顏色、照明和視點等方面具有不同相似度的參考.RealSR數據集是在相同場景下通過調整單反相機的焦距獲取真實圖像數據集,在長焦距下獲得HR 圖像,在短焦距下獲得對應的LR 圖像.DRealSR 由5 種不同的單反相機(佳能、索尼、尼康、奧林巴斯和松下)拍攝的室內外廣告海報、植物、辦公室、建筑物等構成.City100 數據集是在室內環境下拍攝的紙質明信片圖像.大型數據集對于提高深度卷積神經網絡的性能非常重要,所以在數據集較少的情況下會對數據集進行擴充,一方面可以對數據集中圖片進行0.5、0.6、0.7、0.8、0.9 等倍數的縮小;另一方面可對數據集中圖像進行不同角度的旋轉.
6.2 常用圖像SR 重建評價指標和方法
在SR 重建方法不斷發展的過程中,研究者們提出了一系列評價指標來評估各種方法對圖像進行SR 重建的效果,表3 從方法特點、方法類別以及方法適用場景等多方面對SR 重建質量評價方法進行了多維度的總結.常用評估方法包括:平均主觀得分(Mean opinion score,MOS)、平均主觀得分差異(Dierential mean opinion score,DMOS)、均方誤差(Mean square error,MSE)、結構相似性(Structural similarity index,SSIM)、多尺度結構相似性(Multi-scale structural similarity,MSSSIM)、特征結構相似性(Feature structural similarity,FSIM)、視覺信息保真度(Visual information fidelity,VIF)、信息保真度準則(Information fidelity criterion,IFC)、非對齊參考圖像質量評估(Non-aligned reference image quality assessment,NAR-DCNN)[145]、主觀感知質量(Perceptual index,PI)[147]、Ma[148]、自然圖像質量評估器(Natural image quality evaluator,NIQE)、圖像完整性標注器(Image integrity notator using DCT Statistics,BLIINDS)[149]、盲圖像質量指標(Blind image quality index,BIQI)[150]、盲/無參考圖像空間質量評估器(Blind reference image spatial quality evaluator,BRISQUE)[151]、學習感知圖像塊相似度(Learned perceptual image patch similarity,LPIPS)[146]、深度雙線性CNN 圖像質量評價(Deep bilinear CNN,DB-CNN)[152]、基于排名學習的無參考圖像質量評估(Rankings image quality assessment,Rank-IQA)[153]、基于深度學習的圖像質量指數(Deep learning based Image quality index,DIQI)[154].
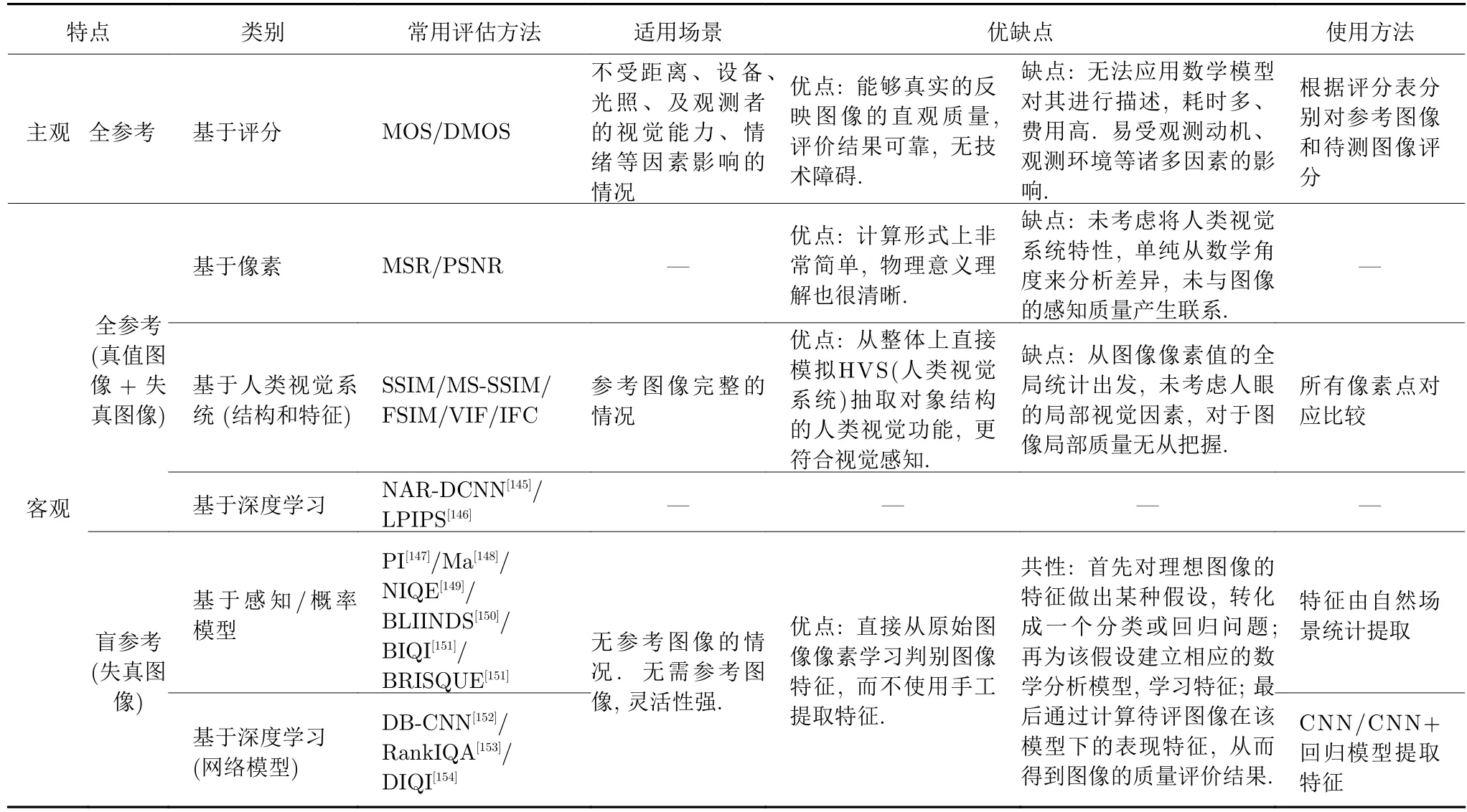
表3 SR 重建圖像常用質量評價方法Table 3 Common quality evaluation methods for SR reconstructed images
7 結束語
SR 重建是計算機視覺領域中的一個典型問題,SR 重建技術在實際生活中具有良好的應用前景,因此目前SR 圖像重建,尤其是結合深度學習技術的SR 圖像重建處于深度研究階段.之前,無論是傳統的SR 重建方法還是基于深度學習的SR 重建方法,研究工作均圍繞提高圖像重建準確性、節約計算成本和提高時間效率等方面展開.近年來,隨著真實圖像數據集的不斷擴大和硬件設備性能的不斷提升,基于深度學習的真實圖像SR 重建技術獲得了良好發展.今后的研究可以從應用場景、降質方式、網絡設計和評價指標四個方面展開:
1)針對不同應用場景,設計更具針對性的網絡模型.目前SR 重建方法的研究多是基于特定自然圖像數據集,與各種各樣的深度學習網絡模型結合取得了良好效果,例如由于LR 和HR 有非常高的關聯度,殘差網絡的思想在圖像SR 中應用效果良好;為了減少參數量,采用遞歸神經網絡;近幾年,GAN網絡也不斷發展并成功應用于SR 重建中.由于不同領域的圖像有各自的特點,例如醫學圖像、SAR圖像、交通監控圖像、夜視圖像等,針對具體應用領域有針對性地選擇和設計網絡是提高重建性能、提高技術實用性的關鍵因素.
2)針對不同降質方式建立自適應的退化模型提高SR 網絡的針對性,或者建立普適的退化模型提高SR 網絡的泛化能力.首先,在建立成像退化模型的過程中,研究者對圖像噪聲以及圖像模糊核的估計鮮有研究和討論,往往將噪聲默認為加性高斯白噪聲,并未考慮系統噪聲和量化噪聲等.所以,在SR 重建研究中,針對不同降質方式建立適合的模型會大大增強重建的針對性與準確性.其次,設計適應性強的模型來處理任意噪聲和模糊核是提高SR 網絡泛化能力的重要手段.
3)網絡模型的設計.SR 重建網絡大多由特征提取與重建兩部分構成.在后續研究中,對于前者需要探索更多卷積模式和特征提取方法,例如局部、全局與多尺度特征融合,自適應卷積核、通道和空間注意力機制以及空洞卷積的合理使用等;對于后者,在不增添冗余且無效信息的情況下改進上采樣層,使其充分利用特征提取部分提取到的特征完成特征圖大尺度上采樣重建,盡量減少圖像特征的損失,提升網絡的魯棒性.
4)圖像的盲超分和盲評估.若想應用于實際場景,設計一種對單幅圖像進行盲SR 重建的技術是未來的趨勢,即一幅低質量圖像的重建不依靠高低分辨率圖像對的學習,而是通過對不成對圖像的學習與表示或者對單幅圖像周圍像素點的充分學習來訓練模型,以供未知降質圖像完成重建.對于重建結果的評價指標,全參考評級指標若想保證評價結果公正且合理,后續的設計應權衡主觀和客觀兩方面完成,無參考評價指標(盲評估)是現在和未來用于評估真實圖像SR 方法性能的趨勢.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
