基于句法和語義的英漢翻譯記憶系統設計研究
2022-12-02 06:12:26董菊霞
電腦與電信 2022年8期
董菊霞
(平頂山學院,河南 平頂山 467000)
1 引言
互聯網技術的快速發展,促進了機器翻譯系統開發,借助互聯網平臺,實現系統數據庫信息實時更新,為用戶提供網絡訪問連接[1]。該系統支持多種語言的相互轉換,能夠為用戶交流提供便利條件。目前,機器翻譯系統主要分為兩種類型,分別是語料庫翻譯、語法分析翻譯[2]。相比之下,語料庫翻譯技術發展較好。由于自然語言歷經多年發展形成,人們針對相同的語言理解存在一定差異,因而降低了機器翻譯的準確性。面對重復率較高的文件翻譯工作,耗費時間較多[3]。翻譯記憶技術的提出,打破了傳統機器翻譯模式,能夠縮減重復語句的翻譯時間[4,5]。由于翻譯記憶技術研發時間比較短,尚未形成完善的英漢翻譯記憶系統。本文嘗試將語義和句法作為譯文指標,開發一套英漢翻譯記憶系統。
2 英漢翻譯記憶
2.1 英漢翻譯記憶方法
翻譯記憶指的是將以往翻譯任務獲取的經驗作為信息基礎,開展下一次翻譯任務,在此期間使用的系統,是翻譯記憶系統[6]。本文提出的英漢翻譯記憶,是以英語和漢語作為翻譯相互轉換的兩種語言,運用翻譯記憶系統,在記憶庫中搜索相似資源,作為譯文參考依據。用戶在使用該系統過程中,以系統提供的資源作為輔助翻譯工具,根據自己的理解,調整最終翻譯結果,以此提高翻譯效率。當系統處理新的翻譯任務時,將此任務與數據庫中資料進行匹配,生成相似譯文,作為翻譯參考依據,用戶根據譯文情況,選擇接受此翻譯結果,或者在此基礎上做出更改[7]。當本次翻譯結束后,相關翻譯信息將被存儲至記憶庫中。隨著使用時間不斷積累,記憶庫中的資源就會逐漸增加,有助于翻譯效率的提升[8]。
2.2 英漢翻譯記憶作業流程
英漢翻譯記憶方法涉及的主要技術有相似度計算、記憶庫技術、譯文構造技術[9]。運用這3項技術,對數據進行檢索、資源匹配、人工校對等處理,從而生成翻譯結果。本文提出的英漢翻譯記憶系統,從記憶庫中檢索相關數據,與原文數據進行對比,完成英語和漢語之間的轉換處理。如圖1所示為英漢翻譯記憶作業流程。
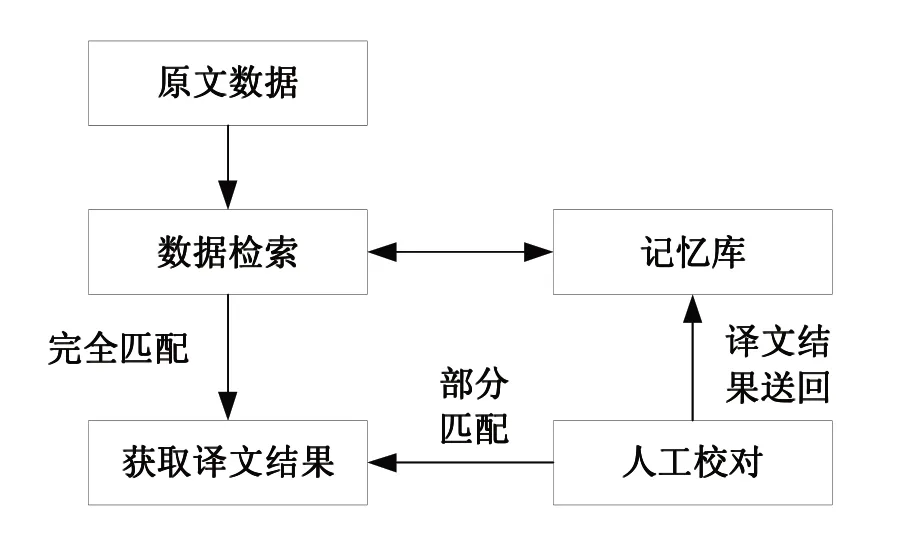
圖1 英漢翻譯記憶作業流程
首先,根據原文數據,調用記憶庫中的信息,經過數據檢索,尋找與之匹配的譯文資源。接著,對比檢索譯文資源與原文數據是否完全匹配,如果完全匹配,則生成譯文結果。反之,采用人工校對的方式,對本次譯文結果進行校對,同時將校對相關信息存儲至記憶庫中,以此豐富記憶庫中的譯文資源,同時優化譯文標準。
3 基于句法和語義的英漢翻譯相似度算法
翻譯相似度算法作為翻譯記憶系統開發的核心工具,以語義和句法作為翻譯相似度判斷指標,分析英語句子和漢語句子的譯文是否匹配。一般情況下,相似度范圍[0,1],數值越接近1,則認為翻譯語句與原句越相似,從語義、句法兩個方面來看都是滿足翻譯意思標準的[10]。另外,單詞排序同樣符合譯文要求。如果相似度數值接近0,則認為兩個語句之間不存在聯系,語義和句法幾乎都不同[11]。本算法中,利用[0,1]范圍內數據表示譯文句子之間的相似程度。
關于相似度算法的開發,首先利用Link Grammar Parser軟件計算需要翻譯的句子,獲取該語句的句法結構[12]。其次,判斷生成的句法結構與原句的句法結構是否相同,如果完全相同,運用算法繼續計算獲取語義,并判斷生成的語義與原句的語義是否相似。其中,句義相似度的判定,以句子中的各個組成部分作為判定對象,分別對各個部分的語義相似度進行判斷,得到綜合判斷結果,從而避免譯文句子與原句之間實際相似度與計算結果產生偏差。例如,句子s1:TIFF IFD entry value has wrong size.句子s2:TIFF IFD entry has invalid value.對這兩個句子的相似度的計算,首先進行拆分,而后分別計算各個對應詞組的相似度。詞組1:(TIFF IFD entry),(TIFF IFD entry value);詞組2:(has),(has);詞組3:(invalid value),(wrong value)。這種相似度方法,與傳統方法中計算賓語value方法不同,給出的主要成分entry和value更加貼近實際語義。假設句子成分數量為n,利用句子成分字符串計算得到n數值,并采用公式(1)計算句子相似度:
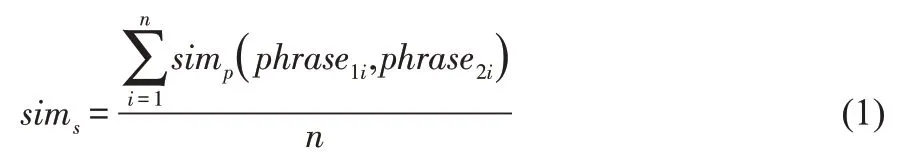
假如抽取句子單詞的期間,發現單詞抽取后句子的成分為空,那么該句子中的被過濾單詞判定為代詞,句子中的各個成分相似度利用公式(2)計算。
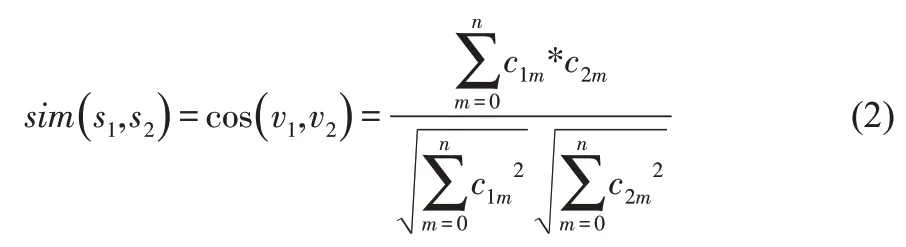
公式(2)中,v1和v2代表向量,c1m和c2m均為字符。
例如句子They like singing.和句子He likes reading.之間的相似度計算,句子成分分為3個詞組。詞組1:{(they)(he)};詞組2:{(like)(like)};詞組3:{(sing)(read)}。利用公式(3)計算。通常情況下,采用wup計算的數據值范圍是(0,1),在Synset之間LCS深度不可能是0的情況下,可以使用公式(3)進行計算分析,但是如果輸入的Synsets相同,數據值就是1。
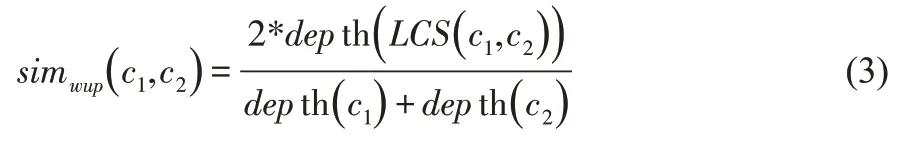
公式(3)中,wup方法得到的計算結果范圍為(0,1);LCS代表公共包容最小值;depth代表深度。
基于上述原理,利用C語言進行編程,如下:

4 基于句法和語義的英漢翻譯記憶系統設計
4.1 系統總體架構設計
本系統架構主要分為3個模塊,分別是索引生成模塊、相似度計算模塊、譯文處理模塊。其中,相似度計算模塊又分為句法處理模塊、語義計算模塊。如圖2所示為系統總體架構。
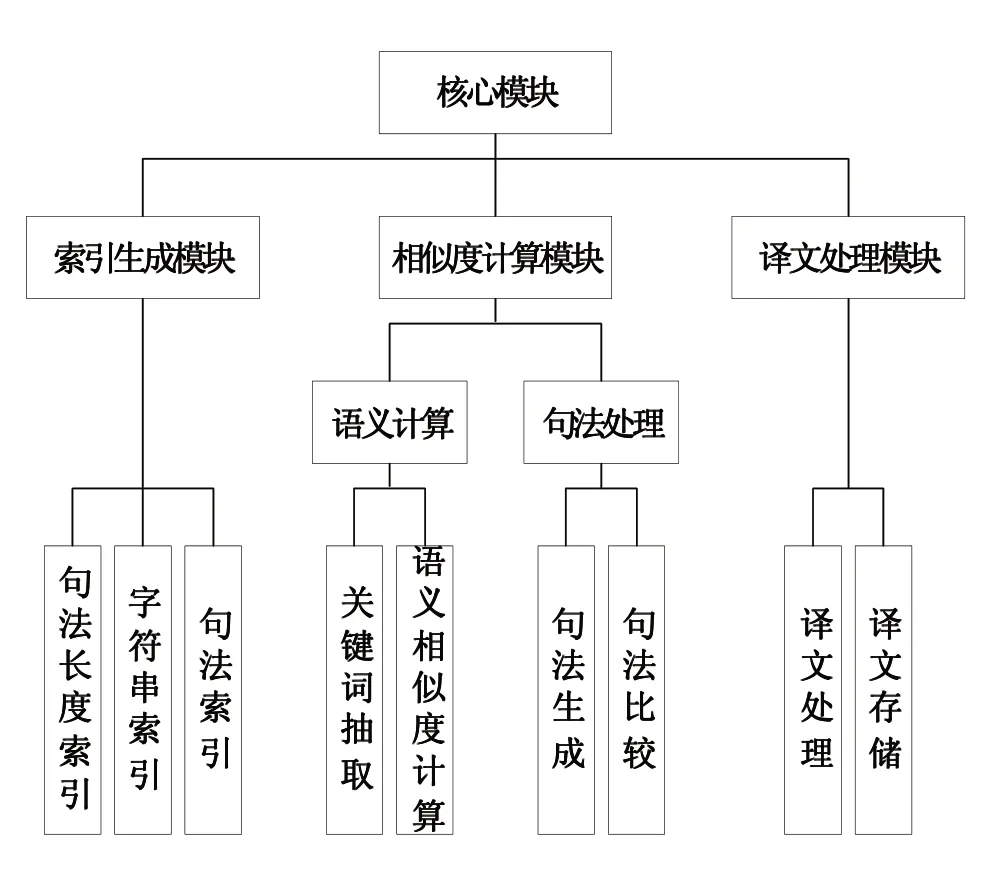
圖2 系統總體架構
該架構中,索引生成模塊包括句子長度索引、字符串索引、句法索引3項功能;譯文處理模塊包括譯文處理、譯文存儲2項功能;句法處理模塊包括句法生成、句法比較2項功能;語義計算模塊包括關鍵詞抽取、語義相似度計算2項功能。
(1)句子長度索引:以“句子長度”為對象,在記憶庫中創建索引關系;
(2)字符串索引:以“字符串”為對象,在記憶庫中創建索引關系;
(3)句法索引:以“句法”為對象,在記憶庫中創建索引關系;
(4)句法比較:采用相似度計算方法,對原句和譯文結果中的句法進行比較;
(5)句法生成:通過相似度計算,生成句法相似度計算結果;
(6)關鍵詞抽取:從原句中抽取關鍵詞,作為譯文比對重點對象;
(7)語義相似度計算:采用相似度計算方法,對原句和譯文結果中的語義進行比較。
4.2 系統總體作業流程
按照如圖2所示的總體框架結構,設計系統總體作業流程:
第一步:向系統中輸入需要翻譯的語句;
第二步:根據英漢語言轉換需求,確定翻譯語句的語言類型;
第三步:分析句子字符串、長度,調用系統記憶庫,從庫中找到相似的譯文資源;
第四步:對比譯文資源的句子與原文的語義是否相符,如果相符,則輸出譯文,反之,執行下一步;
第五步:將句法作為資源搜索條件,從記憶庫中搜尋與原文的句法相似的例句;
第六步:計算記憶庫生成句子與原句的句法相似度;
第七步:從生成的例句中,挑選出句法相似度最高的例句,作為譯文結果;
第八步:根據用戶對譯文結果的滿意程度,決定是否對譯文進行更改。如果對譯文滿意,則直接輸出譯文結果,反之,對譯文采取修正處理,并將相關信息存儲至系統記憶庫中。
4.3 翻譯記憶庫設計
翻譯記憶庫分為3個級別,包括詞匯級、句子級、更深層級。其中,采用詞匯級設計的記憶庫優點為:譯文生成過程比較簡單,記憶庫作業簡單;缺點為:加工程序較為繁瑣,降低了翻譯效率。采用句子級設計的記憶庫優點為:加工程序比較簡單,容易擴充,句子翻譯較為清晰,容易比對;缺點為:譯文生成計算難度較高,對雙語資料的加工處理要求偏高。采用更深層級設計的記憶庫優點為:譯文生成的信息偏多,包括句子結構、詞類等,譯文資源較多;缺點為:加工程序頗深,加大了譯文信息例句擴充難度。
通過對比上述3個層級的實例庫的優點和缺點可知,如果前期譯文工作量較少,后期記憶庫的加工程度就會更大,反之前期工作量過重,后期可以降低加工程度,但是增加了管理工作量。對于英語句子的翻譯,是將句子拆分為多個簡單的句子,每個句子又分為主語、謂語、賓語。因此,本系統設計記憶庫時,以簡單句子為單位,根據句子成分展開翻譯,以此降低譯文難度,使得記憶庫開發比較容易實現。
本系統設計的記憶庫,兼顧系統管理與譯文檢索效率,以句子的句法、語義作為檢索要點,設計如表1所示的記憶庫結構。
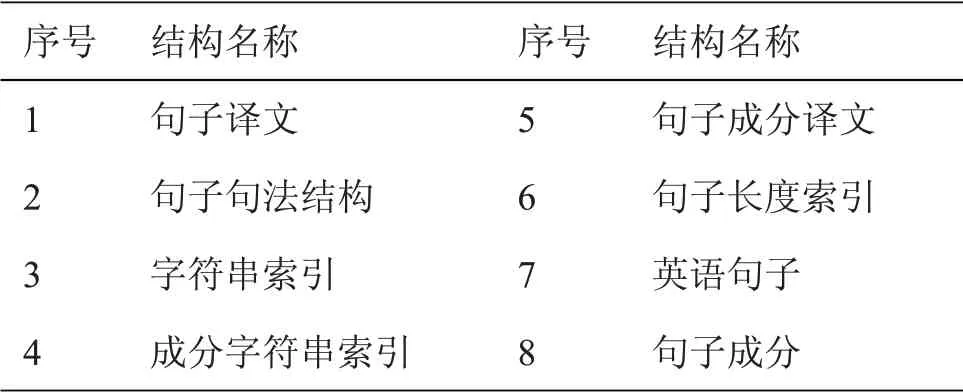
表1 記憶庫結構
按照表1所示的記憶庫結構,存儲譯文資源,如果譯文結果未能得到用戶認可,則存儲用戶更改過的譯文信息,作為下一次相同句子翻譯參考依據。
關于記憶庫的創建,利用SQL Sever軟件開發3個數據信息表,表中的信息按照表1中的結構編輯。以下為3個數據信息表的設計方案:
(1)Component表:用于存儲句子的各個譯文內容和句子結構。
(2)Structure表:用于存儲與句子相關的信息,例如:譯文的句法結構等。
(3)Sentence表:用于顯示譯文結果,包括英語句子信息、漢語句子信息,兩部分信息相對應。
4.4 相似度計算
本系統采用相似度算法,對原句、譯文句子的相似度進行判斷,該判斷結果將作為系統翻譯處理依據。如果相似度達到100%,則輸出譯文結果,如果相似度不足,則繼續遍歷譯文結果,經過對比計算相似度參數數值,如果仍未達到100%,則與之前遍歷的譯文相似度數值進行對比,取最大值。而后判斷當前是否仍然存在未計算相似度對應的譯文例句,如果存在,繼續遍歷譯文并計算相似度,與之前最大值進行對比,直至所有譯文例句的相似度數值計算結束,從中選取相似度數值最大的譯文語句作為譯文結果,輸出譯文結果后,等待用戶審核,判斷是否對此譯文結果滿意,如果不滿意,更改譯文結果。如圖3所示為相似度計算流程。
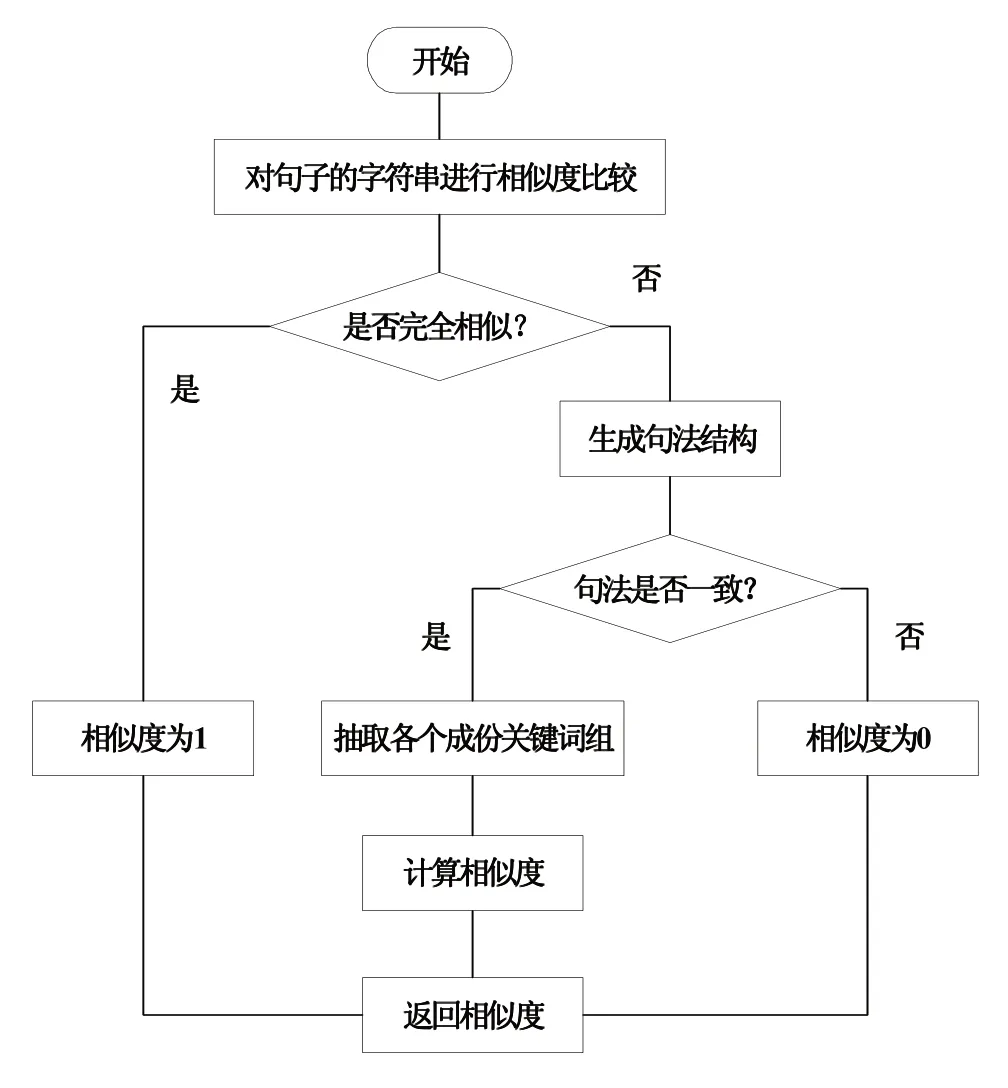
圖3 相似度計算流程
首先,以句子的字符串作為對比對象,開展相似度對比。如果句子中的字符串完全相似,則生成相似度結果為“1”,反之,生成原句的句法結構,將其作為下一步相似度對比對象。接下來,對比原句的句法與譯文的句法是否一致,如果達成一致,則從譯文中抽取各個成分關鍵詞組,計算相似度,并生成相似度結果,數值范圍[0,1]。如果句法未能達成一致,則生成相似度結果為“0”。最后,返回相似度計算初端,開啟下一次句子相似度計算。
4.5 譯文生成
本系統針對英漢語句的翻譯,采用相似度算法進行計算,所得計算結果范圍[0,1]。按照相似度取值情況,將譯文匹配類別劃分為3種:(1)“完全不匹配”,對應相似度數值為0,此情況需要修改譯文才可以使用,譯文生成的流程為“wrong size”→“invalid value”→“非法值”→修改大小錯誤→生成譯文結果。(2)“模糊匹配”,對應相似度數值為(0,1),此情況需要采用人工翻譯生成的譯文才可以使用,譯文生成的流程為“has”→“has”→“有錯誤”→調整部分譯文結果→生成譯文結果。(3)“完全匹配”,對應相似度數值為1,直接復用譯文即可,譯文生成的流程為“TIFF IFD array entry”→“TIFF IFD array entry”→“TIFF圖像的IFD數組項”→復用“TIFF圖像的IFD數組項”→生成譯文結果。
5 系統測試與分析
5.1 測試內容與方法
(1)英漢翻譯系統的索引生成和關鍵詞的提取
索引生成測試:記憶庫中,創建主索引和次索引。其中,主索引創建建立在英語句子字符串基礎上,次索引創建建立在句子長度基礎上,根據索引關系在記憶庫中快速完成句子的檢索,從而找到與待譯句子相近的例句。
關鍵詞的提取測試:主要測試系統提取出的關鍵詞是否為待譯句子的核心和主要詞匯。
(2)英漢翻譯系統相似度測試
本次測試以傳統機器翻譯系統作為對照組,以本文設計的英漢翻譯系統作為實驗組,分別對兩種系統的英漢語句翻譯中譯文結果相似度進行測試。測試中,分為兩種情況,其中一種情況為不含有重復句子(全為新句),另外一種情況為含有重復句子(部分為新句)。每種情況設定英語句子的數量分別為200個、400個、800個。
(3)英漢翻譯系統耗時測試:該項測試內容以不同情況下的系統作業耗時作為主要測試指標,兩種情況及英語句子數量設置同測試內容(2)。
5.2 測試結果分析
對本系統的索引生成和關鍵詞的提取功能進行測試,結果如表2所示。
表2中測試結果顯示,本系統能夠有效創建待譯句與數據庫中例句之間的索引關系,并且提取句子關鍵詞的可靠性較高,有助于系統英漢翻譯準確性的提升。

表2 系統索引生成和關鍵詞提取功能測試結果
另外,按照系統測試內容與方法,分別對傳統機器翻譯系統、本翻譯系統的譯文相似度、耗時情況進行測試,結果如表3、表4所示。
表3中,與傳統機器翻譯系統相比,本文設計的翻譯系統生成的譯文相似度更高,僅有英語句子增加至800個時,存在2個句子譯文相似度未能達到標準,而傳統機器翻譯系統的譯文相似度不達標數量達到了37個。針對重復語句情況,本翻譯系統的譯文相似度效果更佳,僅有1個句子譯文未能達到標準,而傳統機器翻譯系統的譯文相似度出現了下降變化趨勢。因此,本翻譯系統在英漢句子翻譯中的精確度更具優勢。
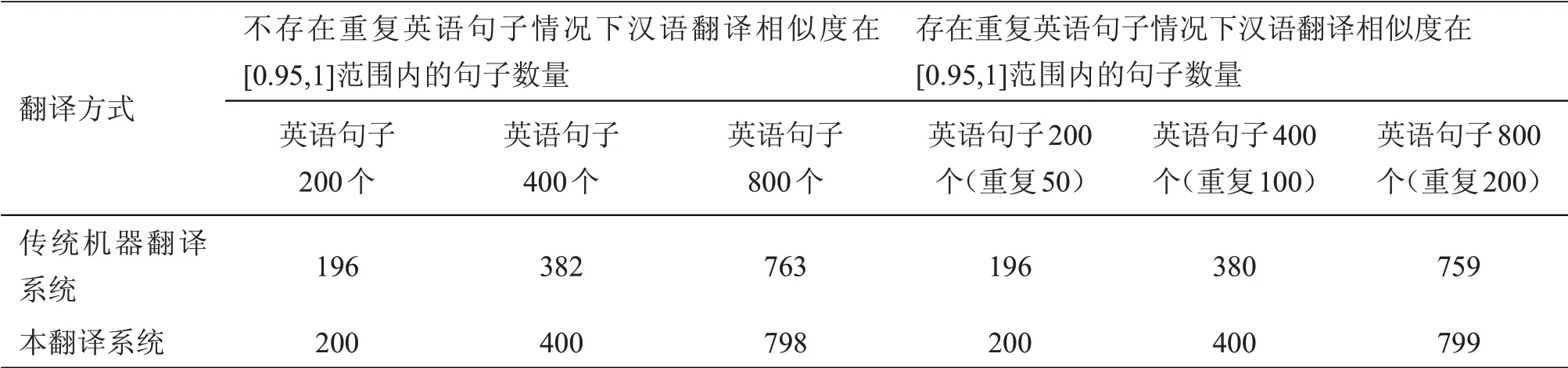
表3 英漢翻譯系統的譯文相似度測試結果
表4中,與傳統機器翻譯系統譯文耗時情況相比,本翻譯系統在不同情況下的譯文耗時更短一些,隨著句子數量的增加,單個句子譯文耗時明顯下降。另外,英語句子中存在重復語句情況下,傳統機器翻譯系統的耗時幾乎保持不變,而本翻譯系統的耗時出現了明顯下降的變化特點。因此,本翻譯系統在英漢句子翻譯中的耗時更具優勢。

表4 英漢翻譯系統的耗時測試結果
6 結語
本文采用翻譯記憶技術,以語義、句法作為翻譯處理指標,設計一套英漢翻譯記憶系統。該系統通過構建記憶庫,將兩種語言的翻譯資源存儲至其中,而后按照原文中的語義、句法,提取記憶庫中的資源,與原文進行匹配,取相似度最高的譯文作為翻譯結果,經過人工修正生成譯文。系統測試結果表明,本系統能夠更為精準地翻譯句子,且作業效率較高。
猜你喜歡
中華詩詞(2021年3期)2021-12-31 08:07:22
大連民族大學學報(2021年2期)2021-07-16 05:41:42
開放教育研究(2020年2期)2020-03-31 01:54:14
中華詩詞(2018年3期)2018-08-01 06:40:40
中華詩詞(2018年11期)2018-03-26 06:41:32
作文周刊·小學一年級版(2016年27期)2017-06-03 23:21:17
現代語文(2016年21期)2016-05-25 13:13:44
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
海外文摘(2016年4期)2016-04-15 22:28:55
