碳排放數據報送聯盟鏈的架構與信譽評價
2022-12-01 06:00:32汪鵬文亞鳳
電子設計工程 2022年23期
汪鵬,文亞鳳
(華北電力大學電氣與電子工程學院,北京 102206)
我國已明確碳達峰與碳中和的目標[1],發電廠的碳減排很重要。碳排放配額指標是電力市場促進碳減排高效的政策工具,但是在碳排放配額指標分配中基準線值[2]的確定依賴于發電廠大量真實的碳排放數據。目前,碳排放數據報送過程中多方機構難以建立互信且發電廠參與積極性不高。
區塊鏈憑借去中心化等優勢為碳排放數據報送中多方機構建立互信提供了新的解決方案,發電廠參與積極性問題也可以通過激勵機制解決[3]。目前已有若干學者將區塊鏈與激勵機制有機結合形成了一部分研究成果。文獻[4]針對區塊鏈激勵架構展開研究,為激勵機制的場景適配與效果評估提供了參考;文獻[5]以通用代幣作為激勵開發了K-匿名激勵機制系統;文獻[6]引入了信譽值概念;文獻[7]憑借信用評價體系為參與綜合能源服務方注入活力;文獻[8]依靠信任值促進車輛積極參與用戶信息交易;文獻[9]分析了清潔能源消納激勵機制的設計思想;文獻[10]構建了基于智能合約的數據共享激勵機制;文獻[11]提出的激勵模型將信任度高節點獎勵作為主節點;文獻[12]為多場景激勵機制框架搭建提供了參考。
綜上,現有研究主要將區塊鏈技術與激勵機制有機結合應用于數據共享或清潔能源消納方面,在碳排放數據報送方面待進一步突破。因此該文在碳排放數據報送系統中構建了基于聯盟鏈技術的應用架構,其次,在激勵層設計了信譽評價機制,并通過實例仿真驗證了其適用性。
1 碳排放數據報送中聯盟鏈技術應用架構
1.1 碳排放數據報送系統的框架
現有區塊鏈模式有三種:公有鏈、聯盟鏈與私有鏈,它們在建鏈原則、共識機制方面存在顯著差異[13]。公有鏈任何人都可以參與,去中心化程度最高但算力消耗巨大;聯盟鏈只允許授權節點參與區塊的生成、驗證與訪問,是當下區塊鏈應用部署的熱點;私有鏈記賬權通常由中心機構掌握。將三種區塊鏈模式進行對比,如表1 所示。

表1 三種區塊鏈模式的優劣
實際應用需根據場景選擇區塊鏈模式,考慮碳排放數據的報送需碳排放數據分析中心與各類發電廠共同參與,且運行效率要求較高,因此應用聯盟鏈技術。參照文獻[14],將基于聯盟鏈的碳排放數據報送系統框架分為物理層與虛擬層,如圖1 所示。

圖1 碳排放數據報送系統框架
1)在物理層中,各類發電廠在數據源頭把控碳排放數據質量,而碳排放數據分析中心依據報送數據進行研究得出分析報告,有利于電力行業基準線值劃定,從而促進清潔能源的消納。
2)虛擬層為碳排放數據報送系統中聯盟鏈技術的應用,點對點傳輸技術去除了中心機構對數據報送的影響,分布式存儲保障了數據的不可篡改與可溯源。另外,鏈中節點又被分為主節點與普通節點,碳排放數據分析中心為主節點,各類發電廠經過準入許可成為普通節點。準入過程使碳排放數據分析中心對各類發電廠起到了監管作用,保證了鏈上節點的可靠性。
發電廠通過授權加入聯盟鏈的步驟如下:首先,發電廠發送加入意圖至鏈上任一節點,收到信息的對應節點向其反饋聯盟鏈中主節點地址。其次,發電廠向聯盟鏈主節點發出公鑰地址、身份認證等申請信息,在主節點確認其身份后,將其公鑰地址寫入聯盟鏈頭部注冊表,然后新節點公鑰進行全鏈廣播。之后,新節點通過自己的私鑰加密申請信息,并廣播通知到主節點之外的所有節點。最后,主節點之外的所有節點成功獲取新節點申請信息則進行回復,若新節點接收到所有節點的回復,則表明加入聯盟鏈成功。聯盟鏈中機構準入過程如圖2 所示。

圖2 聯盟鏈中機構準入過程
1.2 聯盟鏈的基礎架構模型
區塊鏈的基礎架構分為六層[15],各層對應不同功能,總體實現去中心化,從而為多方提供可信的基礎。根據碳排放數據報送系統需要設計聯盟鏈基礎架構模型,如圖3 所示。

圖3 聯盟鏈的基礎架構模型
1)數據層包括碳排放數據區塊、哈希算法與鏈式結構。每個區塊分為區塊頭和區塊體兩部分,其中,區塊頭記錄了時間戳、默克爾樹根與前一區塊哈希值,而區塊體包含一個區塊的全部碳排放數據。鏈上首個區塊到當前區塊依據時間順序按鏈式結構相連,實現碳排放數據可溯源。
2)網絡層包括傳播機制、驗證機制與分布式對等網絡(P2P 網絡)。P2P 網絡中節點地位對等,碳排放數據傳遞不依賴中心機構而在節點之間進行,通信的靈活性與可靠性得以提高。
3)針對傳統實用拜占庭容錯機制(PBFT)工作效率低的問題,專家通過對比實驗證明,基于信譽投票的PBFT 優化方案起到改善的效果[16]。參照該方案在共識層設置基于信譽評價的PBFT 共識機制,動態選取信譽評價優的節點參與鏈內區塊驗證,從而縮短共識時間,提高聯盟鏈的運行效率。
4)激勵層設計了旨在促進發電廠參與積極性的信譽評價機制。發電廠只有提高碳排放數據報送滿意度才能提高本身的信譽評價,而信譽評價優的發電廠更容易被碳排放數據中心選擇。
5)合約層包括智能合約與預置的腳本代碼及算法機制。在碳排放數據報送過程中,智能合約只要觸發條件便立即執行預置條款。
6)聯盟鏈在應用層封裝了碳排放數據報送的各種典型應用,包括但不限于發電廠(機構)準入應用、信譽評價應用、碳排放數據報送應用等。
碳排放數據報送在聯盟鏈的信息交互過程如圖4 所示。碳排放數據分析中心上傳數據要求后,合約層選擇調用合適的合約,激勵層讀取信譽評價要求,共識層基于信譽評價的PBFT 共識機制選取節點參與共識,網絡層完成數據報送全過程的節點互聯互通,數據層將碳排放數據區塊按照分布式存儲方式存儲在各個節點。

圖4 聯盟鏈信息交互過程
2 激勵層的信譽評價機制設計
在分析了碳排放數據報送系統中的聯盟鏈架構后,針對發電廠碳排放數據報送缺乏積極性的難題,在聯盟鏈激勵層設計信譽評價機制。發電廠每次數據報送完畢,碳排放數據分析中心可以根據報送全過程的體驗對發電廠進行信譽評價,之后系統調用智能合約自動更新發電廠信譽評價積分。碳排放數據分析中心通過信譽評價機制能夠充分了解發電廠的過往信譽情況,并在挑選發電廠時做出更合理的選擇。
在碳排放數據報送中,發電廠將碳排放數據的數據總量D、報價P提交到聯盟鏈系統,然后等待碳排放數據分析中心回復。智能合約將依據預置算法處理發電廠的報價P、數據總量D與信譽評價E數據,綜合衡量后為碳排放數據分析中心推薦合適的方案。每次碳排放數據報送完畢,碳排放數據分析中心需提交參與該次報送發電廠的數據質量打分、交易履約情況打分、業務咨詢情況打分,三項分值最終決定發電廠該次的信譽評價。綜合考慮以上因素,設計了相應數學計算公式,數學計算公式為:
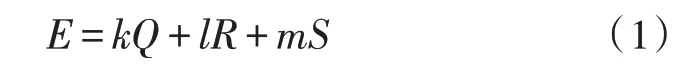
式中,Q表示之前x次數據質量打分的均值,R表示之前x次交易履約情況打分的均值,S表示之前x次業務咨詢情況打分的均值,k、l、m表示各打分均值的相應權重。
CRITIC 權重法綜合考慮了指標對比強度與指標之間的沖突性,在客觀賦權方面性能優于標準離差法與熵權法[17],因此信譽評價機制選擇采用CRITIC 權重法衡量各評價指標的權重。
設定存在n個評價對象,p項評價指標,則起始指標數據矩陣為:

式中,xij代表第i個評價對象第j項評價指標的數值。
各評價指標需要進行如下無量綱化處理:

標準差(可以了解各評價指標內的取值差異波動狀況)的計算方法為:

式中,Sj代表第j個評價指標的標準差。
相關系數(可以了解評價指標間的相關性)的計算方法為:
鋼板路基箱臨時道路是在長期實踐的基礎上研發的道路結構,但由于垃圾沉降及道路積水影響,鋼板路基箱容易發生漂移、分離,行駛車輛經常發生輪陷、側翻事故。為此對路基箱進行了多項改進,以鋼板路基箱連接技術為基礎[1],優化跨明溝鋼板與路基箱連接,保障車輛通行安全;優化倒車平臺與路基箱連接形成的簡易卸料平臺,在保證安全的前提下提高效率。

最后得到第j個評價指標Wj的權重:

式中,Cj代表第j個評價指標的信息量,計算方法為:

設定某一范圍內存在若干電廠,信譽評價機制運行過程如圖5 所示。首先,電廠上報碳排放數據的報價與數據總量。其次,智能合約調用對應電廠的信譽評價積分,然后在綜合考慮報價、數據總量、信譽評價下核算推薦方案。最后碳排放數據分析中心決策出參與報送的電廠,并在報送完成后對該次參與的電廠進行評價,智能合約同步更新對應電廠的最新信譽評價積分。

圖5 信譽評價運行過程
通常選擇具體的發電廠時,報價低的發電廠更容易被考慮,但是報價低的發電廠難以保證碳排放數據的高可靠性,因而文中在激勵層設計信譽評價機制,該機制依據各發電廠以往數據的報送情況計算其最終信譽評價積分。綜合權衡報價、數據總量、信譽評價積分三因素選拔發電廠,有利于引導發電廠提高參與報送積極性。
3 案例分析
碳排放數據分析中心挑選發電廠進行碳排放數據有償報送屬于多目標優化問題,基于粒子群算法的多目標搜索算法[18]通常是解決該類實際問題的較好方法。該類問題解決步驟主要為:首先確定目標函數、約束條件與決策變量參數,然后通過隨機解迭代計算求出一個非劣解子集,最后依據決策者意愿得出最終解。
設定碳排放數據分析中心希望獲得五類發電廠(火電廠、風電廠、核電廠、水電廠、太陽能電廠)的碳排放數據,實際中每類發電廠有四家可供選擇。這些發電廠在數據報價、數據總量、信譽評價方面都存在差異,而碳排放數據分析中心希望數據報價越低越好,數據量越大越好,信用評價滿足約束條件。在以下碳排放數據報送模型中,數據報價通過P表示、數據總量通過D表示,出售方信譽評價通過E表示,選擇的賣方用Y表示。構造的目標函數和約束條件為:

式中,P1表示購買數據總花費,D1表示購買數據的數據總量,另外出售方總體信譽評價約束條件為86 分。
現設定發電廠報價、數據總量、信譽評價分別如表2、表3、表4 所示。其中,k取值1~5 分別代表火電廠、風電廠、核電廠、水電廠、太陽能電廠,Mk、Nk、Ok、Pk代表每類電廠中可供選擇的四個發電廠。
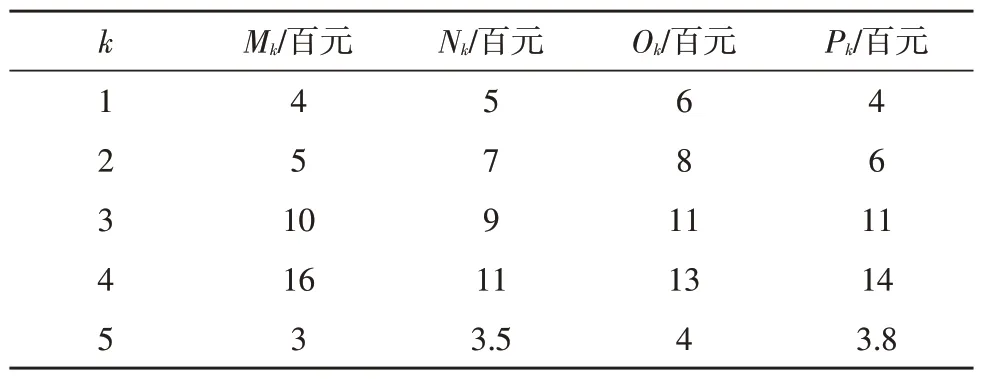
表2 發電廠報價表

表3 發電廠數據總量表

表4 發電廠信譽評價表
對表格進行舉例說明如下:表1 中,M1、N1、O1、P1代表四個不同火電廠,而它們的報價分別是400 元、500 元、600 元、400 元;表2 中,M2、N2、O2、P2代表四個不同風電場,它們的數據總量分別是3兆、3.5 兆、3.6 兆、3.2 兆;表3 中,M3、N3、O3、P3代表四個不同核電廠,它們的信譽評價分別為75 分、93 分、86 分、79 分。
按照上述確定好的目標函數、約束條件與決策變量參數,通過Matlab 將該實例進行仿真,得到非劣解空間分布如圖5 所示,包括非劣解方案共計五種。圖中縱軸對應每種方案所需的總花費,橫軸對應每種方案包含的數據總量。
5 種非劣解方案對應電廠具體選擇情況如表5所示。舉例說明如下:方案1 中,選擇火電廠P1、風電廠O2、核電廠O3、水電廠P4、太陽能電廠P5五個電廠報送數據;方案2 中,選擇火電廠P1、風電廠M2、核電廠O3、水電廠P4、太陽能電廠P5五個電廠報送數據。

圖6 粒子群尋優仿真結果圖
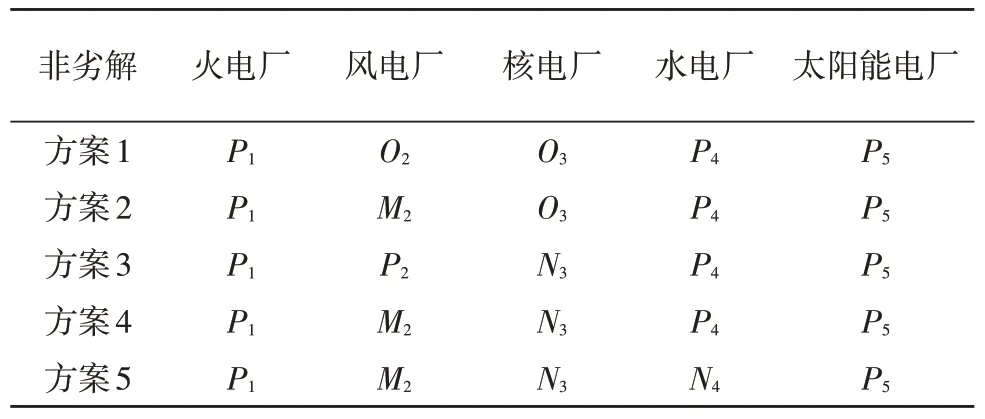
表5 非劣解方案表
聯盟鏈中智能合約將依據總花費將5 種非劣解方案進行排序,如表6 所示,每種方案同時附帶數據總量與出售方信譽評價。將推薦方案表發送至碳排放數據分析中心,為其選擇發電廠提供全面參考。

表6 推薦方案表
4 結束語
該文研究了碳排放數據報送聯盟鏈架構,促進了發電廠與碳排放數據分析中心的互通、互信,設計的信譽評價機制解決了發電廠參與積極性不高的難題,實例分析驗證了信譽評價在碳排放數據報送中的適用性。未來的工作中,信譽評價機制中的考核因素應隨著相關部門最新政策的發布、市場的具體情況做出更合理的設計。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:48
石油瀝青(2021年4期)2021-10-14 08:50:44
瘋狂英語·初中天地(2021年4期)2021-06-09 06:50:54
文苑(2018年21期)2018-11-09 01:23:06
中國衛生(2015年9期)2015-11-10 03:11:12
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國衛生(2014年3期)2014-11-12 13:18:12
中國火炬(2014年4期)2014-07-24 14:22:19
自動化博覽(2014年5期)2014-02-28 22:31:36
河南科技(2014年10期)2014-02-27 14:09:22
