基于行為監測的嵌入式操作系統堆棧溢出測試*
2022-11-17 11:56:06楊興達
計算機工程與科學 2022年11期
楊興達,陳 燦,方 菱
(1.安徽大學物質科學與信息技術研究院,安徽 合肥 230000;2.中國科學院合肥物質科學研究院,安徽 合肥 230000)
1 引言
嵌入式操作系統是一種面向安全關鍵的系統,其堆棧安全至關重要。豐田的凱美瑞車型曾發生過嚴重的意外加速UA(Unintended Acceleration)事故,事故就是由于堆棧溢出造成TASKX死亡所導致的[1]。堆棧溢出通常難以捕捉,因為異常暴露的時間可能滯后于其發生時間。例如,任務P的堆棧溢出,并侵占優先級較低的任務Q的私有堆棧,則至少在任務Q被調度并運行前,系統看起來一切正常。當任務Q顯露異常時,開發者難以確定此異常是由任務Q本身造成的還是由其它任務的堆棧溢出引起的,更難以定位造成堆棧溢出的具體代碼[2]。另外,為了避免堆棧溢出,開發者經常會無意識地過度分配堆棧,而嵌入式系統是一種資源受限的系統,堆棧資源的浪費將會增加隨機存取存儲器RAM(Random Access Memory)的成本。在理想的情況下,開發者為各任務堆棧預分配的空間應該略大于該任務實際使用堆棧的極大值。但是,人為地預估堆棧空間十分困難,也無法保證預估結果的準確性。
2 相關研究
關于堆棧溢出測試,相關研究人員進行了一定的研究。
Zhang等人[3]定義了一種用于描述函數間調用行為的樹形結構,并通過在樹形結構中提取極端樹的方式來計算堆棧使用的極大值,從而避免可能的堆棧溢出問題。這種方法雖然可以靜態地對系統堆棧進行評估,但是其分析過程比較復雜,需要人為考慮所有的極端情形并繪制函數樹模型,且每種函數樹的模型都不盡相同,導致此方法在實際工程測試中不夠高效。
Xie等人[4]提出了一種算法,可以將堆棧溢出的檢測問題轉化為整數范圍的分析問題。該算法先使用函數定位模塊計算代碼檢測范圍,然后將調用函數與風險函數庫中的函數進行比對,以掃描檢測范圍內所有的風險函數,最后通過對風險函數的參數進行分析來準確計算當前函數所需堆棧是否會溢出。該算法仍具有一定的局限性,因為它十分依賴風險函數庫。如果被調函數不在風險函數庫中,或者造成堆棧溢出的只是一條賦值語句而非函數,那么該算法就會失效。
Choi等人[5]提出了一種基于靜態分析配置文件的堆棧最大值動態監測方法。該方法首先通過分析可執行與可鏈接格式ELF(Executable and Linkable Format)文件提取與函數相關的數據,然后使用深度優先搜索DFS(Depth First Search)確定堆棧最大值,最后通過監測堆棧最大值的地址是否被改寫來捕獲堆棧溢出。該方法雖然可以動態地發現堆棧溢出,但是不能定位溢出位置。
針對相關研究中存在的不足,本文提出了一種基于實時堆棧分配與回收行為監測的動態堆棧測試方法。首先,靜態地確定堆棧行為測試點;接著在測試點上采用一套標準的數據采集與分析流程進行堆棧監測,無需對不同測試點進行特殊改動,在測試效率上有所提高,并在靜態分析方法上進行了動態補充;其次,通過插樁來覆蓋源代碼中所有的堆棧行為測試點,并不依賴于任何第三方庫,不會出現失效問題;最后,不僅可以通過堆棧指針SP(Stack Pointer)地址判定堆棧溢出,還能夠實時定位發生溢出的源代碼,對堆棧溢出測試的功能性進行了拓展。
3 堆棧行為動態監測方法
本節將介紹任務堆棧分配與回收行為實時監測方法的總體設計與具體實現。
3.1 相關技術概述
下面將簡單介紹后文所提及的相關技術。
(1)靜態測試與動態測試:在嵌入式軟件測試中,靜態測試是基礎,動態測試是必要補充[6]。靜態測試往往是通過提取源代碼編譯生成的匯編代碼或二進制代碼中的一些特征進行分析,或者構建模型后對模型進行測試驗證。比如Fang等人[7]先通過形式化方法建模并驗證模型,然后再根據模型開發測試用例生成器,對嵌入式實時操作系統進行了高效的測試驗證。動態測試則是通過某種方式獲取程序運行時的軌跡信息進行分析[8,9]。動態測試所發現的漏洞是軟件中實際存在的,不會誤報,并且動態測試不需要像靜態測試那樣進行復雜的數據流分析[10]。
(2)軟件插樁技術:軟件插樁是一種在軟件運行時進行的狀態分析技術,廣泛應用于軟件質量評價、漏洞挖掘、性能分析與優化等領域中,是解決軟件執行路徑收集、關鍵函數調用分析等問題的主要手段[11,12]。
(3)HOOK技術:HOOK是一種操作系統內部的回調函數,會在特定的事件到來之際被回調執行。
(4)控制器局域網絡CAN(Controller Area Network)協議:CAN是一種用于實時應用的串行通信協議總線,可用于汽車中各種不同元件之間的通信。
(5)分布式處理:將位于不同地點或具有不同功能或擁有不同數據的多臺計算機通過通信網絡連接起來,協調地完成信息處理。
3.2 測試框架概述
本文方法首先靜態分析了源代碼中所有可能的測試點。對于堆棧溢出測試來說,測試點就是具有堆棧分配或回收行為的代碼行。接著,通過軟件插樁技術在測試點插入用于采集堆棧數據的樁函數接口。開發者在編寫代碼時就可以自行插樁,以減輕測試者的負擔,樁函數的插入邏輯和編碼行為類似于HOOK函數。
插樁后,樁函數應在被測系統實際運行時動態收集測試點的堆棧數據并進行實時分析。為了規避數據分析給操作系統帶來的額外工作負荷,本文方法采用了分布式處理的設計思想來進行數據分析,即被測系統僅采集數據,數據分析的工作則交由另一臺機器負責。被測系統在完成數據采集后立即將數據傳送給上測試器UT(Upper Tester),再由UT完成實時的數據分析和溢出判定工作。另外,測試數據的統計和堆棧溢出的報警服務也由UT提供。
因為本文方法的被測系統通過CAN進行數據傳輸,其在傳輸超過8字節的數據時需要分包,為了進一步降低數據傳輸對操作系統運行效率的影響,本文方法將采集到的數據壓縮成8字節長度的測試碼,具體的測試碼設計規則將在3.4節中介紹。最后,UT根據測試碼的設計規則來反向解析,得到實時的堆棧數據,并進行堆棧溢出判定。當堆棧溢出發生時,測試者可以通過UT實時發現異常,并根據測試點的信息來定位源代碼中造成堆棧溢出的確切位置。本文方法的測試流程如圖1所示,測試架構如圖2所示。
徐進步站在一個塔頭上,一點也不知道身后背包里一長截手紙垂下來了。上海女知青謝菲站在另一個塔頭上,用上海話朝他喊:“你把你那尾巴卷起來行不行,拖那么長尾巴,演大老鼠啊!”

Figure 1 Workflow diagram of the proposed method圖1 本文方法工作流程圖
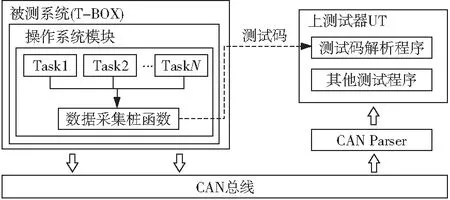
Figure 2 Test frame of the proposed method圖2 本文方法測試框架圖
3.3 消除數據解析延遲的影響
測試碼由被測系統發送至UT顯然需要時間,且UT的解析反饋也會造成無法避免的延遲。為了消除延遲對測試的實時性影響,本文方法的測試碼包含了詳細的堆棧異常信息,其中包括發生異常的任務內部函數編號,使得UT只依靠延遲收到的測試碼也能準確定位到發生堆棧溢出的代碼位置。
3.4 基于堆棧結構與行為確定測試點
本文方法中被測操作系統進行任務堆棧分配時,會由高地址向低地址遞減分配,不同任務的私有堆棧空間被靜態確定后,在物理地址上是連續的,如圖3所示。

Figure 3 Physical structure diagram of task stack圖3 任務堆棧物理結構圖
每一塊任務私有堆棧都是由3個區域組成的,如圖4所示。A區域用于存放靜態數據,如普通指針、數組和常量等;B區域是任務的內部函數被調用時所申請的一塊空間,可以在被調用函數返回后回收再利用;C區域只有一個魔術數字,被用作堆棧溢出檢測。其中,B區域的F1和F2是2個不同的函數,F2在F1的調用返回后重用了F1的堆棧空間。F1.1是F1內部調用的一個函數,其堆棧是緊接著F1的棧頂分配的。圖4中的P1、P3、P5是具有堆棧分配行為的測試點,P2、P4則是具有堆棧回收行為的測試點,操作系統各任務中的每個測試點都需要被監測。另外,中斷服務程序ISR(Interrupt Service Routines)的堆棧行為與普通函數一致。對于A區域來說,其堆棧的分配行為在編譯器編譯完成后就已經確定了,故A區域只需要一個測試點就可以監測整個靜態數據區的堆棧情況。

Figure 4 Example of task stack allocation and reuse behavior圖4 任務堆棧分配與復用行為示例
在測試點插樁后,樁函數會將相應的測試碼通過CAN發送出去,每個任務都需要額外承擔發送測試碼的工作,所以每個任務的執行時間會加長,并且執行用時與測試點數量成正比。因此,本文通過一個全局宏開關來控制測試點樁函數的有效性,只有在測試模式時,宏開關才會被打開,樁函數才會得到執行。
3.5 堆棧數據壓縮與測試碼設計
測試碼需要記錄各種不同的測試資源,本文方法將測試碼的8字節作為8個數位以最大范圍地表示這些資源。
操作系統中每個任務的堆棧空間都是靜態分配的,從任務堆棧的起始地址(棧底,高地址,變量名為BOS)計算出其結束地址(棧頂,低地址,變量名為TOS)。因此,測試碼需要記錄BOS,而任務堆棧的靜態分配大小是已知的,無需記錄。另外,測試碼還需記錄當前任務SP的實時地址,用于判定堆棧是否溢出,正常堆棧的SP應該在[BOS,TOS]。最后,測試碼還應記錄任務中實時調用的函數信息,以在堆棧溢出時確定源代碼中發生異常的具體位置。鑒于某些函數簽名十分冗長,本文方法為各任務中的函數建立了映射,以數字而非字符串來標識不同的函數,使得測試碼能夠以較大的進制在有限的數位上表示更大的數據范圍。測試碼中各數位的職能信息如表1所示。另外,被測系統中的堆棧地址都具有0x40000000大小的固定偏移,為了壓縮數位空間,本文方法在采集堆棧地址信息后會移除偏移,以縮小數據范圍。例如,UT接收到的16進制測試碼“10 5C 10 04 30 30 30 34”表示當前任務已經回收了編號為4的函數所申請的堆棧空間,并且當前SP的地址為0x40001004,當前任務的堆棧上界為0x4000105C。

Table 1 Bit mapping table of test code
3.6 UT設計
UT接收到測試碼后,會解析測試碼并得到各個數位的信息。被測系統中測試所需的有效信息都應在UT中備份,這樣UT在進行數據分析時無需被測系統介入。另外,UT除了監測堆棧溢出,還需要比對任務在調用函數前后的SP記錄,以保證堆棧回收的正確性。如果某測試點的SP在堆棧分配前后不一致,則說明堆棧回收過程出現了異常,此時UT不能直接定位異常代碼,測試者需要排查其余任務的堆棧溢出異常來確定此回收異常的原因。
4 實驗與分析
本文通過對基于MPC5748G芯片的車載遠程信息處理器T-BOX(Telematics BOX)系統進行堆棧溢出測試,發現了如下問題:在1 ms周期性任務中,雖然沒有發生堆棧溢出,但是其堆棧被靜態分配得過大,造成了系統資源的浪費;在500 ms周期性任務和全球定位系統GPS(Global Positioning System)任務中,利用本文方法定位到了3處堆棧溢出。
具體地,在500 ms任務的數據打包函數中,開發者申請了一塊數組空間用于業務數據采集,當數組容量達到閾值時會打包上傳當前數據并清空數組以復用。但是,程序在擦除舊數組時發生了問題,導致數組前10個索引上的數據沒有被清除。隨著系統的持續運行,未被清除的垃圾數據越積越多,最終造成了任務堆棧溢出,系統被強制復位,RAM數據全部丟失。本文方法準確地定位到了這個異常,并且發現此異常溢出的數據覆蓋了與500 ms任務堆棧相鄰的任務中的部分數據。GPS任務中的1處堆棧溢出則是由于函數遞歸調用嵌套太深導致的,因為開發者在靜態分配任務堆棧時忽略了遞歸與ISR所需的堆棧空間,溢出直接造成了系統崩潰。另外,開發者違反了MISRA-C標準,該標準明令禁止任何直接的和間接的遞歸函數調用。
在修正了堆棧異常的代碼后,500 ms任務和GPS任務實際使用的堆棧極值分別為228和164。這2個任務中共有10個由極端環境觸發的硬件保護函數未被執行,導致測試點未觸發完全。通過估計并補償這部分函數所需的堆棧空間,本文方法最終將500 ms任務和GPS任務靜態分配的堆棧大小優化至242和190。
測試發現的全部堆棧異常信息如表2所示;操作系統中部分任務堆棧空間的靜態分配值和實際使用極大值對照如圖5所示;測試統計數據和相關優化如表3所示。
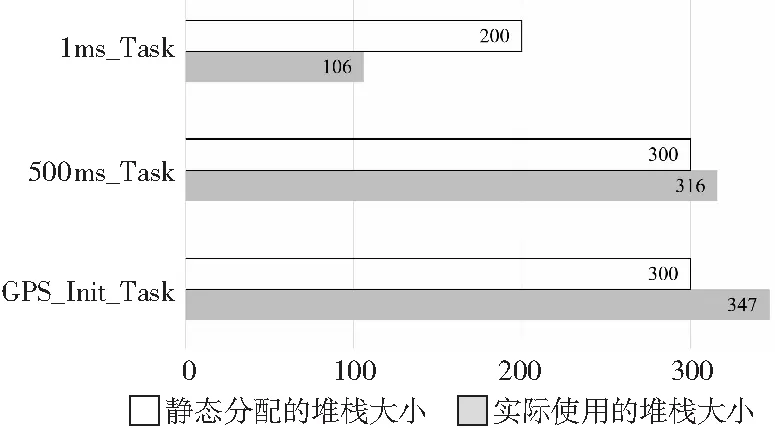
Figure 5 Comparison diagram of actual space used by task stack圖5 任務堆棧實際使用空間對照圖

Table 2 Exception information table of task stack表2 任務堆棧異常信息表
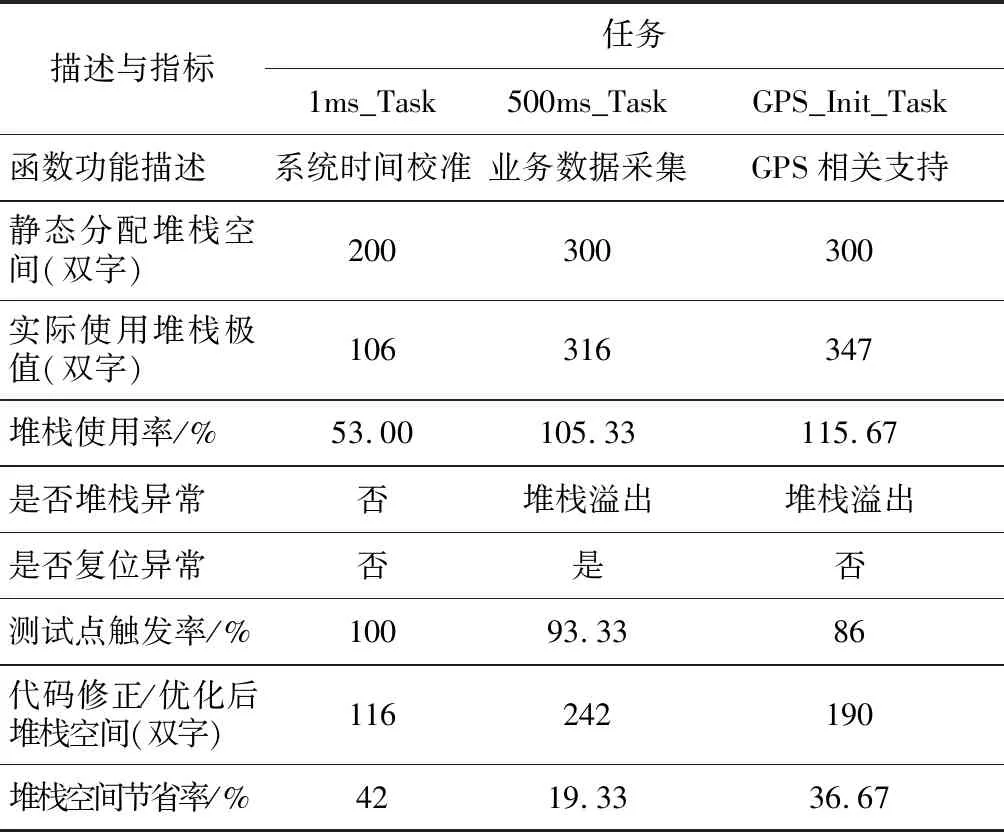
Table 3 Statistics table of test data
5 結束語
本文針對嵌入式操作系統的堆棧安全問題,提出了一種基于實時堆棧分配與回收行為監測的動態堆棧溢出測試方法。該方法不依賴于任何第三方庫,且不會產生誤報,解決了嵌入式操作系統堆棧溢出測試的實際工程問題,在實驗中精確定位到了3處堆棧異常,并檢測到1處受其它任務堆棧溢出影響而導致的數據覆寫異常。實驗結果表明,使用該方法動態監測嵌入式操作系統中的實時堆棧溢出問題是可行且有效的。另外,本文的測試結果可以指導操作系統任務堆棧的靜態分配。通過對全部6個操作系統任務插入232個測試點,本文方法共監測了232個函數,并在測試后對異常代碼進行了修正,對靜態分配過大的堆棧空間進行了優化。最后,將1 700個雙字的任務RAM優化到了1 071,即壓縮至原RAM空間的63%,開發者可以利用空余出的堆棧為操作系統增添一些新任務,或者更換RAM更小的設備以降低硬件成本。在未來,重點研究一種自動化的插樁工具,用于改善開發者或測試者需要主動執行代碼插樁的情形,以提高測試效率。
猜你喜歡
艦船科學技術(2022年13期)2022-08-11 09:30:02
鐵道通信信號(2020年9期)2020-02-06 09:15:22
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
兒童故事畫報(2019年5期)2019-05-26 14:26:14
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
