基于司外揣內原理的中醫“舌象-體質”深度學習模型構建研究
2022-11-09 09:54:42姜榮榮高佳奕
醫學信息 2022年18期
姜榮榮,高佳奕,楊 濤,3
(1.南京中醫藥大學護理學院,江蘇 南京 210023;2.南京中醫藥大學人工智能與信息與信息技術學院,江蘇 南京 210023;3.江蘇省中醫外用藥開發與應用工程研究中心,江蘇 南京 210023)
中醫體質學說是以中醫理論為主導,研究人類各種體質特征、體質類型的生理、病理特點,并以此分析疾病的反應狀態、病變的性質及發展趨向,從而指導疾病預防和治療的一門學說[1]。中醫體質辨識是中醫體質學說的核心內容之一,其通過四診采集臨床信息,通過中醫理論辨識出體質結果[2]。在中醫體質學說的發展過程中出現了多種體質分類方法[3-6],然而這些方法多依賴體質評分量表,效率較低,且問題回答存在主觀性,影響體質判定結果。中醫認為人是一個有機的整體,疾病變化的病理本質雖然藏之于內,但必有一定的癥狀、體征反映于外。司外揣內作為中醫診斷的基本原理之一,對中醫診斷和健康測評具有十分重要的意義。舌診是中醫診斷司外揣內原理的集中體現,是四診中望診的重要內容,人體的健康或疾病狀態在舌象上會有較為明顯的反映[7]。如何充分的利用舌診信息,客觀、標準、高效地評估中醫體質,已經成為中醫體質領域探索的方向之一。針對中醫體質辨識,相關學者從不同角度進行了研究和探索[8-10],但大多采用傳統機器學習算法構建中醫體質模型,模型的精度有待進一步提升。隨著計算機視覺技術的飛速發展,針對圖像的識別、處理和分析技術取得了巨大進步[11]。因此,本研究提出基于中醫司外揣內原理,構建“舌象-體質”深度學習模型,以期為中醫體質辨識智能化發展提供參考。
1 模型構建
考慮到中醫臨床舌象數據集的樣本數較少,且最終體質類別與舌色、舌苔色、舌形、舌態等多個特征潛在相關,特征不明顯與訓練樣本較少可能會導致最終的分類結果精度較低。本文參考Woo S 等[12]的方法構建特征注意力模塊,將舌圖的多尺度信息融入注意力模塊中,以殘差方式堆疊,學習不同尺度、不同權重的圖像特征,實現中醫體質辨識模型;此外,模型額外引入有關舌象的文本描述信息進行輔助訓練,通過文本與圖像多模態信息相結合的模型學習方式實現中醫體質的精準分類,模型結構見圖1。
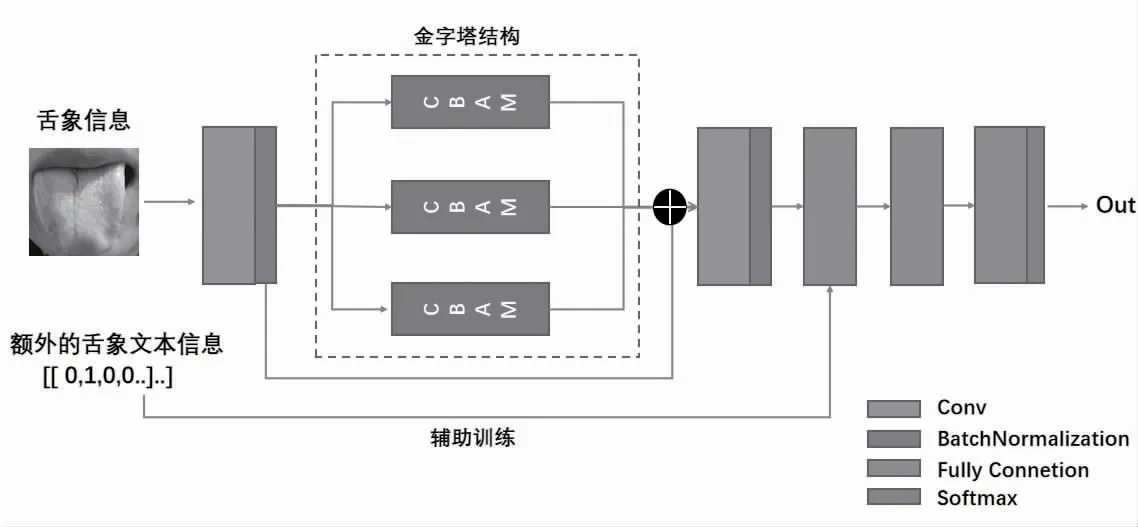
圖1 中醫體質辨識模型結構
卷積注意力模塊(convolutional block attention module,CBAM)[12]旨在對卷積操作后的信息進行深一步學習,為各特征分配不同權重,對結果貢獻明顯的特征給予較高權重,相反對貢獻較少的特征給予較少權重,將后續學習的關注點放在權重較高的特征上。本模塊中的注意力分為空間注意力與通道注意力,二者采用串聯的方式結合,見圖2。
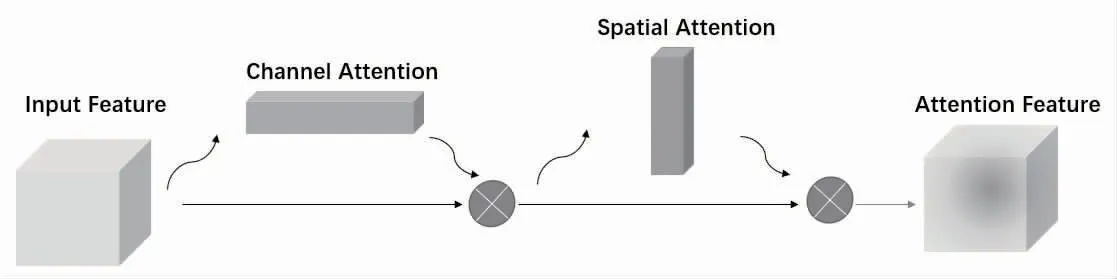
圖2 CBAM 注意力模塊
通道注意力即學習特征各個通道的重要程度,通過全局池化的方式將H*W 維度變換至1*1 維度,把注意力僅放在對通道特征的學習上。由于MaxPooling[13]與AveragePooling[13]的特點不同,又各具優勢(MaxPooling 側重于特征選擇,選出分類辨識度更高的特征;AveragePooling 側重于特征的融合,實現特征比較完整的傳遞),因此采用MaxPooling與AveragePooling 相結合的池化方式,Channel Attention 的結構見圖3。
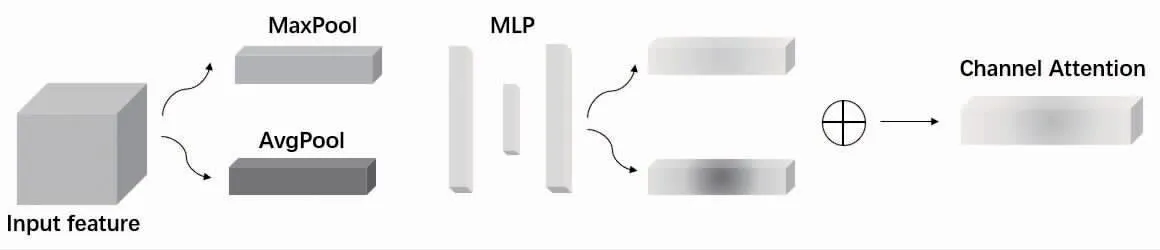
圖3 Channel Attention 結構
各個注意力模塊(CBAM 模塊)的卷積核空洞率(dilation rate)有所差異,卷積核采用不同的感受野范圍、堆疊注意力模塊的方式獲得不同感受野范圍(即多尺度)的特征,在原卷積核的基礎上獲得長距離依賴特征,以此進一步提升模型的特征提取能力。
2 模型應用
2.1 數據集 本研究的實驗數據來源于南京中醫藥大學醫學信息實驗室中醫圖像數據庫,共檢索出2014-2016 年利用手機采集的257 名志愿者的舌圖,年齡25~86 歲,包括紅色、絳舌、胖大舌、瘦小舌等多種舌象,其中部分志愿者采集了其不同時間段的多張舌圖。排除未包括舌體區域的圖像后,共納入367 張舌圖構建舌象數據集,其中3 張典型舌圖見圖4。
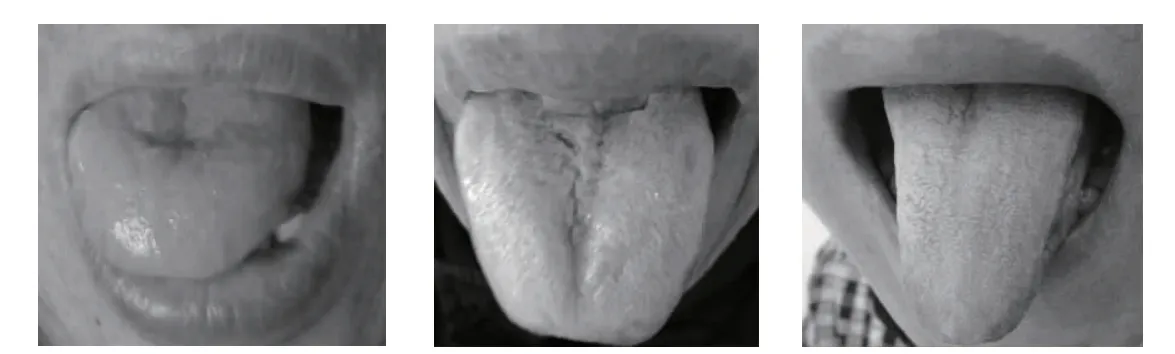
圖4 舌象數據示例
2.2 數據預處理 數據集中的體質類型包括:痰濕質89 例、濕熱質70 例、瘀血質42 例、氣虛質40例、陽虛質34 例、陰虛質32 例、氣郁質16 例及平和質3 例,其中氣郁質與平和質的樣本數較少,因此未納入此次的體質類別。由于原始圖像的大小不一,而全連接層需預定義權重矩陣的大小,因此,實驗預先對圖像的大小進行了統一,將其隨機裁剪至224 像素*224 像素*3 通道大小。
因數據集的樣本數有限,實驗在輸入前進行數據增強,從而更好地模擬舌象拍攝過程中不同的角度或光源亮度對拍攝造成的影響。采用調整亮度的數據增強方法將數據擴充至原來的3 倍。為了統一樣本集的數據分布,提升網絡泛化能力,實驗預先對輸入圖像進行歸一化,將所有樣本的像素值調整至[-1,+1]區間內,且在輸入網絡前將樣本隨機打散,避免訓練集中出現類別不均衡的現象。此外,額外加入有關舌象是否有齒痕、裂紋、芒刺的文本信息輔助訓練,其中“有”與“無”采用0 和1 來表示。
2.3 網絡參數設計 深度學習網絡的部分超參數設置如下:選擇Adam[14]作為優化器,交叉熵作為損失函數,學習率設置為1e-5,各卷積層的初始化權重采用截斷正則化方式得到。3 個不同的CBMA 模塊使用不同的dilation_rate,旨在獲得不同感受野范圍內,多尺度的特征注意力結果。
2.4 評價指標 采用經典的多分類評價指標[15]宏平均(Macro Average)和微平均(Micro Average)對模型整體進行評價,而針對其中的單個體質采用準確率(Precision,P)、召回率(Recall,R)和F1 進行評價。其中宏平均是針對每個類別的P、R 和F1 求得算數平均值,其計算公式如下:
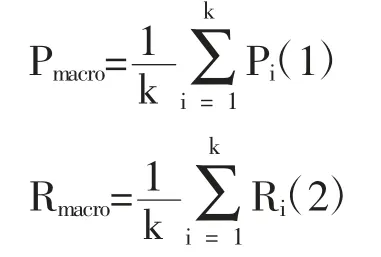
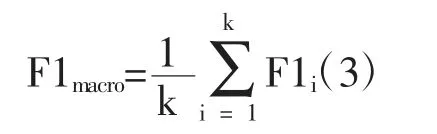
微平均的計算公式如下:
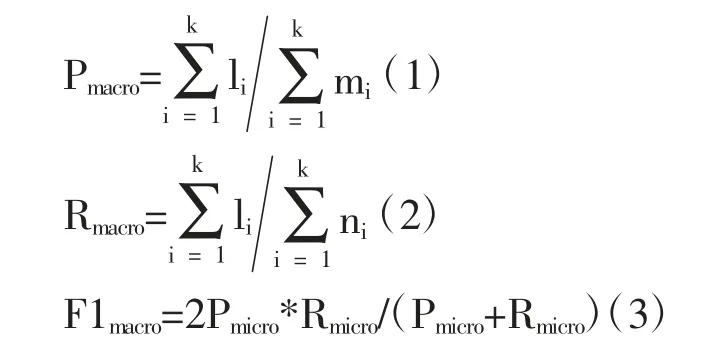
其中k 為類別數據,li 表示模型被預測為第i類且實際也屬于第i 類的樣本個數,mi 表示模型被預測為第i 類的樣本個數,ni 表示實際屬于第i 類的樣本個數。
2.5 模型訓練 采用十折交叉驗證法[16]訓練模型,設置隨機值為1,取十折交叉驗證結果作為最終體質分類結果,見表1。各體質類別的分類結果見表2。

表1 體質分類十折交叉驗證結果
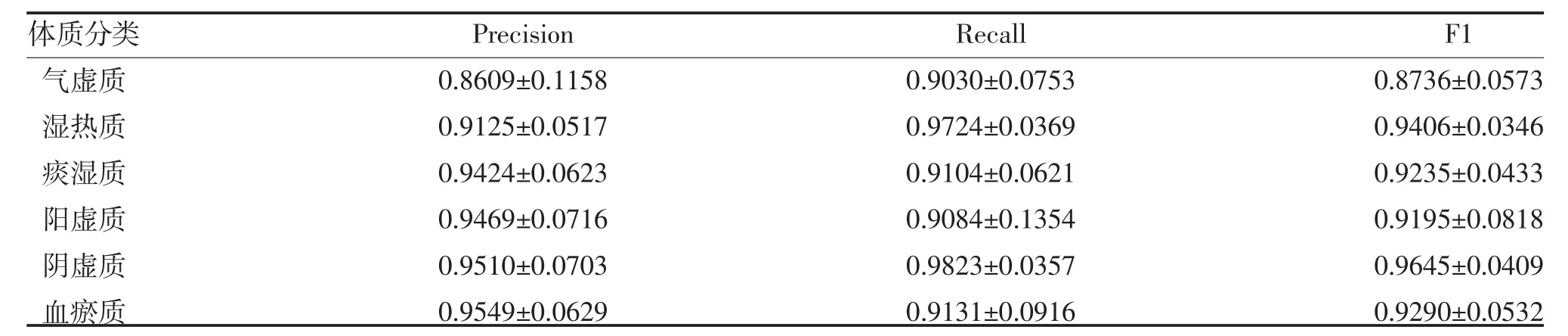
表2 體質分類結果
采用Class Activation Map 思想,對網絡最后一層卷積層的特征圖進行可視化,判定特征注意力的權重分配是否正確,直觀地觀察模型的學習結果。以濕熱質與陰虛質為例,可視化圖像中顏色較深的區域表示模型在學習過程中對該區域特征的關注度較高,見圖5、6。可知對于濕熱質而言,網絡在學習過程中更關注其舌苔,即舌苔特征對于濕熱質的分類更為重要;對于陰虛質而言,網絡在學習過程中更關注其舌質,即舌質特征對于最終陰虛質分類的貢獻程度更高,這與“舌苔反映邪實,舌質反映本虛”的中醫理論相吻合。
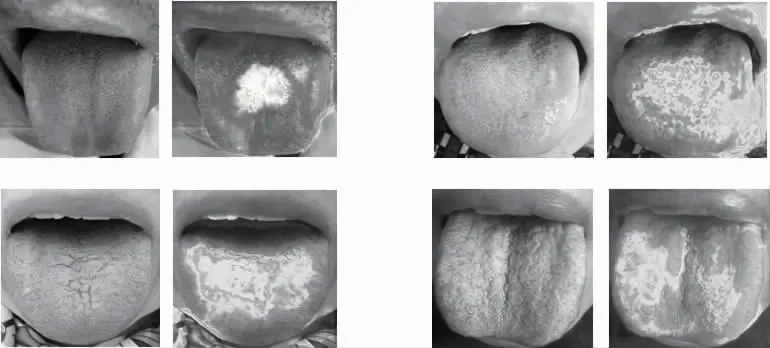
圖5 濕熱質特征圖可視化結果
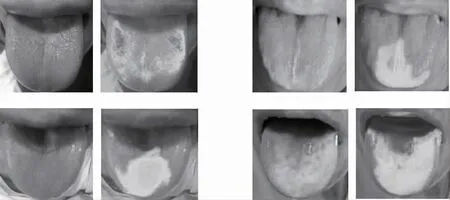
圖6 陰虛質特征圖可視化結果
3 總結
通過構建多尺度的注意力模型,將注意力模塊以殘差方式連接,實現多尺度、不同權重的特征學習,同時也適當引入相關文本信息,以圖像與文本特征相互結合的方式共同訓練模型,以此探尋舌象(外)與最終體質類別(內)之間的潛在關系,最終實現對6 種中醫體質(氣虛質、濕熱質、痰濕質、陽虛質、陰虛質和血瘀質)的分類。本研究算法針對各體質類別的分類精度較高,并且通過可視化的形式觀察特征圖,直觀地顯示了訓練過程中分配的特征注意力權重,發現其與中醫理論相吻合。中醫舌診是中醫特診診法之一,在健康評估和臨床診療中發揮了重要作用,通過計算機視覺相關技術,構建舌圖到中醫體質的有效映射,可以為中醫望診和體質辨識的智能化發展提供參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
