基于語音識別技術的智能配電網調度控制系統
2022-10-31 06:28:50廣西電網電力調度控制中心周智成潘連榮謝代鈺劉津銘
電力設備管理 2022年17期
廣西電網電力調度控制中心 唐 佳 周智成 潘連榮 謝代鈺 劉津銘
伴隨著我國以特高壓電網為核心的大規模電網的開發,配電網的運行方式產生了重大變化,其調度方式也越來越多樣化。而網絡信息時代的到來,也使得智能配電網的調度系統得到了穩定開發,配電網的大規模開發以及安全性運行均受到極大影響,而發展智能配電網的前提,是實現配電網設計調度系統的平穩運轉、實現國民用電的用電安全。配電網設計的調度系統是一種綜合性較強的管理技術,涵蓋了計算機技術和通信的諸多方面。
文獻[1]中提出了一種配電網調度方法,考慮配電網運行中的負荷波動率對配電網源荷進行優化,在主體博弈的基礎上運行配電網會有極佳的調度效果;文獻[2]中提出了對智能電網調度控制系統進行第二次防失誤的操作,提升配電網的狀態感知與管控風險能力,可更安全的控制配電網。本文在傳統方法的基礎上,做了更深層次的探索,為我國智能配電網的發展做參考。
1 系統硬件設計
本文設計的智能配電網調度控制系統硬件模塊的總體結構,主要由各類服務器、存儲裝置、網絡裝置和語音識別裝置組成。
1.1 語音識別裝置
此系統中的語音識別模塊硬件[3]的總體結構主要由語音識別芯片、主控單片機、寄存器和USB 轉串口組成(圖1)。語音識別模塊中核心的語音識別芯片采用WT588D 芯片,此芯片的識別技術是根據固定詞匯的方法進行識別的,使用前,用戶將需識別內容的拼音字符按順序寫入主板上的ROM 芯片中,當語音識別系統進行工作時,主控單片機會將這些內容一一寫入寄存器內,每次的語音內容經過語音識別芯片地辨別與管理后,再與提前輸入好的固定詞匯進行配對,重合率最高的被認為是識別結果,然后反饋給主控芯片,由主控芯片將結果通過USB 轉串口反饋給上位機。
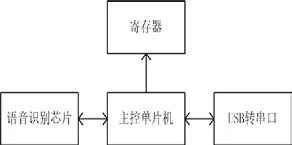
圖1 語音識別硬件簡單結構圖
WT588D 芯片具有識別率的準確度高、脫機識別、非特定語音識別、可播放語音等特點。其非特定語音識別的中文語音模型,是在語言建模的基礎上經大量中文語音數據的解析后建立起來的,算法工程師進行了無數次地抽樣,根據式樣語音的特點和差別,選擇了其中表現最佳的語音識別基元的特點,創建了最優中文語音模型并應用到芯片上。
1.2 防竊電裝置
系統中關鍵的防竊電模塊選擇了ATT7026EU微控器,其內部集成了6路16位的A/D 轉換裝置,用數字接口控制配電網運行時產生的數字信號,再通過SPI 接口實現與調度控制系統之間的交互,其SPI 接口負責傳遞芯片與外部微控制單元間以串行方式產生的參數。本次設計使用的微控器非線性測量誤差小于0.1%,使配電網地調度控制更精準。在ATT7026EU 芯片中,支持3.3V±10%電壓供電,芯片引腳提供模擬和數字電路的電源,電網信號經過插針網格陣列封裝進行減一操作,最后輸入EMU仿真器中,得到的電力數據會存儲到寄存器中。本次設計的微控器ATT7026EU 中,為保持配電網調度控制系統穩定運行,設置了電源管理單元,芯片會在電壓過低時進行復位操作。
2 系統軟件設計
2.1 語音信號分析和預處理
語音識別模型[4]主要包括信號的預處理、信號的特征處理、模式匹配并分析三方面。信號預處理主要包括采集語音樣本、對于語音樣本進行歸一化處理、預加重和加窗分幀等。利用語音信號頻率的標準范圍(300Hz~3.4kHz)來選取一個抗混疊濾波器對信號進行預濾波處理,控制輸入信號的頻率低于采樣信號頻率,防止工頻電源(50Hz)的混疊干擾,這樣就能獲取大量離散的時間語音信號。而奈奎斯特采樣定理則表明,要保持所采樣語音的完整性,采樣頻段必須要超過最大頻段的二倍,且通常都會選取在5~10倍之間。信號進行模數轉換就會涉及到信息量化的運算,為方便實踐采用1/2/3字節進行量化。本文設計中的信號量化處理使用2/3字節。
信號的分析有時域和頻域兩個方向。時域分析通過傅里葉變換獲得短時能量和過零率等數據,有高準確率、低計算率等優點。假如Y(a)代表時域分析信息,Yb(a)代表經過加窗分幀后的第b 幀的時間信息,Hb代表第b 幀時信號Yb(a)的短時能量信息,那么有如下公式:

公式(1)中,b=0,1n,2n,3n,…,;m 代表幀長;n 代表幀移長度。式(2)中,Hb一般代表某一幀信號的能量數據,進行語音識別的端點檢測。短時過零率代表了某幀信號波的圖像經過水平軸的次數,則:

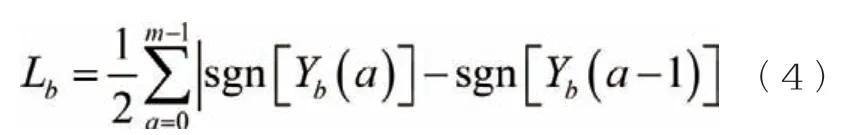
式(3)中sgn[x]代表符號函數,式(4)中Lb代表信號Yb(a)的短時過零率。信號分析最佳辦法就是短時過零率,用其判斷語音內容的清濁音最為有效。
2.2 設計數據解析模塊
本文設計的配電網調度控制系統的核心是對電源、配電網、儲能以及負荷的優化調度控制。系統中的用戶信息采集模塊基于DS 平臺提供的電壓與電流變化量對比值,對電流和電壓互感器的參數進行二次測量。具體過程如下:Ib=Ic×Hl;Vb=Vc×Hy;Pb=Pc×Hl×Hy;Qb=Qc×Hl×Hy。式中:Ib代表經過配電變壓器后的電流數據;Vb代表經過配電變壓器后的電壓數據;Pb代表經過配電變壓器后的有功功率數據;Qb代表經過配電變壓器后的無功功率數據;Ic代表系統測量的用戶端電流數據;Vc代表系統測量的用戶端電壓數據;Pc代表系統測量的用戶端有功功率數據;Qc代表系統測量的用戶端無功功率數據;Hl代表電流互感器的變化數據;Hy代表電壓互感器的變化數據。
用戶信息采集模塊每15分鐘就會顯示一次配電變壓器測量的數據,將此數據與配電網調度控制系統中的變壓器編碼對比,一致的數據將會被接入城市配電網調度控制系統,與此同時,城市配電網的調度管理系統也會進行調閱、查看歷史相關數據,通過監控可獲得每日的最高電壓、最低電壓、最大電流時刻、最小電流時刻。
3 仿真實驗
3.1 語音識別模塊測試結果及分析
本文設計所使用的命令短語內容以智能配電網中常用的調度控制命令為主,短語長度為5~9個字符不等,錄音人員方面選取了6名不同性別的學生,年齡在18~25歲之間,音頻均為普通話并在安靜的環境內錄制。實驗首先進行語音文件的錄制,通過剪輯處理得到所需的語音信號并進行預處理。通過基于MATLAB 的端點檢測技術,獲取這些語音信號的開始與結束的節點,再利用梅爾頻率倒譜系數提取語音信號,最后根據DTM 算法識別語音信號,與模板對比相似度高的即為識別結果。
本次6人錄制的語音文件分別當作訓練和測試樣本的正確數、錯誤數、正確率分別為:音頻一17/3/85%、音頻二16/4/80%、音頻三18/2/90%、音頻四18/2/90%、音頻五20/0/100%、音頻六19/1/95%。可看出,本文所設計的語音識別模塊,其語音識別的正確率達到了80%以上,識別效果較好,所以此模塊可在本文提出的配電網調度控制系統中穩定地工作。
3.2 調度控制系統運行測試及結果分析
本文設計的智能配電網調度控制系統中的大多數負荷由高壓配電網供應,只有少數的負荷由微電網群供應,這就導致了智能配電網調度控制系統非常依賴于高壓配電網,但是高壓配電網存在線路損耗,負荷總功率須小于發電總功率,所以判斷配電網調度控制系統能否運行的核心標準就是線路損耗。本次實驗中,通過雙層優化調度模型計算出普通智能配電網調度控制系統的相關調度數據,然后再次計算出本文所提的基于語音識別技術系統的相關調度數據,對比兩系統的線路損耗參數來驗證本文系統是否可行。
由圖2可知,加入語音識別模塊的調度控制系統線路損耗平均值為144kWh,相比于普通調度控制系統的損耗平均值162kWh 降低了11.1%,本文所提系統更能安全穩定地運行且其供電質量更高,所以本文設計的基于語音識別技術的智能配電網調度控制系統是可行的。
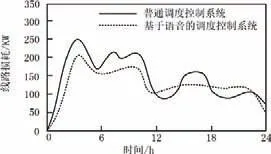
圖2 兩個系統的線路損耗對比
4 結語
智能配電網調度控制系統達成了對資源的合理分配與高效利用的目的,而本文所提的基于語音識別技術的智能配電網調度控制提高了原系統的可靠性、靈活性、安全性與實用性,使配電網的調度控制系統趨于完整。但與此同時也帶來了一些問題,如系統開銷、狀態同步、資源管理器的定位與計算等,所以今后還需繼續智能微電網地深入研究,切實地提高計算性能與降低成本等。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
文苑(2018年23期)2018-12-14 01:06:06
經濟技術協作信息(2018年32期)2018-11-30 01:43:16
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
電子制作(2018年11期)2018-08-04 03:25:42
電測與儀表(2016年5期)2016-04-22 01:14:14
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
