優化預訓練模型的小語料中文文本分類方法
2022-10-24 09:28:06陳藍楊帆曾楨
現代計算機 2022年16期
陳藍,楊帆,曾楨
(貴州財經大學信息學院,貴陽 550000)
0 引言
數字信息資源是指所有以數字形式將文字、數值等多種信息存儲在計算機中,通過網絡通信、計算機或終端再現出來的資源。近年來,數字信息資源的快速增長,為用戶帶來便利的同時也導致了“信息爆炸”。數字信息資源的重要組成部分之一就是文本,針對種類繁多的文本信息資源,運用現代化的管理手段和管理方法,將資源按照一定的方式組織和存儲起來,能夠使用戶在查找海量信息時實現高效檢索。
目前,將文本信息轉換為計算機能夠識別的數據是自然語言處理的一個重要問題。其中最普及的解決方法是將文本轉換為向量的形式,將一句文本語言轉化為一個向量矩陣,通過相似詞具有相近的向量,對詞義進行表示。目前,由于深度學習的發展及應用,學者們通過各種神經網絡對生成的多個維度的詞向量進行特征提取,降低損失函數值從而對詞向量進行優化,增強向量對詞義的表達能力。
在現實需求以及自然語言處理技術的基礎上,本文提出了一種中文文本字向量的表示模型,使用GloVe模型和BERT模型生成的字向量進行融合后,通過文本特征提取得到對應的字粒度向量。
1 研究現狀
在中文自然語言處理領域,計算機無法對非結構化的文本數據進行處理,因此在對中文文本信息進行處理時,需要經過分詞以及向量化的過程,也就是將文本信息轉化為計算機能夠識別的數值數據。其中在文本向量化方面,最早的文本轉換方式為one-hot(獨熱)編碼形式,one-hot編碼雖然解決了分類器處理離散數據困難的問題,但是沒有考慮詞與詞之間的相互關系,并且由one-hot生成的特征矩陣較為稀疏,增加了機器運算的負擔。在2014年前后,主要有兩種文本向量化方法,一種是矩陣分類算法,另一種是基于淺窗口的方法。基于淺窗口方法的代表模型就是Word2Vec,為了獲得更多的語義信息,Mikolov等提出了基于深度表示的模型—Word2Vec,該模型為輸入文本搭建一個具備上下文信息的神經網絡,從而計算得到含有上下文信息的詞向量,該向量也在一定程度上反映了詞與詞之間的相關性。雖然Word2Vec可以利用上下文信息預測詞向量使得生成的詞向量包含了語義信息,但由于其構建過程是單向學習,沒有充分利用所有語料。而基于矩陣分解算法通過文本共現矩陣表達文本詞向量,通過奇異值分解(singular value decomposion,SVD)對共現矩陣進行降維,章秀華等提出一種奇異值分解域差異性度量的低景深圖像目標提取方法,其能夠完整提取目標,但SVD的計算代價過大,并且難以將新的詞匯或者文本合并進去。2014年Stanford NLP Group結合Word2Vec以及SVD的優點提出了GloVe(global vectors for word representation)模型,該模型基于全局詞頻統計將一個詞語表達為一個向量,通過單詞之間的相似性、類比性等,計算出兩個詞語之間的語義相似性。方炯焜等結合GloVe詞向量與GRU模型提高了文本分類性能。石雋鋒等通過并行實現統計共現矩陣和訓練學習,從而在中文和英文的詞語推斷任務上,顯著地提高了預測的準確率。FANG等以GloVe為基礎建立情感分析系統,雖然GloVe能夠最大限度地利用全局和局部信息進行語料庫訓練,但無法應對一詞多義或者新詞組合的情況。針對該問題,2019年Devlin等引入動態詞向量BERT(bidirectional encoder representations from transformers)模 型,BERT模 型 利 用Transformer結構的encoder部分對文本進行雙向學習和處理,主要包含MLM(masked language model)任務 和NSP(next sentence prediction)任務。其中,核心任務是MLM任務,通過對目標單詞進行掩碼來預測詞語的向量,利用自注意力機制學習詞與詞間關系,使得詞向量的表示能夠融入句子級的語義信息。段丹丹等使用BERT預訓練語言模型對短文本進行句子層面的特征向量表示,并將獲得的特征向量輸入Softmax回歸模型進行訓練與分類,實驗證明BERT有效地表示句子層面的語義信息,具有更好的中文短文本分類效果。Chao等結合動態掩碼與靜態掩碼,提出新的MLM任務與層間共享注意力機制,有效地提高了BERT在實體關系提取上的性能。Danilov等提出了一種基于雙向編碼轉換(BERT)和圖卷積網絡的門上下文感知文本分類模型(GC-GCN),通過使用帶有門控機制的GCN將圖嵌入和BERT嵌入集成在一起,以實現上下文編碼的獲取。雖然BERT解決了詞向量無法表示一詞多義的問題,但通過BERT進行向量化的過程中,缺乏了整體的詞和詞之間的關系。綜上所述,現在國內外學者在文本向量化領域做了一些相關工作,但目前的文本向量化在中文文本語料的處理上仍然存在表義不足,因此,中文文本向量化具有研究潛力與價值。
本文在上述研究的基礎上提出了基于GloVe與BERT字向量模型的融合字向量模型。通過GloVe領域預訓練產生的文本向量無法解決一字多義的情況,但是能夠最大限度地利用全局和局部信息進行語料庫訓練,從而給每一個字都提供一個相對穩定的字向量,在投入的數據量較小的情況下,通過BERT領域預訓練難以達到訓練效果,更多的是依賴初始權重集的選擇。因此,GloVe與BERT在訓練時各有優劣,本文通過擴充GloVe字向量產生的維度,與BERT字向量進行向量融合,從而在預訓練生成的融合字向量中,既體現了GloVe字向量的全局穩定性,也通過BERT字向量的展現解決了一字多義的問題。
本文采用今日頭條發布的中文新聞數據,該數據屬于短文本類型,且包含大量同義或異義字詞。新聞文本數據通過GloVe及BERT模型生成的融合字向量矩陣,該矩陣通過卷積神經網絡實現文本特征的提取后進行字向量訓練優化,通過全連接層對新聞數據的分類結果的準確率、召回率等一系列指標進行評判,對文本詞向量的詞義表示能力進行評價。
2 思路與框架
2.1 融合向量模型
融合字向量模型基于GloVe字向量模型以及BERT字向量模型,主要分為四個部分:輸入處理層、融合層、特征提取層以及分類輸出層,其具體結構如圖1所示。
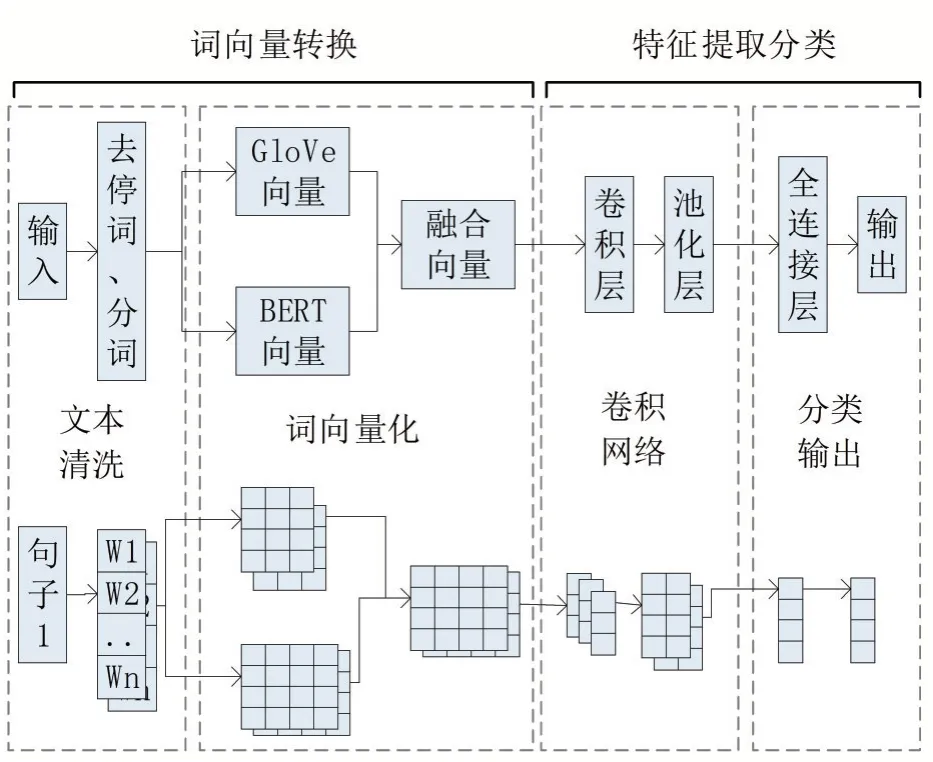
圖1 融合字向量模型結構
在該融合字向量模型中,以今日頭條發布的條新聞數據作為輸入,選取數據中的文本數據以及標簽數據,提取文本數據中的中文字詞后,為了使GloVe與BERT的分詞結果相同以達到詞向量矩陣的數據量相同,從而進行BERT_tokenize單字分字處理,得到字粒度的中文文本語料庫。
將該語料庫輸入GloVe字向量模型中,本文以300維的中文GloVe模型作為預訓練模型獲取字向量,在該字向量的表示中,GloVe模型通過語料的全局信息進行訓練后,相同字有相同的字向量,因此不能表達一詞多義。同時,將處理好的語料庫輸入BERT模型,生成768維的文本字向量,將GloVe向量與BERT向量通過點加的方式獲得融合字向量。
融合字向量通過文本卷積神經網絡獲取多層級的語義特征信息,通過訓練發現該字向量的關鍵信息,從而對768維的向量進行特征抽取,實現詞向量降維。
在進行特征提取后,經過全連接層對文本數據進行分類處理。
2.2 輸入處理層
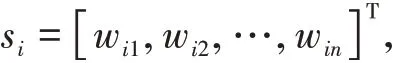
在GloVe詞向量模型中,將×個字中第一次出現的字挑選出來,若共有個不重復字,這個字組成共現矩陣的坐標標簽,那么共現詞頻矩陣可表示為式(1):
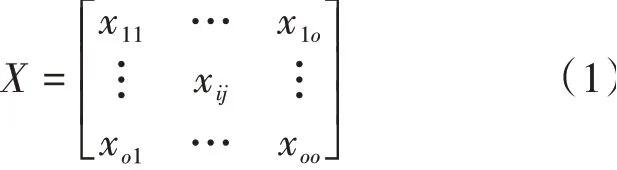
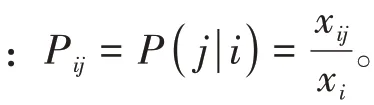
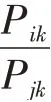
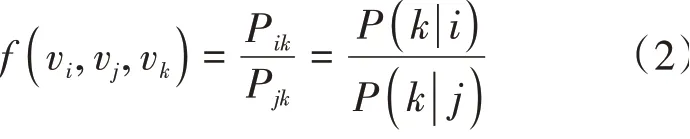
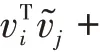
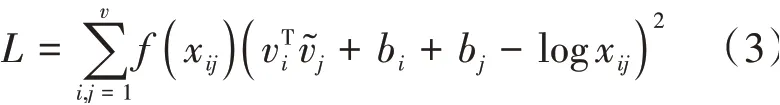
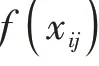
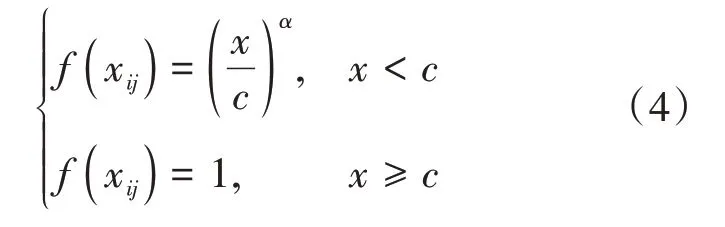
最后,通過AdaGrad的梯度下降算法對該函數進行訓練,從而獲取較優的詞向量。GloVe詞向量模型訓練過程如圖2所示。
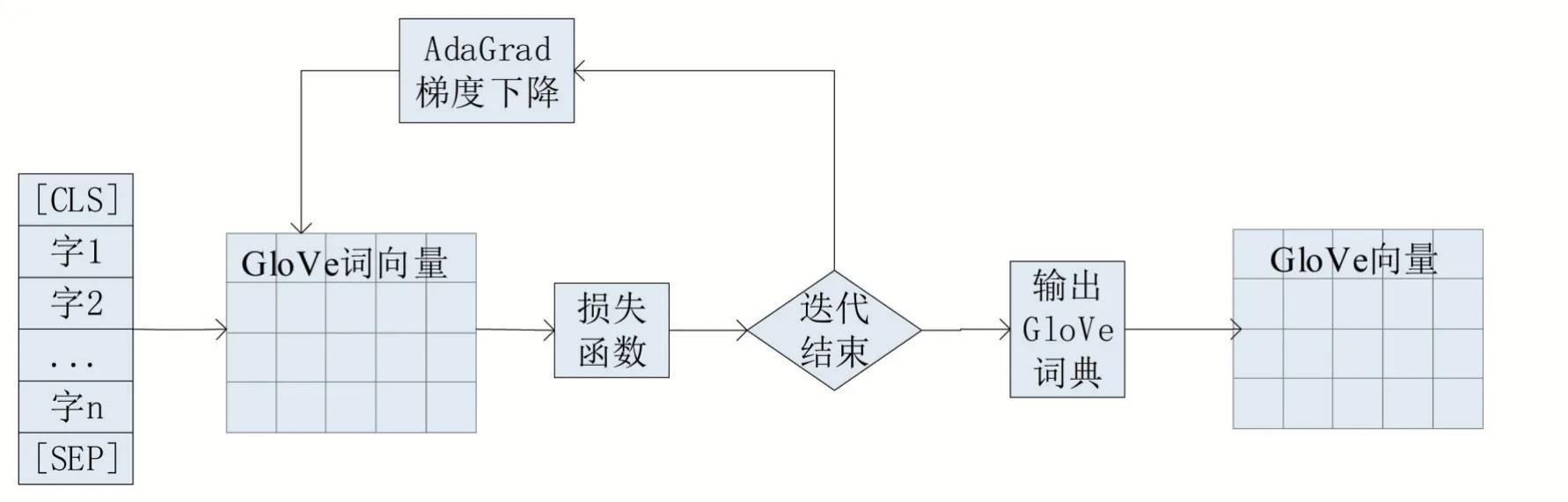
圖2 GloVe詞向量模型結構
BERT以Transformer的encoder結構為基礎,主要包含MLM掩碼任務和NSP語句預測任務,BERT在輸入嵌入層(input embedding)通過查詢詞典中每個詞語對應的向量表得到句子的向量矩陣,與GloVe不同的是,BERT在輸入嵌入層的基礎上增加了體現詞語在句子中所在位置的位置嵌入層,具體計算方式見式(5):
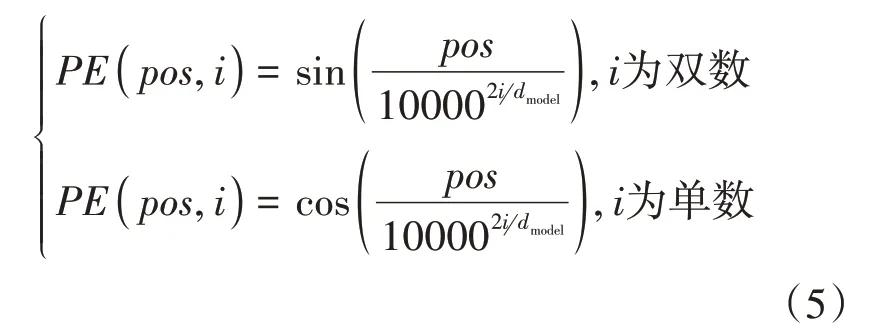
其中,為該詞在句子中的位置,根據出現位置的單數或雙數,以sin或cos方式生成的位置值交替出現,為模型需要訓練的參數。BERT在位置嵌入層的基礎上增添了體現句子在文本語料的位置關系的句子嵌入層,根據句子出現的位置,表示為[,,…,,,,…,,…]的形式,E表示第個句子的第個詞,且E=E=…=E,用以區分該句中的詞語與其它句子中的詞語。這三個嵌入層共同組成encoder結構的輸入層。
三個矩陣、、與相乘得到q,k,v,∈( 1,2,…,),將q與k做 點 積 得 到α,α通過全連接層后得到0~1之間的','與對應位置的v相乘且求和得到輸出b,這就是多頭注意力機制,具體過程如圖3所示。
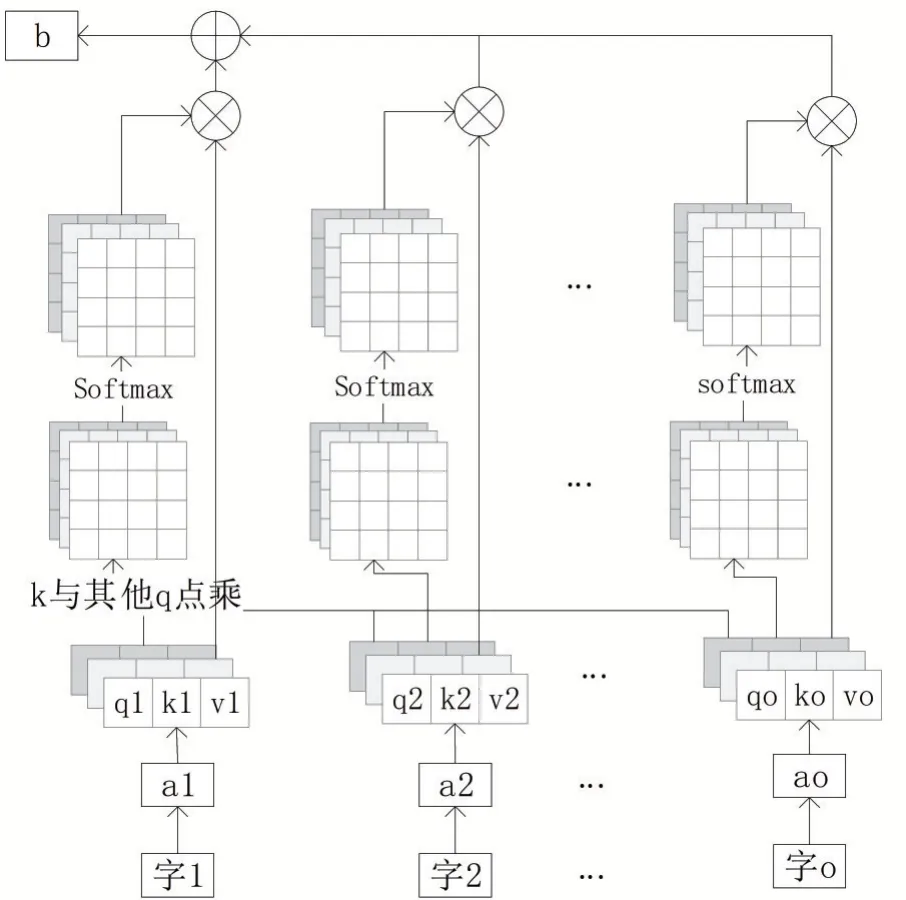
圖3 多頭注意力機制
多頭注意力機制生成的b通過前饋神經網絡的訓練生成BERT詞向量,BERT詞向量模型結構如圖4所示。
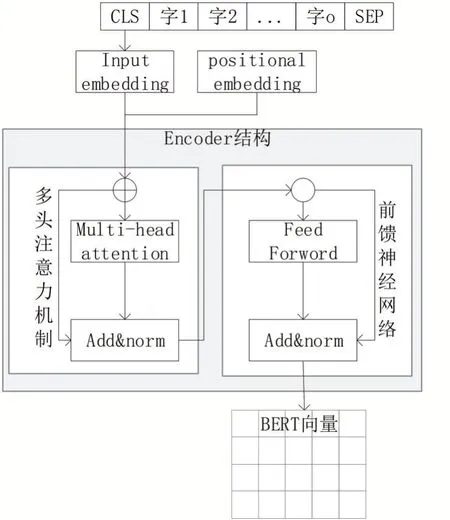
圖4 BERT詞向量模型結構
2.3 融合層
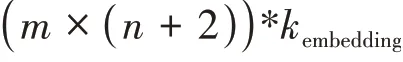
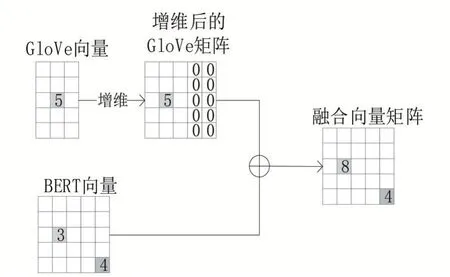
圖5 融合字向量
2.4 特征提取層
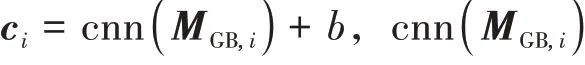
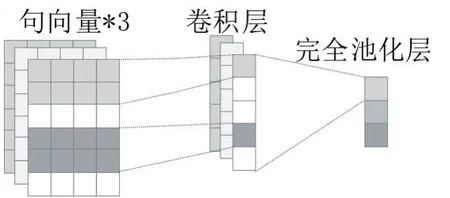
圖6 文本卷積神經網絡結構
2.5 分類輸出層
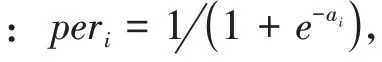
3 實證研究
3.1 實驗數據
本實驗以今日頭條發布的開源新聞數據集作為輸入數據,原數據集包含15類共382669條數據,每條數據包含文本id名、文本類別數值代號、文本類別名、文本內容、關鍵詞五列。從15類新聞中抽取“文化”和“娛樂”兩個板塊的新聞,其中文化新聞共28030條,娛樂新聞共39396條,滿足實驗所需。從這兩個類別的數據中抽取文本類別數值代號和文本內容兩列內容后,分別抽取250條、500條、2500條、5000條,組成共有500條數據、1000條數據、5000條數據、10000條數據的4個不同大小的文本語料庫。
將文本內容進行文本正則化處理,僅保存文本中的中文字,并且按照字粒度對文本進行分詞后,將其按照類別標簽存儲在各自類別的文件夾里,每一條文本存儲在以索引編號命名的文件里。將文本數據進行打亂順序處理,選取其中20%的數據作為評估集,80%的數據作為訓練集,并且評估集與訓練集相互獨立。由于單次劃分得出的結果并不穩定,因此每個輸入數據集進行20次實驗,選取20次實驗中效果最好的5次實驗結果的平均值做為最終的實驗結果。
3.2 評價指標
本文實驗的評估指標有:評估集的準確率、評估集的查全率、評估集的查準率,評估集的值四個。
將“文化”類的數據設為負類,“娛樂”類的文本數據設為正類,得到的預測類別與實際類別的情況見表1。
(3)梁彎曲撓度分布在裂紋處存在尖點,且對于開裂紋,當載荷較小時,撓度在裂縫處的尖點現象并不明顯,但隨著載荷的增加,尖點現象愈加明顯.同時,梁橫截面轉角在裂紋處發生突變,轉角不連續.
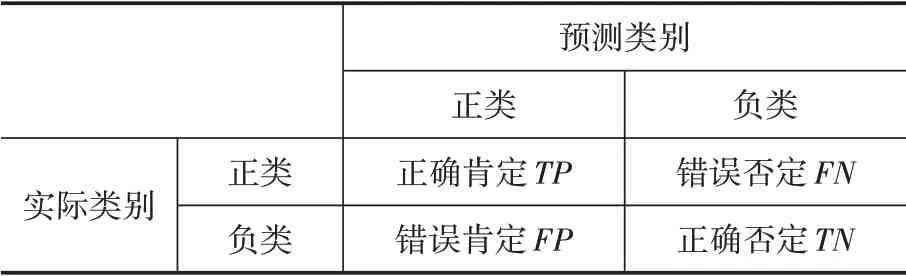
表1 二分類混淆矩陣
將預測為正類且實際類別也為正類的結果記為,預測為負類但實際類別為正類的結果記為,將預測為正類但實際類別為負類的結果記為,預測為負類且實際類別也為負類的結果記為,那么有:

其中展示了分類正確的數據條數與數據總數的比值,可以在總體上衡量一個預測的性能;表示被正確分類的正類數據條數與所有應該被判斷為正類的數據條數之間的比值,展示正類樣本被誤判的程度;展示了被正確分類的正類數據條數與所有被判斷為正類的數據條數之間的比值,找到所有的正類防止漏掉正類樣本。將和視為相同重要的兩個評估標準,對模型的性能進行了一個綜合評價。
3.3 參數設置
GloVe詞向量基于全局詞頻統計把單詞表現為一個300維的向量形式,詞典大小為352221;BERT預訓練模型采用bert-basechinese模型,包含12個encoder單元,768個 隱藏單元數,12個注意力機制的頭數,110M參數,詞典大小為21128,生成768維的詞向量。在文本卷積神經網絡中,選取兩層卷積神經,為了查看兩個字組成的詞語之間的關系,將第一層卷積核的大小設為2;為了查看主謂賓之間的關系,將第二個卷積核的大小設為三;由于是二分類,在全連接層采用sigmoid激活函數,將數據特征分為正負兩類。具體參數見表2。
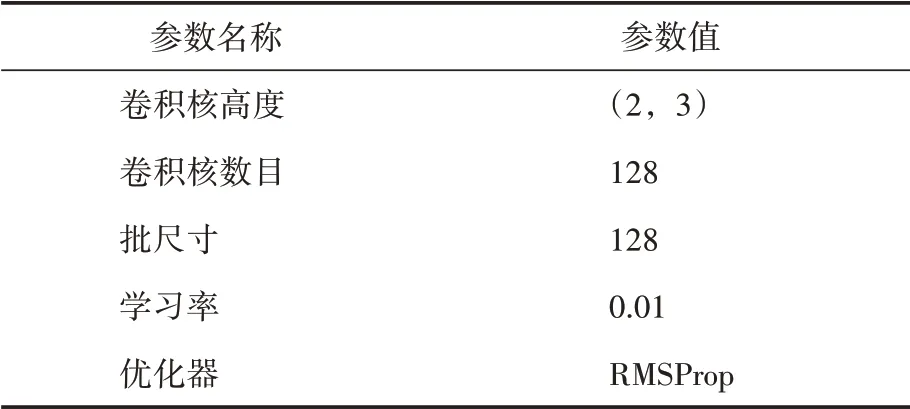
表2 卷積層參數設置
4 結果與分析
為了驗證該融合向量算法的有效性,將今日頭條的4種不同大小的數據集在GloVe預訓練算法、BERT預訓練模型以及融合詞向量預訓練模型中進行訓練,得到的準確率見表3。
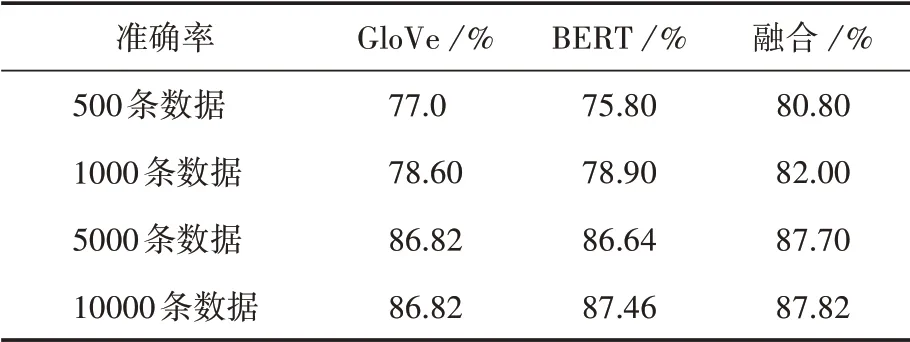
表3 準確率
各個模型在不同數據集上的召回率見表4。
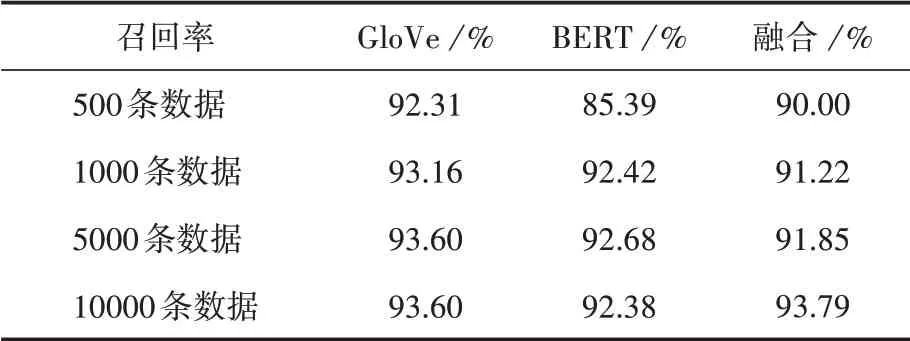
表4 召回率
模型在不同數據集上的查全率如圖7所示。
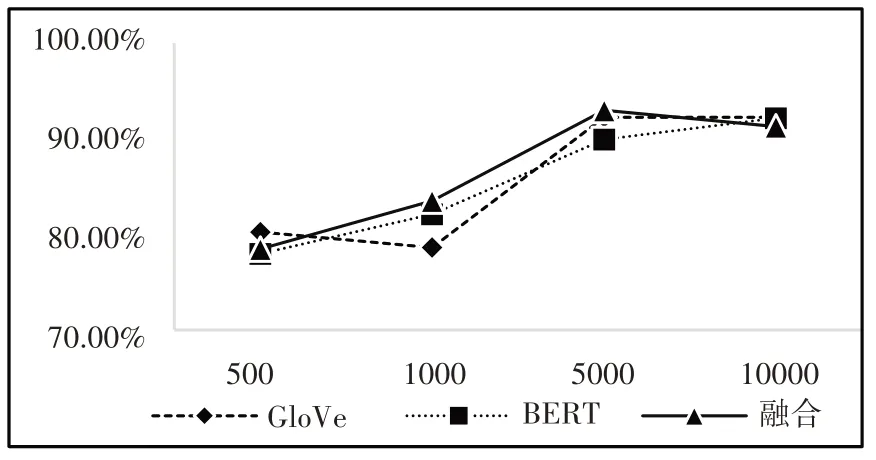
圖7 查全率
模型在不同數據集上的值如圖8所示。
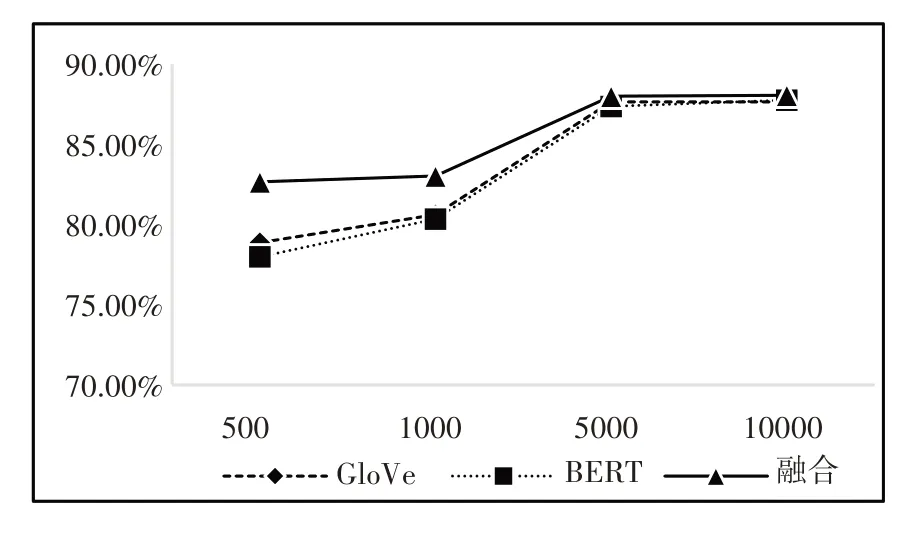
圖8 F1值
由實驗得出如下結論:
(2)通過表4中召回率的展示可以發現,GloVe模型的表現不比BERT模型表現差。在表2中,輸入數據為500條時,GloVe模型產生的詞向量最終訓練后的準確率為77.00%,而BERT預訓練模型產生的詞向量訓練后的準確率為75.80%,這是由于小數據量時的同詞異義的情況出現的概率較小,采用詞頻統計的方法構建字典從而生成詞向量,相比使用數據進行迭代優化出來的詞向量,在數據量較小時能夠更加準確地表達詞義。
(3)在圖8中,融合向量模型的值總是略高于單一模型的值,并且數據量越小,融合向量模型的優勢越明顯。圖7顯示,相較于單一模型產生的詞向量,融合向量模型的查全率在1000條以及5000條數據組成的語料庫中都高于單一模型的訓練效果。在表3中,融合向量準確率在數據量較小時有小幅度的提升,當數據量為500時,融合詞向量相較于BERT詞向量提升了5個百分點,相較于GloVe詞向量提升了3個百分點;當數據量為1000時,融合詞向量相較于BERT詞向量的精確率提升了3.1個百分點,相較于GloVe詞向量提升了3.4個百分點。
(4)上述圖表顯示,當輸入的數據量較大時,各個模型訓練出來的詞向量的最終準確率都在86%~88%之間,準確率相差一個百分點以內,并沒有顯著的區別。這是由于輸入模型的數據量足夠讓BERT訓練出一個較好的結果,同時也反映了融合詞向量模型在大數據量時的訓練效果,雖然沒有明顯優于BERT詞向量模型,但也并不遜色于BERT詞向量模型。
從5000條輸入數據增加至10000條輸入數據時,GloVe模型與融合詞向量模型的準確率沒有明顯的變化,而BERT詞向量模型的準確率提升了0.82個百分點,但BERT模型依靠增加數據量來提升準確度的收效減小,代價過大。
5 結語
本文的研究價值主要體現在:通過對BERT與GloVe模型生成的詞向量進行融合,獲取兩種詞向量的語義信息,從而在小數據量的語料庫中,融合詞向量的語義信息表示能力有一定的增強,采用淺層文本卷積神經網絡對融合詞向量進行特征提取,使得該融合詞向量能夠準確表達詞義的同時,也降低了實驗中對硬件的要求,降低了模型的部署難度。
本文詳細闡述了融合詞向量的整體框架、模型結構,以及相關的計算公式,并用不同大小的數據集來驗證模型的有效性。實驗表明,相較于傳統的GloVe模型和單一的BERT預訓練模型,融合詞向量模型的準確率在較小數據量的情況下都能得到提升。這說明融合不同詞向量方法的文本表示能夠獲取字詞的先驗知識,同時根據數據特征進行優化,從而獲得詞向量更好的表示方法。
在未來的研究中,可以嘗試采用不同維度的文本信息,比如詞粒度文本信息,在詞向量融合時引入注意力機制,為BERT詞向量以及GloVe詞向量加一個權重之后進行詞向量融合,從而進一步提升文本的表達能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
現代出版(2020年3期)2020-06-20 07:10:34
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
