基于圖數(shù)據(jù)庫的閱讀行為知識圖譜構建研究
2022-10-24 09:32:14陳光儀陳義明吳小慧
現(xiàn)代計算機 2022年16期
陳光儀,陳義明,吳小慧
(湖南農業(yè)大學信息與智能科學技術學院,長沙 410128)
0 引言
語義網絡作為人工智能的重要應用領域之一,可以給用戶提供一個更加準確、更加智能的知識獲取環(huán)境。而知識圖譜是實現(xiàn)語義網絡的技術基礎,是通向語義網絡環(huán)境的鮮明道路。在智慧學習的大環(huán)境下,疊加近年來新冠疫情的防控需求,在線閱讀已越來越多地成為廣大讀者的首選閱讀方式。如果能夠有效獲取讀者的閱讀行為并構建對應的知識圖譜,對于圖書館而言,可以及時了解其在閱讀過程中的實際需求,繼而進行針對性的閱讀指導并為讀者推薦個性化的閱讀內容;對于出版商而言,可以及時調整、改進電子出版物的內容編排及后續(xù)再版工作,以更好地適應目標讀者群體的實際需求。因而,此項研究工作對于進一步提升讀者的閱讀學習效果,完善圖書館的智慧化閱讀服務,推動促進全社會形成良好的智慧學習環(huán)境大有裨益。
1 知識圖譜構建技術
構建知識圖譜有自頂向下和自底向上兩種方式。前者通常是指基于百科類網站等高質量的結構化數(shù)據(jù)源,從中提取本體和模式信息后再加入到知識庫中,因而適用于那些內容明確、關系清晰的領域知識圖譜構建;而后者是指通過借助特定的技術手段從公開采集的數(shù)據(jù)中提取模式信息,選擇其中置信度較高的新模式,經人工審核后再加入到知識庫中。目前大部分知識圖譜的構建都采用自底向上的方式,其層次架構按照知識獲取的過程可分為信息抽取、知識融合和知識加工。
信息抽取是指從多源異構的數(shù)據(jù)源中提取出實體、屬性以及實體之間的關系,在此基礎上形成本體化的知識表達,它是知識圖譜構建技術的關鍵。早期信息抽取主要是基于預定規(guī)則的抽取技術,工作量龐大且僅適用于特定的專業(yè)領域,后來人們開始嘗試使用統(tǒng)計機器學習的方法,通過標注部分數(shù)據(jù)得到訓練集,在此基礎上再使用均方根誤差算法(root mean squared error,RMSE)或多項式回歸算法(polynomial regression,PR)等有監(jiān)督學習算法識別命名實體。
從開放領域中抽取信息所得到的結果,可能具有較高的數(shù)據(jù)冗余度且包含大量錯誤內容,數(shù)據(jù)內在的層次性和邏輯性也缺失嚴重,這就需要通過有效的知識融合技術來清洗并整合數(shù)據(jù),主要工作包括實體對齊和知識合并等。
經過融合處理后,所得到的數(shù)據(jù)、信息或事實表達還必須經過進一步的知識加工才能形成最終結構化、網絡化的知識體系。此過程中涉及的主要技術包括本體構建、知識推理和質量評估。
上述層次架構可用圖1所示的模型來表示。
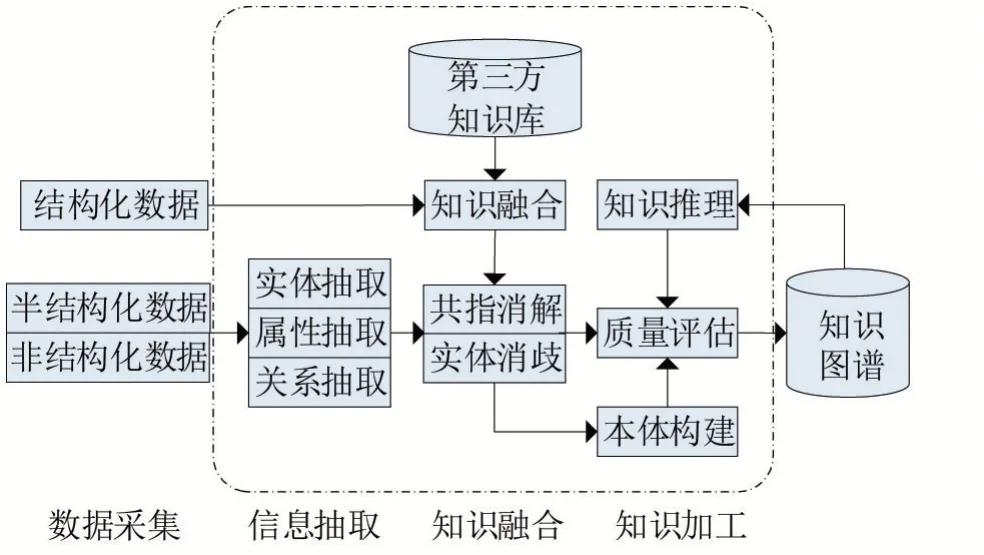
圖1 自底向上構建知識圖譜的層次架構
2 閱讀行為知識圖譜構建
就本文所研究的讀者閱讀行為知識圖譜構建而言,采用自底向上的方法更為合適。這種方法將知識圖譜的構建過程分為四步:知識獲取、知識表示、知識存儲和知識可視化錯誤!未找到引用源。。
結合項目的實際需求,本文設計出閱讀行為知識圖譜構建系統(tǒng)的實現(xiàn)流程如下:首先從存檔的電子出版物中抽取出讀者的閱讀行為數(shù)據(jù),然后對數(shù)據(jù)進行清洗并進行格式調整,再將數(shù)據(jù)加載到圖數(shù)據(jù)庫中,創(chuàng)建知識節(jié)點及節(jié)點之間的關系以得到完整的知識圖譜,最后使用圖數(shù)據(jù)庫操縱語言對知識進行查詢推理,并將結果可視化地呈現(xiàn)在頁面上。完整流程如圖2所示。
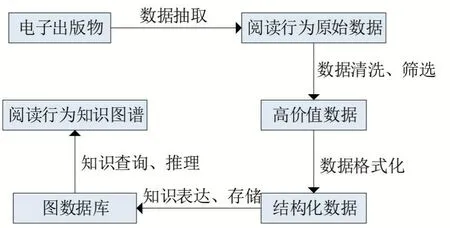
圖2 閱讀行為知識圖譜構建流程
2.1 知識獲取
構建知識圖譜的首要任務是獲取知識。從各種類型的數(shù)據(jù)源中提取出實體(概念)、屬性以及實體之間的相互關系,在此基礎上形成本體化的知識表達。
本文構建閱讀行為知識圖譜所需的數(shù)據(jù)主要來源于讀者在閱讀過程中所生成的各種標注和注釋信息,這是一種簡明且方便獲取的、用以了解讀者閱讀行為的數(shù)據(jù)。讀者在閱讀電子出版物的過程中,會隨手在文檔中添加一些附注、標記和注釋信息,這些信息真實準確地反映了讀者個人的閱讀習慣,及其對所閱讀內容的認識、理解和掌握程度。為保證數(shù)據(jù)來源的隨機性和真實性,本文收集整理了數(shù)十位學生讀者在閱讀不同類型電子出版物后所形成的文檔材料,編寫程序自動提取出其中所包含的讀者閱讀行為數(shù)據(jù)。部分原始數(shù)據(jù)如圖3所示。

圖3 閱讀行為原始數(shù)據(jù)局部
2.2 知識表示
自動提取的原始數(shù)據(jù)中往往會包含一些信息噪音。因而本文設計了專門的數(shù)據(jù)清
洗程序以去除其中的噪音,然后再將數(shù)據(jù)格式化為知識表示的形式。具體過程為:
(1)首次清洗。構造如下正則表達式,對抽取的數(shù)據(jù)進行完整清洗,去除價值密度低的數(shù)據(jù),保留重要的標記注釋文本、生成時間和創(chuàng)建位置等內容。
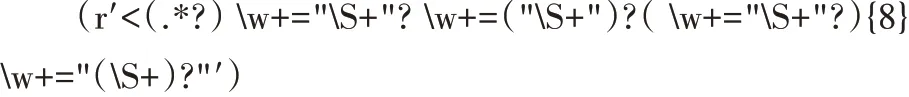
(2)再次清洗。將元組轉換為列表數(shù)據(jù),構造正則表達式,采用循環(huán)掃描的方式對數(shù)據(jù)進行再次清洗。其中的少部分數(shù)據(jù)可能發(fā)生錯置現(xiàn)象,需要抽取相應數(shù)據(jù)并重載至正確位置。
(3)格式化數(shù)據(jù)。構造正則表達式,整理清洗后的數(shù)據(jù),對它們進行適當?shù)那蟹趾秃喜ⅲ詈髮⑺袛?shù)據(jù)格式化為知識表示的形式。
2.3 知識存儲
關系型數(shù)據(jù)庫在結構化數(shù)據(jù)的存儲和處理方面擁有絕對優(yōu)勢,但對知識存儲及語義檢索的支持卻不夠友好。而以圖論為基礎的圖數(shù)據(jù)庫在這些方面卻恰好擁有與生俱來的長處,尤其在保持數(shù)據(jù)語義及處理復雜關系等方面,圖數(shù)據(jù)庫明顯優(yōu)于關系型數(shù)據(jù)庫。目前在學術研究和商業(yè)領域,主要的圖數(shù)據(jù)庫產品包括ArangoDB、FlockDB和Neo4j等。根 據(jù)DBEngine排名,其中最為活躍的當屬開源產品Neo4j,它不僅支持嚴格的事務處理,還提供強大的圖搜索能力和極好的橫向擴展能力。
本文通過編寫程序,實現(xiàn)了將格式化后的讀者閱讀行為數(shù)據(jù)自動加載到Neo4j圖數(shù)據(jù)庫中的功能。程序能根據(jù)格式化數(shù)據(jù)的結構創(chuàng)建相應節(jié)點,添加屬性并標注關系,自動完成知識圖譜的存儲和構建。
2.4 知識可視化
Neo4j數(shù)據(jù)庫支持強大的圖操縱語言Cypher,可以快捷高效地實現(xiàn)知識圖譜的查詢和推理。在配置好所需模塊后,調用瀏覽器打開圖數(shù)據(jù)庫,輸入相應Cypher命令便能查詢所需內容并將結果可視化呈現(xiàn)在頁面上。本文所創(chuàng)建的讀者閱讀行為知識圖譜的部分查詢結果如圖4所示。
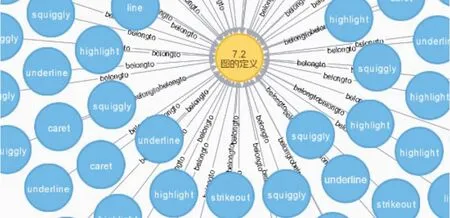
圖4 讀者閱讀行為知識圖譜局部
3 結語
本文介紹了讀者閱讀行為知識圖譜的完整構建過程,設計并實現(xiàn)了一個自動化的開放知識圖譜構建系統(tǒng)。測試結果表明:本文所得成果能正確高效地實現(xiàn)對讀者閱讀行為數(shù)據(jù)的自動提取、清洗、篩選和格式化,并能在此基礎上將融合后的數(shù)據(jù)表達為知識再存儲到圖數(shù)據(jù)庫中。后續(xù)研究工作重點在于:一方面對獲取的閱讀行為數(shù)據(jù)和讀者閱讀習慣、閱讀情感之間的關聯(lián)性進行深入研究;另一方面對如何將所構建的知識圖譜用于幫助圖書館提供更好的智慧閱讀服務進行分析。作者將從這兩個方面著手,扎實開展后期的理論研究和實踐創(chuàng)新工作,以期取得更有價值的成果,為推動全社會形成良好的智慧學習環(huán)境添磚加瓦。
猜你喜歡
世界科學技術-中醫(yī)藥現(xiàn)代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
開放教育研究(2020年2期)2020-03-31 01:54:14
傳媒評論(2019年4期)2019-07-13 05:49:14
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
