基于機器學(xué)習(xí)的零件加工質(zhì)量預(yù)測及優(yōu)化
2022-10-23 14:00:26蘇欣高曉旭賴復(fù)堯劉德坤
機械制造與自動化 2022年5期
蘇欣,高曉旭,賴復(fù)堯,劉德坤
(1. 西南電子技術(shù)研究所,四川 成都 610036; 2. 西安電子科技大學(xué),陜西 西安 710071)
0 引言
數(shù)控機床作為重要裝備,其加工過程穩(wěn)定性和質(zhì)量提升亟需應(yīng)用機器學(xué)習(xí)為核心的工業(yè)大數(shù)據(jù)技術(shù)支撐。加工工藝參數(shù)的選擇是數(shù)控加工中的重要組成部分。切削參數(shù)智能推薦是數(shù)控加工智能化的必要條件,更是保證產(chǎn)品質(zhì)量的關(guān)鍵[1-2]。目前,對于數(shù)控加工參數(shù)選擇方面主要依賴人工經(jīng)驗,雖然有相關(guān)數(shù)據(jù)的采集與存儲,但數(shù)據(jù)的價值沒有被充分挖掘。為了解決這些問題,迫切需要在數(shù)控加工過程中實現(xiàn)工藝參數(shù)的自動推薦和持續(xù)優(yōu)化。
本文以包含多個不同特征的機械零件為研究對象,提出了一種基于XGBoost結(jié)合遺傳算法的質(zhì)量目標(biāo)優(yōu)化模型,運用熱力圖分析和特征重要度分析方法對特征進行篩選,找出影響質(zhì)量的強相關(guān)特征。通過篩選出的特征進行基于XGBoost的回歸預(yù)測分析,并通過改進的遺傳算法進行質(zhì)量目標(biāo)優(yōu)化,最終獲得最優(yōu)的零件加工工藝參數(shù)。
1 基于XGBoost算法的薄壁零件質(zhì)量預(yù)測方法
本文提出基于XGBoost機器學(xué)習(xí)的質(zhì)量預(yù)測分析方法,具體實現(xiàn)步驟包括(圖 1):
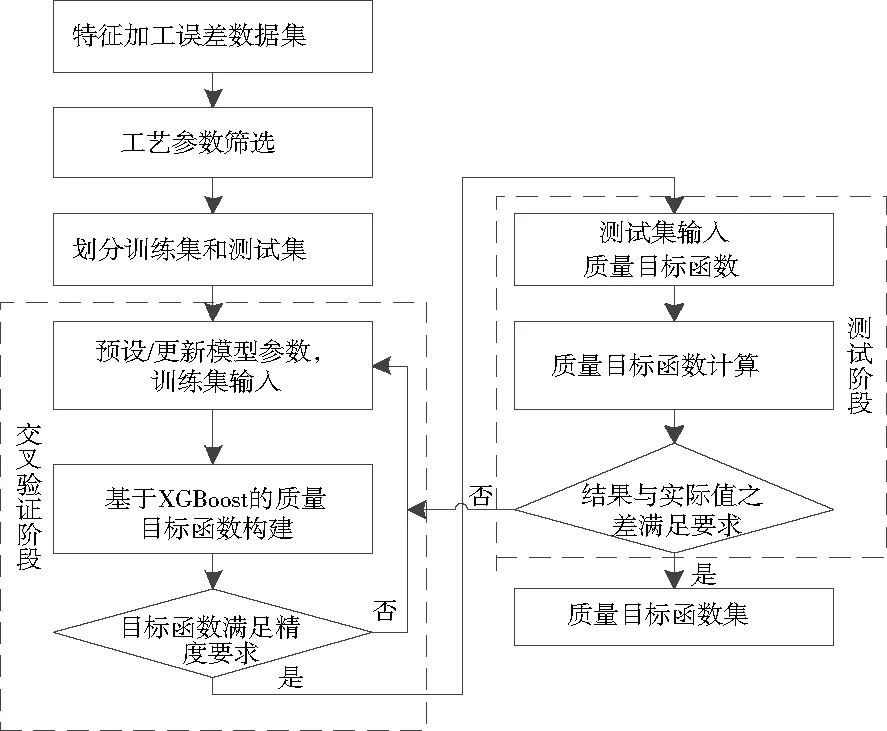
圖1 基于XGBoost機器學(xué)習(xí)的質(zhì)量預(yù)測分析流程圖
1)特征加工誤差數(shù)據(jù)集采集:數(shù)控加工過程中,使用采集信號設(shè)備采集數(shù)控機床上的加工工藝參數(shù)值以及相應(yīng)的各個特征的加工誤差;
2)特征參數(shù)篩選:通過熱力圖分析和特征重要度分析,發(fā)現(xiàn)各個特征之間的相關(guān)程度和重要度,獲取影響質(zhì)量的強相關(guān)特征參數(shù);
3)劃分?jǐn)?shù)據(jù)集:基于篩選的特征參數(shù),將數(shù)據(jù)集劃分為訓(xùn)練集和測試集;
4)交叉驗證階段:采用XGBoost模型進行建模,構(gòu)建質(zhì)量目標(biāo)函數(shù),以滿足精度要求;
5)測試階段:使用構(gòu)建的目標(biāo)函數(shù)對測試集進行預(yù)測,預(yù)測結(jié)果需滿足精度,否則重新進行模型訓(xùn)練,最終獲得對質(zhì)量/效率的精準(zhǔn)預(yù)測;
6)生成目標(biāo)函數(shù)集:質(zhì)量目標(biāo)函數(shù)集刻畫了工藝參數(shù)(轉(zhuǎn)速、切深和轉(zhuǎn)速等)與質(zhì)量之間的映射關(guān)系。
1.1 特征參數(shù)篩選
對數(shù)據(jù)集進行特征參數(shù)篩選可以減少特征數(shù)量、降維、減少過擬合;也可以增強對特征和特征值之間的理解[3]。本文采用皮爾森相關(guān)系數(shù)與基于學(xué)習(xí)模型的特征排序相結(jié)合的方式對特征進行篩選,既可以利用皮爾森相關(guān)系數(shù)對線性關(guān)系進行準(zhǔn)確分析,又可以結(jié)合基于學(xué)習(xí)模型對非線性關(guān)系建模較佳的優(yōu)勢對特征進行準(zhǔn)確地篩選。
1.2 目標(biāo)函數(shù)構(gòu)建
目前機器學(xué)習(xí)算法中關(guān)于回歸算法主要有邏輯回歸算法(Logistic)、基于核函數(shù)的支持向量機(SVM)以及基于決策樹的回歸算法(包括隨機森林回歸算法,GBDT回歸算法和XGBoost回歸算法等)。本文以工藝參數(shù)為自變量,質(zhì)量目標(biāo)(即不同特征的加工誤差) 為因變量,采用XGBoost[4-6]算法構(gòu)建質(zhì)量目標(biāo)函數(shù),作為目標(biāo)優(yōu)化的基礎(chǔ)。
XGBoost是一種提升樹模型,將許多樹模型集成在一起,形成一個很強的分類器,其優(yōu)化目標(biāo)函數(shù)為
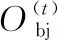
2 基于遺傳算法的目標(biāo)優(yōu)化方法
在傳統(tǒng)基于遺傳算法的神經(jīng)網(wǎng)絡(luò)或模糊神經(jīng)網(wǎng)絡(luò)[7]中,適應(yīng)度函數(shù)一般取目標(biāo)函數(shù)的倒數(shù),而目標(biāo)函數(shù)取網(wǎng)絡(luò)的全局誤差函數(shù),即
式中:q為輸入的樣本數(shù);g為相應(yīng)樣本輸出數(shù);ydl為實際輸出;Ydl為期望輸出。
為克服q、g對目標(biāo)函數(shù)的影響,對目標(biāo)函數(shù)進行如下改進:
調(diào)整后的新目標(biāo)函數(shù)既保留了前者的優(yōu)點,又避免了輸入輸出數(shù)對尋優(yōu)過程的影響,故選取新的適應(yīng)度函數(shù)為
本文基于線性求和方法建立零件級質(zhì)量目標(biāo)優(yōu)化函數(shù),采用改進后的遺傳算法進行優(yōu)化,優(yōu)化變量為轉(zhuǎn)速n(r/min)、切深t(mm)和進給s(mm):
式中:T為綜合目標(biāo)函數(shù);i為零件上加工特征總數(shù)量;Qi為第i個特征加工誤差。
3 實驗驗證
為驗證上述方法的準(zhǔn)確性,以典型零件中的加工特征分別構(gòu)建質(zhì)量目標(biāo)函數(shù)并進行優(yōu)化。該零件上加工特征及對應(yīng)尺寸如表 1所示。
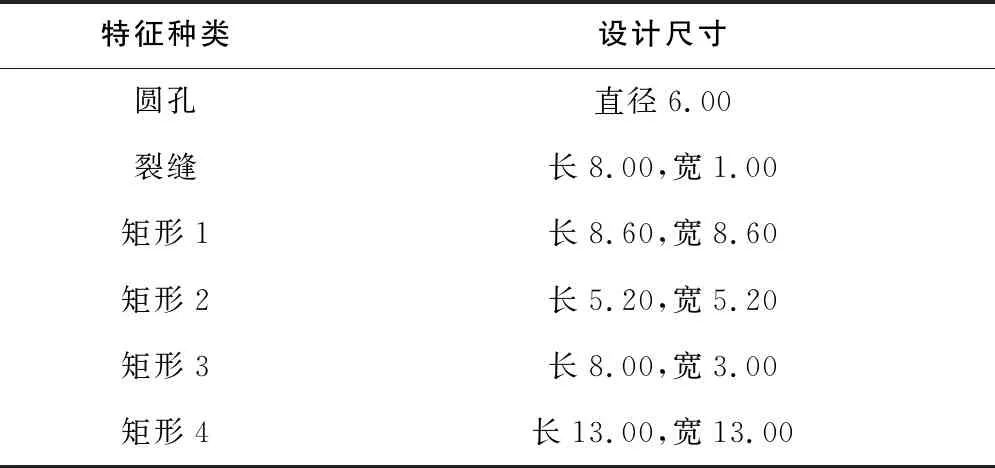
表1 加工特征及尺寸表 單位:mm
3.1 特征篩選分析
采用皮爾森相關(guān)系數(shù)與基于學(xué)習(xí)模型的特征排序相結(jié)合的方式對特征進行篩選,結(jié)果如圖 2所示。
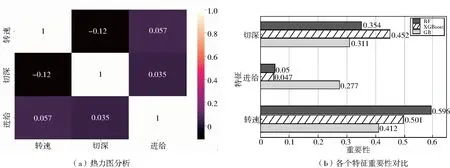
圖2 特征熱力圖及特征重要度分析圖
通過熱力圖和特征重要度排序分析,由熱力圖分析可知各個工藝參數(shù)之間相關(guān)性較小,通過重要度分析可知各個工藝參數(shù)中重要度降序排列分別為:轉(zhuǎn)速、切深、進給。綜合分析,3個參數(shù)均要作為之后的分析特征。
3.2 質(zhì)量目標(biāo)函數(shù)構(gòu)建
采用XGBoost算法構(gòu)建質(zhì)量目標(biāo)函數(shù),結(jié)果如表 2所示。
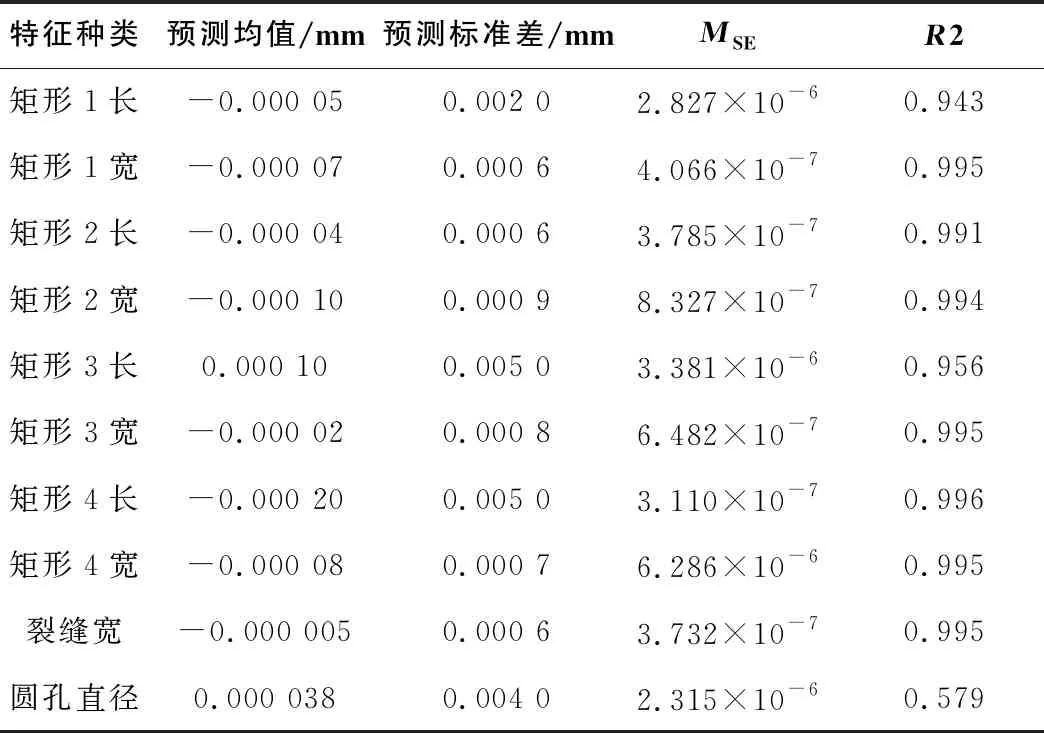
表2 質(zhì)量目標(biāo)函數(shù)構(gòu)建結(jié)果
從表2可以得出,不同特征下基于XGBoost的質(zhì)量目標(biāo)函數(shù)擬合值與真實值之間差值的均值接近于0,標(biāo)準(zhǔn)差也接近于0,擬合穩(wěn)定性較強。MSE接近于0且R2的值接近于1,說明擬合精度很高,擬合效果較佳。
3.3 質(zhì)量目標(biāo)優(yōu)化
采用改進后的遺傳算法以整個零件加工誤差為目標(biāo)進行優(yōu)化,最優(yōu)優(yōu)化結(jié)果如表 3所示。

表3 最優(yōu)優(yōu)化結(jié)果
最終實際選擇的加工參數(shù)為轉(zhuǎn)速35 000 r/min,切深0.03 mm,進給2 900 mm。在該工藝參數(shù)下利用XGBoost算法對質(zhì)量進行預(yù)測,預(yù)測值與原有的實際加工誤差之間的對比如表4、圖3-圖7所示。

表4 質(zhì)量優(yōu)化工藝參數(shù)與其他工藝參數(shù)加工誤差對比
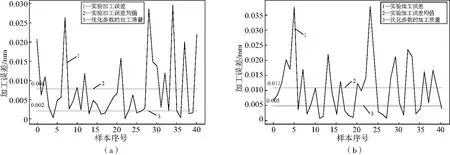
圖3 矩形8.6 mm×8.6 mm優(yōu)化前后誤差對比圖
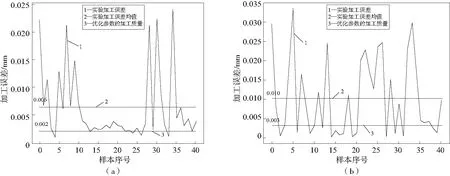
圖4 矩形5.2 mm×5.2 mm優(yōu)化前后誤差對比圖
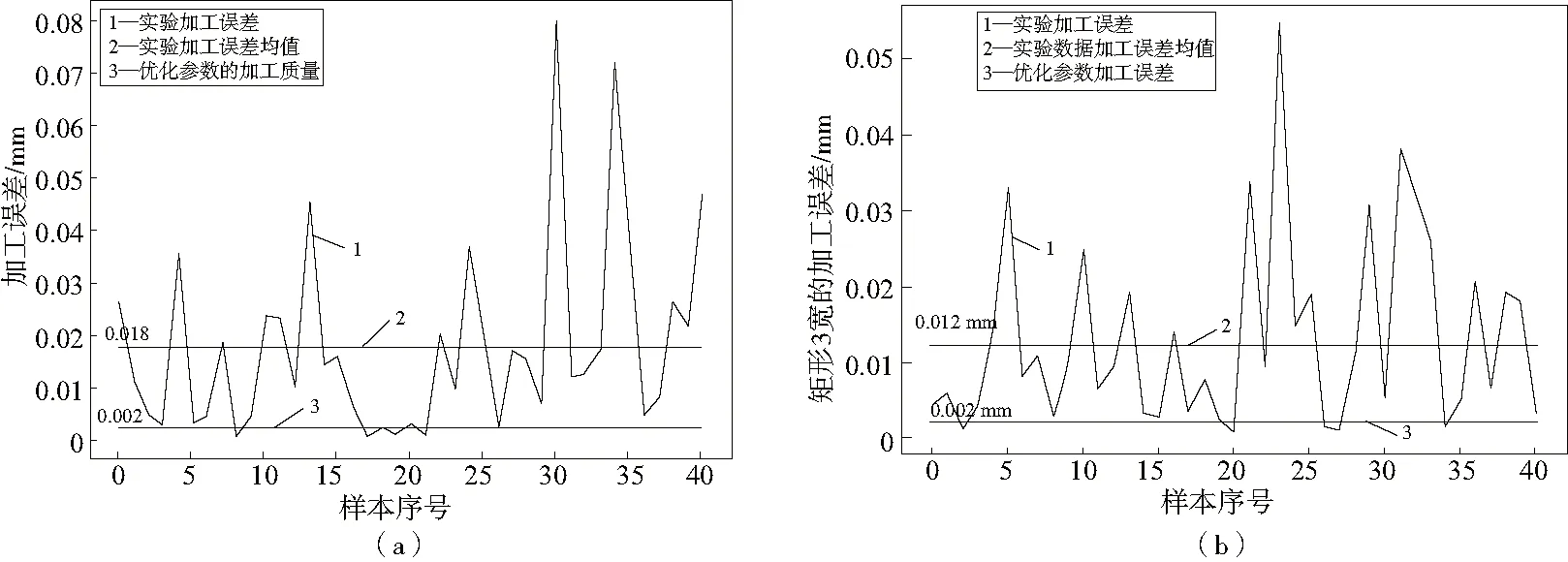
圖5 矩形3 mm×8 mm優(yōu)化前后誤差對比圖
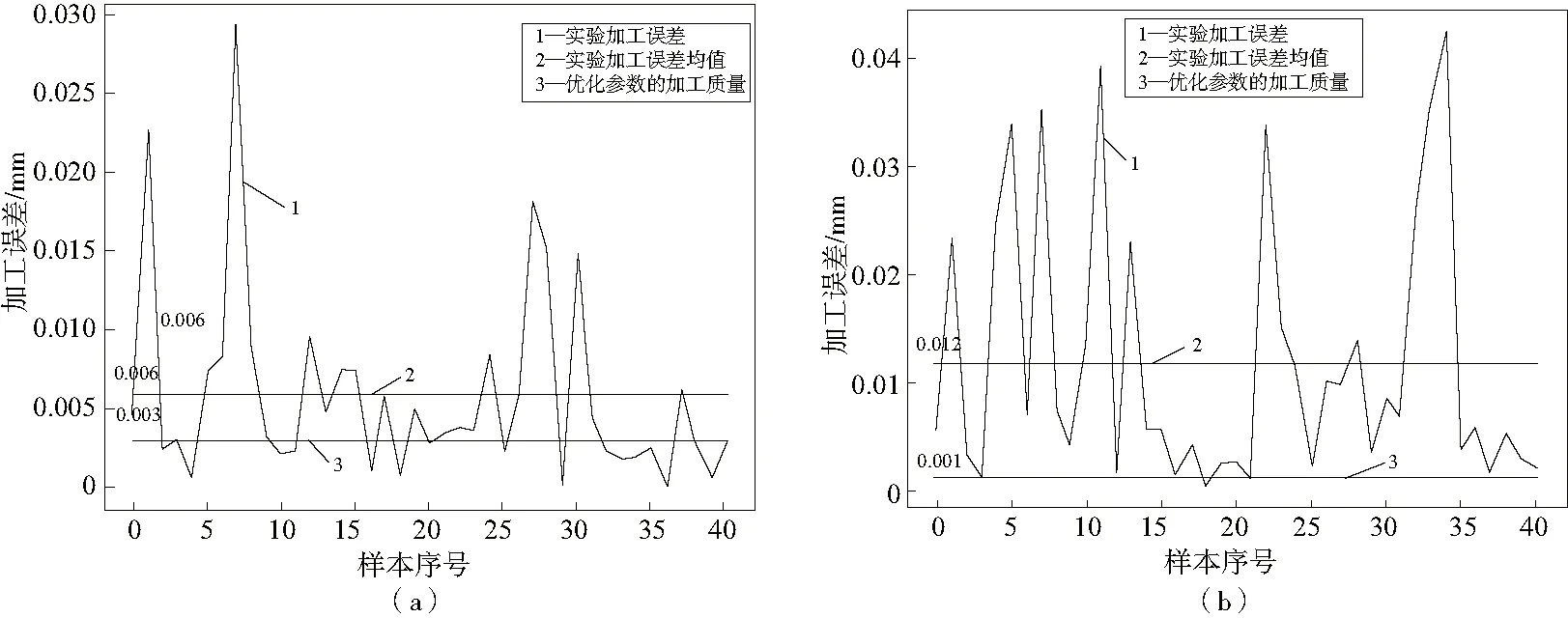
圖6 矩形13 mm×13 mm優(yōu)化前后誤差對比圖
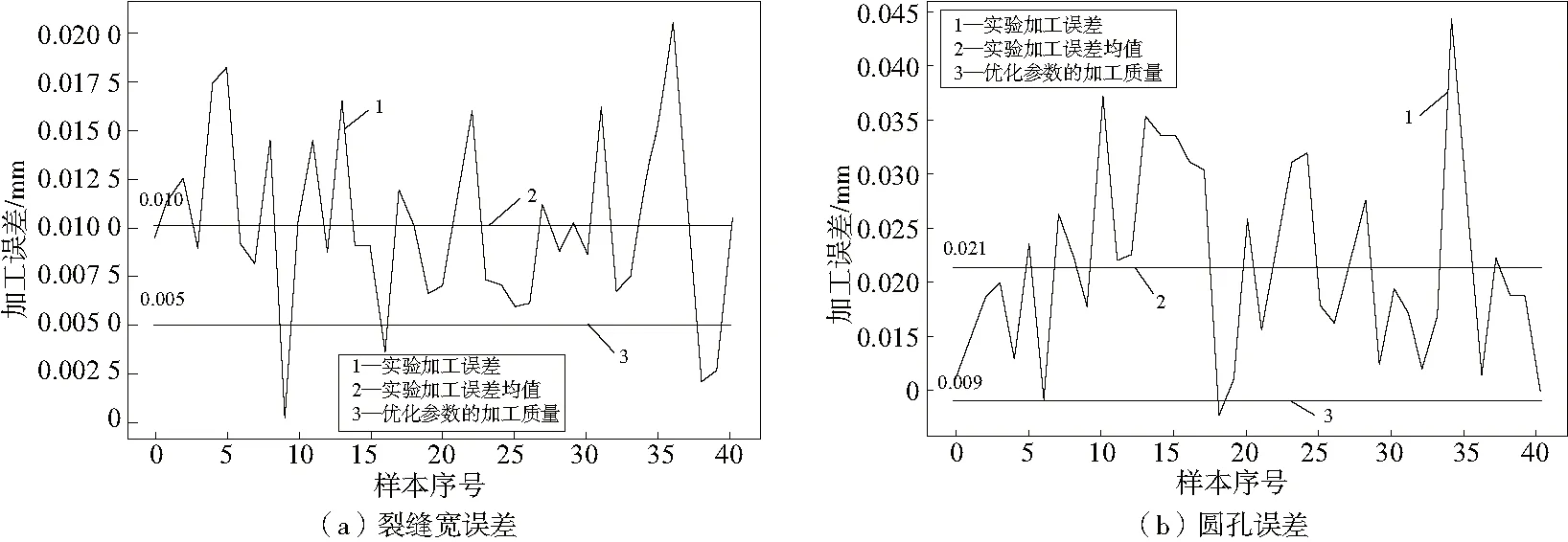
圖7 裂縫1 mm和圓孔Φ6 mm優(yōu)化前后誤差對比圖
4 結(jié)語
本文提出了一種基于XGBoost和遺傳算法的優(yōu)化算法,充分綜合了各個加工工藝參數(shù)和力學(xué)參數(shù)的影響因素。通過特征相關(guān)性分析與特征重要度排序,找到對質(zhì)量和效率具有強相關(guān)的特征要素,并在此基礎(chǔ)上對XGBoost模型參數(shù)進行質(zhì)量目標(biāo)函數(shù)構(gòu)建,有效提升了模型預(yù)測精度,進而通過遺傳算法進行了多目標(biāo)優(yōu)化算法模型構(gòu)建,提高了加工質(zhì)量。
猜你喜歡
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
中學(xué)生數(shù)理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化·中考版(2020年10期)2020-11-27 01:59:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中國生殖健康(2019年2期)2019-08-23 08:12:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
