基于LSTM模型的盜竊犯罪預測研究*
2022-10-16 15:45:08徐會軍福建警察學院
警察技術 2022年5期
徐會軍 福建警察學院
引言
犯罪治理是國家治理體系和治理能力現代化的重要內容之一,開展犯罪預防,維護社會治安,是關系人民群眾生命財產安全和改革、發展、穩定的大事,對犯罪趨勢的預測可以指導警力有效投入,然而,很多公安實戰部門仍然使用同比、環比等較為簡單和傳統的趨勢分析手段應對宏觀情報,缺少較為科學的定量分析手段。在我國,盜竊類案件是占比較高的刑事案件,但由于其高發低破的特點,是公安機關較為頭痛的一類犯罪,因此,以盜竊案件類為對象,開展基于深度學習的犯罪預測研究與應用,對于公安部門依據預測結果開展高發案件的專項整治行動與情報研判分析具有十分重要的實際意義。
本文以日為時間單位,采用LSTM網絡開展盜竊案件的趨勢預測分析,探索適合地區環境的犯罪預測模型和分析手段。
一、研究綜述
犯罪預測的研究方向包括:犯罪時空預測(時序預測和犯罪預測)、犯罪類型預測、犯罪人預測、受害人預測和再犯預測[1],本文主要開展犯罪時序預測研究。時間序列數據通常能夠刻畫事物及現象的發展過程,并揭示其發展規律,通過建立合適的數學模型對過去時空的時間序列數據進行統計分析則可以實現有效預測[2],犯罪時序預測是利用犯罪數量時序數據進行犯罪預測的一種犯罪預測方法。
我國警務研究者自80年代初就開始運用不同的數理統計方法開展犯罪時序預測研究。楊萍采用數學模型對云南省1977~1986年連續10年的年刑事案件模擬仿真,較為準確的預測1987年的刑事案件數,為犯罪預測的可能性提供科學依據[3];李其富應用灰色預測模型GM(1,1)對全國的殺人案和搶劫案的案件數進行了外推預測[4];屈茂輝等建立了中國財產類犯罪的ARMA(1,10)時序預測模型[5];唐德權等采用2014年芝加哥犯罪數據,設計了一種多模態信息特征融合的犯罪預測算法[6];張晟運用決策樹算法分析多發性盜竊案件以期預測潛在案發時段和區域[7];鄧靈評引入多種聚類算法對入室盜竊犯罪行為分析,探索盜竊犯罪的時空規律[8]。研究者嘗試多維度進行犯罪分析和預測,但多數依賴國外數據或國內的宏觀統計數據,主要采用傳統的機器學習方法或數理統計方法,多數集中于長期或宏觀視角的研究分析,缺乏對于微觀層面的數據分析以及對于短期預測研究還需進一步豐富與改進[9]。
傳統的犯罪分析對于經驗的依賴性強,容易受主觀盲目性、分析數據量等因素限制;目前,我國犯罪的情勢出現了新變化,新型犯罪不斷出現,需要推廣科學的研究方法在犯罪學中的應用[10],社會治理亟需犯罪學界貢獻出更為科學有效的犯罪治理良策。犯罪預測面臨的一個主要挑戰是能否準確有效地分析日益增長的犯罪數據集[11],大數據時代的來臨,為短期犯罪預測提供了技術支撐。在當前大數據時代背景下,隨著機器學習方法在各研究領域的不斷普及和應用,犯罪預測防控研究迎來了新的機遇,運用深度學習方法開展犯罪分析與預測研究,能夠有效促進理論與實踐,為社會治理與犯罪防控提供科學有效的手段。
犯罪事件具有時間和空間上的關聯性,這種關聯性在學習算法中表現為對數據時空特征的記憶性。深度學習之所以比傳統機器學習具有更強的泛化能力,就是因為其良好的記憶能力,尤其長短期記憶模型(Long Short-Term Memory,LSTM)算法能夠有效記住犯罪事件在發生時間和空間上的長期或短期特征,這是傳統機器學習算法所不具備的。LSTM是由RNN發展而來的一種遞歸網絡[12],具有隱藏單元循環遞歸的特點,能夠將上一時間節點的特性傳遞到當前節點,在性能上具有更好的優勢,近年來被廣泛應用于時序分析研究上,沈寒蕾等提出基于長短期記憶模型的入室盜竊犯罪預測研究[9];顏靖華等提出基于LSTM網絡的盜竊犯罪時間序列預測研究,對比ARIMA、支持向量回歸、隨機森林以及XGBoost等方法的預測結果,具有較高的預測精度[13];劉學仁等提出基于長短期記憶模型的盜三車犯罪預測[14]。從研究結果來看,基于深度學習的犯罪預測分析手段具有較為出色的預測表現,能夠較好的實現犯罪行為的分析預測。
本文通過對A市的盜竊警情數據開展基于LSTM的盜竊犯罪趨勢預測分析研究,通過分析提取盜竊案件內在的規律性和關聯性,充分運用大數據技術“大海撈針”的特點,為A市公安機關預防犯罪行為的發生和案發后的情報研判提供較為科學的方法,對于指導公安機關實施微觀打擊,提升綜合戰斗力,具有十分重要的實戰意義。
二、LSTM模型
1943年,Warren McCulloch和Walter Pitts提出人工神經網絡(Artificial Neural Networks,ANN),打開了人工神經網絡的全新局面。ANN是一種模擬人體大腦神經活動行為的復雜網絡結構,通過對人腦神經元的建模和聯接,構建出具有人腦神經功能的模型。神經網絡從環境中學習,將結果以樣本模式存儲并輸入網絡,再根據學習算法調整各層網絡的權值矩陣,學習過程的結束與否由網絡的權值收斂值決定。
循環神經網絡(RNN)是指隨著時間的推移而反復出現的一種結構。它廣泛應用于自然語言處理(NLP)、語音和圖像處理等領域。RNN實現了類似人腦的機制,能在一定程度上保留處理過的信息,不同于其他類型的神經網絡不能保留處理過的信息,因此是進行時間序列分析的最好選擇。
RNN存在長序列依賴會出現梯度爆炸和梯度消失問題[15],而犯罪事件的近期重復性特點,具有時空范圍依賴度,因此無法用于犯罪預測研究。1997年,Hochreiter等人解決了長期依賴問題,在RNN改進基礎上提出LSTM模型[12],可以對長期依賴信息進行學習,能夠處理梯度消失問題,使得可處理序列長度更長的問題。LSTM擁有優異的長序列性能,是一種包含多個神經網絡模塊的連接鏈結構,LSTM網絡引入了三個門限(交互運算過程),分別是遺忘門ft更 新門it和 輸出門ot,如圖1所示。
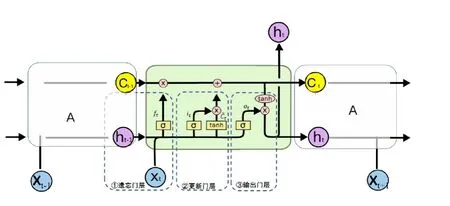
圖1 LSTM內部運算結構圖

(1)首先細胞狀態Ct-1的信息,將在最上面那條線上傳遞;利用不同門運算過程,t時刻的隱層狀態ht與輸入Xt會 對Ct進行狀態更新并傳遞到下一時刻。
(2)遺忘門層:使用取值為[0,1]間控制變量σ逐位與狀態變量Ct-1相乘,當σ為0時,則Ct-1對應的信息就被舍去(遺忘)了,只有σ為1時才保留完整狀態信息。
(3)更新門層:這一層有兩個步驟,一是通過變量σ控制狀態變量,表示有所選擇的遺忘過去信息,獲得輸出it;二是通過歸一處理為[-1,1]的激活函數tanh進行類似遺忘門的過程,表示有保留的獲取更新信息Ct,兩部分信息加起來就是更新內容。
(4)輸出門層:利用變量σ控制輸出內容,并通過tanh函數縮放為最后t時刻的輸出。
以上就是LSTM在t時刻的完整運算過程。本文的研究就是在上述過程中實現對盜竊警情的分析預測。
三、數據分析與討論
本研究主要目的在于探索深度學習技術在犯罪趨勢預測的應用實踐,針對A市3年的日盜竊犯罪的110接警數據,運用TensorFlow平臺的LSTM模型模擬預測,為犯罪預測提供較為科學的方法手段。
(一)數據預處理
1. 時間分割
考慮到數據的特殊性,研究首先對110警情數據進行脫敏處理,僅保留數據的時間列;然后進行時間分割,為LSTM模型輸入數據做準備。本研究假定犯罪預測模型是針對指定區域每天的犯罪情況做預測,因此,通過Excel透視表功能,將數據整合以日尺度為單位的時間序列,從時間維度上將原始數據按天進行分割,整理為包括每日的盜竊犯罪案件數量和對應時間的數據集。經整理,數據集共包含盜竊警情56000起,日均51起,其中,最高105起,最低4起,標準差為19.5起。從數據集的時間分布趨勢上看(如圖2所示),警情數量隨時間波動較大,呈上升趨勢,之后趨于平穩的狀態。
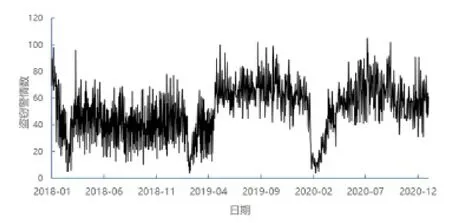
圖2 盜竊警情分布趨勢
2. 平穩性檢驗
為確保數據集具有較好的平穩時序特征,需要對數據集進行單位根(ADF)檢驗。因為數據集的ADF檢驗值小于1%置信水平的臨界值,對數據集進行一階差分平移,平移后,數據集的ADF檢驗值小于1%置信水平的臨界值,屬于平穩序列,能夠進行時序預測(見表1)。
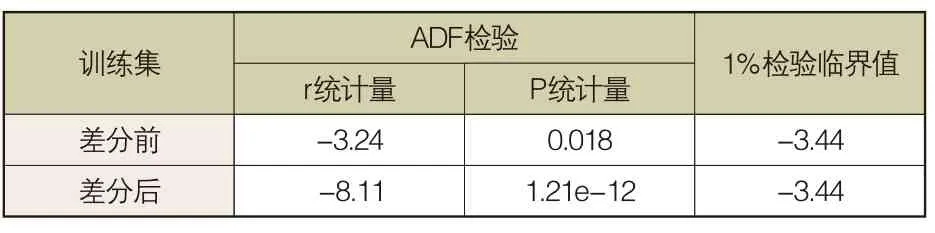
表1 數據集的ADF檢驗結果
3. 建立多變量序列
本文參考顏靖華等人提供的特征因素提取方法[13],引入月份(month)、工作日(Is_weekend)、是否節假日(Is_holiday)、每月均值(month_avg)、每工作日均值(weekend_avg)、每非工作日均值(weekday_avg)以及前一日的警情數量(count_lag1),建立多變量時間序列,并轉換為監督學習數據集,其中滯后觀察日為1,并進行歸一化處理。
4. 模型構建
預測模型主要由LSTM、Dense兩個層級構成,將上述數據集按比例分割成訓練集和測試集數據輸入LSTM模型,其中損失函數為MAE,優化器函數為ADAM,設置好epoch、batchsize等參數,并采用均方根誤差(RMSE)對模型進行性能評估。

(二)結果與討論
擬合結果如圖3所示,虛線前的日期為訓練集,虛線后的日期為測試集。在訓練集中,LSTM模型較好地捕捉了盜竊犯罪案件數量的波動,擬合效果較好。將測試集結果輸入LSTM模型進行性能評估,預測性能評估指標RMSE為0.099,表明測試結果較好。圖4為預測結果進行反歸一化及逆向1階差分等還原操作過程后數據對比效果。
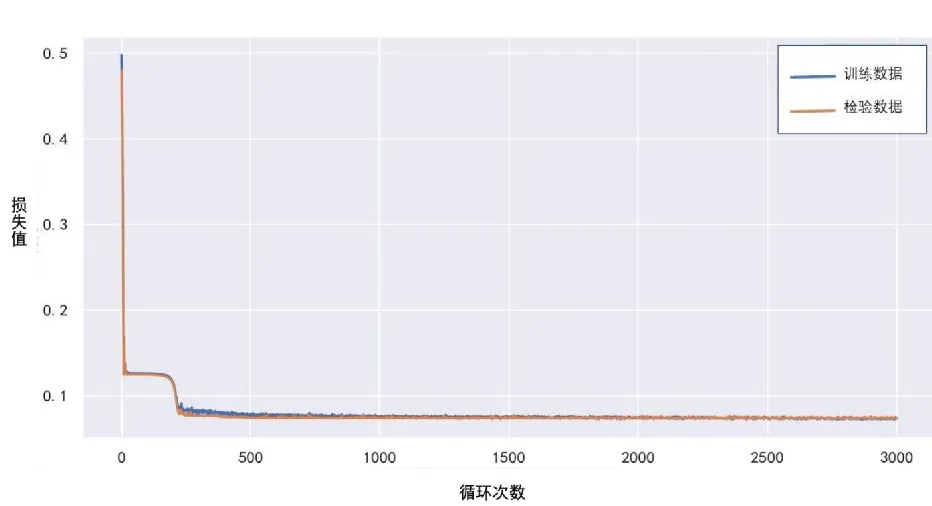
圖3 LSTM損失分析過程
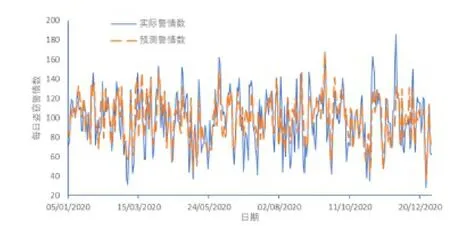
圖4 LSTM預測結果
四、結論
本文采用LSTM模型實現了多變量時間序列的日尺度盜竊警情數據的預測分析,結果表明,LSTM模型能夠較為出色的對日尺度下的警情進行模擬預測,能夠一定程度的給出犯罪行為的總體趨勢演變情況。本文研究基于盜竊案件是一個獨立的封閉系統的假定下開展,然而,犯罪行為是一個受眾多因素影響的復雜事件,本文的研究僅僅提供了一個犯罪預測的方法和手段,在犯罪預測和情報研判實戰中,應當融合社會等因素,預測結果也只能作為警力部署和智慧決策的參考。
從技術角度上看,犯罪預測面臨的一個難點就在于能否準確有效地分析日益增長的犯罪數據集,對于使用規模較大的數據集時,模型精度就高,反之,模型精度就會較低,因此,一個具有較高精度的犯罪預測分析模型的實現,需要大量的歷史案例積累進行訓練。另外,受限于犯罪預測算法的局限性和不確定性,多種模型的混合應用能夠有效提高犯罪預測的精度[11],后續的研究將引入更多的因素,通過構建混合模型來提升預測精度,讓預測方法更加科學,更貼近實戰。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
