基于圖注意力網絡字詞融合的中文命名實體識別
2022-10-16 12:28:02宋旭暉于洪濤李邵梅
計算機工程 2022年10期
宋旭暉,于洪濤,李邵梅
(1.鄭州大學 網絡空間安全學院,鄭州 450001;2.戰略支援部隊信息工程大學 信息技術研究所,鄭州 450002)
0 概述
命名實體識別(Named Entity Recognition,NER)是信息抽取的子任務之一,主要指識別文本中的人名、地名、組織名等實體,是關系抽取[1]、事件抽取[2]、問答系統[3]等自然語言處理任務的重要基石。早期的命名實體識別方法主要基于規則和字典,但這些方法的效率較低、成本過高,且需要大量的專業知識。隨著深度學習在自然語言處理領域的廣泛應用,研究人員將深度學習應用到命名實體識別模型中。基于深度學習的模型一般可以分為嵌入層、編碼層和解碼層3 個部分。模型首先利用嵌入層將字詞級別的輸入轉化為相應的字詞向量,其次將字詞向量輸入編碼層以學習上下文語義特征,最后通過解碼層對編碼層輸出的特征向量進行分類,從而完成對實體的標注。[4]
在編碼層中,卷積神經網絡(Convolutional Neural Network,CNN)[5]與循環神經網絡(Recurrent Neural Network,RNN)[6]因其高效并行運算、兼顧上下文信息等優勢被廣泛應用[7-8],但梯度消失、梯度爆炸、數據空間限制等問題的存在嚴重影響了模型的準確性與可擴展性。由于在命名實體識別任務中語句與篇章結構均以圖數據的方式存在,因此越來越多的研究人員考慮將基于圖注意力網絡的編碼器應用于模型中。相比于CNN、RNN 等序列模型,基于圖注意力網絡的編碼器可以充分利用圖結構在空間中的優勢,并利用信息交互的方式減少信息傳遞損失,因此具有更好的識別效果。圖注意力網絡在圖中引入注意力機制,每個節點特征的計算都會通過計算相鄰節點對該節點的影響來動態調整權重,從而將注意力集中在影響較大的節點上。文獻[9]將圖注意力網絡(Graph Attention Network,GAT)[10]引入中文命名實體識別,將自匹配詞匯、最近上下文詞匯等詞匯知識融入到編碼層中,提出協同圖網絡(Collaborative Graph Network,CGN)的模型,進一步提高命名實體識別效果。然而由于該模型使用的GAT 網絡在計算注意力時,連續的線性計算對于任何查詢節點i,注意力網絡都傾向于同一節點j更高的注意力權重,因此得到的是靜態注意力,損害了圖注意力的表達能力。基于此,本文采用改進的圖注意力網絡(GATv2)[11]提高命名實體識別的效果。
此外,CGN 模型只在編碼層利用詞匯知識,在嵌入層沒有充分利用詞邊界信息。然而在模型的嵌入層中,詞邊界信息是影響中文命名實體識別性能的重要因素。在命名實體識別任務中,詞邊界信息的缺乏會導致無法確定實體的首尾位置,進而降低識別準確率。研究表明,在命名實體識別模型中融入分詞信息,可以提高模型識別效果[12-13]。與英文相比,中文沒有顯性的詞邊界信息,因此本文在嵌入層融入分詞信息,以改善詞邊界信息缺乏問題。
為提高基于CGN 網絡的中文命名實體識別模型[9]的識別準確率,本文提出一種基于改進圖注意力網絡的中文命名實體識別(WS-GAT)模型。通過在嵌入層加入分詞信息,并在序列編碼過程中使用向量拼接方式,從而充分利用詞邊界信息。在編碼層對圖注意力網絡進行改進,采用GATv2 模型改進節點間相關系數的計算方式,以計算節點間的動態注意力,提高命名實體識別準確率。
1 本文模型
本文模型結構分為嵌入層、編碼層和解碼層3 層,如圖1 所示。
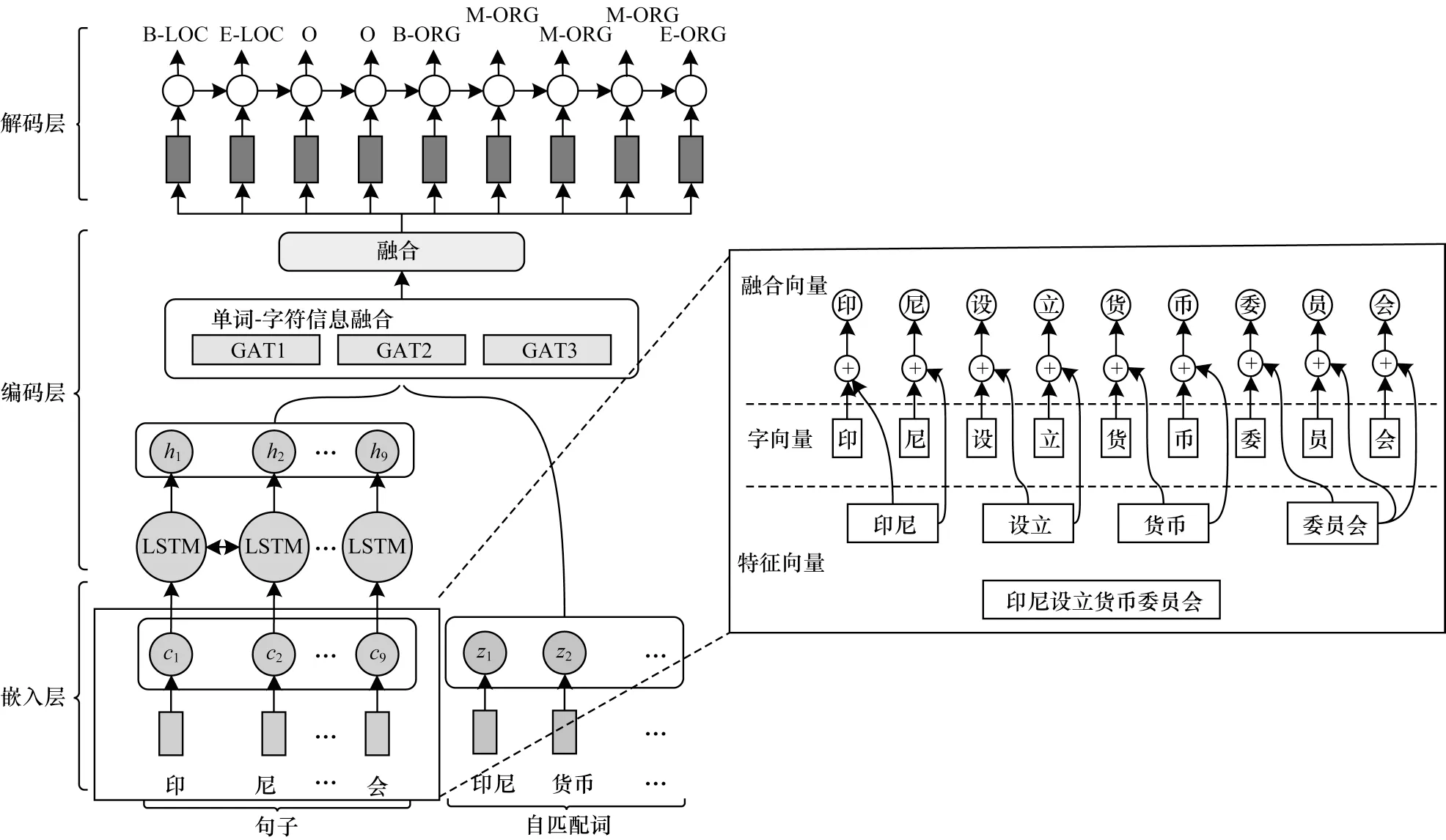
圖1 WS-GAT 模型結構Fig.1 Structure of WS-GAT model
由圖1 可知,模型首先在嵌入層將文本映射成字符向量,將分詞信息映射成特征向量,并與字符向量進行融合,作為嵌入層的字向量表示。其次,在編碼層使用BiLSTM 提取特征,利用GATv2 網絡將詞匯信息融合,作為最終的特征表示。最后,在解碼層采用條件隨機場進行解碼,實現對實體的標注。與傳統的命名實體識別模型相比,本文模型在嵌入層融入分詞信息并生成包含詞匯邊界信息的字向量(如圖1 中右側框圖所示),能夠緩解難以確定詞匯邊界的問題。此外,在編碼層采用GATv2 網絡(如圖1 中編碼層單詞-字符融合框圖所示),能夠提高模型的特征提取能力。
1.1 融入分詞信息的嵌入層
1.1.1 字向量的生成
在通常情況下,模型嵌入層負責對輸入字符和詞匯進行編碼,而在中文命名實體識別任務中,對字符進行編碼的方式由于存在語義缺失等問題,導致無法有效利用詞匯信息。且與英文相比,中文沒有顯性的詞邊界特征,詞邊界信息的缺失降低了命名實體識別的性能。因此,本文模型采用將詞匯的分詞特征向量與字向量相融合的方式,以改善詞邊界信息缺失的問題,提高命名實體識別準確率。字向量與分詞特征向量進行融合的方式如圖2 所示。
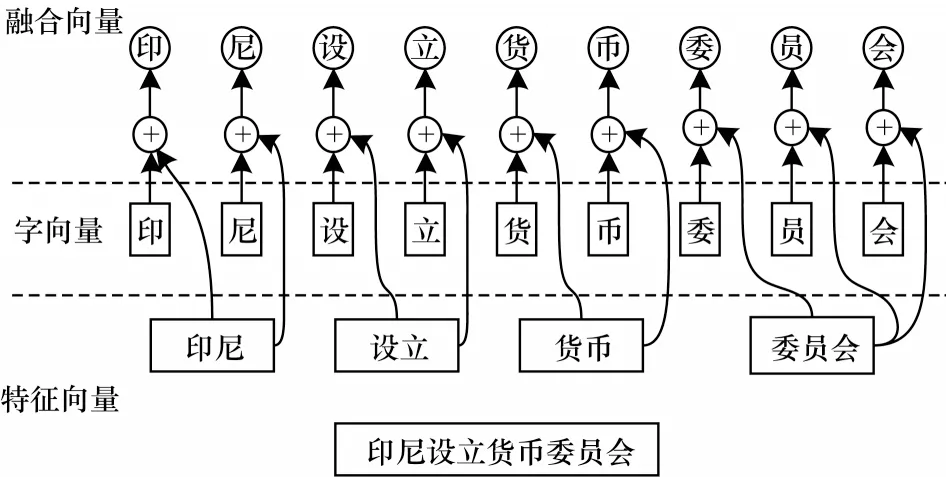
圖2 字向量與分詞特征向量的融合示意圖Fig.2 Schematic diagram of word vector and word segmentation feature vector
如圖1 所示,模型的輸入是一個句子和這個句子中所有的自匹配詞,字符的自匹配詞是指包含該字符的詞匯。本文用t={t1,t2,…,tn}表示該句子,其中tn表示句子中的第n個字。對句子中的每個字符均通過查找字符嵌入矩陣的方式表示為一個向量xi,其表達式如式(1)所示:

其中:ac是一個字符嵌入查找表。
模型通過分詞工具對句子進行分詞并對訓練集中的數據進行標注以構建分詞特征,如對于“北京”實體,在訓練集中的標注為“北B-LOC”、“京E-LOC”。為了獲得詞邊界信息,本文在數據中增加分詞特征,將“北京”實體重新標注為“北seg:0 B-LOC”、“京seg:1 E-LOC”。將重新標注的數據輸入到模型后,模型通過維護特征查找表實現分詞特征的編碼,將分詞信息編碼為特征向量[s1,s2,…,sn],進而將分詞特征編碼與字向量進行拼接,并作為字符的向量表示。最后將詞匯信息融合到字向量中,得到包含詞邊界信息的字向量,其表達式如式(2)所示:

其中:si表示該字對應的特征向量;⊕表示向量拼接;ci表示融合后的字向量表示。
1.1.2 自匹配詞向量的生成
為了表示單詞的語義信息,得到自匹配詞的向量表示,本文將模型中輸入句子匹配到的詞匯表示為l={z1,z2,…,zm},通過查找預訓練單詞嵌入矩陣,將每個單詞表示為一個語義向量zi,其表達式如式(3)所示:

最后將字向量和詞向量進行拼接,得到嵌入層最后的輸出表示:
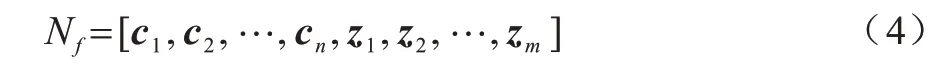
其中:zi為自匹配詞向量表示。
1.2 基于多個圖注意力網絡的編碼層
模型編碼層負責捕獲文本的上下文特征,相比于CNN、RNN 等序列模型,圖注意力網絡因其對圖結構數據的強大特征提取能力被應用于命名實體識別中。為增強特征提取效果,本文應用GATv2 網絡對特征進行編碼,從而得到文本的語義表示。
首先使用BiLSTM 模型[14]對嵌入層獲得的字向量進行初步建模,通過計算得到前向和后向2 個不同的特征表示,并將這2 個特征表示進行拼接,得到包含上下文特征的向量H={h1,h2,…,hn},如式(7)所示:

然后將向量H輸入到GATv2 網絡中以提取特征,從而得到包含更加豐富語義信息的特征向量。具體來說,構建單詞-字符交互圖G=(V,E),其中:V是節點集合,代表所有的字符和自匹配詞;E是邊集合,代表不同的關系。本文通過參考文獻[9]的構圖方式構建的圖注意力模型由3 個單詞-字符交互圖構成:包含圖、轉換圖和Lattice 圖,它們分別用來整合詞內語義信息、上下文詞匯信息和自匹配詞邊界信息,構圖方式如圖3 所示。這3 個圖共享相同的頂點集V,并引入3 個鄰接矩陣A來表示圖中節點和邊的信息。在包含圖中,如果自匹配詞i包含字符j,則將鄰接矩陣AC中(i,j)的值賦為1。在轉換圖中,如果單詞i或字符m與字符j的最近前序或后序相匹配,則對應AT中的(i,j)或(m,j)的值被賦為1。在Lattice 圖中,如果字符j和匹配詞i的第1個或最后1個字符匹配,則AL中(i,j)的值賦值為1,如果字符m是字符j的前一個或后一個字符,則AL中(m,j)賦值為1。
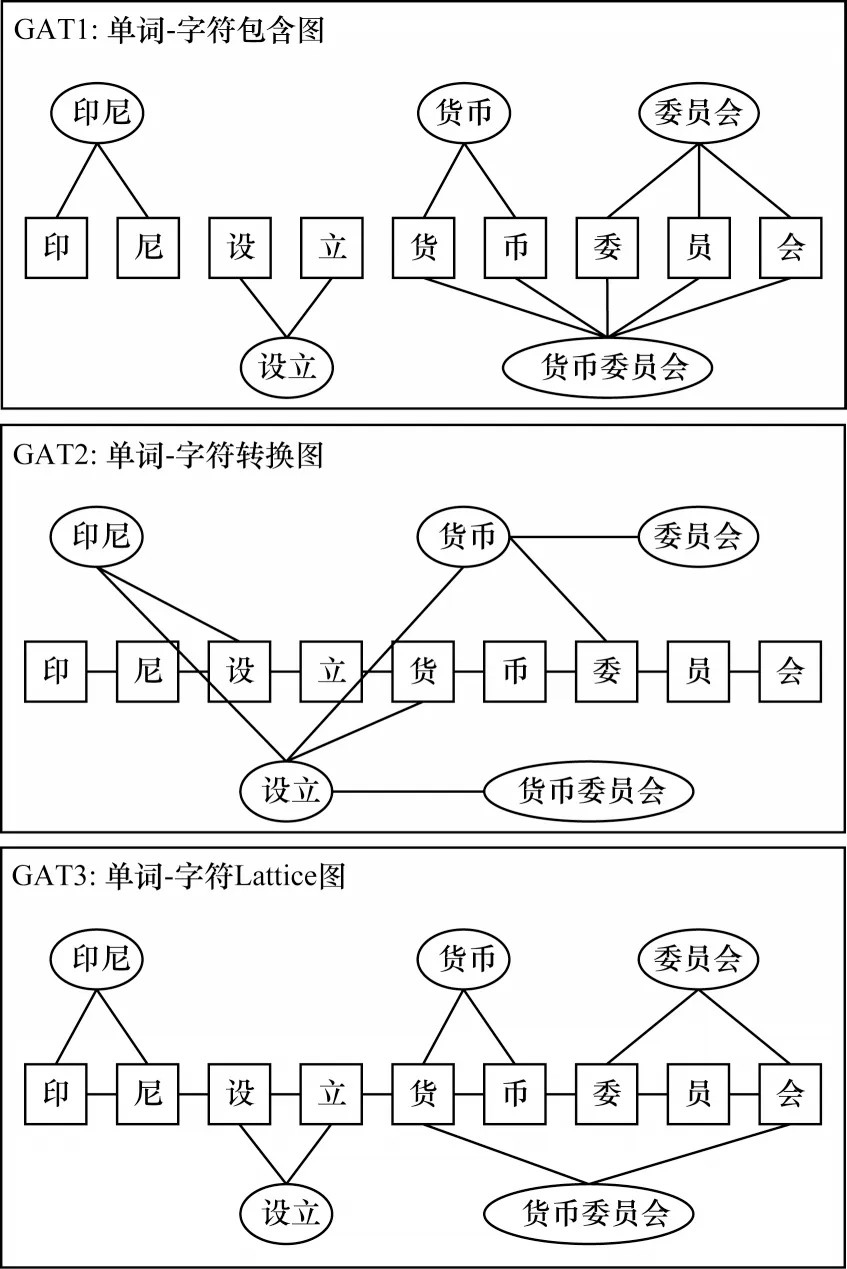
圖3 單詞-字符交互示意圖Fig.3 Schematic diagram of word-character interaction
GAT 網絡的輸入是節點的特征表示NFj={h1,h2,…,hN}以及鄰接矩陣A,其中A∈?N×N,N為節點數。文獻[10]使用GAT 網絡進行字詞信息融合,如公式(8)所示:
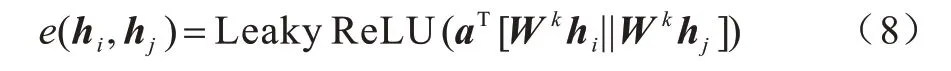
其中:e(hi,hj)表示節點j和節點i間的相關系數;a和W均為可學習的參數矩陣;k為注意力頭數。
傳統GAT 網絡存在靜態注意力問題[11],由于權重矩陣W和注意力矩陣a的連續應用,導致經過連續線性變化的hi和hj對于任何查詢節點,注意函數相對鄰居節點是單調的,即對于任何查詢節點i,圖注意力網絡都傾向給同一節點j更高的權重,這損害了圖注意力的表達能力。因此本文采用GATv2 網絡進行特征提取,表達式如式(9)所示:
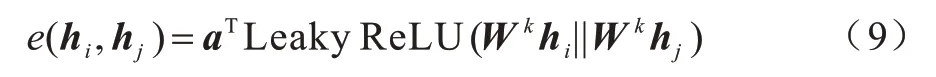
改進后的公式對注意力功能進行修正,在經過非線性層之后,應用注意力矩陣a可以計算所有節點的貢獻程度,進一步增強了節點的特征向量表示。
將上一步計算得到的相關系數進行歸一化,得到節點的注意力系數,表達式如式(10)所示:
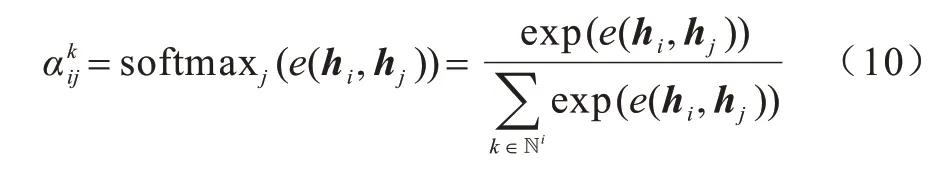
之后進行加權求和,得到最終的輸出特征:
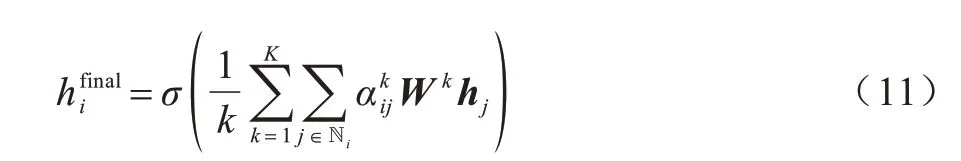
使用3 個圖注意力網絡進行編碼后,獲得的節點特征分別為G1、G2、G3:

其中:Gk∈?F′×(n+m),k∈{1,2,3}。保留這些矩陣的前n列作為最后的字符表示來解碼標簽。
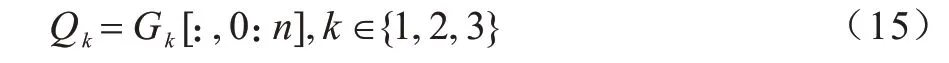
最后,對3 個交互圖獲取的包含不同詞匯知識的向量進行融合,表達式如式(16)所示:
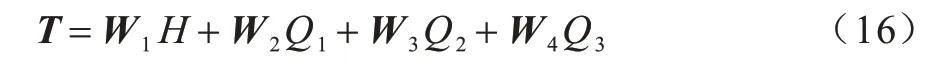
其中:W1,W2,W3,W4為可訓練矩陣;H是輸入的上下文表示;Q1,Q2,Q3為3 個GAT 圖得到的字符表示。
最終,本文得到融合上下文信息、自匹配詞信息和最近上下文詞匯知識的新句子表示,使用矩陣T來表示,其中T∈?F′×n。
1.3 基于條件隨機場的解碼層
解碼層負責對輸入的上下文表示生成對應的標記序列。在自然語言處理任務中常將條件隨機場(Conditional Random Fields,CRF)[15]作為解碼器,CRF 通過捕獲連續標簽之間的依賴關系進行全局優化,在很大程度上解決了輸出標簽獨立假設的問題,被廣泛應用于序列標注等任務。
本文模型也采用CRF 作為解碼層,對于編碼層的輸出序列T={r1,r2,…,rn},若其對應的標注序列為Y={y1,y2,…,yn},則標注序列y的概率為:
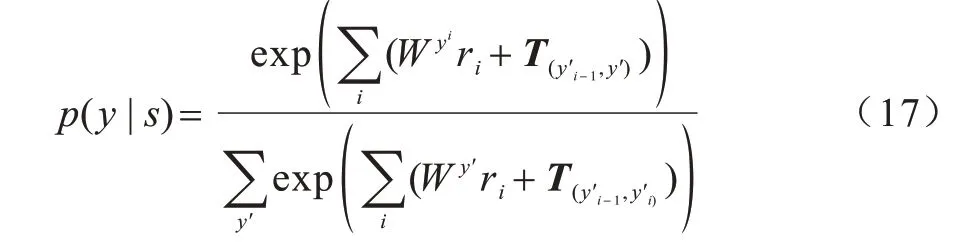
其中:y′是一個任意的標簽序列;T是存儲一個標簽到另一個標簽的轉移得分矩陣。在模型訓練過程中,采用L2 正則化最小化對數似然損失函數來優化模型,損失函數的定義為:

其中:y是L2 的正則化參數;θ是所有可訓練集的參數。
2 實驗結果與分析
2.1 數據集介紹
實驗共選取了6 個中文數據集,包括MSRA[16]、OntoNotes4.0[17]、Resume[18]、Weibo[19]4 個常用數據集,以及People Daily[20]、Boson 這2 個公開數據集來評估模型結果。各數據集信息如表1 所示,其中“—”表示無此項內容。

表1 數據集信息Table 1 Information of datesets
2.2 標注規范和評價指標
命名實體識別有多種標注方式,包括BIO、BMESO、BIOES 等。本文實驗采取BMES 標注方式,其中,B、M、E 分別代表實體的開始、中間以及末尾部分,S 代表一個單獨的實體。
本文選用精確率(P)、召回率(R)以及F1 值為評價指標衡量模型好壞,計算方式如下:

其中:Tp為模型標記正確的實體個數;Fp為錯誤標記的實體個數;Fn為未進行標記的實體個數。
2.3 實驗參數設置
本文將在中文Giga-Word 數據集上預先訓練的字符作為輸入模型的字符嵌入[18],采用文獻[21]中提供的詞匯信息作為詞匯嵌入,并使用dropout[22]算法防止模型過擬合。在MSRA、People Daily 和Boson 3 個數據集上使用Adam 算法[23]優化參數,在OntoNotes4.0、Resume、Weibo 數據集上使用隨機梯度下降(Stochastic Gradient Descent,SGD)算法優化參數。實驗設定的超參數值如表2 所示。

表2 實驗超參數設置Table 2 Experimental hyper parameters setting
2.4 實驗結果
相對于CGN 模型,本文模型在嵌入層融入詞匯的分詞信息,并在編碼層改進圖注意力網絡。為驗證本文模型的有效性,本文對于在嵌入層融入分詞信息并改進圖注意力網絡的模型(即本文模型)以及僅在嵌入層融入分詞信息的模型分別進行實驗。下文從改進策略有效性、與其他模型的對比、模型復雜度和模型的收斂速度4 個角度對模型進行分析。
2.4.1 改進策略有效性分析
為驗證本文模型在中文命名實體識別任務上的有效性,本文在MSRA、OntoNotes4.0、Resume、Weibo、People Daily 和Boson 數據集上對改進前后的模型進行對比實驗,結果如表3 所示,表中加粗數字表示該組數據最大值。

表3 本文模型改進前后在不同數據集下的F1 值對比Table 3 Comparision of F1 value of model before and after improvement in this paper under different datasets %
由表3 可知,在MSRA、OntoNotes4.0、Resume、Weibo、People Daily 和Boson 數據集上,本文模型的F1值相比改進前模型均有一定程度的提高,證明了融入分詞信息與改進圖注意力網絡對于提高命名實體識別性能的有效性。
此外,在MSRA、OntoNotes4.0、People Daily 和Boson 數據集上,僅融入分詞信息的模型F1 值相比改進前的模型均有一定程度的提高,在這4 類數據集上分別提高了0.45%、1.07%、0.86%、0.77%。進一步分析表4 可以得出如下結論:融入分詞信息對小數據集的影響更為明顯;在比較規則的數據集上,融入分詞信息對于模型的F1 值提升較小。綜上所述,融入分詞信息在一定程度上緩解了詞邊界確定困難的問題。
通過將僅融入分詞信息模型的實驗結果與在此基礎上改進圖注意力網絡(即本文模型)的實驗結果進行對比,可以看到在MSRA、OntoNotes4.0、Resume、Weibo 和People Daily 數據集上,本文模型的F1 值相對僅使用分詞信息的模型有一定程度的提高,這說明改進后的圖注意力網絡GATv2 解決了GAT 網絡的靜態注意力問題,進一步提高了編碼層的特征提取能力。
2.4.2 與其他模型的對比結果
為全面驗證本文模型的有效性,引入Lattice LSTM[18]、LGN[24]、FLAT[25]、LR-CNN[7]等模型與本文模型進行對比,各對比模型分別基于LSTM、CNN、GCN、Transformer 網絡實現,覆蓋了幾種常用的特征提取器,結果如表4 所示,表中加粗數字表示該組數據最大值,“—”表示原論文中未列出實驗結果。由表4 可知,本文模型在Resume 和Weibo 數據集上的F1 值略高于其他模型。雖然本文模型在OntoNotes4.0 數據集上的F1 值表現略差,但模型召回率得到了明顯提升。

表4 不同模型在不同數據集下的實驗結果對比Table 4 Comparison of experimental results of different models under different datasets %
2.4.3 模型時間復雜度分析
命名實體識別作為自然語言處理任務的重要組成部分,對訓練以及測試的速度有很高的要求。本文模型在嵌入層融入分詞信息時會引入額外的計算開銷,但不影響后續計算中原有模型的處理結構和輸入數據規模。此外,GATv2 網絡與標準GAT 網絡具有相同的時間復雜度[11],所以本文模型除了增加分詞開銷外不會引入其他的計算開銷。為具體度量分詞的時間開銷在模型總處理時間上所占的比例,本文通過實驗對模型復雜度進行分析。
實驗隨機選取10 個訓練epoch 作為樣本,并對比融入分詞信息前后的模型訓練時間。如表5 所示,在MSRA、OntoNotes4.0、Resume 和Weibo數據集上,模型融入分詞信息占用了一定的時間,但占整體處理時間的比例較小,對模型性能的影響不大。在OntoNotes4.0 數據集上,本文模型的訓練時間增加了2.82%,但F1 值提高了3.16%。在其他數據集上,F1 值也取得了一定程度的提升。綜上,在嵌入層融入分詞信息僅犧牲較少時間復雜度,但獲得了F1值的提升。

表5 不同模型在不同數據集下的時間復雜度與F1 值對比Table 5 Comparison of time complexity and F1 value of different models under different datasets
2.4.4 模型收斂速度對比
為進一步探究融入分詞信息對模型收斂速度的影響,本文研究了在不同的數據集下,模型融入分詞信息前后的F1 值與迭代次數的關系,結果如圖4所示,其中CGN with seg 表示在CGN 中融入分詞信息的模型。可以看到,在保持迭代次數和學習率不變的情況下,融入分詞信息后,模型在不同數據集下的的收斂速度均得到了提升。
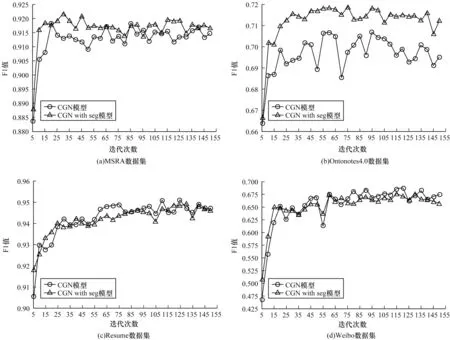
圖4 模型收斂速度的對比Fig.4 Comparison of model convergence speed
3 結束語
本文提出一種基于改進圖注意力網絡的中文命名實體識別模型,通過在嵌入層融入分詞信息,以有效結合文本中的詞匯信息,緩解字詞融合的詞邊界確定困難問題。對模型編碼層的圖注意力網絡進行改進,增強特征提取能力,使用條件隨機場解碼文本,以實現對實體的標注。實驗結果表明,與CGN 模型相比,本文模型在保持迭代次數和學習率不變的情況下,收斂速度更快,證明了融入分詞信息、改進圖注意力網絡對中文命名實體識別的有效性。下一步將重點改進分詞信息融合策略,降低噪聲對識別結果的影響,并通過優化模型,提高模型運行效率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
