面向圖像分類的對抗魯棒性評估綜述
2022-10-14 06:02:14李自拓孫建彬楊克巍熊德輝
計算機研究與發展 2022年10期
李自拓 孫建彬 楊克巍 熊德輝
(國防科技大學系統工程學院 長沙 410073)
2019年瑞萊智慧RealAI團隊對人臉照片進行算法處理,將照片打印并粘貼到鏡框上,通過佩戴眼鏡成功攻破19款商用手機的人臉解鎖[1];2020年美國東北大學團隊[2]設計了一款印有特殊圖案的T恤,可使穿戴者躲避智能攝像頭的監測;2021年騰訊科恩實驗室[3]通過在路面部署干擾信息,導致特斯拉Model S車輛經過時對車道線做出錯判,致使車輛駛入反向車道……
由此可見,盡管深度學習在執行各種復雜任務時取得了出乎意料的優異表現,但在安全應用領域仍有很大的局限性.Szegedy等人[4]發現,深度學習對于精心設計的輸入樣本是很脆弱的.這些樣本可以輕易用人類察覺不到的微小擾動,欺騙一個訓練好的深度學習模型,使模型做出錯誤的決策.現在,深度學習中的對抗攻擊技術受到了大量關注,以面向圖像分類為主的對抗攻擊算法[5-10]不斷涌現.
在此背景下,越來越多的研究者開始關注如何提升模型抵御對抗攻擊的能力,即增強模型的對抗魯棒性,并探索出了一系列的對抗防御手段,如梯度遮蔽[11-12]、對抗訓練[6,13]、數據處理[14-15]和特征壓縮[16]等.盡管這些方法對于改善模型的對抗魯棒性是有效的,但是目前針對模型對抗魯棒性的評估框架尚未完善,主要是通過不斷改進攻防算法,反復進行對抗,定性給出模型魯棒性好壞的基準,或者使用分類準確率等指標單一地衡量模型的對抗魯棒性.此外,許多攻擊算法或多或少會受到實驗條件的限制,難以適用于所有的深度學習模型,這些問題為模型的對抗魯棒性評估(adversarial robustness evaluation)帶來了挑戰.
目前,面向圖像分類的對抗魯棒性評估領域還有很大的發展空間,如何正確、科學、定量且全面地評估模型的對抗魯棒性,正在吸引業界和學術界的關注.為了更好地探究對抗魯棒性評估問題,本文系統梳理并分析總結了面向圖像分類的對抗魯棒性評估方法,以促進該領域的研究.
1 對抗樣本相關介紹
生成對抗樣本是開展對抗魯棒性評估工作的基礎.為了更好地理解對抗魯棒性評估,本節首先簡要介紹對抗樣本的概念和相關專業術語,并探討對抗樣本存在的原因.為行文方便,對本文使用的符號進行說明,如表1所示:

Table 1 Notations Used in this Paper
1.1 對抗樣本及相關術語
概念1.對抗樣本.最早提出這一概念的是Szegedy等人[4],他們在原始樣本上添加肉眼難以察覺的微小擾動,愚弄了當時最先進的深度神經網絡(deep neural networks, DNNs),誘導模型分類錯誤.如圖1所示,通過在原始樣本上添加圖中的擾動,就能讓模型將卡車錯誤地識別成鴕鳥.

Fig.1 Illustration for the generation of adversarial example[4]
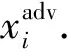
(1)
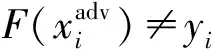
概念3.對抗攻擊知識.它指的是攻擊者所掌握的相關信息,包括訓練樣本、模型結構和模型輸出等.針對攻擊者對智能系統了解情況的多少,可以將攻擊劃分為白盒攻擊、灰盒攻擊和黑盒攻擊,攻擊難度依次增大.由于灰盒攻擊的邊界難以界定,目前研究大多以白盒攻擊和黑盒攻擊為主,本文不對灰盒攻擊進行相關介紹.
概念4.對抗攻擊能力[20-21].指攻擊者修改訓練數據或測試數據的能力.在針對圖像分類任務開展對抗攻擊時,攻擊者的能力往往僅限于對測試集數據進行修改,不考慮通過數據投毒等手段,影響模型的訓練過程,這種攻擊被稱為探索性攻擊.與之對應的誘導性攻擊,指的是通過修改訓練集,破壞原有訓練數據的概率分布,使模型無法達到理想的分類效果.由此可見,誘導性攻擊從根本上實現了對模型的攻擊,比探索性攻擊的攻擊性更強.
通過分析圖像分類全過程各環節[22]的特點,從上述提到的攻擊目標、知識以及能力3個維度對對抗攻擊方法進行分類,形成如圖2所示的對抗攻擊分類框架.誘導性攻擊主要對原始數據輸入以及數據處理階段進行攻擊,探索性攻擊是在模型訓練完成后,針對分類階段進行攻擊;倘若攻擊者無法獲取模型訓練及訓練前各階段的信息,則開展的攻擊為黑盒攻擊,否則為白盒攻擊;在最終的分類階段,針對攻擊者能否精確控制分類器對測試樣本的分類結果,可以將對抗攻擊劃分為目標攻擊和非目標攻擊2類.
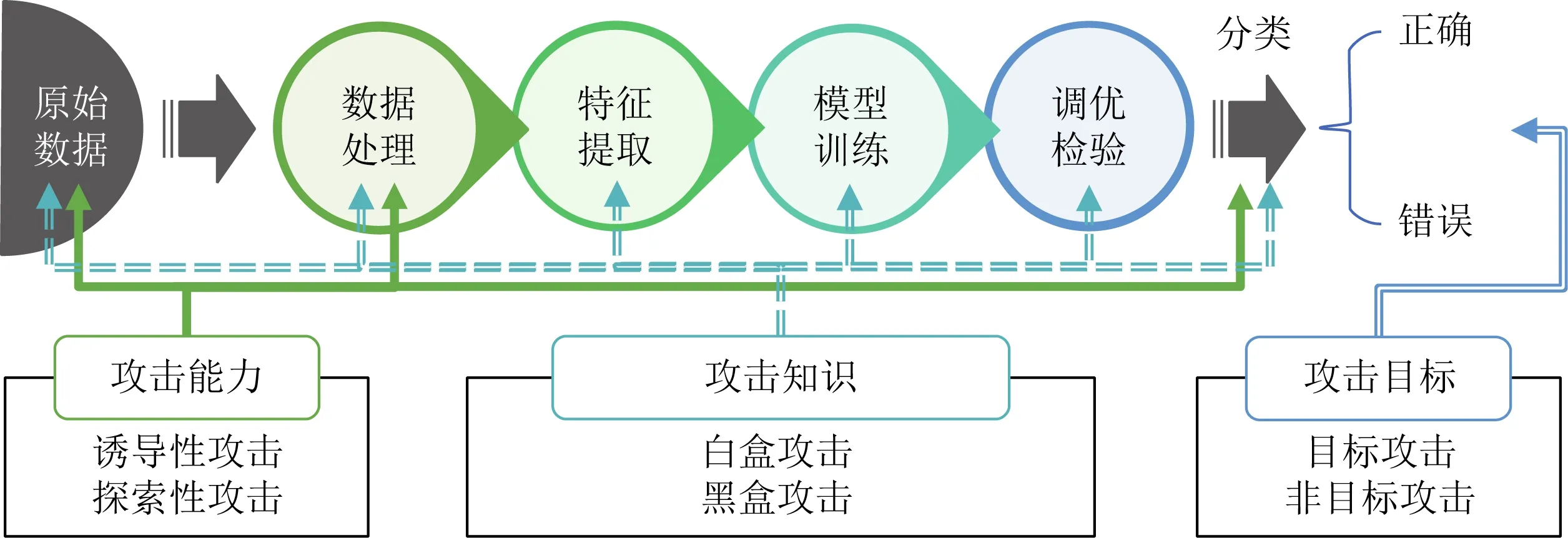
Fig.2 Classification framework of adversarial attack
1.2 對抗樣本存在的解釋
對抗魯棒性評估與對抗樣本密切相關,深入理解對抗樣本產生的機理有助于從根本上提出科學的評估方法與指標.然而關于對抗樣本存在的解釋仍有許多爭議,目前還沒有得出一個準確統一的結論.
Szegedy等人[4]認為網絡模型的非線性特性是導致對抗樣本存在的原因.具體而言,他們從正負實數分類問題中發現,由于無理數的個數要遠多于有理數,訓練集中無理數和有理數的比例難免失去平衡,基于此數據集訓練的模型可能無法對有理數進行正確的分類.但不可否認的是,有理數是的確存在且稠密的.對抗樣本好比有理數,模型的非線性特性使得模型訓練時對高維特征的提取不充分,僅僅學習到局部子空間的特征,可能導致一直存在但被發現的概率很低的對抗樣本難以被觀察到,進而影響了模型的決策.遺憾的是,文獻[4]并沒有給出相關的數學說明.
相反,Goodfellow等人[23]恰恰認為對抗樣本存在的原因與高維空間的線性模型相關,并以此提出快速梯度符號(fast gradient sign method, FGSM)攻擊算法.假設模型的權重向量為w,則有
(2)
當w的維數n非常大時,即使擾動ε很小,wT·ε可能會是一個比較大的數值.因此,得出結論:在高維空間的線性模型中,微小擾動也能使輸出產生較大的變化,以致模型進行錯誤分類.不過,該觀點也存在一些局限性,張思思等人[24]指出線性不是生成對抗樣本的充分條件.還有研究表明[25]高維空間的線性模型并沒有更容易發現對抗樣本,不是所有的線性模型都會存在對抗樣本.
此外,Moosavi-Dezfooli等人[8]證明了全局通用的對抗擾動的存在,并提出對抗樣本的存在是由于分類器決策邊界的幾何相關性.之后,Moosavi-Dezfooli等人[26]又進一步證明了存在共享子空間,決策邊界沿該空間正彎曲,添加擾動的樣本可以越過邊界,成功愚弄模型.Tanay等人[25]也從模型決策邊界角度提出了分類決策邊界超出樣本的子流形導致產生對抗樣本的觀點.
2 對抗魯棒性評估
科學、有效地評估模型的對抗魯棒性對于構建對抗魯棒模型、提高智能系統安全性具有重要意義.然而,至今尚未形成一個公正、統一的對抗魯棒性評估指標或方法.現階段面向圖像分類的對抗魯棒性評估主要分為基準評估和指標評估2類.前者通過提出并改進各種攻防算法[27-31],反復進行對抗,以排名基準[32]的形式反映對抗魯棒性的強弱;后者從對抗樣本的角度出發提出一系列評估指標,旨在通過全面、合理的指標對模型的對抗魯棒性進行評估.相比前者,后者的優勢在于能夠以客觀可量化的方式衡量模型的對抗魯棒性,為增強模型的對抗魯棒性提供可解釋的科學依據.
2.1 基本概念
在深度學習領域,魯棒性(robustness)指的是智能系統在受到內外環境中多種不確定因素干擾時,依舊可以保持功能穩定的能力.而對抗魯棒性(adversarial robustness)[12,33]專指對抗環境下模型抵御對抗攻擊的能力,即模型能否對添加微小擾動的對抗樣本做出正確分類的能力.以任意攻擊方法在原始樣本上添加擾動,模型正確識別該樣本的概率越高,說明模型的對抗魯棒性越強.從數據空間的角度來看,添加的擾動可以被描述為對抗擾動距離[7](即原始樣本和對抗樣本之間的距離),距離范圍內的樣本都能夠被正確分類.因此也可以說,最小對抗擾動距離(minimal adversarial perturbation)越大,則允許添加的擾動范圍越大,模型的對抗魯棒性越強.
可以看出,對抗魯棒性評估的關鍵是計算最小對抗擾動距離.如果可以計算出最小對抗擾動距離的精確值,那么最小對抗擾動距離的值將可以作為模型對抗魯棒性評估的指標.然而,由于神經網絡模型是大型、非線性且非凸的,對抗魯棒性等模型屬性的驗證問題已被證明是一個NP完全(non-deterministic polynomial-complete, NP-C)問題[33-35].作為與對抗魯棒性相關的指標,最小對抗擾動距離難以被精確求解.因此,許多研究轉向使用最小對抗擾動的上界或下界去近似精確值[36].當擾動距離大于上邊界距離時,說明至少有1個添加了該擾動的樣本被模型誤分類;當擾動距離小于下邊界距離時,則任意添加了該擾動的樣本都能被模型正確分類,如圖3所示.通過最大下邊界距離或最小上邊界距離逼近最小對抗擾動距離,從而實現對模型對抗魯棒性的評估.
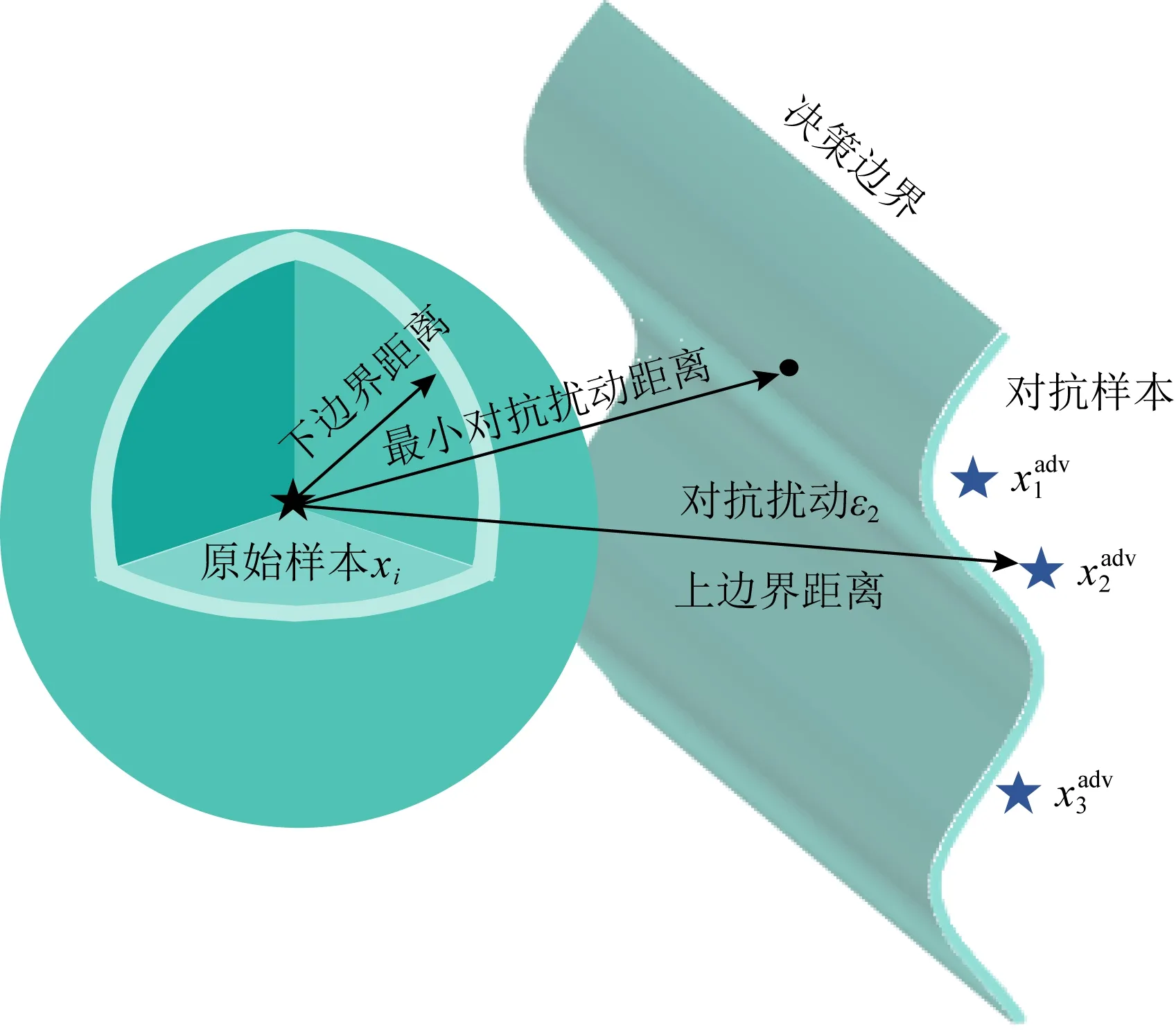
Fig.3 Schematic diagram of upper and lower boundary of adversarial disturbance
2.2 評估準則
對抗魯棒性評估是一個比較困難的問題,執行不合理的實驗會導致評估無效.比如向原始樣本添加的擾動過大,人眼即可判別生成樣本與原始樣本,在此基礎上得到的評估結果是無意義的[37].諸如此類的錯誤常常被研究人員忽略.本文梳理了進行對抗魯棒性評估時需要遵守的3個評估準則[37],以便指導研究人員開展正確的評估.
1)合理使用攻擊算法進行評估.部分攻擊算法是針對某種特定模型而設計的,若將其應用于其他模型,很難體現出模型是否具有抵御這種攻擊的能力,也無法說明模型具有對抗魯棒性.另外,在進行對抗魯棒性評估時,需要保證評估的普適性,這就意味著不能僅僅使用帶有默認超參數的對抗攻擊進行評估,應該排列組合所有參數,達到不同程度的攻擊效果,從而評估模型的對抗魯棒性.
2)保證模型在正常環境下的良好性能.實驗表明,對抗訓練會導致智能系統中神經網絡模型的準確率下降[38].顯然,以犧牲模型對原始樣本的準確率來增強模型對抗魯棒性的做法是不可取的.因此,開展對抗魯棒性評估,應說明模型對原始樣本的分類準確率.被攻擊模型保持正常環境下的分類準確率是正確評估對抗魯棒性的前提.在滿足該前提的條件下,如果被攻擊模型能夠正確識別對抗樣本,才能說明模型具有較好的對抗魯棒性.
3)結合實際需求選擇評估結果分析方法.理論上,評價智能系統的對抗魯棒性應分析模型受到攻擊威脅時的最壞結果.在現實情況中,往往從統計學角度以平均效果衡量魯棒性的好壞.針對不同需求,應適當調整評估思維,給出符合實際的評估結果.進行統計學分析時,還需對分類準確率等結果進行方差計算,避免出現較高的偏差,使評估結果失去穩定性.
2.3 評估指標體系
當前大多數研究通過分類準確率、攻擊次數或擾動強度這3種指標進行對抗魯棒性評估.這些指標能夠直觀上反映模型對抗魯棒性的強弱,但未能全面地考慮到影響對抗魯棒性的因素.針對該問題,本節梳理了現有研究中所涉及的30余種對抗魯棒性評估指標,并從被攻擊模型和測試數據2個角度對指標進行分類.
2.3.1 面向模型的指標
在圖像分類全過程中,被攻擊模型的訓練與決策是影響最終魯棒性評估效果的關鍵環節.進行對抗魯棒性評估時,可以從訓練、決策階段關注模型的結構、行為特征,通過挖掘模型結構相關指標,深入理解模型在對抗環境下的反應,總結與模型決策相關的評價指標,幫助研究人員實現模型對抗魯棒性的評估.因此,本節將面向模型的指標進一步劃分為基于模型行為的指標和基于模型結構的指標.
1)基于模型行為的指標
模型行為可以理解為模型對測試樣本做出的反應.基于模型行為的指標主要是依據對抗環境下模型的輸出結果進行對抗魯棒性度量.
① 原始樣本分類準確率(OA)
盡管我們的目的是解決對抗環境下的模型魯棒性評估問題,但是為了保證模型的基本性能,也需要對正常環境下模型的行為表現進行測試,避免出現模型的對抗魯棒性表現優異而在原始樣本上的分類效果很差的情況,以致無法應用于現實場景中.
原始樣本分類準確率(original accuracy,OA)經常被用來衡量正常環境下模型的分類性能,其含義是被分類正確的原始樣本數量占總體樣本數量的百分比.
(3)
其中,count(·)表示括號內等式為真則為1,否則為0.OA值越大,說明模型在正常環境下的分類性能越好.
② 對抗樣本分類準確率(ACA)
除描述正常環境下模型分類性能的指標外,還有一些公認的、被廣泛接受和使用的、用以描述對抗環境下模型分類性能的指標,如對抗樣本分類準確率(adversarial classification accuracy,ACA).它指的是被正確分類的對抗樣本的數量占總體樣本數量的百分比,數學表達式為
(4)
由式(4)可見,ACA值越大,說明模型在對抗環境下的分類性能越好,在一定程度上可以說明模型的對抗魯棒性越好.
③ 對抗樣本攻擊準確率(AA)
與對抗樣本分類準確率相對應的是對抗樣本攻擊準確率(adversarial accuracy,AA).它指的是被錯誤分類的對抗樣本的數量占總體樣本數量的百分比,數學表達式為
(5)
由式(5)可見,AA值越大,說明模型在對抗環境下的分類性能越差,在一定程度上可以說明模型的對抗魯棒性越差.
針對白盒攻擊與黑盒攻擊2種不同的攻擊,還可以將攻擊準確率進一步劃分為白盒攻擊準確率(adversarial accuracy on white-box attacks,AAW)和黑盒攻擊準確率(adversarial accuracy on black-box attacks,AAB)[39].
④ 白盒攻擊準確率(AAW)
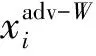
(6)
由式(6)可見,AAW值越大,說明模型越容易將由白盒攻擊方法生成的對抗樣本錯分成其他類別,在一定程度上可以說明模型的對抗魯棒性越差.
⑤ 黑盒攻擊準確率(AAB)
黑盒攻擊準確率(AAB)[39]與白盒攻擊準確率(AAW)類似,不同之處在于對抗樣本是由黑盒攻擊算法生成.
(7)
由式(7)可見,AAB值越大,說明模型越容易將由黑盒攻擊方法生成的對抗樣本錯分成其他類別,在一定程度上可以說明模型的對抗魯棒性越差.
⑥ 正確類別平均置信度(ACTC)
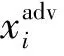
(8)
其中,n表示對抗樣本攻擊失敗的數量,P(·)表示模型分類的置信度.ACTC值越高,說明模型正確識別對抗樣本類別的能力越強,對抗魯棒性越強.
⑦ 對抗類別平均置信度(ACAC)
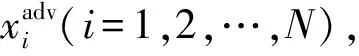
(9)
其中,m表示對抗樣本攻擊成功的數量,P(·)表示模型分類的置信度.ACAC值越高,說明模型識別對抗樣本類別的能力越差,對抗魯棒性越差.
⑧ 噪聲容忍估計(NTE)
主流攻擊算法以最大化模型錯分為除正確類別外的某一類別的概率為目標,很少關注除正確類別和錯分類別外的其他類別的情況.降低模型將樣本分類成其他類別的概率是提高對抗樣本穩健性的有效手段.Luo等人[41]致力于最大化目標類的概率與所有其他類的最大概率之間的差距,提出噪聲容忍估計(noise tolerance estimation,NTE)衡量對抗攻擊的魯棒性:
NTE(F,T)=
(10)
其中,Pyj(·)表示模型將樣本錯分成類別j的置信度,Pyk≠j(·)表示模型將樣本錯分成除類別j外的其他類別的置信度.NTE值越大,說明對抗樣本的魯棒性越強.將NTE值取平均,平均NTE值越小,模型容易混淆除正確類別外的多種類別,在一定程度上可以說明模型的對抗魯棒性越差.
⑨ 互補魯棒性曲線(CRC)
除以上指標外,許多研究通過繪制曲線圖,表達了多種指標在一定范圍內變化時模型分類器的不同響應,更加直觀地展示了對抗魯棒性評估的結果.如Dong等人[42]采用2條互補魯棒性曲線(comple-mentary robustness curves,CRC),展示了受到對抗攻擊的深度學習模型的魯棒性.互補魯棒性曲線如圖4所示.
圖4(a)是“擾動-準確率”曲線,Dong等人[42]通過計算所有擾動下的分類準確率繪制而成,橫坐標是擾動大小,縱坐標是分類準確率.他們選取基于自然進化策略(natural evolution strategy, NES)的梯度估計算法作為攻擊算法,Res-56(Resnet-56)模型等作為被攻擊的模型.通過圖4(a),我們可從全局視角對比8種模型抵御NES攻擊的魯棒性.如使用NES算法攻擊TRADES和Convex模型,相同擾動下TRADES模型的準確率始終比Convex模型高,在一定程度上說明TRADES模型抵御NES攻擊的魯棒性更好.圖4(b)是“查詢次數-準確率”曲線,橫坐標是模型查詢次數,縱坐標是分類準確率.其中,模型查詢次數亦可替換成不同攻擊方法的迭代次數.該曲線能夠顯示攻擊的效率,例如盡管查詢次數為20 000時,Res-56與DeepDefense模型的分類準確率都下降到0,但是Res-56模型受攻擊后分類準確率下降得更慢、曲線更靠右,說明Res-56模型抵御NES攻擊的能力更強.
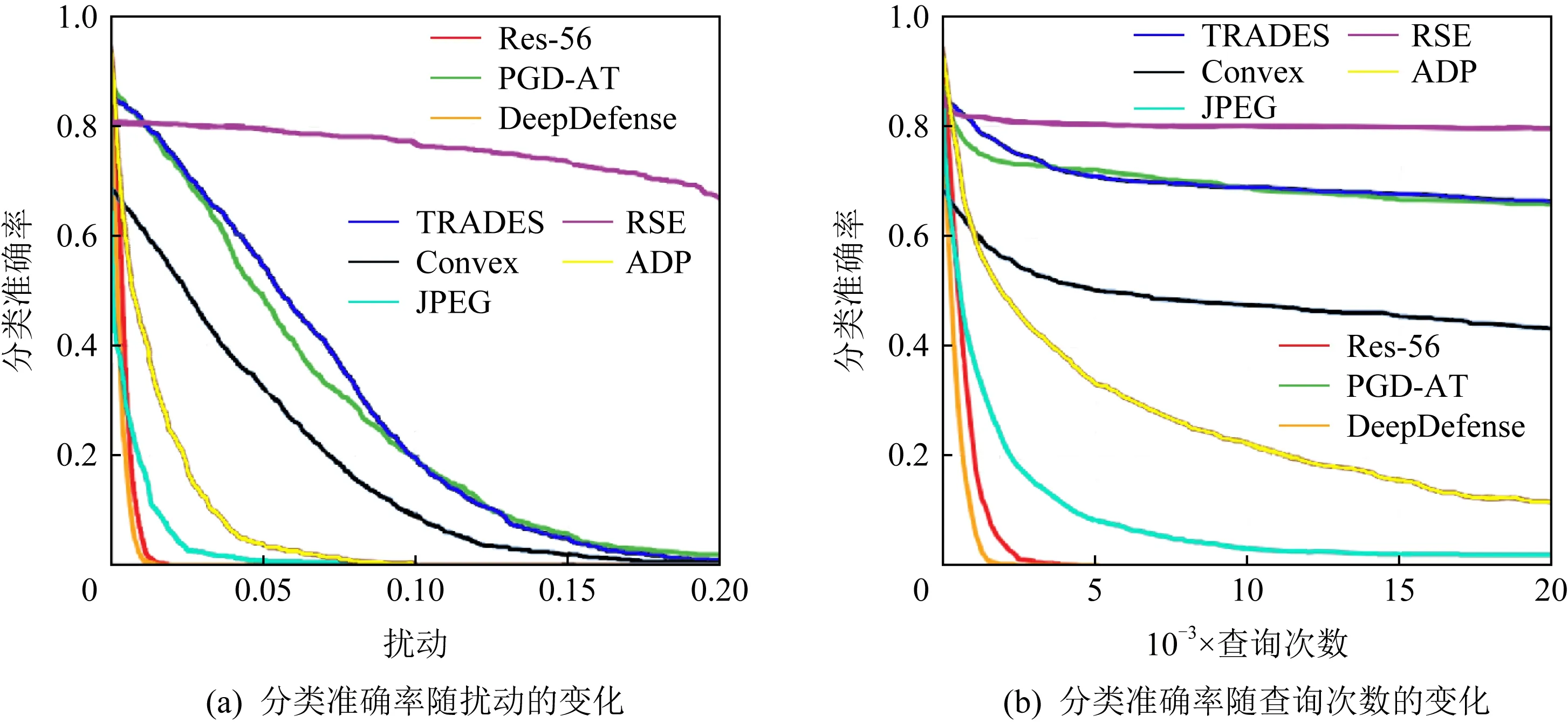
Fig.4 Complementary robustness curves[42]
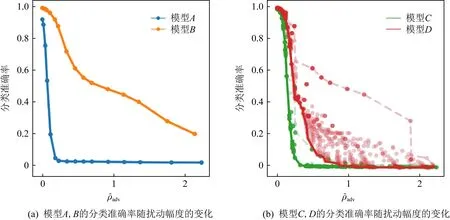
Fig.5 Accuracy-perturbation curves[43]
⑩ 精確擾動曲線(APC)
相比于互補魯棒性曲線(CRC),ircelj等人[43]提出的精確擾動曲線(accuracy-perturbation curves,APC)優勢在于展示了被攻擊模型受不同擾動影響的最差性能.首先組合各種超參數,生成添加了不同大小擾動的對抗樣本,并計算不同模型對它們的分類精度;其次根據式(11)計算這些對抗樣本的子集(它們的原始圖像已被模型正確分類)添加的擾動大小;最后將每組擾動幅度和分類精度繪制為“擾動-準確率”曲線,如圖5所示:
(11)
圖5(a)橫坐標為擾動大小,縱坐標為分類準確率.顯然,曲線B對應模型的對抗魯棒性更強.然而,在使用多參數組合的方法時通常得到分散的“擾動-準確率”點,這為評估對抗魯棒性的強弱帶來了困難.為此,ircelj等人[43]進一步設計了一種最小包絡法(minimum wrap),將每個擾動對應的最小準確率的點連接成線,如圖5(b)中的曲線C和曲線D,這2條曲線體現了對抗樣本在2種模型上分類的最壞情況估計.通過對比發現,相比于模型C,模型D的對抗魯棒性更強.
上述CRC和APC這2種評估指標通過繪制“擾動-準確率”曲線,定性給出模型的評估結果.Wu等人[44]提出了一種分段采樣曲線(piece-wise sampling curves,PSC)框架,如圖6所示.該框架通過曲線下面積(area under curve,AUC)[45]實現了測量結果的可量化,避免了人為比較帶來的主觀偏差,同時盡可能多地適用于不同攻擊方法.
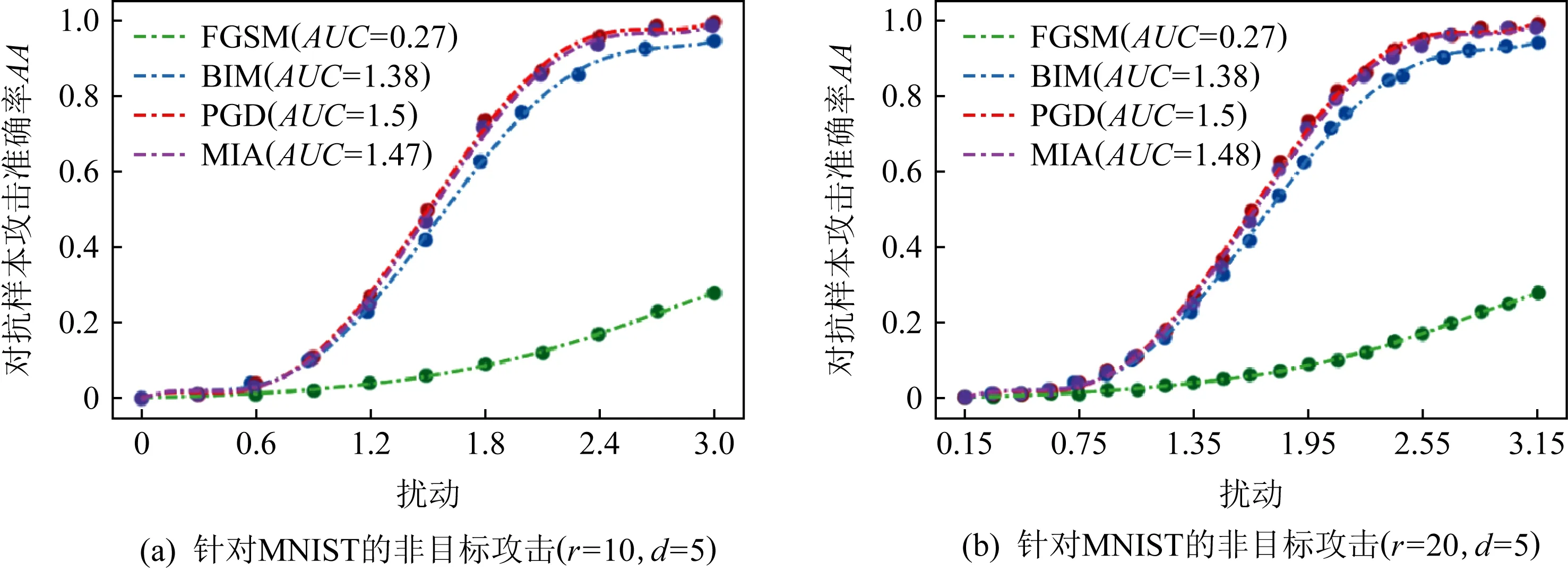
Fig.6 Piece-wise sampling curves[44]
PSC框架包括3個步驟,分別是選擇擾動范數lp、劃分擾動范圍與繪制分段采樣曲線.以圖6為例,Wu等人首先確定擾動范圍ε=[0,3],將分辨率r分別設為10和20(將擾動范圍劃分成r段);而后對范圍內r個分段采樣擾動點上的對抗樣本進行測試,獲得該擾動下的攻擊準確率,通過調整參數多次實驗,獲得r個擾動點上的最佳攻擊準確率;最后根據選擇的擬合函數階數d=5,將采樣點進行擬合,得到最終的5階分段采樣曲線.圖6(a)使用4種非目標攻擊算法攻擊一個4層卷積神經網絡在MNIST數據集上訓練的模型,FGSM算法對應的AUC最小,說明隨著擾動的增大,FGSM攻擊準確率提升的速率最慢,模型抵御FGSM攻擊的能力最好.圖6(b)對擾動范圍進行了更細致的劃分,更加準確地描述了模型在不同攻擊下的性能,但同時也會花費更多的計算資源.
此外,Wu等人[44]構建了PSC工具包,用戶只需在特定設置下上傳添加不同擾動時模型的分類準確率結果,就能生成對應的分段采樣曲線.與使用單個或多個擾動點進行評估的方式相比,該方法可以量化對抗魯棒性的強弱.
2)基于模型結構的指標
與基于模型行為的指標不同的是,這一類指標關注模型內部神經元、損失函數等與模型結構相關的信息,觀察模型內部對于對抗樣本的反應,進而衡量模型的對抗魯棒性.
① 神經元敏感度(NS)
對抗魯棒性意味著模型對對抗樣本保持一定的鈍感,盡管受到擾動的影響,原始樣本和對抗樣本在模型的隱藏層中仍具有相似的表示,從而輸出正確的分類結果.因此,一些研究人員嘗試通過計算原始樣本與對抗樣本在隱藏層中特征表示的偏差,衡量模型的對抗魯棒性.
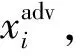
(12)
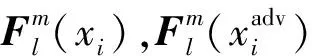
② 神經元不確定性(NU)
在關鍵安全應用領域,模型預測的不確定性被廣泛研究.陳思宏等人[47]研究發現預測不確定性越大,模型對抗魯棒性越強,通過增加模型預測的不確定性,以達到提高對抗魯棒性的目的.預測結果的方差是衡量不確定性最直觀的方法.
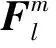
(13)
其中,variance(·)是方差計算函數.NU值越大,模型的對抗魯棒性越強.
③ 沖突上下限(ΔK)
Dempster-Shafer證據理論常被用來處理不確定信息,輔助完成智能決策任務.蘇記柱[48]對CNN模型進行重構,結合證據推理方法,分析信息沖突值隨擾動強度的變化關系,提出了2個對抗魯棒性評估指標:沖突上限Δkmax和沖突下限Δkmin,計算公式分別為
(14)
(15)
其中,k0={k01,k02,…,k0N}為每個樣本特征之間的沖突值,kmax={kN1,kN2,…,kNN}表示在FGSM攻擊下,當樣本逐漸添加擾動至被模型誤分類時,每個樣本特征之間的沖突值,Δkmax為模型可接受的樣本特征之間沖突的最大變化范圍.Δkmax越大,表示模型的魯棒性越強,反之,模型的魯棒性越差.kmin={kmin1,kmin2,…,kminN}為每個樣本所產生的對抗樣本中最小的沖突值.Δkmin越大表明模型越魯棒.
不難發現,沖突上限是沖突下限的特殊情況.沖突上限限制了攻擊方法和擾動強度大小,沖突下限適應的場景更加寬泛.
④ 經驗邊界距離(EBD)
Liu等人[49]以模型的決策邊界為切入點,對輸入樣本周圍鄰域進行全面分析,提出經驗邊界距離(empirical boundary distance,EBD)指標.該指標為所有樣本決策邊界距離的平均值,計算公式如下:
(16)
εvik=minRMS(vik),
(17)
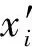
該指標計算了模型對不同方向輸入擾動的樣本的分類置信度,并以此作為估計樣本到決策邊界距離的標準,從模型結構的角度挖掘了模型決策區域的信息,為魯棒性評估提供了一種新的思路.
⑤ 經驗邊界距離(EBD-2)
在EBD的基礎上,Liu等人[39]又進一步提出了EBD-2評估指標,該指標的優勢在于可以計算所有類別的決策邊界的最小距離:
(18)
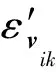
⑥ CLEVER score
Weng等人[50]發現,使用最小對抗擾動距離的上界或下界去估計模型的對抗魯棒性時,距離下界與局部梯度的最大范數相關,故將魯棒性評估問題轉化為局部Lipschitz常數估計問題.
為了有效、可靠地估計局部Lipschitz常數,Weng等人提出了一種稱為CLEVER的魯棒性度量指標,利用極值理論[51]去估計最小對抗擾動距離下邊界,并給出了相應的數學證明.該指標的優勢在于獨立于攻擊進行魯棒性度量,適用于任何模型.CLEVER數值越大,模型的對抗魯棒性越強.
⑦ 二階CLEVER score
在CLEVER的基礎上,Weng等人[52]進一步提出二階CLEVER,將CLEVER擴展為能夠評估具有不可微分輸入轉換的網絡的魯棒性,使其可評估部署了多種基于梯度掩蔽的模型.
⑧ CROWN框架
通過尋找最小對抗擾動距離下界去估計模型的對抗魯棒性,存在計算耗時、估計誤差大等問題.為此,Weng等人[53]利用ReLU網絡進一步提出Fast-Lin和Fast-Lip算法,計算出較高精度的距離下界,用以評估模型的對抗魯棒性.同時,相比于基于線性規劃的方法和Reluplex[33]方法,Fast-Lin和Fast-Lip計算速度要快2~4個數量級.盡管Fast-Lin和Fast-Lip能夠以高精度估計對抗邊界,但是仍有一些模型需要ReLU以外的函數激活,例如RNN和LSTM等.
為解決激活函數受限的問題,Zhang等人[54]提出了適用于具有一般激活函數的模型的魯棒性評估框架CROWN,該框架允許靈活地選擇激活函數的上界或下界,從而減小評估對抗魯棒性時難以避免的近似誤差.實驗表明,與文獻[53]相比,CROWN的認證下界提高了26%,并且可以將CROWN擴展到具有各種激活函數的大型神經網絡中.此外,對于具有超過10 000個神經元的模型,可以在大約1 min內利用1個CPU內核求出魯棒性下界.
⑨ 經驗噪聲不敏感度(ENI)
Xu等人[55]率先提出算法魯棒性的概念,這一概念的提出受益于2個相似樣本的測試誤差往往非常接近的思想.受此啟發,Liu等人[49]從Lipschitz常數的角度,提出了ε經驗噪聲不敏感度(ε-empirical noise insensitivity,ENI).具體而言,將原始樣本和對抗樣本輸入模型,計算模型損失函數之間的差異,以損失值大小來衡量模型對約束ε的廣義噪聲的不敏感性和穩定性:
ENIf(ε)=
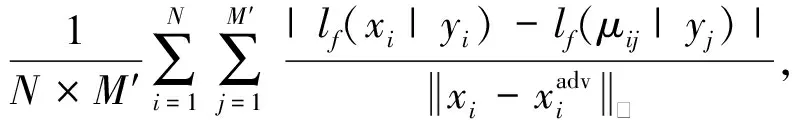
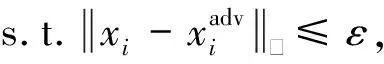
(19)
其中,M′是使用各種攻擊算法依次生成對抗樣本的數量,lf(·|·)表示模型f的損失函數.ENI能夠衡量模型對包括對抗擾動在內的廣義噪聲的魯棒性.ENI值越小,說明模型的對抗魯棒性越強.
與基于模型行為的指標相比,以上9種指標的優勢在于能夠刻畫圖像分類過程中模型的內部特性,挖掘更多關于模型結構的隱性知識,從模型本身而非直接的模型結果的角度評估對抗魯棒性.
2.3.2 面向數據的指標
在進行對抗魯棒性評估時,應從圖像分類全過程出發,分析各階段影響評估結果的因素,進而實現全面、科學且準確的評估.然而,由于習慣上過度關注于智能系統的高精度性能結果,研究者常常忽略了測試過程是否充分以及測試數據質量的好壞帶來的影響.因此,在進行對抗魯棒性評估時,同樣需要關注模型測試的充分性以及測試數據的質量.考慮到對抗樣本的特點,即測試數據的質量與圖像的不可感知性相關,本文將面向數據的指標進一步劃分為基于測試充分性的指標和基于視覺不可感知性的指標.
1)基于測試充分性的指標
測試充分性[56]這一概念最早是在軟件工程領域提出的,它是指使用一組有代表性的數據對軟件進行全面測試的程度.Pei等人[57]將其類比到模型測試中,提出了一種神經元覆蓋率(neuron coverage,NCov)指標來量化神經元被激活的比例.
(20)
其中,T′為測試集,x為測試樣本,N總為神經元總數,out(ne,x)指的是給定一測試樣本返回模型中神經元ne的輸出值,t為設定的閾值,當輸出值大于閾值時神經元被激活.然而,Ma等人[58]經實驗發現,NCov無法體現測試集中原始樣本和對抗樣本之間的差異.為此,他們提出了多層次多粒度覆蓋的一系列測試標準DeepGauge,使用k節神經元覆蓋率(k-multisection neuron coverage,kMNCov)、神經元邊界覆蓋率(neuron boundary coverage,NBCov)、強神經元激活覆蓋率(strong neuron activation cov-erage,SNACov)這3種指標來衡量對抗環境下模型測試的充分程度.
①k節神經元覆蓋率(kMNCov)
為體現原始樣本和對抗樣本的差異,Ma等人將進行測試時神經元輸出范圍劃分為主要功能區和極端案例區.當測試樣本與原始樣本分布相近時,神經元輸出值落入主要功能區[lown,highn],否則落入極端案例區(-∞,lown)∪(highn,-∞),也就是對應對抗樣本所在的區域.將區域[lown,highn]劃分成k個長度相等的節段,kMNCov為測試集T覆蓋的節數與總節數之比,用以衡量覆蓋主要功能區程度,數學公式描述為
(21)
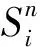
② 神經元邊界覆蓋率(NBCov)
神經元邊界覆蓋率NBCov是測量給定測試集T′覆蓋極端案例區面積大小的指標,定義為極端案例區被覆蓋的神經元數量與神經元總數的比率:
NBCov=
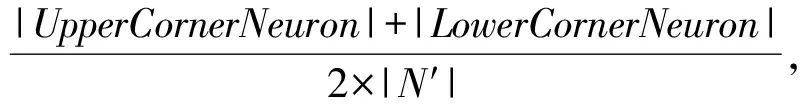
(22)
其中,UpperCornerNeuron是極端案例區上邊界神經元被覆蓋的數量,LowerCornerNeuron是極端案例區下邊界神經元被覆蓋的數量,N′表示上、下邊界神經元數.NBCov值越大,說明極端案例區被覆蓋的部分越多,對抗樣本在模型中的測試效果越充分.
③ 強神經元激活覆蓋率(SNACov)
在研究DNN可解釋性問題時,過度活躍的神經元可能有助于DNN模型的學習.因此,Ma等人[58]又提出了側重于活躍神經元的測試指標,即描述極端案例區上邊界情況的指標SNACov.它被用來測量測試集T′在極端案例區中上邊界被覆蓋的情況,描述為覆蓋的極端案例上邊界神經元數與總神經元數之比:
(23)
值得注意的是,提高測試充分性并不能有效改善模型的對抗魯棒性[59-60],但是測試越充分說明評估結果的可信度越高.因此,在進行對抗魯棒性評估時,可以考慮通過①~③指標來檢驗結果的可信度或準確性.
2)基于視覺不可感知性的指標
相比于原始樣本,對抗樣本最鮮明的特點是添加了肉眼難以感知的擾動.如果添加的擾動太大導致樣本過于模糊不清,肉眼即可判別出樣本為對抗樣本,便失去了評估對抗魯棒性的意義.本節總結了多種指標來刻畫擾動的不可感知性.
① 平均lp失真度(ALDp)
目前大多數研究采用lp范數(p=0,1,…,∞)來衡量原始樣本與對抗樣本之間的擾動距離,Liu等人[39]提出將ALDp作為擾動不可感知性的度量指標.從數學含義上講,該指標是lp失真度的平均歸一化:
(24)
其中,N表示樣本的數量.ALDp越小,失真越小,對抗擾動越小,肉眼區分原始樣本和對抗樣本的難度越大.
② 平均結構相似度(ASS)
在實踐中,通常需要對整個圖像進行單一的整體質量測量,Wang等人[61]提出的結構相似度(structural similarity,SSIM)就是評估圖像整體質量的指標.針對對抗環境下的評估問題,平均結構相似度(average structural similarity,ASS)[39]是在SSIM的基礎上進行改進,被用來描述原始樣本與對抗樣本之間的結構相似度.
(25)
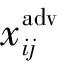
③ 擾動敏感度(PSD)
基于對比掩蔽理論[62-64],Liu等人[39]提出了擾動敏感度(perturbation sensitivity distance,PSD)指標來評估人類對擾動的感知.因此,PSD定義為
(26)
Sen(xij)=1/SD(xij),
(27)
(28)
其中,M是像素總數,δij是第i個樣本的第j個像素,xij表示周圍正方形區域,Si是由n×n區域中的像素組成的集合,μ是區域內像素的平均值.當像素具有低方差時,擾動靈敏度高.PSD越大,添加于對抗樣本中的擾動越容易被察覺.
還有學者從特征數據的角度挖掘樣本特征差異與魯棒性的相關性.董一帆[65]認為模型對原始樣本和對抗樣本進行特征提取后,兩者的特征子集差距越小,說明模型的對抗魯棒性越強.因此,引入特征子集一致性[66]指標來衡量模型的對抗魯棒性,計算公式為
(29)
其中,A和B分別為2個子集,X為特征總空間,w為特征總數,令|A|=|B|=k,0
除以上指標外,還有許多與常規圖像處理相關的評估指標,如高斯模糊魯棒性(robustness to Gaussian blur,RGB)[40]、圖像壓縮魯棒性(robustness to image compression,RIC)[40],以及與腐蝕擾動相關的評估指標,如自然噪聲平均差值(mCE)、自然噪聲相對差值(RmCE)和連續噪聲分類差別(mFR)[49,67]等.從某種意義上來說,以上這些指標的確可以衡量模型的對抗魯棒性.例如,Corrupt算法[39]中添加的擾動是自然噪聲,可以根據(RmCE)的大小來衡量對抗擾動的距離.但是對于大多數對抗攻擊算法,這些指標更多地是衡量其他特定環境下的魯棒性,并非嚴格的對抗魯棒性.因此,在進行指標評估時,應針對特定的需求選取合適的指標.
本文按照指標類別、攻擊方式和擾動類別等維度,對以上30余種評估指標進行詳細的描述,如表2所示.考慮到實際應用過程中往往僅選取部分指標進行評估,根據指標的含義,給出了每一種指標和對抗特性的相關度,并將相關度劃分為4個等級,使用不同數量的“★”進行表示.“★”的數量越多,說明指標與對抗特性越相關.其中,“★”表示雖然指標無法評估對抗魯棒性,但在進行評估時需要通過這些指標進行測試,以保證評估結果的有效性;“★★”表示指標和對抗樣本相關,常被用于評估對抗樣本或衡量對抗擾動以外的其他擾動(自然噪聲、墮化擾動等),能夠反映模型的魯棒性,而并非嚴格意義上的對抗魯棒性;“★★★”表示指標與對抗特性較為相關,但由于評估視角單一、片面,往往需要結合多種指標綜合給出評估結果;“★★★★”表示能夠從全局角度或基于模型內部機理評估模型的對抗魯棒性,指標的大小在一定程度上反映了對抗魯棒性的強弱.
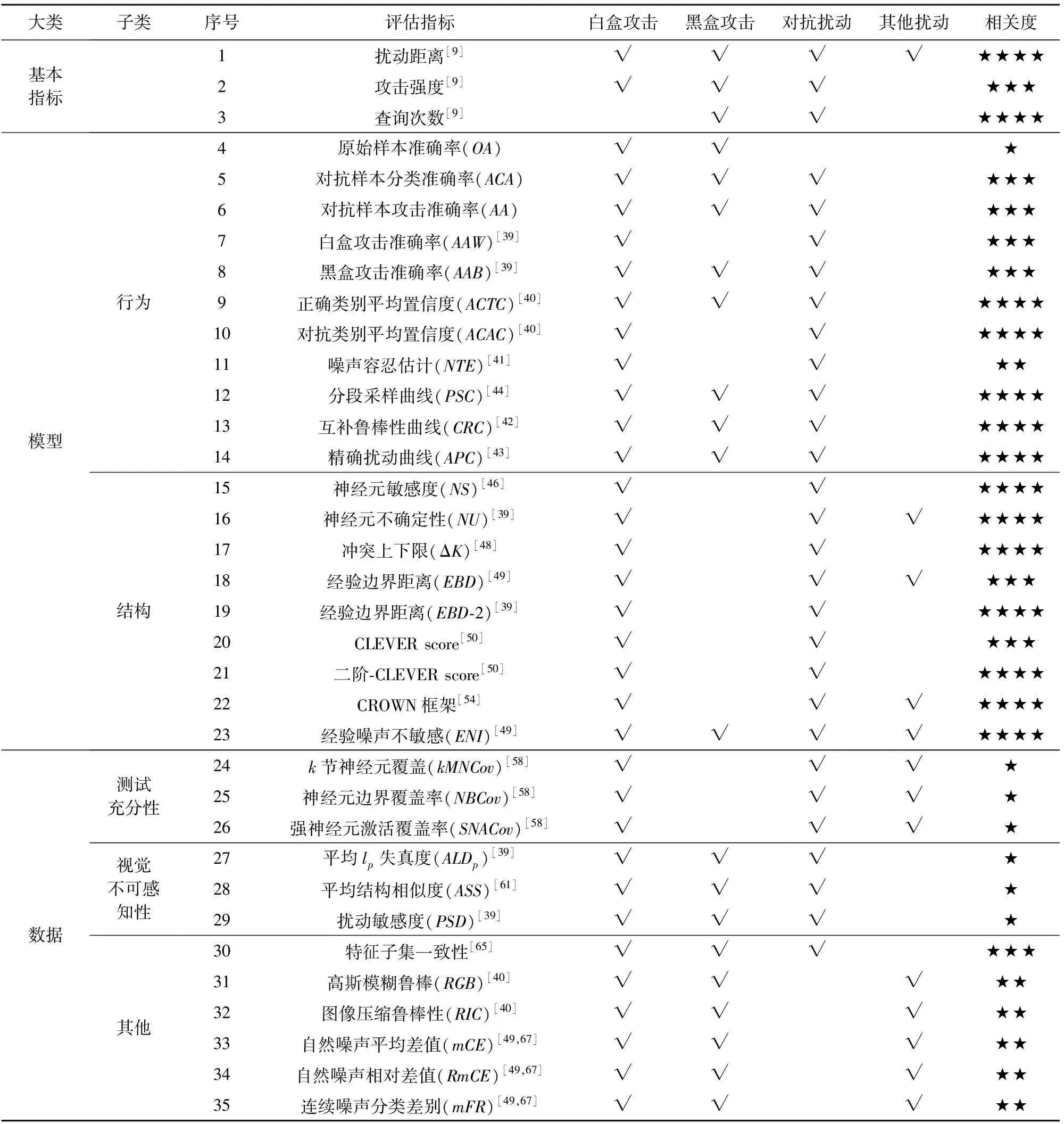
Table 2 Evaluation Indexes of Adversarial Robustness
顯然,3種基本指標以及面向模型的指標與對抗魯棒性評估的相關程度較高,而面向數據的指標的相關程度普遍較低,這與對抗魯棒性評估的本質有關.深度學習模型的黑盒特性與不可解釋性[68]為對抗魯棒性的評估帶來了困難,挖掘更多模型內在的信息有助于了解對抗環境下模型面對不確定干擾因素的反應.因此,進行對抗魯棒性評估可以采用OA,ACTC,PSC,EBD等面向模型的指標,同時也要結合實際需求,考慮是否將面向數據的指標納入評估范圍內.
3 對抗攻防工具與數據集
近年來,對抗攻防研究發展迅速,相應算法層出不窮.自2016年始,許多研究單位推出了集成眾多主流算法的對抗攻防工具,以提高研究者與開發人員的測評效率,助力推動智能系統安全領域的發展.此外,在使用對抗攻防工具進行實驗的過程中,各學者還應用了多種不同的數據集.本節將介紹主流的數據集與對抗攻防集成平臺,方便后續開展對抗魯棒性評估研究.
3.1 常用數據集
目前,針對不同領域、不同應用場景的圖像數據集層出不窮,本文選取圖像分類領域較為經典的、被廣泛使用的6種數據集進行介紹,具體信息如表3所示:
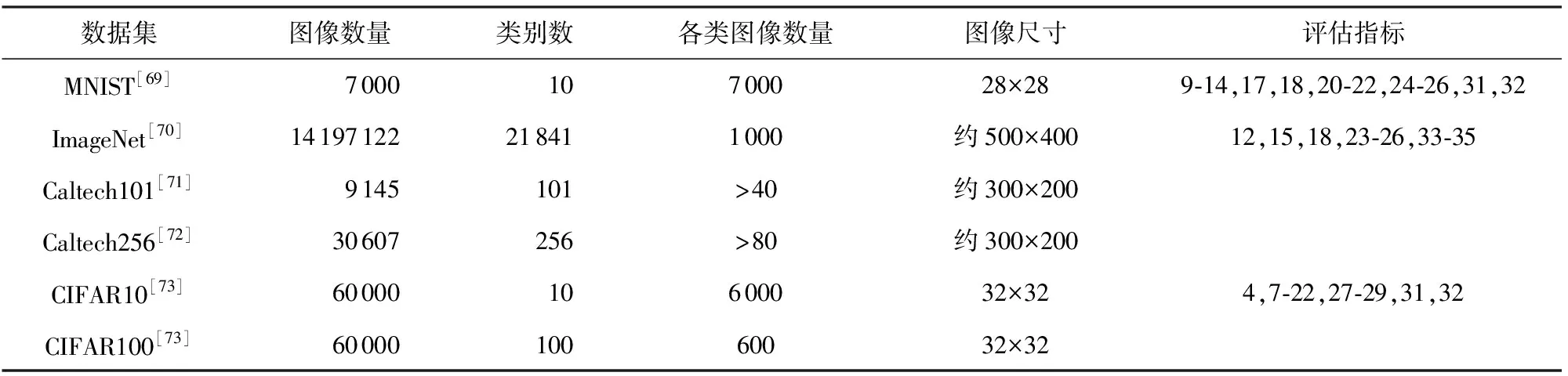
Table 3 Common Image Classification Data Sets
1)MNIST
MNIST數據集[69]是圖像分類領域常用的數據集之一.該數據集由美國國家標準與技術研究所(National Institute of Standards and Technology)組織整理,收集了來自250個人的0~9手寫數字圖片.該數據集總計70 000組圖片數據,具體包括訓練集圖片60 000張及對應標簽60 000個、測試集圖片10 000張及對應標簽10 000個,每張圖片像素大小為28×28.共有16種指標在該數據集上開展對抗魯棒性評估.
2)ImageNet
ImageNet數據集[70]于2007年開始收集,直到2009年以論文形式發布,后續被Kaggle公司繼續維護,是世界上圖像分類、識別、定位領域最大的數據庫.截至目前,ImageNet數據集總共有14 197 122張圖像,涵蓋21 841個類別.使用率最高的子集是ImageNet大規模視覺識別挑戰賽(ILSVRC)2012—2017圖像分類和定位數據集.該數據集跨越1 000個對象類,包含1 281 167個訓練圖像、50 000個驗證圖像和100 000個測試圖像,每張圖片像素大小約為500×400.共有10種指標在該數據集上開展對抗魯棒性評估.
3)Caltech101/256
Caltech101數據集[71]是加利福尼亞理工學院收集整理的數據集,由9 146張圖像組成.每張圖像都標有1個對象,包含101個類別對象以及1個額外的背景雜波類別.每個類約40~800張圖像,大多數類別有大約50張圖像,每張圖片像素大小約為300×200.Caltech256數據集[72]在2006年被發布,包括256類目標圖像和1類背景圖像,共257類.與Caltech101相比主要變化表現在:圖像總數達到30 608張,且每類最少含有80幅圖像,最多含有827幅圖像,目前暫無相關研究基于此數據集開展對抗魯棒性評估.
4)CIFAR10/100
CIFAR10數據集[73]是由Hinton的學生Alex Krizhevsky和Ilya Sutskever整理的一個用于識別普適物體的小型數據集.該數據集由10個類別的60 000個像素為32×32彩色圖像組成,每個類別包含6 000個圖像,其中有50 000個訓練樣本和10 000個測試樣本.CIFAR100數據集與CIFAR10數據集類似,不同的是CIFAR100數據集具有100個類別,每類包含600張圖像,其中訓練樣本500個,測試樣本100個.CIFAR100數據集[73]中的100個類分為20個超類,每張圖像都帶有一個“精細”標簽(它所屬的類)和一個“粗略”標簽(它所屬的超類),共有22種指標在CIFAR10上開展評估.
綜上所述,在面向圖像分類的對抗魯棒性評估研究中,使用最多的數據集有CIFAR10,MNIST和ImageNet.為便于進行評估結果的對比,研究人員可使用以上3種數據集開展對抗魯棒性評估實驗.
3.2 對抗攻防集成工具
對抗攻防集成工具實現了將攻防算法模塊化,為攻防對抗實驗提供了可組合、可操作、可更新的框架.為方便研究者快速了解各種工具并使用,現總結國內外主流的對抗攻防工具內嵌的攻防算法以及適用框架等信息,如表4所示.考慮到篇幅長度,我們將每一種工具的具體細節整理到附錄表A2~A10.

Table 4 Mainstream Adversarial Attack and Defense Integration Tools
1)CleverHans(1)https://github.com/cleverhans-lab/cleverhans
CleverHans[74-75]是最早被提出的機器學習模型攻防庫,它集成了16種攻擊算法和1種防御算法.基于該庫,研究人員可以快速研發更強的對抗攻擊與防御算法,實現模型的對抗訓練以及魯棒性基準測試.在最初版本v0.1中CleverHans僅支持Tensor-Flow1[82],部分模型可支持Keras[83],從v4.0.0開始,CleverHans支持的框架分別有JAX,TensorFlow2和PyTorch[84].
2)Foolbox(2)https://github.com/bethgelab/foolbox
Foolbox[76]是一種Python工具箱,用于生成對抗擾動并量化和比較機器學習模型的魯棒性.Foolbox v0.8.0提供了48種對抗攻擊算法,所有攻擊算法都能夠通過調整內部超參數生成最小的對抗擾動.此外,針對大多數攻擊算法適用于特定的深度學習框架,Foolbox v0.8.0允許在諸多機器學習框架上運行,如PyTorch,Keras,TensorFlow,Theano[85],Lasagne和MXNet[86],引入原始樣本誤分類準確率、正確類別分類置信度、對抗類別分類置信度等對抗魯棒性評估指標,同時支持自定義評估指標.目前,Foolbox更新到3.0版本,它現在建立在EagerPy之上,并對PyTorch,TensorFlow,JAX框架提供支持.
3)ART(3)https://github.com/Trusted-AI/adversarial-robustness-toolbox
對抗性魯棒性工具集(adversarial robustness toolbox, ART)[77]是用于機器學習安全性的Python庫.ART提供的工具使開發人員和研究人員能夠防御和評估機器學習模型和應用程序,以抵御逃避、中毒、提取和推理等對抗性威脅.ART支持許多流行的機器學習框架(TensorFlow,Keras,PyTorch,Scikit-learn[87],MXNet,XGBoost[88],LightGBM[89],CatBoost[90],GPy等9種框架)、多種數據類型(圖像、表格、音頻、視頻等)和機器學習任務(分類物體檢測、語音識別、生成模型、認證等).截止目前,ART集成了近40種攻擊算法、30多種防御算法以及包括CLEVER score在內的6種對抗魯棒性評估指標.
4)DEEPSEC(4)https://github.com/ryderling/DEEPSEC
DEEPSEC[40]是同時具有對攻擊和防御算法進行比較研究、驗證各種攻擊和防御有效性以及評估機器學習模型魯棒性等功能的平臺.它全面、系統地集成了各種對抗攻擊、防御算法和相關評估指標,其中攻擊算法有16種,防御算法有13種以及評估指標有15種.用戶可在平臺上使用MNIST和CIFAR10數據集訓練DenseNet[91],AlexNet[86],ResNet56[92]等模型,但是該平臺僅支持PyTorch.
5)AdverTorch(5)https://github.com/BorealisAI/advertorch
AdverTorch[78]是用于對抗性魯棒性研究的Python工具箱,包含21種攻擊算法和7種防御算法模塊,以及用于對抗性訓練的腳本.AdverTorch構建在PyTorch上,可利用動態計算圖的優勢實現簡潔有效的攻防測試.
6)Ares(6)https://github.com/thu-ml/ares
Ares[42]是一個專注于對對抗魯棒性進行基準測試的Python庫.基于Ares算法平臺,RealAI等后繼推出基于深度學習模型的對抗攻防基準平臺adversarial robustness benchmark,此基準平臺可以更加公平、全面地衡量不同攻防算法的效果,提供簡單高效的魯棒性測試工具.同樣,該平臺對主流的攻防算法實現了模塊化的設計,支持數十種主流攻防算法的實現.
7)AdvBox(7)https://github.com/advboxes/AdvBox
AdvBox[79]是由百度開源的一系列AI模型安全工具集,可以在PaddlePaddle[93],PyTorch,Caffe2[94],MXNet,Keras,TensorFlow中生成欺騙神經網絡的對抗樣本,也可以對機器學習模型的魯棒性進行基準測試.與之前的工作相比,該平臺不僅支持對抗樣本的生成、檢測和保護,還適用于許多攻擊場景,例如人臉識別攻擊、真假人臉檢測和“隱形T 恤”.
8)DeepRobust(8)https://github.com/DSE-MSU/DeepRobust
DeepRobust[80]與以上平臺工具不同,它是適用于圖像領域和圖領域的對抗性學習庫.目前Deep-Robust包含圖像領域的10種攻擊算法和8種防御算法以及圖域的9種攻擊算法和6種防御算法,具體實驗在Pytorch上實現.
9)AISafety(9)https://git.openi.org.cn/OpenI/AISafety
AISafety[39]是一個用于對抗攻擊全流程評測算法學習研究的Python庫,其主要研究內容為集成對抗攻擊和噪聲攻擊相關的攻擊算法、評測算法和加固防御算法.該平臺可靈活測試數據集質量、算法訓練、評估和部署等算法各項指標.目前AISafety已集成的數據集有CIFAR10,ImageNet數據集,針對CIFAR10數據集集成了ResNet20[95],FP_ResNet[96],VGG16[97]測試模型,針對ImageNet數據集有VGG19模型.此外,用戶可按照模型擴展要求,實現并上傳自定義模型.
10)RobustBench(10)https://github.com/RobustBench/robustbench
RobustBench[81]是一個圖像分類領域評估攻防算法魯棒性的基準平臺,由圖賓根大學的團隊發布.除了標準化的測試基準之外,RobustBench還提供了最龐大模型的存儲庫,其中包含120多個模型.
通過統計谷歌學術中以上10種工具所對應文獻的引用次數及占比發現(11)本文將對抗攻防工具所對應文獻的引用次數作為該領域研究人員或學習者使用這10種對抗攻防工具開展評估的次數,進而分析出最受業界歡迎與認可的3種對抗攻防工具.,目前最常用的3種對抗攻防集成工具是Foolbox,CleverHans和ART,如圖7所示.研究人員可參考上述結論,結合實際需求,選擇合適的對抗魯棒性評估工具.
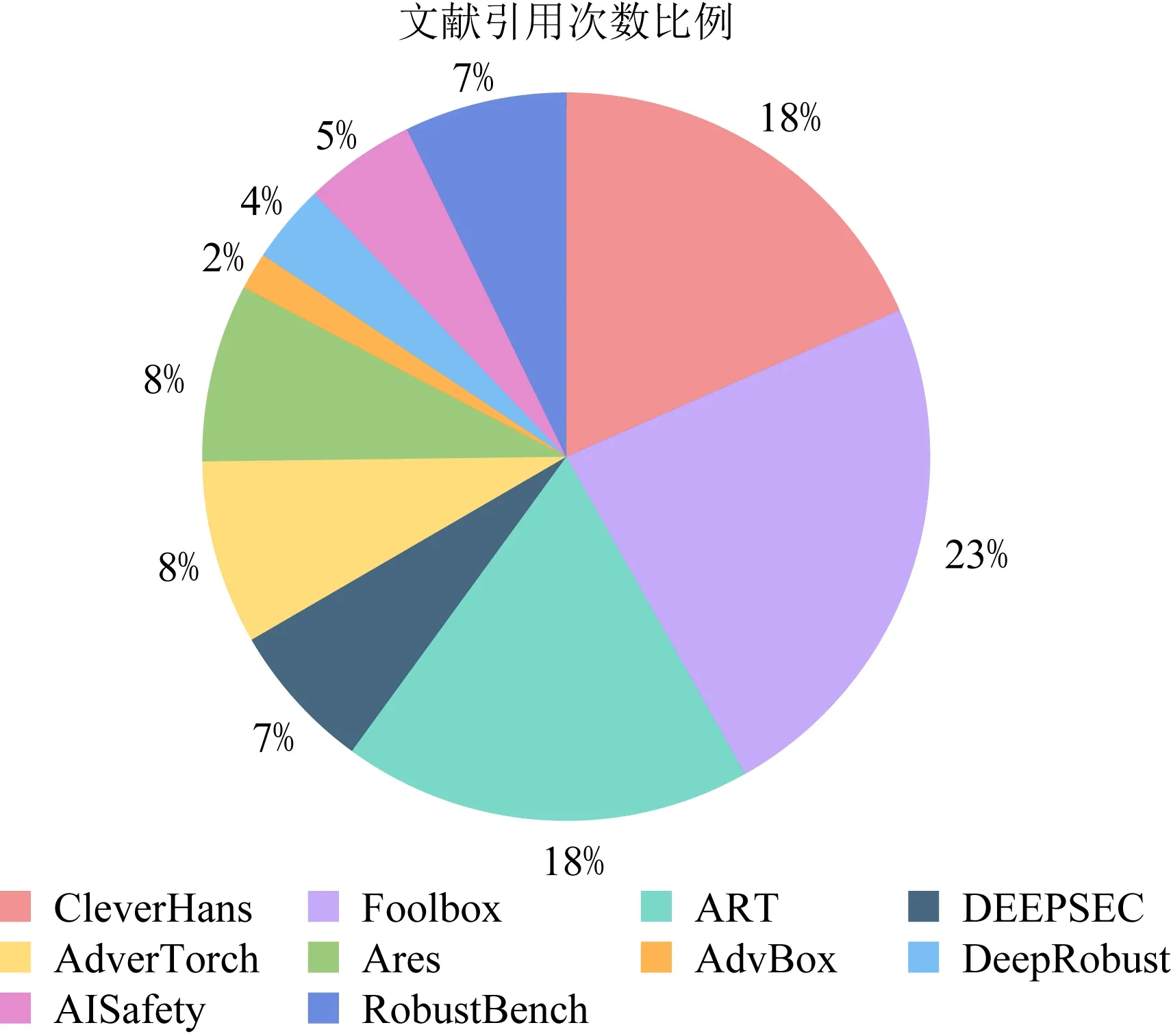
Fig.7 Proportion of citation times of 10 tools
4 未來研究方向
對抗攻擊技術近年來獲得了業界內的廣泛關注,取得了許多突破性進展,但關于對抗魯棒性評估的研究仍處于起步階段,依然面臨許多的挑戰.基于本文對對抗魯棒性評估研究現狀的深入分析,未來該領域的研究需要重點關注4個方向:
1)深入開展對抗樣本存在機理、深度學習模型脆弱性和可解釋性等理論研究.目前國內外學術界關于對抗樣本的存在原因尚未達成共識,缺乏完備的數學理論支撐,對于如何正確解釋深度學習模型的內在邏輯與擾動下的決策行為尚在探索當中.這些難題與對抗魯棒性的評估有著緊密關聯,開展相關理論研究有助于理解對抗魯棒性評估問題的本質,把握影響模型對抗魯棒性的關鍵因素,能從根本上解決對抗環境下模型魯棒性的評估問題,是未來對抗魯棒性評估問題在理論層面上值得研究的方向之一.
2)提出一種或一組通用的、可量化的、綜合的對抗魯棒性評估指標.無論是面向數據的指標還是面向模型的指標,分析視角單一,給出的評估結果很難被直接采納.此外,影響模型對抗魯棒性的因素眾多,采用一種或幾種指標難以準確、完整地評估對抗魯棒性的強弱.參考其他研究領域指標評估的方法,梳理影響對抗魯棒性的全部因素,抓住關鍵要素,提出一種或一組通用的、可量化的、綜合的指標,全面評估模型的對抗魯棒性,是未來對抗魯棒性評估問題在方法層面上值得研究的方向之一.
3)構建科學、統一、規范、完備的對抗魯棒性評估框架.面向圖像分類的數據集種類繁多,攻擊方法不斷被創新,評估指標與評估方法不盡相同,盡管對抗攻防集成工具涵蓋多種攻防算法,但也無法保證進行對抗魯棒性評估的實驗條件和度量標準是一致的,這為模型與模型之間、模型防御前后對抗魯棒性的比較帶來了困難.搭建對抗魯棒性評估框架,全面綜合各種攻防算法、數據集與評估指標,在標準對抗環境下從多層次、細粒度分析圖像分類全過程模型抵御對抗攻擊的能力,是未來對抗魯棒性評估問題在流程層面上值得研究的方向之一.
4)重點研究黑盒、非目標的融合攻擊環境下的對抗魯棒性評估方法.物理場景中難以獲取模型的全部信息,針對白盒、目標攻擊的評估方法難以應用于實際智能系統模型的對抗魯棒性評估任務,且由于目前黑盒、非目標攻擊的性能遠低于人們的預期,無法保證使用該攻擊進行評估的效果.更重要的是,現實環境中攻擊者可能融合對抗擾動、自然噪聲等多種類型干擾或多種攻擊方法開展對抗攻擊,亦或利用智能系統在動態環境下依據時間、空間等信息進行決策的漏洞,設計融合多元信息干擾的對抗攻擊方法,這給對抗魯棒性評估帶來了新的契機與挑戰.如何評估模型在黑盒、非目標的融合攻擊環境下的對抗魯棒性,是未來對抗魯棒性評估問題在實際應用層面上值得研究的方向之一.
5 總 結
面對對抗攻擊等各種威脅,增強模型的對抗魯棒性是保障智能系統安全的重要方式和手段.評估對抗魯棒性是指導提升模型對抗魯棒性的基礎.然而,關于對抗魯棒性評估的研究還停留在初級階段,僅僅依靠排名基準或簡單指標無法準確衡量模型抵御對抗攻擊的能力.因此,本文在調研和分析國內外對抗魯棒性評估研究的基礎上,針對圖像分類這一基礎視覺任務,從對抗樣本存在原因、對抗魯棒性評估準則、對抗魯棒性評估指標等方面對現有研究成果進行了歸類、總結和分析.同時,梳理了現階段主流的圖像分類數據集和對抗攻防集成工具.最后,指出了對抗魯棒性評估未來可能的研究方向,旨在為該領域研究的進一步發展和應用提供一定借鑒與幫助.
作者貢獻聲明:李自拓負責文獻調研、內容設計、論文撰寫和最后版本修訂;孫建彬負責提出指導意見、框架設計和全文修訂;楊克巍負責論文審核與修訂;熊德輝負責提出指導意見以及論文修訂.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
