基于遺傳算法優化極限學習機的炸彈氣動參數辨識
2022-10-14 03:18:32甘躍鵬伍友利王康健
兵器裝備工程學報 2022年9期
甘躍鵬,伍友利,王康健,陳 鞭,管 軍
(1.空軍工程大學 航空工程學院, 西安 710038; 2.江蘇科技大學, 江蘇 鎮江 212100)
1 引言
為了降低無控炸彈落點的散布范圍進而實現對目標的精準打擊,需要準確的炸彈氣動參數。在進行炸彈打靶試驗過程中,利用各種儀器設備采集炸彈實際飛行數據,在實際測得的數據中提取炸彈的氣動參數,比實驗室和計算所獲得的參數更能代表炸彈真實的運動狀態。炸彈彈道的穩定性取決與炸彈的氣動參數,炸彈氣動參數辨識技術是飛行器氣動參數辨識中的一個關鍵分支,為了提高無控炸彈的命中精度、減少彈藥使用量,需要進行炸彈氣動參數辨識的方法研究。
近年來,氣動參數辨識誕生了很多方法,發展十分迅速,目前較為經典的方法是最小二乘法、極大似然法、Kalman濾波法以及最近興起的某些智能算法。崔乃剛等將一階高斯馬爾科夫過程描述作為氣動參數誤差模型,并增廣到狀態方程中,根據獲得帶有測量誤差的慣導信息,對氣動參數進行估計。王正熙等采用卡爾曼濾波對四旋翼無人機的氣動參數進行在線估計,計算相應比例因子,對轉速進行補償,提高無人機的高度和航向的控制性能。趙述龍等設計了一套CIFER的辨識工具,對具有不確定因素較大的氣動參數進行頻域辨識。李金晟等基于極大似然準則,采用神經網絡-牛頓法,對無控旋轉彈丸的飛行狀態數據進行處理,提取出其零升阻力系數。韓建福等提出一種雙BP神經網絡對撲翼飛行器的氣動參數進行辨識。
極限學習算法是一種熱門的神經網絡算法,由于其學習速度快、泛化能力強等優點被廣泛應用。嚴侃等基于最小二乘原理,通過求解隱含層輸出矩陣的Moor-Penrose廣義逆矩陣,精確辨識彈丸阻力系數。張夢蝶等提出用改進的貝葉斯優化算法,解決傳統核極限學習機算法參數優化困難的問題。但由于極限學習算法隨機產生的輸入權重和隱含層神經元容易引發預測結果發散,為此研究者進行了大量的相關研究。
本文利用遺傳算法優化極限學習機算法中隱含層神經元個數、輸入層到隱含層的權值個數以及隱含層到輸出層的權值個數,解決了預測結果容易發散的問題,并且使用遺傳算法也克服了一般優化算法容易產生的陷入局部最優的問題,進一步使用這種遺傳算法優化的極限學習機對某型無控炸彈的氣動參數進行了辨識,并與傳統極限學習機辨識的結果進行了比較。將遺傳算法優化的極限學習機應用到某型無控炸彈的氣動參數辨識。
2 炸彈彈道模型
炸彈彈道模型使用修正質點彈道模型(簡稱4D模型),此模型是在地面坐標系中,具體方程組如下:
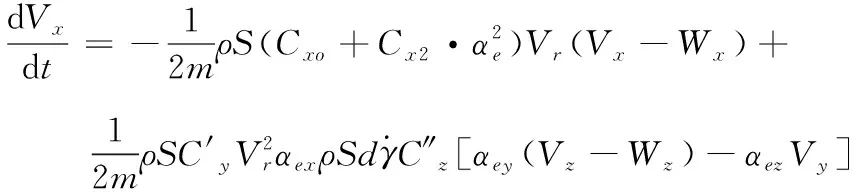
(1)
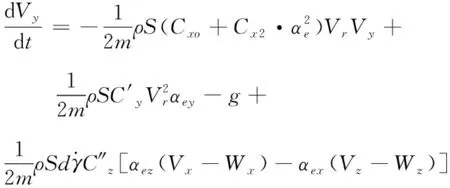
(2)
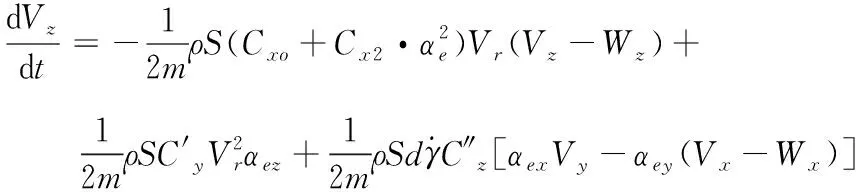
(3)
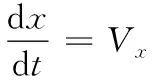
(4)
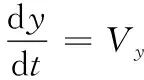
(5)
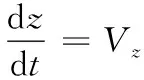
(6)
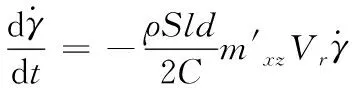
(7)
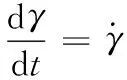
(8)
炸彈相對于空氣的速度為:
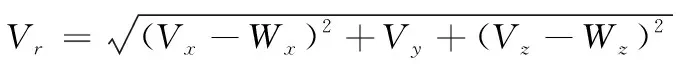
(9)
動力平衡角的直接計算公式為:
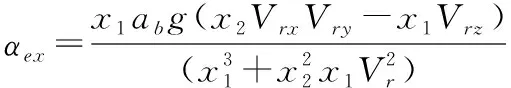
(10)
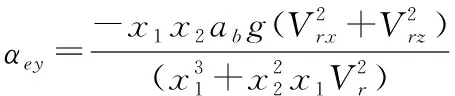
(11)
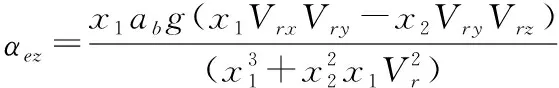
(12)
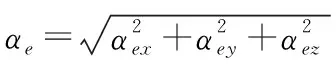
(13)
式(10)—式(13)中的相關參數可以由下面的式(14)—式(22)計算得到。
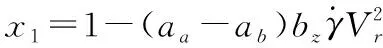
(14)
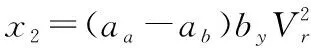
(15)
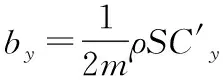
(16)
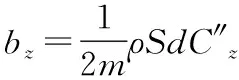
(17)
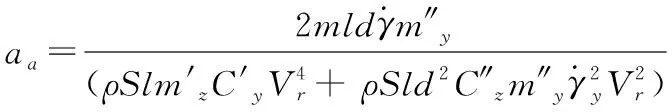
(18)
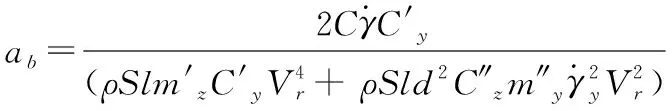
(19)
=-
(20)
=
(21)
=-
(22)
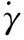
3 極限學習算法
極限學習算法可以看為一種只有一層隱含層的前向傳播神經網絡,和其他神經網絡一樣,可以分為訓練階段和預測階段。與經典的神經網絡不同的是,極限學習算法是隨機生成輸入權重值和隱含層神經元閾值。這兩者之間是獨立的并且不需要調整,其結構如圖1所示。
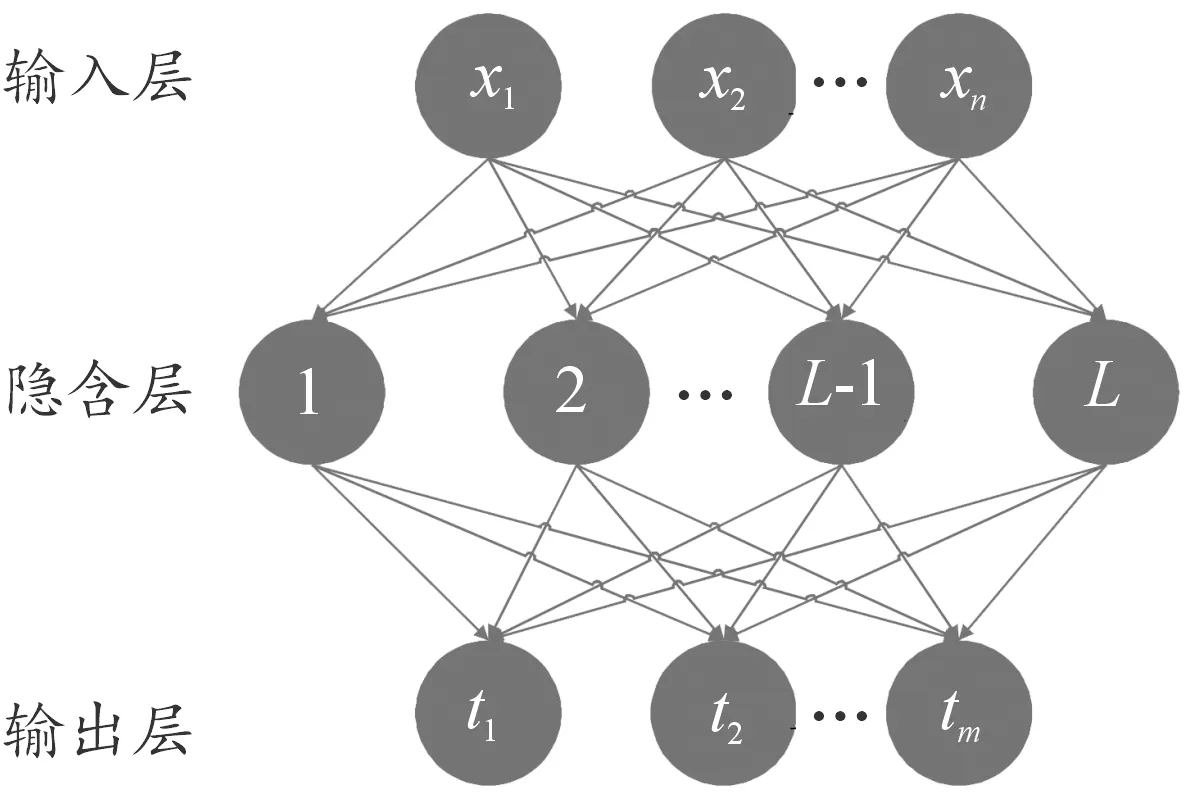
圖1 極限學習算法結構示意圖Fig.1 Structure diagram of ELM
給定組訓練樣本(,)∈×,其中是維輸入向量,是維目標向量。隱含層含有個神經元,(,,)是極限學習算法的激活函數,其輸出為:
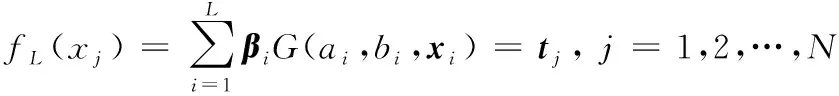
(23)
式(23)中:(,)分別為輸入的權重值和隱含層神經元閾值;為連接第個隱含層神經元和輸出神經元的權重向量。可以將式(23)變化為矩陣的形式,即:
=
(24)
其中
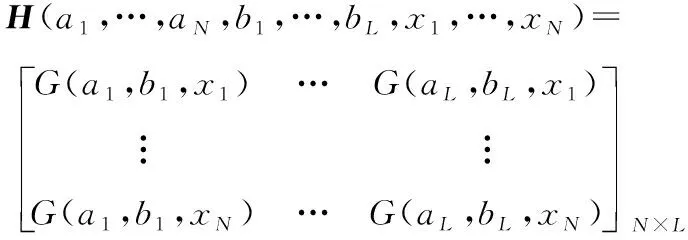
(25)
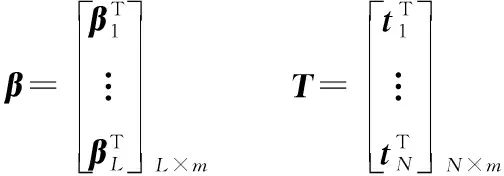
(26)
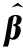
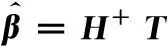
(27)
式(27)中,是的Moore-Penrose廣義逆矩陣。
極限學習算法可以主要歸納為以下3個步驟:
1確定隱含層神經元個數,隨機設定輸入層和隱含層的連接權重和閾值(,);
2將一個無限可微的函數作為隱含層神經元的激活函數(,,),計算隱含層輸出矩陣;
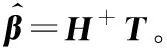
4 遺傳算法
遺傳算法(GA)起源于對生物系統進行計算機模擬,是一種對自然界生物進化機制進行模仿的隨機全局搜索和優化方法。GA算法可以高效、并行地進行全局搜索,并在搜索過程中可以自動獲取和累積相關搜索空間的知識,并自適應地控制搜索過程來求出最優解。
遺傳算法的一般步驟可以歸結于以下5個步驟:
1初始隨機產生種群。
2依據策略判斷個體適應度,如果能夠符合優化準則,輸出最優個體和最佳解,結束。否則進行下一步工作。
3根據適應度選擇其父母,適應度高的被選中概率就大,反之選擇概率就小。
4將成為父母的個體,根據一定的方法用他們的染色體交叉,產生后代。
5對后代染色體進行變異操作,再進行交叉、變異的操作產生新的種群,然后回到步驟2,開始循環,直至產生最優解。
遺傳算法計算流程如圖2所示。
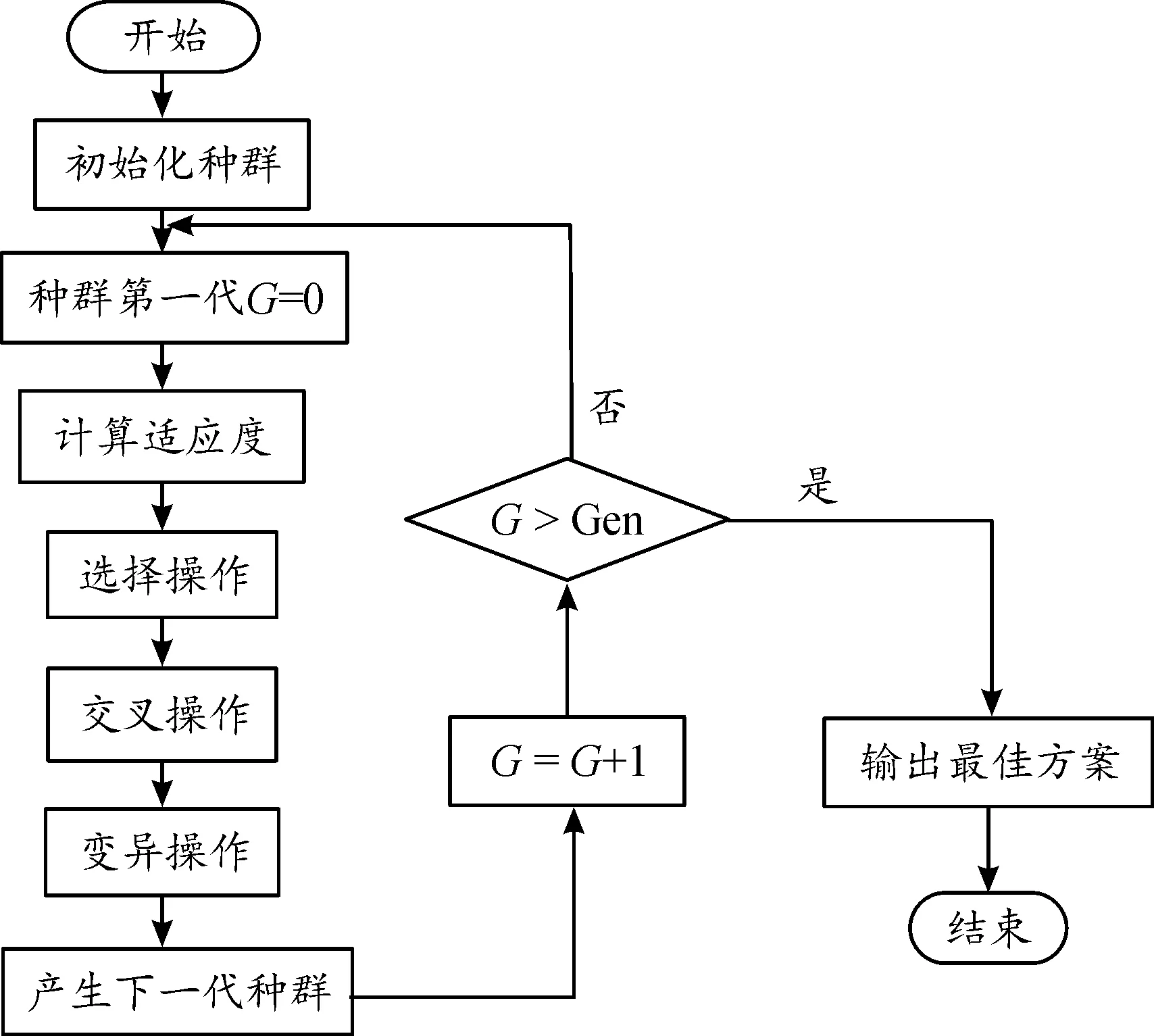
圖2 遺傳算法計算流程框圖Fig.2 The flow chart of genetic algorithm(GA)
5 炸彈氣動參數辨識
5.1 數據獲取及處理
標準大氣條件下使用4階龍格庫塔法(積分步長0.01)求解4D模型,本文基于分段辨識的思想提取氣動參數,將彈道數據劃分為若干區間。由于每一個小區間內速度變化很小,因此可以把區間內的氣動系數視為常數。得到8 000組彈道數據,表1為初始設置。

表1 彈道初始設置Table 1 Ballistic initial setting
得到的數據包括炸彈飛行速度、姿態、位置等,為了提高算法的精度,消除不同量綱間的影響,需要對其進行歸一化處理。歸一化處理公式為:
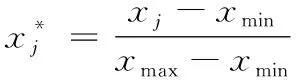
(28)
選取其中7 000組數據作為訓練集,1 000組數據作為測試集。
5.2 遺傳算法優化極限學習機(GA-ELM)算法氣動參數辨識
ELM模型結構設置
ELM初始需設置的參數為:輸入層節點個數、隱含層神經元數、輸出層節點個數和激活函數。
2) 隱含層神經元。神經網絡通過我們設置的隱含層層數將這些不同的樣本特征映射到一個維空間中,隱含層神經元決定了神經網絡的訓練時間和預測的準確程度,因此設置的神經元個數需合理,設置不合理,會導致訓練時間長或預測不準確的問題產生,而ELM是設置隱含層神經元個數之后不再更改,因此設置神經元個數十分重要。
3) 輸出節點數。本文中采用修正質點彈道方程,需辨識的氣動參數如表2所示。

表2 辨識氣動參數名稱及函數名Table 2 Name of aerodynamic parameter and function to be identified
4) 激活函數。激活函數的目的是將非線性特性加入到ELM中。Sigmoid函數是一個S型曲線,由于其單調遞增同時其反函數也是單調遞增的特性,Sigmoid函數通常被用作神經網絡的閾值函數。本文中選取Sigmoid函數作為極限學習機的激活函數。
GAELM算法步驟及流程
GA-ELM算法步驟如下。
1將染色體種群編碼進行初始化,提取出極限學習機的輸入層權值和隱含層閾值元素,并計算其染色體長度。之后隨機初始化染色體。
2設置適應度函數。利用ELM對樣本的輸出誤差作為適應度函數,計算初始種群中分體的適應度函數,計算初始種群中的個體適應度。
3進行選擇、交叉、變異操作。采用輪盤賭選擇時,對于適應度函數,由于取得是均方誤差,在進化過程中,均方誤差減小,因此,輪盤賭設置時,適應度函數需取其倒數,從而選擇“適應度大”的個體。
4計算子代個體的適應度,并與父代個體合并,留下適應度較好的個體,構成新的子代種群。
5反復迭代步驟3和步驟4,直至達到最大設定值。
6輸出最優的染色體信息。對適應度最好的染色體進行解碼,并將解碼后得到的權值和閾值賦給預測使用的ELM。
7以最優的權值和閾值初始化ELM的參數,獲得最優的網絡結構。最后測試網絡的預測精度。
GA-ELM算法計算流程如圖3所示。
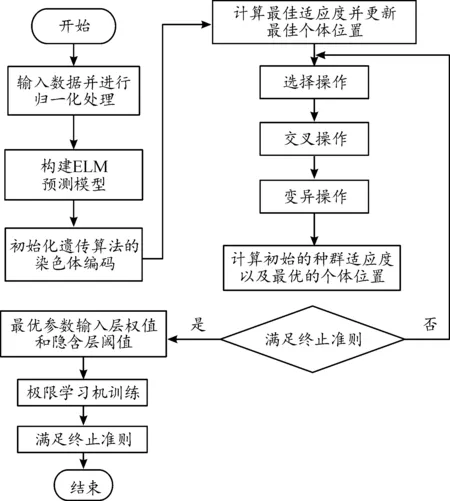
圖3 GA-ELM算法計算流程框圖Fig.3 GA-ELM algorithm flow chart
6 仿真驗證
使用ELM和GA-ELM 2種方法辨識氣動參數,具體見圖4—圖10。圖中橫坐標為馬赫數,縱坐標為待辨識的氣動參數,紅色曲線為參考值曲線,黃色曲線為使用ELM的預測值曲線,藍色曲線為使用GA-ELM的預測值曲線。由于測試集樣本過大,導致參考值曲線和GA-ELM的預測值曲線部分重合,小圖窗中是圖中部分放大,可以觀察到GA算法,可以有效提高ELM算法的辨識精度。
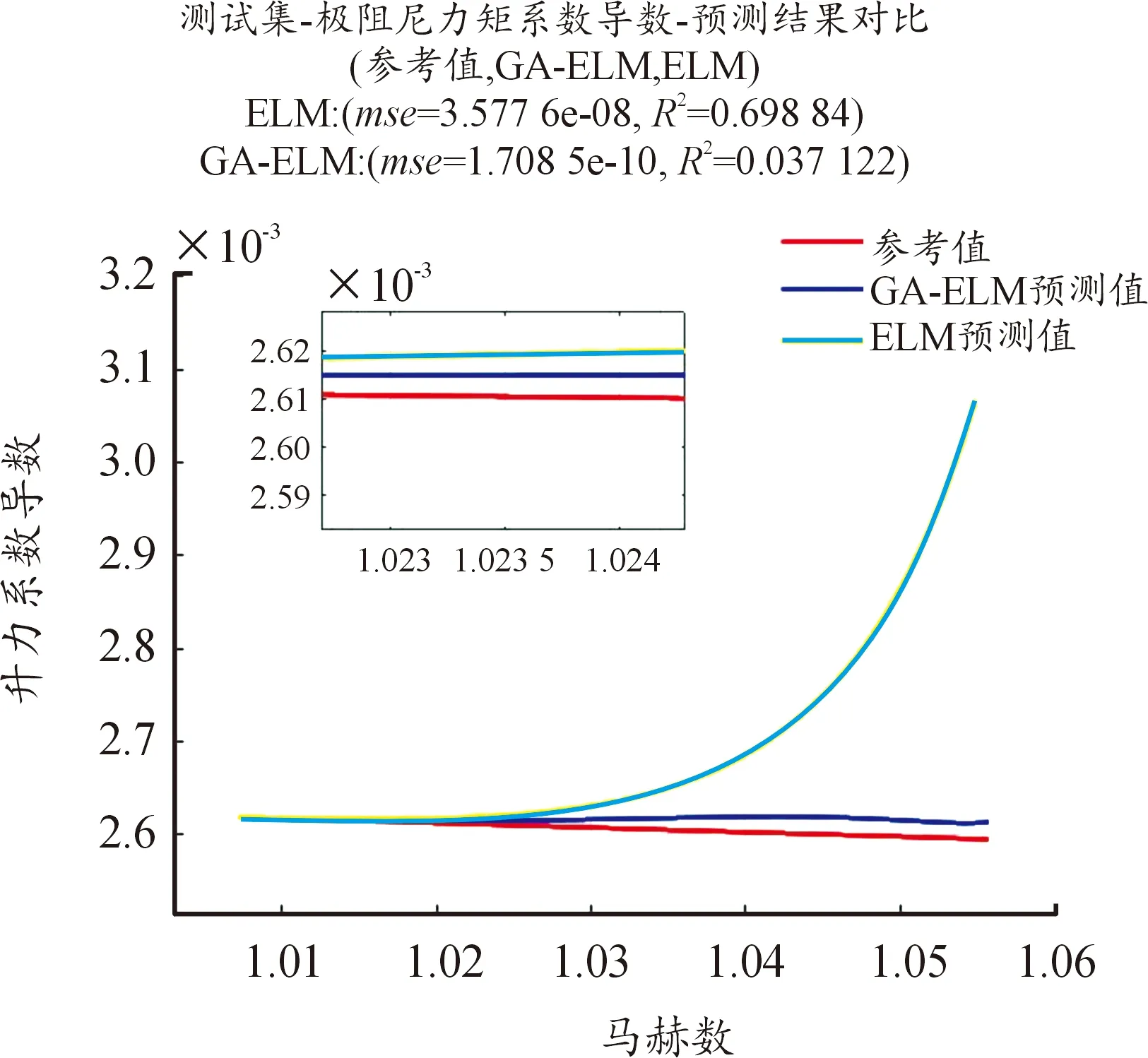
圖4 辨識結果曲線Fig.4 Identification result
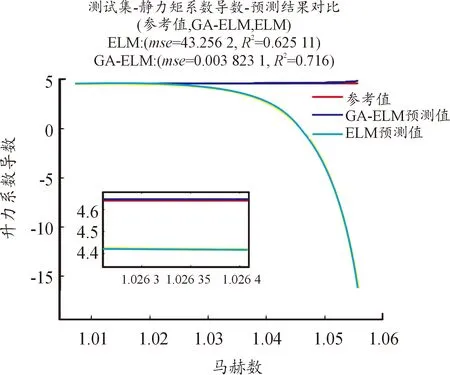
圖5 辨識結果曲線Fig.5 Identification result
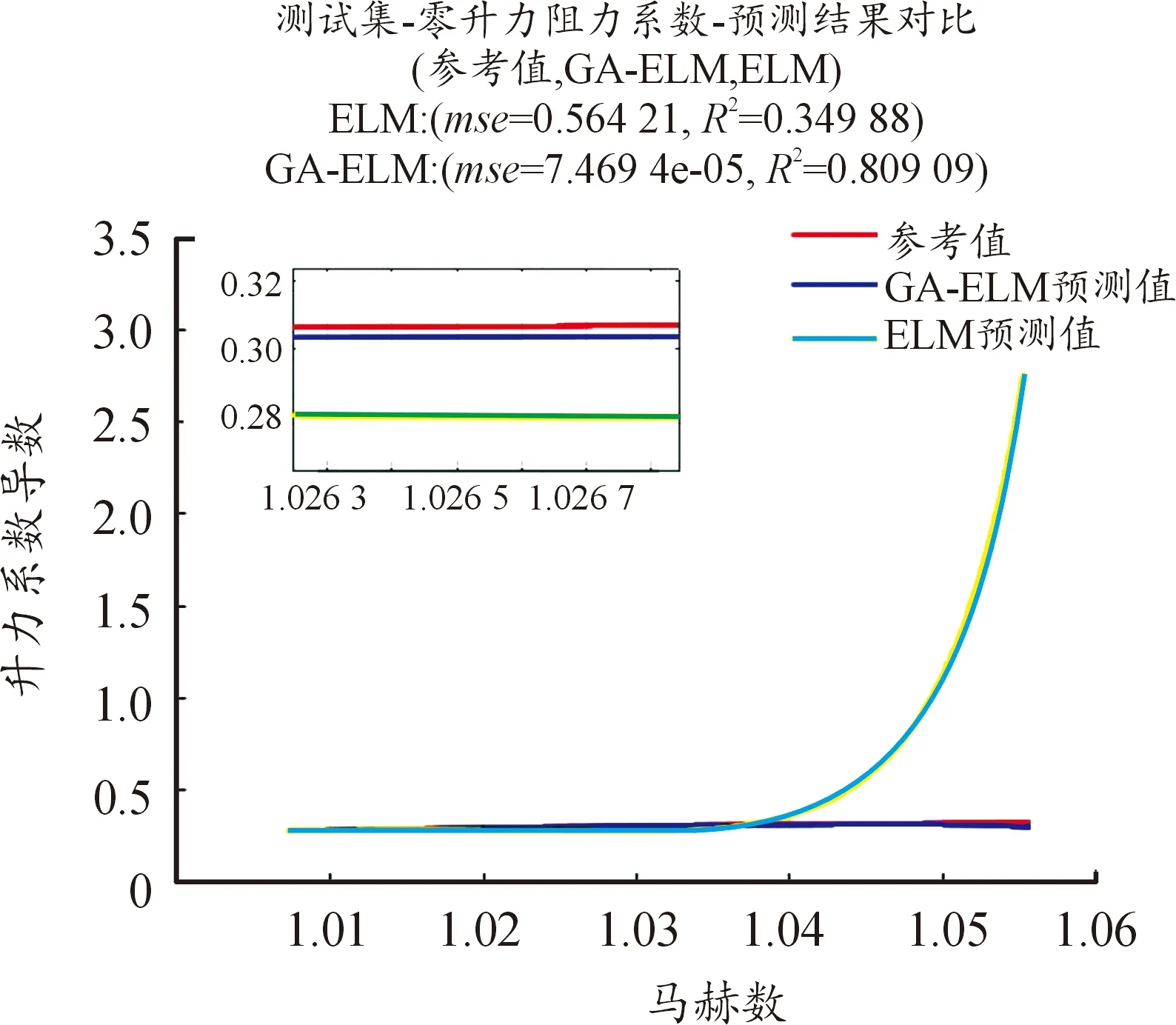
圖6 Cx0辨識結果曲線Fig.6 Cx0 Identification result
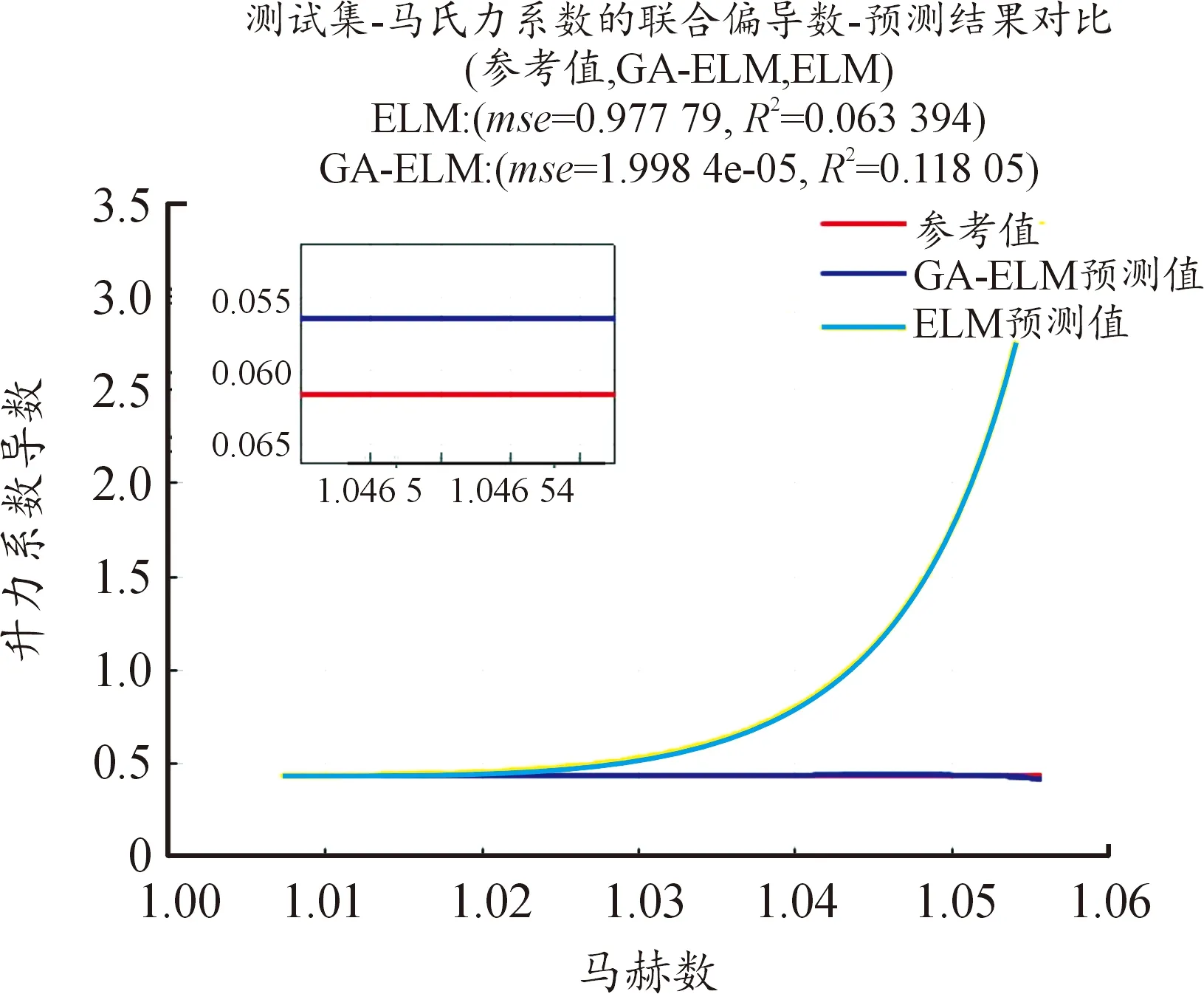
圖7 辨識結果曲線Fig.7 Identification result

圖8 辨識結果曲線Fig.8 Identification result
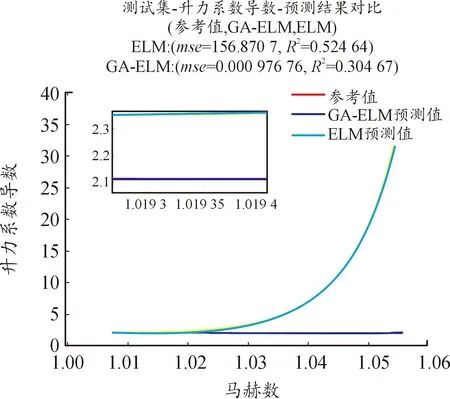
圖9 辨識結果曲線Fig.9 Identification result
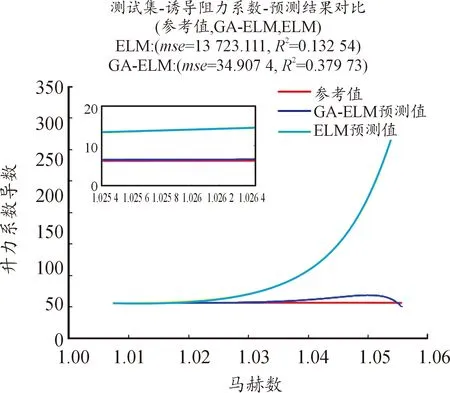
圖10 Cx2辨識結果曲線Fig.10 Cx2 Identification result
圖4—圖10中還給出了2種算法辨識氣動參數的均方差(MSE),MSE體現其辨識精度,MSE的數量級越小,辨識精度越高;反之,辨識精度越低。從圖4—圖10可知,加入遺傳算法后的極限學習機算法辨識精度更高,預測值和真實值幾近相同,而未加入GA算法的ELM算法,其辨識精度低,預測值和真實值差距較大。GA算法優化產生ELM的輸入權重及閾值,可以使得輸入權重和閾值包括更多的樣本信息,提高其辨識精度。
7 結論
本文應用GA算法優化ELM算法,改善了ELM 算法的尋優精度,GA-ELM算法的尋優精度明顯提升,但由于GA算法是全局搜索算法,計算時間較長,因此,加入GA算法后導致GA-ELM算法辨識氣動參數的時間增長。根據仿真試驗可得到以下結論:
1) GA-ELM算法可以實現炸彈的氣動參數辨識。
2) GA算法迭代尋優產生ELM的輸入權重和隱含層神經元閾值,可以有效提高模型辨識精度。
3) 雖然GA-ELM算法提高了辨識精度,但計算辨識炸彈氣動參數的速度較慢,對實際工程應用還有一定差距,還需對辨識速度優化。
