基于深度強化學習的無人艇集群博弈對抗
2022-10-14 03:04:42劉殿勇
兵器裝備工程學報 2022年9期
關鍵詞:策略
蘇 震,張 釗,陳 聰,劉殿勇,梁 霄
(1.珠海云洲智能科技股份有限公司 工業發展部, 廣東 珠海 519080;2.大連海事大學 船舶與海洋工程學院, 遼寧 大連 116026)
1 引言
水面無人艇作為智能化無人系統和作戰平臺的代表性武器裝備,具有體積小、造價低、隱身性好、全海域航行、全天候工作等特點,能夠在環境調查、情報偵查、警戒巡邏、反水雷作戰等領域發揮重要作用。
在復雜多變的海洋環境下,單無人艇載荷配置十分有限、任務能力偏弱、作戰樣式相對單一,在很大程度上無法保證任務的順利完成。無人艇集群協同作戰可彌補單艇能力的不足,充分發揮群體靈活部署快、監控范圍廣、作戰組織靈活、抗毀重構性強等優勢。為應對無人艇集群攻擊,最有效的方法就是利用無人艇集群對入侵的無人艇集群進行攔截、驅離或圍捕,從而形成無人艇集群間的博弈對抗。
博弈對抗技術是智能化軍事應用的基礎和共性技術,是解決指揮控制中作戰方案生成、任務規劃及臨機決策等智能化的關鍵,同時也是訓練模擬、自主集群無人化作戰等軍事關鍵領域智能化建設的核心技術基礎。因此,在網絡環境下,研究無人艇集群博弈對抗技術具有重要的理論意義和軍事價值。
Marden等研究了基于博弈理論的協同對抗技術,通過評估當前行為的后續影響,以及對可能發生的情況進行預測估計,從而制定更為合理的實時方案。Atanassov等對傳統模糊集進行了進一步拓展,由于直覺模糊數的二元標量性具有更強的模糊表述能力,被廣泛地應用于解決不確定環境下的決策問題。Park等基于微分博弈理論,提出了一種機動決策方法,遵循分級決策結構,使用評分函數矩陣描述機動決策過程,以選擇動態作戰態勢下最優機動決策方案,提升機動決策的有效性。邵將等通過建立多無人機協同空戰連續決策過程,使用貝葉斯推論對空戰態勢進行實時評估,并以此設計的決策規則進行機動決策。陳俠等通過建立無人機的能力函數,建立多無人機協同打擊任務的攻防博弈模型,給出了有限策略靜態博弈模型與純策略納什均衡的求解方法。通過求解博弈模型的混合策略納什均衡解,并結合一定作戰經驗,形成任務決策方法。段海濱等研究了“狼群”智能行為機理,并將其應用于無人機集群系統對抗任務,解決無人機集群協同決策問題。魏娜等針對多自主水下航行器的水下協同對抗博弈問題,以博弈論為基礎,多無人艇的多次對抗為作戰背景,從同時考慮敵我雙方對抗策略的角度出發,對多無人艇的動態協同攻防對抗策略問題進行了研究。李瑞珍等采用協商法為機器人分配動態圍捕點,建立包含圍捕路徑損耗和包圍效果的目標函數并優化 航向角,從而實現協同圍捕。陳亮等提出混合DDPG算法,有效協同異構agent之間的工作,同時,Q函數重要信息丟失及過估計等問題有待解決。Foersteret提出了使用集中式評論家的 COMA,集中式評論家可以獲得全局信息來指導每個智能體,從而進一步提高每個智能體的信息建模能力。
上述研究成果的取得表明國內外研究學者在無人艇集群博弈對抗方面取得了一定的研究成果,但仍處于起步階段,存在許多實際問題有待進一步解決。
第一,無人艇集群動態博弈對抗研究較少。海上博弈對抗環境復雜且目標大都為動態,動態對抗在決策過程中不僅需要考慮博弈前一階段的影響,同時需考慮對后一階段產生的后果。
第二,實時決策效率較低。無人艇集群動態博弈對抗過程中,每個階段均需通過多步矩陣運算產生對抗雙方的博弈收益,這將導致博弈空間復雜度成指數級增長,現有求解算法難以實現實時決策目的。
本文中針對紅藍雙方無人艇集群動態博弈對抗問題,開展基于深度強化學習的無人艇集群協同圍捕決策研究。首先,根據無人艇集群狀態信息與無人艇運動性能進行圍捕環境建模;然后,采用基于雙評價網絡改進的DDPG算法設計策略求解方法,并且立足協同圍捕任務,設計基于距離和相對角度的階段性獎勵函數;最終,經仿真實驗驗證,訓練得到的智能體能夠較好的完成協同圍捕任務。
2 問題描述
無人艇集群協同圍捕是集群作戰的典型樣式,在無限大且無障礙的作戰區域內,存在若干艘逃逸無人艇與圍捕無人艇,逃逸無人艇要在躲避圍捕無人艇追蹤;圍捕無人艇要對逃逸無人艇盡快完成對其的圍捕。本文中追擊-逃逸過程在二維平面內進行,且假設通過探測設備,雙方均能獲得所有無人艇運動參數信息。
紅方無人艇的目標點均勻分布在以藍方艇群中心為圓心,以為半徑的圓上。此外,考慮到無人艇機動性,若各紅方艇距離目標點均小于時,可視為圍捕完成。以5艘圍捕無人艇,一艘逃逸無人艇為例,圍捕過程如圖1所示,圍捕完成如圖2所示。
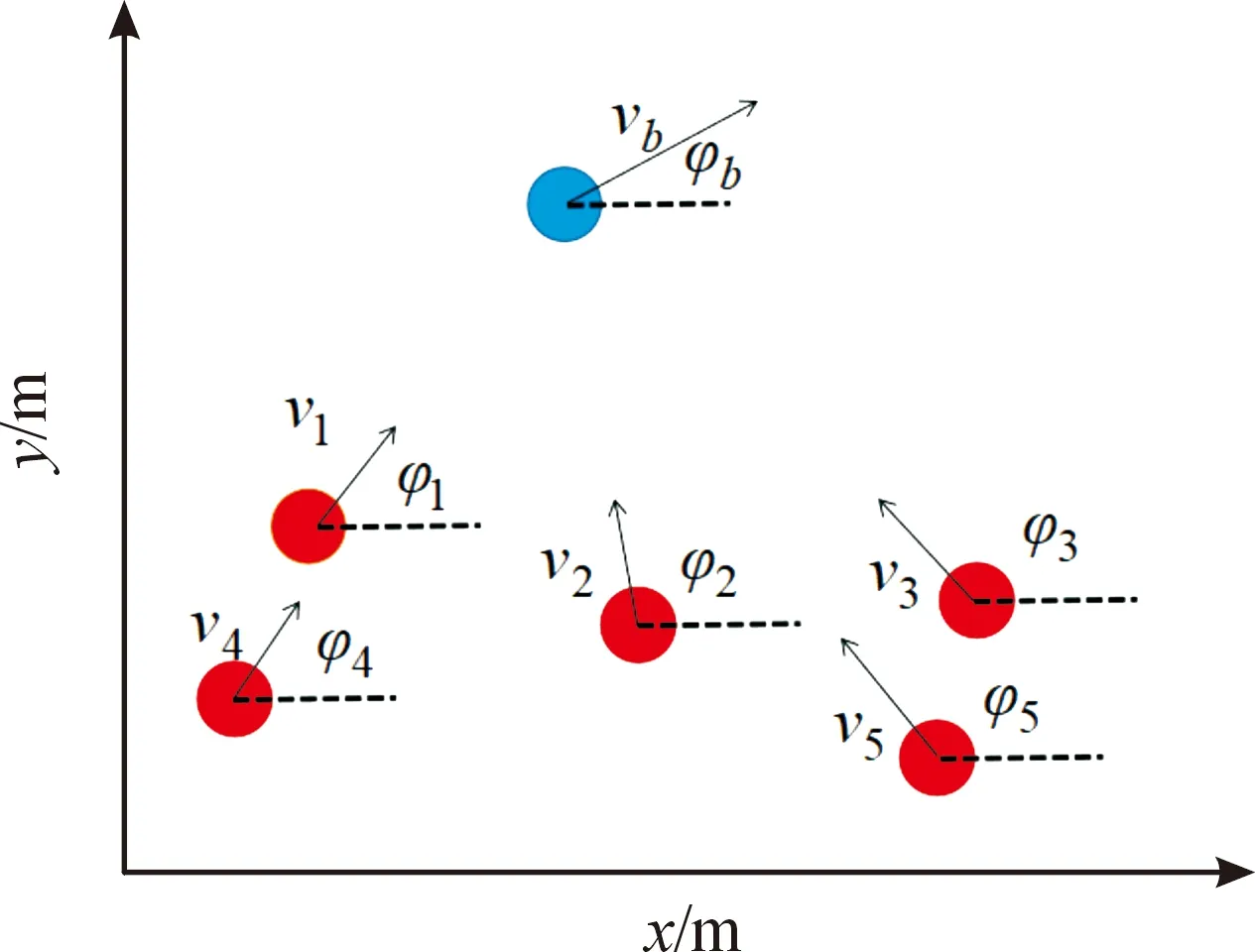
圖1 圍捕過程示意圖Fig.1 Round up process
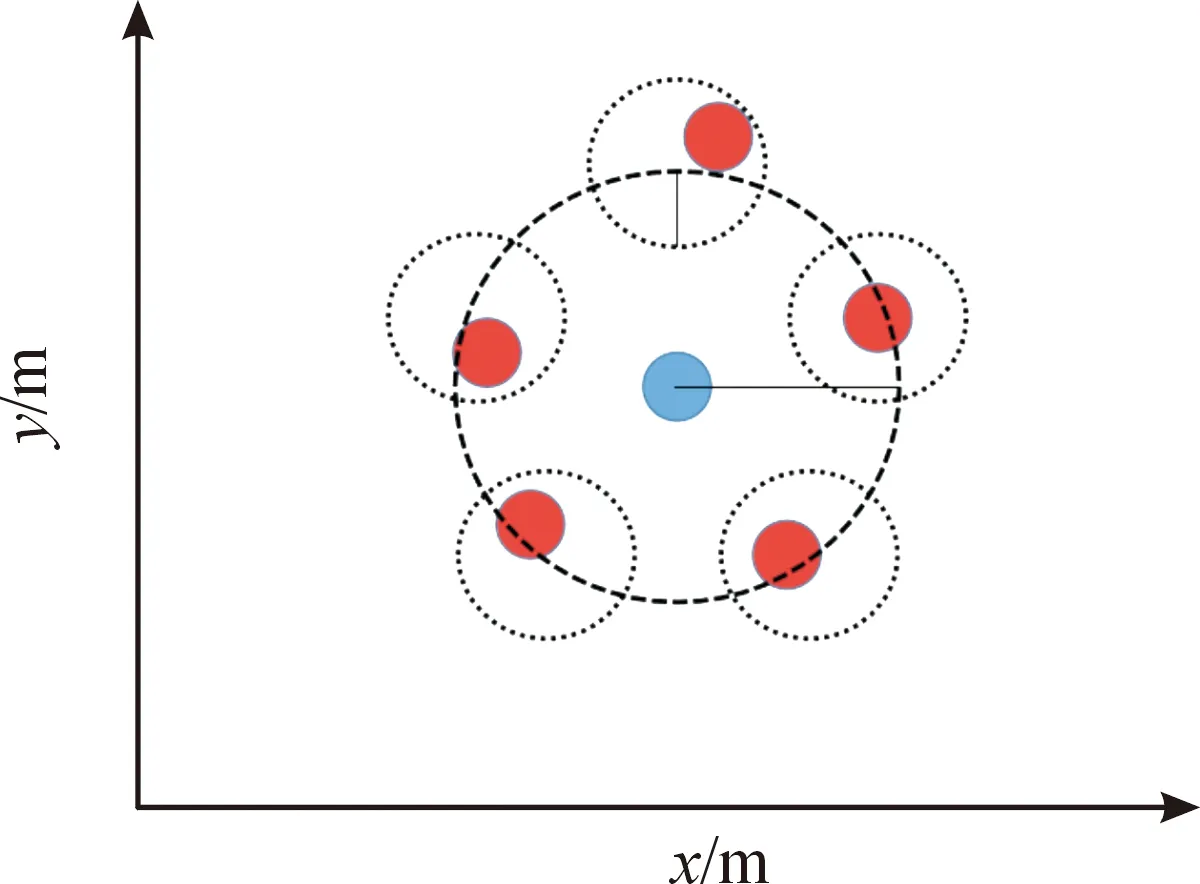
圖2 圍捕完成示意圖Fig.2 Round up complete
無人艇運動模型為
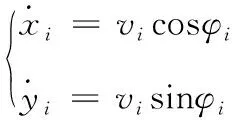
(1)
式中:表示第艘無人艇橫向位置;表示無人艇縱向位置;表示無人艇速度大小;表示無人艇艏向角。
第艘無人艇與第艘無人艇相對距離和相對角度為
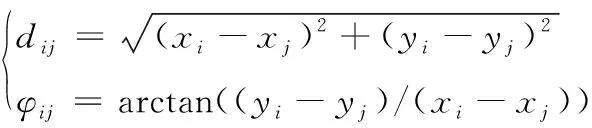
(2)
狀態空間包括各無人艇位置信息,其具體形式為
=(,,,,…,,,,)
(3)
無人艇動作空間是連續的,對應的動作為二維速度向量。定義藍方無人艇速度大小∈[0,max],max為藍方無人艇速度上限;艏相角∈[0,2π](單位為弧度);定義紅方無人艇速度大小∈[0,max],max為紅方無人艇速度上限;艏相角∈[0,2π]。
3 集群博弈對抗策略
本文中基于改進的深度確定性策略梯度(deep deterministic policy gradient,DDPG)算法研究無人艇集群博弈對抗策略問題,DDPG算法結構如圖3所示。
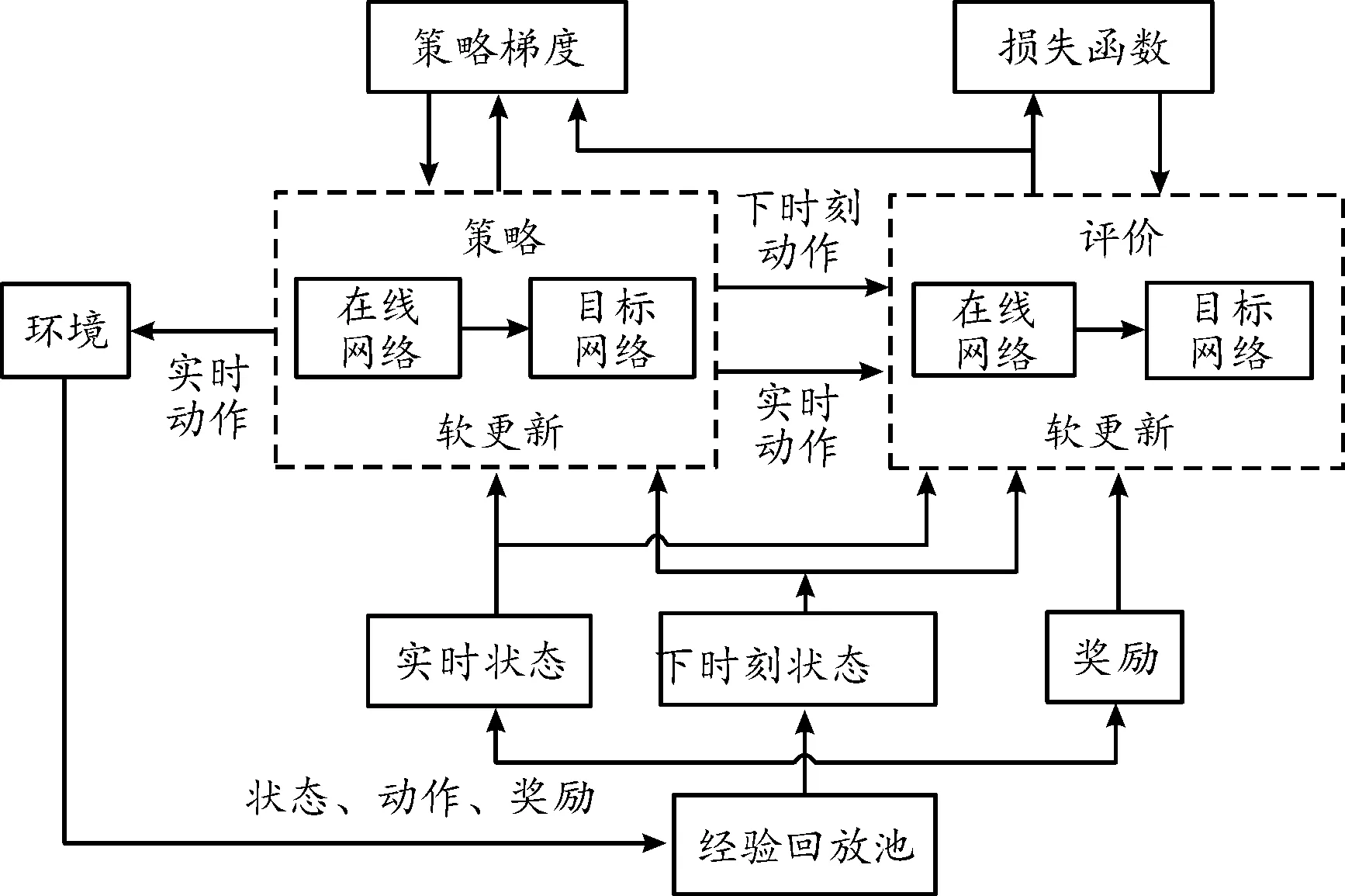
圖3 DDPG算法結構框圖Fig.3 DDPG structure
首先,為每艘無人艇設計策略網絡和評價網絡,其中的評價網絡接收無人艇的狀態和動作進行學習,策略網絡只接收狀態信息。該算法主要包括策略函數網絡和評價函數網絡,且每個網絡均包括了主網絡和目標網絡,主網絡和目標網絡的結構完全一樣,網絡總體結構如圖4所示。

圖4 策略網絡和評價網絡總體結構框圖Fig.4 Network structure of actor and critic
DDPG算法是深度Q網絡算法在連續動作空間的進階版,因此DDPG同樣存在目標值高估問題。針對該問題對算法結構做出如下改進:
1) 建立2套結構相同的評價網絡,計算時序差分目標時采用2個目標網絡輸出中的較小值作為目標值,2個主網絡均通過最小化均方差更新。
2) 降低策略網絡的更新頻率,促使評價網絡更新更穩定。
3) 在目標策略網絡的輸出上增加一個服從正態分布的噪聲,從而平滑值估計,避免評價網絡過擬合。策略主網絡更新時,采用2個評價主網絡輸出的較小值。
算法流程如下:
改進的DDPG算法
初始化策略網絡和2套評價網絡參數
初始化經驗池
for episode=1,do
初始化智能體狀態
for=1,do
為每一個智能體,選擇加入噪聲的隨機過程動作
返回所有智能體的動作集合,獎勵,下一個狀態值
儲存狀態轉移數據對到經驗池
從經驗池中隨機選擇最小批次數據
計算損失函數更新評價網絡
計算策略梯度更新策略網絡
“軟更新”目標網絡參數
End for
End for
其中,代表總回合數;代表回合時長。
獎勵函數決定了深度強化學習的收斂速度與收斂程度,需要根據作業任務與環境來設置獎勵函數。在傳統強化學習中,獎勵函數的設計通常做法是只有一個結果獎勵,即只有在智能體到達最終目標時才會獲得獎勵,因此這種做法在操作規則較為復雜的任務中并不適用。為此,本文中將任務獎勵分解為目標獎勵與過程獎勵兩部分,通過賦予無人艇階段性運動獎勵來引導其學習到正確的圍捕行為,得到最優博弈對抗策略的同時避免回報稀疏問題。針對協同圍捕,下面設計紅方無人艇獎勵函數。
集體獎勵函數為
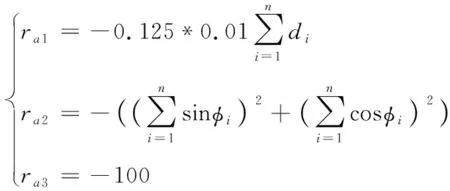
(4)
式中:為第艘紅方無人艇距藍方無人艇的距離;為第艘紅方無人艇與藍方無人艇的角度。
=1+2+3
(5)
式中:1表示當紅方與藍方距離未達到包圍范圍時獎勵,獎勵考慮因素為平均距離;2表示當紅方與藍方距離達到包圍范圍時獎勵,獎勵考慮因素為相對角度;3表示規定時間內未完成圍捕,紅方任務失敗。
4 仿真結果
為驗證基于深度強化學習的無人艇集群博弈對抗策略有效性,下面分別進行5對1和7對3圍捕下的集群博弈對抗仿真。
5對1下的仿真參數如表1所示。收益如圖5所示,其中,回合收益表示一回合中每次迭代所獲得的獎勵的和,平均收益為最近一百回合收益的平均值。可以看出,收益整體呈上升趨勢并最終穩定在較高水平,證明所建立的已經收斂。算法約在3 800回合收斂,最大獎勵值為800,每艘無人艇均可到達目標位置完成圍捕任務。
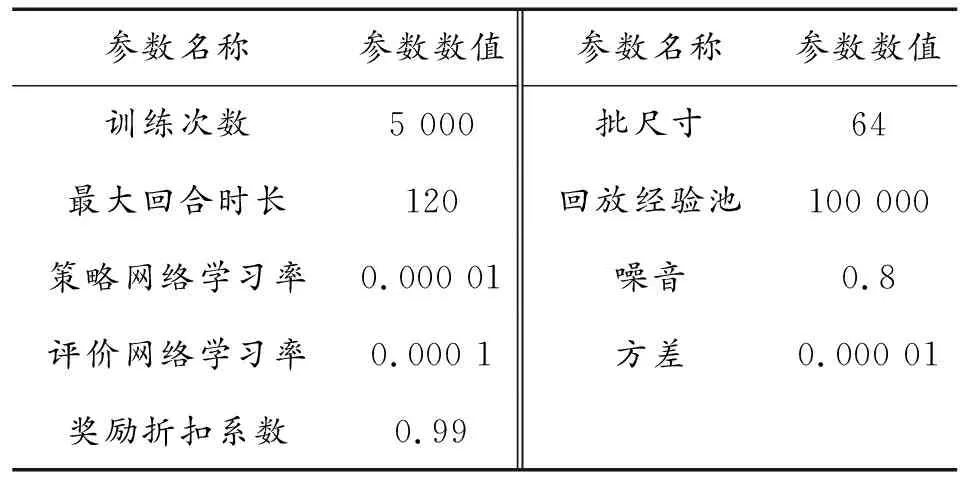
表1 5對1仿真參數Table 1 Simulation parameters under 5 vs 1
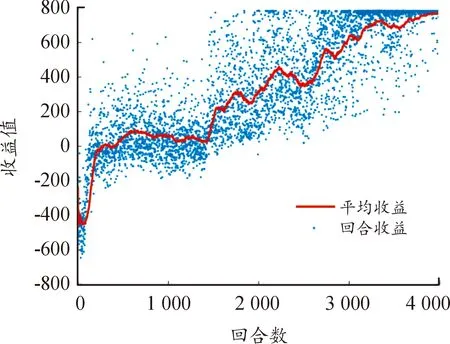
圖5 5對1回合收益示意圖Fig.5 Round reward under 5 vs 1
圍捕仿真結果如圖6所示,圖6(a)為起始位置,圖6(d)為圍捕完成時位置,中間各時刻位置圖相差14 s。在圍捕初始時刻,紅方無人艇位置相對分散,藍方無人艇出現在紅方無人艇北偏西方向。隨后,紅方向藍方無人艇所在方向進行集中,逐漸接近藍方無人艇;藍方無人艇向目標區域靠近,并在紅方無人艇接近時向北方向進行偏移躲避,狀態如圖6(b)所示。接著,紅方無人艇追上藍方無人艇并在其周圍做伴隨運動,逐漸形成圍捕趨勢;藍方無人艇繼續向目標區域靠近,狀態如圖6 (c)所示。最終,紅方無人艇在藍方無人艇到達目標區域前完成對藍方無人艇的圍捕,狀態如圖6(d)所示。
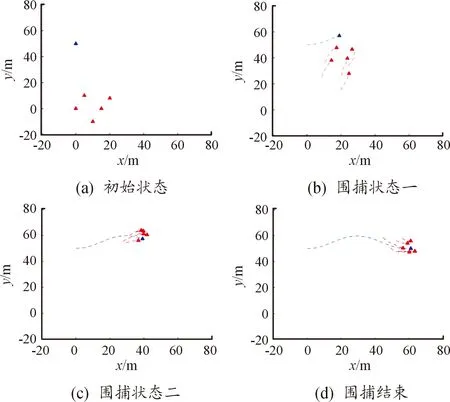
圖6 5對1仿真結果示意圖Fig.6 Simulation results under 5 vs 1
7對3下的仿真參數如表2所示。收益如圖7所示,可以看出,收益值呈整體上升并最終穩定在較高水平,算法約在4 300回合收斂,最大獎勵值為1 000,每艘無人艇均可到達目標位置完成圍捕任務。
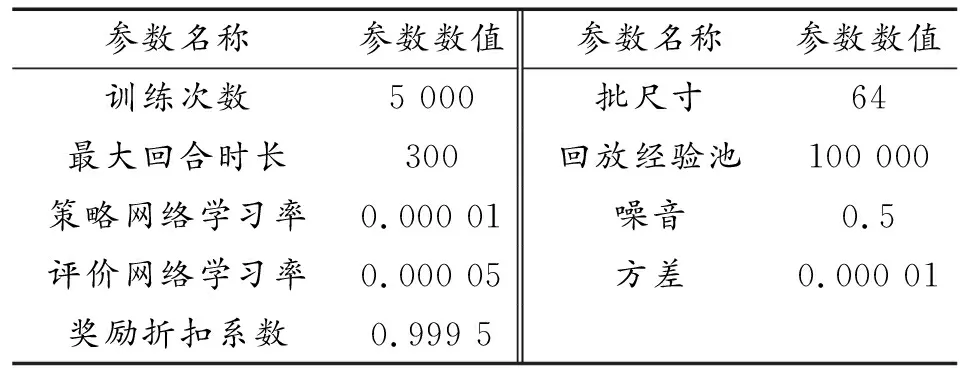
表2 7對3仿真參數Table 2 Simulation parameters under 7 vs 3
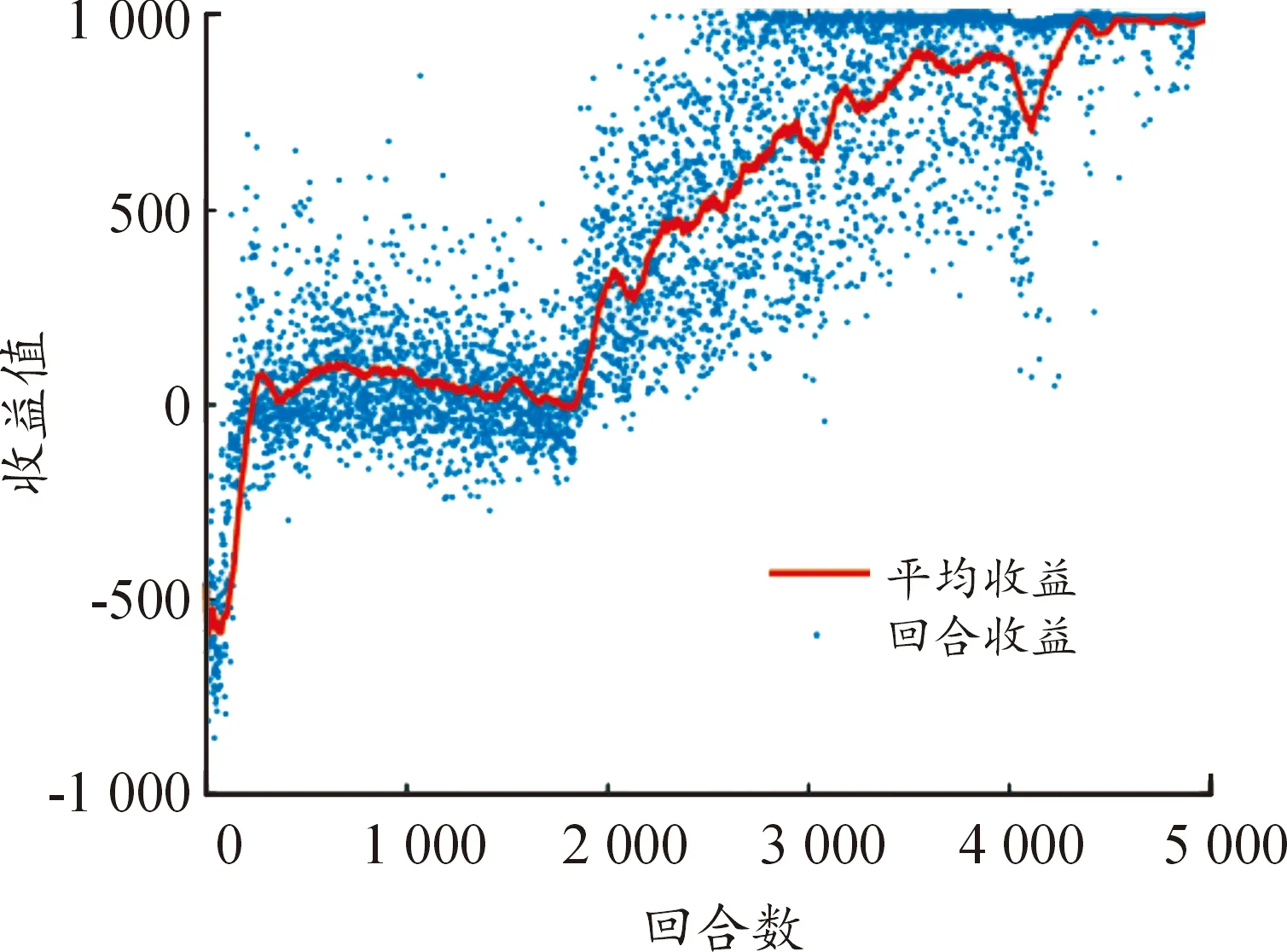
圖7 7對3回合示意圖Fig.7 Round reward under 7 vs 3
圍捕仿真結果如圖8所示,圖中(a)為起始位置,(d)為圍捕完成時位置,中間各時刻位置圖相差32 s。在圍捕初始時刻,紅方無人艇與藍方無人艇相距300 m左右,藍方無人艇位于紅方無人艇北方向,目標區域位于藍方無人艇東北方向,紅藍雙方位置均較為散亂。隨后,紅方無人艇向藍方無人艇所在方向進行運動;藍方無人艇邊向目標區域靠近,邊對紅方無人艇追捕行為進行躲避,狀態如圖(b)所示。接著,紅方無人艇追上藍方無人艇,并在其周圍逐漸展開圍捕趨勢;藍方無人艇繼續向目標區域運動,狀態如圖(c)所示。最終,紅方無人艇完成對藍方無人艇的圍捕,圍捕半徑約為300 m,并以圍捕狀態伴隨在藍方無人艇周圍進行運動,狀態如圖(d)所示。

圖8 7對3仿真結果示意圖Fig.8 Simulation results under 7 vs 3
5 結論
設計了協同圍捕環境下深度強化學習算法的狀態信息、動作信息、神經網絡結構和獎勵函數,并分別開展了5對1和7對3下的集群博弈對抗仿真驗證。仿真結果表明,基于深度強化學習的紅方無人艇集群能夠對藍方無人艇進行有效的協同圍捕。未來工作將在此基礎上研究弱連通下的無人艇集群博弈對抗。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:42
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年9期)2018-10-08 02:29:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:10
數學大世界(2018年1期)2018-04-12 05:39:14
幸福(2017年18期)2018-01-03 06:34:53
中國衛生(2016年8期)2016-11-12 13:26:50
