基于電子健康記錄的智能算法研究綜述
2022-10-11 09:05:44李天皓
電子科技大學學報(社科版) 2022年5期
□李天皓 張 倩 陸 煒
[電子科技大學 成都 611731]
引言
電子健康記錄(Electronic Health Records,EHRs),是指以計算機可處理形式存在的關于護理主體健康狀態的信息存儲庫,通常又被稱作電子健康檔案或電子病歷[1]。EHRs由醫療服務機構與病人一次或多次交互產生,主要記錄的信息包括病人的人口統計資料、用藥記錄、生命體征、臨床病史、實驗室檢測結果以及診斷報告等信息[2~3]。電子醫療記錄(EMR)與EHRs相似,但EMR最常指的是單一的醫療事件,而EHRs 包含了病人的整個醫療記錄情況[4]。目前,EHRs的定義在學術界仍缺乏統一的認識。一方面,EHRs本身的功能形態還在不斷發展之中;另一方面,不同國家和組織根據自己的需求和理解給出定義[5],但人們對EHRs應當具備的一些基本特征有著相近的認識[6]。簡而言之,學術界對EHRs認識的共同點大于分歧。
EHRs是旨在與其他醫療衛生組織和機構(例如實驗室、專家、醫學影像設施,藥房,急救設施以及學校和工作場所診所)共享信息,合理利用EHRs的信息對于控制公共傳染病、干預衛生應急事件、預防與監測慢性疾病、改善患者護理、增強臨床決策支持和提高全民健康水平均有重要的作用[7~8]。電子健康記錄系統和其他的健康數據數字化系統一樣,它可以讓醫療保健變得更為智能、安全、高效,在這個過程中,區塊鏈、人工智能和大數據等智能技術發揮著巨大的推動作用[9~10]。
本文將“電子健康記錄”“電子健康檔案”和“電子病歷”作為關鍵詞,結合智能算法應用進行綜述。主要工作包括:對比電子健康記錄的國內外研究趨勢和分析EHRs的發展情況,并針對國內外結合EHRs和人工智能、大數據、區塊鏈等智能算法的研究情況進行分析,最后提出我國發展EHRs的建議。
一、國內外EHRs研究與使用情況
對國內外EHRs的應用情況進行分析有助于梳理國內電子病歷發展歷程、分析國內外文獻發表和主題演化情況,從而梳理EHRs主題的研究狀況。
(一)國內外EHRs建設情況
我國EHRs的建立起步較晚,從2000年左右開始,逐漸有少量的大型醫療機構使用計算機代替手寫病歷。在2003年非典流行時期,EHRs出現過一次快速興起,由于當時醫院建立了隔離區,無法與非隔離區直接進行物質和信息互換, 很多醫院使用傳真機在隔離區和非隔離區之間交換電子病歷文檔[11]。而國外發展EHRs的時間較早,如美國和日本,從1960年就開始將計算機技術應用于日常的病歷系統中[12~13]。目前最新的研究報告表示,美國公立醫院的EHRs采用率達到了88%[14]。 2017 年,我國也有94%的醫院使用來自電子健康檔案的電子臨床EHRs數據,這些數據最常用于醫院質量改進、監測患者生命體征和衡量組織績效[15]。
我國政府十分重視電子病歷的發展情況,自2002年10月以來,出臺了發展電子病歷、數字化醫療的衛生信息化發展綱要文件《全國衛生信息化發展規劃綱要(2003~2010年)》。在2009年形成了電子病歷的基本框架和出臺相應的標準《電子病歷基本架構與數據標準(試行)》,隨后通過試點、改革、建立分級制度等措施,逐步完善了我國電子病歷的發展機制。2018年發布《電子病歷系統應用水平分級評價標準(試行)》,并要求到2022年,全國二級和三級公立醫院電子病歷應用水平平均分級達到3級和4級。目前,隨著各地醫療機構的電子病歷的建立,互認共享和患者信息脫敏等問題還有待解決。2022年2月,國家衛健委發言人表示,正在研究建立全國統一的電子病歷。歷經初步試點、推廣普及、規范建設,我國電子病歷逐漸向高質量管理方向邁進。
(二)國內外EHRs研究情況
通過對國內外文獻發表的情況進行分析,可以知曉主題的發文情況與趨勢。本文通過伊瑪目阿卜杜拉赫曼本費薩爾大學的電子資源門戶訪問 Web of Science (WOS)核心合集(WOSCC)數據庫,以EHRs為關鍵詞索引外文文獻,并對文獻出版數量進行分析。WOS數據庫是科學和學術出版的選擇性引文索引,涵蓋期刊、會議論文集、書籍和數據匯編,被全球研究學者廣泛認為是最可靠的科學引文索引[16]。而中文文獻采用了CNKI數據庫作為文獻來源,包含了核心期刊:CSSCI,以“電子病歷”“電子健康記錄”和“電子健康檔案”為關鍵詞進行檢索。中英文文獻檢索的時間區間為2000年1月~2022年3月,一共檢索到26 361篇英文文章和1 141篇中文文章,并使用Pyechars進行發文數據分析。
1. 發文量分析
根據2000~2021年的國內外發文量,繪制了國內外發文對比圖,如圖1所示。可以看出,自2000年以來,以EHRs為主題的文章數量逐年增加,特別是近十年來(2010年~2020年)發文量從581篇增長到4 436篇,增長近八倍, 說明了EHRs正不斷獲得國際學者們的關注與研究。特別是,2020年以來,文章數量增長加快,達到一年600余篇的發文量。自2019年起,由于新冠肺炎的影響[17],通過發文趨勢圖可以看出,EHRs發揮了重要的作用,如整合病歷數據、分析致死原因[18]等。

圖1 國內外發文量對比圖
中文發文量從2000年以來呈現了穩步上升的態勢,最高是2021年,發文106篇。從數量上對比,國內發文量不足外文發文量的1/40,且在2014年后國內發文量下降。究其原因,本文進一步整理了國內機構在WOS上的發文情況,如圖2所示。從圖2可以看到,國內學者近些年將相關主題的文章發表在了國外的期刊上,且最高是2021年的278篇,是國內的兩倍多,且2016年后,國內機構外文發文量明顯增多。一方面,說明中國學者也逐漸關注EHRs并將其納入研究范圍,他們將研究成果更多地發表在國際期刊,從而擴大研究成果的影響力,側面反映出我國EHRs建設的有效性。另一方面,隨著技術的不斷發展,近年來EHRs的定義和使用也越來越規范化,但國內缺乏公開和完備的醫療電子數據庫,許多學者更傾向于投稿到國外的期刊,以獲得更廣泛的認可。
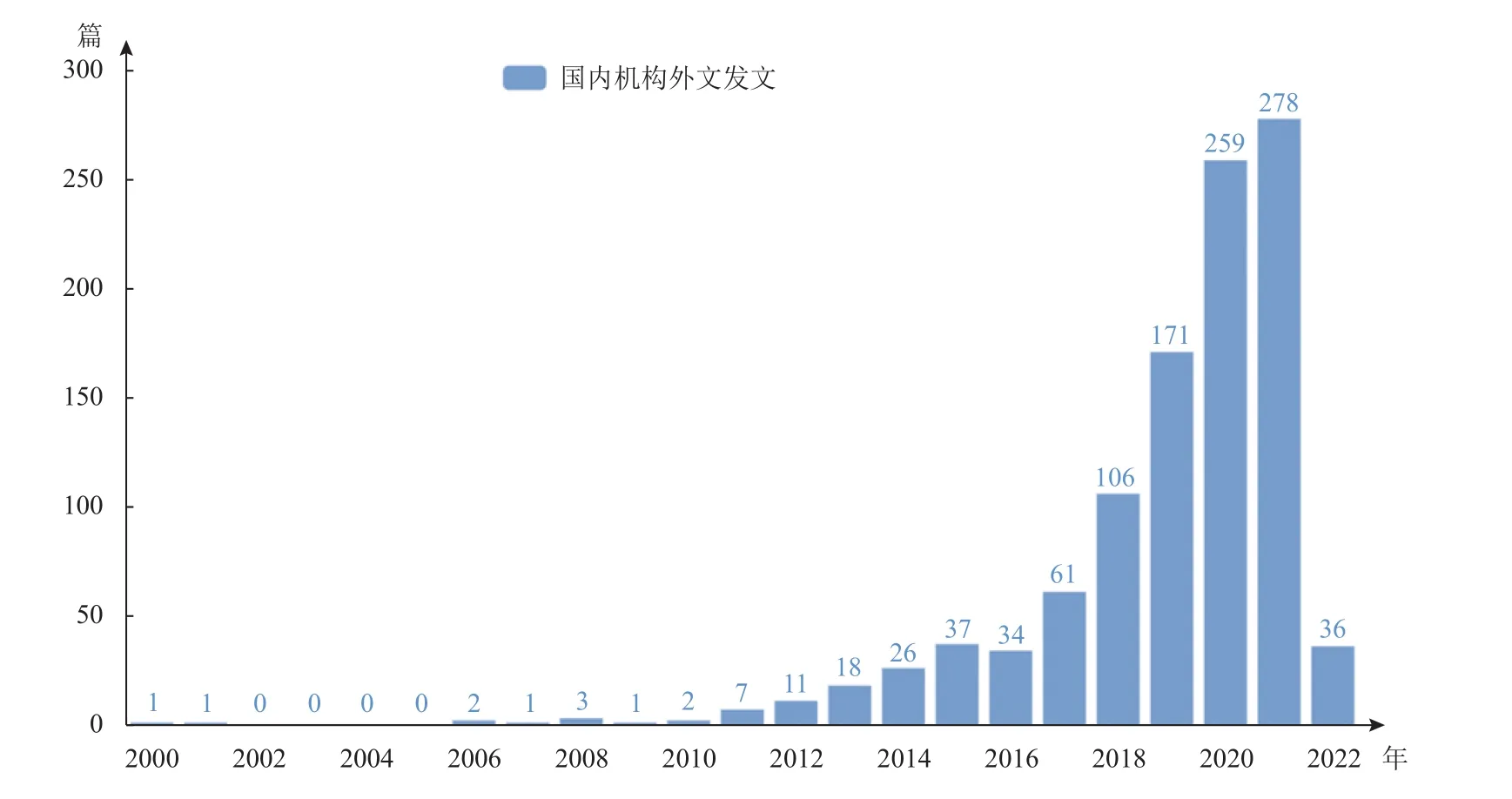
圖2 國內機構外文發文情況
2. 主題詞演化情況
主題詞演化圖能夠清晰地展現研究的熱點趨勢與各個關鍵詞之間的相關性。本文通過對近20年來WOS和CNKI中EHRs相關文獻關鍵詞的提取,選擇了出現頻率最高的5 000個關鍵詞,基于自然語言處理、降維聚類等技術對數據進行處理后,利用Biblioshiny(v1.3.2)進行可視化,將他們按照四個時間段制作成桑基流程圖,如圖3所示。
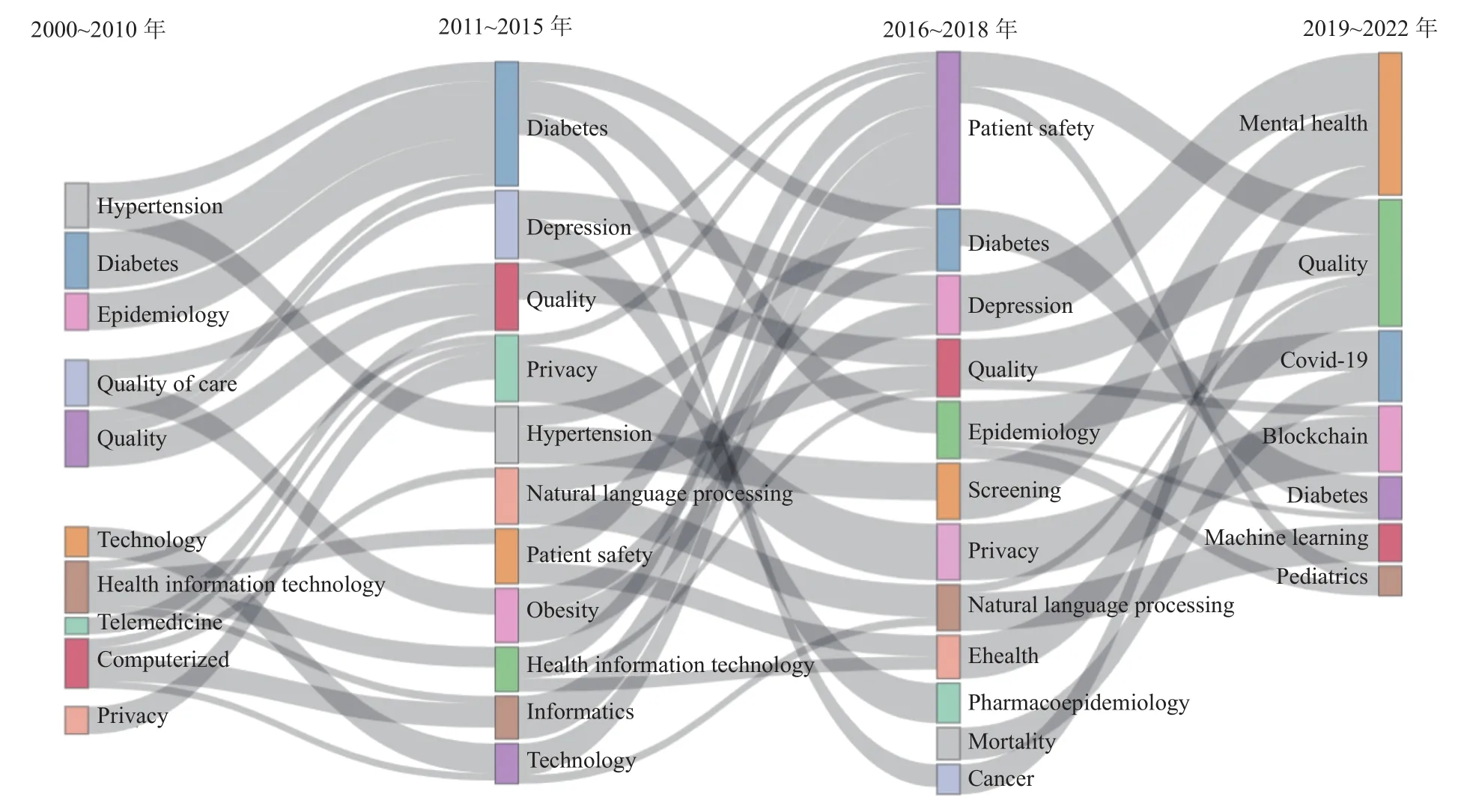
圖3 外文文獻主題詞變化圖
圖3中用灰色路徑表示主題關聯程度,得到了文獻主題的演化圖。可以從圖3中看到,第一個階段(2000~2010)年,hypertension(高血壓)和diabetes(糖尿病)是學者們利用EHRs最愛研究的主題。第二個階段(2011~2015)年,這一時間段出現的主題是上一時期研究過的主題的演變,并且在內容上有聯系,例如diabetes(糖尿病),與上一時期中的hypertension(高血壓)、epidemiology(流行病學)和quality of care(護理質量)等有一定聯系,是研究延續性的體現。除了糖尿病外,depression(抑郁癥)、quality(質量)和privacy(隱私)居于前列,表明研究者們越來越關注與發揮EHRs的作用,提升患者的生活質量和精神狀態。第三階段2016~2018年,患者安全成為最熱門的主題,患者安全包括病人安全、用藥安全、醫療保健安全等方面,是提高醫療質量的關鍵。第四階段(2019~2022)年,隨著COVID-19的爆發,EHRs被用于預測患者死亡率、預測患病人數等[19]。與此同時,區塊鏈與EHRs的結合也成為了新的熱點,區塊鏈能夠很好地解決EHRs中患者隱私的問題。整體而言,主題演化圖體現了基于EHRs的研究主題在時間和內容上的變化情況,能夠更快地把握研究熱點與主題之間的變化,為研究提供方向。
同理,國內文獻主題演化圖如圖4,由于國內文獻數量相對少,本文只劃分了三個時間區間進行分析。第一階段(2000~2010年)的相關研究主要集中在醫院信息系統和社區衛生服務相關研究,此時醫療糾紛問題成為該階段的熱門主題,醫院信息系統的建設備受關注。第二階段(2012~2015年)我國通過試點與改革逐步實現電子病歷的規范化,病案管理也成為這一時期的研究熱點。第一階段至第二階段,在國家信息化建設的發展進程中,病歷模板和居民健康檔案都逐步實現電子化,這一階段的研究熱點也隨之發生演變。第三階段(2016~2022年),利用EHRs進行命名實體識別研究成為熱門趨勢,大數據與人工智能技術也逐漸成為主要研究方向,同時利用EHRs研究新型冠狀病毒肺炎成為了新的研究方向。從第二階段至第三階段可以了解到,EHRs與區塊鏈聯系緊密,區塊鏈獨特的加密技術和去中心化體系能夠有效地保護患者隱私,提高存儲效率。
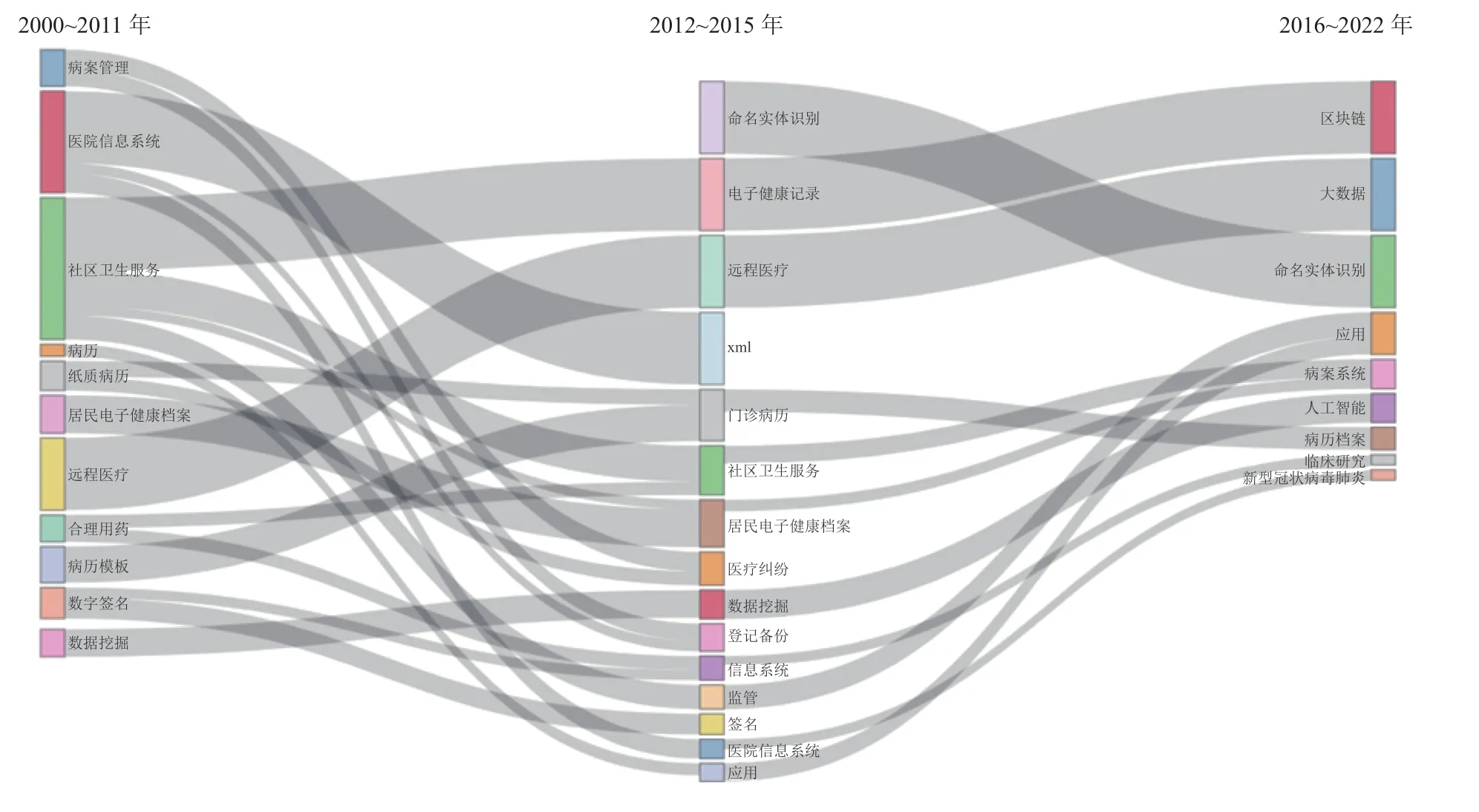
圖4 中文文獻主題詞變化圖
總體而言,醫療檔案與病歷管理等關鍵詞始終是研究的趨勢,EHRs需要借助醫療檔案管理的相關研究進行完善。隨著信息化的發展,大數據與病歷檔案系統、數據庫等主題詞關系緊密,人工智能與數據挖掘聯系緊密,智慧醫療也由醫院信息系統延展而來。通過主題演化圖,能夠了解當下EHRs的主題與之前的主題演化關系,清楚地認識到主題變化的過程。
3. 關鍵詞詞云分析
詞云圖可以直觀展示大量文本數據及其顯著性。以EHRs為主題的論文中使用的關鍵詞隨著年份在不斷變化,尤其是與已經發表了很長時間的論文相比,最近發表的論文更能展現當下的研究熱點。本文根據關鍵詞出現的頻率展現了近三年最熱門的30個關鍵詞,得到了如圖5所示的詞云圖,其中單詞的大小對應著出現頻率的高低。可以從圖5(a)中看出,外文文獻研究中最熱門的關鍵詞集中在machine learning(機器學習)、blockchain(區塊鏈)、COVID-19與privacy(隱私)等。而機器學習則是最熱門的話題,目前也有基于EHRs的外文綜述,分別聚焦于深度學習[2]、疾病診斷[20]等方面進行分析,國內尚且缺乏基于EHRs的智能算法類的綜述文章。

圖5 關鍵詞詞云圖分析
類似地,從圖5(b)中的中文詞云圖可以看出,國內學者的熱門研究點主要在醫院信息系統、數據挖掘和病案管理等方面。該方面的研究多數在如何建立健全醫療電子檔案[21]、醫療電子檔案的共建與分享[22~23]和當下國內電子病歷管理存在的問題[24]等。相比于外文文獻,國內學者更看重醫療信息化方面的研究。一方面,信息化技術將改善醫學數字信息的“孤島”,從而提高患者就醫體驗和醫生工作效率,減少醫患矛盾[25~26]。另一方面,得益于國內政策引導,我國從2011年開始加強了醫療信息化建設的步伐。同時,基于大數據、區塊鏈、深度學習和人工智能等智能技術在EHRs領域的應用也得到了研究者的關注[27~29]。
(三)國內外現有研究綜述
隨著人工智能相關的硬件與軟件的發展,近年來醫療信息化記錄產生的數據被學者們廣泛用于研究。本文梳理了近年來現有的基于EHRs的國內外研究情況,如表1所示。可以從表1看出,現有的國外文獻聚焦于不同的具體發展方向,如自然語言處理、表征學習、疾病診斷等方面的方法綜述,而國內文獻聚焦于文本挖掘與實體識別、檔案建設和疾病篩查等問題。

表1 國內外現有研究綜述
(四)國內外現有醫療電子數據庫情況
數據庫是EHRs的載體,國外特別是美國具有許多健全和廣泛的醫療電子數據庫。而我國已初步建立健康醫療數據庫,但仍存在著諸多問題,如質量差的特征、缺乏統一標準、醫療機構間數據孤島等問題。這些問題部分由于國內數字化起步較晚,多元化數據的整合較少,醫療數據呈現出數量大(因為人口基數大)的特點。
任務型數據庫如Kaggle和UCI中的部分數據庫,由于缺乏病人整體的治療過程和病人基本特征等信息,按照EHRs的定義不在本文的探究范圍。表2展示了部分國內外醫療電子數據庫的情況。

表2 國外現有醫療電子健康數據庫
國外醫療電子數據庫有綜合的急診科ICU數據庫如MIMIC[47]和eICU,也有專科數據庫如SEER腫瘤數據庫和MURA骨科數據庫。其中MIMIC數據庫具有數據量大、存儲格式規范、易讀取等特點,被學者廣泛用來研究。而國內的數據庫存在數據庫種類少、數據類型不夠豐富、存儲不規范不易讀取等問題。隨著云計算和云存儲的發展,EHRs的儲存與讀取問題將會得到改善,有利于學者進行后續的研究[48]。
二、國內外基于EHRs的智能算法發展情況
目前,國內許多醫院都因無法有效地利用EHRs進行數據分析來為他們的臨床實踐生成高質量的見解而苦惱[49~50]。臨床上產生的EHRs必須要加以利用才能發揮其作用,但EHRs儲存的數據必須經過數據提取、分離、清洗等操作后才可為研究所用。針對不同的醫療場景和問題,采取合適的處理方式是解決問題的關鍵,本節將按照不同的智能算法方法對國內外利用EHRs的研究進行綜述。
(一)時序類模型
循環神經網絡(Recurrent Neural Network,RNN)算法通常用于處理時序類數據或文本類數據。RNN算法通過循環神經元,使得一個序列的當前輸出與之前的神經元有聯系,從而向著序列的演進方向進行鏈式遞歸。由于RNN的梯度會隨著時序不斷積累從而出現指數級衰減,存在梯度消失問題,導致RNN的性能受到了制約,無法解決數據的長期依賴問題。LSTM作為RNN的一種變體,能夠很好地處理長期時間序列數據,GRU是LSTM的一個簡化版,具有與LSTM相同性能下收斂更快、參數更少的特點。GRU公式如式(1)給出:
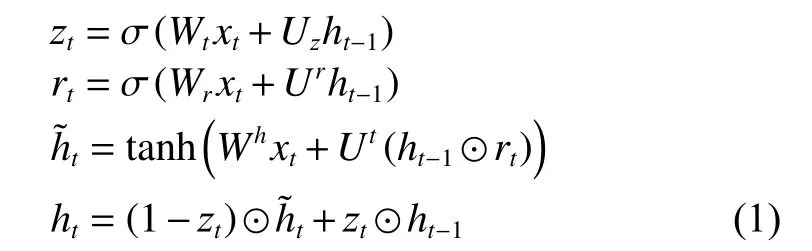
圖6展示了GRU的結構,圖6和式(1)中的xt表示輸入,ht表示隱藏狀態, σ ,tanh 表示激活函數,rt與zt分別表示重置門和更新門。

圖6 GRU網絡結構圖
通常RNN類算法擅長處理時序數據,被廣泛應用于EHRs的研究中,如對病人的死亡風險進行預測[51~53]、病人再次入院間隔[54]、或者疾病預測[55~56]等方面。對于語言類數據,LSTM及其變體常常被用來對醫學文本實體命名以提高醫生查看病歷的工作效率。由于在LSTM模型中,信息只能向前傳播,雙層循環神經網絡BiLSTM很大程度上改善了LSTM對上下文信息的學習。由BiLSTM繼續發展成后來的Transformer和BERT[57]模型,都成為了自然語言處理(NLP)領域同時期的SOTA模型。生物醫學文本挖掘任務的語境化語言表示模型BioBERT[58]也有助于理解復雜的生物醫學領域文本。
BERT類算法存在模型龐大、參數多、收斂緩慢等問題,在實際生產生活應用中還有一定的距離。因此,現階段BERT研究方向多聚焦于在模型性能差異不大的情況下,盡可能地壓縮模型大小[59]。
(二)卷積類模型
卷積神經網絡(Convolutional Neural Networks,CNN)在圖像分類、語音識別和句子分類方面取得了優異的表現。每個卷積神經網絡包含了一個卷積層和池化層,卷積層可以疊加形成深度卷積網絡。卷積層通過滑動核心塊,對輸入數據進行卷積,從而抓住局部的數據特征,一維卷積計算公式由式(2)給出:
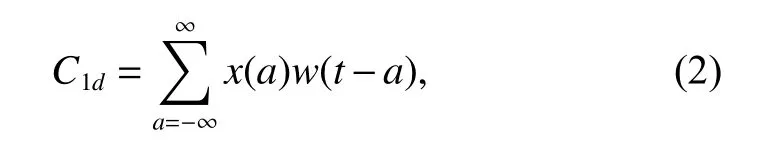
其中x為輸入信號,w為加權函數或卷積過濾器。經過卷積后,需要經過一個池化層以提取主要的數值特征,如最大值、平均值等。
在EHRs中,CNN常用于疾病診斷和風險預測任務中,通過提取數據表征進行學習。Cheng等使用RNN在EHRs中進行表征分析,通過時間-事件的二維矩陣對患者信息進行表征,構建CNN模型進行表征提取和風險預測[60]。CNN也被用來預測EHRs患者死亡率和檢測不良事件[61~62]。在預后護理方面,CNN通過對醫學圖像數據的利用與挖掘,可以實現對乳腺癌患者的藥物反應預測[63]。
CNN主要應用于醫學圖像處理處理。病人的影像學檢查會產生許多圖像數據,如胸透和CT[64~66]等。通過對這些圖像進行學習可以實現自動化的疾病診斷,如甲狀腺癌的篩查[67]等,從而有效降低醫生負擔,同時提高臨床診斷效率。EHRs的文本數據可以輔助醫學診療決策,CNN可以充分利用文本數據實現更好的診療效果。在醫學文本分類任務中,如TextCNN[68]利用預訓練好的詞向量通過CNN進行文本分類,并在兒科疾病診斷中得到了良好的應用[69]。在智能疾病診斷任務中,CNN可與NLP技術相結合[70],充分利用半結構化或非結構化的醫療文本數據,如醫囑、手術記錄、護理記錄、前臺登記數據、既往病史等,實現疾病特征的表征學習和診斷。
盡管CNN在各種診斷任務中都達到了醫生級別的準確度,但模型可解釋性的缺失不利于算法的臨床落地。另一方面,多學科疾病的診斷和更復雜多模態信息下的診斷,也是CNN類算法的研究方向[71]。
(三)生成類模型
變分自編碼器(Variational Auto-Encoder,VAE)[72]和生成對抗網絡(Generative Adversarial Networks, GAN)[73]都是生成模型(Generative model)的代表。所謂生成模型,即能自動生成樣本的模型。可以將訓練集中的數據點看作是某個隨機分布抽樣出來的樣本,如果能夠得到這樣的一個隨機模型,便可以得到這個生成模型,但這個隨機分布需要通過對訓練集的學習來得到或逼近。
由于GAN在實際的生成效果中比VAE更優秀,這里我們只介紹GAN的工作原理。GAN由Goodfellow于2014年提出,是一種兩個神經網絡互相競爭的特殊對抗過程[73]。第一個網絡為生成器G,用于生成數據,第二個網絡為判別器D,用于區分生成器創造出來的假數據。GAN目標函數V則由式(3)給出:
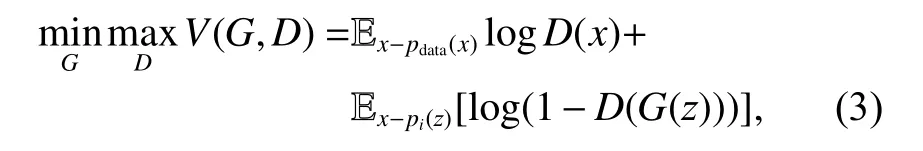
其中,x表示數據樣本,z表示白噪聲,pdata(x)表示生成模型分布,而pz(z)表示噪聲的先驗分布。原始的GAN存在模式崩潰以及難以收斂等問題,WGAN(Wasserstein GAN)將衡量生成器和判別器數據分布之間的距離公式改為 Wasserstein距離[74],它相對KL散度與JS 散度具有一定的平滑特性,理論上可以解決GAN梯度消失的問題。為了使GAN能夠更好地適應卷積神經網絡的架構,DCGAN(Deep Convolutional GAN)通過替換池化層、刪除全連接層和使用批歸一化的方式實現更好的生成效果,進一步提升了GAN的穩定性和生成結果的質量[75]。近年的Lipschitz GAN將辨別器的Lipschitz常數約束為小于等于1,避免了梯度 Uninformative 的問題,其生成樣本的穩定性和質量均優于WGAN[76]。到目前為止,GAN已經有數百種變體,如LSGAN[77]、ACGAN[78]等,以適應不同領域的任務。
GAN十分擅長無監督學習的任務,特別是生成逼真的醫學圖像,如利用GAN對胸腺圖像進行擴增,用于識別胸腺癌,輔助醫生進行臨床診斷[79]。同時得益于GAN的生成能力,可以對醫學結構化數據進行擴增,從而減少由樣本不平衡帶來的訓練誤差[80~81]。由于EHRs數據記錄著患者的隱私問題,導致在數據共享中受到限制。GAN為EHRs數據的可替換性提供了解決方案,通過捕獲多維、異構的數據特征,生成逼真的多模態EHRs數據,降低數據采集和共享的障礙,保護患者的隱私。同時,GAN也可以作為補全缺失數據的方法之一[82],利用GAN學習已有數據的分布特征,利用生成器對缺失數據進行填補,達到比傳統補全方法更好的填補效果。
目前,GAN的發展仍然面臨諸多挑戰,如全局收斂性的證明和對抗樣本的困擾等[83],但GAN依然是生成模型中最具有潛力的模型,未來可以利用GAN模型生成更多高清的醫療圖像輔助臨床醫生診斷。
(四)強化學習
強化學習(Reinforcement Learning, RL)是一種以目標為導向的智能決策技術,它以馬爾可夫決策過程(Markov Decision Process, MDP)為理論基礎,描述了如何根據與環境的重復交互所得到的經驗在順序決策過程中學習最佳策略。MDP通常由〈s,p,a,r,γ〉五元組構成,分別為狀態空間s、轉移概率p、動作空間a、 獎勵函數r和折現因子 γ 。經典的強化學習方法,如Q-learning或其變體,利用迭代計算出狀態的動作價值函數Q,如式(4)給出:
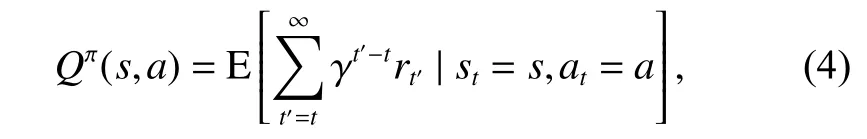
其中, π表示由狀態s和對應動作a構成的策略空間,Q-learning通過最大化累計獎勵達到最終目標。當狀態和動作空間高維且不連續時,Q-learning則無法工作,DQN(Deep Q Network)將RL和深度學習(Deep Learning, DL)相結合[84],利用神經網絡擬合Q值,成功解決了上述問題,但依然存在Q估值過高的問題,DDQN則采用了兩個神經網絡分別估計動作的選擇和動作的評估來消除Q值高估的問題[85]。
在EHRs相關研究中,RL可以為患者提供最佳的個性化治療方案[86~87]。但是傳統的RL方法(如Q-learning)無法解決多維狀態下的決策問題。隨著DL技術的不斷發展和成熟,深度強化學習(Deep Reinforcement Learning, DRL)算法與EHRs相結合的研究取得了許多進展,如使用DQN學習最佳肝素給藥策略[88]、采用DDQN算法建議膿毒癥患者的靜脈注射液和升壓藥劑量[89]、基于DDQN為病人提供最佳的麻醉劑量建議[90]等,這些方法都取得了超越人類醫師的治療效果。DL因其可解釋性問題而存在一定缺陷,研究人員將RL與博弈論結合,在并發癥的治療決策問題中使用夏普利值解釋臨床特征的重要性,為Ⅱ型糖尿病患者建議個性化治療方案[91]。盡管單純的RL方法已經能夠成功地應用于臨床醫療輔助決策,但是智能體通過“探索”“試錯”和“獎勵指導”來學習,可能導致學習到的策略威脅患者的健康,尤其在藥物的相互作用中,決策的安全性尤其重要。為了更安全地提供輔助決策,監督學習可以與強化學習相結合,為患者學習一個更加“安全”的治療方案,以確保處方的低風險性和安全性[92]。
隨著多智能體技術不斷發展,學者們開始將多智能體強化學習應用在EHRs數據中,以支持臨床決策的研究。首先,針對多個醫生會診治療的場景,學者們采用了多個智能體模擬多醫生會診場景,實現對患者關鍵生理指標的最佳控制[93]。其次,由于患者的狀態是多維的,存在治療周期長、治療藥物復雜等問題,在應用強化學習解決醫療問題中,往往面臨著獎勵的稀疏問題。因此,有研究采用了多智能體分層強化學習輔助臨床決策,通過實施具有層級特點的多智能體對策略進行加速學習[94]。
盡管RL在EHRs數據利用方面顯示出可靠的前景,但是在實際應用中還需要考慮諸多問題,如狀態和動作的處理、獎勵函數的制定、智能體的探索策略設計、模型策略的評估和在多智能體強化學習中的信用分配等問題[95]。
(五)區塊鏈技術
區塊鏈技術是一種分布式數據存儲技術[96],它將需要存儲的交易信息通過hash算法編譯成區塊,并通過鏈的形式與其他區塊相連接,具有透明、匿名、不可篡改等特點。
EHRs系統在醫療應用過程中面臨著互操作性差、信息不對稱和數據泄露等問題[97]。區塊鏈因其安全性、匿名性和數據完整性等優勢,使得在其上存儲患者的醫療記錄成為合理的選擇。EHRs數據在上傳區塊鏈后,任何人無法更改和刪除,確保了病人記錄的準確性和唯一性[98],但這項技術需要電子簽名、加密算法、云存儲等技術的支持。電子簽名能夠提高數據訪問的安全性,如多權限電子簽名[99]、基于角色的身份驗證[97]等方式,以增強簽名的不可偽造性。區塊鏈加密算法中的公鑰加密[100]、對稱加密[101]等加密技術增強了醫療數據的安全性,但密鑰的管理成為數據加密的關鍵,為了防止私鑰不被泄漏,采用輕量級的密鑰備份和恢復方案[102]成了不錯的選擇,或使用智能合約授權用戶的密鑰訪問權限[103]來管理密鑰。最后,區塊鏈中EHRs的存儲大都采用云數據庫與鏈下數據庫存儲方式,將原始數據存儲在云端,將數據索引存儲在聯盟區塊鏈網絡中,以降低區塊鏈存儲負擔和隱私泄露風險[104]。
利用區塊鏈技術對EHRs進行數據共享是推廣EHRs研究的關鍵,目前的技術普遍采用智能合約[104]和問責機制[105]等方式,以提高數據共享的私密性,如通過群簽名智能合約實現匿名信息交換[99],從而增強EHRs數據在不同醫療機構之間的流動性,實現醫療數據的便捷共享,以防止數據共享過程中的隱私泄露。
基于區塊鏈技術的EHRs系統可以方便地對患者醫療記錄進行增、刪、改、查和授權訪問,但是區塊鏈技術在應用中還面臨著一定的挑戰,如可擴展性和存儲容量、缺乏社交技巧、缺乏普遍定義的標準。
三、政策與建議
縱觀我國基于電子病歷的研究現狀,不難發現,在推動醫療智能化的過程中,數據的整合、數據的利用和數據隱私問題仍是急需解決的關鍵問題,為此,本文提出如下建議:
1. 規范數據整合,加大醫療信息數據庫的建設力度。雖然我國的醫療信息化建設已在逐步普及,但是由于城鄉醫療資源的差異,醫療數據庫的普及受到限制[23],數據質量不高,數據利用不足[49]。醫療數據庫的標準化建設將為醫療信息管理與利用提供助力,醫療機構應通過數據采集、樣本處理及規范化存儲,實現臨床信息的數據整合、質量控制和數據服務的信息平臺,通過醫療數據實現創新增值。
2. 打破“信息孤島”,建立有效的EHRs數據共享與互認機制。醫療信息的共享將有助于慢性病患者[106]和老年患者[107]的長期治療。目前,我國除少數大城市的大型醫療機構,大部分醫療機構之間的數據都是相互獨立的[108],各級各類醫療機構的醫療信息平臺沒有實現對接,數據難以共享,存在不同的醫療機構之間的化驗結果互不相認等情況。為此,醫療機構應該整合醫療信息資源,統一數據標準,消除數據壁壘,落實數據的共享互認機制,改善資源之間的互通互聯問題,提高數據的互操作性,杜絕“信息孤島”困境,推進數據的整合利用[109]。
3. 開放資源,建立標準的集成公開醫療數據集。對比發達國家的醫療信息管理現狀,諸如美國、英國、丹麥等都有自己的集成的、公開的醫療數據庫,供相關研究人員使用[110]。目前我國的標準集成公開醫療數據庫屈指可數,政府應該組織專業人員整合與建立針對特定疾病或人群的醫療數據集,支持行業領先企業或研究機構在醫療大數據領域的創新與應用研究,利用數據幫助研發人員解密醫學規律、整合醫學知識,實現跨學科的數據交互,為相關疾病研究提供資源,促進智慧醫療技術的進步。
4. 完善醫療信息安全防護體系,做好電子病歷資源數據的隱私保護工作。電子病歷包含患者的隱私信息,相關部門應強化數據安全意識,制定醫療數據采集、存儲、傳輸、共享各個環節的流程規范[111],明確行為邊界和“禁區”。強化醫療信息系統的安全管理,完善數據監測和預警機制,制定醫療信息安全事件的應急措施,盡量避免可能出現的數據隱私風險[112]。在數據存儲中,需充分利用區塊鏈在隱私保護方面的優勢,與現有存儲技術相配合,實現EHRs數據管理與使用過程的可溯源、可追蹤、可把控。在數據共享中,可采用數據生成模型實現EHRs的可替換性,全方位保護患者的隱私。
5. 積極推動智慧醫療研究成果的轉化與落地實施,實現產學研一體化。中科院健康電子研發中心與深圳諾嘉公司共建健康大數據聯合實驗室[50],將基于醫療大數據研究的新技術與新成果轉化為大眾醫療服務的新應用與新產品,實現了個性化與社會化的健康管理。盡管智能算法在理論與仿真實驗中被證明在提升診療水平方面效果顯著,但是新技術、新方法的產業化尚未形成規模,尤其是在利用深度學習技術輔助臨床決策中,神經網絡的可解釋性問題是目前急需攻克的難點,嚴重影響著智能策略的可信度和有效性。
四、結語
智慧醫療是我國《新一代人工智能發展規劃》發展方向之一,基于智能技術的醫療,如深度學習、區塊鏈等,已經成為當前智慧醫療的核心技術。電子病歷的建設與發展為智能技術在臨床醫療中的應用提供了可靠的支撐。盡管我國正在大力推動醫療信息化建設,但對于電子病歷的規范化和標準化方面與其他發達國家還有一定的差距,在醫療數據的開放獲取和數據共享方面存在挑戰。尤其是在我國的醫療發展不平衡情況下,如農村落后于城市、貧困地區落后于發達地區,內地落后于沿海等現狀,限制了醫療信息化水平的穩步提高,合理高效的推廣與研究電子病歷將提升現有的醫療信息水平。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
