基于特征融合與選擇的小樣本表情識別
2022-10-11 12:33:42王從澳黃潤才孫延標孫劉成
傳感器與微系統 2022年10期
王從澳, 黃潤才, 孫延標, 楊 彬, 孫劉成
(上海工程技術大學 電子電氣工程學院,上海 201600)
0 引 言
面部表情識別是計算機視覺領域的一個重要研究方向。近年來,基于計算機的人臉情感識別應用越來越廣泛,如人機交互(human computer interaction,HCI)、商業產品、醫學研究等。在HCI領域,以人為中心的計算機系統不僅能夠根據用戶輸入做出響應,還可以根據用戶行為做出響應。在商業應用領域,如駕駛員疲勞檢測系統、游戲、視頻等娛樂系統。在醫學研究領域,通常用于臨床抑郁癥的識別,疼痛評估以及行為和神經科學的研究。
傳統的人臉表情識別方法依賴于從人臉圖像中手工提取的面部情感特征。應用廣泛的手工特征提取方法包括方向梯度直方圖[1](histogram of oriented gradients,HOG),線性二進制模式(linear binary pattern,LBP),局部相位量化[2](local phase quantization,LPQ)等。Abdulrahman M等人[3]首先提取面部手工特征,然后按順序進行面部動作單元編碼,最后輸入支持向量機(support vector machine,SVM)分類器中進行識別。
在過去幾年中,基于深度學習(deep learning,DL)的技術在解決一系列計算機視覺問題中表現突出,例如目標識別、醫學圖像分析和運動分析等。其中,Jain D K等人[4]提出了一種基于多角度的最優模式深度學習(multi-angle optimal pattern deep learning,MAOPDL)技術,通過使用基于多角度的最優配置對特征集進行適當的對齊,從而克服了照明突變等問題。但是深度卷積神經網絡的訓練依賴大量的樣本數據,因此,針對小樣本的表情識別,往往會出現過擬合現象,嚴重影響模型的識別準確率。
深度學習技術能夠自動提取面部的深層次情感特征,而基于面部界標點的外觀特征能夠提供表情變化期間面部不同關鍵點位置的細節特征。基于此,本文提出了一種融合手工特征[5]和深度學習特征的特征選擇算法,只需要采用少量訓練樣本就能夠實現較理想的人臉表情精準識別。
1 特征融合算法框架
本文提出基于特征融合與選擇算法進行小樣本人臉表情識別,該算法模型包含4個部分,即特征提取模塊,特征融合模塊,特征約簡與選擇模塊和分類模塊。
1.1 算法網絡結構
根據人臉情感表達所涉及的關鍵區域進行68個特征點標記,提取眼睛和嘴巴部位的6個主要特征向量作為人臉幾何特征,同時利用遷移學習的思想通過DenseNet網絡[6]進行學習,提取面部表達的更深層次特征,使用串聯融合的方式對面部幾何特征與深度特征進行融合,生成完整的面部表情特征向量。然后對融合特征向量進行特征約簡和選擇,降低特征向量的復雜性和冗余度。再使用多分類支持向量機(multi-class SVM,MCSVM)做最后的情感分類,識別出7種不同的表情類別。該算法模型的系統流程如圖1所示。

圖1 算法流程
1.2 人臉關鍵區域幾何特征
首先,需要對圖片中的人臉進行檢測,通過Dlib庫函數識別人臉關鍵區域的68個特征點[7]坐標;然后,使用眼睛和嘴巴周圍的特征點進行面部幾何特征提取。選擇眼部靠近鼻子的最近點40#和43#坐標,以及鼻子的最低點34#坐標作為固定點。從固定點出發,計算區域關鍵點到該點的歐氏距離作為情感特征表征值。圖2顯示了68個坐標點,線段表示選擇標記點對的距離。
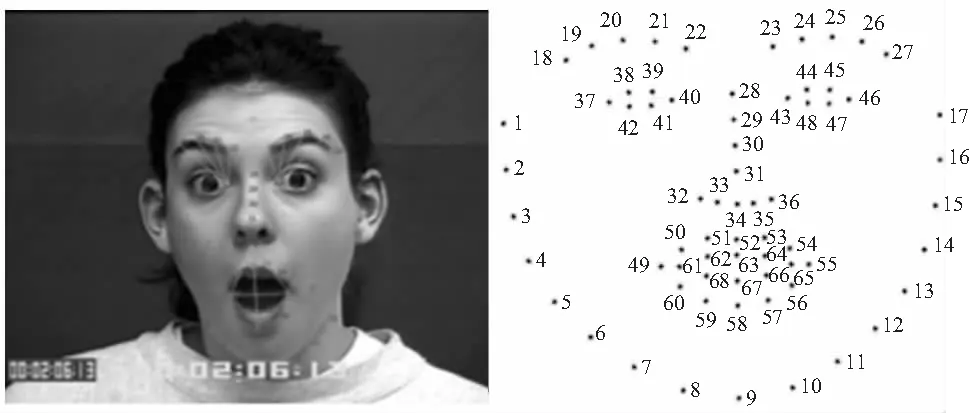
圖2 人臉68個特征點坐標
使用眉毛部位的8個坐標點和嘴巴部位的6個坐標點進行特征值計算,為了減少外界因素影響,本文對各點坐標距離進行歸一化處理。為了規范左眉毛特征表征距離,將所有計算出的距離除以40#和22#坐標點之間的距離。類似地,在右眉上,使用43#和23#坐標距離進行規范化。最后使用34#和52#之間距離標準化嘴巴寬度,嘴巴高度和嘴唇頂部坐標,組合左眉、右眉、左上唇和右上唇的這些歐氏距離以創建包含6個表征值的總特征向量。
首先,計算左眉的歸一化特征向量
(1)
Nleft=D(Eleft1,Eleft2)
(2)
等式(1)表示左眉相關特征值的計算過程,等式(2)表示左眉歸一化距離。其中,Eleft1為40#坐標點,Eleft2為22#坐標點,D(Eleft1,i)為給定兩坐標點(x,y)坐標以計算其歐氏距離,i=[19,20,21,22]。
左唇的特征值表征類似
(3)
Nlips=D(C1,C2)
(4)
式中C1為鼻尖坐標點34#,C2為嘴唇中點52#坐標,i=[49,50,51]。
類似地,使用不同i值,但歸一化距離與左側唇歸一化距離相同。對于寬度(width)和高度(height)值,將分別計算坐標點(49,55)和(52,58)之間的距離,并使用相同的lips值進行歸一化,最后創建總的面部幾何特征向量
Feature=〈Eyeleft,Eyeright,Lipleft,Lipright,Mouthleft,
Mouthright〉
(5)
對于圖像中性姿勢臉和頂點姿勢臉都分別計算方程式(5)中的特征向量,并計算頂點和中性的向量差,作為面部關鍵區域的幾何特征向量。
1.3 深度特征提取
卷積神經網絡(convolutional neural network,CNN)隨著網絡深度的增加,其梯度和層數會越來越深。其梯度在到達網絡的最后一層之前就消失了,該梯度消失問題會嚴重影響神經網絡的學習。ResNets和Highway等網絡使用跳過連接來克服梯度消失問題。但是在小樣本的表情識別過程中,微小的梯度信息在識別中起著至關重要的作用,因此,必須以更復雜的方式保存其梯度信息。
DenseNet網絡通過使用各層之間的前饋連接,從而克服了梯度消失問題。如圖3所示,網絡中,一個塊(block)的每一層都連接著它的后續層,并且所有特征在進入下一個塊之前被串聯起來,因此DenseNet消除了梯度消失問題,通過鼓勵特征復用增強在網絡中的傳播功能,改進了梯度流在整個網絡中的信息傳遞。該網絡模型采用concat的形式進行連接,公式表示為
Xl=Hl(X0,X1,…,XL-1)
(6)
式中Hl為一個組合函數,主要包括BN,ReLU,Poolong,Conv等操作。所有的層輸入來源于前面所有層在Channel維度的Concat。
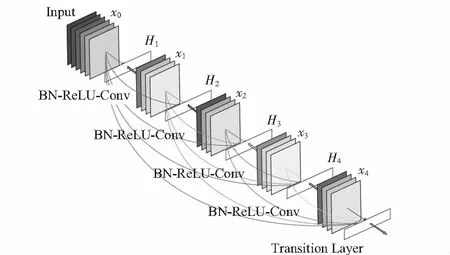
圖3 DenseNet網絡結構
實驗采用DenseNet169進行分類,采用微調技術來加快模型訓練。首先,凍結模型的最初幾層權重,僅訓練模型的最高層;然后,利用2個全連接層對原網絡進行替換。實驗的最小批次設置為256,損失函數為分類交叉熵函數,采用自適應梯度優化算法Adam進行優化,學習率初始化為0.1,每15 000次迭代將學習率除以10,該模型共訓練了20個批次。同時,為了解決樣本量不足的問題,引入Dropout正則化,進而提升模型分類性能和泛化特性。
1.4 特征融合
在人臉關鍵區域的手工特征提取中,為了最大程度讓提取的特征值能夠體現某一特定情緒的特點,算法通過計算人臉“中立”與“巔峰”時刻兩組特征點的歐氏距離作為變量表示采樣點的特征信息。變量轉換如下
β=Tmax-Tmin
(7)
然后將手工提取的特征向量與深度學習的特征向量進行串聯融合[8],并將融合后的特征描述符送入特征選擇模塊進行熵減和選擇。
在上一步提取了DenseNet的最后一個卷積層特征,并利用全局平均池化來降低深度特征的維數。平均池化完成后,將7×7×2 048個特征向量映射到1×1×2 048個特征圖中。因為基于歐氏距離的手工特征和深度特征位于不同的空間,所以,需要將深層特征和手工特征分別進行歸一化,完成后再進行串聯融合,得出4 326個總的特征向量。
2 特征約簡與選擇
針對融合后的特征向量冗余度高、復雜性強等問題,提出一種新的基于熵的特征約簡技術[6]。該技術可以基于高熵值來約簡特征向量,首先,需要計算融合特征的向量熵值,從而給出一個新的熵特征向量;之后,將熵向量按照升序排序并計算其概率值,概率值較高的向量用于支持閾值功能。閾值函數用于根據較高的概率特征值刪除不相關的特征,熵方法的計算定義如下:
記融合后特征向量為ξFd(FV),尺寸大小為ξM×4 096(FV),其中,M表示測試樣本的總數,每個FV(i)和FV(i,j)的熵值計算公式為
E(FV(i))=-∑iP(Fvi)log2(P(Fvi))
(8)
E(FV(i,j))=-∑jP(Fvj)∑iP(Fvi│Fvj)
log2(P(Fvi│Fvj))
(9)
式中P(Fvi)為融合特征向量的先驗概率,P(Fvi│Fvj)為δFd(FV)所有特征的后驗概率,而E(FV(i,j))為熵向量。然后,將E(FV(i,j))進行升序排序,并計算其概率值,從中選擇最高概率(MHP)特征,MHP表示閾值函數,低于MHP值的特征將被丟棄到融合矢量中
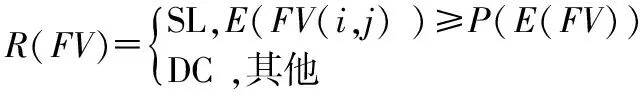
(10)
式中P(E(FV))為MHP值,SL為選定特征,DC為丟棄特征。之后執行CHI2以選擇最佳特征,因為在特征約簡之后,一些不相關的特征仍然保留在約簡向量R(FV)中。因此,選擇一種基于CHI2的特征選擇算法,該方法能夠準確測量特征之間的關聯度
(11)
式中χ2(FV)為選定的特征向量,然后使用MCSVM進行分類。RBF內核函數用于分類。定義如下
K(ξ(i),ξ(j))=exp(-λ‖ξ(i)-ξ(j)‖2)
(12)
式中λ>0,該方法能夠對最佳特征向量進行有效標記和篩選。
3 MCSVM分類器
為了評估算法模型的分類性能,需要對數據集進行10倍交叉驗證[8],并將MCSVM與其他算法分類器進行對比,例如線性SVM(linear SVM,LSVM),三次SVM(cubic SVM,CSVM),精細K最近鄰(fine KNN,FKNN)和加權KNN(weighting KNN,WKNN)等。分類器性能對比指標有正確識別率(correct recognition rate,CRR),靈敏度,假陰性率(false negative rate,FNR),假陽性率(false positive rate,FPR)和曲線下面積(area under the curve,AUC)等。
圖4列出了不同分類算法在CK+數據集上對各類表情的測試CRR,結果表明,MCSVM分類器的平均最大CRR為95 %,與其他分類器相比具有更好的分類效果。
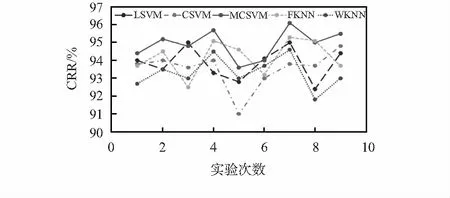
圖4 不同分類算法在CK+上的對比統計
由圖4可知,圖中5 條曲線分別代表LSVM分類器,CSVM分類器,MCSVM分類器,FKNN分類器和WKNN分類器在CK+人臉表情數據集上的9次實驗結果對比圖。從圖中可以看出,MCSVM分類器的平均識別準確率要高于其他四個分類器,因此,MCSVM算法更適用于本文人臉表情的識別與分類。
4 實驗與結果分析
4.1 實驗環境
本文提出的算法模型采用Tensorflow框架進行設計和實現。實驗程序的計算機運行配置為Windows10專業版操作系統,采用i7核心處理器和NVIDIA GE—Force(1070—Ti 4GB—256位)的GPU,內含16GB DDR5 RAM以及64位操作系統等。
4.2 JAFFE數據集實驗結果
為了驗證提出方法的有效性,在JAFFE和CK+兩個著名的人臉表情數據集上對提出的融合算法進行評估,并將識別結果與最新的實驗方法進行對比。
其中,JAFFE數據集是日本ATR機構用于人臉表情識別研究的標準數據集,其中包含213幅日本女性的不同姿態面部表情,表情庫中共有10個人,每個人有7種不同的表情樣本。圖5展示了該數據庫中不同表情的樣本圖像。按照十折交叉驗證的方法對213個數據樣本進行訓練和測試。表1列出了本文融合算法模型在該數據集下的識別混淆矩陣。

圖5 JAFFE數據集中的樣本圖像
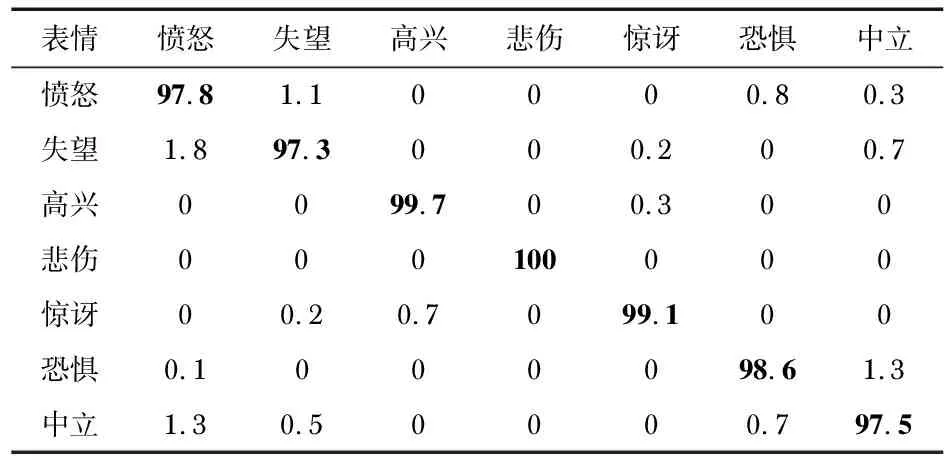
表1 本文融合算法在JAFFE數據集上的混淆矩陣 %
從混淆矩陣中,可以推斷,本文的融合模型在“高興”和“悲傷”表情中表現良好,而在“失望”“中立”和“憤怒”這些情感表達的識別中存在混淆。不過綜合來看,本文算法模型在JAFFE數據集上能夠達到98.57 %的平均識別準確率。
4.3 CK+數據集實驗結果
CK+數據集包含從123個對象中收集的593個圖像序列,每個圖像序列從中性臉逐漸達到表情巔峰。本文對于每一類情感表達的狀態,本文選擇具有峰值信息的最后3個幀作為訓練數據。圖6顯示了CK+數據庫中不同表情的樣本圖像。

圖6 CK+數據集中的樣本圖像
類比JAFFE數據集,本文同樣按照十折交叉驗證的方法對樣本數據進行訓練和測試。表2列出了本文融合算法模型在CK+數據集上的識別混淆矩陣。

表2 本文融合算法在CK+數據集上的混淆矩陣 %
由混淆矩陣可以看出,本文的融合算法對CK+數據集上“高興”和“驚訝”表情的識別準確率最高,能夠達到100 %的識別精度,而在“憤怒”和“中立”表情中容易出現混淆。總而言之,在該數據集上的平均識別準確率能夠高達99.2 %。
表3顯示,本文融合算法(GF)與其他最新算法如SRC(稀疏表達分類)、IL(島嶼缺失)函數、EB/OL(電子文獻)、SIFT-AVG(平均特征匹配)在JAFFE和CK+數據集上的性能對比,對比結果顯示,較單一的手工特征提取和深度學習特征提取,本文的特征融合算法能夠顯著提升模型的識別能力。其中,基于熵的特征約簡和選擇技術大大降低了模型參數和計算復雜度等,有效提升了網絡的識別效率和識別準確率。
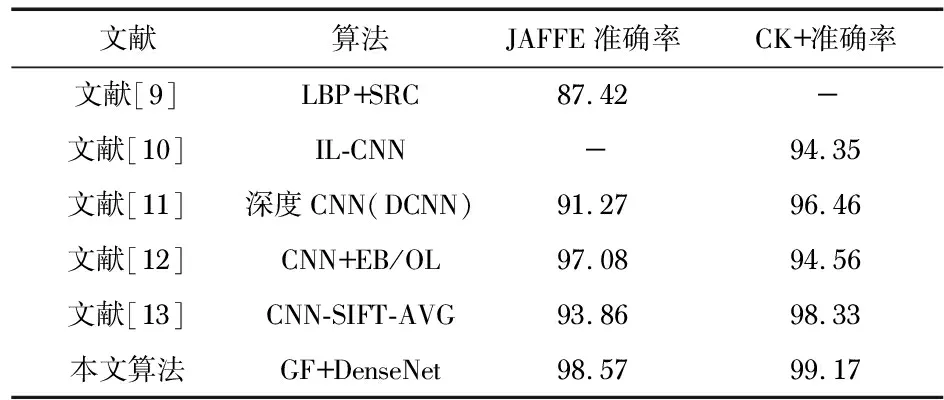
表3 不同算法在JAFFE和CK+上的性能對比 %
5 結束語
本文提出了一種基于特征融合與選擇的人臉表情識別算法,該算法融合了手工提取的人臉關鍵區域幾何特征和DenseNet網絡提取的面部深層次情感特征,然后利用一種基于熵的特征約簡技術對融合后的特征向量進行降維,并使用MCSVM進行表情分類。利用標準的小樣本數據集JAFFE和CK+對所提方法進行實驗評估,結果顯示,該融合算法優于許多現有的深度學習算法,能夠在樣本量較小的前提下,進一步提升表情識別的準確率。
下一步的研究計劃將在本文融合算法的基礎上繼續改進算法體系結構,使其具有更廣的泛化能力和魯棒特性,能夠適用于視頻數據[14],3D人臉數據集和深度圖像數據等。并努力探索更好的深度學習算法來增強網絡的識別性能。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
