基于音節切分的藏文印刷體識別
2022-10-01 03:47:16才讓當知華卻才讓黃鶴鳴
計算機工程與設計 2022年9期
才讓當知,華卻才讓+,黃鶴鳴
(1.青海師范大學 計算機學院,青海 西寧 810008;2.青海師范大學 藏語智能信息處理及應用國家重點實驗室,青海 西寧 810008;3.青海師范大學 藏文信息處理教育部重點實驗室,青海 西寧 810008)
0 引 言
藏文文獻資料非常豐富,但是可用的電子化信息資源非常少。隨著藏文信息處理技術的發展,需要對大量的藏文文獻電子化。人工鍵盤錄入是一項繁重且低效的解決方式,充分利用文字識別技術將會大幅提升藏文文獻電子化的效率,并且把人從繁重的重復工作中解放出來。與中文、英文等主流文字相比,藏文印刷體識別研究起步相對較晚,缺少高質量的標注數據集,文本圖像的分割相對困難,因此,印刷體藏文識別效果相對較差,落地使用的產品較少。
在國內,印刷體藏文識別方法已經從傳統的特征匹配方法[1],發展到了現在的基于神經網絡模型的識別方法,并達到了應用的水平。在國外,Kojima M.等提出了基于字典匹配的印刷體藏文字識別方法,可以識別相似字符[2]。Zach Rowinski等研究了圖像二值化、文本圖像切分、特征提取、識別等問題,開發了藏文OCR系統NAMSEL[3],該系統首先使用SVM進行識別,之后采用隱馬爾科夫模型對識別結果進行微調,完成識別。
以上文獻中,都采用字丁作為切分單元,而且每個文獻報道的字丁個數不同。合法的藏文字丁有1000多個,如果忽略使用頻率極低的字丁,用于識別的字丁數遠小于這個數字。公保杰和陳洋在各自開發的識別系統中,分別選用了563個和584個字丁[4]。以字丁為單元進行識別時,類別數目少,有利于分類器訓練;但缺點也比較明顯:一是相似字丁多,降低了分類性能;二是元音符號和弱音節符會導致字丁之間的筆畫粘連,影響到文本圖像分割,從而影響識別效果。為了有效解決以字丁為識別單元引起的缺陷,本文提出了以音節為識別單元的藏文印刷體識別方法。相比于藏文字丁的個數,藏文音節的個數較多,經過詳細推算,才丹夏茸認為藏文有17 532個音節;而多拉通過預料統計認為藏文有18 088個音節[5]。本文中音節的個數為19 450。
1 預處理
受光照不均等環境因素影響,得到的文本數字圖像往往存在質量較差、受噪聲影響大以及傾斜等現象。為了提高識別效果,需要對圖像進行二值化、傾斜矯正和規范化等預處理。
1.1 二值化
本文采用局部自適應二值化提取文本的輪廓和邊界信息,主要過程是:先將圖像平均分成若干塊;然后,分別計算每個塊的平均閾值[6];最后,對圖像進行二值化。
分別用P(x,y) 和p′(x,y) 表示局部自適應二值化前后像素 (x,y) 的灰度值,則

(1)
式中:閾值T(x,y) 是以 (x,y) 為中心、r為半徑的窗口內所有像素的平均值,即
(2)
二值化前后文本數字圖像的效果對比如圖1所示:由于受光照不均的影響,原圖右側存在明顯的陰影,如圖1(a)所示;經過局部自適應二值化,消除了受光照不均導致的陰影,有利于后續文本圖像的分割,如圖1(b)所示。

圖1 局部自適應二值化
1.2 校 正
傾斜的文本數字圖像會導致其中的待識別字符也存在一定程度的傾斜,影響文本圖像的分割和識別效果,因此,需要傾斜校正。本文采用霍夫變換進行文本圖像的自動校正。首先,將圖像平面上的像素點 (x,y), 通過公式
ρ=xcosθ+ysinθ
(3)
映射到參數空間中,圖像平面上一個點對應參數空間中的一條曲線。其次,由霍夫變換原理,在參數空間平面曲線相交最多的點,對應圖像平面上的直線,如圖2(a)所示。最后,文本數字圖像需要向相反的方向旋轉θ,其中θ表示直線與水平方向的夾角;當檢測到多條直線時,取平均值,則旋轉校正更準確,旋轉校正結果如圖2(b)所示。

圖2 霍夫變換矯正
1.3 規范化
經過行切分和列切分,得到待識別的字符圖像,但這些字符圖像的尺寸往往有較大差別,并且圖像上下邊緣存在不同程度的空白,如圖3(a)所示。因此,需要刪除空白并調整字符位置,統一圖像尺寸[7]。根據藏文字形結構特點,對音節文本圖像進行兩步規范化:第一,刪除上下空白部分;第二,統一將音節文本圖像的尺寸歸一化為48×32。規范化后的結果如圖3(b)所示。

圖3 規范化
2 藏文印刷體文本圖像分割
首先對藏文印刷體文本圖像按行分割,然后在此基礎上進行按字丁和音節分割。根據藏書寫特點,選擇分割更容易的文本識別單位。最后采用所設計的藏文印刷體分割技術構建由于神經網絡訓練的印刷體標注數據庫。
2.1 行切分
和漢文以及英文相比,藏文書寫有一些顯著特點:①所有藏文字符都以基線對齊[8];②藏文的字間距和行間距更小;③元音符號可能使前后兩個字符或上下兩個字符粘連,如圖4所示(橫縱坐標單位為像素);④字體過大時,字丁和元音之間的距離增加,增大了行切分的難度[9],如圖5所示。因此,印刷體藏文文本圖像的分割更具有挑戰性。
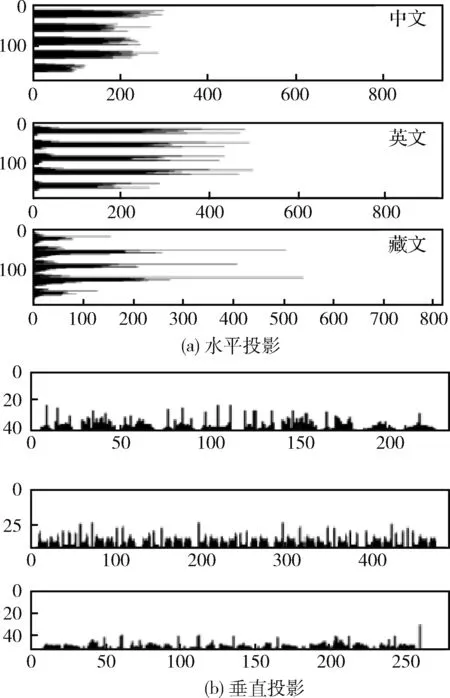
圖4 文本投影

圖5 藏文基線
當字體較大時,元音和輔音之間有一定的間距,因而它們會被當作兩個獨立的連通域,導致分割錯誤。如果適當填充元音和輔音之間的空隙,可減少對行切分的影響。同時,本文采用對字符間的空隙敏感度較小的投影分割法:遍歷每一行,得到的最大連續像素數為行高,按照這個行高進行行切分。投影分割法能有效避免被分割成多個區域的情況,分割結果如圖6所示。矩形框是藏文文本行的外接框,4個頂點是文本行在整體文檔圖像上的位置,分割時取4個點的坐標即可。

圖6 行分割
2.2 音節切分


圖7 藏文字丁/音節示例

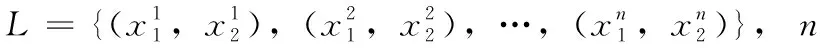

最后,通過確定 (y1,y2,x1,x2) 4個點的取值按音節分割,其中 (y1,y2)、 (x1,x2) 分別是垂直與水平方向上裁剪的起始位置和終止位置。由于輸入是行文本圖像,垂直方向上分割的起始位置為行邊界,終止位置是行高度,因此每個音節的 (y1,y2) 兩個點取值為 (0,h)。 水平方向上分割的起始位置和終止位置 (xi,xj) 由l′得到,通過遍歷按音節分割,算法的流程如圖8所示。

圖8 音節切分流程


圖9 按列分割
2.3 分割實驗


表1 藏文字丁分割準確率(字體:喜馬拉雅)/%


表2 藏文音節分割準確率(字體:喜馬拉雅)/%

對比表1和表2可以看出:①按字丁為單元分割時,隨著字號變小,分割準確率下降明顯,并且二值化閾值差值較大;②以音節為單位分割時,準確率與字號變化關系不大,二值化閾值從原來的160調整為180,閾值差只有20;③由于藏文書寫的特點,字丁受更多的藏文字符構件的干擾,比音節分割難度程度更大。與按字丁分割相比,按音節分割準確率提高了3.95個百分點,說明以音節為單位分割效果更穩定。
3 分類器的設計與實驗
為了驗證音節比字丁更適合作為印刷體藏文的識別單位,本節首先構造了隱藏層數為3的卷積神經網絡模型為識別驗證模型,最后將識別效果優的模型進行優化。
3.1 卷積神經網絡
卷積神經網絡是深度學習中最成功的一種模型,特別適合處理多維數據結構,被廣泛應用于計算機視覺[10,11]、自然語言處理鄰域[12]等領域。本文的分類器采用卷積神經網絡,它由輸入層(Input layer)、隱藏層(Hidden layer)、全連接層(Full-connected layer)以及輸出層(Output layer)不斷堆疊構成[13]。本文在輕量級的LeNet-5網絡的基礎上進行改進,網絡結構如圖10所示。使用3×3的卷積核在歸一化后的特征圖上遍歷提取特征,其次使用2×2卷積核進行池化。池化分為最大和平均池化。最大池化能更多地保留紋理信息,而平均池化能更多地保留圖像的背景信息。因此本文中采用最大和平均交替式的池化,并將網絡隱藏層增加到了7層。當神經網絡層堆疊過多時容易發生過擬合現象,所以采用Dropout丟棄一部分訓練參數,可以有效緩解過擬合的發生[14]。當訓練神經網絡模型時Dropout=0.5。

圖10 LeNet-5網絡模型
將得到的音節特征圖像展開為一維向量,輸送到輸出層,通過Softmax函數計算樣本屬于每一個類別的概率,實現分類任務,如式(4)
(4)
其中,sj為表示當前元素的指數與所有元素指數和的比值。zj是分類器前層單元的輸出,j表示類別索引位置,k為類別總數。
3.2 數據集
收集高覆蓋度的文本語料,將其打印掃描保存為文本圖像,對文本圖像以音節為單位進行分割,并對圖像音節進行標注,得到共19 450個音節的132 500個樣本,這些樣本構成藏文印刷體音節圖像數據庫。同時,構建共626個字丁的30 500個樣本,這些樣本構成藏文印刷體字丁圖像數據庫。上述兩類數據庫中,除了基本的字丁和音節外,還包括一些常用的梵文。
3.3 識別實驗
分別以字丁和音節為識別單元,在卷積神經網絡模型上做對比識別實驗。以字丁為識別單元時,訓練卷積神經網絡模型的主要參數見表3。

表3 基于字丁的LeNet-5網絡模型參數
字丁的類別較少,當模型迭代1000次時,在訓練集上,識別率已達99.67%,如圖11所示;并且,在學習特征的過程中,模型訓練損失值的下降沒有出現非常明顯的上下波動,說明訓練過程非常穩定;迭代1000次時訓練損失值基本傾向于0,如圖11所示。

圖11 基于字丁的LeNet-5網絡模型準確率/損失值

音節的數量遠多于字丁,以音節為單元訓練卷積神經網絡模型時,直接采用字丁的訓練參數則無法達到同樣的識別率,見表4。當迭代次數為1000時,訓練識別率僅達到了57.4%;不改變其它參數而僅僅提高迭代次數,則準確率隨著迭代次數的增加在遞增;當迭代次達10 000時,訓練識別率達到了97%,如圖12所示。

表4 基于音節的LeNet-5網絡模型參數

圖12 基于音節的LeNet-5網絡模型準確率/損失值
音節類別是字丁類別的30倍,遠多于字丁。因此,當迭代次數為10 000左右時訓練損失值才基本平緩并且基本接近于0,如圖12所示。當其它參數不變時,基于音節的模型需要更多的迭代次數來學習特征,這個迭代次數是基于字丁的識別模型的10倍。
分別訓練好基于字丁和基于音節的卷積神經網絡識別模型后,對印刷體藏文文本圖像進行開放測試,測試字體均為喜馬拉雅,見表5。可以看出,基于音節的識別模型比基于字丁的識別模型高出21.52個百分點。說明音節文本圖像比字丁文本圖像包含著更多的字符特征信息,而這些輔助特征信息在識別中發揮著重要的作用。

表5 識別單位測試
確定音節為識別單元后,對網絡模型從池化方式、參數和卷積層層數等方面進行優化,最終提出了基于LeNet-5網絡的印刷體藏文識別模型,采取參數見表6,訓練集上最高識別準確率為99.8%。

表6 最優參數
目前沒有公開的藏文文本識別測試數據集,因此,本文構建了涉及藏文歷史、人物傳記、小說和新聞等內容的測試數據集,共有4076個音節。在這個數據集上本文所提出的方法,其平均識別正確率達96.11%,見表7。

表7 開放測試

4 結束語
結合藏文字形結構特點,提出了基于音節切分的藏文印刷體識別方法。通過實驗發現,本文提出的藏文印刷體識別準確率比基于字丁的識別方法高21.52個百分點。并在包含4076個音節的印刷體藏文文本圖像測試集上,本文方法的平均識別率達96.11%,結果表明以音節為單位的識別模型更有效。
未來工作中,將對已構建的標注數據集進行擴充,并引入自動文字檢測技術,嘗試端到端的藏文文本檢測與識別。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
