基于生成式自監督學習的太陽能電池板缺陷檢測
2022-09-30 08:49:04凌旭峰周麗婕楊紅衛
機械制造 2022年7期
□ 凌旭峰 □ 周麗婕 □ 祝 毓 □ 楊紅衛 □ 楊 杰
1.上海師范大學天華學院 上海 201815 2.上海圖書館(上海科學技術情報研究所) 上海 200031 3.上海志良電子科技有限公司 上海 200072 4.上海交通大學圖像處理與模式識別研究所 上海 200240
1 研究背景
隨著光伏發電技術的日益成熟,我國逐步采用太陽能這種安全清潔的能源。光伏發電已經成為我國新能源發展的重要領域,并可以戰略性地解決潛在能源危機和環境污染問題。光伏發電應用的核心部件是太陽能電池板,生產工藝復雜,容易產生缺陷。在生產和使用過程中,檢測并替換有缺陷的太陽能電池板,能夠顯著提高發電效率,延長太陽能電站的使用壽命。
目前,太陽能電池板缺陷檢測方法主要分為人工目視檢測、物理檢測、機器視覺檢測三種。
人工目視檢測方法由專業人員通過可見光相機或紅外相機拍攝的太陽能電池板圖像來判斷是否存在缺陷,需耗費大量人力資源,且檢測效率低,對于不同的缺陷存在嚴重的主觀意向,已處于逐漸淘汰階段。
物理檢測方法指使用聲波、紅外、激光掃描、共振超聲振動等方法檢測太陽能電池板的缺陷。王亞麗等[1]設計了一種基于紅外熱像技術進行太陽能電池板缺陷檢測和分類的方法,可以根據常見的黑片、斷柵、隱裂、碎片等缺陷,提取紅外圖像平均灰度值差、長寬比、邊緣曲率等特征,進行缺陷檢測。試驗表明這一方法能夠檢測定位缺陷,并對缺陷進行正確分類。白愷等[2]根據晶硅光伏組件缺陷形成機理,提出了一種適用于現場應用的缺陷光伏組件檢測方案,包括紅外熱成像排查、絕緣電阻測試、電致發光測試、光伏組件特性測試,鑒別光伏組件缺陷的產生原因及對發電性能的影響。施光輝等[3]提出通過電致發光測試技術發現電池組件的黑心、黑斑、隱裂、斷柵等缺陷,結合光伏組件電壓電流特性曲線,確定電池組件是否存在缺陷。楊瑞珍等[4]提出了電磁感應主動激勵下晶體硅光伏電池紅外熱成像缺陷檢測方法,具有檢測靈敏度高、可發現內部缺陷、檢測缺陷種類多等優勢,在脈沖式和鎖相式兩種激勵模式下獲得并處理硅電池熱成像序列,實現晶體硅光伏電池中熱斑、裂紋、斷柵、重摻雜等缺陷的可視化檢測。石磊等[5]基于太陽能電池電致發光原理,設計了電致發光缺陷檢測單元,通過機器視覺系統采集數據,生成光伏組件電致發光圖像,輔助人工完成光伏組件的缺陷檢測,減輕疲勞等人為因素對檢測結果的影響。
相比物理檢測方法,機器視覺檢測作為一種新的檢測方法,具有髙效、精確、實時、靈活、非接觸、遠距離測量等特點。隨著信息處理軟硬件技術的不斷發展,機器視覺檢測方法優勢日益顯著。機器視覺檢測方法主要具有三方面優勢。第一,檢測速度快,僅需幾百毫秒。第二,應用部署靈活,可以根據不同的環境進行配置,以滿足用戶要求,實現遠程檢測操作。第三,檢測精度高,檢測標準化、一致性不斷完善。孫海蓉等[6]提出了一種深度卷積自編碼網絡模型,用于小樣本光伏熱斑的識別與定位,自動學習并提取小樣本圖像中的有效特征。試驗結果表明,針對小樣本光伏熱斑圖像數據集,這一方法相比傳統卷積神經網絡識別準確率提升7.98%,并具有更強的泛化能力和穩定性。都胡平等[7]提出了一種在生產過程中檢測電池片破損的方法,采用Sobel算子檢測圖像邊緣,計算電池片偏轉角度,基于角點檢測法檢測電池片是否已破損。試驗結果顯示,這一方法的精度較高,能夠檢測出電池片串焊過程中的位置偏轉、破損等問題。陳鳳妹等[8]設計了一種基于深度學習的太陽能電池板缺陷檢測模型,在SegNet網絡框架基礎上使用空洞卷積代替池化層,增大感受野,并保留圖像邊緣信息。這一模型可以明顯提高檢測的準確率。鄧堡元等[9]提出了一種基于光流法處理光伏電池熱流場的熱圖像序列分析方法,可以準確找到異常發熱源,并與短波紅外成像找到的異常發光源融合,通過深度卷積神經網絡,實現對光伏電池內部缺陷與劃痕、覆蓋、裂紋、缺損等人工缺陷的有效識別。試驗結果表明,這一方法在卷積網絡訓練中能更快收斂。周得永等[10]采用YOLOv3算法對太陽能電池板電致發光圖片進行缺陷檢測,在測試集中精度均值達到81.81%。試驗結果表明,YOLOv3算法對于含有斷柵、隱裂缺陷的太陽能電池板能夠實現比較準確的檢測。劉懷廣等[11]建立了一種特征增強型輕量化卷積神經網絡模型,設計特征增強提取模塊,提高弱邊界的提取能力,同時根據多尺度識別原理增加小目標預測層,實現多尺度特征預測。試驗測試中,這一模型的精度均值達到87.55%,相比傳統模型高近7個百分點,并且滿足精準性與實時性的檢測要求。
現有基于監督學習的機器視覺檢測方法有三個缺點。一是需要對缺陷位置進行精確定位,才能實現缺陷識別,而缺陷定位難度較大。因為缺陷是開放性的,局部缺陷和全局缺陷屬于同一類缺陷,如一條長裂紋中有間斷,是定位為一條長裂紋還是兩段短裂紋,由此產生缺陷檢測定位兩難問題。二是需要數據人工標注數據集支持,并在數據集中進行大量訓練,才能獲得訓練收斂的模型。數據集需要人工標注,既耗時又昂貴,在特殊領域,如醫療領域樣本標注極其昂貴,由此成為人工智能發展的瓶頸。三是數據標注會導致信息損失。一幅圖像所包含的信息非常豐富,除被標注對象之外,還有背景信息、次要目標信息等,而單一的訓練任務僅提取圖像中的標注信息,忽略其它有用信息。由于信息損失,導致監督學習模型的特征提取能力扭曲,泛化能力較差。
自監督學習方法可以克服監督學習方法的缺點。自監督學習分為判別式自監督學習和生成式自監督學習兩種類型[12]。典型的判別式自監督學習方法是對比學習,主要思想是通過自動構造相似實例和不相似實例,獲得一個特征表征的學習模型,使相似實例在投影空間聚集,使不相似實例在投影空間分離[13-14]。采用生成式自監督學習方法,訓練一個深度學習模型,以重建被遮蓋的部分圖像。訓練收斂的重建模型類似于一個圖像編碼器,具有圖像特征提取能力。筆者提出一種基于生成式自監督學習的太陽能電池板缺陷檢測方法,能夠避免像素級復原,在顯著減小運算量的同時提取圖像全局和細節特征,實現較好的缺陷分類識別效果,并且穩健性佳,具有較強的泛化能力。
2 原理
2.1 作用
生成式自監督學習方法可以提取工業產品的表面缺陷,應用于缺陷檢測領域,有四方面顯著作用。
(1) 相比傳統方法,生成式自監督學習方法通過自注意力模糊定位缺陷所在位置,避免缺陷精確定位的難題,不需要顯性判別缺陷位置即可檢測缺陷,適合檢測開放性缺陷。
(2) 生成式自監督學習方法可以對未標注數據集構造自監督任務進行訓練,生成特征提取模型,不需要使用人工標注的大樣本數據集,可以極大減小人工標注工作量,降本增效。
(3) 使用生成式自監督學習方法,在完成特征提取模型訓練后,與有監督模型相比,可以捕捉數據集特征局部細節特征和全局語義特征,模型具有很強的特征提取能力,并且只需要使用對少量標注典型缺陷樣本訓練的一個分類器,就可以達到不錯的分類效果。
(4) 生成式自監督學習方法采用雙通道方式訓練模型,避免從像素層面恢復原始圖像,減小運算量,可以應用于實際工業生產。語義生成式自監督學習方法具有普適性,可以應用于大范圍工業表面檢測,有非常廣泛的應用前景。
2.2 模型架構
生成式自監督學習方法采用雙通道方式來訓練模型[15]。第一個通道使用離散變分編碼器對輸入圖像進行編碼[16],形成輸入圖像的第一種表征方法,即圖像編碼表征。第二個通道將圖像輸入一個視覺變換器的主干網,并采用遮蓋模型,要求模型具有獲得復原被遮蓋圖像塊的能力,進而形成自注意力表征[17]。為了避免像素級復原而導致的大運算量,使用一個全連接分類網絡,將自注意力表征映射為編碼表征,進而將像素級遮蓋復原任務轉換為遮蓋編碼復原任務。這一方法在實現良好圖像特征表達的同時,減小像素級表達的運算量。模型的預訓練過程是不斷訓練視覺變換器和全連接網絡參數的過程,使遮蓋復原編碼與原始圖像編碼之間的誤差盡可能小。
模型架構如圖1所示。
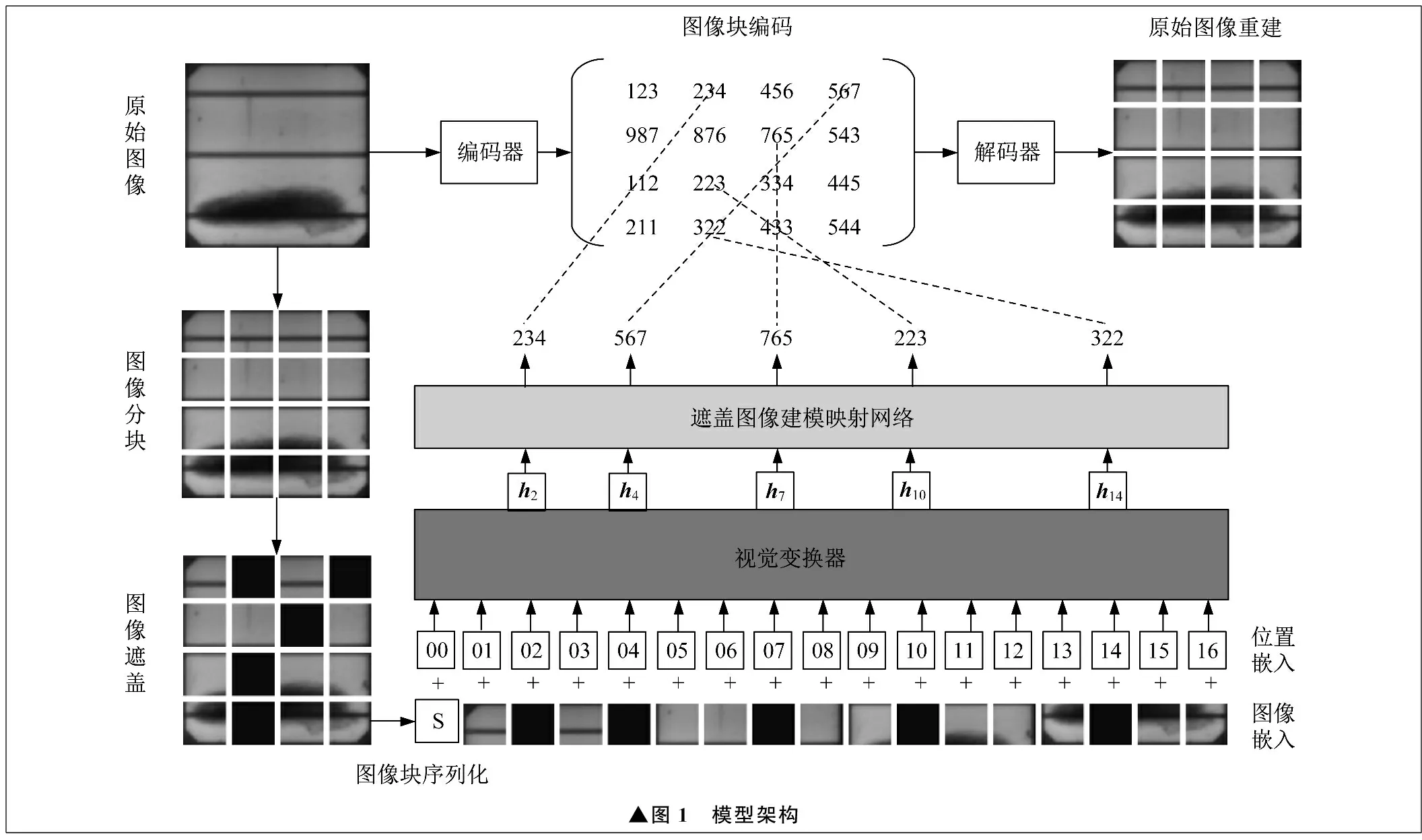
▲圖1 模型架構
2.3 圖像分塊
將高為H,寬為W,通道數為C的數字化輸入圖像標記為X,X∈RH×W×C。R是一個高維張量,每個分量對應不同位置像素在不同通道的值。將圖像X分割為多個圖像塊,設圖像塊的高和寬均為P,則圖像X可以分割為HW/P2個圖像塊。舉例而言,輸入圖像的高和寬均為224,將P設為16,則圖像可以分割為196個圖像塊。將這196個圖像塊堆疊起來,由此形成長度為196的圖像塊張量。
2.4 圖像離散編碼通道
模型使用離散變分編碼器和解碼器對圖像進行編碼和解碼。編碼器和解碼器都由深度殘差網絡組成,需要通過訓練得到。為圖像建立一個詞匯表,詞匯表詞典長度為8 192個詞,詞典均勻離散分布。使用離散變分編碼器對圖像中的每個圖像塊進行編碼,將圖像中的每個圖像塊均映射至長度為8 192個詞的詞匯表詞典中的碼字。輸入圖像X分割為196個圖像塊,輸入編碼器,得到196個離散編碼,每個編碼的取值在0~8 191之間,于是輸入圖像轉換為長度為196,取值為0~8 191的數組。離散變分編碼器可以極大壓縮圖像,提取圖像特征。解碼器使用196個碼字重建原始圖像,重建圖像的優劣標志著編碼器特征提取能力和生成能力的強弱。
2.5 視覺變換器主干網通道
在196個圖像塊的最前方,疊加一個附加的可以學習的類別標志,用于綜合整個序列的語義信息。整幅圖像看作由196個單詞構成的一段話,圖像識別可以看作是對這段話的語義識別,隨后連接嵌入映射層。將包含類別標志的序列通過預歸一化層輸出至12個串接的視覺變換器模塊序列,每個視覺變換器模塊由注意力層、前饋層、跳接并聯、Dropout層等組成。通過一個全連接層,實現分類功能,作為下游任務。生成式自監督學習方法通過遮蓋圖像建模任務來對網絡進行預訓練,隨機遮蓋輸入圖像塊序列的40%,如輸入16個圖像塊,遮蓋5個圖像塊,在遮蓋后的序列疊加位置嵌入編碼,經過嵌入層嵌入后,輸入視覺變換器,由復原法重建被遮蓋的40%圖像塊。圖1中,全黑的方塊是被遮蓋的圖像塊,輸入視覺變換器后,被遮蓋圖像塊的輸出預測嵌入向量值h2、h4、h7、h10、h14,接入后續全連接層。
2.6 全連接網絡訓練
視覺變換器主干網輸出完整的196個圖像塊嵌入向量值,只需取出被遮蓋的預測嵌入向量值h2、h4、h7、h10、h14,沒有被遮蓋的可以丟棄。隨后再訓練全連接網絡,網絡輸入為h2、h4、h7、h10、h14,輸出被遮蓋圖像塊的編碼。網絡訓練目標要求輸入重建圖像塊編碼與對應原始圖像塊編碼之間的誤差盡可能小,通過梯度下降法不斷迭代訓練,直致模型收斂。模型訓練完畢后,只需要保留視覺變換器主干網,丟棄之后的全連接網絡,即可得到圖像的編碼網絡,完成圖像特征提取網絡的訓練。
3 試驗分析
為了測試基于生成式自監督學習的太陽能電池板缺陷檢測方法的實際效果,進行了試驗。試驗在Linux操作系統中完成,操作系統版本為Ubuntu 20.04,服務器具有128 GiByte內存,配備四塊RTX 2080Ti GPU顯卡。試驗時選擇主流深度學習平臺PyTorch 1.7.1,應用Python編程語言,采用Miniconda3創建獨立試驗環境,試驗過程如圖2所示。

▲圖2 試驗過程
3.1 數據集
太陽能電池板缺陷數據集包含2 624幅8位灰度圖像,分辨率為300像素×300像素。缺陷太陽能電池板樣本的性能都存在不同程度的退化,從44個不同的太陽能電池板模塊中提取。
對所有圖像根據大小和透視圖進行標準化,并消除由用于捕獲電致發光圖像的相機鏡頭引起的失真。采用缺陷概率,即0~1之間的浮點值描述圖像,并對太陽能電池板組件類型進行標注。
將2 624幅圖像按照7∶2∶1分為訓練集、驗證集、測試集,樣本分布見表1。由表1可以看出,圖像樣本數不均衡,缺陷概率為0與缺陷概率為100%的樣本數較多,缺陷概率為33%與缺陷概率為66%的樣本數較少,單晶缺陷概率為66%的樣本數僅為56,多晶缺陷概率為66%的樣本數僅為50,給模型訓練和泛化帶來一定困難。

表1 太陽能電池板缺陷數據集樣本分布
數據集中,多晶缺陷概率為100%的圖像如圖3所示,多晶不同缺陷概率的圖像如圖4所示,單晶缺陷概率為100%的圖像如圖5所示,單晶不同缺陷概率的圖像如圖6所示。

▲圖3 多晶缺陷概率100%圖像▲圖4 多晶不同缺陷概率圖像▲圖5 單晶缺陷概率100%圖像▲圖6 單晶不同缺陷概率圖像
由圖3可以看出,缺陷1與缺陷4圖像缺陷顯著,缺陷2與缺陷3圖像缺陷不顯著,多晶缺陷概率均為100%的圖像類內差別很大。由圖4可以看出,缺陷概率為0的圖像比缺陷概率為66%的圖像缺陷更為顯著,顯示很強的非線性特征。由圖5可以看出,缺陷1圖像缺陷顯著,缺陷3圖像缺陷不顯著,缺陷2與缺陷4圖像介于缺陷1與缺陷3圖像之間,單晶缺陷概率均為100%的圖像類內差別同樣很大。由圖6可以看出,缺陷概率為0的第一幅圖像與缺陷概率為66%的圖像相似,缺陷概率為0的第二幅圖像與缺陷概率為33%的圖像顯示了更多的缺陷,同樣顯示出很強的非線性特征。
對比圖3、圖4、圖5、圖6,存在圖像類內樣本差異大、圖像類間樣本差異小、非線性強等特點。如多晶缺陷概率為100%的圖像呈現出豐富的多樣性,單晶缺陷概率為100%的圖像也呈現出豐富的多樣性。從圖像表面看,存在多晶缺陷概率為100%的圖像比單晶缺陷概率為33%的圖像紋理更加干凈的情況,也存在單晶缺陷概率為0的圖像比單晶缺陷概率為66%的圖像紋理更復雜的情況。數據集類內存在差異很大的樣本,類間存在差異較小的樣本,這給缺陷分類帶來很大困難,提高了預測模型的泛化難度。
3.2 網絡調優
現有的預訓練模型已有廣譜二維圖像特征提取能力,尤其是提取自然界圖像特征的能力,已得到充分訓練。太陽能電池板是工業產品,缺陷視覺特征顯著不同,不能直接使用預訓練模型。筆者導入預訓練模型,在太陽能電池板數據集中進行調優,使調優后的模型可以有針對性地提取缺陷特征。
預訓練模型調優訓練時,參數設定非常重要,合適的參數可以達到收斂快、準確度高的效果。經過反復試驗,選定效果較好的參數。參數中,批次為32,優化器選擇ADM,學習率為余弦優化方案,熱身周期為5,層衰減為0.75,下降路徑為0.2,權重衰減為0.05,訓練周期為200次。訓練結果如圖7、圖8所示。
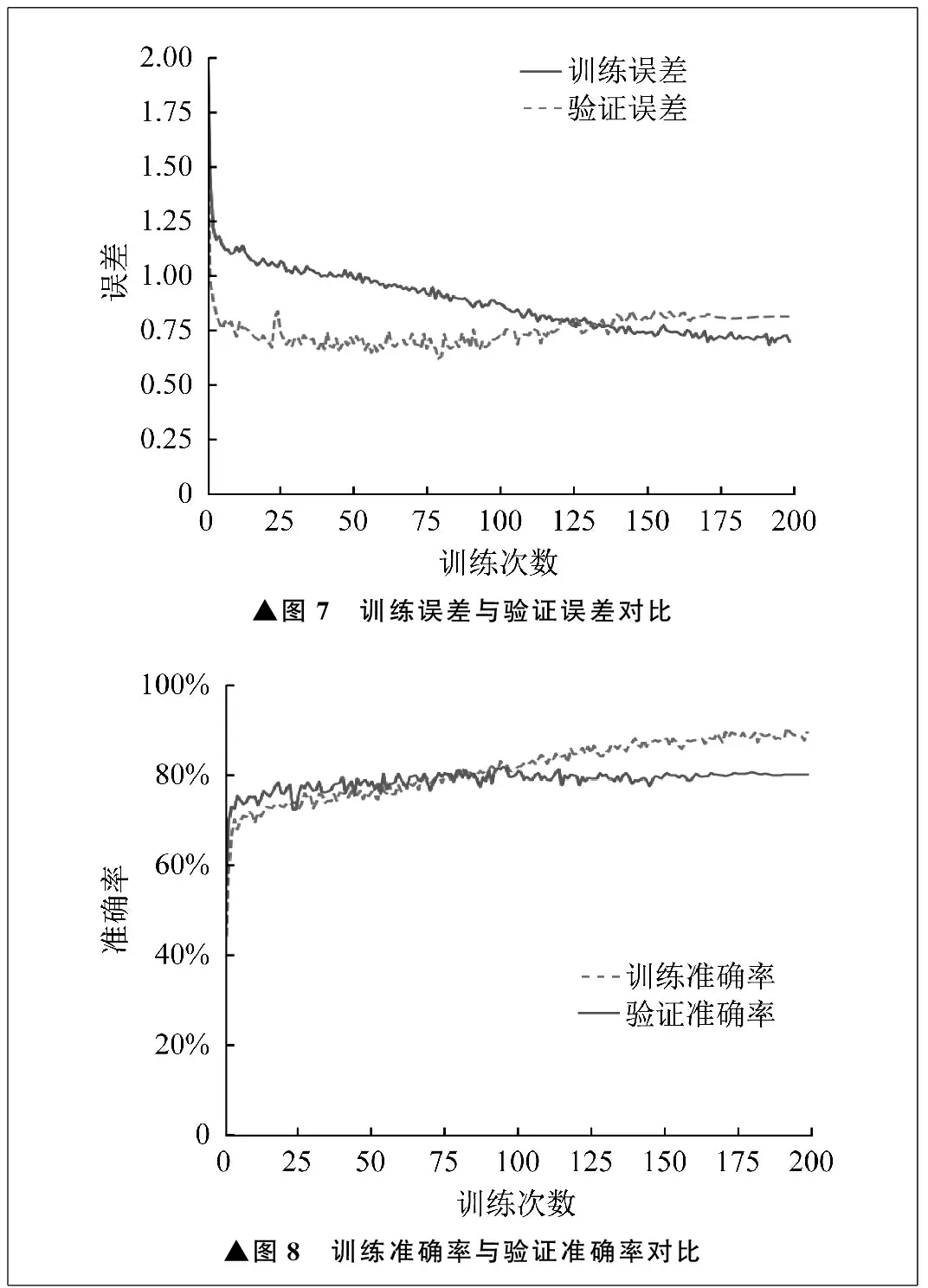
▲圖7 訓練誤差與驗證誤差對比▲圖8 訓練準確率與驗證準確率對比
使用訓練集調優時,由圖7可以看出,隨著訓練次數的增加,訓練誤差降低,驗證誤差降低。訓練次數達到80次左右時,驗證誤差達到最低,訓練誤差繼續降低。訓練次數達到150次時,訓練誤差收斂到0.75左右,此時已經基本收斂。從經驗來說,訓練誤差與驗證誤差的交匯點就是模型訓練的最優訓練點。再往后訓練,雖然訓練誤差可能繼續降低,但是驗證誤差卻會提高,模型有過擬合的危險。由圖8可以看出,隨著訓練次數的增加,訓練準確率與驗證準確率提高,訓練次數達到114次時,驗證準確率達到81.74%,之后驗證準確率基本穩定。
3.3 對比試驗
進行一系列對比試驗,對比對象包括采用監督學習的卷積神經網絡基線模型ResNet、2021年最佳模型Swin Transformer、基于對比學習的自監督學習模型,對比試驗結果見表2。
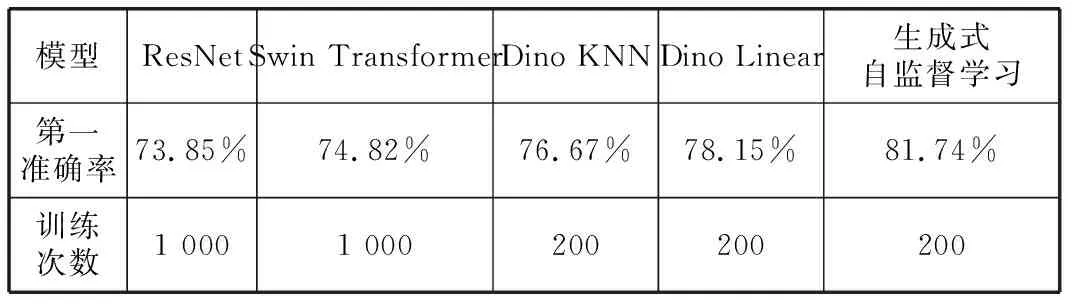
表2 不同模型對比試驗結果
表2顯示,如果不進行缺陷區域檢測等工作,直接使用監督學習的ResNet、Swin Transformer來分類,模型訓練識別準確率都低于75%。原因是太陽能電池板的缺陷是開放式的,沒有固定模式,在這種情況下,缺陷區域定位難度大。在無法定位缺陷區域的情況下,傳統有監督學習方法難以準確提取特征,也就難以實現準確識別。
Dino是基于對比學習的自監督學習,主干網絡為視覺變換器,效果較好。自監督學習注意力模型可以依托注意力機制,非顯性提升缺陷區域的自注意力,從而達到較好的特征提取效果。表2顯示,Dino KNN的識別準確率達到76.67%,Dino Linear的識別準確率達到78.15%,生成式自監督學習的識別準確率則達到81.74%。Dino的對比學習屬于判別式自監督學習,特征提取能力不如生成式自監督學習,因而識別準確率低于生成式自監督學習。
4 結束語
針對太陽能電池板檢測這一難度較大的工業產品質量控制問題,使用生成式自監督學習提取特征,結合有監督學習進行調優分類,檢測太陽能電池板的缺陷。在太陽能電池板缺陷數據集中進行測試,并進行對比試驗,生成式自監督學習在200次訓練的情況下獲得81.74%的識別準確率,高于對比學習和有監督學習。試驗結果表明,生成式自監督學習在特征提取方面有獨特優勢。生成式自監督學習能夠很好地解決開放性缺陷問題,省略缺陷定位環節,提高穩定性。相比判別式自監督學習,生成式自監督學習更能抓住細節信息,特征提取能力更強。生成式自監督學習具有很強的圖像分割功能,特征提取能力普適性較強,有良好的泛化能力。通過研究確認,生成式自監督學習在特征提取方面具有局部細節豐富、捕捉全局語義特征等優良屬性,具有良好的靈活性,在工業產品質量檢測及工業圖像領域具有應用推廣價值。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
人大建設(2020年4期)2020-09-21 03:39:12
電子制作(2019年15期)2019-08-27 01:12:00
人大建設(2017年2期)2017-07-21 10:59:25
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
人大建設(2017年9期)2017-02-03 02:53:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
