基于前向注意力機制的長句子語音合成方法
2022-09-28 14:50:06田澤佳卓奕煒
電子設計工程 2022年18期
田澤佳,門 豪,卓奕煒,劉 宇
(1.武漢郵電科學研究院,湖北武漢 430074;2.南京烽火天地通信科技有限公司,江蘇 南京 210019)
語音合成在人工智能領域有著十分廣泛的應用場景。隨著對神經網絡技術的深入研究,基于深度學習的語音合成極大程度上改進了傳統語音合成技術,降低了行業門檻。文獻[1-2]最早使用基于常規注意力機制的序列到序列方法進行語音合成的探索。文獻[3]提出全新的語音合成模型Tacotron,其基于常規注意力機制實現了首個端到端的語音合成模型。針對語音合成長句子存在的漏讀、重讀問題,有很多改進的方法,如文獻[4]引入一個卷積窗的約束,對注意力機制本身進行改進,將全局注意力機制轉換為帶卷積窗的注意力。文獻[5]模型使用了自注意力的方法,能夠在更少參數的情況下快速對齊語音幀。
該文針對長句子語音合成中存在的漏讀、重讀等問題,提出前向注意力機制,該機制能夠充分考慮文本序列中前后時刻的關系,利用前一時刻語音幀的注意力得分平滑當前時刻的注意力得分,消除注意力計算過程中的異常點,提高長句子合成的質量,比基線模型具有更快的收斂速度,提高了語音合成的效率。
1 前向注意力機制
該文提出的前向注意力機制主要對常規注意力[6]中注意力得分的計算過程進行改進,其核心思想是利用前一時刻生成的正常得分來平滑當前時刻的注意力得分。
通常,注意力機制的基本結構為編解碼器[7],其結構由遞歸神經網絡組成[8],在計算流程上,將輸入的文本序列x=(x1,x2,···,xt,···,xT)轉化為語音序列y=(y1,y2,···,yt)輸出,這里xt為第t幀特征向量;yt為當前t時刻解碼器輸出;每個yt可能對應一個或者多個xt。具體過程:首先通過編碼器將輸入的文本特征序列x生成相對應的更適合注意力機制處理的特征序列H=(h1,h2,···,ht):

其中,Encoder(·)是編碼器的操作,它通常由一個雙向長短時記憶網絡(Bidirectional Long Short-Term Memory,BiLSTM)[9]組成。H∈RD×t為特征序列向量,D為網絡神經元個數,即特征序列向量的維度,ht為第t幀特征序列。
其次是注意力部分,利用編碼器的輸出、前一時刻解碼器的輸出以及注意力部分的信息,計算當前時刻的注意力得分αj:
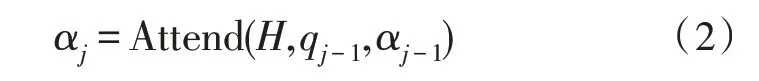
其中,Attend(·)為注意力的計算,qj-1為前一時刻解碼器的輸出,αj-1為前一時刻注意力的得分。
通過對上述注意力機制的計算過程進行分析發現,在注意力得分的計算中沒有施加約束,而是只計算了單個語音幀的分數,但是實際上每個音素往往包含幾十個語音幀,這就會導致同一音素內不同幀之間的注意力得分異常,導致相關語音幀存在較大偏差,從而造成語音重讀問題。因此,該文對上述注意力得分進行了改進,將新的注意力得分記為,在計算得分時,對當前時刻的注意力得分用前一時刻l幀的注意力得分之和加以約束。同時,為了簡化計算,只考慮前一時刻關注的語音幀與其相鄰幀之間的關系,以提升平滑效率,公式如下:

最后,再利用式(4)對式(3)得到的結果進行歸一化處理,得到前向注意力得分。再利用得到的結合隱含狀態向量便得到上下文向量:
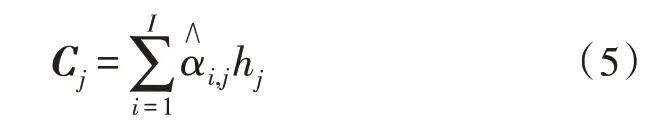
上述方法利用了前一時刻得到的前向注意力得分來平滑當前的異常分值,達到消除異常點的目的,同時保證不同語音幀注意力得分之間的連續性,確保合成語音的單調性,提高模型訓練效率。在實際訓練和后續測試中,長句子合成質量有明顯的提升,未出現重讀和漏讀問題。
2 帶約束的前向注意力
前文提出的前向注意力機制能夠有效解決長句重讀、漏讀問題,但在分析其基本方法的過程中,發現式(3)中的在前l個語音幀中發揮影響的程度不一致,并且前一時刻關注的語音幀在當前時刻不能保持完全相同,因此需要對前一時刻的前l語音幀添加新的約束,并動態調整注意力得分的重要度,以自適應的方式解決異常點問題,提高平滑效果,確保合成語音的自然度。因此,在前一方法的基礎上,提出了帶約束的前向注意力機制。具體的做法為采用具有一個隱藏層和sigmoid 激活單元的深度神經網絡(Deep Neural Networks,DNN)作為過渡代理,產生約束因子uj,用來動態地控制對齊過程中向前移動或停留的動作,如式(6)所示:
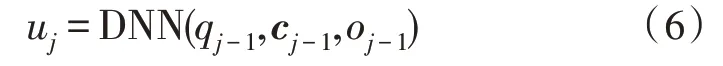
其中,uj∈Rl為當前時刻DNN 利用前一時刻qj-1、cj-1、oj-1產生的約束因子,qj-1為解碼器狀態,cj-1為DNN目標向量,oj-1為上一語音幀的輸出序列。
利用式(6)產生的約束因子能夠對前一時刻的注意力得分加以約束,可以減少注意力得分之間的差值,注意力得分較高的語音幀重要度可能會下降,注意力得分較低的語音幀重要度可能會上升。通過引入該動態調節機制可以使得分值更加平滑。于是對式(3)進行改進,便得到如下新的計算公式:
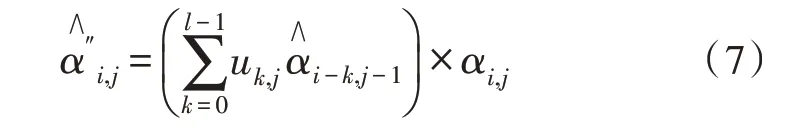
其中,uk,j代表當前j時刻k個語音幀的約束因子,乘上該因子可以達到約束的目的。故通過式(4)對式(7)得到的結果進行歸一化處理,可得到新的注意力得分
前文中提出的帶約束的前向注意力機制也可以從專家產品模型[10](Product of Experts,PoE)的角度來思考。PoE 模型的核心思想是通過將各自獨立的模塊組合到一起,然后將模塊各自的輸出進行歸一化,每個模塊相當于一個軟約束。在該文提出的帶約束的前向注意力機制中,式(6)相當于為單調對齊的任務添加一個約束,任務中的另一個約束為αi,j,即原注意力概率,帶約束的注意力得分便是基于這兩個約束的乘積。因此,不滿足單調對齊條件的路徑的注意力得分較低,以此達到單調對齊的目的。
常規的序列到序列聲學模型難以做到控制合成語音速度,而該文提出的帶有約束的注意力機制可以實現該功能。在語音合成的過程中,對DNN 網絡[11]中的sigmoid 輸出單元添加正偏置或者負偏置,會使帶約束的注意力得分增加或者減少,進而影響參與注意力計算的音素移動的快慢,從而可以達到控制合成語音合成速度的目的。
3 實驗與分析
3.1 實驗條件
該文中實驗的操作系統為Ubuntu18.04,顯卡使用的是NVIDIA GeForce GTX 2070S,處理器為Intel i5-5200U,內存為16 GB,主頻為3.2 GHz,程序基于Tensorflow 1.3.0 深度學習框架。
實驗中使用了公開的標貝女聲數據集。該數據集為一位女性專業人士錄制的普通話語音數據集,整個數據集音頻有效時長約為12 小時,采樣格式為無壓縮PAM WAV 格式,采樣率為48 kHz。錄音語料涵蓋各類新聞、小說、科技、娛樂、對話等領域。數據集由10 000 個話語以及相對應的文本拼音標注組成,劃分為訓練子集、驗證子集和測試子集,分別包括8 000、1 200、800 條語句。
3.2 實驗過程
該實驗針對基線模型Tacotron2 語音合成模型[12]中存在的重讀、合成效率低等問題,采用控制變量的方法,使用該文提出的前向注意力機制替換原模型中的帶卷積窗的注意力,完整的網絡結構如圖1 所示。完整的語音合成是基于序列到序列架構的模型,模型分為兩部分,第一部分是頻譜預測網絡,負責從文本和音頻中提取出特征序列向量,并通過注意力機制獲取兩個特征序列向量的映射,最終輸出預測的梅爾頻譜圖;第二部分為WaveNet 神經聲碼器[13],用于將梅爾頻譜圖[14]轉化為聲音波形輸出。語音合成模型的核心為注意力機制,由編碼器和解碼器兩部分結構組成。編碼器部分由3 個卷積層和一個BiLSTM 組成,卷積層的作用與N-gram 相似[15],具備感知上下文的能力,解碼器由預處理網絡和兩個LSTM 層組成。文本序列首先由卷積層提取上下文信息,然后傳遞到BiLSTM,用以生成編碼器隱狀態,之后通過注意力機制生成編碼向量,再由解碼器將該向量和LSTM 的輸出連接后,送入到解碼器端的LSTM,計算出新的編碼向量,該向量再與LSTM 的輸出拼接后,進入后處理網絡,用以預測頻譜。整個實驗中,采用的基線模型為帶卷積窗的注意力機制的Tacotron2 語音合成模型,其基本的編解碼器網絡結構與該文所采用的網絡結構相同,唯一不同的是注意力得分的計算部分。
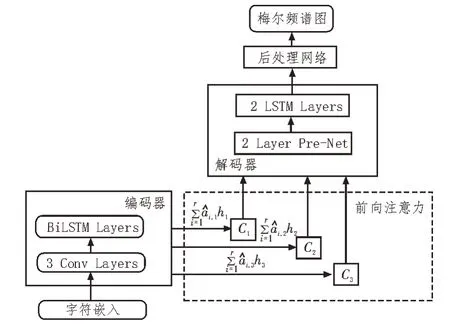
圖1 基于前向注意力機制的語音合成模型示意圖
3.3 實驗結果及分析
該文討論了在不同注意力機制下的序列到序列模型在語音合成中的效果,以評估不同注意力機制下聲學特征生成的穩定性。從測試集中隨機選擇120 條文本進行語音合成,其中最長的語句大致有100 個字,采用MOS 評分法[16-17]對合成的語句進行主觀評估。該文共建立了4 種基于序列到序列的聲學模型,分別為基于常規注意力機制(記為Att_None)、帶卷積窗的注意力(記為Att_Win)、前向注意力(記為Att_For)、帶約束的前向注意力(記為Att_ForTA)。幾種注意力機制下的MOS 得分情況如表1 所示。

表1 不同方法的MOS得分
由表1 可以看出,在使用前向注意力機制方法后,合成的語音質量相對于常規注意力機制和帶卷積窗的注意力機制都有了一定程度的提升,其中相比于基線模型Tacotron2,合成語音的MOS 得分提升了2.5%,原因在于該方法在不影響合成語音質量的前提下,解決了長句子合成中存在的重讀、漏音等問題,提升了語音合成的自然度。
同時,該文還使用前向注意力機制的聲學模型和基線模型合成同樣長度的句子,對這兩種方法的特征預測網絡對齊情況和預測的梅爾聲譜圖進行了對比,如圖2 所示。
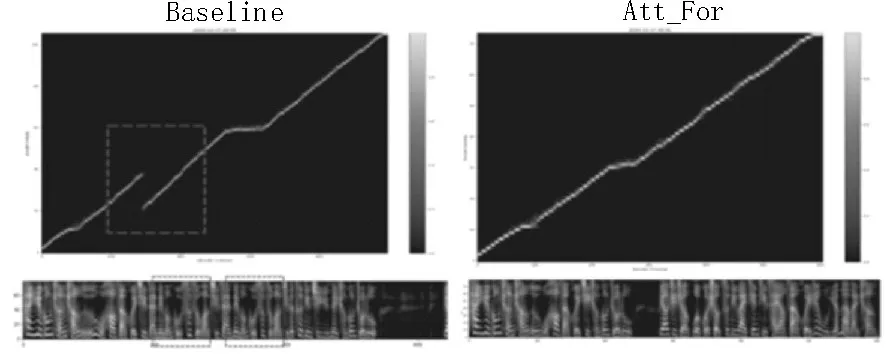
圖2 特征預測網絡對齊情況和梅爾聲譜圖對比
在合成相同長句子時,左圖代表基線模型Tacotron2 的對齊情況和梅爾頻譜圖,右圖顯示的是前向注意力機制下的對齊情況和梅爾頻譜圖。由圖中可以看出,在合成相同長度句子的情況下,基線模型在特征預測網絡對齊圖上出現了重疊現象,生成的梅爾頻譜圖出現了頻率譜的重復,并且合成長句子的時間較長,也就是合成效率較低;而使用了前向注意力機制模型的相同句子在特征對齊圖上未出現重疊現象,對應的梅爾頻譜也未出現頻譜的重復,同時整個句子的合成耗時較短,說明了該文方法有效地解決了長句子合成中的問題,提高了語音合成的質量,并且提高了合成效率。
在對帶約束的前向注意力的方法測試中,該文對DNN 網絡中sigmoid 輸出單元添加正偏置或者負偏置,會使帶約束的注意力得分增加或者減少,進而影響參與注意力計算的音素移動的快慢,從而達到控制合成語音合成速度的目的。該文驗證了該方法的有效性,具體做法是使用前一實驗中合成的20 個話語進行對比,從0 開始以步長0.2 增加或減少偏置值,分別合成20 個話語,計算合成話語長度和偏置為0 的話語長度的平均比值,如圖3 所示,從圖中可看出,每次調整不同的偏置,能夠有效地實現對合成語句速度的控制。
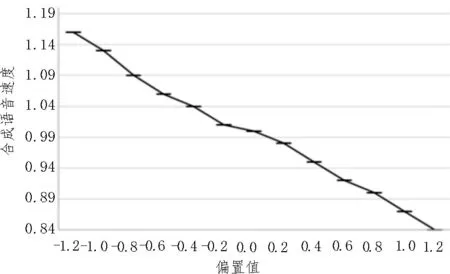
圖3 偏置值對合成語音速度的影響
4 結束語
該文提出的前向注意力機制能夠有效平滑注意力計算中出現的異常得分,消除異常點,解決長句子語音合成中出現的漏讀、重讀問題,提高語音合成質量。更進一步地,該文又提出了改進的帶約束的前向注意力機制,通過對前一時刻的注意力得分引入約束因子來自適應平滑當前時刻的注意力得分,提高了長句子語音合成的穩定性且能夠自主控制合成語音速度。實驗結果表明,相對于基線模型Tacotron2,前向注意力機制的長句子語音合成方法在MOS 得分上提升了2.5%,且帶約束的前向注意力能夠有效地控制合成語音的速度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
四川勞動保障(2021年9期)2022-01-18 05:11:08
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
中國衛生(2016年9期)2016-11-12 13:28:08
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛生(2015年9期)2015-11-10 03:11:12
核科學與工程(2015年4期)2015-09-26 11:59:03
中國衛生(2014年3期)2014-11-12 13:18:12
