物理虛擬仿真實驗的可視化學習分析*——以“霍爾法測量磁場”實驗為例
2022-09-27 06:16:44李漁迎劉冰潔王依朦
現代教育技術 2022年9期
李漁迎 倪 晨 劉冰潔 關 佳 王依朦
物理虛擬仿真實驗的可視化學習分析*——以“霍爾法測量磁場”實驗為例
李漁迎1倪 晨1[通訊作者]劉冰潔2關 佳1王依朦1
(1.同濟大學 物理科學與工程學院,上海 200092;2.科大奧銳科技有限公司,安徽合肥 230000)
隨著大規模虛擬仿真實驗的開展,在線教學因缺乏個性化輔導與實時反饋而制約了實驗的教學效果。而高仿真、沉浸式的虛擬仿真實驗為網絡化、智能化、個性化的實驗教學提供了新途徑,是國家教育新型基礎設施建設的重點。基于此,文章依據精準教學驅動下的可視化學習分析方法,結合虛擬仿真實驗過程中產生的多答案、高耦合異構數據特征,設計了實驗特征分析、問題域挖掘、問題歸因三個特征模型,并借助直觀的可視化圖形幫助教師從知識掌握、實驗態度、實驗操作方法等多角度對學生虛擬仿真實驗的學習效果進行精準診斷,從而實現個性化指導。同時,文章以“霍爾法測量磁場”實驗為例,基于上述三個特征模型進行了教學應用、分析了應用效果,明確了實驗難點和錯誤之間的關聯。文章對物理虛擬仿真實驗進行的可視化學習分析,有助于物理實驗教學的數智化轉型升級,并推動可持續發展的高質量虛擬仿真實驗教學體系構建。
可視化學習分析;虛擬仿真;精準教學;大學物理實驗
引言
近年來,基于計算機仿真、虛擬現實和網絡技術構建的高度仿真的虛擬實驗環境,以其網絡化、沉浸式、高效率、低成本等優勢,在實驗教學中得到了廣泛應用。其中,物理虛擬仿真實驗通過對真實物理實驗儀器和實驗過程的高度仿真,較大程度地保證了實驗的真實度和輸出結果的可靠性。有研究表明,學生在虛擬實驗中所獲得的科學探究能力和實驗技能的熟練程度會對應遷移、轉化,為真實的實驗工作奠定基礎[1]。作為線下實驗室的教學補充,虛擬仿真實驗室有助于改善學習者的學習體驗,達到更好的學習效果[2]。但在教學應用的過程中,虛擬仿真實驗存在教學指導理論缺失、師生交互設計不足、教學評價制度不完全等問題,導致教與學脫節嚴重,使教學易陷入學生實驗操作難、教學指導難的困境[3][4]。
學習分析通過對數據的處理和分析,利用已知模型和方法去解釋影響學習者學習的重大問題,評估學習者的學習行為,已成為當代提供教學反饋的重要支持手段之一[5]。可視化技術基于學習行為數據內在的結構和規律匹配不同的可視化方案,清晰、高效地傳達數據背后的意義,進一步凸顯了學習分析在解決復雜問題上的優勢,使師生能夠在快速理解教育現象的基礎上,啟發教育決策[6]。因此,可視化學習分析綜合學習分析和可視化分析的優點,支持教師基于學習數據進行自主假設、探索、驗證、解釋等動態推理,可幫助教師通過人機協同來更靈活地探索如何在虛擬仿真實驗教學中做出復雜的教學決策,從而充分發揮教師的主導作用[7]。該技術在虛擬仿真實驗教學應用中尚處于起步階段,亟待推進相關的理論與實證研究,建立科學、系統的虛擬仿真實驗教學指導方案與評價體系。
基于上述分析,本研究與物理虛擬仿真實驗系統研發單位科大奧銳科技有限公司合作,以精準教學理論為指導,將云平臺的學習數據特征與物理實驗教學規律相結合,設計物理虛擬仿真實驗可視化學習分析的思路。在此基礎上,本研究構建實驗特征分析、問題域挖掘、問題歸因三個特征模型,開展虛擬仿真實驗教學的科學評測應用研究,以期為引導學生自主學習、賦能個性化教育實施、推進信息技術與高等教育實驗教學深度融合、推動教學模式創新提供參考。
一 物理虛擬仿真實驗可視化學習分析的思路
相較于其他學科,物理虛擬仿真實驗更注重探究性與實驗方法的設計。在實驗過程中,實驗元件的初始參數會在虛擬仿真實驗開始時隨機生成,因而實驗結果多樣。另外,實驗測量結果也會受不同型號實驗儀器的精準度差異影響,導致讀數不一。物理實驗步步相扣,各答案之間的關聯性極強,因此復雜的物理虛擬仿真實驗數據關系梳理需要借助可視化學習分析的方法輔助診斷、反饋等教學環節開展。可視化分析過程包括數據采集與預處理、建立模型與驗證假設、可視化表征、獲取知識等步驟,是一種非線性過程[8]。在精準教學理念的驅動下,可視化學習分析注重學習者的內在學習條件、學習過程和個性化發展,這就對所收集實驗數據的全面性與采樣率、學習分析模型的準確度與執行頻率提出了更高要求[9]。結合物理實驗特征和學習分析流程,本研究設計了物理虛擬仿真實驗可視化學習分析的思路,包括數據收集與預處理、數據分析模型構建、結果可視化呈現與反饋三個主要環節,如圖1所示。
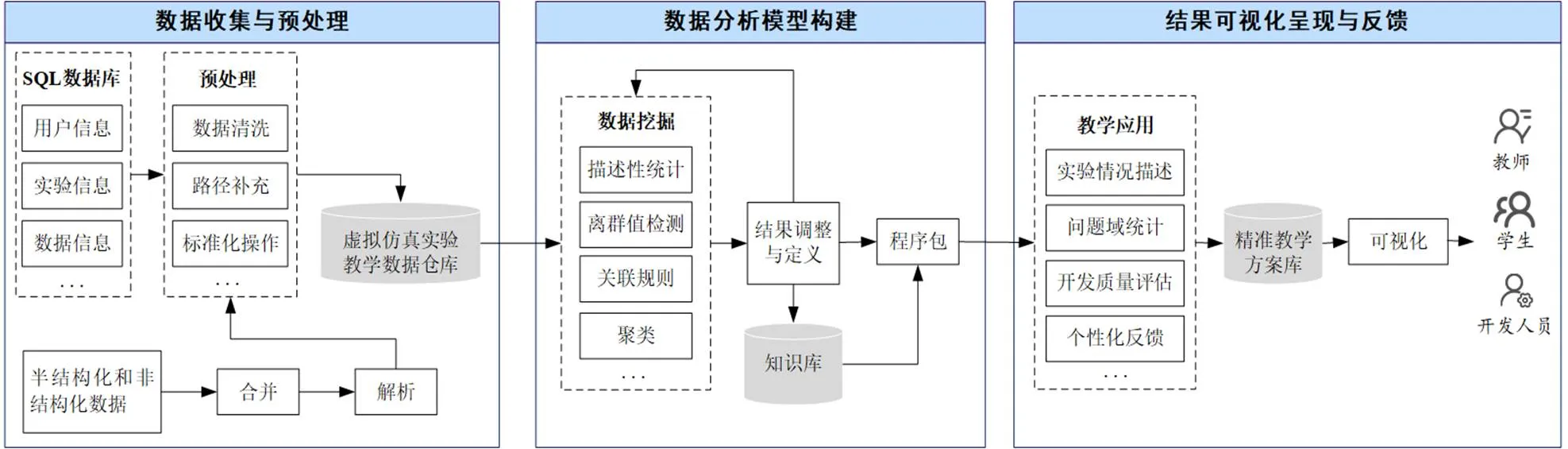
圖1 物理虛擬仿真實驗可視化學習分析的思路
1 數據收集與預處理
學習行為數據的采集,是精準教學得以順利開展的必要前提和實施依據[10]。在虛擬仿真實驗云平臺,學生的個人信息、實驗信息等結構化數據被存儲于SQL數據庫中,而實驗報告以XML文件半結構化形式存儲,還有少量的實驗效果評價、實驗過程交流等非結構化數據。因此,在進行數據預處理之前,要先將所有數據統一為適合挖掘的結構化數據,以提高對數據的管理和查詢效率;在數據預處理階段,要通過過濾或修改那些不符合要求的數據,以提高數據的質量[11]。本環節收集了虛擬仿真實驗平臺上支持學生行為直接測量的相關數據,并將所有數據轉為結構化數據后存儲于數據倉庫中,以供數據分析使用。
2 數據分析模型構建
數據分析模型是可視化學習分析的核心,以解決實際需求為目標,設計匹配算法,獲得可靠的數據分析結果。常見的數據挖掘技術有分類、聚類、統計、回歸、關聯規則挖掘、序列模式挖掘、可視化數據挖掘、文本挖掘等[12]。在實際情況中,面對復雜的決策需求,各類數據挖掘算法經常要結合具體的應用情境一起使用,嚴謹而全面地規劃各數據挖掘算法的應用范圍以達到精準決策的目的。可視化學習分析并非線性的過程,需結合外部評價法與內部評價法對學習分析模型進行質量診斷與細節調控,以實現模型迭代[13]。數據分析模型運行后產生的結果最終由指導教師進行驗證,如果運行結果中仍含有特征不明的數據集,可以挑選出來進行二次運算,直至結果可定義。最終的運算結果被標記后,將以實驗項目為單位存儲于知識庫中。本環節采用知識庫配對存儲數據挖掘與專家分析結果,采用程序包存儲面向不同需求的、完整的學習分析算法,有利于推動各虛擬仿真實驗之間學習分析模型的共建共享。
3 結果可視化呈現與反饋
結果可視化呈現與反饋是指利用合適的圖表直觀地呈現學習分析結果,為教師、學生、開發者等相關用戶提供決策支持與反饋。但在進行反饋干預時,由于教育的復雜性,需著重考慮干預方案實施時的具體情境。如何捕捉合適的時機、教學場景、反饋方式以提供合適的教學干預,需要大量的科學研究和教師豐富的教學經驗[14]。如果干預效果與預想不符,反思原因后就需重新回到模型構建階段再次迭代,直至滿足實際需求,達到精準干預的目的。待明確一套完整的以測輔學方案后,將其數據分析方法、挖掘結果標記及其可視化呈現方法相結合,在此基礎上構建一個精準學習方案庫,可以為后續相關研究提供參考。
二 物理虛擬仿真實驗可視化學習分析的特征
在進行虛擬仿真實驗可視化學習分析時,所收集數據的類型與特征會直接影響具體算法的選擇,而不同的數據分析模型會影響最終的可視化圖形選擇。基于此,本研究圍繞學習者的學習情況診斷這一需求,對其關聯的異構數據特征、基于該需求開發的數據分析模型特征及其對應的可視化圖形特征展開具體分析。
1 異構數據特征
根據維度數,物理虛擬仿真實驗報告中生成的數據可分為一維、簡單多維、復雜多維三類。
①一維數據:是數據集中最小的分析單位。實驗操作判別、計算結果、物理量等數據一般以一維形式呈現,多維的實驗過程性數據表格也是由多個一維數據組成。清洗后的一維數據有兩大特征:正確結果可能多樣,且各結果簇接近正態分布。除此之外,一維數據因受實驗儀器測量值讀取錯誤、數據處理過程單位轉換錯誤等影響導致密度分布不均勻。
②簡單多維數據:物理實驗過程中常用多次測量以獲得準確的結果,該類數據屬于多維數據,在實驗報告中多以表格形式呈現。該類數據在不同實驗測量內容中由于各維度數據的函數關系不同,造成數據簇的分布形狀各異,如存在線性關系的條形分布、平方關系的弧形分布等。
相關的工作人員應該努力學習造林技術,對高科技的手段能夠熟練的運用,對營造林的技術進行宣傳,對科學的理論進行全面的掌握,建立一支強大的高素質的造林隊伍,不斷實現造林水平的上升。在進行營造林的過程中應該重視科技的使用,而不僅僅依靠原始的技術。此外,還應該大力宣傳營造林的意義,可以通過網絡的作用進行營造林的宣傳,讓更多的人了解造林的好處,積極參與其中。
③復雜多維數據:復雜多維數據與簡單多維數據的區別在于維度數是否超過20。當輸入的維度數大于20時,基于距離的計算方法失效[15]。考慮到后續部分的算法原理與距離相關,為更利于開展降維處理,故做此區分。
除了數據本身的特征外,物理實驗數據還存在各步驟之間的答案關聯性強、各步驟的正確答案不唯一兩大特點,在進行數據分析模型設計時需考慮其教學意義。
2 數據分析模型特征
基于上述異構數據特征分析,本研究設計了實驗特征分析、問題域挖掘、問題歸因三個特征模型,以適合不同虛擬仿真物理實驗項目的學情分析需求。
①實驗特征分析模型:基于描述性統計方法,從學生實驗次數、平均實驗時長、實驗成績、最高分四個維度描述在線實驗的基本學情。這四個維度的數據獲取便捷、主題多樣,有利于輔助教師快速掌握實驗項目的難度和學生的知識掌握情況、學習習慣等顯性信息。運用本模型得到的挖掘結果可用于與線下實驗教學的正常數據進行對比,以發現實驗平均時長和實驗次數異常、平均成績異常等情況。
②問題域挖掘模型:借助聚類算法,對同一步驟實驗數據的相似類對象進行標識與分組。本模型結合專家對模型挖掘結果各相似類對象的定義,來精準定位錯誤類型。根據三種不同的數據類型,本研究相應選取三種聚類算法。其中,一維數據的問題域挖掘選取實現較為簡單、且以質心為圓心對數據進行劃分的K-Means算法——為解決該算法初始類別數K值不確定,聚類質量受初始聚類中心、噪聲和孤立點的影響較大等問題,本研究在數據預處理階段采用Canopy算法刪除孤立點,并初步確定K值和各個聚類中心,以降低算法的不穩定性。對于簡單多維數據的問題域挖掘,本研究選取基于高斯混合模型(Gaussian Mixed Model,GMM)的聚類算法——該算法根據數據分布的特點不斷訓練,以自動擬合簇的形狀,適合多維且數據關系不明確的變量集。而對于復雜多維數據的問題域挖掘,本研究首先利用主成分分析法對數據進行降維,之后根據新產生的特征因子數對應采取改進版的K-means算法或GMM算法。
③問題歸因模型:在問題域挖掘模型結果的基礎上,借助關聯規則算法找出各步驟答案的頻繁項集,并發現項與項之間的順序關系。前后項均為錯誤類的關聯規則,說明前項錯誤大概率是導致后項錯誤出現的主要原因,即后項錯誤并不是真正的知識難點,而是由前項錯誤導致。從教學有效性的角度考慮,篩選出該類規則后,只需重點關注前項(即實驗時存在的關鍵問題)即可。由于錯誤記錄數占總記錄數的比值較小,故本研究將Apriori關聯規則算法中的支持度設置為1%,表示兩步驟的錯誤類同時出現的概率應大于1%;置信度設置為60%,表示前項錯誤類的出現能導致60%概率以上的后項錯誤發生。
3 可視化圖形選擇
三 物理虛擬仿真實驗可視化學習分析的教學應用
1 案例介紹
“霍爾法測量磁場”實驗是大學物理和實驗教學中的一個重要內容,大多數高校都開設了該實驗項目,在教學中具有代表性。基于此,本研究以上海市T大學的“霍爾法測量磁場”實驗為例,介紹虛擬仿真教學過程及其可視化學習分析結果。本實驗為“物理實驗(下)”課程中的內容,面向理工科一年級本科生開設,每年有約3000名學生參與該實驗。虛擬仿真實驗的教學內容與線下實驗基本一致,學生基于物理實驗中心平臺仿真實驗模塊提供的實驗簡介、原理、內容等學習資源進行自主學習,同時基于仿真程序搭建儀器、調節數據、獲取數據進行模擬實驗,并將實驗報告文件提交至平臺,項目操作界面與實驗報告界面如圖2所示。

圖2 “霍爾法測量磁場”虛擬仿真實驗項目操作界面(左)與實驗報告界面(右)
2 分析過程
本實驗分析數據由平臺上學生提交的實驗報告文件批量讀取并轉換獲得,主要包括學生信息、實驗次數、實驗時長、實驗成績、完整的測量數據五部分內容,這些內容客觀、真實地記錄了學生在虛擬仿真實驗教學中的學習行為和學習結果。具體的分析過程如下:①借助Minidom解析器解析XML實驗報告文件,遍歷各節點,實現從半結構化數據到結構化數據的無損映射;借助正則表達式拆分非結構化字符串類數據,提取其中的結構化數據。②對殘缺、錯誤、重復的數據進行清洗。③根據各步驟的數據維度采用相關聚類算法,對該實驗的13個步驟分別進行問題域挖掘;挖掘后經由教師驗證,對各步驟的顯著答案類別進行編碼與含義標記,編碼格式為“HE步驟序號_類別序號”。④運行Apriori關聯規則算法,挖掘各步驟、各答案類別之間的顯著關系。⑤借助Excel、Echarts等工具實現問題域挖掘結果和問題歸因模型挖掘結果的可視化。
3 應用效果
(1)實驗特征分析模型:發覺學情異常點
依據從實驗次數、平均實驗時長、實驗成績、最高分四個維度分析得到的班級整體分布情況,可以初步掌握學生完成實驗項目的情況,及時發現潛在的學習異常現象。本研究對T大學參與“霍爾法測量磁場”實驗的2730名學生為期一學期的實驗數據進行統計,得到15851條虛擬仿真實驗記錄,在此基礎上運用條形圖繪制了“霍爾法測量磁場”實驗特征分析模型統計圖,如圖3所示。教師可根據圖內線條的花色和長短,識別各維度數據的占比差異。
圖3顯示,從實驗的最高分看,68.36%的學生處于90分以上的高分段。而在線下實驗教學中,教師根據實驗操作情況和實驗報告內容給出評分,僅有約46%的學生總評達到90分以上。經對比,本研究發現學生的最高線上實驗成績顯著高于線下(Sig.值為0.000),此結果證實了霍爾效應虛擬仿真實驗的教學有效性。但從實驗完成度來看,有36.29%的實驗記錄得分<5分,一半以上學生的實驗次數>3次,說明學生無法通過一次實驗就能完成所有的學習內容。結合占比最大的半小時內實驗時長記錄分析,可知許多學生并沒有認真地對待每一次實驗,他們可能利用物理實驗課程最終成績選取整個實驗過程中所得最高分的評價漏洞多次猜答案,以獲得高分。針對這個線上教學常見的問題,教師需要精準掌握學生的學習行為,嚴格監督其實驗態度,指引學生從知識理解出發對知識進行加工、內化,避免走向唯分數論的試誤型、無意義學習。實驗特征分析模型初步表征了實驗項目的難度和實驗完成度,有利于分析學習異常情況,為更深入的學習分析提供了依據。

圖3 “霍爾法測量磁場”實驗特征分析模型統計圖
(2)問題域挖掘模型:健全評價綜合度
霍爾電壓測量是“霍爾法測量磁場”實驗的重難點內容。本研究以該內容的問題域挖掘結果為例,采用多維平行坐標系圖進行可視化呈現,結果如圖4所示。平行坐標系將實驗表格中的多維數據落點于多個等距數軸上,隨著數據的增多,各點連線后的形狀差異越發明顯。教師根據平行坐標系中各類數據的線條形狀,即可快速識別不同的數據規律。該內容聚類結果與平臺實際評分進行比較,求得福爾克—馬洛斯指數(Fowlkes-Mallows Index,FMI)值為0.672,說明成對的準確率與召回率的幾何平均值較高,聚類質量良好。
在圖4中,類別1為正確答案,由幾組正反向線性曲線構成。對比正確答案,觀察其他類別在圖中各數軸上的值域范圍和數軸之間的關系,可以發現:①曲線整體距離零軸較遠,即錯誤數值的絕對值主要集中在0或10附近(類別3、4),導致該錯誤的具體原因是霍爾效應實驗開始時未調零。②曲線呈波浪曲線而非線性變化,說明不同數軸之間的符號沒有進行正負轉變(類別6),導致該錯誤的具體原因是學生未掌握換向法測量原理,數據呈單項遞增或遞減趨勢。③曲線呈震蕩,說明部分極性設置錯誤(類別2、7),該類學生在測量原理或磁場、電壓的設置有誤——如果是粗心導致,那么就要對學生的實驗態度和學習習慣多加注意。但是,原因也可能在于學生對霍爾實驗儀器開關的控制不熟練,導致部分符號出錯。④曲線開口較小,與零刻度軸更為貼近,原因主要在于實驗剛開始前未調零,或測量元件位置放置不當,導致數值略微偏小(類別5)。基于問題域挖掘模型分析結果,教師在物理虛擬仿真實驗教學中可從實驗操作、實驗數據處理、實驗知識點、實驗態度等維度細化評價內容。
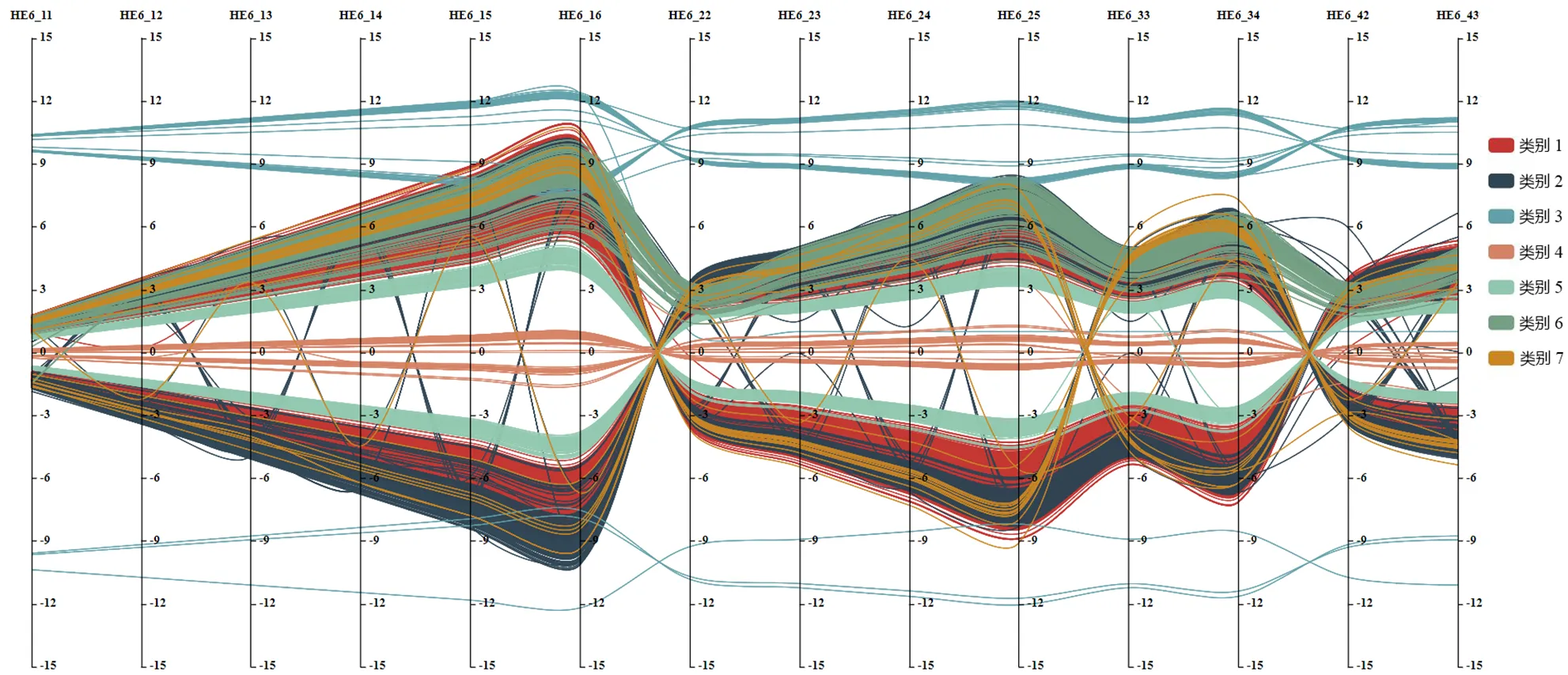
圖4 “霍爾法測量磁場”中復雜多維數據的聚類結果圖
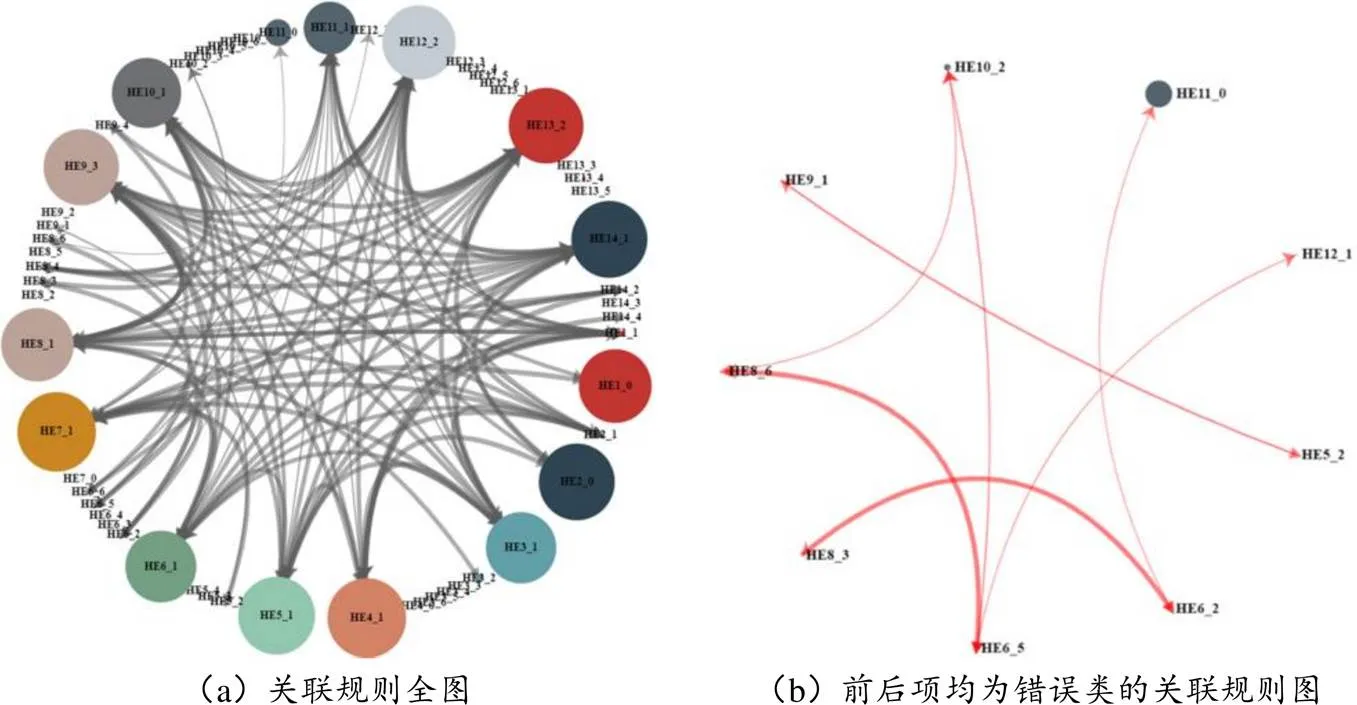
圖5 “霍爾法測量磁場”虛擬仿真實驗各題答案的關聯規則圖
(3)問題歸因模型:提升反饋精準度
在有向關系圖中,各節點編碼名稱與問題域挖掘結果一致。本研究采用有向關系圖,繪制了“霍爾法測量磁場”虛擬仿真實驗各題答案的關聯規則圖,如圖5所示。圖5(a)呈現了“霍爾法測量磁場”實驗中所有的關聯規則,圖5(b)對其中前后項均為錯誤類的關聯規則進行了可視化呈現。圖中箭頭由前項指向后項,表明前項是后項的因。經驗證,圖5(b)所得結果均與實驗邏輯關系相符。從實驗操作來看,由于霍爾電壓(HE6、HE8)、霍爾系數(HE10)、載流子類型(HE11)、載流子濃度(HE12)存在計算關系,如未將霍爾元件置于磁場中央而影響霍爾電壓的測量,必然會導致以上步驟出現一系列錯誤關聯,即所有實驗結果測量值均偏小。而從知識點掌握來看,概念理解不清的學生在第6、第8步驟均存在符號記錄錯誤問題(HE6_2、HE8_3),且該問題會受實驗內部邏輯關系的影響,從而造成元件類型判斷錯誤(HE11_0)。
在實驗中,物理數學關系越復雜的物理量往往錯誤率越高,也越難明確根本性的錯誤原因。關聯規則歸因模型通過追溯錯誤答案類別之間的關系,精準定位錯誤步驟,診斷錯誤原因,有效解決了這一難題。該模型通過提升反饋精準度,既提高了教師的在線輔導效率,又有利于改善學生的在線學習體驗,避免其因學習陷入困境而出現厭倦感,保證了高質量的學習[16]。
四 結語
相較于理論性課程,物理實驗課程的實驗內容更加復雜、實驗答案更具開放性和關聯性,這進一步加大了教師精準診斷的難度,也強化了學生對及時、有效教學指導的需求。本研究發現,借助可視化學習分析可以表征虛擬仿真實驗數據的分布規律,呈現清晰的物理量關聯關系,并幫助教師由原來基于經驗假設的教學逐漸轉為基于數據指導的教學,提高了教學效能,故在改善線上虛擬仿真實驗教學效果方面潛力巨大。后續研究可在學情分析的基礎上,結合相關學科特點和教學過程,增加對科研能力、設計能力、情感態度等更多維度的考察,從診斷、預測、評價、反饋等多方面發揮可視化學習分析方法的作用,從而不斷豐富精準教學方案庫,建設更高質量的虛擬仿真實驗教學服務體系。
[1]Miranda-Valenzuela J C, Valenzuela-Oca?a K B. Using virtual labs to teach design and analysis of experiments[J]. International Journal on Interactive Design and Manufacturing(IJIDeM), 2020,(4):1239-1252.
[2]Cheng L, Niu W-C, Zhao X-G, et al. Design and implementation of college physics teaching platform based on virtual experiment scene[J]. The International Journal of Electrical Engineering & Education, 2021,(2):1-14.
[3]Moozeh K, Farmer J, Tihanyi D, et al. Learning beyond the laboratory: A web application framework for development of interactive postlaboratory exercises[J]. Journal of Chemical Education, 2020,(5):1481-1486.
[4]Reeves S M, Crippen K J. Virtual laboratories in undergraduate science and engineering courses: A systematic review, 2009-2019[J]. Journal of Science Education and Technology, 2020,30:16-30.
[5]徐鵬,王以寧,劉艷華,等.大數據視角分析學習變革——美國《通過教育數據挖掘和學習分析促進教與學》報告解讀及啟示[J].遠程教育雜志,2013,(6):11-17.
[6]Vieira C, Parsons P, Byrd V. Visual learning analytics of educational data: A systematic literature review and research agenda[J]. Computers & Education, 2018,122:119-135.
[7]胡立如,陳高偉.可視化學習分析:審視可視化技術的作用和價值[J].開放教育研究,2020,(2):63-74.
[8]Keim D.A, Mansmann F, Schneidewind J, et al. Visual data mining [M]Springer, 2008:76-90.
[9]Lambe D, Murphy C, Kelly M E. The impact of a precision teaching intervention on the reading fluency of typically developing children[J]. Behavioral Interventions, 2015,(4):364-377.
[10]張忻忻,牟智佳.數據化學習環境下面向個性化學習的精準教學模式設計研究[J].現代遠距離教育,2018,(5):65-72.
[11]Rahm E, Do H H. Data cleaning: Problems and current approaches[J]. IEEE Data Engineering Bulletin, 2000,(4):3-13.
[12]Paiva R, Bittencourt I I, Tenório T, et al. What do students do on-line? Modeling students’ interactions to improve their learning experience[J]. Computers in Human Behavior, 2016,64:769-781.
[13]Song Y, Chen W Y, Bai H, et al. Parallel spectral clustering[A]. Joint European Conference on Machine Learning and Knowledge Discovery in Databases[C]. Berlin: Springer-Verlag, 2008:374-389.
[14]Hatala R, Cook D A, Zendejas B, et al. Feedback for simulation-based procedural skills training: A meta-analysis and critical narrative synthesis[J]. Advances in Health Sciences Education, 2014,19:251-272.
[15]Berkhin P. Survey of clustering data mining techniques[A]. Grouping Multidimensional Data[C]. Berlin: Springer-Verlag, 2006:25-71.
[16]袁磊,張淑鑫,雷敏,等.技術賦能教育高質量發展:人工智能、區塊鏈和機器人應用前沿[J].開放教育研究,2021,(4):4-16.
Visual Learning Analysis in Physical Virtual Simulation Experiment——Taking the Experiment of “Hall Method to Measure Magnetic Fields” for Example
LI Yu-ying1NI Chen1[Corresponding Author]LIU Bing-jie2GUAN Jia1WANG Yi-meng1
With the development of large-scale virtual simulation experiment, the lack of personalized tutoring and real-time feedback restricts the teaching effect of the experiment. The highly simulated and immersive virtual simulation experiment provides a new way for networked, intelligent and personalized experimental teaching, which is the focus of the new infrastructure construction for national education. Accordingly, based on the visual learning analysis method driven by precision teaching, combined with the multi-answer and highly coupled heterogeneous data characteristics generated in the process of virtual simulation experiment, this paper designed three feature models of experimental feature analysis, problem domain mining and problem attribution, which can help teachers accurately diagnose students’ learning effects of virtual simulation experiments from the perspectives of knowledge mastery, experimental attitude and experimental operation methods with the help of intuitive visual graphics, so as to realize personalized guidance. At the same time, taking the experiment of “Hall method to measure magnetic fields” as an example, this paper carried out teaching application, analyzed application effects, and clarified the relationship between the experiment difficulties and the experiment errors, based on the above three feature models. The visual learning analysis in physical virtual simulation experiment in this paper was helpful for the digital intelligence transformation and upgrading of physical experiment teaching, and could promote the construction of a sustainable high-quality virtual simulation experiment teaching system.
visual learning analysis; virtual simulation; precision teaching; college physics experiment

G40-057
A
1009—8097(2022)09—0091—09
10.3969/j.issn.1009-8097.2022.09.010
本文為虛擬仿真實驗教學創新聯盟項目“虛擬仿真物理實驗精準教學評價研究”(項目編號:VSE21013R07)的階段性研究成果。
李漁迎,在讀碩士,研究方向為智慧教學及物理實驗信息化教學研究,郵箱為1930937@tongji.edu.cn。
2022年2月20日
編輯:小米
猜你喜歡
井岡教育(2022年2期)2022-10-14 03:11:44
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
甘肅教育(2020年4期)2020-09-11 07:42:36
物理之友(2020年12期)2020-07-16 05:39:20
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
甘肅教育(2020年8期)2020-06-11 06:10:04
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:00
傳媒評論(2019年4期)2019-07-13 05:49:14
中學生數理化·中考版(2017年12期)2017-04-18 12:55:05
