基于單相機的飛行器結構表面應變片三維定位方法
2022-09-26 09:29:08李立欣周書濤周江帆董學金蘇志龍張東升
強度與環境 2022年4期
李立欣 周書濤 周江帆 董學金 蘇志龍 張東升
(1 上海大學力學與工程科學學院上海市應用數學與力學研究所,上海 200444;2 北京強度環境研究所,北京 100076;3 上海衛星裝備研究所,上海 200240)
0 引言
光學三維重建是研究物體三維信息獲取的熱點方向之一,發展了諸如明暗恢復法、多視角立體視覺、近景工業測量、光度立體法等。其中,多視角立體視覺技術利用視覺幾何,從一組普通光學圖像中對物體的三維形狀和空間位置進行測量和重構,可以大大提高三維測量的效率,有效地構建目標的三維數據,在工業自動化檢測和航空航天逆向工程等方面具有廣闊的前景。將多視角立體重構與不同領域的應用需求相結合,研究人員們建立了多種具有實用價值的光學三維重建方法。例如,結構光三維形貌測量是建立在雙視角成像基礎上的一種經典三維形貌測量技術,由于它測量精度高且適用性強,已經廣泛應用于許多工業生產領域[1,2],但結構光需要額外的投影設備配合才能進行測量。RGB-D相機和光場相機的出現為三維重建提供了簡單易行的途徑[3],由于這類測量主要采用共軸形式,測量精度有待進一步提高。隨著深度學習技術在計算機視覺領域中的快速發展,出現了基于單幀圖像的三維形貌重建技術[4,5],該技術在人臉三維重建得到了應用;然而這類方法目前還只能應用在特定的對象,并且需要大量的前期訓練才能提高測量精度。除此之外,采用單相機對物體進行多角度成像是多視角立體測量中一種經濟的三維重建技術[6,7],可從不同角度獲得的場景圖像中實現對相機姿態和物體三維信息的同時估計,在實際應用中備受青睞,也是本文進行航天飛行器結構三維點稀疏重建的關鍵方法。在航空航天領域,對飛行器結構進行逆向工程是結構和力學設計優化的關鍵方法,對結構安全性和可靠性具有重要意義。因此急需發展一種方便、可靠的幾何測量方法對飛行器結構進行精確的三維測量。在結構試驗中,一般會在結構上布置大量的電阻應變片監測部件主要部位的變形。為了精確對比試驗測試與數值仿真結果,需要精確測量所有應變片的空間位置。當飛行器結構尺寸較大和粘貼的應變片的數量較多時,采用傳統的逐點式測量方法獲取應變片的三維坐標的難度和成本往往會很大。為此通過單相機多視角成像,發展了基于多視覺幾何的應變片三維坐標測量與定位方法,以期為航空航天領域飛行器結構的優化設計提供一種方便可靠的三維坐標重構技術。為了實現飛行器結構上應變片三維坐標的精確測量,使用一個標定[8,9]的單反相機對目標進行多角度成像,通過識別布置在結構上的編碼點,可靠地估計相機相對于參考幀的姿態信息;然后使用深度學習中的目標檢測技術,對圖像中的應變片進行識別和坐標提取,并結合特征匹配和相鄰幀之間的極線約束對相鄰圖像中的應變片進行匹配;最后利用三角測量原理,實現應變片的空間定位。
1 測量原理
本文實現大幅面測量區域內應變片的三維定位遵循單相機多視覺立體三維重構的一般步驟,主要涉及相機姿態估計、目標點(應變片)識別與匹配、以及三維坐標重構[10,11]。
在測量操作上,采用定焦相機(記為C)按照如圖1所示的方式對目標結構進行多視角成像,其中1C,2C,…,Ci,…,Cn為不同視角下的相機位置。為了能夠進行相機姿態估計和應變片坐標重構,在成像過程中需要控制相機使相鄰幀Ci和 1Ci+的視場需具有足夠的重合區。在獲得至少兩幀圖像后,即可相對于參考坐標系進行相機姿態估計和應變片三維坐標重構,最后根據在視場中放置的比例尺,可以確定結構的物理尺寸。以下對該過程中的主要方法進行詳細介紹。
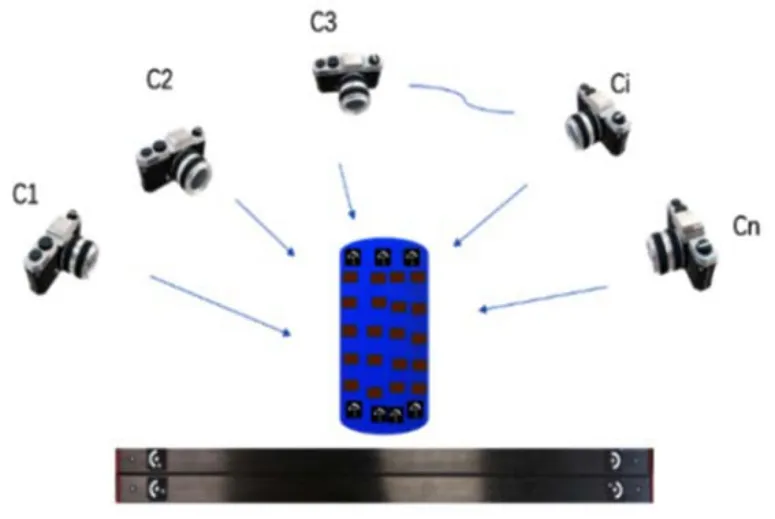
圖1 單相機多視覺測量示意圖Fig.1 Schematic diagram of multiple view measurement with a single camera
1.1 基于PnP算法的相機全局姿態估計
在應變片三維定位問題中,由于應變片的尺寸通常(最小3mm左右)遠小于目標結構的尺寸,且定位精度要求高,因此需要對相機姿態進行可靠估計。為此,本文假設測量相機的焦距固定,在測量前使用張氏標定法對相機內參進行預標定[12],然后在測量中以布置在目標結構上的編碼點為控制點,確定相機的姿態。由于編碼點具有唯一性、識別魯棒性好且定位精度高,可以比自然場景特征提供更加可靠的控制點信息,因此可以得到更精確的相機姿態估計。圖2為本文中使用的15位環形編碼點[13,14]。

圖2 編碼點示例Fig.2 Examples of coding points
在檢測到相鄰圖像中的共同編碼點后,可采用多點透視算法(Perspective-n-Point,PnP)相對參考坐標系確定相機姿態,包括旋轉矩陣與平移向量t∈3。假設以第一幀相機(C1)坐標系為參考系,則相機姿態的確定方法如下。在給定n對三維點和二維圖像點對應關系的前提下,可以利用PnP算法確定當前幀相對于參考坐標系的旋轉矩陣R與平移向量t。為此,重構第一二幀中觀察到的編碼點的初始三維坐標是進行PnP姿態估計的關鍵。由于相機內參已知,可以通過估計前兩幀之間的本質矩陣得到第二幀相對于參考系的姿態,然后進行三維重構得到初始三維坐標。假設在第一二幀中得到的編碼點坐標對為,其中pj1和pj2采用齊次坐標形式,下標j表示編碼點的序號。根據標定相機的極線約束原理[15],可以得到
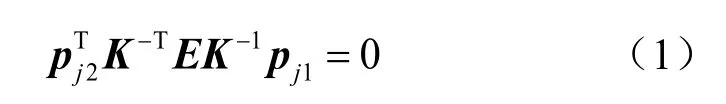
其中,K為已標定的相機內參矩陣;E為本質矩陣,表示當前幀相對于參考坐標系的姿態變換關系,即表示平移向量對應的反對稱矩陣)。根據式(1)可知,一對編碼點可為求解本質矩陣E提供一個方程。盡管是E是一個3×3的矩陣,但其秩為2(即行列式det(E)=0),因此需要八對編碼點即可確定本質矩陣E。對本質矩陣進行奇異值分解后,可以得到第二幀相對于參考坐標系的旋轉矩陣R和平移向量t。然后,可使用三角測量方法對每一對編碼點對應的三維坐標定初始的三維坐標,但由于PnP算法依賴于Pj進行進行重構。盡管上述過程可以確后續相機姿態的估計,因此提高Pj的重構精度有利于提高應變片定位精度。為此,本文進一步采用光束平差法(Bundle A djustment,BA)[16]對Pj進行優化。光束法平差的本質是求解關于相機姿態 (R和t)與三維點Pj的最小二乘優化問題,使得總體重投影誤差最小[17,18]。需要注意的是,在應變片三維定位中,為了保證透視投影模型下小尺寸應變的可識別性,相鄰兩幀相機的姿態變化不宜過大,因此而來的一個問題是相機的基線變化比物距小得多。如果在BA優化中直接以Pj的坐標為參數,往往會存在數值穩定性問題。為此這里采用逆深度參數化的方式表示空間點,然后建立BA優化模型。由于參考坐標系為第一幀相機坐標系,因此上述重構的三維點Pj的Z坐標即為其深度,于是其逆深度可以表示為wj=1/Zj。從而,Pj可以被逆深度參數化為P j=pj1/wj。根據初步估計的旋轉矩陣R和平移向量t,Pj可被重投影到第二幀圖像得到重投影圖像點坐標,然后與觀察到的對應點做差得到重投影誤差。將所有觀察到的編碼點的重投影誤差進行求和,可得到BA優化模型
其中,N為編碼點對數,〈〉為歸一化算子。通過求解上述模型,即可得到最優逆深度,然后根據逆深度參數化得到高精度的初始三維點Pj。在初始三維坐標確定之后,可使用PnP算法依次確定后續圖像幀相對于參考坐標系的相機姿態。由于在測量中應變片圖像序列往往比較長,單純使用PnP算法會存在一定的誤差累計。為了消除累計誤差,在新的姿態估計完成之后,可以對其及上一幀應用式(2)中的BA優化,可以同時提高每一幀中編碼點三維坐標重構精度和相機姿態的估計精度。
1.2 基于YOLO模型的應變片圖像識別
布置在結構表面的應變片尺寸小、數量多,而且外觀相似度比較高,因此很難采用人工識別或者傳統圖像處理的方式完成應變片識別。為了解決這個問題,本文采用深度學習的方式從圖像序列中識別應變片的坐標。目前,深度學習的目標檢測方法大體上分為2類,即兩階段目標檢測方法和一階段目標檢測方法。兩階段的目標檢測方法常見的有Faster R-CNN[19],這一類檢測方法往往先處理圖像生成候選區域,然后再對候選區域進行分類和回歸;其優點是檢測精度高,缺點是檢測速度比較慢。一階段目標檢測的代表性方法有YOLO[20]和SSD[21]等,這類方法不需要生成候選區域,直接通過圖像回歸出物體的類別和坐標,不生成二階段目標檢測方法所需的候選框,檢測速度快。在考慮應變片的特征后,本文使用YOLO(You Only Look Once)進行應變片識別[22,23]。YOLO模型使用一個單獨的 CNN 模型,實現端到端的目標位置檢測以及分類;與Faster R-CNN相比,YOLO速度快,而且準確率也很高[24,25]。YOLO算法直接把輸入的原始圖片分割成互不重合的小方塊,然后通過卷積運算遍歷每一個小方塊,產生特征圖,再得到與特征圖中對應的每個元素,從而達到目標點位置推理的目的。在應變片檢測任務中的具體細節如下。
首先建立應變片圖像數據集。對粘貼在結構表面的應變片進行多角度拍攝,通過數據增強的手段擴展樣本數量,使得樣本數量大于等于訓練YOLO模型的經驗值1500。然后人工標注每張圖像中的應變片的位置。標注完成后,按8:2的比例隨機將數據集分成訓練集和測試集,隨后開展模型訓練。采用Pytorch框架,構建了YOLO v 5x模型,并對其進行訓練。模型輸入端主要包含自適應圖片縮放、Mosaic數據增強和自適應計算錨定框。其中,Mosaic數據增強通過對圖像隨機的縮放、裁剪、排布,將同一組的圖像拼接起來,拼接后的圖像用于后續的模型訓練。訓練時,圖像按照輸入大小縮放為1280×1280像素后分組依次輸入Backbone主干網絡。Backbone網絡模型提取的特征圖的長度和寬度相對較大,然而最終分類定位的輸出維數相對較小,因此需要對特征維數進行壓縮。為此在主干網絡和檢測頭Head之間添加一個Neck層。Neck結構可更好地利用主干輸出的圖像特征,將其進一步融合后傳輸到檢測頭進行分類和定位。經過Neck網絡層壓縮和融合后傳遞給Head 輸出層,最后輸出應變片的類別和圖像坐標。為評估訓練的YOLO模型的性能,可采用mAP (Mean A verage P recision) 作為模型精度的綜合評價指標。在訓練完成后,評估模型的mAP@0.5的數值,當該指標大于0.95時,認為模型訓練達標。對成功訓練的YOLO進行部署后,進行應變片檢測。
1.3 應變片的立體匹配和重構
通過第1.1和1.2節,我們可以得到相鄰幀之間相機姿態信息和每幀圖像中的應變片坐標。接下來就可以通過立體匹配的方法對相鄰幀可見的應變片進行匹配,然后采用三角測量計算空間位置。相機姿態估計得到的旋轉矩陣和平移向量可為應變片的匹配提供極線約束,這樣可以減小搜索范圍,提高匹配效率和降低誤匹配率。應變片匹配中的極線約束如圖3所示。由于應變尺寸很小,且彼此之間相似度較高,因此為了在極線約束區域內得到穩定的匹配結果,需要再引入兩個約束條件。首先,將YOLO模型檢測到的應變片視為特征點,它們在相機進行移動和旋轉時,會因視角變化產生尺度和方向上的變為。為了解決這一問題,本文利用尺度不變特征描述(feature descriptor)[26]提取每個應變片的特征向量,然后在相鄰兩幀圖像中按照距離最近原則進行特征向量搜索,得到匹配分數最高的一對描述子,將它們對應的應變片視為最佳匹配。需要注意的是,此時得到的最佳匹配并不唯一,需要進一步篩選。考慮到拍攝圖像時相機的移動范圍較小,相鄰圖像中的目標發生的是仿射運動,所以相鄰圖像中的應變片和編碼點的移動趨勢具有高度的一致性。因此,可以依據編碼點的匹配關系,確定相鄰幀間的仿射變換關系,對上述匹配得到的應變片進行進一步篩選,提高應變片的匹配準確度。最后,結合相機之間的空間位姿關系,即可確定檢測出的應變片在世界坐標系中的三維坐標。
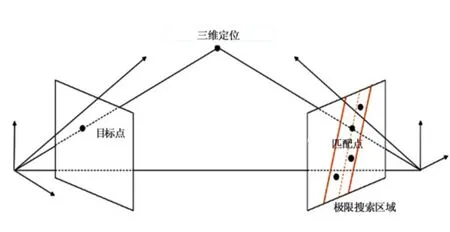
圖3 極線搜索示意圖Fig.3 Epipolar constraint relationship
2 實驗驗證
實驗采用佳能EOS 5D Mark IV單反相機,分辨率為4464×2976像素。為了驗證本文方法的重構精度和應變片三維定位的可行性,實驗部分包括兩個方面的內容。首先,采用精度為1μm兩根高精度標尺驗證定位精度;然后,對一個粘貼有86個應變計和25個編碼點的圓柱形結構(直徑300 mm)進行測量。
2.1 定位精度驗證
精度驗證中使用了如圖4所示的兩根標尺,標尺上兩個定位圓之間的長度分別為949.880 m m和949.606 mm。

圖4 精度驗證用的標尺Fig.4 Scale bars for accuracy validation
測試中,對圖4中包含兩個標尺的場景進行5次成像,并對標尺長度進行重構。需要注意的是,為了保證精度測量的合理性,在估計相機姿態時僅使用不在標尺上的編碼點。在重構標尺時,以較長的標尺作為長度參考,然后重構較短標尺上兩個定位圓的坐標。得到定位圓坐標后,將兩個定位圓之間的距離作為標尺長度的測量值,然后與標尺的實際長度(即949.606 mm)進行比較,得到重構誤差,結果如表1所示。根據驗證結果可知,5次測量得到的最大絕對誤差值為0.120 mm,平均值為0.098mm(四舍五入后為0.100 mm)。根據圖4可以看出,測量的水平視場大小約為1 m,說明對于1 m大小的物體,本方法的定位精度可以達到0.100 mm/m。

表1 精度驗證結果Table 1 Accuracy verification results
2.2 圓柱結構應變片測量
在精度驗證之后,使用本文方法對布置在直徑為300mm圓柱上的應變片(86個)進行定位測量。在采集圖像時,相機環繞目標結構移動,并確保相鄰圖像有重疊部分,共拍攝32張圖片,如圖5所示。由于目標結構特征尺寸僅有300 mm,為了不使目標結構在圖像中的占比過小,本次測量中使用一根較短的標尺(長度為551.423mm)恢復結構的物理尺度。測量中首先使用訓練的YOLO模型識別單反相機拍攝的圖像中的應變片。由于采用了重疊成像的方式,每幀圖像能夠清晰的記錄部分應變片的信息,將訓練后模型應用到這種重疊圖像序列,可以保證能夠識別到圓柱結構上的所有應變片,識別效果如圖6所示。然后,在確定各個相機的位姿關系后,以第一幀圖像對應的相機坐標系為參考,根據第1節中的方法對應變片進行匹配和三維重構。需要注意的是,并非所有在第一幀中的應變片都能夠在第二幀中找到對應的應變片,由于拍攝視角的遮擋關系,會有一部分應變片在第二幀中無法找到對應的應變片。因此,在完成對第一幀應變片空間定位后,繼續對第二幀中未配對的應變片與第三幀中的應變片進行匹配,然后依次再進行重構。需要說明的是,在此種情況下,應變片的空間坐標是基于前一幀的相機坐標系進行確定的,需要根據坐標轉換將其映射到全局參考坐標系。通過上述處理過程,最終完成對圓柱殼表面所有應變片的三維定位,如圖7所示。為了說明重構的可靠性,根據應變片的三維定位結果對圓柱進行了擬合,得到圓柱直徑為300.052mm,其相對與真實直徑的誤差僅為0.052 mm。由于測量視場約為0.55 m,可換算得到1 m視場下的定位精度約為0.100mm/m,這與 第2.1節中的結果相吻合。

圖5 拍攝的序列圖像Fig.5 Sequential images

圖6 應變片識別示例Fig.6 Examples of strain gauge recognition

圖7 應變片三維重構結果Fig.7 Three-dimensional reconstruction of strain gauges
3 結論
本文介紹了一種基于單相機的多視角三維測量方法,實現了圓筒構件上應變片三維坐標的定位。該方法利用編碼點對相機姿態進行高精度估計,然后采用YOLO模型對應變片進行識別,得到應變片的圖像坐標。最后基于相鄰相機的位姿關系,依次完成所有應變片的立體匹配和三維空間定位。實驗表明該方法操作簡單,可以實現大幅面結構上小應變片的識別定位;對于1 m以內大小的結構,本方法的定位精度可以達到0.100 mm/m。本文方法不僅適用于應變片,在后續的研究中,將嘗試通過訓練其它被測小目標物體的深度學習模型,從而重構出這些物體的三維坐標,具潛在的實際應用價值。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:02
中華詩詞(2019年7期)2019-11-25 01:43:04
中學生數理化·八年級物理人教版(2019年3期)2019-04-25 06:20:54
中學生數理化·八年級物理人教版(2018年3期)2018-05-31 08:52:45
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
海峽科技與產業(2016年3期)2016-05-17 04:32:12
