基于改進膠囊網絡的音調篡改檢測算法*
2022-09-24 03:44:34杜海云王宏霞
通信技術 2022年8期
杜海云,王宏霞
(四川大學,四川 成都 610207)
0 引言
多媒體技術的迅速發展讓音頻編輯變得方便,也讓編輯后的音頻更加逼真,但也存在潛在的威脅,如人耳可能很難分辨經過音頻編輯軟件修改的語音。此外,此類軟件很容易獲取,如果犯罪分子加以利用進行詐騙,或是案件審理過程中將偽造的語音作為證據呈遞,會導致音頻文件的安全性和真實性受到質疑[1-6]。常見的音頻偽造方式有音色轉換、語音合成和語音變調,其中,音色轉換可以模仿目標者的說話音色,迷惑聽者或說話人識別系統;音調修改能隱藏當前說話人的身份信息,比如在采訪節目中通常會對被采訪對象的語音進行變調處理來保護人身安全。在音頻編輯軟件工具和算法盛行之前,通常借助非電子方式變調,比如捏鼻,但要求說話人具備一定技巧。而音頻編輯軟件的出現降低了篡改語音的難度,因此篡改語音無需太多知識和技巧。然而,對音調進行篡改也有負面性,可能對說話人驗證系統(Automatic Speaker Verification,ASV)產生威脅。為了保證音頻文件的安全性不受質疑,需要檢測算法能夠識別音調篡改。此外,在真實場景下可能會存在各種噪聲和壓縮情況,而且噪聲種類和強度各異,壓縮編碼格式和強度也各不相同。壓縮和噪聲的存在會讓聽感不自然,而且還會對算法的性能和ASV 系統的性能產生影響,所以設計的篡改語音檢測算法需要能夠抗衡噪聲、壓縮等真實場景下可能存在的這些干擾因素,即要求算法具有一定的魯棒性。
音頻篡改檢測也被稱為音頻取證,分為主動取證和被動取證兩種,主動取證會通過數字簽名、水印等方式檢測篡改[7],而被動取證無須預先嵌入信息來檢測真偽,更加符合實際場景對算法的需求。
語音篡改檢測領域發展至今已有一些成果。2013 年,Wu 等人[8]通過梅爾頻率倒譜系數(Mel-Frequency Cepstral Coefficients,MFCC)特 征,對電子偽造語音進行檢測。隨后有研究將MFCC 的統計特性作為特征進行檢測,性能有所改進[9]。2017年,Cao 等人[10]利用線性頻率倒譜系數(Linear Frequency Cepstral Coefficients,LFCC)作 為 特 征檢測音調篡改,但是在信噪比(Signal to Noise,SNR)較低的情況下,算法性能有所下降。2019 年,Wang 等人[11]在短時傅里葉變換(Short Time Fourier Transform,STFT)頻譜圖的基礎上,結合改進的DenseNet 網絡設計檢測算法,在純凈語音數據上取得了較好的檢測結果。同年,Dou 等人[12]提出了基于多分辨率的類耳蝸系數特征(Least Mean Square-Multi Resolution Cochleagram,LMS-MRCG)的算法,對含噪聲的、音調篡改的語音進行檢測,但同樣在低SNR 環境下性能變差。2020 年,Ye 等人[13]研究了基于LFCC 特征和卷積神經網絡(Convolution Neural Network,CNN)的方法,對音調篡改進行檢測,算法表現較好,但實驗中設計了過低的變調因子篡改的語音,而變調因子過低很可能無法隱藏說話人身份,說話人身份信息保留較為明顯[3]。從以往的研究當中可以看出,該領域針對魯棒性的研究較少,而且這些研究提出的算法在有噪聲影響下,性能下降較為明顯。
針對當前音調檢測算法普遍魯棒性較弱的問題,提出了一種基于改進膠囊網絡的音調篡改檢測算法。同時為增強算法的魯棒性,將相對頻譜感知線性預測(RelAtive SpecTrAl-Perceptual Linear Predictive,RASTA-PLP)特征和MFCC 特征進行融合,同時將提取特征、一階差分系數和二階差分系數映射至3 個通道構成整體特征,然后輸入到改進的膠囊網絡當中。該算法在檢測不含噪聲、含已知噪聲、含未知噪聲以及經過壓縮的音調篡改語音實驗中表現均較好。
1 基于改進膠囊網絡的音調篡改檢測算法
1.1 特征提取
目前語音變調的方式多為時域法,包括重采樣和時域尺度變換兩步,可改變信號頻域信息。因此檢測音調篡改的語音時,所使用的特征應當在識別不同變調因子篡改的語音時具有區分度。
變調語音檢測中常見的特征有MFCC、線性預測編碼系數(Linear Prediction Coding Coefficients,LPCC)、LFCC 等。在聲學的其他相關領域中,感知線性預測系數(Perceptual Linear Predictive,PLP)和RASTA-PLP 特征也較為常見,面對魯棒性問題,這兩種特征通常用于加強算法的魯棒性,這點在語音識別任務中有所驗證[14]。RASTA-PLP是基于PLP 特征所設計的特征。PLP 特征經過人類聽覺模型處理機制處理,輸入信號選擇經過聽覺模型機制處理后所得到的信號,代替線性預測系數分析過程所使用的時域信號,更有利于魯棒性強的語音特征提取。PLP 基于聽覺模型的處理步驟包括臨界頻帶分析、等響度預加重和強度—響度變換。RASTA-PLP 特征在PLP 特征基礎上加入RASTA 濾波技術,改善了短時語音頻譜易受到通道噪聲影響的問題。RASTA 濾波通過利用低端限制頻率很低的帶通濾波器對語音進行處理,信號當中穩定的頻率成分會被抑制,意味著對通道噪聲也能進行一定程度的抑制[15]。RASTA-PLP 的特征提取過程如圖1 所示,和PLP 特征提取過程類似,RASTA 濾波處理過后的信號共振峰結構保持良好。
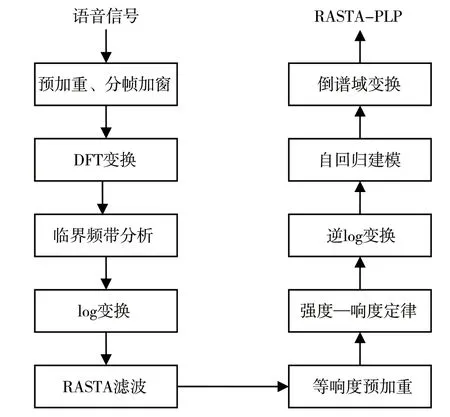
圖1 RASTA-PLP 特征提取過程
如果經過變調處理,RASTA-PLP 的特征值也會發生改變。在TIMIT 劃分的測試集中提取的第1維度的RASTA-PLP 特征值如圖2 所示,圖中橫坐標分別表示+8 變調、原始語音和-8 變調的語音,縱坐標表示每種類型語音在所有分量上的平均值。可以看到第1 維度的特征值對于升調和降調都較為敏感,同時其他維度的特征也在升調或者降調時遵從類似的規律。RASTA-PLP 特征在區分不同變調語音時是可區分的,因此可以視為檢測變調語音的特征。由于RASTA-PLP 特征也具有良好的抗噪性,所以通過融合RASTA 和PLP 特征來增強檢測算法的魯棒性。
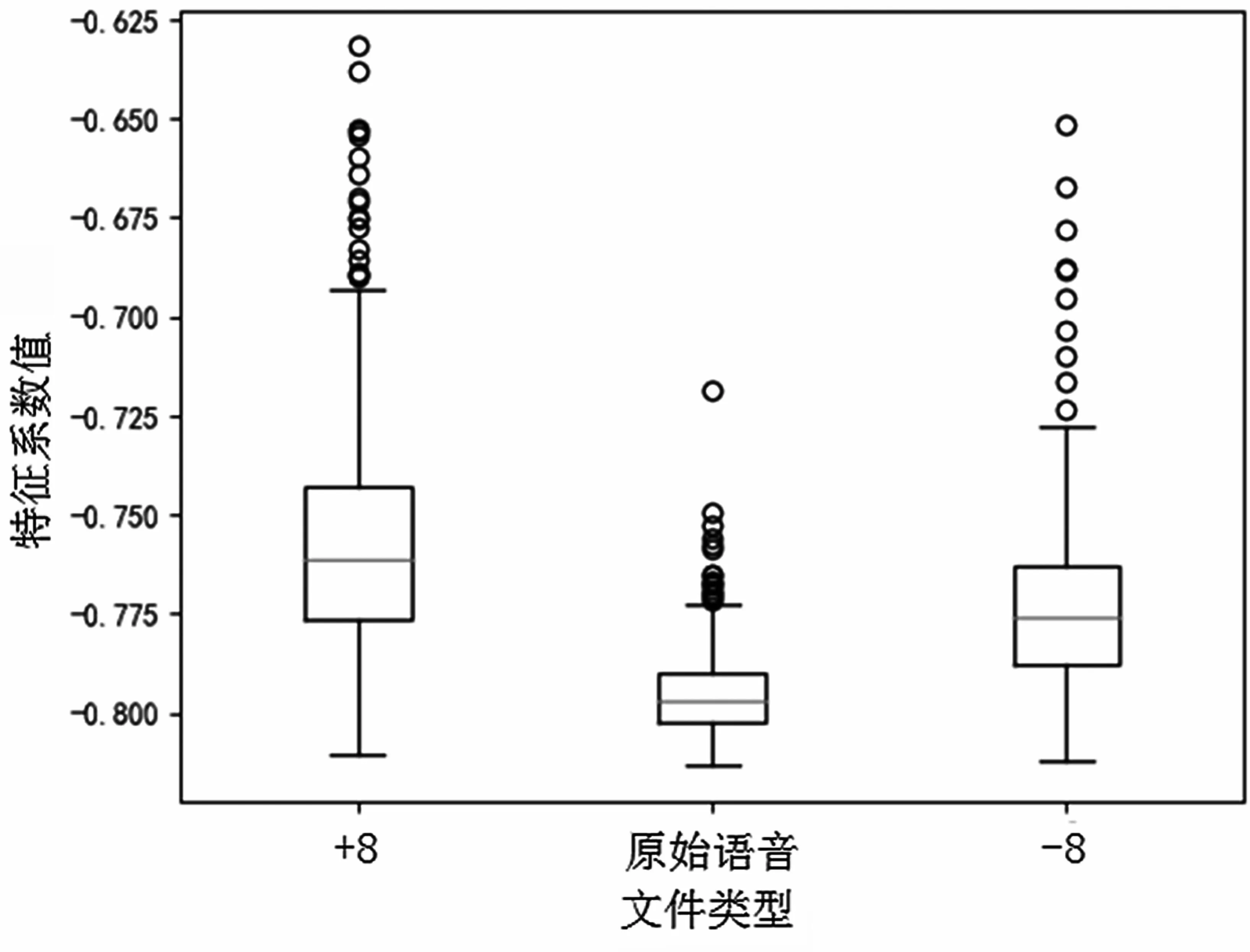
圖2 在TIMIT 測試集中RASTA-PLP 特征第1 維度的分量
MFCC 特征在變調語音篡改檢測任務中表現良好,其特征提取過程如圖3 所示。MFCC 特征提取過程中,輸入信號經預處理后需要經過快速傅里葉變換(Fast Fourier Transform,FFT)、Mel 濾波器、對數(log)運算和離散余弦變換(Discrete Cosine Transform,DCT),最終選取特征值得到MFCC 特征。
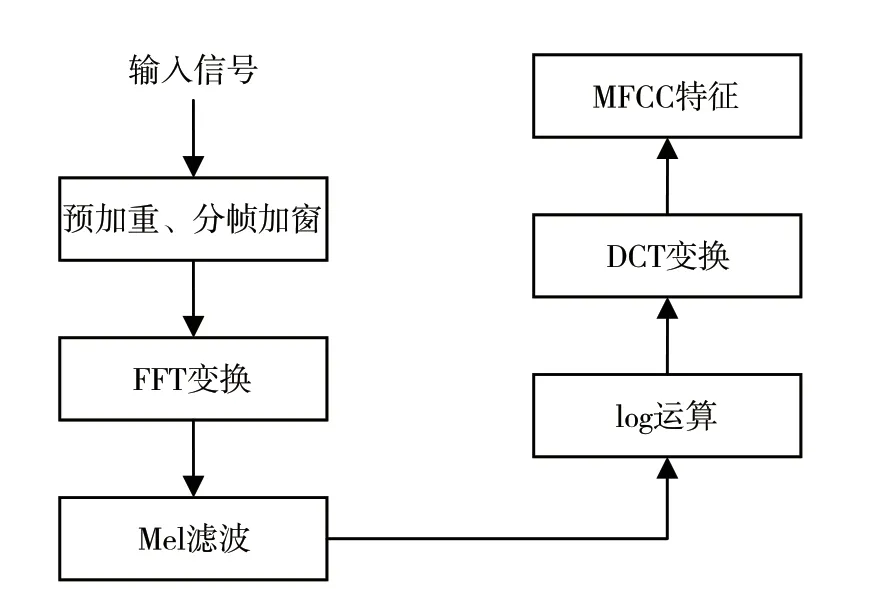
圖3 MFCC 特征提取過程
以特征MFCC 提取過程為例[9],信號經預處理后,需要先經過FFT 變換,FFT 變換會計算每幀的頻譜信息,再經過Mel 濾波器處理。該步驟的計算過程為:
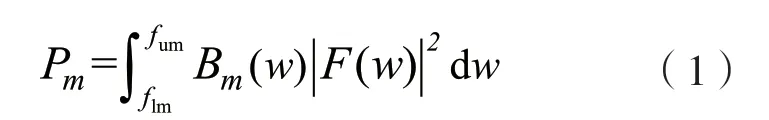
式中:w為信號幀的索引;F(w)為信號的頻譜信息;B(w)為Mel 濾波器;下標m指經過的第m個Mel濾波器,1 ≤m≤M,M為Mel 濾波器的數量;fum為濾波器截止頻率的上限;flm為截止下限頻率;Pm為經過Mel 濾波器得到的功率。
對音頻進行變調,會改變信號的頻域信息,從而對FFT 和Mel 濾波器對信號的處理產生影響,頻譜信息和功率都會發生改變,進而影響最終的MFCC 特征值,該特征值針對不同的音調改變也是具有區分度的,因此認為MFCC 可以用來檢測音調篡改的特征。同時引入MFCC 特征的相關系數矩陣。假設MFCC 特征維度為L,對第j維度和第j′維度的分量計算相關系數,其中1 ≤j≤j′≤L,則相關系數矩陣特征的計算公式為:
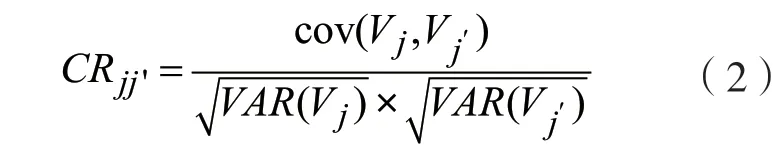
式中:Vj為第j維度的所有分量;cov 為協方差運算;VAR為方差運算;CRjj′為第j維度和第j′維度分量的相關系數。算法中使用的特征融合了RASTAPLP 特征、MFCC 特征及其相關系數矩陣,該融合特征可以表示為:
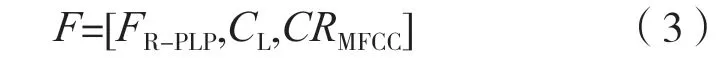
式中:FR-PLP為RASTA-PLP 特征系數;CL為MFCC特征;CRMFCC為MFCC 特征相關系數。拼接融合這些特征為F,構成了檢測算法的輸入特征信息。
同時,在特征提取時還計算了特征的一階差分系數和二階差分系數,但是并未將特征和差分系數值進行串聯拼接,而是映射至特征圖像的RGB 三通道中,作為網絡的輸入信息。
1.2 網絡結構
本文使用的網絡結構為改進的膠囊網絡(Capsule Net)結構,膠囊網絡結構是在2017 年由Hinton 等人[16]提出的。早在2011 年,膠囊的概念就有了雛形,之后對此概念進行了拓展和優化形成了膠囊網絡,發展至今也出現了膠囊網絡的各種變體。
CNN 網絡在各種任務當中都有運用,但是隨著研究的深入,其短板也暴露在視野中。CNN 多借助池化、卷積等非線性操作由淺到深逐層提取特征,最終對局部特征進行整合,但因為卷積池化運算會導致部分特征信息丟失,而丟失的特征信息可能對目標任務有幫助,并且最終層獲取的信息一般是輸入信息的很小一部分。此外,CNN 網絡雖對減少模型參數量、計算量有益,但同時性能可能會下降。CNN 無法對輸入數據內部的相對位置信息進行學習,一般只能判斷是否存在某種模式,而膠囊網絡讓網絡對輸入數據的學習更加充分。
在膠囊網絡中,特征表征的基本單位是膠囊結構,并將特征信息以向量的方式進行表達,而CNN的輸出是標量形式。膠囊網絡本質是一組多維向量,膠囊輸出的模長表示該膠囊學習的模式出現的概率大小,例如如果輸出向量的模長接近1,那么代表出現可能性接近100%。
初始膠囊網絡結構在單個膠囊結構、路由算法和激活函數的設計和CNN 網絡存在差異。單個膠囊結構的計算過程可以簡化為圖4 的流程,首先和輸入相乘,膠囊的輸入v是上個膠囊的輸出;其次將w和輸入v相乘,得到u,對向量進行加權處理,即將各個權重c和u分別進行相乘,其中c為標量;再次對加權后的向量進行求和,記為s;最后將其輸入激活函數,膠囊網絡的激活函數為Squashing非線性函數,其定義為:
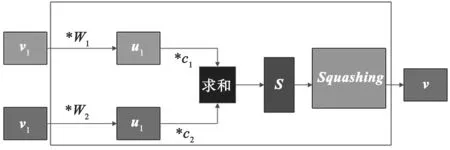
圖4 膠囊結構計算過程
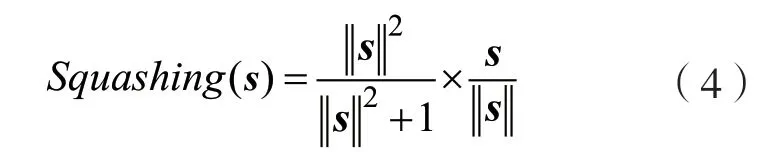
式中:等號右邊第一個分式代表對s進行縮放,第二個分式可以視為s同等方向的單位向量。通過Squashing 函數能夠很好地保留s的方向信息,并且將長度保證在0~1 之間,實現對向量的壓縮和重分配,減少計算量。
在計算過程中,權重c是通過路由算法進行更新的,膠囊層內權重c的和為1。在2017 年提出的初始膠囊網絡中,并非全部都為膠囊層,淺層結構中也存在卷積結構。淺層卷積結構提取輸入信息中的低維特征,送入主膠囊層(PrimaryCaps)和數字膠囊層(DigitCaps),對深度特征進行提取。在主膠囊層中也存在卷積結構,主膠囊層的輸出會送入數字膠囊層,數字膠囊層是全連接結構,輸出代表分類結果,并且輸出是向量形式,通過輸出模長可判斷輸入信息是否存在某種模式,是否屬于某個類別。
初始膠囊網絡結構的淺層卷積所提取的特征可能無法很好地表示前端提取的特征,而且面對復雜輸入和分類情況,算法性能可能欠佳。因此通過改進膠囊網絡的卷積層結構來優化算法,加深輸入膠囊層的特征信息,令膠囊網絡更加適應輸入信息和篡改檢測任務,從而提升算法的性能,并且通過仿真實驗證明,改進的算法具有一定的魯棒性。
圖5 展示了該算法的大致網絡結構,輸入的特征圖像即融合特征F原是具有三通道的圖像,但送入網絡前進行處理,轉化為灰度圖像,轉化過程為:L=G×587/1 000+R×299/1 000+B×114/1 000(5)式中:R,G,B分別代表RGB 3 個通道中的像素值。對3 個通道中的信息都進行保留,R通道代表靜態特征信息,G和B通道代表動態特征信息。
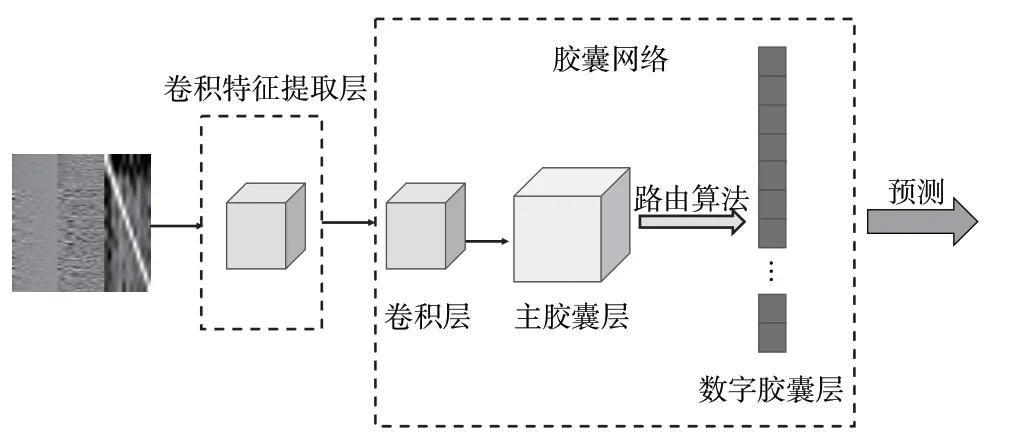
圖5 改進的膠囊網絡結構
因此,輸入的訓練數據實際大小為(224,224,1),之后對卷積層進行改進,將第一個卷積層卷積核大小設置為(9,9),輸出設置為64 維,步距為4,填充為2,激活函數為ReLU,池化函數為自適應平均池化函數,該函數可以自動調整輸出為程序中指定的維度。實驗中將該池化層輸出設置指定為(28,28,64),送入后續卷積層。詳細網絡結構參數設置見表1,表中介紹了網絡層各層的輸出和一些參數設置。

表1 改進的膠囊網絡結構參數
2 實驗設計與分析
2.1 數據集
實驗數據來自TIMTI 數據集和TCHCHS30 數據集,對數據集內的純凈語音進行變調處理,變調工具使用Adobe Audition。實驗中,TIMIT 數據集的訓練集和測試集的數量比為9,即訓練集5 670 句,測試集630 句;THCHS30 數據集是中文普通話數據集,訓練集選擇5 000 句,測試集500 句。變調因子范圍為±4~±5,該范圍的變調語音屬于較弱的變調,如果變調因子小于此值,變調后的語音無法有效隱藏說話人身份信息,但同時過高的變調因子會令語音聽感不自然而令人生疑。由于篡改檢測算法在弱變調語音上一般性能會下降,因此為了尋求弱變調語音情況下篡改檢測性能較好的解決方案,選擇了±4~±5 的變調范圍。
同時為了驗證算法的魯棒性,對語音進行加噪和壓縮處理,噪聲來自SPIB 數據集,選擇其中說話人噪聲、白噪聲、車輛噪聲、粉紅噪聲和通信信道噪聲。為測試算法在未知噪聲場景下的性能,車輛和通信信道噪聲僅在測試集加入,其余噪聲類型在訓練集、測試集均加入,每個語音文件都加入一種噪聲,強度不同,加噪后每個語音的SNR有20 dB、10 dB 和0 dB 3 種。壓縮則是將文件壓縮為比特率分別為64 kbit/s、128 kbit/s 和192 kbit/s 的MP3 文件,而原始語音文件的比特率是變化的,普遍為140 kbit/s 左右。在抗壓縮性實驗中考慮了比特率降低和虛高的情況,并且訓練集和測試集均是由3 種比特率壓縮后的語音混合而成,未將3 種壓縮比特率單獨實驗。
2.2 性能分析
實驗所使用的特征為第1 節中描述的融合特征F。將F的靜態和動態特征分別映射至RGB 三通道,但是在網絡的輸入端對特征圖像進行灰度處理,轉化為單通道輸入圖像,以另一種方式保留特征信息。模型訓練時優化器選擇Adam,學習率初始設置為0.000 1,衰減設為0.98。實驗將改進的膠囊網絡模型與一些經典分類模型AlexNet、ResNet 和初始膠囊網絡結構在設計的特征F上進行對比。在初始膠囊網絡實驗中,僅根據變調檢測任務的分類數改變相關參數,即輸出膠囊設為5,分別對應±4~±5和真實的語音文件分類。
算法性能評價指標為準確率。無噪聲環境下變調語音篡改檢測實驗結果如表2 所示,表中的結果分別展示了其他模型和改進的膠囊網絡在TIMIT 數據集和THCHS30 數據集上的性能,其中ResNet 模型為ResNet34。從表2 中的實驗結果可以看出,在無噪聲時所有模型在TIMIT 數據集和THCHS30 數據集上的表現都較好,改進后的膠囊網絡表現比初始膠囊網絡性能有所提升,改進的CapsNet 網絡能夠增強在無噪聲環境下的檢測算法性能,說明對特征卷積層進行加深在一定程度上能夠加強性能。
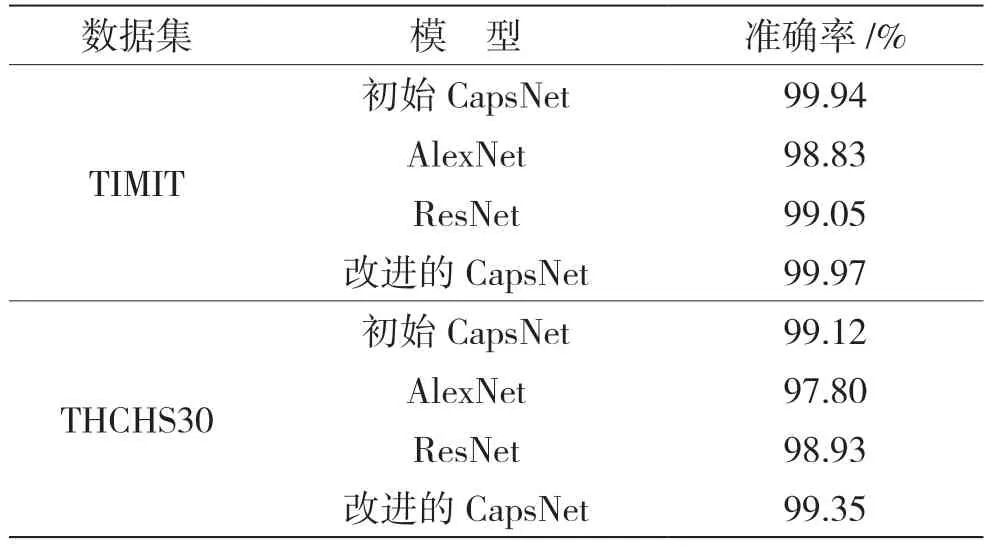
表2 無噪聲環境下,不同模型的檢測準確率
接下來對算法在噪聲和壓縮場景下的魯棒性進行實驗。在已知噪聲場景、未知噪聲場景和壓縮場景下的語音檢測準確率實驗結果見表3,對比模型選擇的是在無噪聲場景下表現較好的初始CapsNet。
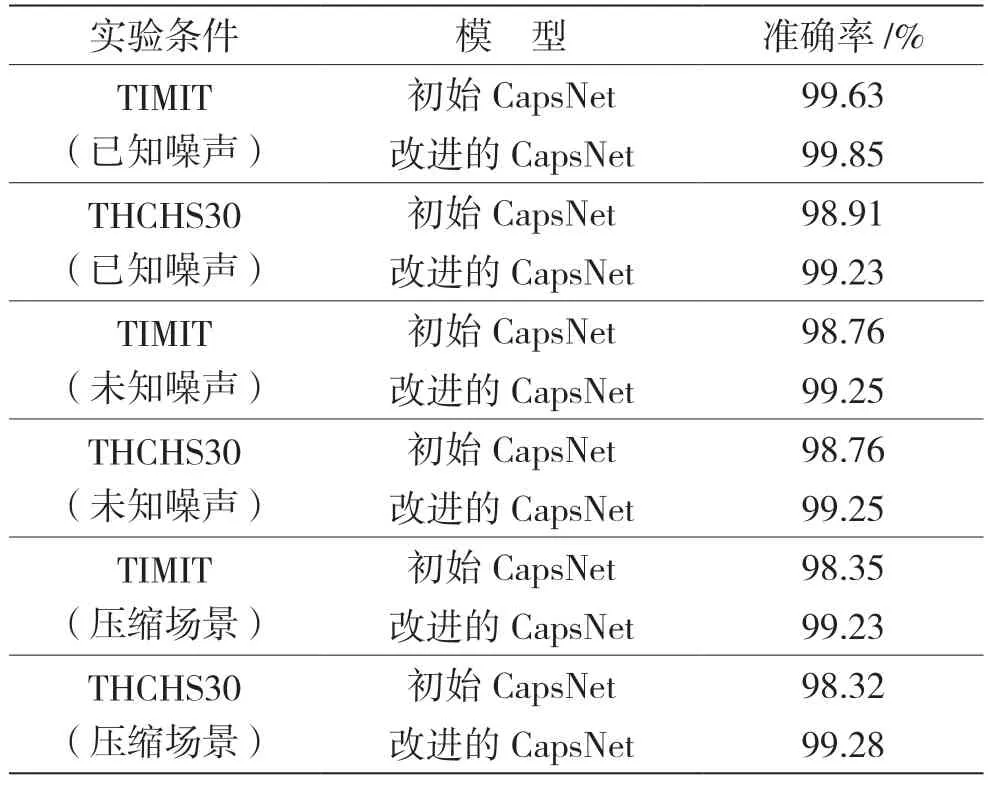
表3 在已知噪聲、未知噪聲和壓縮情況下,不同模型檢測準確率的比較
通過表3 結果可以得知,即使有噪聲影響,膠囊網絡的結構也可以對數據進行較好的訓練,在已知噪聲和未知噪聲場景下算法性能受到的影響較小。雖然在未知噪聲場景下算法性能較在已知噪聲環境下有輕微幅度的下降,但算法保持著良好的抗噪性。在面對MP3 壓縮時,初始膠囊網絡表現略差于改進的膠囊網絡,并且較無噪聲無壓縮環境下性能下降較多。通過該實驗可以認為,利用特征F結合改進的膠囊網絡結構可以實現良好的抗壓縮性。因此,通過實驗結果可知該算法具有良好的魯棒性。
3 結語
語音編輯技術可能會引發安全問題,如果用于犯罪可能會對社會造成嚴重威脅。本文針對語音變調篡改檢測展開研究,通過融合RASTA-PLP 特征和MFCC 相關特征,同時改進膠囊網絡結構進行語音篡改檢測。通過與其他算法進行對比實驗可知,本文設計的算法在面對噪聲和壓縮這些常見的干擾因素時,能夠保持良好的魯棒性。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
