一種改進的Turbo 碼結構設計及DSP 實現*
2022-09-24 03:44:46梁立林
通信技術 2022年8期
梁立林
(中國電子科技集團公司第十研究所,四川 成都 610036)
0 引言
1993 年,Turbo 碼的發明掀起了信道編碼理論和技術的一場革命,對該領域的理論和工程實現產生了深遠的影響。如今,Turbo 碼被廣泛用于民用3G 和4G 通信以及數據鏈通信等系統中。
在5G 發展的推動下,2016 年,以Ericsson和Orange 為代表的一些公司和機構提出了增強型Turbo 碼方案。該增強型Turbo 碼在長期演進(Long Term Evolution,LTE)標準Turbo 碼的基礎上進行了一系列的改進,如文獻[1]提出了咬尾編碼方案,使增強型Turbo 碼在短碼時也有良好性能,同時也解決了高碼率下的錯誤平層問題;文獻[2]通過引入更多的校驗比特分支,使低碼率場景性能得到了提升。此外,增強型Turbo 碼也引入了新的打孔、交織方案等。增強型Turbo 碼相比于傳統Turbo 碼性能提升明顯,且實現結構改動較小,易于工程實現,具有極高的研究價值。
隨著近些年軍事裝備的高速發展,數據鏈通信領域對抗干擾性和通信速率提出了更高的要求,因此編譯碼器需要更高的誤碼率(Bit Error Ratio,BER)性能和更大的碼率范圍。本文基于增強型Turbo 碼方案,進行了并行譯碼算法的研究。首先參考增強型Turbo 碼的設計思路,采用咬尾碼方案,提升了高碼率下的性能;其次設計了更低碼率的編譯碼結構,改善了低碼率場景下的性能;最后結合并行譯碼算法和數字信號處理器(Digital Signal Processor,DSP)芯片的優化技術,對譯碼器的DSP 實現進行了優化,使譯碼計算效率得到了大幅提升。
1 算法設計
1.1 增強型Turbo 碼
增強型Turbo 碼采用咬尾編碼結構,編碼時先進行一次預編碼,根據預編碼輸出狀態計算得到能咬尾的初始狀態,再用該初始狀態進行第二次編碼,從而得到編碼輸出。此方法使每個分量編碼器的初始和最終狀態都是相同的,并且咬尾編碼結構沒有引入額外的傳輸比特,因此沒有碼率損失。同時,碼的網格圖可看成環,迭代譯碼的過程可以看作是在網格圖上的不斷循環,循環的結構避免了低權重截斷碼字的出現,因此采用咬尾的方式能有效解決目前Turbo 碼存在的錯誤平層問題[1]。
LTE Turbo 碼的母碼率為1/3,通過打孔和重復方式可改變碼率。增強型Turbo 碼相對于LTE Turbo碼增加了兩路校驗位,可支持更低的母碼率,低碼率下更具性能優勢[2]。
增強型Turbo 碼采用的是近似正則置換(Almost Regular Permutation,ARP)交織器[1]。為取得更好的性能,增強型Turbo 碼的交織器和打孔采用了聯合設計方法。增強型Turbo 編碼器的結構如圖1所示。
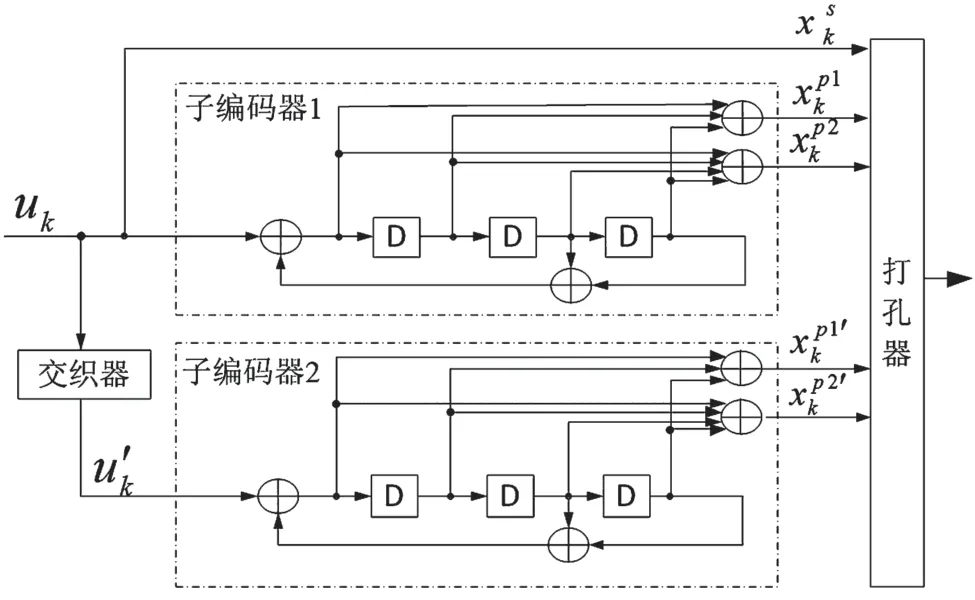
圖1 增強型Turbo 碼編碼器結構
采用咬尾編碼方案后,碼的網格圖可看成環。最大后驗概率(Maximum A Posteriori,MAP)迭代譯碼的過程可以看作是在環狀網格圖上的不斷循環,且無須進行尾比特特殊處理,第一次迭代時前向和后向度量可初始化為等概率值。通過兩個軟輸入軟輸出譯碼器循環不斷地交替譯碼,來改善相互傳遞的外信息[3]。
Turbo 譯碼器結構如圖2 所示。接收信息經解打孔器后得到ys,y p和y^p,分別為系統位信息、校驗位信息和經過交織的校驗位信息。L為譯碼器輸入的先驗信息,Le為譯碼器輸出的外信息,LLR為最終譯碼輸出的對數似然比。
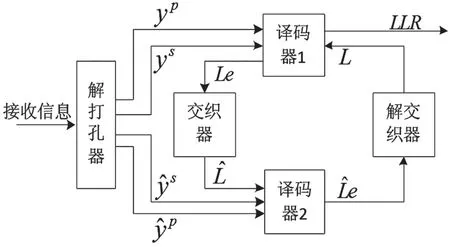
圖2 Turbo 譯碼器結構
1.2 MAP 譯碼算法
目前常見的MAP算法有Log-MAP、Max-Log-MAP、SF-Max-Log-MAP 等。相對于Max-Log-MAP,SFMax-Log-MAP 僅增加了在外信息傳遞時乘以SF 修正因子的步驟,性能卻得到了較大提升,并與Log-MAP相差不到0.1 dB[4]。因此在實際工程中,更適合采用SF-Max-Log-MAP 算法來降低運算復雜度。
SF-Max-Log-MAP算法基于編碼的網格圖,其中,s′為前一個狀態,s為當前狀態,為k時刻對應的發射系統位,為對應的發射校驗位,為對應接收到的系統位信息,為接收到的校驗位信息。定義Ak(s)為對數前向狀態度量;Bk(s)為對數后向狀態度量;Γk(s′,s)為對數分支度量;Lc為信道信噪比參數;L(uk)為先驗信息;LLR(uk)為對數似然比;Le(uk)為外信息;SF為比例因子,取值為0.75。
在計算前向和后向狀態度量時,隨著迭代次數的增加,計算結果幅度逐漸增大,會導致定點實現時結果溢出,所以采取最大值歸一化方法來限制其幅度。整理算法公式如下:
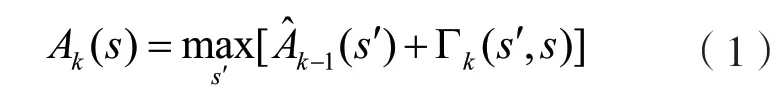
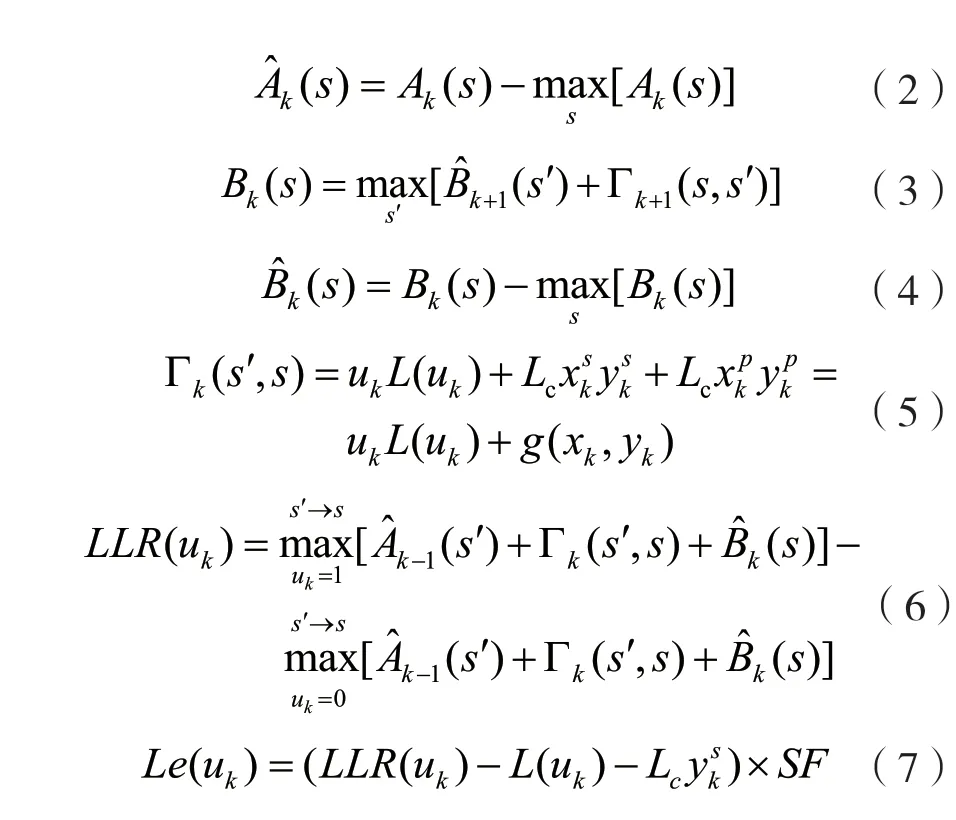
1.3 并行譯碼算法
MAP 譯碼算法采用的是遞歸的計算方式,這導致譯碼器難以實現并行化,因此為了減少譯碼延遲,可采用并行譯碼算法。常用的并行譯碼算法有傳統的分塊并行譯碼算法和較為先進的全并行譯碼算法[5]。分塊并行譯碼算法中的邊界狀態迭代分塊并行譯碼算法中[6],各子塊間沒有交疊,每完成一次迭代,將各子塊交換相鄰邊界處的前向和后向狀態度量作為下一次迭代的初值,隨著迭代的進行,邊界值也將不斷逼近真實值。增強型Turbo 碼采用了咬尾編碼方案,因此各子塊相鄰邊界處的前向和后向狀態度量也能自然銜接,更加符合邊界狀態迭代分塊并行算法的結構。此外,考慮DSP 實現的復雜度,選用邊界狀態迭代分塊并行譯碼算法。
設原始碼塊長度為L,將其分成M個并行子塊。分別表示m子塊在第i次迭代時k位置處的前向和后向狀態度量,m編號為1~M。初次迭代時,將前向和后向狀態度量的初值設置為等概率值。后續迭代中,將第i次迭代中m子塊的前向狀態度量最終值作為第i+1 次迭代時,mod(m+1,M)子塊的初始值將第i次迭代中mod(m+1,M)子塊的后向狀態度量終值作為第i+1 次迭代時,m子塊的初值
1.4 改進的低碼率設計
增強型Turbo 碼增加了1/5 的母碼率設計,在文獻[7]的仿真中,相對于從1/3 碼率簡單重復得到1/5 碼率的Turbo 碼有0.5 dB 的BER 性能提升。參考這一思路,本文提出了1/7 和1/9 的母碼率設計方案,編碼器結構如圖3 所示。
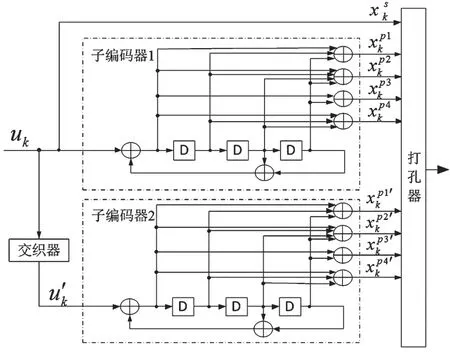
圖3 改進的Turbo 編碼器結構
在碼長為2 020,調制方式為二進制相移鍵控(Binary Phase Shift Keying,BPSK),信道為加性高斯白噪聲(AdditiveWhiteGaussianNoise,AWGN),BER為10-5的仿真實驗場景下,迭代12次,仿真驗證結果如圖4 所示。相對于以1/3 碼率重復得到1/5 碼率的方案,1/5 母碼率方案有0.6 dB的BER性能提升;相對于以1/5 碼率重復得到1/7碼率的方案,1/7 母碼率方案有0.5 dB 的BER性能提升;相對于以1/7 碼率重復得到1/9 碼率的方案,1/9 母碼率方案有0.4 dB 的BER性能提升。
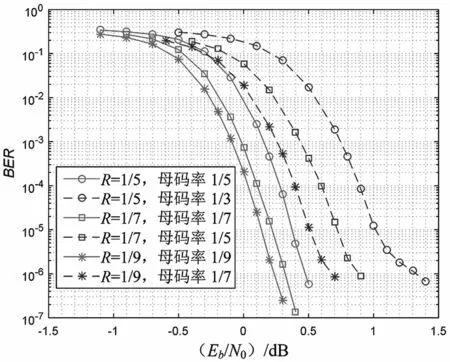
圖4 低母碼率方案性能對比
2 DSP 實現
2.1 DSP 芯片簡介
本文選用的是TEXAS INSTRUMENTS(簡稱TI)公司的TMS320C6678 多核DSP 芯片。TMS320C6678是TI 基于KeyStone 的多核數字信號處理器,主頻高達1.25 GHz,集成了8 個C66x CorePac,其中每個核都有各自獨立的L1 和L2 緩存,具有4 MB 共享內存空間[8]。
TI 針對C66x 系列內核程序優化,提供了高效的編譯器,可自動進行軟件流水優化。同時,也提供了很多高效的數學計算內聯函數,因此可利用內聯函數進行并行計算優化,提高計算效率[9]。例如,使用_dsadd2()內聯函數可實現4 個short 類型的并行飽和加法。
2.2 定點量化
根據硬件實現的需求,譯碼器實現時,需將浮點數據轉換成相應的定點數據。通常輸入譯碼器數據按照6 bit 量化時,可以獲得接近浮點的算法性能。根據項目需求,如表1 所示,本文設計接收信息y位寬為8 bit。參考文獻[10]的分析,結合MAP 算法計算公式,可設計Γ位寬為11 bit,A和B位寬為13 bit,LLR位寬為15 bit,Le位寬為11 bit。最后根據DSP 的運算單元數據類型,設計接收信息y使用8 bit 的char 型數據,Γ,A,B,LLR和Le相應擴展數據位寬,并使用16 bit 的short 型數據。
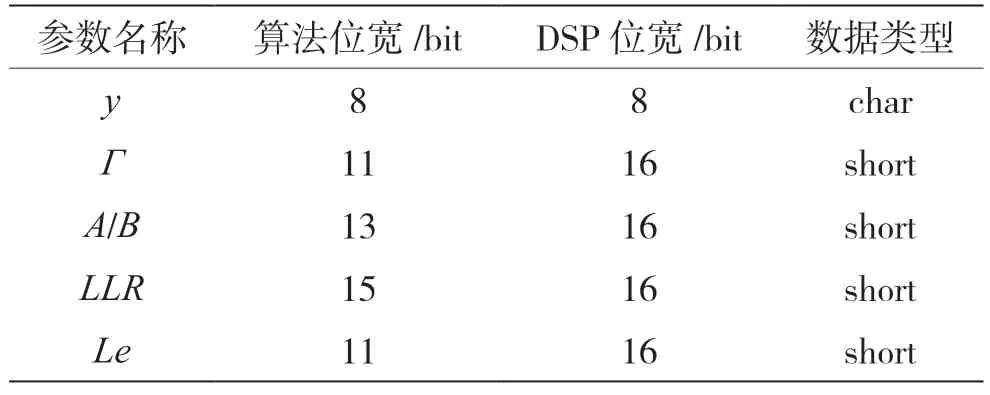
表1 定點量化設計
2.3 實現優化
根據前面推導的譯碼算法的計算過程,可將DSP 實現歸納為以下步驟:
(1)計算分支度量Γ;
(2)根據Γ計算狀態度量A和B;
(3)根據A和B計算外信息Le;
(4)將外信息經過交織或解交織后得到的信息作為另一分量譯碼器的先驗信息;
(5)重復1~4 步驟,直到完成設定的迭代次數,將最后一次的LLR判決譯碼輸出。
由Γ的計算公式(5)可知,其中的g(xk,yk)不包含先驗信息,可預先計算,而不必每次迭代重復計算。另外,根據圖3 的編碼器結構可推導出其編碼狀態轉移表如表2 所示。觀察編碼狀態轉移表可知,在輸出校驗位的位數小于4 時,輸出校驗位取值有對稱相等的情況,可利用其對稱性減少分支度量的重復計算及數據存取。例如,校驗位為3 位時,當前狀態為0,輸入比特為0 時,下一狀態為0 和4 時的校驗位輸出都為000。
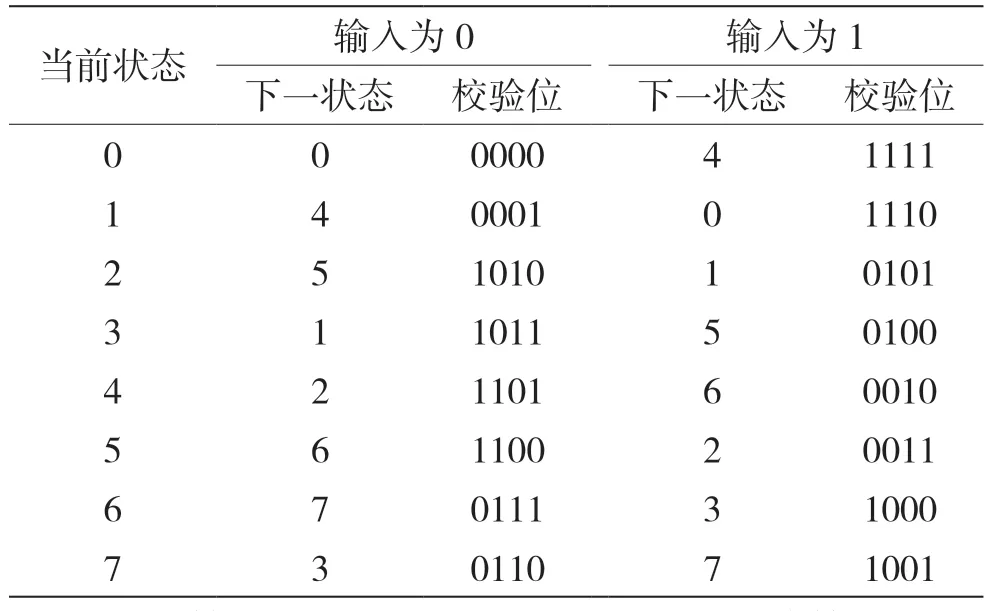
表2 編碼狀態轉移表
譯碼算法主要是加法、減法和max 計算,可以選擇DSP 支持的內聯函數_dsadd2()、_dssub2()和_dmax2()。以上內聯函數能夠支持64 bit 的long long類型數據位寬,可同時對4 個short 類型數據進行并行計算。根據前面并行譯碼算法的分析,可將原始碼塊劃分成4 個并行計算的子塊,正好匹配4 倍并行內聯函數,從而提高計算效率。
通過以上分支度量計算優化和并行譯碼算法的改進,極大提升了譯碼算法的計算效率。采用單核計算,利用DSP 芯片內timer 計數測量程序運行時鐘周期,結果如表3 所示。所驗證場景的碼塊長度為2 020,譯碼迭代12 次。
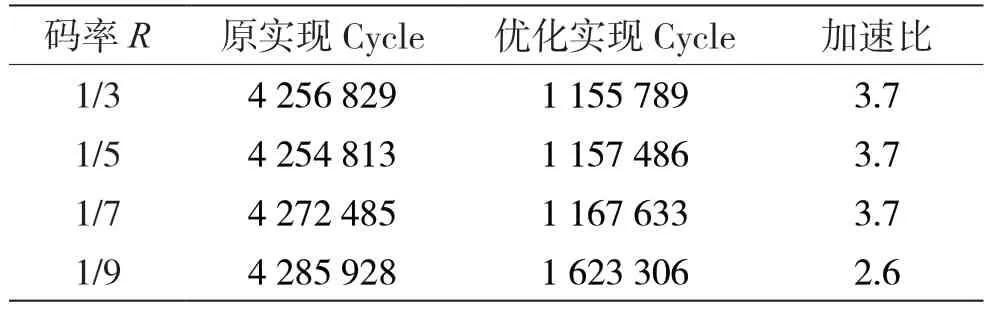
表3 DSP 實現優化計算效率提升
2.4 性能驗證
對DSP 并行定點實現算法和非并行浮點算法性能進行仿真對比。在碼長為2 020,調制方式為BPSK,信道為AWGN 的場景下,迭代12 次,驗證碼率分別為1/3,1/5,1/7,1/9 時,譯碼器的BER性能仿真結果如圖5 所示。從圖5 中可以看出,并行定點實現算法和非并行浮點算法性能一致,各碼率下未出現明顯的錯誤平層問題。此外,該DSP 實現的譯碼器在工程項目中得到了驗證,性能也和仿真一致。
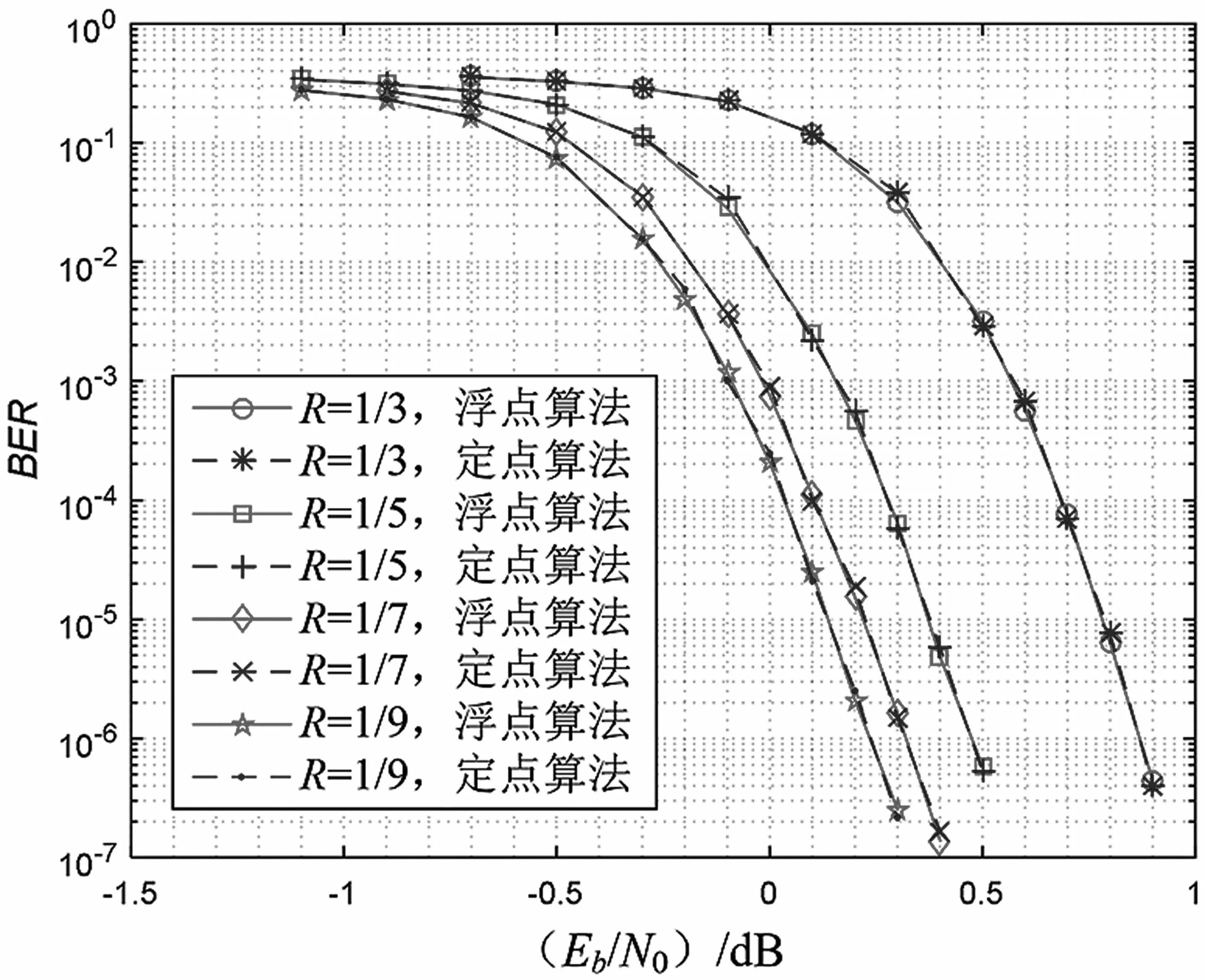
圖5 譯碼器BER 性能驗證
3 結語
本文在數據鏈通信系統的項目需求背景下,研究了5G Turbo 譯碼增強方案,針對傳統Turbo 碼的不足,提出了改進設計。此外,結合并行譯碼算法對譯碼器的DSP 實現進行了優化。仿真和項目驗證表明,該設計性能達到預期,具有較高的工程應用價值。
