基于分解和超平面擬合的進化超多目標優化降維算法
2022-09-22 03:36:54劉海林肖俊榮
電子與信息學報 2022年9期
劉海林 肖俊榮
(廣東工業大學應用數學學院 廣州 510520)
1 引言
在自然科學和工程實際問題中,經常會出現多目標優化問題。當目標個數大于3時,通常稱該問題為超多目標優化問題。隨著大數據的廣泛應用,出現超多目標優化的情形將會越來越普遍[1-7]。目標的增多可能會存在目標之間不一定都是互相沖突的,其中可能存在一些目標與其它目標是正相關關系,這些目標對求解該問題的前沿界面 (Pareto Front,PF)是不必要的,稱為冗余目標。如果能找出這些冗余目標,把它剔除,就可使求解的超多目標優化問題得到極大的簡化[1,8-11]。將冗余目標從超多目標優化問題中剔除的過程稱為目標降維[12,13]。在目標降維研究領域,已有的算法主要分為下面兩種類型:
(1) 基于支配關系的算法。具有代表性的是[10],該算法先用多目標進化優化算法求得一組PF近似解,再利用這組解之間的支配關系,剔除那些對整體支配結構影響較小的目標。PCSEA[8](Pareto Corner Search Evolutionary Algorithm)是該類型另一個較知名的算法,與其它降維算法不同的是,PCSEA是先用多目標進化優化算法找出所有的corner解,再利用這些corner解來判斷是否有冗余目標。然而,PCSEA只能處理部分類型的目標降維問題,有些情況無法處理,這點在該算法的論文中也有提到。
(2) 基于相關關系的算法。該類算法一般是先運行多目標進化優化算法求得問題的一組PF近似解,再根據這組解反映出的目標之間的相關信息來找出冗余目標。這類算法具有代表性的有文獻[14]提出的算法L-PCA, L-PCA可以處理PF為線性的目標降維問題,但在處理一些PF為非線性的目標降維問題時遇到了困難。為了解決該問題,Saxena等人[1]提出了算法MVU-PCA,MVU-PCA利用了流形學習中的算法MVU (Maximum Variance Unfolding),把在幾何上非線性的PF轉化為線性的PF,再采用L-PCA的方法進行目標降維。MVUPCA在處理一些PF非線性的目標降維問題時有了一定的效果。L-PCA和MVU-PCA可以較好地處理一些目標與單個目標正相關導致冗余的目標降維問題,例如測試問題DTLZ5(I, m)[1];對于目標與多個目標存在多元相關關系導致冗余的目標降維問題則難以處理,例如測試問題MAOP(I, m)[9]。
文獻[15]提出了一種不同于上述類型的目標降維算法,該文設計了一種用超平面擬合的算法,提出了算法LHA和NLHA[15]。該方法利用多目標進化優化算法求得PF的一組近似解,再用一個超平面去擬合這組近似解,從而判斷出哪些目標是冗余的。該方法簡單、高效,不僅可以處理冗余目標與單個目標正相關,還能處理冗余目標與多個目標線性組合正相關的目標降維問題。遺憾的是,LHA在處理PF為非線性的降維問題時易出錯,這點在LHA處理測試問題集MAOP(I, m)中有反映出來;而NLHA是通過一種目標的冪變換,來使非線性的PF映射到新的目標空間中靠近某個線性超平面,再用超平面擬合的方法進行降維。遺憾的是,NLHA的處理方法只能把少部分類型的PF線性化,在復雜形狀的PF情況下,仍難以達到有效的降維效果。由于在實際問題中,非線性的PF更加常見,因此,在基于超平面擬合方法的基礎上,找到一種新的技術來處理PF為非線性的目標降維問題具有重要的意義。
本文提出了一種基于分解和超平面擬合的目標降維算法(Decomposition and Hyperplane Approximation, DHA)。該方法利用“以直代曲”的思想將幾何上非線性的PF近似解集分解為多個近似線性的PF近似解子集,通過構建的帶擾動項的稀疏超平面擬合的數學模型,找到一個最優的綜合超平面去擬合這些子集,最后根據該超平面提取出原問題的本質目標集。相比于LHA, DHA可以更好地處理PF為非線性的目標降維問題;相比于NLHA,DHA在處理非線性的PF時注重的是局部,通過放大局部特征,可以更好地把握目標間的沖突關系,具有更好的穩定性。
本文第2節簡單地引入目標降維問題的一些相關概念;第3節將詳細介紹本文提出的目標降維方法DHA;第4節將對本文提出的算法DHA進行實驗,并與其它有代表性的目標降維算法進行對比;第5節是對本文所做工作的總結。
2 目標降維問題的相關概念與基于超平面擬合的目標降維算法簡介
2.1 目標降維問題的相關概念
一個多目標優化問題可以表示為下面的式子:


2.2 基于超平面擬合的目標降維算法介紹


3 基于分解和超平面擬合的目標降維算法
3.1 基本思想與模型的構建
當多目標優化問題的PF呈非線性時,采用基于超平面擬合的降維方法可能難以達到去冗余效果。例如,一個3個目標的多目標優化問題,種群進化到后期呈現如圖3所示情形。從圖中可以看出目標f1和 目標f2是 相互沖突的,f2與f3呈正相關關系,因此f3和f2中之一可作為冗余目標去除。按照基于超平面擬合的降維算法,則需擬合出平行于f3或f2的平面,才可達到去冗余效果。而當種群處于圖3的情形時,它的最優擬合超平面很可能是圖3中的藍色平面,該平面的截距均大于0,依此超平面無法發現冗余目標f3。 實際上,由于f3是冗余的,因此它對于種群中的每一部分來說都是冗余的。假設將圖3所示的種群分解為3個子種群,如圖4的紅色、綠色、藍色實心圓所示,去除f3對每個子種群內個體的支配關系都不影響,即f3對于每個子種群來說都是冗余的。由于子種群的分布相對于整個種群通常更接近于線性的,因此從子種群更容易擬合出平行于冗余目標的平面,達到去冗余的效果。
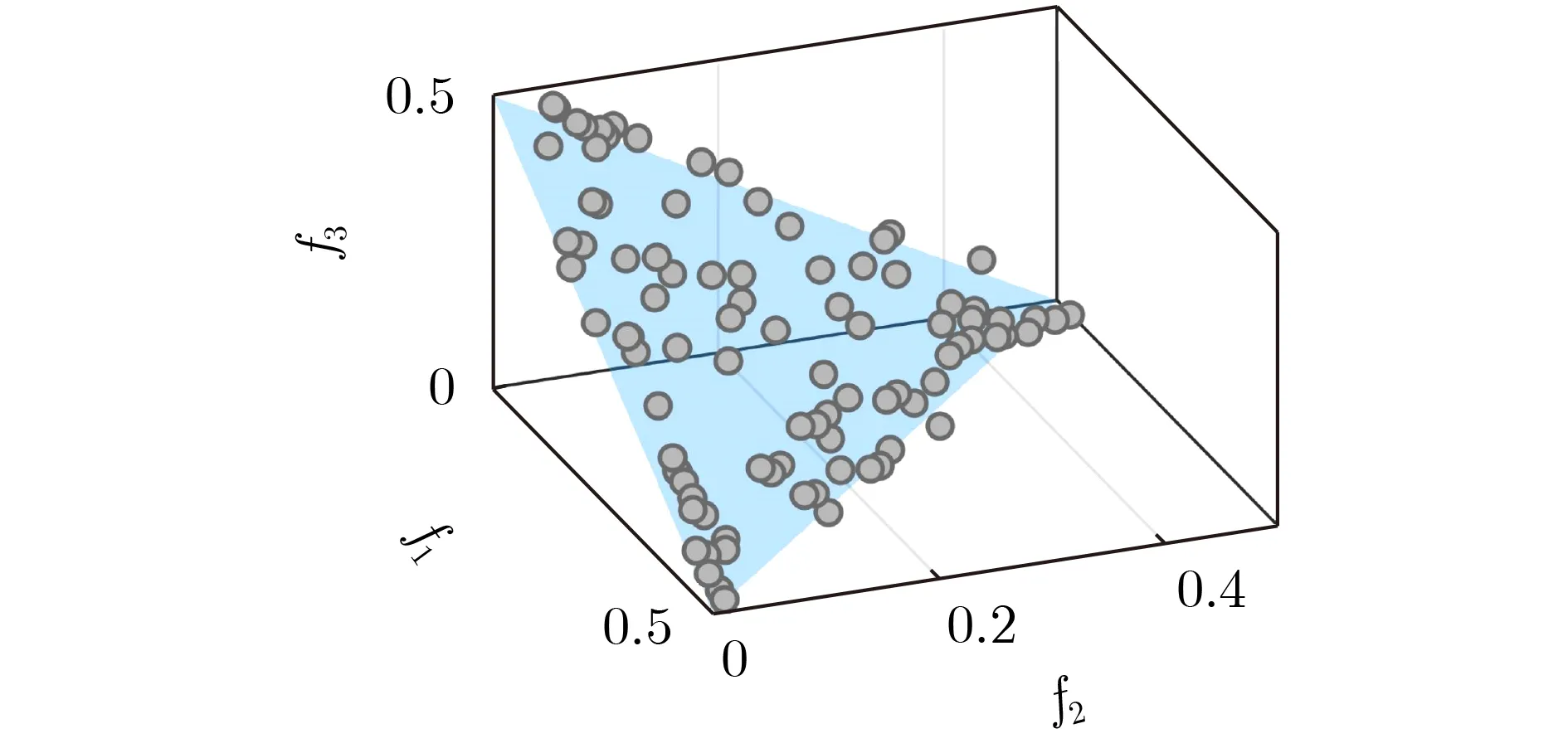
圖1 目標均非冗余時超平面擬和種群示意圖

圖2 存在冗余目標時超平面擬合種群示意圖

圖3 用超平面擬合非線性的種群分布的示意圖

圖4 多個平面擬合非線性種群分布示意圖
另一方面,應該考慮的是分解后對子種群采用超平面擬合的方法會不會把本質目標錯當冗余目標去除。實際上,由于子種群跟整個種群的沖突關系是不一定等價的,因此存在一些情況可能會導致過度降維。該情況是:當某個目標對于整個種群來說是不可或缺的,但它對于每個子種群來說又是冗余的。我們認為出現這種情況是比較少的。對于大多數情況來說,本質目標至少對PF的某個部分來說是不可或缺的,一旦缺失會改變相應部分個體之間的支配關系。
因此,針對非線性的PF,本文將種群分解為多個子種群,用基于超平面擬合的方法從子種群中提取冗余目標,達到更好的去冗余效果。為避免從不同子種群提取出不同的本質目標集,本文采用單一超平面加一些細微的系數擾動來擬合所有子種群,最后用該超平面反映的沖突關系作為提取結果。
根據上面的討論,本文提出了DHA的數學模型:


3.2 一種基于角度的分解策略

該分解方法既考慮了子種群中心的分布性又考慮了子種群內個體的聚集性,既反映種群總體的特征,也反映它的局部特征。因此,該分解方法可以較好地保留種群攜帶的信息。
3.3 目標降維算法框架
本節提出兩個算法框架,分別是在線的(表1)和離線的(表2)進化目標降維算法DHA框架。
在表1的步驟2中調整MOEA/D-M2M的權重向量是因為基于分解的算法在獲取初始權重向量時是在單位超立方里布點的,對于PF取值范圍差距很大的問題,若不調整權重向量的尺度,將導致后續再次進化時獲取的解集的分布性較差,該策略在文獻[15]有詳細介紹。在表1的步驟3和步驟5分別是對問題的第1、第2次目標降維。將相應的種群輸入到離線的DHA中(表2),DHA根據3.1節所述的原理和數學模型進行降維,具體步驟在表2中。在第2次降維后若沒有目標減少,則認為已找不到冗余目標并

表1 在線的進化目標降維算法DHA

表2 離線的目標降維算法DHA

4 實驗設計與實驗結果
4.1 評價指標
評價算法的性能需要恰當的評價指標。本文采用文獻[15]中使用的成功率指標和σ?指標。其中,成功率是指在某個問題中成功提取本質目標集的概率,在計算時用對問題成功提取本質目標集的次數除以總運行次數。對于σ?指標,它的定義式為


4.2 參數設計
為了展示本文所提算法的效果,本文選擇了幾個有代表性的降維算法作為對比算法:基于相關關系的L-PCA和NL-MVU-PCA;基于支配關系的greedyδ-MOSS和PCSEA;基于超平面擬合的LHA和NLHA。對比算法的參數大小均設置為原論文設置的大小,如表3所示。

表3 降維算法參數表
為了檢測算法的效果,測試函數是必不可少的;本文采用了3個常用的目標降維算法測試函數集:



對于實驗數據的獲取分為無噪聲和帶噪聲兩種情況,無噪聲指從問題的真實PF中獲取數據;帶噪聲指未從PF取點,用多目標進化優化算法運行一次代數后的PF近似解集。近似解集中可能含有一些未收斂到真實PF的點,這些點稱為噪聲點。由于DTLZ5(I,m)和MAOP(I,m)是相對容易收斂的測試函數,因此本文對其獲取帶噪聲時的數據;而WFG3(I,m)是一個難以收斂的測試函數集,本文只測試它們在真實PF取點(無噪聲)的情況。


4.3 實驗結果與分析
對于測試問題DTLZ5(I,m)。從表4、表5可以看出,本文提出的算法DHA與其他算法相比,具有較高的穩定性。對于LHA, PCSEA在個別問題上的表現不佳,從表5顯示它們存在個別σ?值為0的情況,這反映著它們對應問題上沒有去冗余效果。LHA, NLHA它們在DTLZ5(2, 50)的成功率較低,而σ?值卻較高,這顯示了雖然它們有不錯的去冗余效果,但很多時候不能完全去冗余。而本文DHA在該問題上的兩個指標值都穩定且較高,這反映著DHA在個別情況下優于LHA, NLHA。

表4 各算法在DTLZ5(I, m), WFG(I, m), MAOP(I, m)問題上的降維成功率

表5 各算法在DTLZ5(I, m)、WFG(I , m),MAOP(I, m)問題上的的平均σ ?值
對于測試問題集WFG3(I,m),它是一個PF為線性的測試問題集。從表4和表5可以看到,DHA對每個測試情況都能較好地處理,而對于算法LPCA, NLMVUPCA, PCSEA存在個別成功率和σ?值都為0的情況,即沒有降維效果。對于算法LHA,NLHA也能較穩定地處理每種情況。對該測試問題,由于PF是線性的,DHA對于LHA和NLHA沒有明顯的優勢,但也反映了DHA能較好處理PF為線性的帶冗余目標的超多目標優化問題。
MAOP(I,m)中的冗余目標不是跟單個目標正相關,而是與多個目標存在多元相關關系,這大大地增加了目標降維的難度。從表4和表5可以看出,LPCA, NLMVUPCA對該問題的大部分測試情況的成功率和對應的σ?值都較低,效果較差。PCSEA只能較好地處理前4種情況,對于后面4個測試情況效果較差。其它4個包括DHA可以較好地處理該問題。從greedy-δMOSS在MAOP2(3, 5)的測試結果看到,該算法也存在一些情況不穩定的,受到了噪聲點的干擾。對于LHA和NLHA, DHA在MAOP4(4, 10)和MAOP6(6, 10)上有些許優勢。LHA和NLHA在這兩個測試函數的成功率較低而σ?值卻較高,這是因為他們去冗余效果不錯,但最終找出本質目標集的情況卻不多,而DHA在這兩方面都較好。
5 對DHA的進一步探究
5.1 DHA對進化算法的作用分析
為探究DHA在實際進化過程中起到的效果,本文將施加DHA的MOEA/D-M2M記為DHAMOEA/D-M2M與未施加DHA的MOEA/D-M2M對超多目標優化問題求解效果進行對比實驗,用傳統的反轉世代距離[18](IGD)作為評價指標。IGD的定義為

將DHA-MOEA/D-M2M與MOEA/D-M2M在測試問題DLTZ5(5, 10),DLTZ5(2, 20),DLTZ5(5, 20)進行實驗,兩個算法均運行600代后停止,對于前者在進化300代后調用DHA進行1次目標降維。對實驗的其它參數設置同第4節。對每個問題獨立運行20次,計算IGD值,實驗結果如表6所示。
從表6可以看到,除了MAOP1(3, 5),其它運行結果均有明顯的提升。這反映了在進化過程中使用DHA進行目標降維,可以有效提高所求解集的質量。

表6 DHA-MOEA/D-M2M與MOEA/D-M2M在各個測試函數獨立運行20次的平均IGD值與標準差
5.2 對DHA參數的敏感性分析
DHA需要設置兩個參數:子種群個數K和參數λ。在第4節的實驗中K設為10,λ設為1。為檢驗DHA的穩定性,現將K取5個值:6, 8, 10, 12, 14,λ取5個值:0., 1, 1.5, 2, 2.5,兩個參數兩兩配對在測試問題MAOP5(6, 10)上進行實驗,計算各自降維成功率,將得到的25個實驗結果作3維曲面圖,結果如圖5所示。從圖5可以看到,DHA對子種群數K和參數λ的取值在一定區域內不敏感,通過合適的取值可以使DHA保持較高的成功率。
5.3 種群大小對DHA降維效果的影響分析
對于PF的真實維數較高的超多目標優化問題,若種群個體太少,則可能因難以刻畫真實PF的特征導致對問題過度降維的結果。由于DHA是基于種群分解,因此種群大小對DHA的影響會大于其他算法。為探究該影響,本文采用DTLZ5(2, 5),DTLZ5(5, 10), DTLZ5(7, 10)作為測試問題;將每次進化代數G設為固定300;種群大小N分別設為20,30,50,100,200,300,400;其他參數同4.1節的設置。采用在線的DHA框架,對每個問題獨立運行20次,實驗結果如圖6所示。從圖中可以看到當問題的PF真實維數不高時,如DTLZ5(3, 5)和DTLZ5(5, 10),DHA對種群大小的要求不高,適當的取值均可獲得較高的成功率。而對于PF真實維數比較高的問題DTLZ5(7, 10),此時種群不宜太小,太小則會影響效果。從圖6可以看到,當種群大小設為200以上時,DHA對DTLZ5(7, 10)保持了較高的降維成功率。
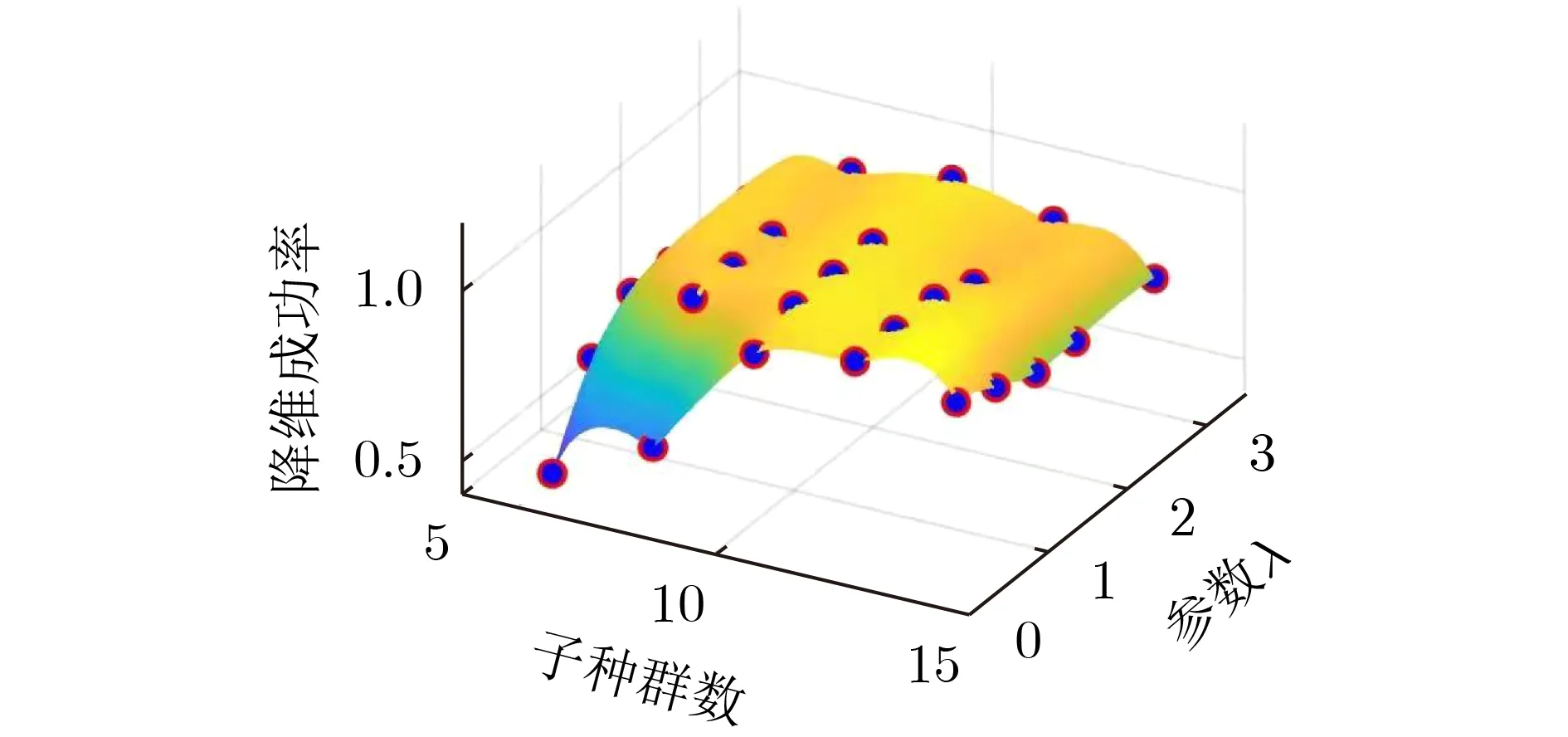
圖 5 DHA對應不同的K , λ 值在MAOP5(6,10)上的降維成功率曲面圖

圖 6 不同種群大小下,DHA在相應問題的降維成功率變化圖
6 結束語
本文提出了一種基于分解和超平面擬合的目標降維算法DHA。在該算法中,種群中的非劣解集基于角度被分解成多個非劣解子集,根據本文構建的DHA的數學模型找到一個綜合的超平面結合擾動項來擬合這些子集,進而根據該超平面提取原問題的本質目標集。該算法既可以處理前沿界面分布為線性,也可以處理前沿界面分布為非線性的目標降維問題。為了測試DHA的性能,采用3個常用的目標降維測試問題DTLZ5(I,m), WFG3(I,m)和MAOP(I,m),并與當前具有代表性的目標降維算法進行對比。計算機仿真結果表明提出的算法無論前沿界面是線性或非線性的情形都具有優異的性能。當前的目標降維算法大都是以進化到一定代數的非劣解集作為近似的PF來找出冗余目標,是否存在一個更好的判斷冗余目標的方法,還有待進一步研究。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
中老年保健(2021年12期)2021-11-30 02:58:01
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
Coco薇(2016年8期)2016-10-09 02:11:50
現代企業(2015年2期)2015-02-28 18:45:09
