一種基于生成對抗網(wǎng)絡的建筑能耗多步預測方法
2022-09-22 07:49:28張卓淵
電腦知識與技術 2022年23期
張卓淵
(廣東工業(yè)大學,廣東廣州 510006)
1 概述
中國提出了力爭在2060年前實現(xiàn)碳中和的目標,其中建筑部門作為造成碳排放的主要責任領域之一,建筑運行時的節(jié)能減排備受關注[1]。與此同時,隨著經(jīng)濟社會的發(fā)展,人們對建筑環(huán)境的要求日益提高,準確地預測建筑能耗將有助于蓄冷策略規(guī)劃和可再生能源耦合等一系列建筑節(jié)能減排措施的實施[2-3]。
建筑能耗預測方法根據(jù)時間步長一般可分為單步預測和多步預測方法[4]。單步預測方法僅預測下一時刻的能耗,但在建筑能耗預測任務中,通常需要預測多個時間步長判斷未來的能耗變化趨勢,因此許多研究者對建筑能耗多步預測方法進行研究。而在建筑能耗多步預測方法中,深度學習模型是研究的主流方向。Rahman等[5]運用循環(huán)神經(jīng)網(wǎng)絡(Recurrent Neural Network,RNN)對商業(yè)建筑和住宅建筑能耗進行中長期預測,Zhou等[6]將長短期記憶神經(jīng)網(wǎng)絡(Long Short-Term Memory,LSTM)用于辦公室照明插座能耗多步預測,Kim等[7]將LSTM和卷積神經(jīng)網(wǎng)絡(Convolutional Neural Networks,CNN)相結合預測住宅能耗數(shù)據(jù)。
近年來,生成對抗網(wǎng)絡[8](Generative Adversarial Networks,GAN)能夠以其獨特的對抗思想,利用反向傳播直接修正網(wǎng)絡輸出的分布,進一步捕捉數(shù)據(jù)間的深層次非線性關系,在金融[9]、農(nóng)業(yè)[10]相關序列預測研究中均顯示了其有效性。為進一步提高建筑能耗多步預測的精度,本文提出了一種基于GAN的建筑能耗多步預測方法,將LSTM作為生成器,CNN作為判別器,利用GAN中生成器和判別器的對抗思想進一步捕捉數(shù)據(jù)間的深層次非線性關系,降低預測誤差。本文以美國某大學實驗樓的能耗數(shù)據(jù)進行實驗,直接預測未來24小時的能耗數(shù)據(jù),結果驗證了本文提出方法的有效性。
2 相關工作
2.1 建筑能耗多步預測方法
根據(jù)文獻[4]總結,建筑能耗預測方法分為單步預測和多步預測方法。多步預測原理如圖1所示,通過輸入長度為n的歷史能耗序列進入模型,預測出未來m個時刻的能耗序列。
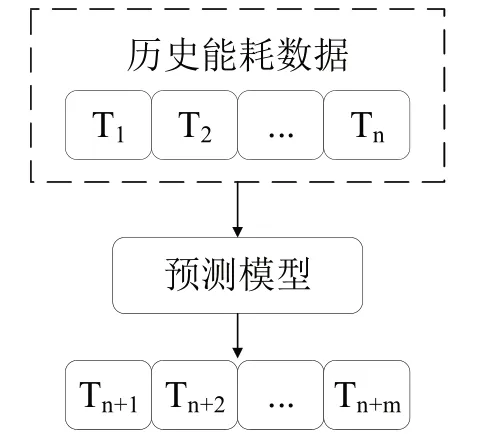
圖1 多步預測方法
2.2 生成對抗網(wǎng)絡原理
生成對抗網(wǎng)絡是Goodfellow等[8]基于零和博弈思想提出的模型。如圖2所示,模型由兩個神經(jīng)網(wǎng)絡:生成器網(wǎng)絡和判別器網(wǎng)絡組成。生成器網(wǎng)絡不斷學習真實數(shù)據(jù)的分布,擬合偽造數(shù)據(jù)去欺騙判別器網(wǎng)絡,而判別器網(wǎng)絡則盡力去辨別輸入的數(shù)據(jù)是生成器網(wǎng)絡擬合的偽造數(shù)據(jù)還是真實數(shù)據(jù),兩者的最終目標是達到納什平衡,讓生成器網(wǎng)絡學習到真實的數(shù)據(jù)分布。其損失函數(shù)表達式如式(1)所示:
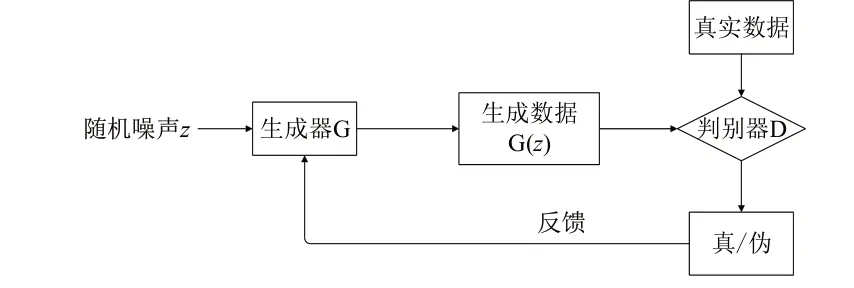
圖2 生成對抗網(wǎng)絡基本結構
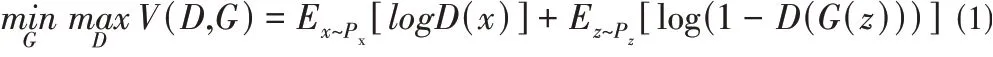
式(1)中,Px為真實數(shù)據(jù)分布,Pz為輸入的噪聲分布,生成器為了學習真實分布Px,通過輸入隨機分布的噪聲z生成偽造數(shù)據(jù)G(z),生成器的目標是騙過判別器,使得D(G(z))的值越大。而判別器的目標則是正確判別數(shù)據(jù)的真?zhèn)危沟肈(x)值越大,D(G(z))值越小。
3 一種基于GAN的建筑能耗多步預測方法
3.1 預測模型設計
本模型結構如圖3所示,給定一段真實歷史能耗數(shù)據(jù)X={x1,x2,…,xt},t為時間窗口長度,將序列X輸入生成器,生成器輸出預測序列Xf={x^t+1,x^t+2,...,x^t+24},其對應的真實序列為Xr={xt+1,xt+2,...,xt+24}。接著將預測序列Xf和對應的真實序列Xr橫向拼接組成序列Xfake和真實序列Xreal輸入判別器,判別器區(qū)分輸入序列的真?zhèn)巍V云唇映尚蛄械男问捷斎攵皇侵苯訉f和Xr輸入進判別器,是為了使判別器能夠捕獲相關的時間序列信息。判別器將判別的結果反饋給生成器,生成器再根據(jù)判別器的結果調整自己的輸出,再次嘗試騙過判別器。兩者互相對抗,最終生成器準確預測出建筑能耗數(shù)據(jù)的未來分布。
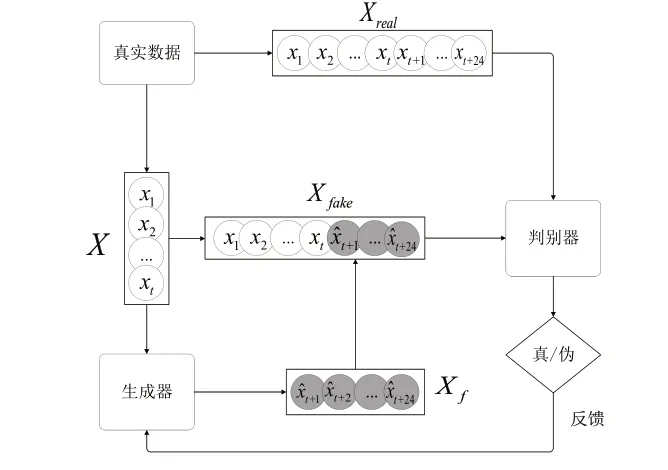
圖3 基于建筑能耗預測的生成對抗網(wǎng)絡
本文模型生成器結構為LSTM,LSTM在處理時間序列數(shù)據(jù)時具有長期記憶的能力,具有較好的預測效果。判別器采用CNN卷積神經(jīng)網(wǎng)絡結構,CNN具有良好的提取深層特征的能力,作為判別器能夠有效分辨出輸入數(shù)據(jù)的真?zhèn)巍Mㄟ^LSTM和CNN在訓練之間互相的對抗博弈,模型能夠進一步捕捉數(shù)據(jù)間的深層次非線性關系,得到更精準的預測結果。
3.2 損失函數(shù)
由于原始GAN網(wǎng)絡的損失函數(shù)在訓練過程中存在梯度消失或梯度爆炸的問題,Mao[11]提出最小二乘損失(Least Squares GANs,LSGAN),它可以根據(jù)樣本與決策邊界的距離對樣本進行懲罰,從而解決原始GAN訓練不穩(wěn)定的問題。本文引入最小二乘損失作為判別器和生成器的損失函數(shù),判別器損失函數(shù)定義為:
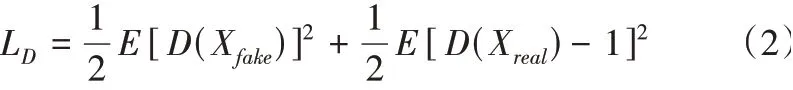
生成器損失函數(shù)定義為:
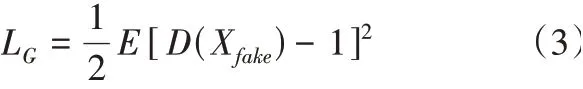
同時,為了使生成模型的預測結果更接近真實能耗分布,本文在生成器訓練過程中加入x^t+1和xt+1的L1范數(shù)作為生成器損失函數(shù)的一部分,定義為:
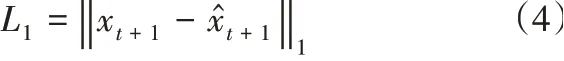
因此生成器的總損失函數(shù)為:
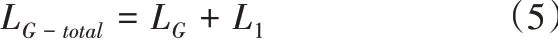
3.3 預測流程
建筑能耗預測的整體算法流程圖如圖4所示。首先將數(shù)據(jù)集按7:3的比例劃分為訓練集和測試集,對訓練集數(shù)據(jù)歸一化到[0,1]之間,測試集數(shù)據(jù)再根據(jù)訓練集進行歸一化,這樣做是為了防止歸一化過程中數(shù)據(jù)泄露的問題。接著利用時間窗口劃分數(shù)據(jù)集,為充分利用訓練集進行訓練,訓練集時間窗口步長設置為1,而測試集時間窗口步長設置為24。運用重構的訓練集對建筑能耗預測GAN模型進行訓練。通過生成器和判別器的對抗博弈,生成器能夠預測出未來的建筑能耗。
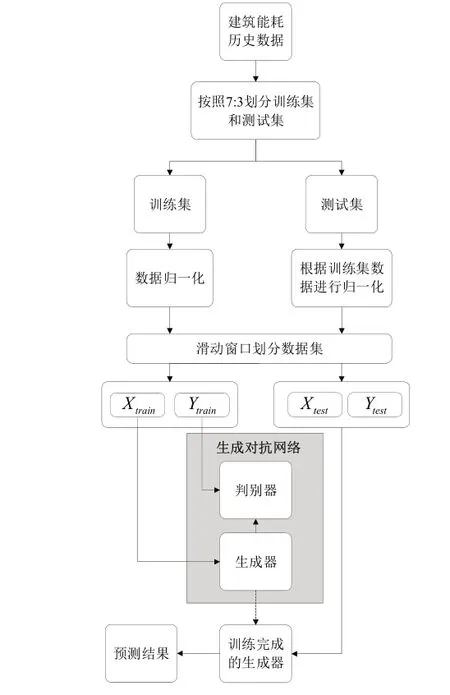
圖4 建筑能耗預測流程圖
4 實驗與分析
4.1 實驗設置及數(shù)據(jù)集
本實驗基于Pytorch框架進行,CPU為AMD2700X,GPU為NVIDIA RTX 2080,選用美國某大學實驗樓從2014年12月1日到2015年11月29日總共364天的能耗數(shù)據(jù),數(shù)據(jù)間隔為每小時采樣一次,總共8736個數(shù)據(jù)點,將其按照7:3比例劃分為訓練集和測試集。每日能耗分布箱型圖如圖5所示,由圖5得出每日的能耗高峰分布在日間(8:00-18:00),而夜間非工作時間能耗較低,與現(xiàn)實情況相符合。
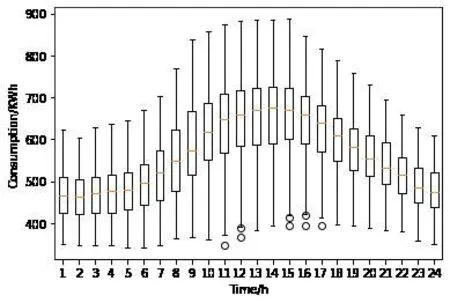
圖5 每日能耗分布箱型圖
4.2 評價指標
為客觀評價模型的預測效果,本文采用平均絕對誤差(Mean Absolute Error,MAE),均方根誤差(Root Mean Squared Error,RMSE)和回歸決定系數(shù)R2作為本文模型的客觀評價指標。以上指標的公式定義如下,式中i為預測值,xi為對應的真實值,n為數(shù)據(jù)集長度為真實數(shù)據(jù)平均值。
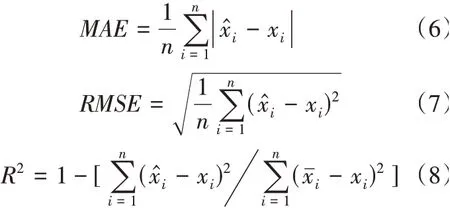
4.3 超參數(shù)選擇
4.3.1 LSTM神經(jīng)元數(shù)目
神經(jīng)元數(shù)目是影響模型性能的因素之一,神經(jīng)元數(shù)目過小或過大都會導致模型性能的降低。本文設置神經(jīng)元數(shù)目為{128,256,512,1024},預測結果如表1所示。由表1可得神經(jīng)元數(shù)目取512時MSE最低,預測誤差最小,因此選擇LSTM神經(jīng)元數(shù)目為512。
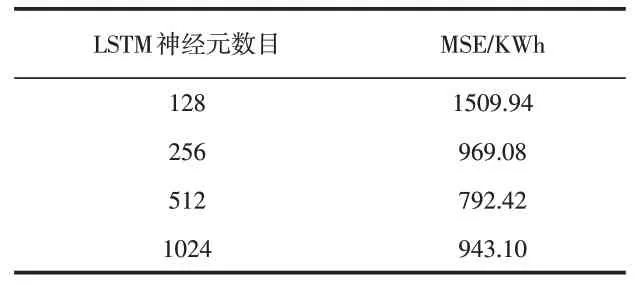
表1 LSTM不同神經(jīng)元數(shù)目的對比
4.3.2 時間步長
如圖6所示為隨機選取的兩周能耗數(shù)據(jù),由圖6可知,在工作日(周一~周五)的能耗較高,而在非工作日(即周末)的能耗較低,整體能耗以一周為單位呈現(xiàn)周期性波動,因此設置時間步長為一周(即t=7×24=168)。
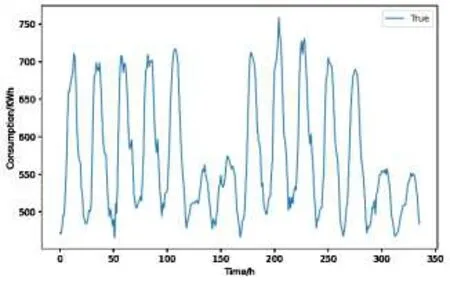
圖6 兩周的能耗數(shù)據(jù)
4.4 實驗分析
為了客觀驗證本文模型的準確性,本文選擇了LSTM[6]、CNN-LSTM[7]模型進行對比,預測結果如表2所示,從表2中可以看出,基于GAN的預測模型在MAE和RMSE指標上均為最低,說明相比于其他模型,GAN的預測結果與真實能耗值之間的誤差最小。而在R2指標上GAN相比于其他方法更接近1,說明GAN的預測能耗值和真實能耗值之間相關性越強。證明了通過生成器和判別器的對抗訓練,能夠進一步學習到數(shù)據(jù)間的深層次非線性關系,得到更精確的結果。
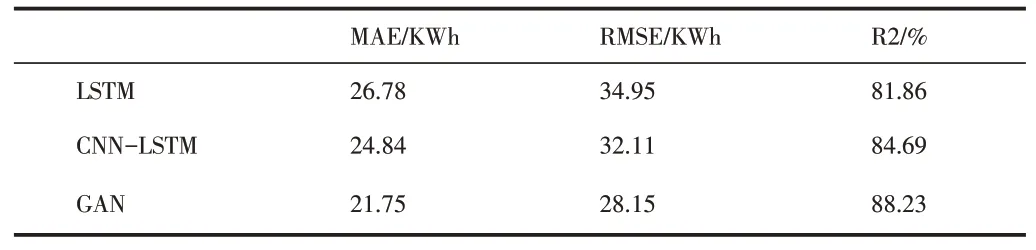
表2 不同模型的指標對比
LSTM、CNN-LSTM和GAN模型的預測結果(隨機選取兩周)如圖7~圖9所示。由圖可得,三種模型都能預測出能耗的大致趨勢,但由于非工作日(周六日)與工作日(周一~周五)相比能耗變化幅度較大,因此三種模型在非工作日的預測結果都出現(xiàn)一定的誤差,其中LSTM誤差較大,而CNN-LSTM和GAN的誤差較小。從總體上看,GAN模型的預測曲線與實際曲線的重合度最高,這也與表2的結論相符合。
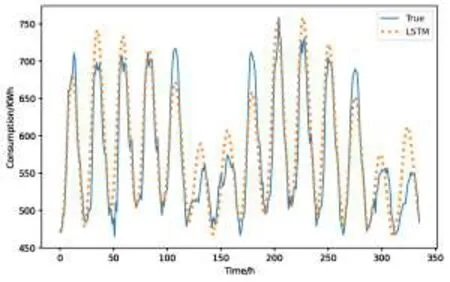
圖7 LSTM的預測結果

圖8 CNN-LSTM的預測結果
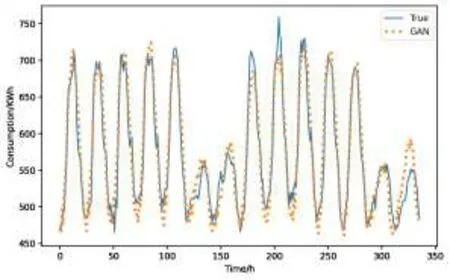
圖9 GAN的預測結果
5 結論
本文提出一種基于生成對抗網(wǎng)絡的建筑能耗多步預測方法,以LSTM為生成器,以CNN為判別器,以歷史能耗數(shù)據(jù)作為輸入,預測建筑未來24小時的能耗值。實驗結果證明,通過生成對抗網(wǎng)絡的對抗性訓練,能夠進一步學習數(shù)據(jù)間的隱層關系,降低預測模型的誤差。通過超參數(shù)的調整,本文模型在MAE、RMSE、R2指標上達到了最佳,準確預測出未來的建筑能耗,可為建筑的能源規(guī)劃、能耗管理和節(jié)能減排的優(yōu)化提供一定的指導。后續(xù)工作將考慮天氣狀況及室內(nèi)人數(shù)等條件因素對建筑能耗的影響,構建更精確的建筑能耗預測模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
北方建筑(2021年6期)2021-12-31 03:03:54
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
文苑(2020年10期)2020-11-07 03:15:36
現(xiàn)代裝飾(2020年6期)2020-06-22 08:43:12
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
意林原創(chuàng)版(2016年10期)2016-11-25 10:28:30
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
少兒科學周刊·兒童版(2015年6期)2015-11-24 03:49:38
